基于小波包分解的EHO-ELM 与EHO-DELM日径流多步预报模型研究
2022-10-27李新华崔东文
李新华,崔东文
(1.云南兴电集团有限公司,云南文山 663000;2.云南省文山州水务局,云南文山 663000)
0 引言
日径流时间序列预报被广泛应用于水库实时运行调度、水电系统经济运行及航运、防洪等领域,尤其是时间序列分析及多步预报一直是日径流预报研究领域的热点和难点。目前日径流时间序列预报方法有自回归模型(Auto Regressive,AR)[1]、人工神经网络(Artificial Neural Network,ANN)[1]、自适应神经模糊推理系统(Adaptive Neural Fuzzy Inference System,ANFIS)[1]、长短时记忆神经网络(Long Short-Term Memory,LSTM)[2]、支持向量机(Support Vector Machine,SVM)[3-5]等,但还没有一种统一和普遍适用的方法。由于日径流受天文、气象、地理等多重因素的影响,常表现出较强的非线性、非平稳性和多尺度等特征,传统单一预测方法难以获得较好的预报效果。当前,基于“分解方法+预测器”模式的多种方法混合预报模型被尝试用于日径流时间序列预报研究,并取得较好的预报效果。孙望良[2]等引入变分模态分解(Variational Mode Decomposition,VMD)、去趋势波动分析(Detrended Fluctuation Analysis,DFA)和LSTM方法,提出DFA-VMD-LSTM 日径流预报模型,并将其应用于三峡水库日径流预报研究,取得较好预报精度;黄景光[3]等基于小波分解(WD)方法和SVM 建立组合日径流预报模型,将其应用于宜昌站日径流预报,验证了该模型具有更好预报稳定性;黄巧玲[4]等将小波变换与支持向量机结合,提出小波支持向量机回归模型(Wavelet Support Vector Machine,WSVR),利用所建立的WSVR 模型对张家山站日径流进行预报,结果显示WSVR 模型可有效模拟和预报日径流;任化准[5]等融合WD 方法、粒子群优化(Particle Swarm Optimization,PSO)算法和SVM,提出WPSO-SVR 日径流预报模型对金沙江中游石鼓站日径流进行预报,表明该模型在日径流预报中具有较强的适应性。然而,上述模型[2-5]及大多数日径流预报仅针对预见期为1 d 的单步预报,在实际应用中,预见期为1 d 的单步预报无法满足日径流预报实际需求,往往需要根据历史数据实现更多尺度的超前多步预报,即实现未来更为长远的日径流时间点预报[6]。
为提高日径流时间序列多步预报精度,针对上述问题,本文基于以下因素,提出基于小波包分解(WPD)、象群优化(EHO)算法和极限学习机(ELM)、深度极限学习机(DELM)多种方法的WPD-EHO-ELM、WPD-EHO-DELM 日径流时间序列混合预报模型,并应用于云南省景东水文站日径流时间序列多步预报。①WPD 能同时将低频、高频信号进行再次分解,提取出更具规律的子序列分量,克服WD 方法不对高频信号再次分解的不足;同时,WPD较小的分解层即能获得较好的分解效果。②目前,日径流时间序列预测器主要有BP 神经网络、SVM、LSTM等,但BP 神经网络模型存在设置参数多、易陷入局部最优等缺点;SVM 模型存在对参数敏感、大容量样本预报中表现不佳等不足;LSTM 模型虽然预测性能较好,但存在内存资源消耗大、运行时间长等缺陷。ELM、DELM 预测器不但预测性能好,且在日径流预报研究中应用不多。③ELM、DELM 网络输入层权值和隐含层偏置是制约其性能提高的关键因素,本文采用EHO 算法优化ELM、DELM 输入层权值和隐含层偏置,以期提高ELM、DELM预测器性能。
1 研究方法
1.1 小波包分解(WPD)
小波包分解(WPD)衍生于小波分解(WD),与之不同的是,WD 只对低频信号再次分解,不分解高频信号,而WPD 同时将低频、高频信号再次分解,并能根据信号特性和分析要求自适应地选择相应频带与信号频谱相匹配。对于波动信号,采用WPD能够凸出信号的细节特征。小波包分解算法公式[7-10]为:
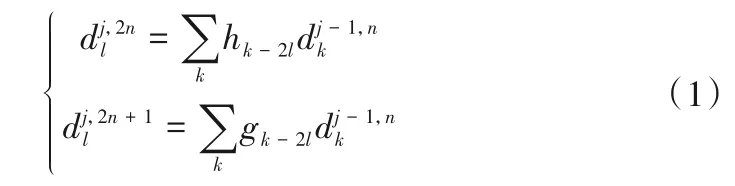
重构算法为:
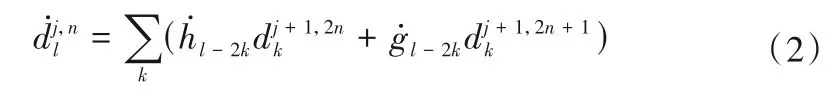
1.2 象群优化(EHO)算法
象群优化(EHO)算法是Wang等人于2016年提出了一种新的群体智能优化算法。EHO 算法源于自然界中大象的畜牧行为,并基于以下假设:①象群分为几个氏族,每个氏族中母象作为首领;每一代中,一定数量的雄象会离开氏族。②女族长是氏族中适应度最好的大象,每头大象的位置根据其位置和女族长的位置进行更新;族长的位置根据氏族中心的位置进行更新。③EHO 算法包括氏族更新操作和分离操作两个阶段,氏族更新代表着局部搜索,雄象离开氏族执行全局搜索[11,12]。
EHO算法数学描述如下[11,12]:
(1)氏族更新。随机初始化大象种群,将大象种群分为n个氏族,每个氏族中有j头大象,在每次迭代中,每头大象j的位置都会随氏族ci中族长(适应度值最好的位置)移动。位置更新数学描述为:
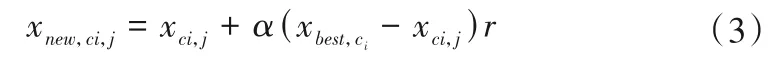
式中:xnew,ci,j表示随氏族ci中第j头大象更新后的位置;xci,j表示氏族ci中第j头大象上一代位置;xbest,ci表示氏族ci中适应度值最好的位置;α∈[0,1]表示最佳女族长对大象个体xci,j的影响比例因子;r表示[0,1]范围内的随机数。
氏族ci中女族位置更新数学描述为:

式中:β∈[0,1]表示氏族中心控制参数;nci表示氏族ci中大象的数量;xci,j表示氏族ci中大象个体。
(2)氏族分离。EHO 算法中,每个氏族ci中具有最差适应度函数值的恒定数量的大象会被移动到新的位置。其位置更新数学描述为:
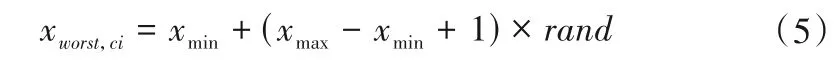
式中:xworst,ci表示氏族ci中具有最差适应度函数值的大象位置;xmax、xmin表示搜索空间上下限值;rand表示[0,1]范围内的随机数。
1.3 极限学习机(ELM)
极限学习机(ELM)是一种广义的单隐层前馈神经网络,具有较快的学习速度和良好的泛化能力。给定M个样本Xk={xk,yk},k=1,2,…,M,其中xk为输入数据,yk为真实值,f(·)为激活函数,隐层节点为m个,ELM输出可表示为[13,14]:

式中:oj为输出值;Wi={ωi1,ωi2,…,ωim}'为输入层节点与第i个隐含层节点的连接权值;bi为第i个输入节点和隐含层节点的偏值;λi为第i个隐含层节点与输出节点的连接权值。
1.4 深度极限学习机(DELM)
深度极限学习机(DELM)从结构上看相当于把多个极限学习机(ELM)连接到一起,能更全面地捕捉到数据之间的映射关系,有效提高处理高维度、非线性数据的能力。设DELM 有Q组训练数据{(xi,yi)|i=1,2,…,Q}和M个隐含层,将输入训练数据样本根据自编码器极限学习机(ELM-AE)理论得到第一个权值矩阵β1,接着得到隐含层特征向量H1,…,以此类推,能够得到M层的输入层权重矩阵βM和隐含层特征向量HM。DELM 数学模型表述式为[15-17]:
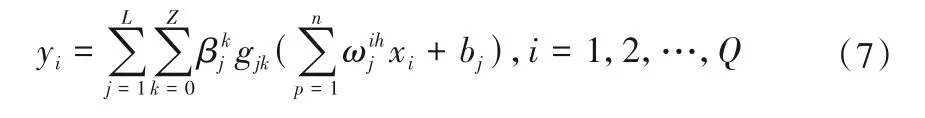
式中:L为隐含层神经元个数;Z为隐含层神经元对应的衍生神经元个数;为第j个隐含层神经元对应的第k个衍生神经元与输出层的权值向量;gjk为第j个隐含层神经元激活函数的k阶导函数;n为输入层神经元个数;为输入层与第j个隐含层神经元之间的权值向量;bj为第j个隐含层节点的偏置。
1.5 建模流程
WPD-EHO-ELM、WPD-EHO-DELM 模型预报步骤如下:
步骤一:为兼顾模型预报精度和计算规模,本文基于dmey小波包基,采用2 层WPD 将景东水文站2016-2020 年逐日时序数据分解为4 个子序列分量[2,1]~[2,4];作为对比方法,采用WD 将实例日径流时序数据分解为4 个子序列分量S1~S4,见图1、2。
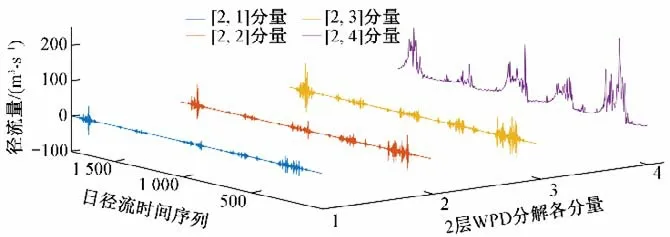
图1 景东站WPD分解3D效果图Fig.1 Jingdong Station WPD decomposition 3D renderings
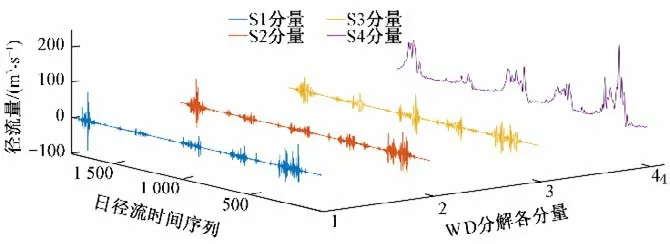
图2 景东站WD分解3D效果图Fig.2 Jingdong Station WD decomposition 3D renderings
从图1、2 可以看出,[2,4]、S4 主要为低频部分,聚集了原始日径流时间序列的大部分能量,描述了日径流序列的趋势;[2,1]、S1 为所有分解分量中的高频成分,也是幅值较低的分量,描述了日径流序列的波动情况。
步骤二:为便于各分量预测结果重构,在延迟时间为1的条件下,采用Cao 方法确定各子序列分量的嵌入维度m,即选取景东水文站前m 天的径流量来预报当日(1 d)、第二日(2 d)、……、第5日(5 d)的日径流量。经计算,Cao方法确定子序列分量[2,1]~[2,4]m值分别为13、24、12、13;确定子序列分量S1~S4m值分别为28、24、26、15;确定原日径流序列m值为25。并选取景东水文站2016-2018年逐日径流作为训练样本,2019-2020年逐日径流作为预报样本。
步骤三:利用训练样本均方误差(MSE)作为EHO 优化ELM、DELM输入层权值和隐含层偏值的适应度函数minf。

步骤四:设置最大迭代次数T,种群规模N;随机初始化大象位置。
步骤五:计算大象个体的适应度值,确定并保存当前最佳大象位置xbest。令迭代次数t=1。
步骤六:利用式(3)更新种群中大象个体位置;利用式(4)更新当前最优个体位置;利用式(5)更新当前最差个体位置,保留更好个体位置。
步骤七:计算更新之后大象种群个体适应度值,比较并保存当前最佳大象位置xbest。
步骤八:令t=t+1。判断是否满足终止条件,若是,输出xbest,算法结束;否则转至步骤六。
步骤九:输出最佳大象位置xbest,xbest即为ELM、DELM 输入层权值和隐含层偏值最佳矩阵。利用最优ELM、DELM 输入层权值和隐含层偏值矩阵建立EHO-ELM、EHO-DELM 模型对各分量进行多步预测,将预测结果叠加重构后即得到实例多步日径流预报结果。
步骤十:利用平均绝对百分比误差(MAPE)、平均绝对误差(MAE)、确定性系数(DC)和合格率(PR)对预报模型进行评估,见式(9)。

2 实例应用
景东站位于云南省普洱市景东县锦屏镇,建于2000 年1月,系红河流域李仙江干流控制站,控制径流面积5 521 km2,水文站至源头河长90 km,河道坡度6.68‰,为省级重要水文站和省级报汛站。李仙江发源于大理州南涧县宝华乡东北部,流经普洱市景东、镇沅等县,于普洱市江城县与红河州绿春县的界河流入越南,出境后称黑水河。李仙江云南境内河道长473 km,落差1 790 m,流域面积19 309 km2,多年平均流量约460 m3/s,主要支流有阿墨江、勐野江、泗南江等。
本文以景东水文站2016-2020 年日径流预报为研究对象,日径流变化曲线见图3。从图3 可以看出,景东水文站日径流时序数据呈现出典型的多尺度、高度非线性特征,其最大与最小实测径流之比高达89.7,起伏变化十分激烈。
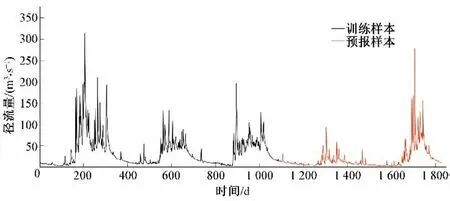
图3 景东站2016-2020年逐日径流变化曲线图Fig.3 Daily runoff change curve of Jingdong Station from 2016 to 2020
2.1 模型参数设置
设置EHO 算法最大迭代次数T=100,种群规模N=50,其他采用算法默认值;ELM 网络激活函数选择sigmoid,隐层节点数为2m-1(m为输入维数),输入层权值和隐含层偏值搜索空间设置为[-1,1];DELM 采用3 隐层网络,隐层节点数为[2m m m](m为输入维数),激活函数选择sigmoid 函数,输入层权值和隐含层偏值搜索空间设置为[-1,1];所有模型数据均采用[-1,1]进行归一化处理。
2.2 预测结果及分析
利用所构建的WPD-EHO-ELM、WPD-EHO-DELM 等6 种模型对景东水文站2016-2020 年日径流进行训练及多步预报,结果见表2。并利用上述评估指标对模型性能进行评估。各模型预报相对误差效果图见图4。
依据表1及图4可以得出以下结论:

表1 各模型景东站多步预测结果对比Tab.1 Comparison of multi-step prediction results of each model Jingdong Station
(1)WPD-EHO-ELM、WPD-EHO-DELM 模型对景东水文站预见期为1~5 d 日径流预报的MAPE分别在0.25%~8.25%、0.52%~9.44%之间,MAE在0.050~1.269 m3/s、0.103~-1.342 m3/s之间,PR≥89.2%,DC≥0.990 0,精度评价等级均为甲级(合格率≥85%、确定性系数≥0.90),预报精度优于WD-EHO-ELM 等其他模型。其中预见期为1~3 d 日径流预报的MAPE≤1.81%、PR 均为100%,DC≥0.999 6,预报效果尤为理想。可见,WPD-EHOELM、WPD-EHO-DELM 模型日径流多步预报结果可靠性较强,均能够很好的逼近实测日径流值,将其用于日径流时间序列多步预报是可行和可靠的。相对而言,WPD-EHO-ELM 模型预报效果略优于WPD-EHO-DELM 模型。
(2)从基于WPD、WD 方法构建的不同模型预报效果来看,WPD-EHO-ELM、WPD-EHO-DELM 模型预报精度优于WDEHO-ELM、WD-EHO-DELM 模型,表明WPD 能充分挖掘日径流时序数据的潜藏规律,同时将低频、高频信号进行再次分解,提取出更具规律的子序列分量,其分解效果要优于WD方法。
(3)从WPD-EHO-ELM、WPD-EHO-DELM 两种模型预报效果对比来看,虽然DELM 相当于把多个ELM 连接到一起,能更全面地捕捉到数据之间的映射关系,但过多的ELM 组合不但增加模型复杂度,同时也增加优化DELM 输入层权值和隐含层偏值的难度;ELM 虽然只有1 个隐层,但通过EHO 算法优化获得最佳ELM 输入层权值和隐含层偏值,同样可以获得理想的预报效果。
(4)WD-EHO-ELM、WD-EHO-DELM 模型仅在单步预报情形下(预见期为1 d)能达到《水文情报预报规范》(GB/T22482-2008)预报精度等级甲级;在预见期为2 d情形下,WDEHO-ELM 模型预报精度等级为乙级,WD-EHO-DELM 模型为丙级;在预见期为3 d 情形下,WD-EHO-ELM 模型预报精度等级为乙级,WD-EHO-DELM 模型已不能满足预报精度要求。在日径流时序数据未经分解情形下,即便在预见期为2 d 情形下,EHO-ELM、EHO-DELM 模型预报精度均不理想,仅EHODELM模型预报精度等级达到丙级,EHO-ELM 模型已不能满足预报精度要求。
(5)从图4 可以看出,WPD-EHO-ELM、WPD-EHO-DELM模型对景东水文站预见期为1~3 d 绝大多数日径流预报的相对误差均在-2%~2%范围内波动,具有更小的预报误差和更高的预报精度。

图4 各模型预报相对误差3D效果图Fig.4 3D rendering of the relative error of each model forecast
3 结论
为提高日径流时间序列多步预报精度,基于WPD 方法、EHO 算法和ELM、DELM 网络,研究提出WPD-EHO-ELM、WPD-EHO-DELM 日径流时间序列多步预报模型,并构建WDEHO-ELM、WD-EHO-DELM、EHO-ELM、EHO-DELM 作对比分析模型,通过云南省景东水文站日径流时间序列多步预报实例对各模型进行验证,得到如下结论:
(1)WPD-EHO-ELM、WPD-EHO-DELM 模型对景东水文站预见期为1~5 d日径流预报均达到《水文情报预报规范》(GB/T22482-2008)预报精度等级甲级,预报效果优于其他对比模型。其中,预见期为1~3 d日径流预报的MAPE≤1.81%、PR均达100%,DC≥0.999 6,预报效果最理想。可见,将WPD-EHOELM、WPD-EHO-DELM 模型用于日径流时间序列多步预报是可行、可靠的。模型及方法可为实现日径流时间序列精准预报提供新的途径。
(2)WPD-EHO-ELM、WPD-EHO-DELM 模型预报精度优于WD-EHO-ELM、WD-EHO-DELM 模型,表明WPD 能充分挖掘日径流时序数据的潜藏规律,同时将低频、高频信号进行再次分解,提取出更具规律的子序列分量,其分解效果要优于WD方法。
(3)相较于WPD-EHO-DELM 模型,WPD-EHO-ELM 模型表现出更简洁、更高效的预报效果。虽然DELM 能更全面地捕捉到数据之间的映射关系,但过多的ELM 组合不但增加模型复杂度,同时也增加EHO 算法优化DELM 输入层权值和隐含层偏值的难度;虽然ELM 网络仅有1 个隐层,但通过EHO 算法优化获得最佳ELM 输入层权值和隐含层偏值,同样可以获得更好的预报效果。
(4)WPD-EHO-ELM、WPD-EHO-DELM 模型能充分发挥WPD 方法、EHO 算法和ELM、DELM 网络优势,表现出较好的预报精度和稳定性能,模型的预报精度随着预见期天数的增加而降低。
