手势识别引导机械臂的零件智能装配方法*
2022-10-26李迅波凡雷雷茹元博孙佳宁范俊飞
李迅波,王 瑜,凡雷雷,茹元博,孙佳宁,高 翔,范俊飞
(1. 电子科技大学机械与电气工程学院,四川成都 611731;2. 电子科技大学广西智能制造产业技术研究院,广西柳州 545003;3. 广西津晶集团有限责任公司,广西柳州 545006)
引 言
智能工厂是生产制造领域的发展趋势,为提高工厂的自动化与智能化水平,实现工人与机器的协同工作,相关领域的发展对人机协同项目的需求越来越大。在传统装配过程中,装配体部件的捡取、识别、装配等过程都是由工人手动完成的,在使用人机交互工具(鼠标、键盘、触摸屏等)时都有一定的限制,很难进行高自由度输入。新兴的人机交互方式往往更为便利,在智能人机交互中,以交互人视角为第一视角的手势表达发挥着重要作用,它将手势识别引入了人机交互系统,极大地方便了人们对智能设备的远距离控制[1]。
目前面向手势识别的方法主要分成两种:一是基于传统机器学习和图像处理的方法,它对复杂环境的特征提取和识别效果偏低;二是基于深度学习神经网络的方法,如Faster R-CNN模型[2]、YOLO模型[3]、SSD模型[4]等,其中YOLOv3因具有较好的识别效果和较快的识别速度而备受青睐。
本文针对SSD模型提出了具有定位与分类正确率高、鲁棒性强的智能机械臂抓取方法。将目标检测算法与区域分析结合起来,根据目标检测的结果缩小零件抓取分析范围,结合传统的图像分析方法提出一个物体角度的抓取参考矩形框生成算法来缩短滑动窗口计算消耗的时间,提高了抓取的成功率和实时性。同时借助改进的YOLOv3网络融合姿态估计方法,对操作人员的手势进行实时有效的识别,以便将正确的操作指令传达到机械臂,控制机械臂的后续检测抓取动作。
1 基于SSD模型的零件抓取位置检测算法
基于SSD模型的共享型卷积零件抓取位置检测方法,建立一个具有双网络模型的目标零件抓取位姿检测算法。通过较少的候选框、避免过多的循环计算及利用目标检测模型来减小区域分析范围从而提升整个网络模型(图1)的实时效率与准确度。将包含所有信息的整张图像分别作为两个卷积神经网络的输入向量,其中一个利用多目标零件检测网络对图像中的零件类别以及位置进行初步的判定,从而缩小候选区域分析的范围,另一个利用基于AlexNet的卷积神经网络对输入向量进行特征提取,获取一个目标零件的抓取位置向量。

图1 双网络零件抓取检测算法
训练数据采用康奈尔数据集[1],其中每张训练图像具有不同的位置描述向量(x,y,w,h)。等待SSD算法选择的目标区域经过滑动窗口生成抓取候选向量后,在AlexNet网络中的卷积层进行对应的特征向量转换,并利用空间金字塔池化(Spatial Pyramid Pooling, SPP)解决两种模型大小不一致的问题。同时所有的候选矩形框全部通过AlexNet的同一卷积层计算,减少了卷积计算过程中大量的重复计算时间,训练过程如图2所示。

图2 双网络零件抓取算法的训练过程
完成上述过程后,再将训练输出结果作为输入向量传入训练好的支持向量机(Support Vector Machine, SVM)分类器中,给出模型当前的目标零件抓取位置判断结果。通过康奈尔数据集中每张训练图像所包含的正负两种样例若干个矩形框信息,生成不同的候选矩形特征向量,使得SVM分类器的性能在正反例样本的训练下变得更加准确可靠。
在双卷积网络的抓取检测基础框架中,实际计算过程会耗费较长的运行时间,通过以下2种方法对上述基础框架进行改进,以提高框架的计算效率。
1.1 共享卷积层
双网络是针对同一输入图像进行相应的特征提取,然而如果同时使用SSD网络和AlexNet网络进行图像特征训练就会消耗不必要的时间,因为在卷积层上,同一图像包含的特征应该是相似的。借鉴共享卷积层的方法,将SSD网络与AlexNet网络结合起来,同时使用SSD基础网络模型中的卷积层Conv5作为特征提取的输出,再根据滑动窗口所产生的目标零件抓取候选矩形框的位置在SPP上进行特征向量的提取,最终作为SVM分类器的输入完成目标零件抓取框可行性判定。更新后的模型如图3所示。

图3 共享网络层改进框架
在图3中,SSD网络负责识别对应零件的特征,而AlexNet网络则负责提取零件抓取位置。采用这种方法,一个卷积神经网络就可同时完成目标识别与抓取位置检测2种任务,同时还极大地节省了计算时间,提升了框架的实时性能。
1.2 物体角度的参考矩形框筛选
在框架进行测试过程中,首先通过SSD网络模型检测到所需的目标零件以及对应的区域范围,然后通过滑动检测窗口的方法生成一系列候选矩形框。虽然检测区域已通过目标检测网络进行了裁剪,但候选矩形框生成的数量仍然过多,因此提出了一个通过传统边缘检测的方式实现物体角度的参考矩形框生成算法,以此来减少因滑动窗口而产生的过多的抓取位置,从而提升检测速度。更新后的最终模型如图4所示。
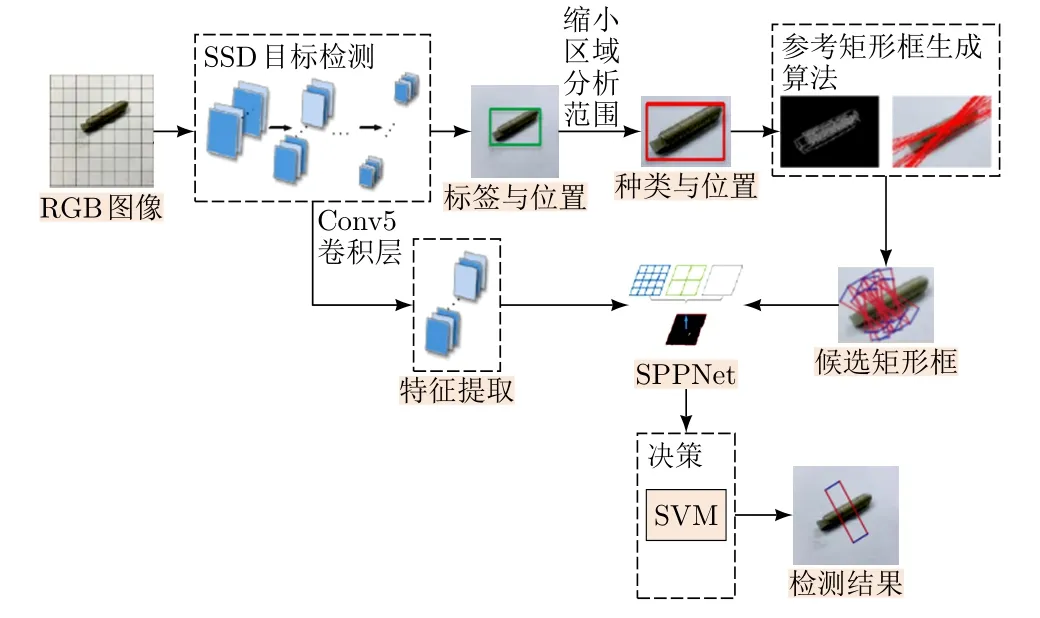
图4 基于SSD网络的零件抓取位置检测算法框架
2 基于YOLOv3网络的复杂背景手势定位算法
采用YOLOv3[5]网络来完成手势定位的任务。YOLOv3网络可将手势所在像素区域从原始图像中提取出来,从而保留手势特征,剔除背景特征。YOLOv3网络是一种卷积神经网络[6],网络输入为包含复杂背景的手势图像,输出为定位到的手势在原始图像中的位置。手势位置可由一个矩形框分离出来,根据矩形框两个对角点的坐标可确定这一矩形框。手势定位[7]去除了复杂背景的干扰,最终仅剩下手势区域部分图像,有助于提升整个手势识别系统的精度。
2.1 改进的YOLOv3网络结构
YOLOv3网络共由53个卷积层组成,网络输入为RGB图像,经过不同深度的卷积操作后,得到3个输出层。输入大小为416×416×3的图像,得到如图5所示的单输入、三输出结构图。从图5可以看出,YOLOv3网络输入为一张RGB图像,图像大小为416×416×3,经过了多层卷积操作后分别在3个不同的网络深度上得到网络输出,输出图像大小分别为13×13×18,26×26×18,52×52×18。其中13×13×18相当于将输入的原始图像划分为了13×13个小网格,分别检测每个小网格附近是否包含有手势目标,并用长度为18的向量来表示目标位置信息,其他大小图像的输出同理。
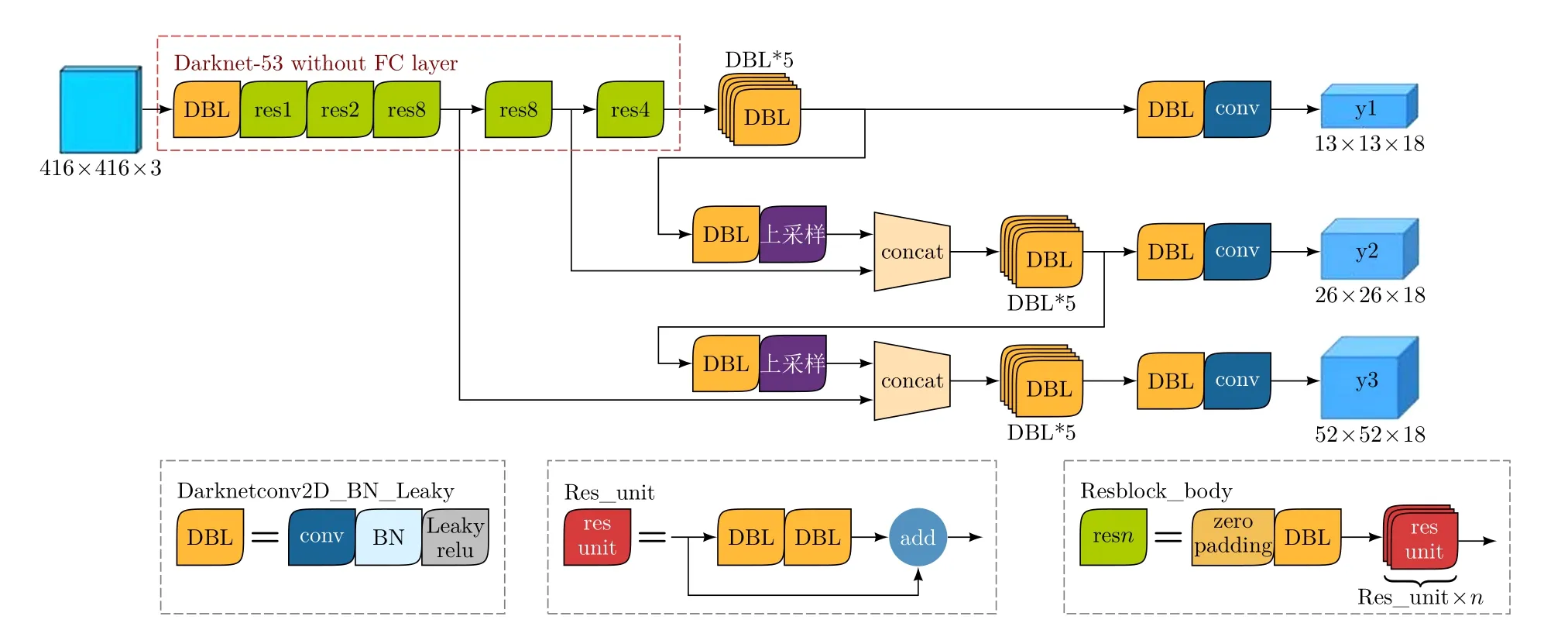
图5 YOLOv3网络结构图
YOLOv3网络利用多尺度特征进行目标定位,有助于提高定位精度。深层网络输出的特征图经过上采样之后变大,然后与浅层网络输出的特征图进行特征融合拼接。由于卷积神经网络在不同的卷积深度上提取到的特征语义不同,因此这一操作可充分利用网络提取到的浅层信息与深层信息进行目标定位,有助于定位精度的提高。
YOLOv3网络采用全卷积结构,引入了残差模块。YOLOv3网络弃用了经典卷积神经网络中常见的池化层和全连接层,采用了全卷积结构。经典卷积神经网络中池化操作常用于特征压缩,以减小后续模型的计算量,其缺点在于池化操作会造成信息丢失。YOLOv3网络以卷积层代替了池化层,通过设定大于1的卷积步长来进行特征压缩,不会造成特征信息的直接丢失。卷积层实际上是一种稀疏连接的全连接层,YOLOv3网络可以直接通过卷积操作进行边界框位置信息的回归。引入经典的残差结构,可有效减少网络退化,从而允许加深网络深度,提高网络的泛化能力。
2.2 基于YOLOv3网络的识别流程
YOLOv3网络的算法流程如图6所示。图中灰色立方块表示网络各层输出的特征图,除了图中展示的两处上采样之外,YOLOv3网络全部由卷积层组成。网络输入为包含复杂背景的单张RGB手势图像,网络有3个输出层。这3个输出层分布在YOLOv3网络的不同深度处,它们分别结合网络在不同深度的图像特征来输出定位到的目标,最终网络需要通过最大抑制算法来完成3个输出层的输出筛选工作,从而找出网络所有输出中的最优结果。
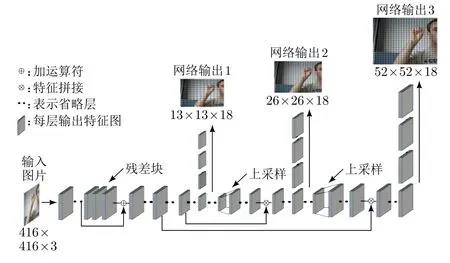
图6 YOLOv3网络算法流程
YOLOv3网络为全卷积网络,输入图像的大小可以不受限制。图6展示了输入大小为416×416×3的图像所得的网络输出结果。网络的三类输出图像大小分别为13×13×18,26×26×18和52×52×18。YOLOv3网络采用三输出的结构来提升网络对图像中各种大小目标的定位能力,并在网络中引入跳转结构来对不同深度的特征图进行特征拼接,使网络能够融合多种特征来进行目标定位,从而提高目标定位精度。
2.3 手势姿态估计模型
准确定义一个手势的姿态,需要引入一种手势姿态的表示方法。图7展示了手势姿态的一种表示方法。它采用21个手势关节点位置来表示手势的姿态,只要能从原始图像中获取这21个关节点的具体坐标位置,就能唯一确定这个手势的具体姿态。

图7 手势姿态的表示
卷积姿态机(Convolutional Pose Machine, CPM)是一种仅由卷积层和池化层组成的卷积神经网络[8]。它通过输入手势图像的特征学习到人手的隐式空间模型,由于不需要进行特征分类,因此卷积姿态机网络内并不包含全连接层,仅采用卷积层输出的特征图来直接确定手势关节点的位置[9]。本文利用CPM来构建一个手势姿态估计模型的算法流程(图8),其关键步骤是根据每张置信图的最大灰度值的坐标来定位关节点。
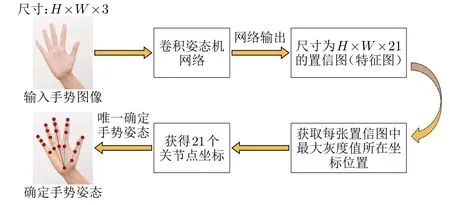
图8 卷积姿态机进行姿态估计算法流程
将构建后的CPM模型融入到Resnet-50手势分类模型中,如图9所示。模型输入为无复杂背景的手势图像,通过YOLOv3网络进行手势定位。由于CPM姿态估计网络与Resnet-50网络的输入图像大小不同,CPM手势姿态估计网络输入图像大小要求为256×256×3,Resnet-50网络输入图像大小要求为224×224×3,因此需要对图像进行缩放以获得相应大小的图像。为保证缩放时图像中手势不会因拉伸而变形,本文采样黑色填充的方法填充缩放前图像的边界使其成为正方形。

图9 融合姿态估计的手势分类模型构成
3 实验结果与分析
手势识别流程见图10。首先采用基于YOLOv3网络的手势定位模型进行复杂背景图像的手势定位,得到手势特征;然后基于Resnet-50网络对手势特征进行手势分类识别;接着将识别结果发送至LabView中,得到相应的指令;最后将指令打包发送到机械臂,控制机械臂运动,机械臂对目标进行位置检测,再进行相应的抓取动作。

图10 手势识别零件抓取流程图
人机交互流程:Dobot M1机械臂支持网线连接,故用网线连接主机与机械臂后,再配置机械臂的具体参数。获取主机及机械臂的IP地址,将其作为Lab-View中上下位机的通信地址,准备接收来自PC端的识别手势后的指令。
主函数由一个内含条件结构的while循环结构组成,摄像头对指定区域内的手势动作不断进行识别,将识别结果通过端口发送到LabView中。LabView得到转化为字符串的语音信号中的有效指令,之后再发送数据包到机械臂,控制机械臂运动。主函数中的条件结构分为4个分支:
1)“开始”分支。主函数识别手势动作并接收到“start”指令,主机通过UDP接口将IP地址发送至机械臂,机械臂开始工作,并通过UDP向机械臂发送初始位置坐标字符串,操纵机械臂运行到事先设置好的初始位置。播放相应零件装配的教学视频。
2)“抓取”分支。主函数识别手势动作并接收到“get”指令,主机向机械臂发送指令,将机械臂运行到假定零件的初始位置,执行抓取动作,然后移动至假定零件的目标位置,并执行放置零件动作。
3)“结束”分支。主函数识别手势动作并接收到“finish”指令,主机将教学视频路径和“抓取”坐标初始化,并回到“开始”分支的初始位置。
4)“错误”分支。主函数识别手势动作并接收到“silence”或“unknown”指令,机械臂不执行任何操。
对零件智能系统中的抓取控制部分进行性能测评,主要测评抓取成功率与分拣识别成功率。分拣识别表示系统在顺序识别零件上是否具有稳定的性能,抓取成功率则表示抓取位置检测算法的实际零件抓取边框的精确度。实验按照装配顺序对6种零件进行了20次实验,每次更换零件的位姿与位置,所得实验数据见表1。从表1可知,通用零件的总体识别率达到了94.1%,而机械臂的抓取成功率达到94%,证明将YOLOv3网络复杂背景手势定位算法应用到零件抓取任务中是可行的,基本可以应用于工业实际零件抓取。
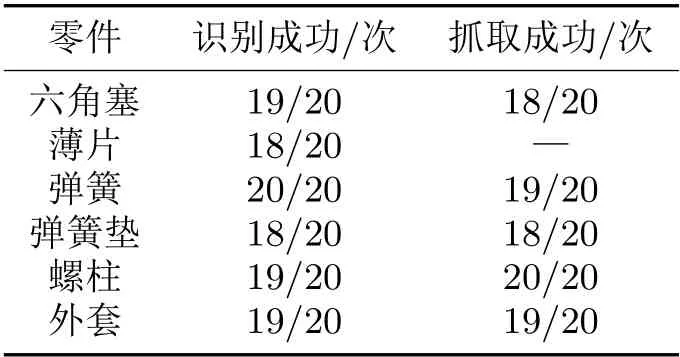
表1 六种零件实验数据记录
4 结束语
本文以SSD模型为基础,结合该模型在多目标零件检测实验中的结果,提出了一个基于SSD模型的零件抓取位置检测算法。首先通过目标检测模型给出当前图像中零件种类与对应位置,通过共享型卷积的思想将SSD卷积层输出作为抓取框特征提取网络的输出,以缩短重复的卷积操作时间;然后通过空间金字塔池化将数据集中的矩形框正负样例集转化为特征向量,作为支持向量机的输入样例进行训练,训练结果作为最终选择抓取位置的判定条件。
基于YOLOv3网络的手势定位模型进行复杂背景图像的手势定位,得到手势特征;然后基于Resnet-50网络对手势特征进行手势分类识别,机械臂将识别结果转化为相应的动作指令,对目标位置进行检测,执行抓取动作,供操作人员完成装配。实验证明,该算法能够实时检测手势,并且按照手势对应的指令顺序完成对应零件的抓取。算法的设计保证了高准确率和实时性,能够满足零件柔性装配[10]的需求。
