基于回译和比例抽取孪生网络筛选的汉越平行语料扩充方法*
2022-10-28王可超郭军军张亚飞高盛祥余正涛
王可超,郭军军,2,张亚飞,2,高盛祥,2,余正涛,2
(1.昆明理工大学信息工程与自动化学院,云南 昆明 650500;2.昆明理工大学云南省人工智能重点实验室,云南 昆明 650500)
1 引言
神经机器翻译NMT(Neural Machine Translation)[1,2]是自然语言处理领域的研究热点。相较于已经取得极大进步的资源丰富型神经机器翻译,低资源神经机器翻译由于缺少高质量的双语语料,效果并不理想。因此,如何高效地扩充语料规模,成为低资源神经机器翻译研究中亟需解决的问题。针对此问题,研究人员提出了多种数据增强方法,通过有限的语料资源扩充双语语料规模。早期的工作主要利用人工的方式进行语料扩充,但效率较低。近年来,随着深度学习技术的发展,利用深度学习方法来扩充双语语料成为有效途径。基于深度学习的数据增强方法主要分为生成式和抽取式。生成式数据增强方法包括:回译(back-translation),将目标端的单语语料通过反向翻译模型扩充为伪平行双语语料;词或单元的替换,通过各种手段替换句子中部分单元(词或短语)来扩充语料;加入枢轴语言,充分利用源-枢轴-目标语言间丰富的对齐语料来提升源-目标语言对的机器翻译性能。抽取式数据增强方法主要通过计算跨语言语义相似度,从可比语料(篇章对齐)中抽出伪平行语料。通过这几种方法,可以大规模扩充双语语料库的规模。
汉语-越南语作为典型的低资源语言对,其平行语料获取难度很大。传统的回译方法中,首先基于小规模平行语料训练基础翻译模型,在此基础上将越南语翻译为对应的汉语句子、组合成新语料再次投入训练。但是,由于用于训练基础翻译模型的平行语料规模和质量欠佳,造成基础翻译模型训练并不充分,若只是直接在该模型上通过回译方法进行语料扩充,得到的伪平行语料会含有过多的噪声,如表1所示。

Table 1 Comparison between back-translation generated translation and standard translation
表1中通过回译得到的汉语译文偏离了原句的意思,且有明显的语义逻辑错误,若要构建用于训练机器翻译模型的双语语料库,必须要过滤掉这种句对。本文将回译和伪平行句对抽取的方法相结合,通过计算跨语言句对间的语义相似度,对生成的语料进行筛选,以获得高质量双语语料。具体来说,本文首先利用回译的方法,将大规模的单语语料扩充为伪平行语料;然后结合回译数据的特点,对传统基于双向长短时记忆Bi-LSTM(Bidirectional Long Short-Term Memory)孪生网络的句对抽取模型进行了改进,改进后的模型将平行语料和伪平行语料混合后对模型进行训练,使模型能更好地分辨平行句与伪平行句,从而抽取出质量更高的伪平行句,以构建用于汉越神经机器翻译的语料库。
2 相关工作
神经机器翻译是目前机器翻译领域内最热门的研究方法,在资源充足的语言对翻译上,神经机器翻译的性能已经明显超过了统计机器翻译[3],但在低资源神经机器翻译上,神经机器翻译的效果还有待提升[4]。用来训练低资源神经机器翻译模型的平行语料相对较少,导致翻译效果欠佳,因此如何获取高质量的双语语料,成为提高低资源神经机器翻译的一种关键性技术。近年来,国内外相关研究人员针对低资源语种的伪平行语料扩充方法进行了广泛研究,并取得了一系列成果。
目前应用最广泛的语料扩充方法是回译。它利用反向的翻译模型,将目标端语言的数据翻译成源端语言的数据,通过这一方法来构造伪平行双语数据来训练正向翻译模型。回译最早是由Sennrich[5]等提出的,文中提出了2种方式来比较回译的性能。第1种方法在只有目标语言句子y的前提下,将源语言对应的句子设置为空,将句对(dummy,y)将其加入到平行语料中进行训练,可以看成是翻译模型和语言模型多任务训练;第2种方式为回译,用训练好的目标语言到源语言的翻译模型翻译目标语言句子y,得到伪平行句对(x′,y),将其加入到平行句对中一起训练。因为y是高质量的单语语句,而x′中可能包含一些〈UNK〉字符或者错误的句法等,其质量较差。这样训练可以想象成去噪声形式的训练。在有噪声的情况下,训练x(源语言)→y(目标语言)方向的翻译模型尽量还能翻译好,以此提升泛化性能。回译已经有了越来越多的扩展方法。He等[6]提出了对偶学习的方法,将回译扩展为在2个翻译方向上训练NMT系统,利用源语言与目标语言的单语数据来同时提升2个方向的翻译模型;Hoang等[7]提出了迭代回译的思想,通过使用回译的数据构建更好的翻译模型,再使用这个更好的翻译模型对数据进行回译,重复此过程以达到迭代的效果。数据增强的方法还有词或单元的替换。比如2017年Fadaee等[8]提出了一种增强语料的方法,首先在规模较大的单语语料上训练出语言模型,然后用语言模型找到句子中可以被低频词替换的高频词的位置并完成替换。通过这种单词替换,增加了训练语料中低频词出现的次数,从而增强神经机器翻译对低频词的理解能力。而蔡子龙等[9]将句子中最相似的单元进行位置上的对调,以此形成新的语料,改变的是语料中句子的结构信息而非语料中的词频信息。此外,Wei等[10]提出了随机替换、随机插入、随机交换和随机删除的方法,为低资源神经机器翻译的数据增强技术开拓了新的思路,也提升了低资源NMT的性能。还有一种增强方法是加入枢轴语言。此类方法通过引入大语种丰富的对齐语料作为枢轴语言来充分提升小语种神经机器翻译的性能。Ren等[11]提出,在大语种之间的翻译过程中将小语种作为中间隐变量引入,将该翻译过程拆分为两个经由小语种的翻译过程,如X、Y为两个大语种,它们之间有大量双语数据,Z作为小语种,它和X、Y之间均只有少量双语数据,为了提升X→Z和Y→Z的翻译性能,可以用此方法来进行优化。
在抽取式语料扩充方法的研究中,Cristina等[12]研究了从NMT系统编码器获得的句子表示中检测新的平行句对,通过比较余弦相似度来进行平行句和非平行句的区分。Grover等[13]提出了一种利用连续向量表示的方法,在使用Luong等[14]提出的双语词嵌入模型学习单词表示后,再使用相似矩阵上的卷积神经网络对一对句子是否对齐进行分类。而Grégoire等[15]使用单一端到端模型估计可比语料中2个句子平行的条件概率分布,取得了更好的效果。
对汉越语言对来说,回译能够快速而有效地扩充汉越平行语料规模,然而,单独使用回译方法生成的伪平行语料质量较差,在实际应用中难以用于下游任务,若直接用于训练翻译模型,可能会降低翻译系统的性能[16]。针对此问题,本文结合回译和平行句对抽取方法对数据进行扩充和清洗。之前工作中,由于大多数句对抽取方法是针对可比语料特点进行训练的,所以本文在此基础上结合回译数据的特点对句对抽取方法进行了改进,使其可以对伪平行语料进行更有效的筛选。本文方法将伪平行语料与平行语料进行混合,用于训练句对抽取模型,以提升模型抽取出的平行句对的比例,使其能够分辨出平行句对与伪平行句对,进而从回译生成的伪平行语料中筛选出高质量的伪平行句对。
3 基于回译和比例抽取孪生网络筛选的伪平行句对抽取方法
3.1 整体框架
本文方法首先利用回译的基本思想,将大规模的越南语单语数据利用基础翻译模型翻译得到汉越伪平行双语数据。但是,由于汉越平行语料规模有限,训练得到的基础翻译模型(翻译方向:越→汉)性能一般,进而导致扩充的伪平行语料中部分句对质量不佳,无法更有效地推进后续工作。本文通过混合小规模平行语料和回译生成的大规模伪平行语料,训练一个基于比例抽取的Bi-LSTM孪生网络,使得该网络可以识别出混合语料中的平行句对。该句对抽取模型通过孪生网络将汉越句对映射到同一语义空间下,计算句对之间的语义相似度,并按相似度得分从高到低排列句对,取出相似度高于设定阈值的句对。在训练过程中,将平行句对和伪平行句对混合,并加标签区分,通过最大化抽取出的平行句对与抽取前平行句对的比值来训练模型,使得模型经过训练后,可以精确地识别原始平行句对。具体而言,抽取的句对结果中,平行句对优先排序,紧接其后的为最接近平行句对的伪平行句对,最后为质量较差的伪平行句对。因此模型在具有识别原始平行句对能力的同时,也能从混合语料中抽取出高质量的伪平行句对,以达到对伪平行数据进行筛选的目的。整体的框架如图1所示。其中,D′1指抽取出的原始平行句对,count(D′1)表示抽取出的原始行句对的数量;count(D1)表示总的原始平行句对的数量。
3.2 基于回译的伪平行句对生成
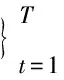
3.3 基于比例抽取的Bi-LSTM孪生网络平行句对抽取方法
基于回译的方法将大规模的目标端单语数据扩充为伪平行数据后,还需要进行数据筛选的工作。本文使用一个基于比例抽取的Bi-LSTM孪生网络来实现数据筛选任务。
Bi-LSTM通过学习句对之间的跨语言语义来估计它们互为翻译的可能性。该句子抽取模型使用共享权值的孪生网络[17],利用双向LSTM[18,19]句子编码器将句子在共享向量空间中进行连续的向量表示,然后源句和目标句的表示被输入到一个带Sigmoid输出层的前馈神经网络中,计算它们为平行句对的条件概率,将相似度高于设定阈值的句对抽取出来。
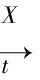
3.3.1 语句编码

(1)
(2)
(3)
(4)
3.3.2 句对信息匹配
对源语句和目标语句进行编码之后,通过使用它们的元素乘积和元素差异的绝对值来量化源语句和目标语句之间的匹配信息,得到匹配向量,如式(5)和式(6)所示:
(5)
(6)
通过将匹配向量馈送到具有Sigmoid输出层的前馈神经网络来估计句子平行的条件概率,如式(7)和式(8)所示:
(7)
p(yi=1|hi)=σ(vhi+b)
(8)
其中,σ(·)是Sigmoid函数,W(1)∈Rdf×dh,W(2)∈Rdf×dh,v∈Rdf,b1∈Rdf,b是模型参数,p(yi=1)表示第i个句对平行的概率,df是前馈神经网络隐藏层的大小。通过最小化句对的交叉熵损失来训练模型,如式(9)所示:
(1-yi)log(1-σ(vhi+b)))
(9)
如果句对的概率大于或等于决策阈值ρ,则将其分类为平行,否则为不平行,如式(10)所示:
(10)
其中n和m分别表示源泉语句和目标语句的个数。
将句子平行的条件概率作为句对之间的相似度,然后对该相似度进行从高到低排列,抽取出大于设定阈值的句对,用于训练一个能抽取出较高质量伪平行句对的句对抽取模型。
3.3.3 基于比例的损失函数改进
传统基于Bi-LSTM孪生网络筛选伪平行句对的方法是在可比语料上实现的,而本文是对回译生成的大规模伪平行语料进行筛选,所以本文方法在结合回译语料的基础上,对传统基于Bi-LSTM孪生网络方法做了一定的改进。
在模型训练阶段,本文方法不再用平行语料和随机生成负例来训练模型,而是将平行句对与伪平行句对按比例混合来训练模型,目的是使模型更好地识别出原始平行句对,在抽取过程中尽可能多地将原始平行句对抽取出来,如式(11)所示:
(11)
通过最大化count(D′1)和count(D1)的比例,使得训练后的模型可以从混合语料中精准地识别并抽取出原始平行句对。
为了使平行句对抽取比例对模型产生积极的影响,本文定义了另外一个损失函数,如式(12)所示:
(12)
最终的损失函数由L1和L2共同决定,如式(13)所示:
L=λL1+(1-λ)L2
(13)
其中,λ是超参数,通过人工设定,用于调节L1和L2的权重。
3.3.4 语料设置
将混合语料输入到基于比例抽取的Bi-LSTM句对抽取模型中,训练句对抽取模型,使模型能精准地分辨出平行句对和伪平行句对。
4 实验与分析
4.1 实验模型设置
翻译模型:为了验证本文方法的有效性,首先基于Transformer翻译模型进行了在汉-越任务上的训练,作为baseline翻译模型。在语料方面,通过网络爬虫工具爬取汉越双语语料,并经过初步的筛选,删掉标点符号过多或无效字符的句子,并删掉越南语中短于5个词和长于50个词的句子及其对应的汉语句子(因为句对过短或过长对于模型训练的收益不大);然后使用jieba分词工具对汉语句子进行分词,经过人工的精准校对和筛选,得到了200 000平行句对。从中分别随机抽取出2 000个句对作为baseline的验证集和测试集,剩余的作为训练集,初始的实验数据具体如表3所示。

Table 2 Representation of sentence pairs after being labeled and mixed
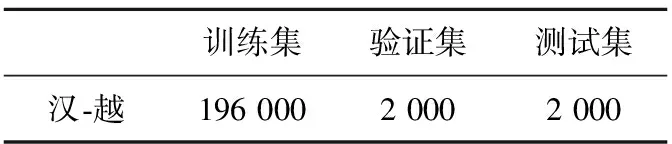
Table 3 Experimental data of baseline model
本文使用清华大学的开源Transformer翻译模型THUMT,在参数设置上,将batch size设置为512,train step设置为50 000,汉语词表大小为41 000,越南语词表大小为32 000,训练过程中每2个周期更新一次模型的参数,每训练2 000步,对模型进行一次评估,最后保存评估得分最高的3个中间模型,使用BLEU(本文统一使用BLEU4)作为评测指标。在汉→越和越→汉的2个翻译方向上分别对模型进行了训练,实验结果如表4所示。

Table 4 Experimental results of the baseline model
通过网络爬取大规模的越南语单语数据,并像之前设置一样删掉过短或过长的句子,选取其中的600 000单语句子。将训练的越→汉的基础翻译模型用于回译,将目标端越南语单语句子回译生成源端汉语句子,最终构成规模为600 000的伪平行语料库。
句对抽取模型:对之前初步校对过的200 000平行句对进行人工筛选,选出其中质量较高的50 000,从伪平行数据中选取200 000,将2部分混合作为句对抽取模型的训练集。从平行数据的剩余部分中分别抽取1 000个句对作为验证集和测试集。该实验数据中,汉语词表大小为50 000,越南语词表大小为35 000。
为了评估所训练模型的性能,本文使用精度P(Precision)、R召回率(Recall)和F1值作为评价指标。精度是指所有抽取出的句对中真实平行句对的比例,召回率是指被抽取出的真实平行句对占测试集中所有平行句对的比例,而F1值是精度和召回率的调和平均值。
Bi-LSTM中词嵌入层的维度设为512,前馈神经网络中的隐藏层有256个隐藏单元,训练过程中的学习率设置为0.000 2,训练5个epoch,train step为36 000,抽取的阈值设为0.98,λ设为0.7。模型的训练结果如表5所示。

Table 5 Training results of the proposed model
4.2 实验结果分析
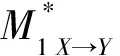
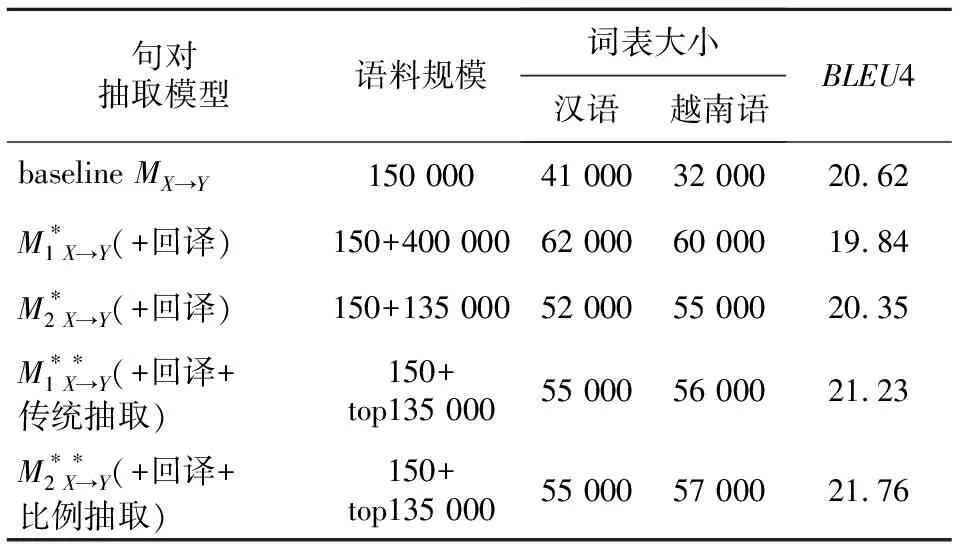
Table 6 Experimental results of different methods on different datasets
通过上述实验发现,仅通过将伪平行语料与平行语料混合来直接训练翻译模型,不但没有提高模型的性能,反而会降低BLEU4值。这是由于用来训练回译基础模型MY→X的汉越平行语料规模不足,导致用基于伪平行语料来直接训练正向的汉越翻译模型MX→Y时反而会引入更多的噪声,从而降低翻译模型的BLEU4值得分。通过基于传统的Bi-LSTM孪生网络方法对伪平行句对进行抽取后,可以有效筛选掉平行程度较低或含有过多噪声的句对,对比传统的抽取方法,本文提出的基于比例抽取的方法对翻译模型性能有更明显的提升,BLEU4值增加了1.14。
4.3 验证实验
本节对基于比例抽取Bi-LSTM孪生网络方法有效性进行验证。实验中的平行语料为人工校对过的高度平行的50 000汉越平行语料,将回译生成的400 000伪平行语料与这部分平行语料混合,并用标签区分它们,在平行句对后加标签“1”,伪平行句对后加标签“0”。通过加标签区分混合语料中的平行和伪平行句对,可以直观地看到模型抽取出的平行句对数和伪平行句对数。将这个混合的语料库作为句对抽取模型的输入语料,通过改变模型抽取句对时的阈值,可以得到不同规模的伪平行语料。具体的实验结果如图2所示。
由图2可知,当阈值设为0.95时,抽取出的混合语料的数量骤减到原来的一半,这说明伪平行语料中有大量含噪声的句对。当逐步提升阈值时,被抽取出的句对数量也随之减少,平行句对所占的比例也就越来越高,这也验证了本文模型的有效性。
为了继续验证抽取出的句对对神经机器翻译的影响,用上述通过不同阈值抽取出的句对分别对翻译模型进行训练,实验结果如图3所示。
通过对比不同阈值下抽取伪平行句对的结果可知,当句对抽取模型抽取出的原始平行数据占比越高时,构成的混合语料库的质量越高,对神经机器翻译模型的提升越大。在阈值设置为0.999时,平行句对占比约为20%,此时得到的BLEU4值最大为21.76,相比只用平行语料训练的baseline提高了1.14。
此外,为了探究训练数据是否加标签对本文方法的影响,分别用加标签和不加标签的训练语料进行了一组对比实验,实验结果如表7所示。

Table 7 Verification of label validity
实验表明,训练数据中加入标签的方法有效地提升了句对提取模型的准确率,并且抽取出的语料对翻译模型的性能也有进一步的提升。
4.4 译文对比分析
为验证用基于回译和比例抽取孪生网络筛选方法构建语料库对神经机器翻译性能的影响,本文还用不同语料库训练的模型分别翻译同一语句进行对比分析,翻译结果如表8所示。
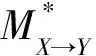
5 结束语
针对汉越神经机器翻译模型训练中平行语料不足的问题,本文提出了一种对语料进行扩充的方法。首先通过回译的方法,将越南语单语数据扩充为伪平行句对,利用基于比例抽取的Bi-LSTM孪生网络删除含有过多噪声的句对,同时抽取出相似度高的句对,用于构建汉越双语语料库。在句对抽取过程中,通过将平行句对混入伪平行句对中来指导抽取的过程。实验表明,基于此方法构建的语料库可以有效地提升汉越神经机器翻译的性能。在未来的工作中,我们会对翻译模型做更多的探索,以消除回译过程中产生的噪声,从而进一步提高汉越神经机器翻译的性能。

Table 8 Comparison of translations results generated by different models
