基于反双曲正切函数的变步长LMS 算法
2022-10-26火元莲安娅琦巩琪连培君
火元莲,安娅琦,巩琪,连培君
(西北师范大学 物理与电子工程学院,甘肃,兰州 730070)
随着信息处理技术的快速发展,自适应滤波器作为一种有效的信号处理工具[1],能够在没有任何相关统计知识的情况下通过某种递归算法对参数进行自适应调整[2-3],使得系统达到最优性能.
最小均方算法(least mean square,LMS)最早是由WIDROW 和HOFF 在1959 年提出的[4]. 由于该算法原理简单、参数少、收敛速度较快且易于实现,因此被广泛的应用在波束形成[5-6]、回波消除[7]和系统辨识[8]等方面. 为了解决传统LMS 算法中快收敛速度和低稳态误差这一矛盾,提出了变步长LMS 算法.其主要思想就是让步长u(n)随着算法自适应调整,以确保步长变化符合算法收敛要求.
对于步长改进的方法,其中最主要的就是利用函数来建立误差和步长之间的非线性关系,如对数函数[9],双曲正切函数[10-12],反正切函数[13-14]和箕舌线函数[15-16]等. 除此之外,许多学者还根据步长函数应具有的函数特性,通过对常见函数进行改进来塑造新的表达式,以此建立误差和步长之间的关系. 陈康[17]提出了基于反双曲正弦函数的变步长LMS 自适应均衡算法,使得步长因子u(n)能够跟随误差信号e(n)动态变化,但其收敛速度和稳态误差有待进一步优化. 仝喜峰等[18]和吴瑶等[19]是在Sigmoid 函数基础上改进的,仝喜峰等[18]是通过对Sigmoid 函数进行变换且引入参数调节所得的函数式构建u(n)和e(n)的非线性函数关系,克服了SVSLMS 算法在收敛阶段步长变化过快的弊端. 吴瑶等[19]是以sigmoid 函数为原型设计了一个调节函数,并与基于Sigmoid 函数的变步长最小均方算法相乘得到非线性函数关系式,该算法进一步兼顾了收敛性和稳态性. 张继荣等[20]结合基于对数函数和基于正态分布函数的变步长LMS 算法的优点,提出新的步长参数调整公式,该算法相比前两者能够达到更快的收敛速度和更高的收敛精度,但在系统发生时变时,算法性能会被影响.
基于变步长算法的主要思想,并结合反双曲正切函数曲线的变化特性. 本文提出了一种新的变步长LMS 算法,基于反双曲正切函数来构造步长与误差之间的非线性关系式. 最后在系统辨识、信号去噪和信号预测方面对本文算法的性能进行了评估.
1 LMS 算法基本原理
自适应滤波器原理如图1 所示. 其中,x(n)代表n时刻的输入信号,y(n)代表自适应滤波器n时刻的输出信号,d(n)代表n时刻的期望信号. 通过期望信号d(n)与滤波器输出信号y(n)的差值e(n)来自适应的调节滤波器的参数,使下一时刻的输出y(n+1)能够更加接近期望信号.w(n)代表n时刻自适应算法得到的滤波器加权系数.
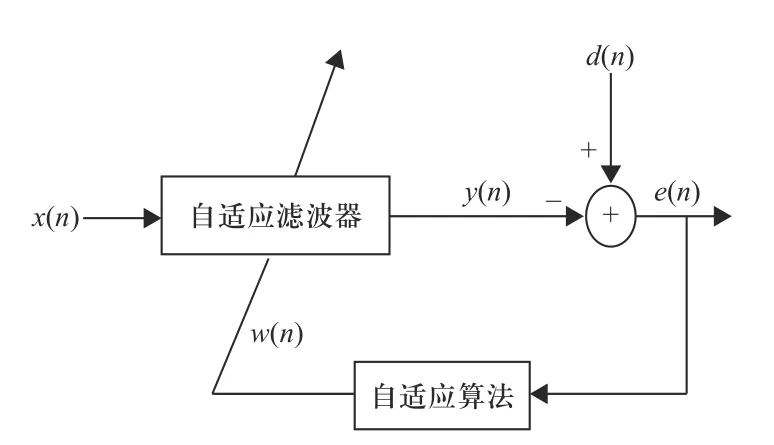
图1 自适应滤波器原理图Fig. 1 Schematic diagram of adaptive filter
LMS 算法的具体步骤如表1.

表1 LMS 算法步骤Tab. 1 LMS algorithm steps
其中X(n)=[x(n),x(n-1),···,x(n-L+1)],W(n)=[w(n),w(n-1),···,w(n-L+1)]分别是实际输入向量和滤波器权系数向量,L表示滤波器长度,u表示固定步长.
算法收敛的条件为步长因子u满足:

其中,λmax为自适应滤波器输入信号自相关矩阵的最大特征值.
2 改进的变步长LMS 算法
2.1 算法原理
为了满足算法设计的关键,兼顾收敛速度、稳态误差和跟踪性能,本文以反双曲正切函数的特性以及其曲线图为基础,通过对该函数的分析以及操作处理,使其函数曲线变化符合自适应滤波算法步长因子的调整原则. 反双曲正切函数表达式为
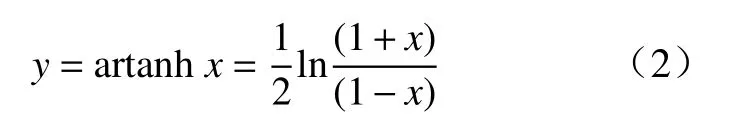
该函数的定义域为(-1,1),它是奇函数,在区间(-1,1)内单调增加. 其图像如图2 中曲线1 所示.
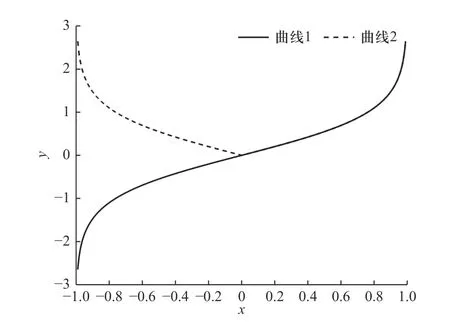
图2 反双曲正切函数及调整过程中的非线性函数曲线Fig. 2 Inverse hyperbolic tangent function and nonlinear function curve during adjustment
对式(2)中的自变量取绝对值,所得函数式为

式(3)的函数图像为图2 中的曲线2,由图可知,该曲线符合算法步长的调整机制,其斜率随着自变量的增大逐渐减小,意味着步长在收敛初期取值较大,在收敛完成期间取值较小,并在误差接近零时缓慢调整. 因此利用式(3)建立步长与误差之间的关系式为
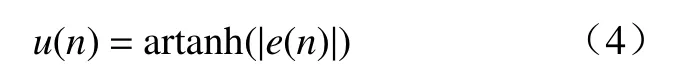
为了更好地控制函数形状,在式(4)中引入参数α , β 和 γ,得到新的步长函数表达式为
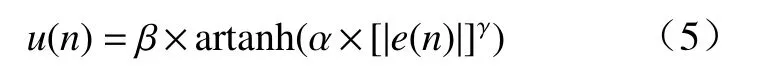
式中: α 和 β为控制函数幅值的参数; γ为控制函数曲线形状的参数.
因此,本文算法的迭代公式为

2.2 参数选择
为了明确新的步长函数式中参数 α 、 β 和 γ对算法收敛性、稳定性和抗干扰能力的影响,下面分别讨论各参数的取值对算法性能的影响,以此选择最优参数. 仿真软件采用Matlab2018,仿真条件参照文献[14]设定:1)自适应滤波器为二阶线性滤波器;2)未知系统的滤波器初始权值为W=[ 0.8 0.5 ]T,在第500 个采样点时刻变为W=[ 0.4 0.2 ]T;3)自适应滤波器输入信号X(n)为均值为0、方差为1 的高斯白噪声;4)干扰噪声v(n)为均值为0、方差为0.000 1 的高斯白噪声;5)输入信号X(n)和干扰噪声v(n)互不相关. 令采样点数为1 000,进行200 次仿真实验,统计其平均值画出学习曲线.
图3 为当 α=0.02, γ=0.1 时, β分别取0.1,1,3,5时的步长u(n)和误差e(n)以及迭代次数n和均方误差MSE 之间的关系曲线图. 由图3(a)可知,当误差e(n)相同时,随着 β取值的增大,曲线在收敛初期的斜率增大,即算法的收敛速度加快,但超过一定的值后,虽然算法收敛速度仍有显著提升,但收敛后步长的调整变化也会增大,这会降低算法的稳定性. 参考图3(b),当 β取0.1 时,算法在迭代500 次时还未收敛. 当 β取值大于1 时,虽然最终收敛的稳态误差相同,但收敛速度有所不同:当 β取1 时,算法在迭代100 次左右时达到收敛;而当 β取3 或5 时,在迭代次数为30 左右的时候,算法就已经达到收敛状态. 因此,综合考虑各方面因素,最终选择 β=4.
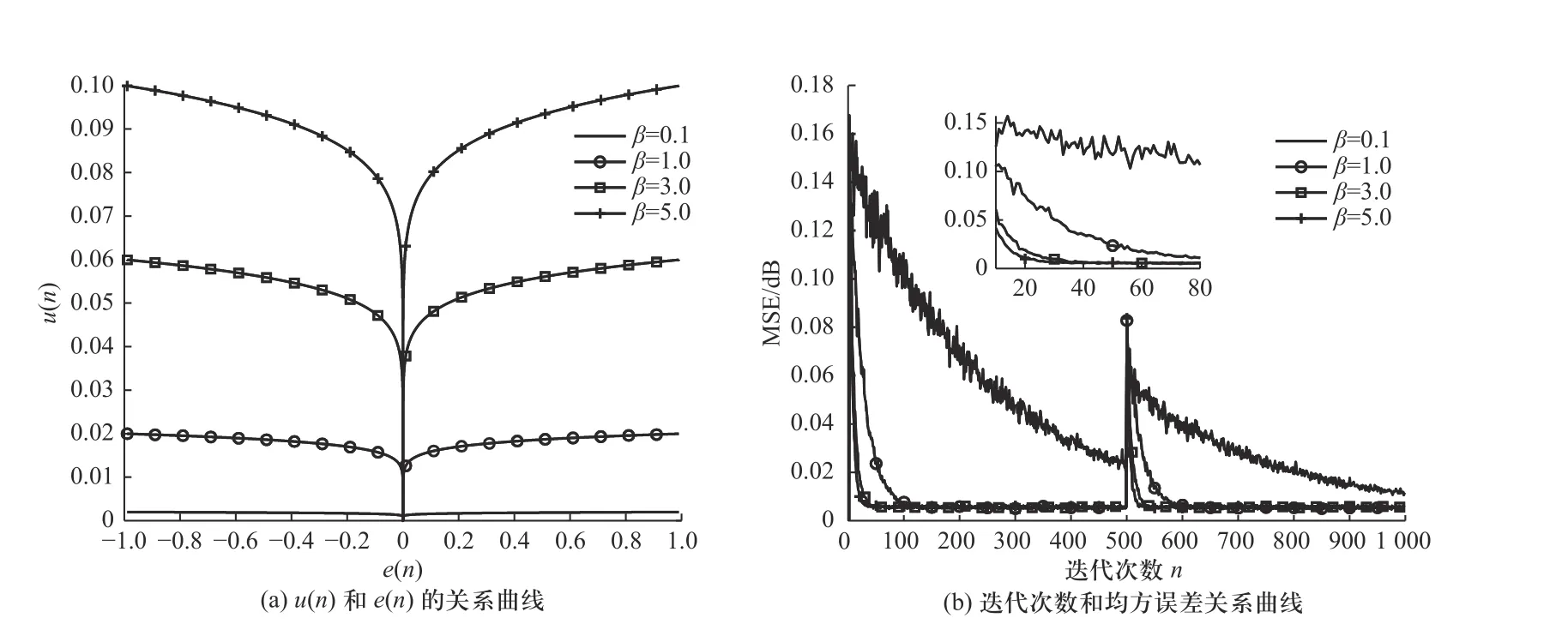
图3 参数 β变化时步长和误差以及迭代次数和均方误差曲线Fig. 3 The step length and error, the number of iterations and the mean square error curve when the parameter β changes
图4 为 β=4, γ=0.1 时,参数 α变化时的步长u(n)和误差e(n)以及迭代次数n和均方误差MSE 之间的关系曲线图, α分别取0.01,0.02,0.03,0.05. 由图4(a)可知,在相同误差下, α取值越大,算法收敛速度越快,但当 α取值超过某一定值时,算法收敛速度的增加是以牺牲稳定性为代价. 因此,对 α的取值还需要参考图4(b), α取值为0.01 时,算法在迭代60 次左右时才完成收敛;而当 α取0.02,0.03 和0.05 时,算法都是在迭代次数为30 左右的时候,达到收敛状态,但随着α取值的增大,算法的稳态误差也会增大,且当 α取值大于0.05 时,该算法发散不收敛. 综合考虑图4(a),最终选择 α=0.02.
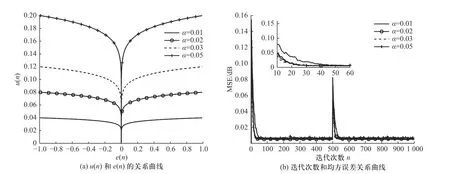
图4 参数α 变化时步长和误差以及迭代次数和均方误差曲线Fig. 4 The step length and error, the number of iterations and the mean square error curve with the change of parameter αchanges
固定 α=0.02, β=4,取 γ分别为0.01,0.1,0.4,0.7 时的步长u(n)和误差e(n)以及迭代次数n和均方误差MSE 之间的关系曲线图如图5 所示. 分析图5(a)可知, γ取值越大,步长会在误差较大时下降到一个较小的值,进而会导致系统的收敛速度变慢;当 γ越小时,步长调整变化越小,这个特性会使算法在收敛阶段的稳定性增强,但较小的 γ却不能为算法在收敛初期提供较大的步长来使算法的收敛速度加快. 由图5(b)可知,当 γ取0.01 和0.1 时,学习曲线几乎重叠,但随着 γ的持续增加,收敛速度会下降且稳态误差增加.因此,综合考虑选择 γ=0.1.
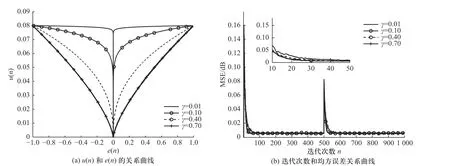
图5 参数 γ变化时步长和误差以及迭代次数和均方误差曲线Fig. 5 The step length and error, the number of iterations and the mean square error curve with the change of parameter γchanges
综上,新的步长调整函数式(7)中的参数 α 和 β是控制步长取值范围的参数, γ是在步长接近0 时,控制稳态均方误差范围的参数. 最终,文中取参数 α=0.02, β=4, γ=0.1.
2.3 算法抗干扰性分析
噪声和干扰都会对LMS 算法的稳定性产生影响,因此衡量算法性能的好坏时,抗干扰性和稳定性也应该被考虑到. 由式(6)可得
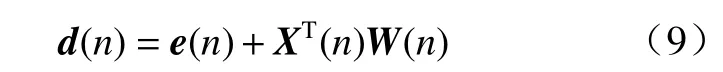
期望信号d(n)也可以表示为另一种形式.
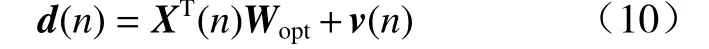
其中,v(n)为干扰噪声,一般是与输入信号无关的均值为零的白噪声;Wopt为最优权系数向量;令ΔW=Wopt-W(n),可由式(9)和式(10)得

对式(11)两边求平方可得.
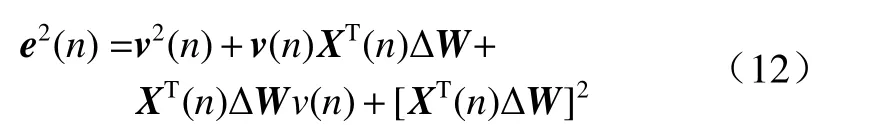
对式(11)和式(12)两边取期望, 并利用v(n)与输入信号无关且均值为0 的特性,化简整理可得
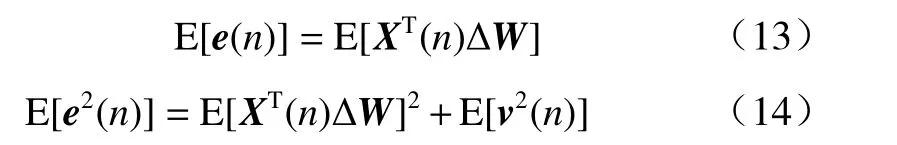
由式(13)可知,误差e(n)的均值不受干扰噪声v(n)的影响,只与输入信号相关,而误差e(n)平方的期望与干扰噪声相关,在干扰较大的时候,会严重的影响到算法的稳定性. 因此本文算法的步长函数与干扰噪声v(n)无关,即具有一定的抗干扰能力.
3 仿真实验
3.1 各变步长算法在系统辨识中的性能对比
为了检验本文所提算法的性能,将其与几个较新的变步长LMS 算法进行比较,其中各比较算法的步长函数如下.
文献[17]提出的基于反双曲正弦函数的变步长函数为
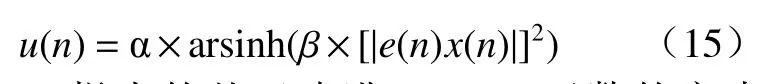
文献[18]提出的基于改进Sigmoid 函数的变步长函数为
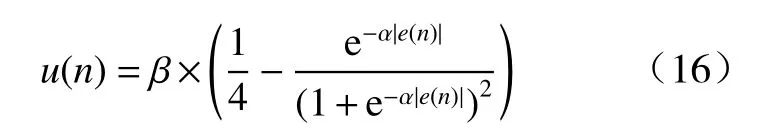
文献[19]提出的在Sigmoid 函数基础上添加调节函数的表达式为

文献[20]提出的基于改进对数函数的变步长表达式为
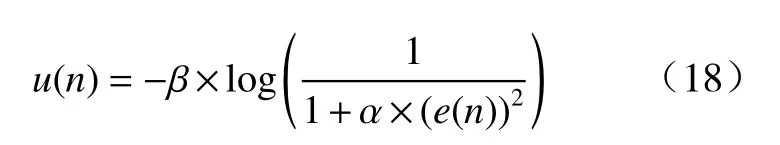
实验仿真环境设置同3.2 节参数选择中的一致:自适应滤波器为二阶线性滤波器,未知系统的滤波器初始权值为W=[ 0.8 0.5 ]T,在第500 个采样点时刻变为W=[ 0.4 0.2 ]T,自适应滤波器输入信号X(n)为均值为0、方差为1 的高斯白噪声,干扰噪声v(n)为均值为0、方差为0.000 1 的高斯白噪声;输入信号X(n)和干扰噪声v(n)互不相关. 令采样点数为1 000,做200 次仿真实验,对比各算法的性能.
在该仿真环境下,通过相同的实验得到上述各个算法的最优参数,如表2 所示,各算法的对比学习曲线如图6 所示.

表2 干扰噪声方差为0.000 1 时各算法参数选择Tab. 2 Selection of algorithm parameters when the variance of interference noise is 0.000 1
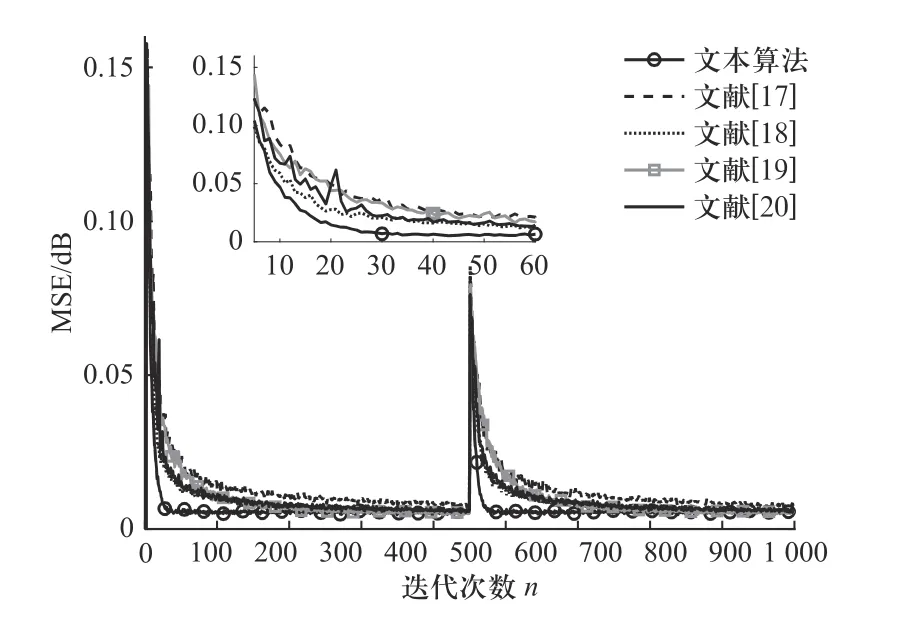
图6 干扰噪声方差为0.000 1 时各算法性能比较Fig. 6 Performance comparison of different algorithm in 0.000 1 interference noise variance
分析图6 可知,本文算法在迭代30 次左右时达到收敛,且收敛后的稳态误差在0.006 左右. 相较于文献[17]中的算法在迭代300 次左右时稳态误差为0.016,无论是在收敛速度还是稳态误差方面,本文算法的效果都明显优于文献[17];而文献[18]、文献[19]和文献[20]的算法几乎都是在迭代300 次左右时达到0.016 的稳态误差,虽然与本文算法稳定收敛后的稳态误差比较相近,但收敛速度却较慢.
将噪声v(n)变为均值为0,方差为0.04 的高斯白噪声,此时,各算法的最优参数选择如表3 所示,学习曲线如图7 所示.
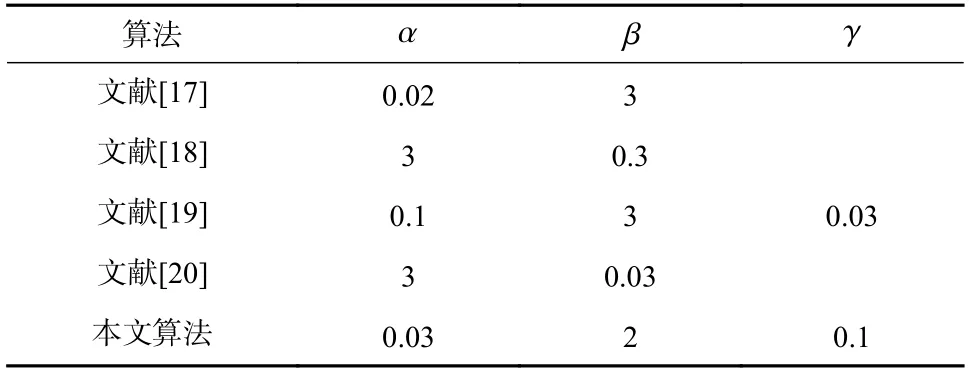
表3 干扰噪声方差为0.04 时各算法参数选择Tab. 3 Selection of algorithm parameters when the variance of interference noise is 0.04
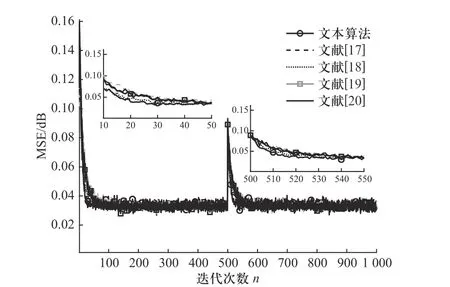
图7 干扰噪声方差为0.04 时各算法性能比较Fig. 7 Performance comparison of different algorithm in 0.04 interference noise variance
观察图7 可知,在本文算法和文献[17-20]所提出的算法稳定收敛后,所达到的稳态误差结果很相近,几乎都在0.032 左右;但本文算法具有较快的收敛速度,相比于它们在迭代50 次左右达到收敛,本文提出的算法在迭代30 次左右就已经完成稳定收敛.
综上所述,在系统辨识环境中,无论加入干扰噪声的方差为0.000 1 还是0.04,本文算法都能得到较好的效果.
3.2 正弦信号去噪
为了分析本文算法的滤波去噪能力,选择输入信号为s=15 sin(0.15 πt),其采样频率fs=1 000,加入信噪比为15 dB 的正态随机噪声,利用本文算法对其进行去噪处理,通过多次实验选择各参数的最优值,实验结果如图8 和图9 所示.
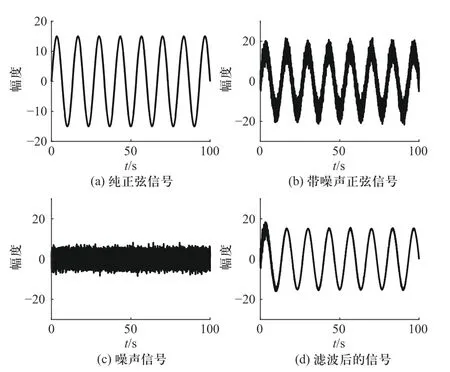
图8 正弦信号去噪结果图Fig. 8 The result of denoising sinusoidal signal
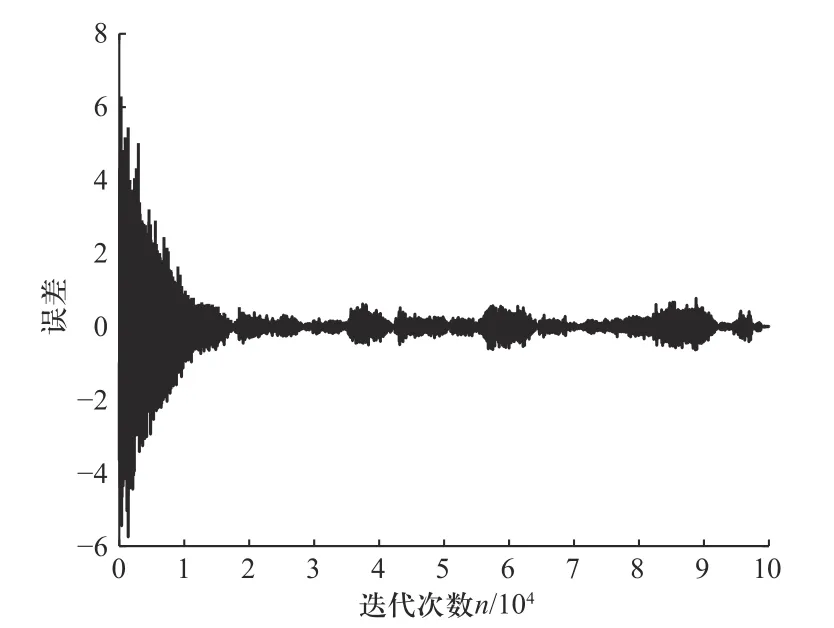
图9 带噪正弦、原始信号和滤波结果的对比图Fig. 9 Comparison of noisy sine, original signal and filtered result
由图8 可知,本文提出算法可用于正弦信号去噪,且通过图9 观察带噪信号、滤波结果和原始信号的对比,发现本文算法对于正弦信号去噪具有良好的效果.
3.3 自适应线性预测
由二阶AR 模型产生自适应滤波器的输入信号x(n),定义如下:
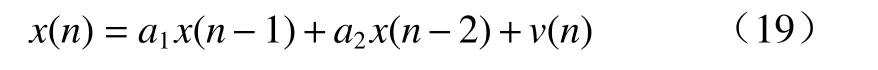
其中,a1=-1.6,a2=0.8,v(n)为零均值的高斯白噪声,二阶AR 模型如图10 所示.

图10 二阶AR 模型图Fig. 10 Second-order AR model diagram
得到输入信号x(n)后,通过二阶线性预测滤波器进行自适应线性预测,其框图如图11 所示.
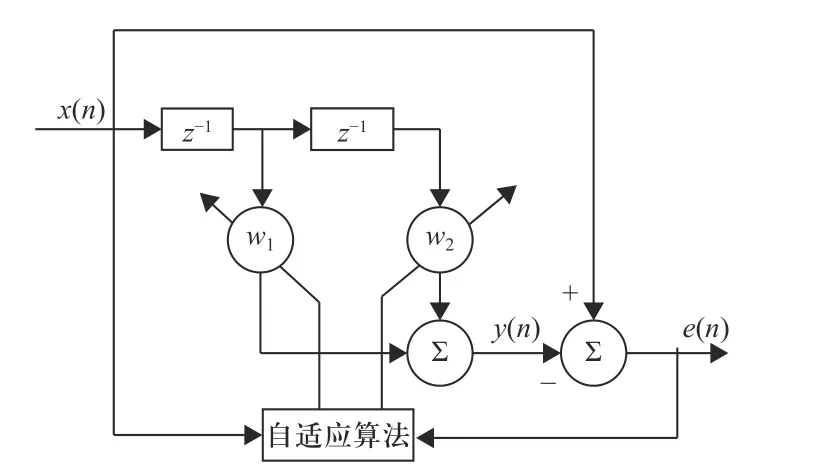
图11 自适应线性预测图Fig. 11 Adaptive linear prediction diagram
图11 中的自适应算法选用本文算法,各参数选择如下: α=0.03, β=2, γ=0.1;设第n次预测的权值向量为W(n)=[w1(n),w2(n)]H,数据长度N为600. 预测结果用权值w1(n),w2(n)的变化曲线以及误差的平方e2(n)的变化曲线表示,权值曲线取20 次预测结果的平均值,观察算法的收敛情况. 其结果如图12 所示.
由图12 可知,两个初始权值向量w1(n)和w2(n)分别从0 出发,经过200 次左右的迭代,两条收敛曲线都到达了最优值附近,而这时所产生的误差来源于输入信号中的v(n). 因此,考虑到输入信号的随机性,使用本文算法进行一定次数的迭代,无论初始权值向量从哪里开始取值,迭代后权值一定会收敛到最优权向量附近.
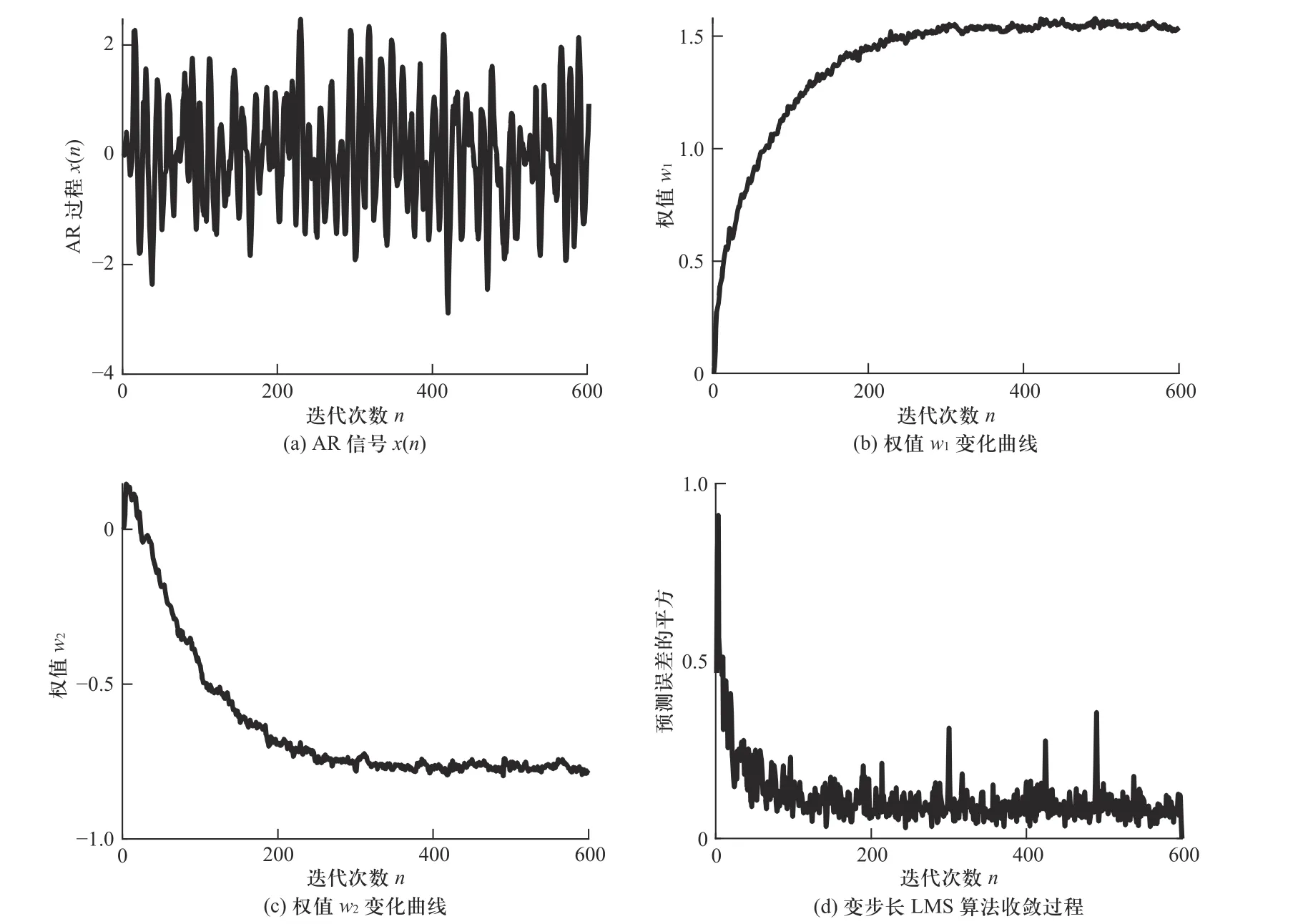
图12 自适应线性预测结果图Fig. 12 The result of adaptive linear prediction
4 结 论
针对定步长LMS 算法的局限性,本文以反双曲正切函数为基础建立步长与误差之间的非线性关系代替传统LMS 算法中的固定步长,实现了对步长因子的动态调整. 最后在系统辨识、正弦信号去噪和线性预测方面对该算法的性能进行了验证. 仿真结果表明,本文算法很好地兼顾了收敛速度、稳态误差和跟踪性能,在系统辨识方面比文献[17-20]的算法具有更优的性能,同时,在正弦信号去噪和线性预测方面的应用也说明了本文算法的有效性和适用性.
