探究工业大数据在柔性作业车间的动态调度
2022-10-27李昊巍
李昊巍
(中国工业互联网研究院,北京 100102)
1 调度规则挖掘架构
柔性车间是能够灵活调整工序加工路径的一种车间模式,在运行中会有很多扰动情况出现,此外还会有高纬度,多样化以及规模化的数据[1]。根据其特点,本文设计的挖掘架构见图1。该架构的组成部分有基于改进随机森林算法挖掘模型、扰动属性聚类策略以及结合大数据预处理模型。
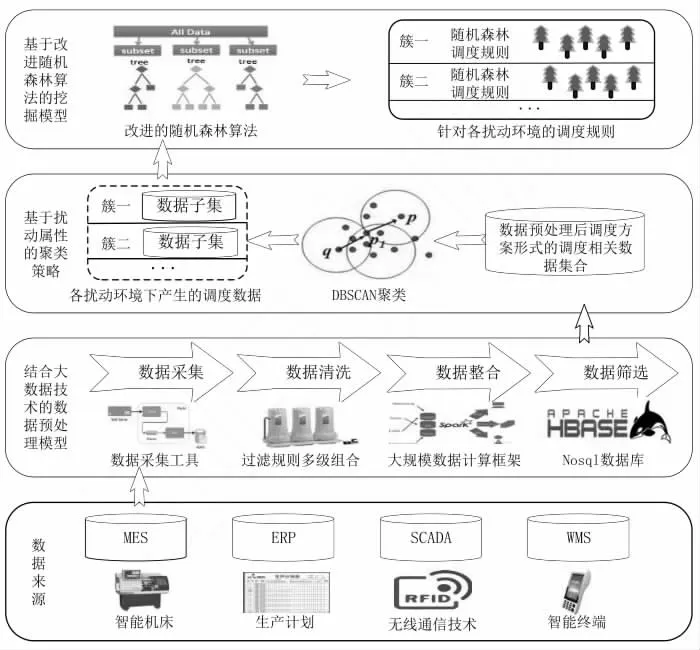
图1 挖掘架构
通过改进随机森林算法模型能够从历史数据中发现调度规律,并通过调度规则来进行表现。这种模型作为挖掘算法,根据决策树来对随机森林规则进行构建,在通过加权之后得到结果,从而能够对优先性高的工件或者是合适的机器进行区分。
1.1 预处理模型
现阶段在制造业中物联网技术、自动化技术以及信息技术的快速发展,尤其是车间底层广泛的应用数据采集装置,无线传感器以及其他智能感知设备,企业大幅度的提高获取调度历史数据的能力。本文提出了和大数据技术相结合的一种数据预处理模型,该模型包含的有数据的筛选、采集、整合以及清洗,见图2。
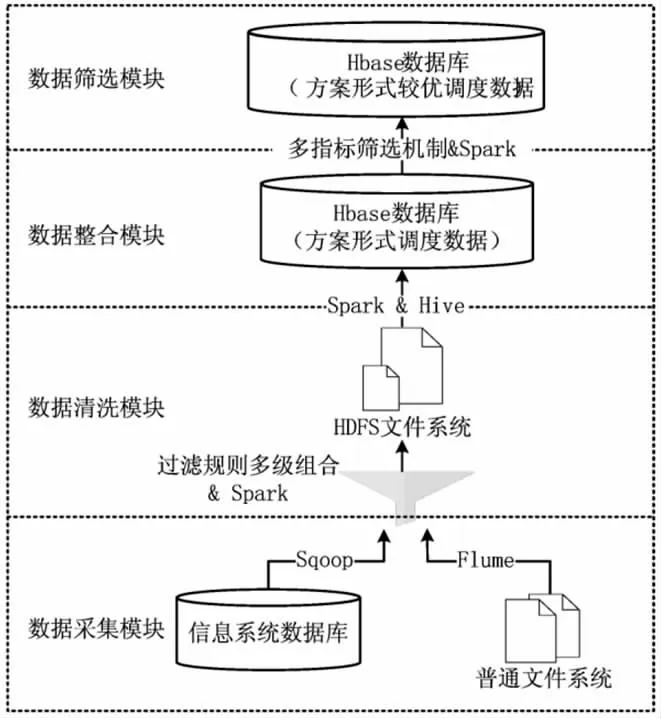
图2
1.1.1 数据采集
要想挖掘,前提需要采集数据,而数据采集是对柔性车间数据从多个数据源中进行采集。本文采取Flume 和Sqoop 数据采集工具,从数据库中获得工件、人员和机器等信息[2]。对柔性车间在扰动下的调度问题进行考虑,需要解决工件机器选择和空间工件选择的问题,所以采集的调度历史数据集合D 能够表示为Dh={d1,d2,d3}。其中d1表示制定方案时和扰动相关的系统信息,比如返工工件的数量,机器故障的数量等。d2表示某个工件的某到工序选择的机器,能够对这道工序进行加工的每台机器信息,比如对这道工序该机器的加工时间,机器前在制品数量等。d3表示空闲机器在等待中对工件进行选择加工时,当前等待中的每个工件的信息,比如工件是不是返工工件,在该机器上工件的加工时间等。
1.1.2 数据清洗
在智能化趋势下的车间,肯定会多次重复的记录调度相关历史数据,从而会使得采集的调度数据集合Dh中有数据重复以及数据冲突的情况,要想对之后的调度挖掘奠定基础必须要对这些调度数据进行数据清洗才行[3]。本文通过建立数据清洗以及过滤规则,定义每种生产属性需要的过滤规则以及内部数据处理逻辑,来对采集的数据进行清洗。根据清洗和过滤规则,采集的每条数据都会根据自身数据集合中的哪种数据,来对数据清洗方法进行查询,选择相应规则进行组合,对于最终的数据清洗根据Spark 来进行完成。在Hadoop 分布式文件系统(HDFS)中把清洗好的调度数据集合Dh进行存储。
1.2 基于生产扰动属性的聚类策略
本文挖掘算法选择的是随机森林法,最终得到该算法的随机森林,实际就是多棵C4.5 决策树。所以,调度性能和决策树的分类性能有着很大的关系,而决策树的分支数量影响着调度规则的复杂程度以及计算效率。而决策树的分支越少,分类性能越好,得到的调度规则的计算效率越高,复杂程度越低。而根据扰动的聚类策略主要就是为了对决策树的分类性能进行提高,对分支数量进行减少[6]。基于此点,通过挖掘算法,能够得到不同扰动下的调度规则。在发生扰动变化时,对调度规则进行切换,能够提升扰动的实时响应能力。
在动态调度中,扰动发生改变,那么生产属性就会影响调度的决策,比如,在没有扰动情况下,在对工件加工进行判断时,空闲机器不会对这个工件是否为紧急订单而考虑其优先性,但如果车间有紧急插单时,那么对于工件进行加工时的优先性会考虑该工件是不是紧急订单。而生产属性影响调度决策主要在决策树中生产属性信息增益率的变化进行体现,其公式如下所示。
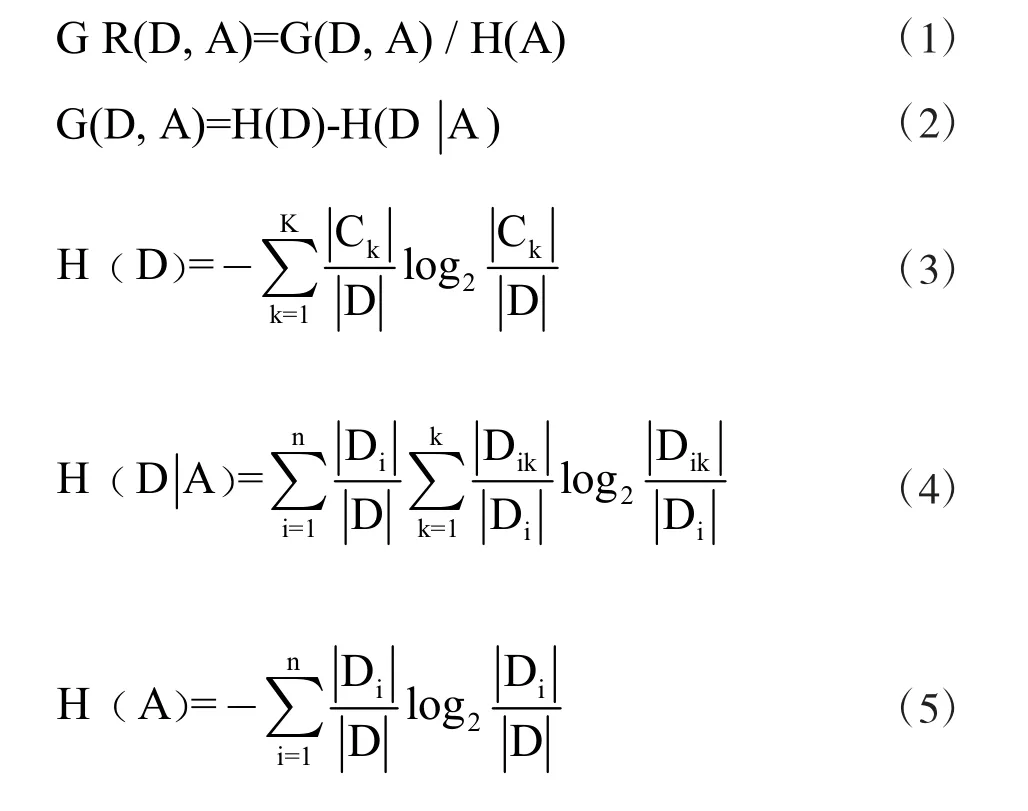
其中,|Dik|表示Dik的训练实例个数,Dik表示Di中属于Ck的集合,|Di|表示Di训练实例个数,D 通过A可以划分为n 个子集D1,D2,......,Dn,|Ck|表示Ck中的训练实例个数,|D|表示D 的训练实例个数,H(A)表示A 的分裂信息,G(D,A)表示A 的信息增益,GR(D,A)表示A 的信息增益率。
1.3 改进森林算法的挖掘流程
改进随机森林算法流程见图3 所示,在图3 中的规则1 是通过d2 数据训练得到的,主要是对选择工件机器问题进行解决。规则2 是通过d3 数据训练得到的,主要是对空闲机器工件选择问题进行解决。对于某个扰动情况下,使用该算法挖掘规则如下:
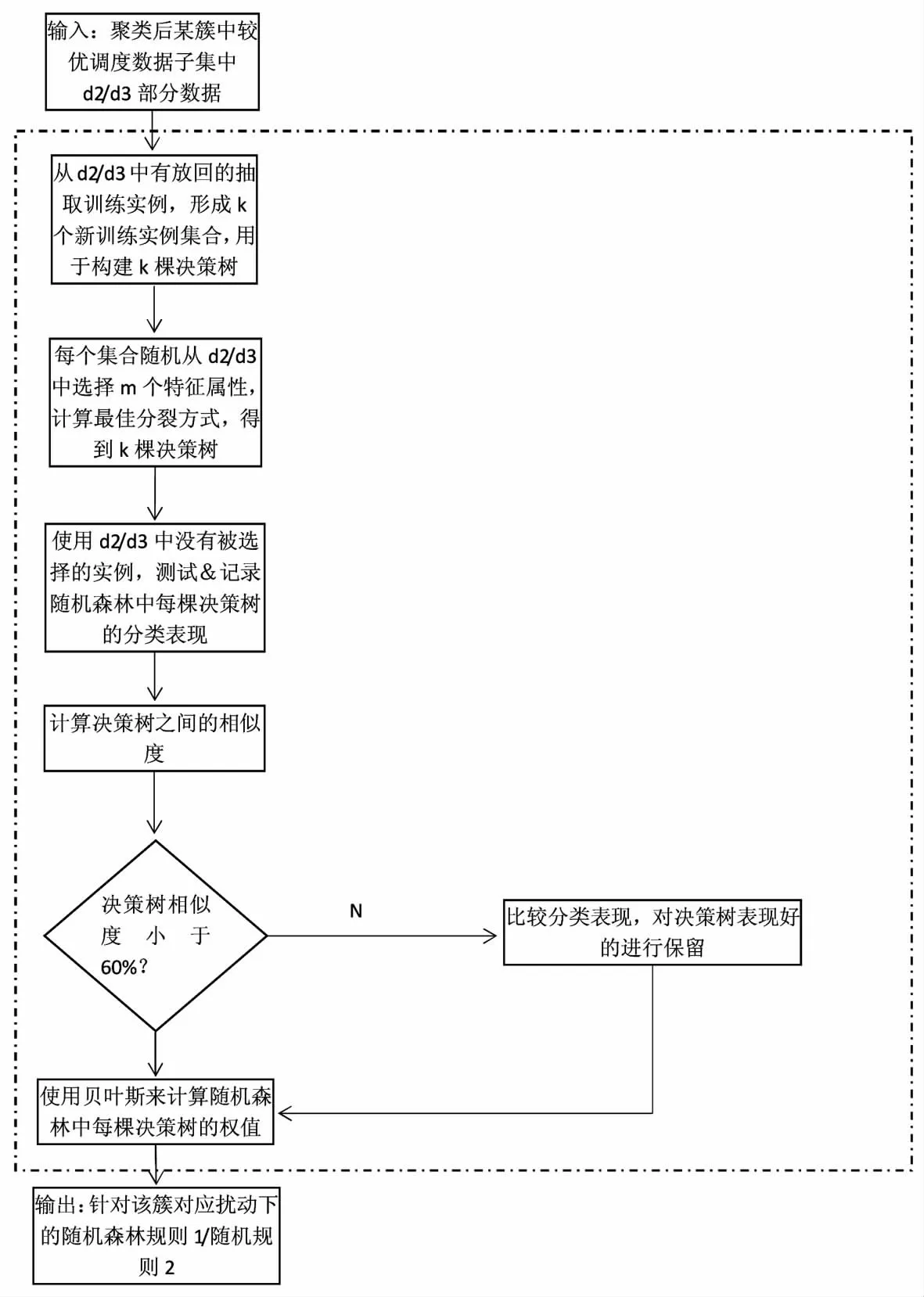
图3 改进随机森林算法
步骤1:对随机森林进行构建,首先训练数据是扰动下对应簇中的较优数据。然后从d2 和d3 部分数据中进行抽取训练实例,形成k 个新集合。最后,从d2和d3 中,随机的进行m 个属性的选择,并对最好的分类进行计算,以此能够得到k 棵决策树。
步骤2:对决策树的分类表现进行测试,测试数据是由d2 和d3 中部分数据没有被选中的实例数据,对每颗决策树分类表现进行测试并记录。
步骤3:对决策树相似的策略进行避免。对决策树之间的相似度进行计算,如果两者之间的相似度在60%以上,那么该决策树就可以认为是相似的,需要对表现比较差的决策树进行淘汰。
步骤4:对每棵决策树的权值进行计算。根据测试的表现,对保留下来的决策树权值进行计算,公式如下所示。
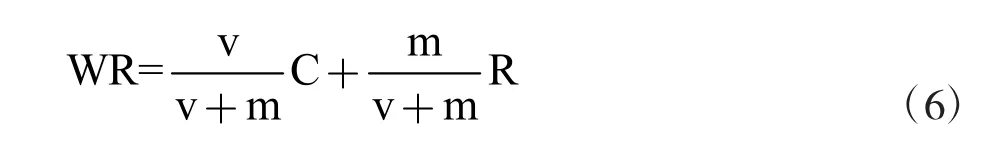
2 结论
对于柔性车间动态调度问题,本文提出了工业大数据特点的调度挖掘方法。这种算法在调度历史存在噪声,高纬度以及大规模的数据中较为合适,这种挖掘方法在实时响应能力,计算效率以及实际可操作性等方面表现是非常不错的。因挖掘得到的调度性能会受到历史调度优劣的影响,所以,之后可对调度规则相关数据进行研究,以此来不断的完善随机森林调度规则。
