一种多策略协同的小水电并发访问控制方法
2022-10-27周彬彬马玮骏赵兴圆李胜殷峻暹陈志刚柯愈晴
周彬彬,马玮骏,赵兴圆,李胜,殷峻暹,陈志刚,柯愈晴
(1.云南电力调度控制中心,云南昆明 650011;2.南京金水尚阳信息技术有限公司,江苏南京 210046;3.深圳航天智慧城市系统技术研究院有限公司,广东深圳 518057;4.中国水利水电科学研究院,北京 100038)
0 引言
云南电网公司,由于地域和气候特点,接入和消纳2 000 余个装机容量不足25 MW 的小型发电站的电量,其中小水电站占比达80%以上,这些发电站对全省电力精细化统调统管具有重要影响。电网调度管理需要及时掌握所辖电站的发电生产情况,并对各类电站进行高效的监控和调配,确保供需平衡和电网安全稳定。然而由于数千用户同时使用系统,在规定时间范围内对各个电站实际运行数据进行统计、计划填报,在数据集中填报和计划编制协调高峰时期,大规模用户的集中操作、高并发访问使得系统响应极其缓慢,严重影响各级调度机构的工作效率。特别是众多小水电站地处偏僻,通信条件差,及时上报发电数据和获得调度指令成为瓶颈,省级电网公司能够最大程度减少各类电站实时上报数据的延时,并将调度指令及时送达电站,对于提高整个区域的发电调度效率至关重要,急需解决多用户并发访问的高效控制和数据库后台服务的动态优化问题。
在提高网络服务器的多用户并发访问效率方面,尽管已有大量研究成果,但并不都能满足具体应用场景下的特殊需求,特别是大多数解决方案都是针对一种访问方式。例如,对于系统调用方面的网络服务多用户并发设计,通常采取多线程的方式实现,但由于系统能支持的线程数量有限,当并发数超过允许的线程数量时,还是无法应对所有的服务请求。有学者提出了一种基于Linux系统epoll调用和任务队列机制的软件优化方法,能根据优先级高低,对不同等级的服务请求进行区分处理,缓解了这类服务程序调用类的多用户并发请求[1]。还有针对云平台非关系型分布式数据库的并发访问,结合特定第三方数据库管理系统(DBMS)的索引机制,如HBase,改进R 树索引,提高分布式读写索引的吞吐量[2]。本文的多用户并发访问是针对桌面Web、手机APP 和短信平台终端等多种访问方式,访问频度呈潮汐式周期变化的特点,而且主要操作是对关系型集中式数据库的读写操作,除了充分利用DBMS提供的优化工具外,还要综合运用分布式控制和负载均衡技术[3]。
本文以云南电网公司的电网调度管理系统优化改进为应用背景,深入分析业务特点,根据系统升级的约束要求,在国产达梦数据库支持的基本数据存储与访问技术框架下,采用主从式负载均衡技术,设计了业务驱动的电网数据访问控制策略,有效分离读写操作,并实现了相关控制软件。不仅彻底解决了数千计用户集中报数时的网页卡死问题,还将同时访问的响应时间从原来的最长30 s,稳定在5 s 以内,大大地改善了用户体验,提高了系统的运行效率。
1 业务特点与系统架构
1.1 云南电网调度管理系统的业务特点
云南电网业务涉及的发电厂,全口径数量为2 260 个左右。其中纳入省调电力电量平衡的电厂有438 个左右,包括10 个左右总调直调、100 个左右省调直调和328 个左右省地共调的电厂,站点的归属在不同时期会根据需要调整,水电个数占43.15%左右,装机容量占69.2%左右;其余1 830 多个地调以下的电厂属于小电,98%以上是水电。随着新能源技术的发展,风电和光电属于优先消纳的可再生能源,由于其出力的随机性和间隙性成为发电优化调度的难点和重点,作为补偿调节的发电能力也从火电逐渐向水电转移[4]。因此对各类上报数据的时效性、一致性和正确性提出了更高的要求。
云南电网已建系统数据库中累积了30多年的数据,按照静态和动态特征可以划分为两大类。静态数据主要指电站基本信息,包含电站共性基础信息(如电站名称、所属供电局、电站类型、调度关系、装机容量、并网电压等级、机组台数、经纬度等),水电站的流域及其边界信息、水库信息、大坝信息、闸门信息等。这部分数据改动频度不高,可以采用按需批量备份/更新到本地的办法解决在线访问拥塞问题。
动态数据是指电站的运行状态信息,主要包含与电站运行状态相关的数据信息,这些数据信息可划分为供给侧数据、需求侧数据、实现供需平衡的调度数据以及与电站相关联的动态数据,会根据监测和上报的时间情况定期修改旧有数据或增加新的数据。其中供给侧数据主要由与各种不同电站相关的电量信息(包含实时数据和历史数据,如发电容量、发电机台数、运行功率等)、电量计划信息(包含短期、中长期发电量预测与计划数据等)、工况信息(包含实时数据和历史数据,如运行状态、设备温度、设备湿度、电压、电流、工况告警等),工况告警信息(如告警设备编号、告警事件、告警内容、严重程度等),需求侧数据主要为用户相关的用电信息(如用电量、电费等)、用电预测信息(包含短期、中长期用电量预测数据等),关联数据主要包含与电站紧密相关的气象数据。
由此可见,对于电网调度管理系统优化改进主要方向在于动态数据的存储访问控制机制,而瓶颈又在于与小电业务相关的用户群,因为小电站地处偏僻、通信条件差(无专线),上报和查询基本依赖手机APP,集中上线时,很容易造成网页服务卡死,无法报数。为此,数据上报提供网页填报和短信上报两种方式,一旦网页填报失败,可采用短信方式补报;电网侧通过专门的短信平台接收短报文并进行解析后处理,完成二次入库操作。
每天早晨8点到9点集中上线的用户约2 500人,按数据库表记录计,上报的时段数据约144 000条,日运行数据约12 000,日计划数据约12 000 条;电厂上报和地调下发96 点发电计划4 000 条。该时段单站点数据库的读写数据量约为400 MB。
1.2 系统总体架构
对大型系统的数据访问与存储的优化需要结合系统的实际业务需求,有针对性的提出系统总体设计方案。对于投资成本有限、数据上报时效严格、安全要求高的业务系统来说,必须综合考虑性价比高的技术。为此,采取主从式数据库服务器+双Nginx(一款web 服务器)的负载均衡集群架构[5,6],以实现整个系统的高可用性目标。整个系统的总体架构如图1所示。
在内网中,整个系统架构主要通过Web 集群的方式来实现,其核心在于采用基于双Nginx 的高可用及负载均衡集群部署方式来提高系统的性能和可用性。Nginx 是一种高性能的HTTP 和反向代理web 服务器技术,借助Keepalived(Linux 下的轻量级别的高可用解决方案),实现任务分配策略[7]。图1 的Web服务器A和B中安装了Keepalived,避免由负载均衡服务器硬件故障造成的单点故障。系统的Web 应用服务同时在A、B、C 三台Web 服务器上,所有用户对系统的数据连接和访问都通过Nginx 负载均衡服务器来指派给各个Web 应用服务器,在经过了流量的合理分配消除服务器之间负载的不平衡后,系统访问请求在服务器集群之间得到了性能优化,提高了系统的反应速度以及系统的可靠性。系统工作原理如图2所示。
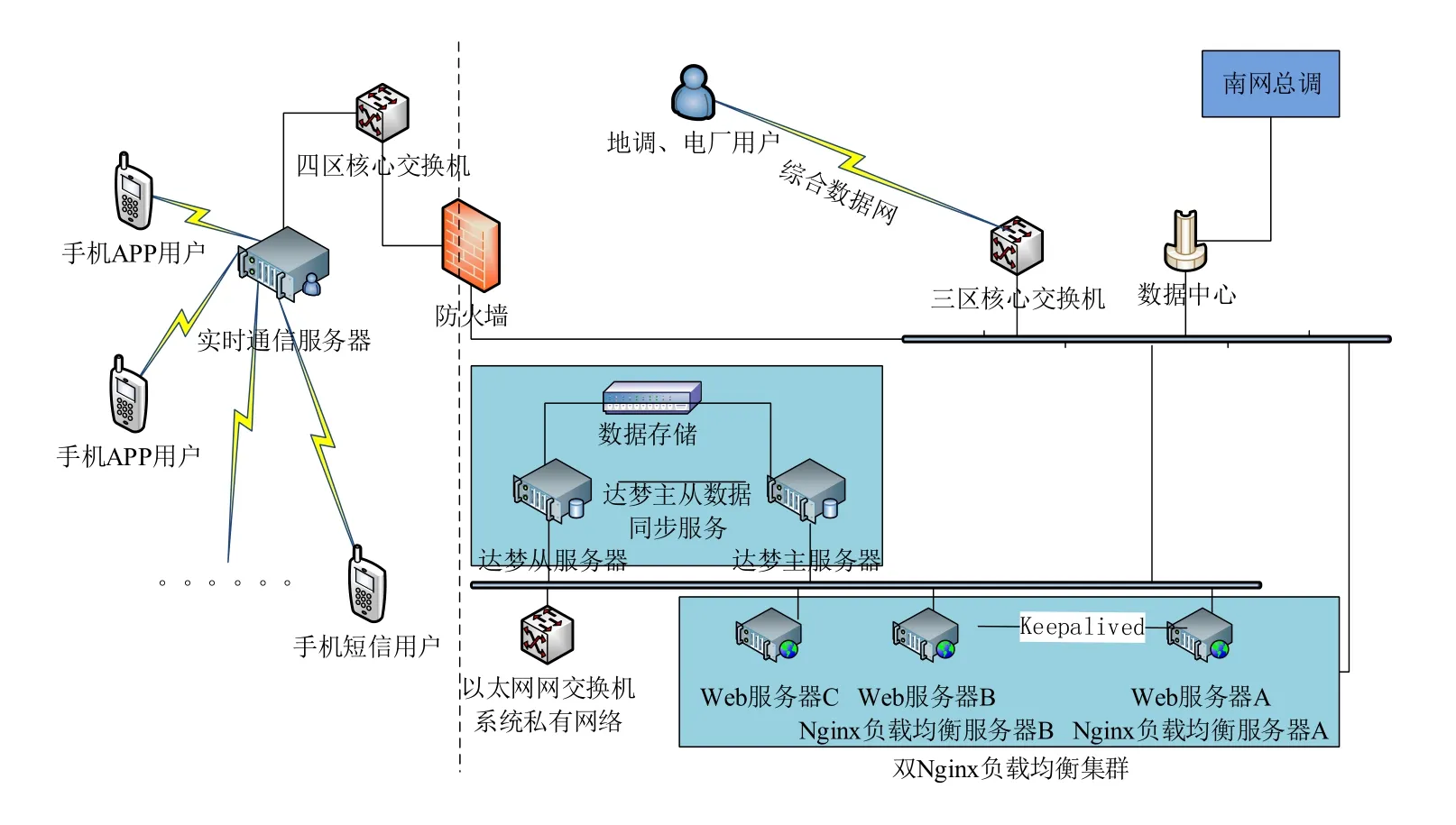
图1 主从式数据库服务器+双Nginx的负载均衡集群架构Fig.1 Load balancing cluster framework based on master-slave DB Server+double Nginx
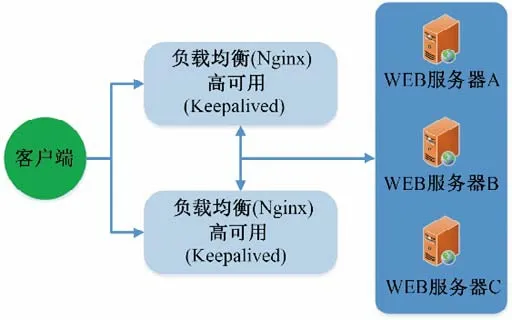
图2 系统工作原理Fig.2 System work principle
2 读写分离的数据访问实现
2.1 与数据库分级适配的读写分离策略
电力系统业务数据具有数据类型多样、结构较为复杂等特点,导致单次数据访问量差异大,如96 点发电计划一条记录包含100 多个字段,读写一次约数十MB,而日运行数据的一条记录字段数则相对较少,一次访问只有数MB。此外,业务要求每天上午8 点-9 点必须完成数据上报和发电计划下达(一般情况先上报再查询),存在多点并发存取现象,可采取将读写操作映射到不同数据库服务器上的办法分而治之。
为了进一步提高数据的更新和查询效率,采用主从数据库的方式对不同层级的数据进行存储[8-10],其中第一层级和第二层级的数据由于访问频繁,存放在主库中,并且使用外键等约束措施保证数据的逻辑关系,维护数据完整性,第三层级和第四层级的数据由于数据量大,访问频度不高,与主库数据相关性小,部署在独立的数据库服务器中,从而缓解主库的数据处理压力。具体分级如图3所示。
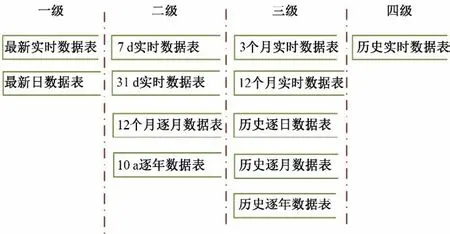
图3 系统工作原理Fig.3 System work principle
Web 程序采用Spring(一种开放源代码的J2EE 应用程序框架),在进入Web Service 之前,使用AOP(Aspect Oriented Programming:面向切面的编程)来做出判断,对数据库的访问是写库还是读库,进而可以对读/写操作进行分离,缓解数据库服务器的压力[11,12]。
使用AOP 来做出判断,依据对数据库操作的方法名判断,比如说以query、find、get等开头的读库,指示到从数据库所在的服务器上;其他的操作指示到主数据库服务器上。
利用数据库提供的主从数据库自动同步数据的服务。配置好数据同步服务后,当主数据库有数据变动时,从数据库自动同步主数据库的数据。读写分离机制如图4所示。
通常,可根据对数据库的并发访问量和系统对数据库的访问方式,设置读写全分离还是部分分离。图4 中对于不经过AOP 处理的非直接Web 访问方式,可不采用读写分离,如通过短信方式访问中心数据库的情况。
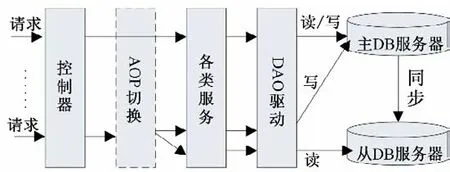
图4 读写分离机制Fig.4 Separated read and write
2.2 系统数据同步控制机制
当进行读写分离操作时,可能发生短暂的读取数据不是最新写入的情况,需要设置有效的数据同步控制机制。
首先,制定数据库设计和访问控制约束条件:
(1)数据库之间不进行实时的数据交换,只在数据量达到一定规模或者定时器超时后,进行批量、定时的数据交换。
(2)数据库之间不建立外键等完整性约束,从而减少约束检查所带来的访问开销。
(3)对非关键业务数据库的读/写操作分散到不同的节点上,从而隔离写操作对读操作的影响。
然后,采用触发器方式来实现主从数据库间的同步更新,确保不同库之间的数据一致性,其处理流程如图5所示。
在图5 所显示的处理流程中,所有表的数据都先由处理程序写入到缓存表中,随后缓存表中的触发器根据写入的数据对实时库或者历史库中相应的库表数据进行更新。对于日以上的数据,还需要同时对多个历史表进行修改。
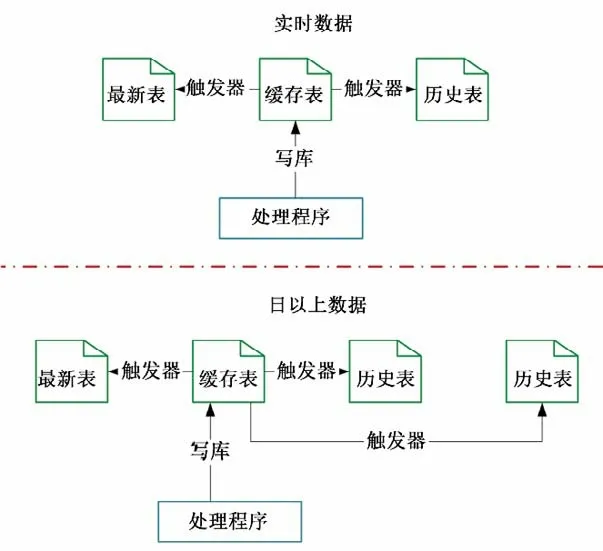
图5 基于触发器的数据同步流程Fig.5 Trigger-based data synchronization process
这种方式的优点是处理程序较为简单,具有较高的可维护性,且单表锁表的时间较短,数据库出现冲突的可能性较小,满足业务应用对数据库读写的需求。
3 改进的负载均衡任务分配算法
在一定访问权限和优先级的控制下,对于发电计划的修订和执行情况应优先保证数千个电站的数据访问延迟间隔最小。虽然将读写操作分别映射到不同数据库服务器上,但对于通过Web 服务器访问系统的应用,还需在Web 应用服务器集群首次接纳任务时,均衡负载,提高整体工作效率。
3.1 常用的负载均衡策
目前Nginx主要支持以下6种负载均衡6种策略:
(1)轮询Polling。将服务请求按照顺序轮流地分配到各个服务器上,适合用于服务器硬件条件基本相同和任务量本身较一致的情况,不能感知服务器运行状态,例如新增或者某个服务器宕机。
(2)权重方式Weight。该方法是在轮询的基础上加一个权重,权重高的服务器处理的请求就多。可以根据情况进行调整,但仍然需要进行session(计算机术语,会话控制)同步。
(3)IP 分配方式IP_hash。无需进行session 同步,固定IP 会固定访问一台服务器。提供的服务不同,面向的地区不同,IP可能会出现集中,造成不均匀,不可控,尤其在恶意攻击情况下,会造成某台服务器崩溃。
(4)响应时间方式Fair。会根据服务器处理请求的速度进行负载均衡分配,最早结束的任务,拿到下一个请求,具有一定的自适应能力,也需要进行session同步。
(5)URL 分配方式URL_hash。根据URL 进行hash,某些请求永远分配到某台Web 服务器,有利于利用服务器的缓存,但是可能由于URL 的哈希值分布不均匀,以及业务侧重造成某些服务器压力大,某些负荷低,也需要进行session同步。
(6)随机方式Random。每来一个请求,从后端服务器中随机地选择一个服务器处理请求。如果随机数是等概率生成的,运行一定时间,就跟轮询算法没什么区别了。
还有其他的一些算法,如加权轮询等,都是针对具体应用特点改进的,适用于特定环境[13-15]。我们根据电力系统数据和业务应用特点,提出了一种IP_hash与Fair相结合的负载均衡任务分配算法IPHF,根据时段内D 到达的Web 应用任务特征,在IP_hash基础上,引入任务时间阈值,作为动态调整参考量,必要时执行Fair 策略。该方法可以有效发挥IP_hash 能够根据用户区域分配服务器的优点,满足常规情况下简单易行的服务器负载均衡配置要求,又能发挥Fair 考虑服务器动态执行任务的特新,克服突发时期IP_hash 无法应对不均匀任务负载造成的临时过载问题。
3.2 IPHF负载均衡任务分配算法
本文综合IP_hash和Fair方式,设计了IPHF算法,将任务分配分为两个阶段:阶段1,IP_hash 动态服务器组分配;阶段2,Fair动态服务器组分配。
式中,ID 表示任务唯一标识,如可与站点号关联;S⊆P,表示任务的主要操作子集,P∈{W,R,B,U},W-写,R-读,B-浏览,U-其他(如计算、修改等);Tf表示任务执行所需要的大致时间,即任务时间阈值。
为了便于操作,根据图3 给出的数据层级划分和系统关于数据字典关于数据库表结构的描述,统计分析常用应用服务的所需时间,设定一个任务特征参数映射表。当有Web 应用服务请求时,先提取HTTP 协议中的相关信息,查找映射表,生成一个三元组。
在时间段D中,电网管理系统中的客户端的Web 应用服务请求遵循定义1,记为Task={task1,task2,…,taskm},其中m为Web应用服务请求的总数。第i个服务请求taski记为式(1):

定义2:在Web 服务器集合S={S1,S2,…,Sn}中,第i个服务器Si的当前任务状态记为式(2):

式中:n为Web 服务器的总数,Ni为服务器Si的当前任务总数,为服务器Si处理完当前所有任务需要的时间,即服务器剩余执行时间。
(1)IPHF阶段1:IP_hash动态服务器组分配算法设计。
用IP_hash 进行静态分配,负载均衡器按照客户端IP 地址组,分配任务到三个Web 服务器之一,使得正常情况下相同的客户端的请求发送到相同的服务器,以保证session 会话的一致性。基本配置如下:

当某个服务器出现长任务过多时,如分配到同一台服务器的多个站点在时间段D 中同时上报96点发电计划,而其他服务器相对空闲时,采用Fair 策略分配处理请求的Web 应用服务器。
任务分配策略切换机制:当客户端的Web 应用服务请求的响应时间大于用户最大容忍时间时,即Tf>,当前客户端所分配的服务器会反馈告警信息到Nginx 负载均衡管理器Keepalived,使之进入IPHF 阶段2;随即,采用Fair 方式处理所积攒的Web 应用服务,直到在下一个D 时段内没有出现响应时间大于的任务请求,再次切换到IPHF阶段1。
(2)IPHF阶段2:Fair动态服务器组分配算法原理。
每个服务器中的当前任务总数Si和服务器执行时间都是已知的。在当前时段D,新接入的任务请求将被分配至最先达到空闲状态的服务器Si中,即式(3):
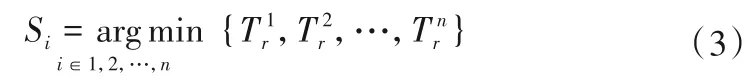
IPHF负载均衡任务分配算法伪代码如下。


4 性能评价
用户的数据库访问时间,体现在客户端访问Web 应用服务器时,从请求任务到响应执行完毕的过程(包括应用服务负载均衡分配、读写分离数据库服务器划分和分级分区数据库表映射)。为了对上述整体优化设计进行综合性能评价,采用基于实际业务数据的算法仿真方式对Web 应用服务的查询时间和成功完成任务的比率进行对比分析[16-18]。
4.1 数据来源与性能评价参数
模拟数据为2019 年7 月至2019 年12 月共6 个月的云南电网运行数据,由于系统采用了分库分区的优化方法,所有运行数据按照月份存储在不同的分区表中,各个分区表的记录数和占用空间等详细信息如表1所示。
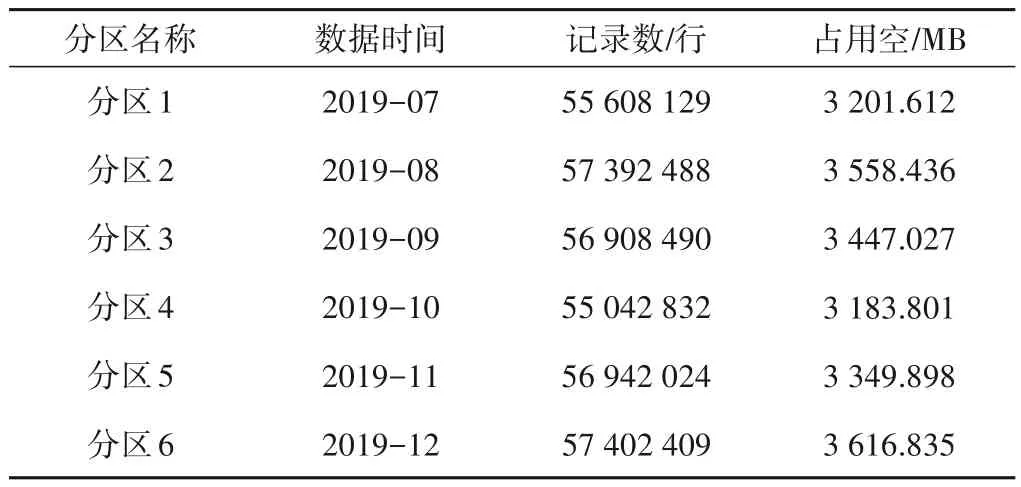
表1 分区表模拟数据详情Tab.1 Partition table simulation data details
模拟测试环境随机抽取了100 组数据,将Web 应用服务请求的平均响应时间t、Web 服务器的负载均衡指数LI以及任务成功接纳率Ps作为算法的评价标准。同时,将IPHF 与单独运用IP_hash或Fair的负载均衡任务分配算法进行对比。
LI、Ps可分别通过公式(4)、公式(5)进行计算。

式中:n为Web服务器的总数,Si为Web 服务器所成功接纳的服务请求总数。
本文规定Web 应用服务请求的响应时间大于任务时间阈值时,即t>,认为任务接纳失败。

式中:s为任务成功接纳的数量。
仿真过程中客户端的数量分别设置为1 000、1 500、2 000、2 500、3 000,客户端的Web 应用服务请求按照泊松分布到达,请求的任务大小符合正态分布;Web 服务器数量设置为3。针对上述三种算法,对相关参数设置分述如下:
(1)IPHF:客户端均匀分配至Web服务器,Tf=5 s;
(2)IP_hash:客户端均匀分配至Web服务器;
(3)Fair:Web 服务器根据其状态(最小剩余任务时间)响应客户端请求。
4.2 性能分析
Web应用服务请求的平均响应时间仿真结果如图6所示。
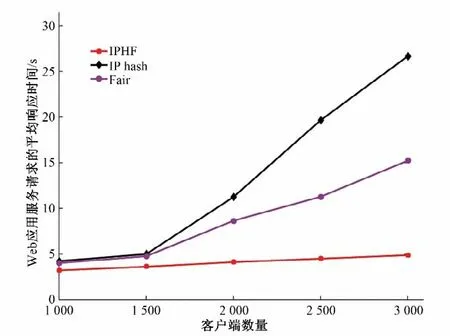
图6 不同算法下的请求平均响应时间MRTFig.6 MRT under different methods
结果表明,当客户端的数量为1 000、1 500时,3 种算法的Web 应用服务请求的平均响应时间保持在5 s 以内。随着客户端的数量的增加,IPHF 相比较IP_hash 和Fair有着更好的表现。当客户端的数量为3 000时,IPHF 的Web 应用服务请求的平均响应时间为4.88 s;而IP_hashFair 的平均响应时间分别为26.68和15.23 s,其中IP_hash 的平均响应时间最长,Fair 表现次之。这是因为这两种算法下,客户端的任务请求被指定的Web 服务器所响应,当某个客户端的请求的任务大小较大时,会导致后续的客户端任务请求发生阻塞,等待Web 服务器处理完前一个客户端的任务请求。
Web服务器的负载均衡指数LI仿真结果如图7所示。
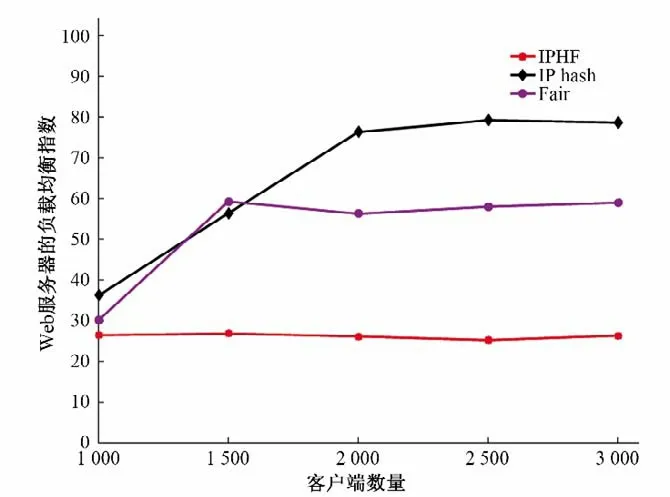
图7 不同算法下的请求平均响应时间MRTFig.7 MRT under different methods
结果表明,IPHF 的LI分别为在不同客户端的数量下保持在26.34。在客户端数量为3 000时,IP_hash 和Fair的LI分别为78.62、58.96。同时,IP_hash 和Fair 随着客户端数量的增加,LI呈现着上升后平稳的趋势,这是由于在客户端数量较少时,IP_hash 和Fair 都可以及时处理客户端的服务请求。随着客户端数量的增加,服务请求数增多,服务器对个别服务请求的响应时间超过Tf,导致请求接纳失败。任务成功接纳率Ps仿真结果如图8所示。

图8 不同算法下的任务成功接纳率指标PsFig.8 Indicator Ps under different methods
同样地,IPHF表现出的性能最佳,在不同数量的客户端下,任务成功接纳率Ps均可达到99%。而IP_hash 和Fair 随着客户端数量的增加,任务成功接纳率Ps有着明显的降低。该项指标的提高,将大大减少用户由于无法正常使用客户端APP 访问电网业务系统的概率,避免盲目尝试短信等其他方式造成的二次信道拥堵。
5 结论
为了提高对地域分布广、数量多的小电站的信息化水平,在硬件和通信条件有限的电网信息管理系统升级改造时,必须考虑如何改善在并发访问度较高、数据存储量较大情况下的用户使用体验。以云南电网为应用背景,综合采用读写分离的主从式数据库服务器、基于分库分区的海量数据存取机制、基于双Nginx 负载均衡服务器的系统架构和改进的任务分配算法,有效提升了系统的可扩展性和快速响应能力。实验结果表明,系统采取的数据访问控制技术极大降低数据的访问响应时间,提高多应用服务器之间的均衡度和总体任务成功接纳率,最大限度地满足发电行业数据上报和查询的业务需求,为保障复杂多源发电站的信息系统可用性提供了先进实用的解决方案。
