NIR-BP联合定量模型快速分析长春西汀注射液的含量
2022-10-27张秉华王小亮
张秉华,王小亮
陕西省食品药品检验研究院,西安 710065
长春西汀是长春花碱的半合成衍生物,于20世纪70年代由匈牙利Gedeon Richter公司研制,具有增加脑血流量、促进头部葡萄糖和氧的摄取利用、减轻脑缺氧损伤、清除动脉粥样硬化斑块等药理作用,以其显著的治疗效果和极低的毒副作用在临床上广泛应用,成为治疗心脑血管疾病的一线用药,在我国的使用量逐年增加[1-4]。
目前,对长春西汀的检验和质量控制方法主要包括用高效液相色谱法测定长春西汀注射液、长春西汀片中长春西汀的含量以及用气相色谱-质谱法测定长春西汀注射液中的长春西汀含量等,而对长春西汀近红外建模和快速检验方法的研究还未见相关报道[5-8]。
本文将近红外光谱快速检测方法和BP(Back Propagation)神经网络智能算法相结合,进行了长春西汀注射液的NIR-BP联合定量建模方法研究,实现了对长春西汀注射液含量的定量快速检验。
1 仪器与试药
1.1 仪器
Matrix-F近红外光谱仪(德国Bruker公司),配有1.5 m长固体光纤探头测样附件,铟镓砷(InGaAs)检测器,OPUS5.5光谱分析软件(德国Bruker公司);MathWorks公司的MATLAB R2010商用数学软件;高效液相色谱仪(美国Waters公司),配有DAD检测器;BP211D电子分析天平(德国赛多利斯公司)。
1.2 试药
2020年国家评价性抽检长春西汀注射液样品,包含8个厂家的78批样品。
2 方法
2.1 含量测定
按照国家新药转正标准56册“WS1-(X-177)2004Z”用高效液相色谱法测定长春西汀注射液的含量。所有样本的含量分布和频数见图1,其中大部分样品的含量分布在4.88~6.04 mg·mL-1范围内。

注:A.含量分布;B.含量频数。
2.2 近红外光谱测定
定量模型建模时建模集、校正集和预测集的划分见表1,建模集、校正集和预测集的样本数量分别为56、10、12,为避免连续样本建模可能引入的系统误差,建模时采用随机取样方法。样本前2个主成分分布见图2,由图2可知,建模集、校正集和预测集分布均匀,随机取样结果合理有效。

表1 定量模型建模样本划分

图2 样本的前两个主成分得分分布
近红外光谱测定方法:用液体附件间接测量法,以固体光纤探头配合液体附件直接测量采集样品NIR图谱。光谱扫描范围为12 000~4 000 cm-1,分辨率8 cm-1,扫描次数64次,每批样品测定3次,取其平均值。最终获得的样本光谱见图3。
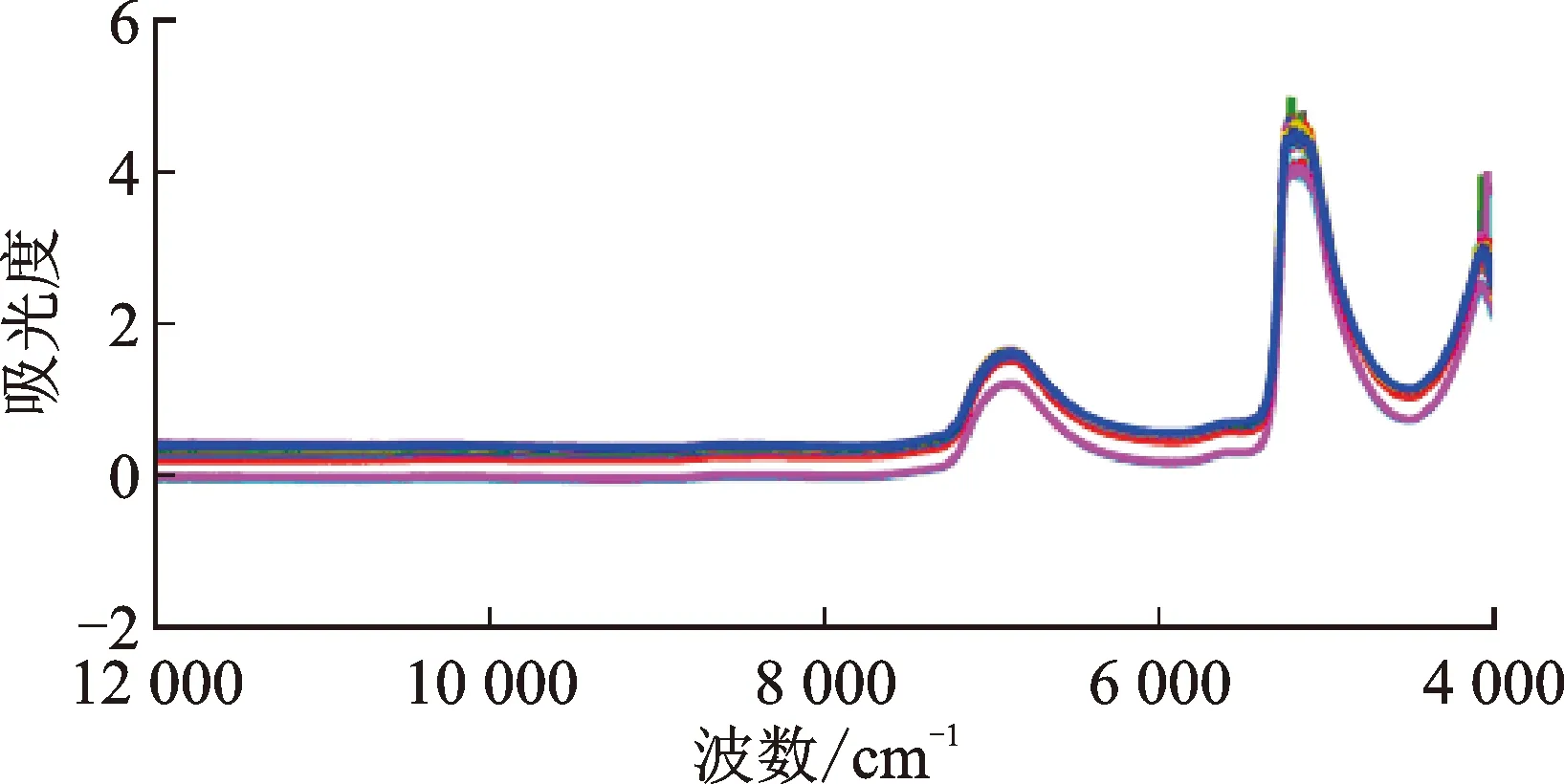
图3 经平均后的近红外建模光谱
2.3 定量模型的精度评价
建模集用于定量模型的建立,校正集参与优化模型,提高模型的泛化能力,而预测集用于对模型的预测精度检验。定量模型的精度通常用相关系数R、交叉验证均方根误差RMSECV、预测均方根误差REMSEP等指标来衡量[9-10]。R用于考察样本预测值与真实值之间的相关程度,R约接近1,说明预测值和真实值之间的相关程度越高;RMSECV用于评价所建立模型的预测能力,通过交叉验证来实现;RMSEP用于评价所建立模型对外部独立样本的预测能力,RMSEP越小,说明模型对外部独立样本的预测能力越高。R、REMSECV和RMSEP的具体表示如下:
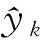

2.4 光谱分析与预处理
受测试样品状态、测试设备误差、高频随机误差、光散射及杂光等外部因素的影响,近红外光谱中除了待测样品的真实响应信息外,还包含其他干扰背景信息。通过预处理可以有效地改进光谱质量,提高后续建模的准确性。常用的光谱数据预处理方法包括均值中心化MC、Min Max归一化、一阶求导、标准正态变换SNV、SG平滑、多元散射校正MSC等[11-12],经过不同预处理方法处理后的样本光谱见图4。

注:A.均值中心化MC;B.MinMax归一化;C.一阶求导;D.标准正态变换SNV;E.SG平滑;F.多元散射校正MSC。
2.5 BP人工神经网络
BP(Back-Propagation)神经网络是一种按误差逆传播算法训练的前馈多层网络,网络包含输入层、隐含层和输出层,每层网络均由多个并行计算的神经元组成,网络层与层之间通过神经元连接,而同一层网络的神经元相互独立[13-14]。典型多输入单输出BP神经网络结构图见图5,xj表示输入层第j个节点的输入,wij表示隐含层第i个节点到输入层第j个节点的权值,θi表示隐含层第i个节点的阈值,Φ表示隐含层的激励函数,wki表示输出层第k个节点到隐含层第i个节点的权值,ak表示输出层第k个节点的阈值,ψ表示输出层的激励函数,yk表示输出层第k个节点的输出。
BP神经网络具有极强的非线性映射能力,在函数逼近、模式识别、分类和数据压缩等领域都有广泛的应用[15-19]。理论上,只要隐含层神经元的数量足够多,BP神经网络能够以任意精度对任意非线性映射进行逼近,契合了近红外光谱定量模型对预测精度的需求。

图5 典型多输入单输出BP神经网络结构图
3 结果与讨论
3.1 光谱预处理方法的选择
由于不同的预处理方法对光谱信息的改善侧重点不同,如导数预处理侧重于消除原始光谱的基线漂移及背景因素干扰,而标准正态变换主要用来消除样品固体颗粒的大小、光程变化及表面散射对样品漫反射光谱的影响[20-21]。因此,无法直接对上述6种预处理方法进行优劣判定,但可结合后续建模过程,从主成分分析信息解释程度和定量建模精度两方面出发选择最优的光谱预处理方法。
不同预处理方法对应的主成分累计贡献率见图6,除一阶求导预处理方法外,其余5种预处理方法在前30阶主成分的累计贡献率均超过了99%,说明其他5种预处理方法均能很好地保留样本的有效光谱信息,可作为建模备选预处理方法。

图6 不同预处理方法对应的主成分累计贡献率
建立6种预处理方法的BP神经网络定量预测模型,对模型的预测精度进行对比,见表2。用原始光谱、均值中心化MC、MinMax归一化、一阶求导和SG平滑预处理光谱进行建模时,所有样本预测值与真实值的相关系数R均未超过0.900。标准正态变换SNV预处理方法所建立模型的交叉验证均方根误差最小,但对预测集的预测误差较大,导致其整体相关系数R并非最优。多元散射校正MSC预处理方法对应的模型预测值与真实值的相关系数R为0.972,为6种预处理方法中的最优值,因此,后续建模中采用多元散射校正MSC方法对光谱进行预处理。
3.2 建模光谱段的选择
通过对建模光谱段的筛选,不仅可以有效降低模型的复杂程度,还可以剔除大量不相关的冗余信息,建立预测能力更强、稳健性更好的预测模型[22-23]。通过对样本光谱的分析可知,光谱在8 000~12 000 cm-1谱段内的吸光度很小,很容易受到噪声信号的干扰,因此建模时首先剔除该谱段的光谱数据。而在4 000 cm-1附近容易受到边缘效应的影响,因此对4 000~4 500 cm-1谱段也不予考虑。从剩余的4 500~8 000 cm-1谱段中选取不同的谱段区间进行建模预测,结果见表3,选取建模谱段为6 000~8 000 cm-1时,可获得最准确的模型预测结果。

表2 不同预处理方法的主成分累计贡献率和模型预测精度

表3 不同建模谱段对应的模型预测精度
3.3 神经网络参数的选择
BP神经网络的设计一般从网络的层数、每层中神经元的数量、激励函数、初始值以及学习速率等方面考虑[24-25]。对于一般应用,1~2层隐含层即可满足精度要求,层数太多会增加网络复杂性,影响网络收敛速度,本研究中采用1层隐含层。隐含层的神经元数量太少,网络的学习能力有限,容错性差;神经元太多,会增加网络训练时间,降低网络的泛化能力。不同隐含层神经元数量对应的模型预测精度见表4,当神经元取值为20个时,所建立的模型具有最佳预测精度。

表4 不同隐含层神经元数量对应的模型预测精度
BP神经网络中常用的激励函数包括双曲正切函数tansig、对数S型函数logsig和线性函数purelin等,隐含层和输出层分别取不同激励函数时对应的模型预测精度见表5,当隐含层激励函数为purelin,输出层预测函数为tansig时,所建立的BP神经网络模型预测精度最佳。

表5 不同激励函数对应的模型预测精度
学习速度主要用来控制网络训练过程中的权值变化幅度大小,学习速度过低会减慢网络学习速度,导致网络很难收敛;学习速度过高会使权值和误差函数产生分歧,导致网络性能指标振荡,无法达到合适的值。学习速率一般取值在0.01~0.10之间,本文中取为0.05。
3.4 定量模型的建立
根据光谱预处理、建模谱段和神经网络参数的优化结果,最终确定的NIR-BP联合定量模型建模参数选取见表6。

表6 NIR-BP联合定量模型建模参数
最终所建立的NIR-BP联合定量模型对建模集和校正集的含量预测结果及误差见图7,模型预测值和真实值很好吻合,最大绝对误差为0.40 mg·mL-1,建模集和校正集的预测均方根误差RMSE和RMSECV分别为0.11、0.16 mg·mL-1。
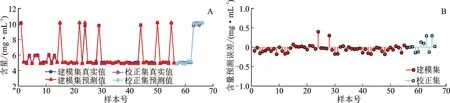
注:A.含量预测;B.预测误差。
建模集及校正集样本含量预测值与真实值的相关系数分别为0.994 7、0.997 7,说明预测值和真实值显著相关。见图8。

注:A.建模集;B.校正集。
3.5 定量模型验证
3.5.1准确性 用12组预测集样本进行定量模型的准确性验证,结果见表7。预测值与真实值的最大绝对偏差为0.27 mg·mL-1,平均绝对偏差为0.10 mg·mL-1,最大相对偏差为4.54%,平均相对偏差为1.64%,未超过近红外快速检验误差限度(5%)。同时,将定量模型预测值与标准方法检验真实值进行配对t检验,在95%的置信区间内,P值为0.914 8,小于显著性水平0.05对应的临界值2.18,说明模型预测结果与标准检验方法检测结果无显著性差异。

表7 NIR-BP定量模型预测准确性验证
图9给出了预测集样本含量预测值及与真实值的相关性,预测值和真实值的相关系数为0.997 8,预测均方根误差REMSEP为0.14 mg·mL-1,所建立的定量模型在预测集上取得了很高的预测精度。
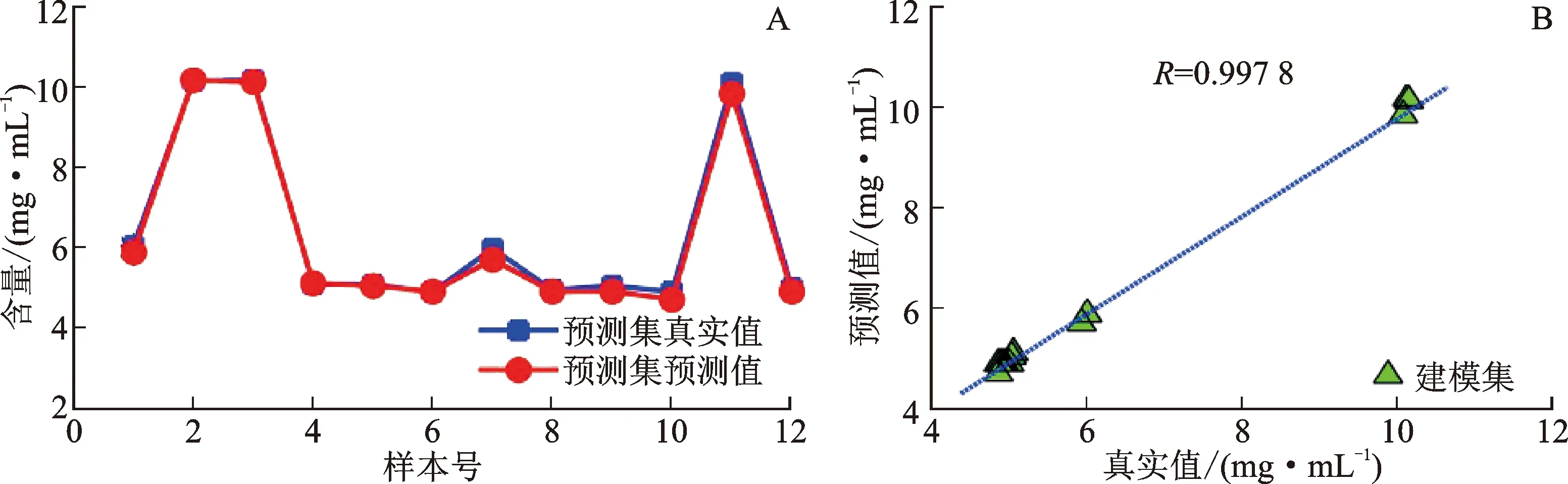
注:A.含量预测值;B.与真实值相关性。
3.5.2专属性 用欧氏距离来衡量所建立定量模型的专属性,假定样本呈随机分布,理论上99%的样品应分布在μ+3σ范围内。建模集和校正集共计66组样本光谱数据与平均光谱之间的欧氏距离平均值μ=0.167 1,标准偏差σ=0.095 8,以此确定的专属性判定阈值为0.454 6。所建立的NIR-BP联合定量模型专属性验证结果见表8,样本1~12为预测集样本,其最大欧氏距离为0.417 2,全部检验通过。样本13~16为烟酸注射液样本,其欧氏距离均远大于阈值,全部检验不通过。专属性验证样本的欧氏距离分布情况见图10,验证结果表明所建立的定量模型对长春西汀注射液具有很好的专属性。
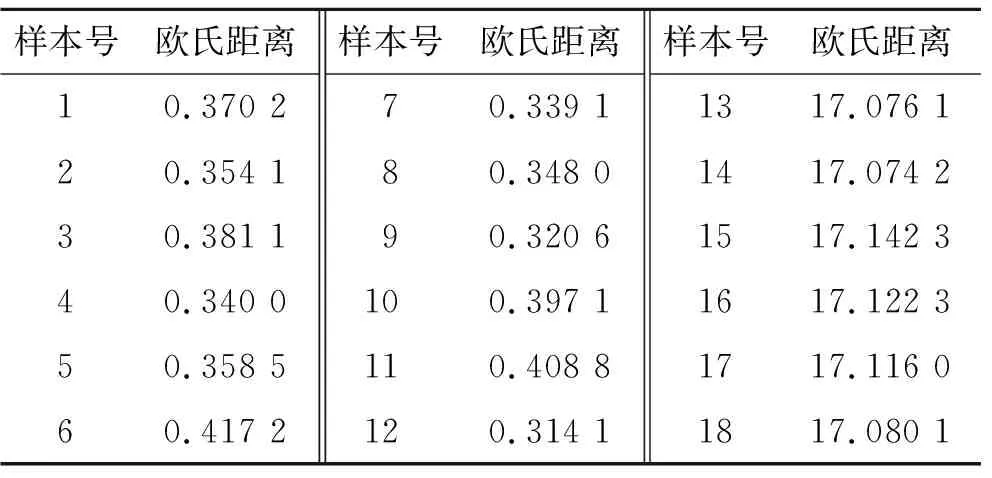
表8 NIR-BP定量模型专属性验证
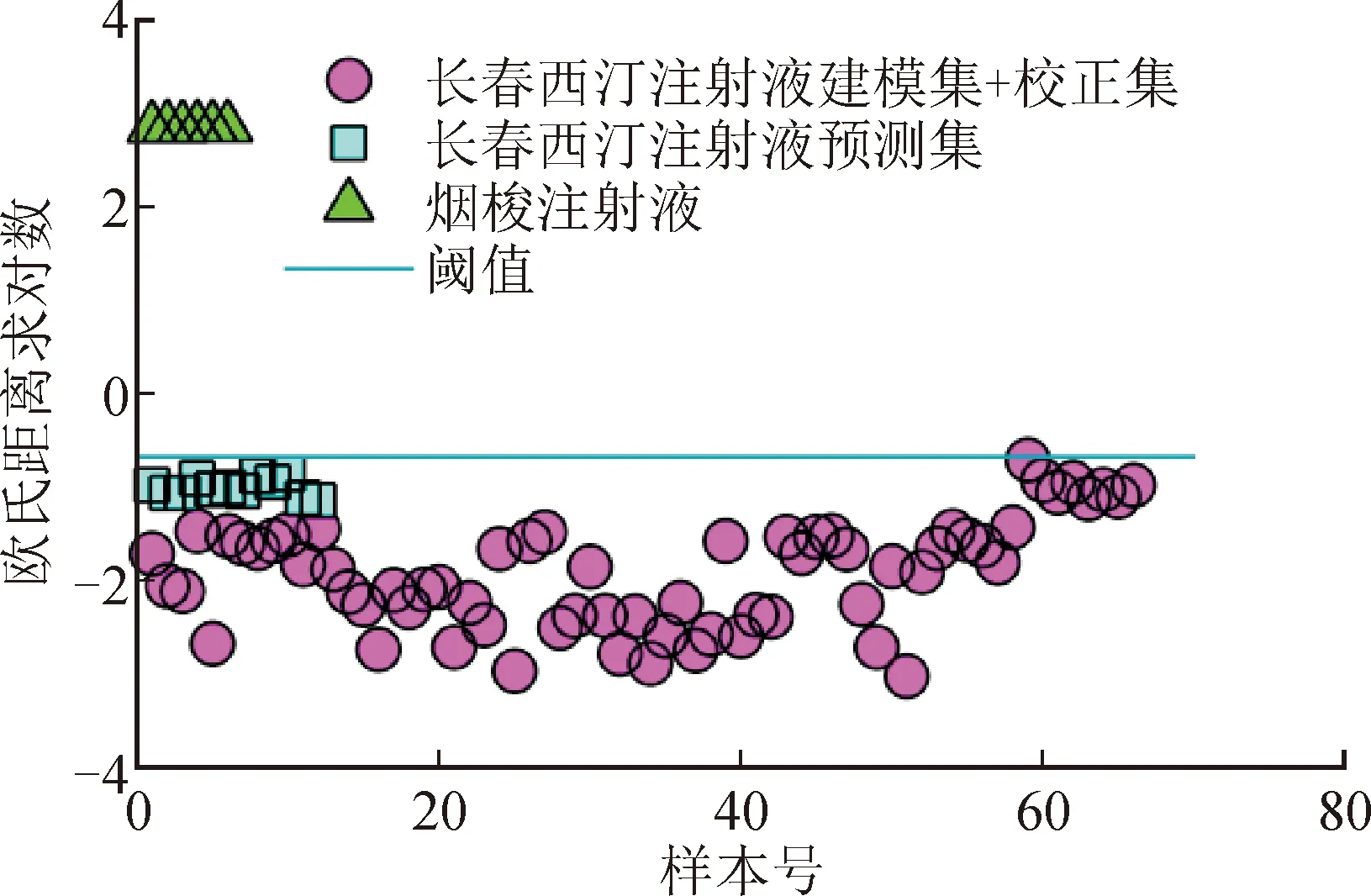
图10 专属性验证样本欧氏距离分布
4 结论
本文将近红外光谱快速检验方法和BP神经网络智能算法相结合,通过对光谱预处理方法、建模光谱段和神经网络参数的优化,最终建立了长春西汀注射液的NIR-BP联合定量模型。
模型的准确性和专属性验证结果显示,所建立的定量模型在95%的置信区间内,P值为0.914 8,与标准检验方法检测结果无显著性差异。长春西汀注射液样本的欧氏距离均小于阈值,烟酸注射液样本的欧氏距离均远大于阈值,表现出良好的专属性。所建立的定量模型均有准确、快速、便捷的特点,提供了近红外光谱建模的新方法,同时对药品的在线检验具有较高的参考价值。
