面向大数据环境的数据库隐私保护区块链模型
2022-10-28吴荣珍
吴荣珍
(福建农业职业技术学院 信息工程学院,福州 353123)
随着大数据技术的不断发展,数据存储的安全问题不容忽视.在大多数的分布式数据库系统中,系统管理员可以访问所有数据.数据库系统的内部威胁或在向第三方传输数据的过程中均有可能泄露数据库数据的隐私.差分隐私算法[1-2]和聚类算法[3-4]是用于隐私保护的常用方法,但是这些方法均无法处理如此大量的数据.对此,本研究基于区块链的技术,提出了一个面向大数据的数据库隐私保护模型.
1 数据管理策略
1.1 数据分配
区块链网络中的所有节点都应该同步整个数据库,以确保在用户账本的一致性.但是,当区块链系统拥有大量用户时,数据库可能会超过1 TB.用户本地硬盘的空间通常会小于1TB,因此将账本同步到本地将影响用户计算机的性能.假设用户u的空闲空间是φu,并且在时间t加入了网络系统.在时间T内产生的总信息记为ψ.假设网络规模足够大,对于任何时间t的用户u,数据管理策略都会为用户分配一个数据文件.文件的大小是确定的,且不会改变.用户u在加入网络时只同步固定数量的数据,数据文件大小取决于u的系统容量和加入时间t,数据的大小为:
(1)
由此可知,数据管理策略仅占用用户u可用硬盘空间的百分之一,不应影响设备正常运行.Lu代表保存在用户u中的账本.事务是指数据文件中不可分割的元素,其中包括事务的哈希信息、用户ID、时间戳、用户行为和行为类型.分配存储空间后,需要决定写入ξu的数据部分.为了保证有足够的备份文件,设计了一个标准来分割数据文件.用户u在加入社交链时将使用我们的同步算法同步ξu数据.每个数据块在同步到用户时都会被标记,数据管理策略将标记次数较少的数据发送给用户.数据同步的过程如算法1所示.算法1中,uid为hash加密后的用户ID,numMarked记录了的交易i的标记数.算法将标记次数较少的数据分配给用户u,并标记分配的事务.

算法1 数据分配算法输入:ξu、uid输出:Lu1:numMarked ← getMarked2:idx← 03:for i = 1 , i < d.length () , i + + do4: idx[i]←min(d)5: Del(numMarked[i])6: Lu ← wirte (get(i))7: marked(get(i), uid)8:ξu ← ξu - size(get(i))9: ifξu < = 0 then10: break
1.2 数据搜索
假设用户u在时间T0生成交易tu,并将其存储在Lu1中.在时间T1,假设Lu1因未知原因被破坏或被修改.数据管理策略必须确保对Lu1的修改不会成功,并确保在节点u丢失时社交链的性能.与传统区块链系统不同,数据管理策略中的用户并不拥有整个账本.因此,设计了一个搜索算法以允许用户u查询自己的交易.首先,搜索算法向加入社交链的每个节点广播查询请求.为了避免暴露用户的隐私信息,设计了一个请求包,其内容包括加密后的用户IDuid、用户网络地址、行为类型和时间戳.由于时间戳的存在,即使请求在传输过程中被拦截,攻击者也无法更改请求.此外,使用单向散列对用户ID进行加密,攻击者永远不会知道用户u的真实身份.一旦请求被广播,所有节点都会将请求包中的uid与它们拥有的uid进行比较.如果节点为uid存储数据,它会检查匹配交易的行为类型.所有节点将它们的搜索结果和时间戳返回给用户u.由于交易是加密的,几乎不可能泄露用户的隐私.
数据的日益增长为数据库带来巨大的压力,尤其是在整个区块链中存储如此多的数据会影响普通用户设备的性能,因此数据管理策略只需要存储敏感的数据.敏感数据类型主要有用户聊天记录、用户浏览记录、用户位置和用户个人信息,将非敏感数据存储在传统的分布式数据库中.
2 共识协议设计
共识协议可以在最短的时间内验证交易,是区块链的核心.对此,提出了通信证明的共识协议(如算法2所示),该协议在大多数情况下具有良好的拜占庭容错能力.使用基于时间的块生成方法[5],提出的协议需要确保一次只能将一个区块添加到共识链中.选举宣言是一个二元元组<时间戳,uid>,其中时间戳是用户决定选择区块的时间.假设块b是在时间t生成的,活跃用户可以根据其系统在时间t的性能来竞争成为记账者.对于从t-Δt到t生成的账本Lt,控制区块后计算能力不会受到影响的用户将成为Lt记账者的候选人.如果用户u是候选人,那么用户u将发送一份选举宣言.Lt会将用户u的uid与交易中记录的uid进行比较,并在收到用户u的宣言后计算其uid出现的次数.其他候选者将关注计数最高的用户u′,并根据恶意用户检测方法检查该用户u′是否为真正的朋友.如果一半以上的用户接受用户u′,则u′将控制Lt并生成块b.

算法2 共识协议算法输入:时间戳、uid、Lt输出:b1:c = 0 , cnt[uid] = 02:for j = 1 ; j≤ len(uid) ; j++ do3: while i ≤ len(Lt) do4: ifLt.uid[i] == ujid then5: cnt[ j]++6:FC ← uargmaxjcnt[j]id9:for k = 1 ; k ≤ j; k++ do10:uk.fol(FC)11: f =uk.chk(FC)13: if f == true then14: c++15:ifc/j > 0.5 then16: b = geneBlock (FC)19:else20:uk.del(FC)
由于每个数据包都包含其所有者的ID,因此数据包的所有者可以直接访问该数据包,而其他用户则需要获得授权后才可以访问数据.所有者授予访问者访问权限,本模型可以帮助所有者检查其身份.
假设数据包所有者A决定授予访问者B访问权限,本模型将检查访问者B拥有的块数.如果B拥有大量区块,可以知道B不是攻击者,因此敏感数据对B是可见的.相反,如果B没有足够的块,本模型会让A重新确认其操作,随后B可以获取A的所有敏感数据.
除此以外,如果访问者B想要访问A的敏感信息,本模型将首先检查B的身份.如果B没有同步所有数据或没有大量区块,那么可以认为B的目标是分析A的行为.因此,本模型将拒绝B的访问请求.本模型然后将评估B的安全性和声誉.基于这两个指标,本模型将决定是否让B访问A的数据.如果B试图访问A的动态个人信息,B的声誉就会降低.如果用户C从B获取A的数据,那么B的安全性将大大降低.如果B的安全性或声誉低于阈值,则B的请求将被拒绝.
使用了顺序的时间戳,即块N的时间戳必须早于块N + 1的时间戳.因此,当攻击者想要伪造区块,它必须修改大量的区块,而这在实践中是不可能的.
3 随机同态加密模型
由于区块链网络中的每个节点都可以查看系统的总账本,因此区块链无法确保用户的隐私.如果攻击者入侵了区块链用户的设备,则所有帐本都将可见.为了在基于区块链的框架中保护隐私,应该对用户行为进行加密.如果用户Alice向用户Bob发送消息m,则用户交互的过程如下:Alice使用签名算法对内容进行签名;Alice将密文c发送给Bob;Bob收到c并用他的私钥解密,得到消息m.

(2)
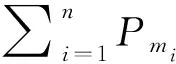
4 实验评估
使用了社交网络的用户行为数据来评估本模型的性能.表1展示了模型在不同加密方式下的数据查询性能.使用y2=x3+ax+b(a和b是两个128位的数字)作为椭圆曲线.由表可知,在搜索查询方面,提出的模型性能均优于其他方法.RSA加密和全同态加密在数据量非常大的情况下会消耗大量的时间.
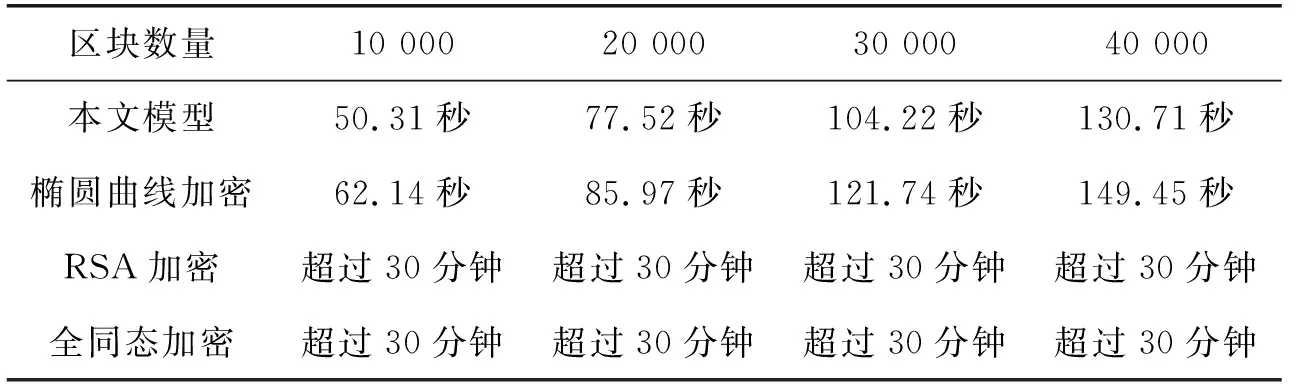
表1 数据搜索时间对比
图1展示了存储相同数据量时不同模型的硬盘空间占用情况,由该结果可知,本模型可节省大量的存储空间.
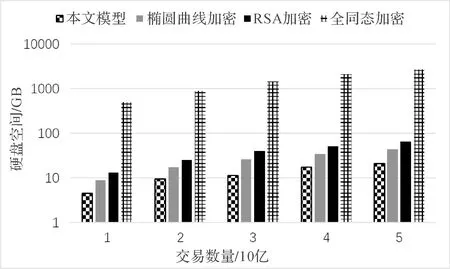
图1 硬盘空间占用
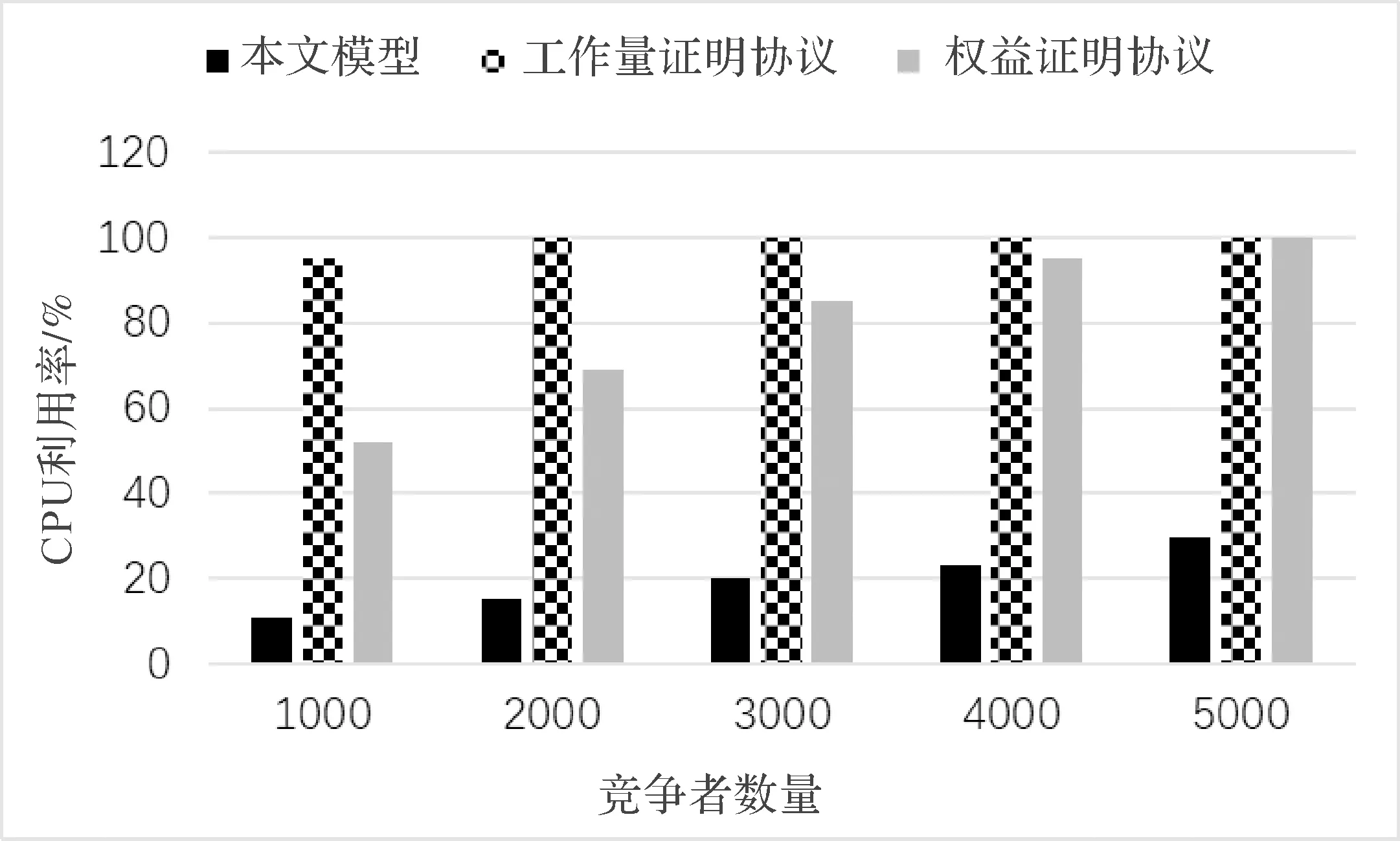
图2 CPU利用率
评估了不同共识协议在不同区块竞争者数量下的CPU利用率,结果如图2所示.提出共识协议能够占用最少的CPU资源,具有最佳的性能.
5 结语
本文提出了基于区块链的数据库隐私保护模型,以确保大数据环境中分布式存储的隐私信息不被泄露.所提出的数据管理策略根据用户设备的性能为用户同步部分数据库数据,以确保设备性能不被影响.提出的共识协议能够快速地验证交易,更适用于大数据环境.实验结果表明,本模型能够有效降低同步数据对用户设备的性能影响,减少了数据库搜索的时间.
