基于GBDT算法的柴油机性能预测
2022-10-25陈天锴王贵勇申立中姚国仲
陈天锴,王贵勇,申立中,姚国仲
(昆明理工大学云南省内燃机重点实验室,云南 昆明 650500)
“2030实现碳达峰,2060年实现碳中和”意味着柴油机发展正处于一个挑战与机遇并存的时代,柴油机作为非道路工程机械与国防装备的主要动力,在各类先进技术引领下,朝着节能减排的目标迈进。各类新技术应用提高了柴油机的复杂程度,高度集成的ECU系统控制参数日益增加。柴油机作为一种多输入多输出、高复杂度与耦合度系统,难以用精确的物理与化学模型准确描述。柴油机性能预测通常采用热力学与流体力学结合经验公式进行建模,如GT-Power,AVL CruiseM,AVL Boost等,上述模型在仿真精度与仿真时间上往往是矛盾的,且建模需要大量发动机参数与试验数据,时间与经济成本较高。
近年来,在跨学科领域融合的趋势下,兴起了使用机器学习来解决各领域前沿问题的热潮,其理论和方法已被广泛应用于解决工程应用和科学领域的复杂问题,在分类与回归预测方面具有极高的性能。文献[6]对比了热力学模型与机器学习方法性能预测的精度。神经网络在发动机有效燃油消耗率(BSFC)和NO预测方面精度更高,且计算所需时间较短。在硬件在环研究与柴油机参数虚拟标定研究问题上,机器学习预测模型具有准确度与精度高、时间与经济成本少,易于结合遗传算法等优化方法等特点。
在柴油机性能预测方面,目前研究主要采用ANN(Artificial Neural Network,人工神经网络)和SVM(Support Vector Machine,支持向量机)方法。国内外学者使用ANN、SVM等多种机器学习方法进行了柴油机经济性、排放性预测的研究。研究表明,ANN和SVM在BSFC、热效率、CO、HC和NO预测上都具有优秀的性能,各方法拟合程度在0.823~0.994之间。
虽然ANN和SVM在处理复杂非线性柴油机系统问题中具有优越的性能,但也暴露出一些问题。ANN存在学习收敛速度慢、训练容易陷入局部极小值非最优解、网络模型泛化能力差,针对不同发动机机型适用性差,神经元与网络层数难以确定等问题。SVM泛化能力强,但性能受核函数与参数影响较大。两种模型均需要对构造函数与模型参数进行大量调试与计算寻优。国内外学者通过结合遗传算法等方式尝试改进ANN和SVM,目前也取得了一定进展。
文献[23]基于汽车、医学、农业等不同领域的71个数据集比较了多种机器学习算法的预测性能,在研究中发现GBDT(Gradient Boosting Decision Tree,梯度提升决策树)在预测性能上优于支持向量机,同时在预测效率方面是最快的算法。
GBDT是一种基于梯度下降的优秀机器学习算法,在多元非线性回归问题方面有较高的精确度与稳定性。目前,该算法还较少应用于发动机领域。GBDT算法可有效处理混合类型特征与参数缺失值,对异常数据具有鲁棒性,可扩展性强,可并行计算,是一种解决柴油机类复杂黑箱系统问题的全新思路。本研究基于GBDT算法,对1台4缸高压共轨柴油机进行建模分析与性能预测,为发动机性能预测提供了一种行之有效的方法。
1 试验设备及试验设计
1.1 试验装置
试验采用配备涡轮增压器的某4缸高压共轨柴油机。发动机具体参数见表1。进气中冷采用流量可控的水冷却,试验台架如图1所示。主要测试设备及参数如表2所示。
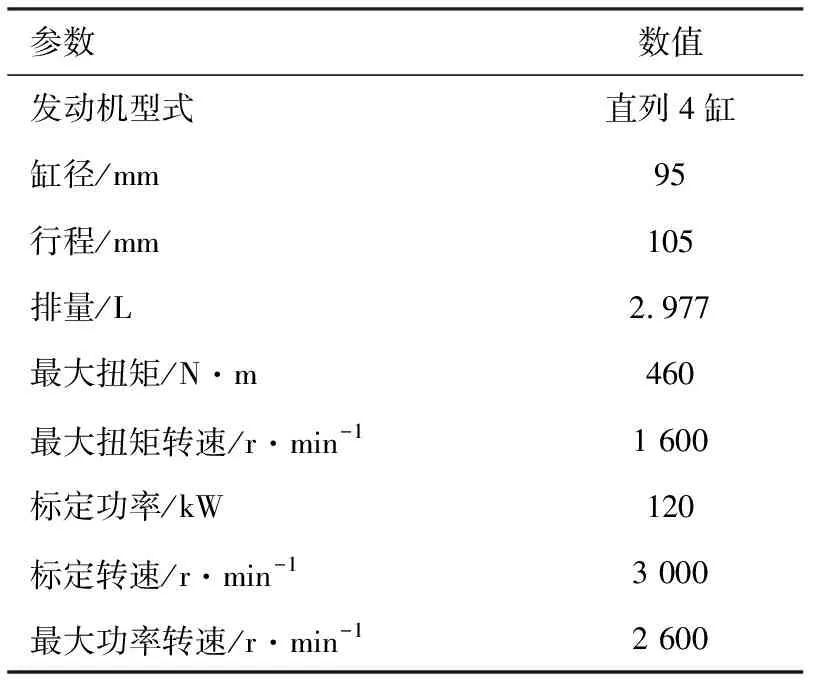
表1 发动机主要技术参数
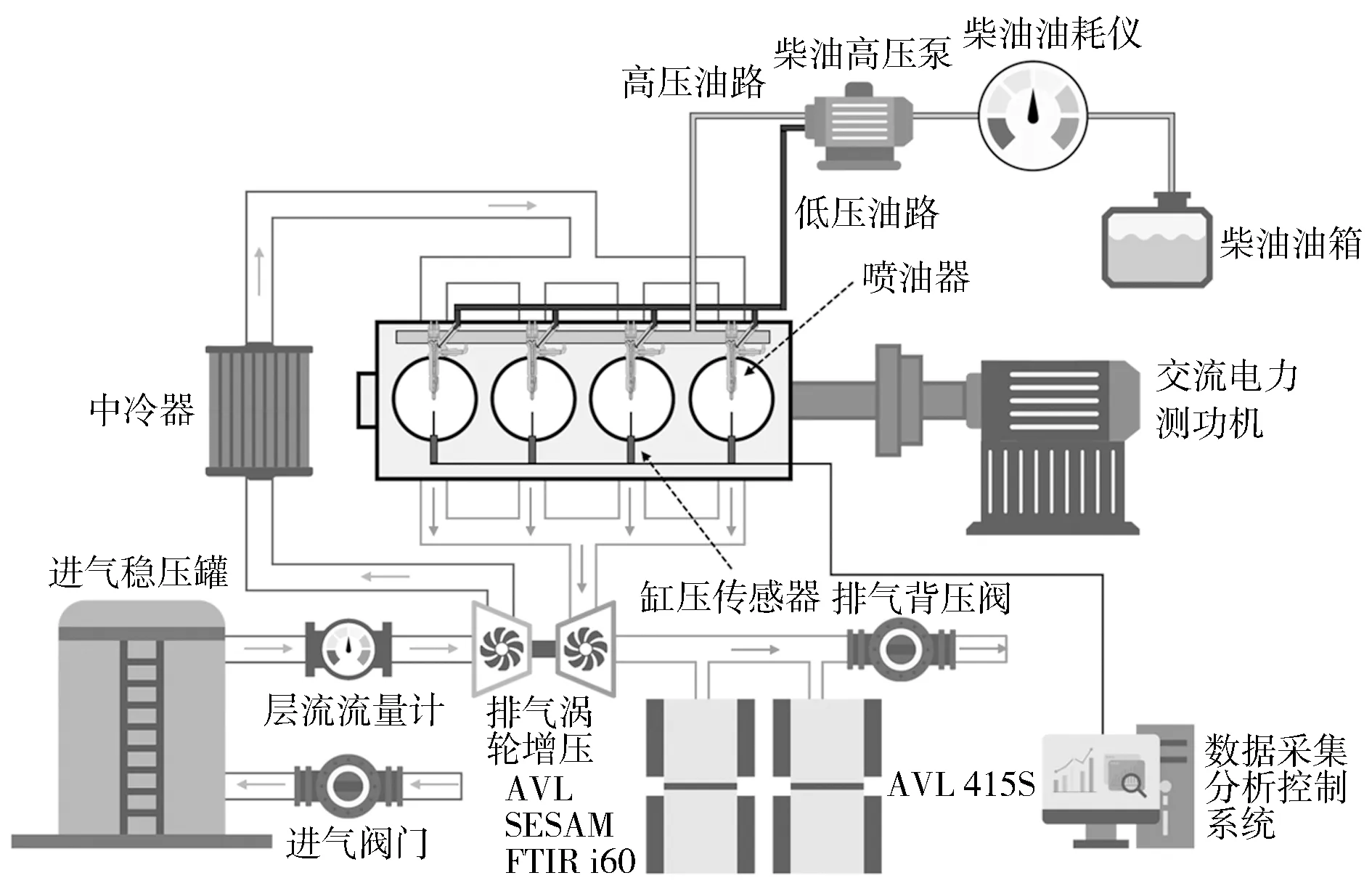
图1 柴油机台架示意
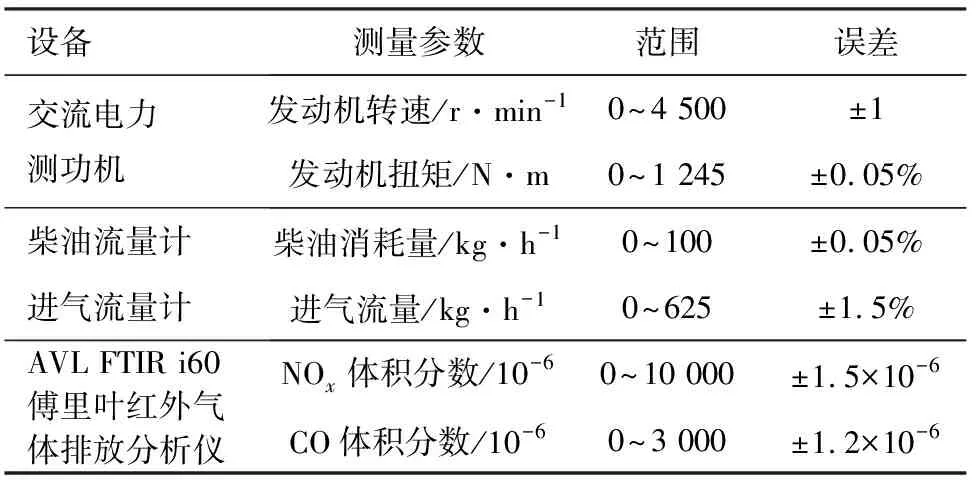
表2 测试设备参数
1.2 空间填充设计
采用试验设计(Design of Experiment,DoE),通过最少的试验次数来获得最大的发动机有效信息量,避免重复试验,缩短试验周期,降低试验成本。试验设计点的分布原则:在试验空间内试验点应均匀分布且正交,避免不同试验点携带重复的试验数据,试验点能有效提供周边空间的信息。
有效的试验设计决定了柴油机性能预测模型特征输入数据量,直接影响模型预测精度和拟合程度。空间填充试验设计基于疏密相等原则,通过数学方法将试验点均匀填充于试验空间中,保证试验次数与有效数据量的平衡。空间填充设计适用于任意维度的试验空间,其试验点生成仅与约束条件形成的样本空间有关,不会受到柴油机真实性能与建模方法的影响。基于Sobol Sequence空间填充算法得出柴油机试验填充空间。利用该方法得到的测试数据点具有高均匀性、可重复、独立特征参数生成等特点,极大增加了训练数据试验组中输入因素水平,保证获取最大试验信息量。
对于生成个影响因素的次数Sobol Sequence填充,记第个特征矩阵为=(,,…),则生成多项式组为

(1)

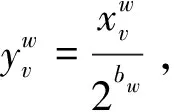
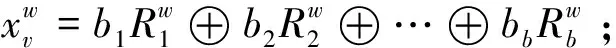
(2)

(3)
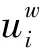
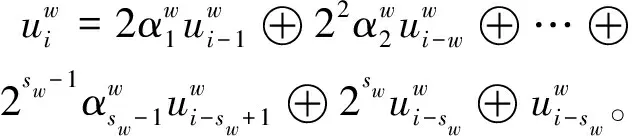
(4)
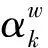
选取转速、扭矩、主喷正时、预喷正时、预喷油量为特征参数,BSFC经济性参数、NO和CO排放参数为响应参数。为保证模型在发动机运行范围内均具较高精度,试验数据均匀分布且覆盖900~3 000 r/min,20%~100%负荷范围。
基于Sobol Sequence算法生成640组试验矩阵。根据台架去除部分不合理试验组,最后实际特征组为574。采用GBDT算法进行柴油机性能预测是一次全新的尝试,目前研究中,采用机器学习方法建立高精度预测模型试验数据量为100~600组。为研究训练数据量与模型准确度关系,进行了尽可能多的试验以保证模型搭建成功,同时,大量试验数据也可用于研究训练数据量对模型精度的影响。其次,为了将GBDT模型应用于柴油机ECU硬件在环及虚拟标定研究,模型需要同时满足实时性与精度要求,为尽量提高模型精度以便于后续研究,避免因试验误差造成的影响,采用了574组工况试验数据进行训练预测。而在实际建模过程中,约100组试验数据即可达到较高模型精度,如图2所示,因此,GBDT柴油机预测模型实际只需要较少的数据量便可建模,且精度较高。

图2 试验数据量与模型拟合程度关系
2 GBDT建模算法
2.1 GBDT算法
GBDT梯度提升决策树算法是目前较为先进的机器学习策略之一,本质为一种优秀的Boosting集成学习算法,广泛运用于分类、回归问题和推荐系统。通过结合决策树与Gradient Boosting算法,在每次迭代过程中通过梯度下降减少损失,将弱学习器决策树集成进行迭代提升为强学习器。每个决策树在前一个决策树基础上进行学习,最后综合所有决策树的预测值产生最终结果。GBDT算法在回归与分类问题上具有优异的性能。
GBDT算法表达式为

(5)
式中:为发动机训练样本点;为GBDT算法模型参数;为回归决策树;为每棵决策树的权重系数。为第棵子回归决策树(=0,1,…)。
给定柴油机试验数据训练集:
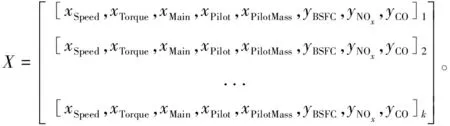
(6)
式中:为转速特征参数;为扭矩特征参数;为主喷正时特征参数;为预喷正时特征参数;为预喷油量特征参数。特征空间边界条件由真实发动机参数可控范围定义。为BSFC特征参数;NO为NO特征参数;为CO特征参数。
迭代模型为
()=-1()+。
(7)
式中:-1()为上一代迭代模型;为本轮迭代决策树;为本轮迭代后模型。
初始化父节点决策树():
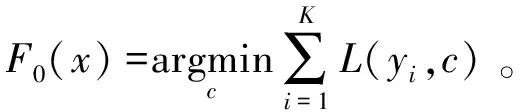
(8)
式中:为使父节点决策树损失函数最小的值。迭代生成子节点决策树=0,1,…。损失函数为(,())。
对于=1,2,…,计算第棵决策树对应的损失函数负梯度残差:

(9)
式中:为负梯度残差。对于=1,2,…,利用CART(Classification And Regression Tree)回归树拟合数据(,,),得出第棵回归树,其对应的叶子节点区域为,,其中=1,2,…,为第棵回归树叶子节点个数。
对于个叶子节点区域=1,2,…,计算出拟合值:

(10)
更新强学习器:

(11)
得出GBDT强学习器表达式为

(12)
2.2 模型参数寻优
GBDT柴油机模型建立后,需对loss(损失函数),learning_rate(决策树权重缩减系数),n_estimators(决策树最大迭代次数),subsample(决策树子采样比例),max_depth(树节点最大深度)等参数调优,以更好地拟合柴油训练集数据,提高模型训练速度与预测精度,防止弱拟合与过拟合。
基于柴油机训练数据集数据量,采用GridSearchCV网格搜索算法,通过网格搜索和交叉验证,采用指定步长遍历优化参数空间,得出最优模型参数组合。
3 模型验证
将试验数据集的80%划分为训练集,20%划分为测试集。为提高模型精度,采用K折交叉验证对原始柴油机数据进行划分。将柴油机数据集随机划分为5份,每次选取4份进行训练,剩余1份作为测试集,重复5次,取5次准确率均值作为模型评价指标。K折交叉验证可以防止小数据集造成的模型欠拟合,同时避免模型超量迭代造成过拟合。
对GBDT模型进行多次迭代训练后,基于5折交叉验证测试集计算模型的RMSE(Root Mean Square Error,均方根误差)、MAE(Mean Absolute Error,平均绝对误差)、(R-Square模型决定系数)、MRE(Mean Relative Error,平均相对误差)评价指标。
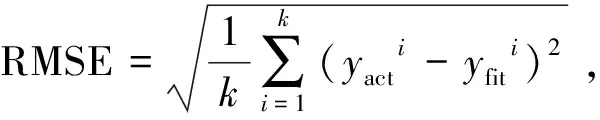
(13)
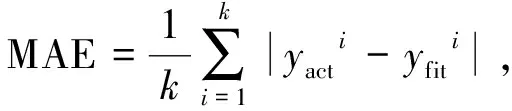
(14)
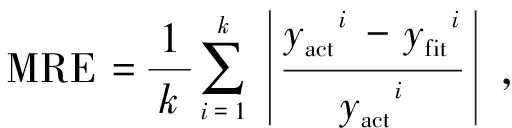
(15)
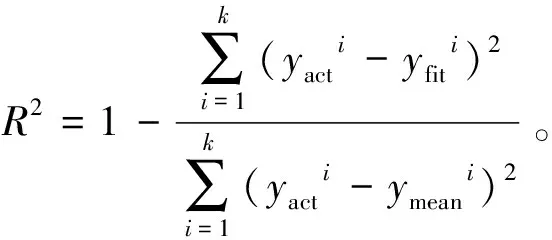
(16)
式中:为真实值;为预测值;为实际响应的平均值。
3.1 模型评估
仿真平台参数为CPU-AMD 3600X,GPU-RX580。模型代码基于Python3.8实现。图3示出模型训练迭代收敛曲线。可以看出,在迭代次数24次时,预测模型拟合程度已经高于90%,模型训练、验证和预测计算总时间为0.071 s,迭代次数在105次时模型超过95%,计算时间0.096 s。可见模型收敛速度较快,用时较少。

图3 模型训练迭代R2收敛曲线
将测试集数据BSFC,NO,CO真实值与模型预测值进行对比验证。
图4至图6分别示出BSFC,NO,CO预测值回归验证。从图中可以看出,测试集模型BSFC,NO,CO预测值均处于95%置信区间中,测试点密集分布于回归线=附近,模型敏感性和可信度较高,对BSFC,NO,CO输出具有良好响应。=0.981,NO=0.993,=0.992。决定系数表征模型拟合程度,反映预测值[,NO,]浮动受预测模型输入影响程度,即表示BSFC,NO,CO响应值变异中百分比受特征变量[,,,,]控制。取值为(0,1),越接近1,模型拟合程度越高。通过对112组测试集进行预测,可以看出模型整体离散程度密集,预测精度高,具有较高的稳定性。

图4 BSFC回归测试集验证
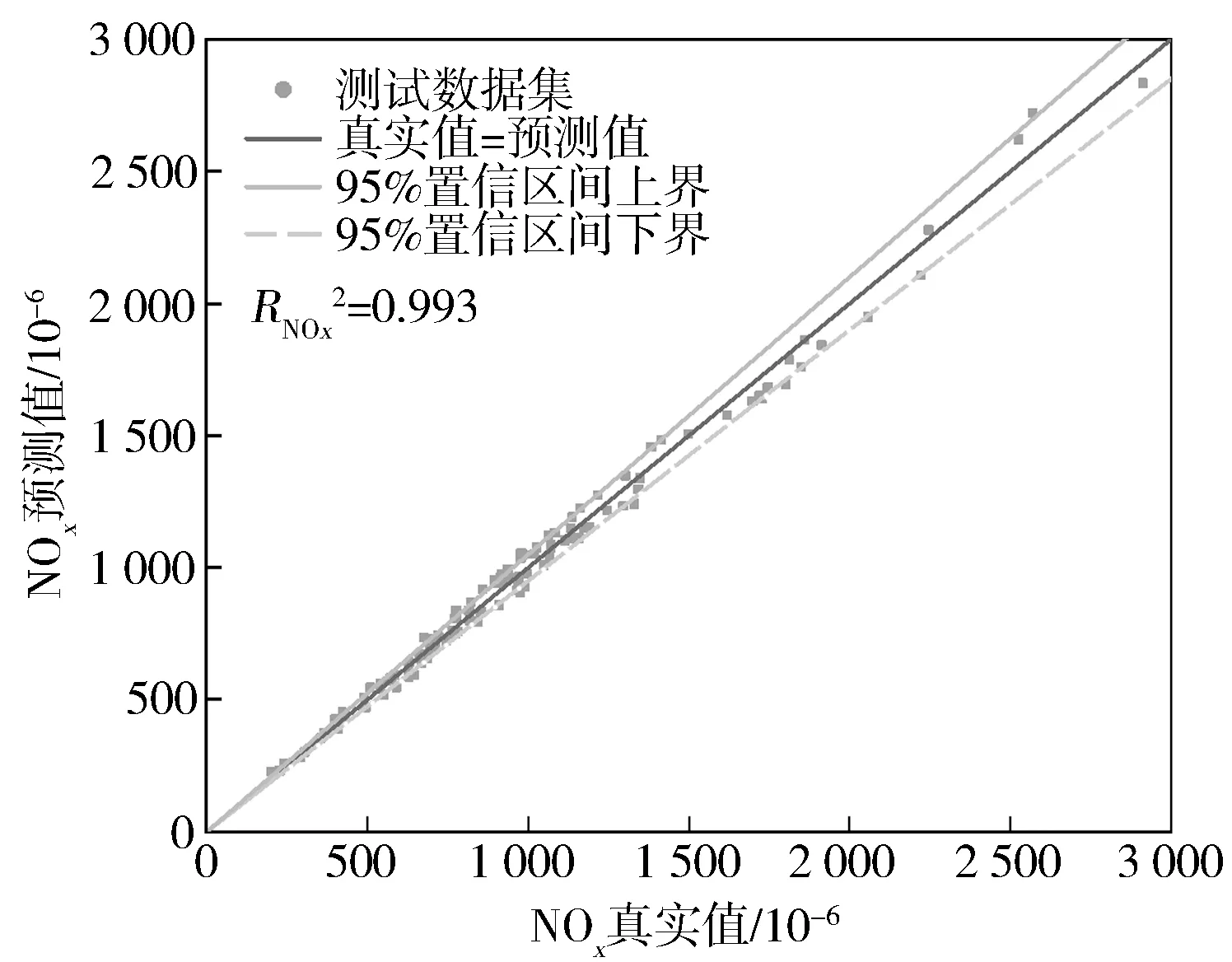
图5 NOx回归测试集验证
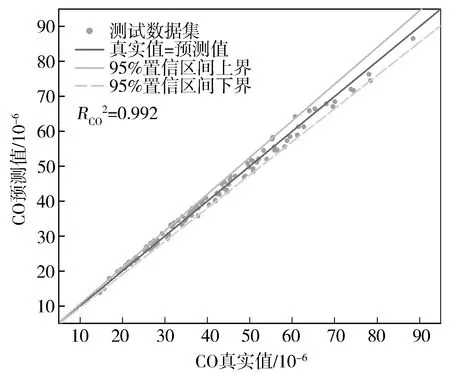
图6 CO回归测试集验证
图7至图9分别示出模型BSFC,NO,CO预测值与真实值的拟合程度对比。从图中可以看出,BSFC,NO和CO预测值均具有较高拟合程度,跟随程度高,预测值与柴油机真实输出趋势一致,在准确度与趋势上均能满足要求。可见GBDT模型能够准确预测该柴油机的BSFC,NO和CO数据。

图7 BSFC预测值与真实值对比
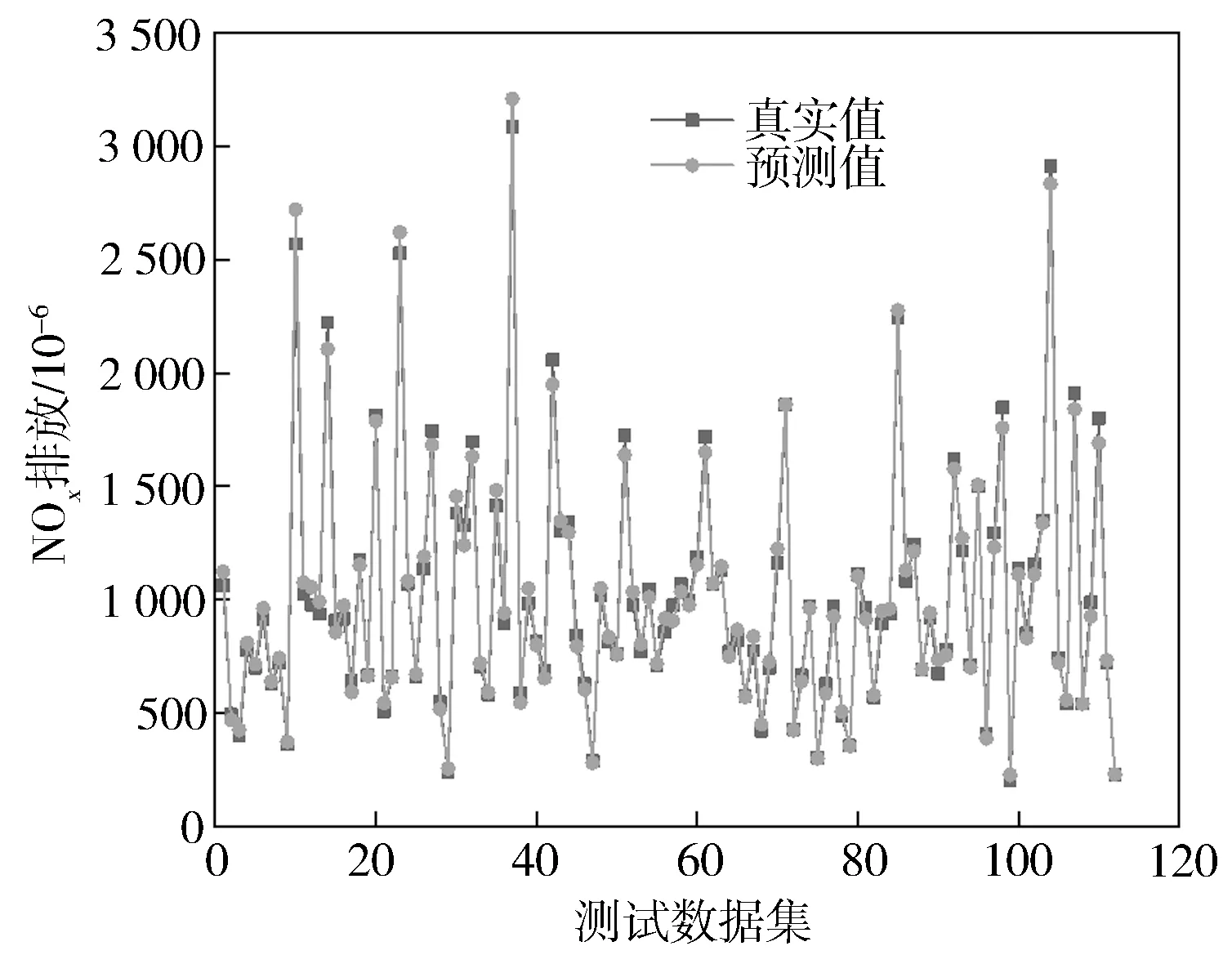
图8 NOx预测值与真实值对比
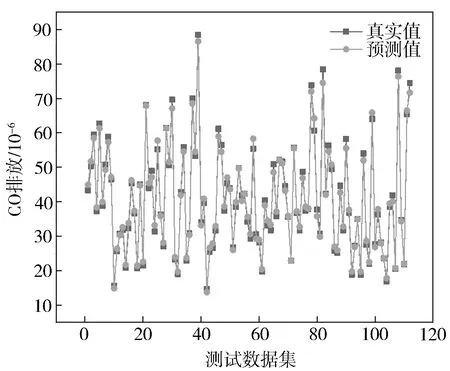
图9 CO预测值与真实值对比
图10至图12分别示出BSFC,NO,CO预测值相对误差分布。由图可知,模型相对误差分布波动较小。112组测试数据集中,BSFC预测值5个最大相对误差分别为3.82%,-3.63%,-3.18%,-3.01%,-2.83%,平均相对误差为0.81%;NO预测值5个最大相对误差分别为7.84%,-7.38%,7.37%,-7.01%,6.94%,平均相对误差为3.68%;CO预测值5个最大相对误差分别为-5.97%,5.80%,5.79%,5.68%,-5.32%,平均相对误差为2.95%。可见GBDT柴油机模型具有较高准确度与稳定性。
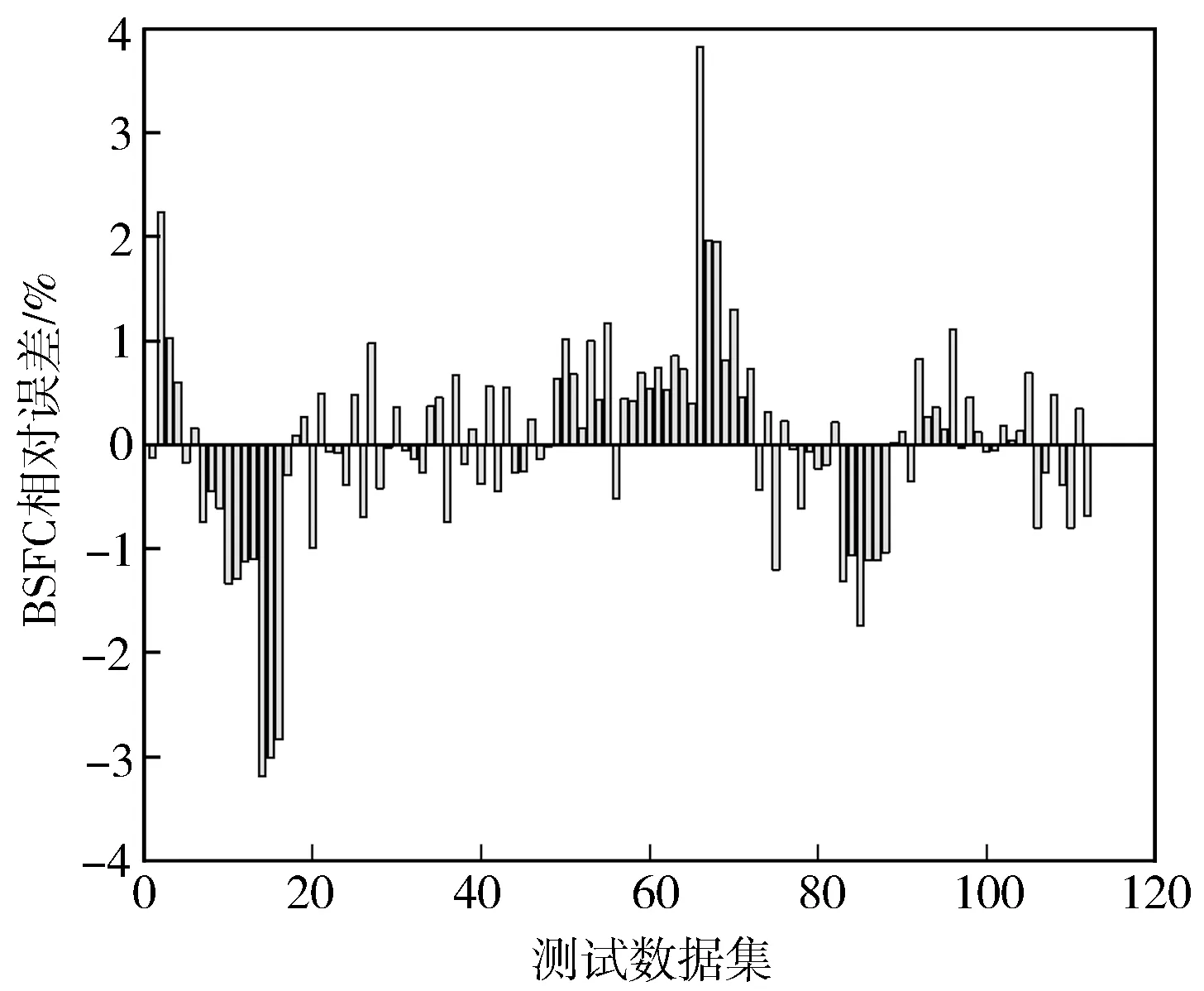
图10 BSFC预测值相对误差分布
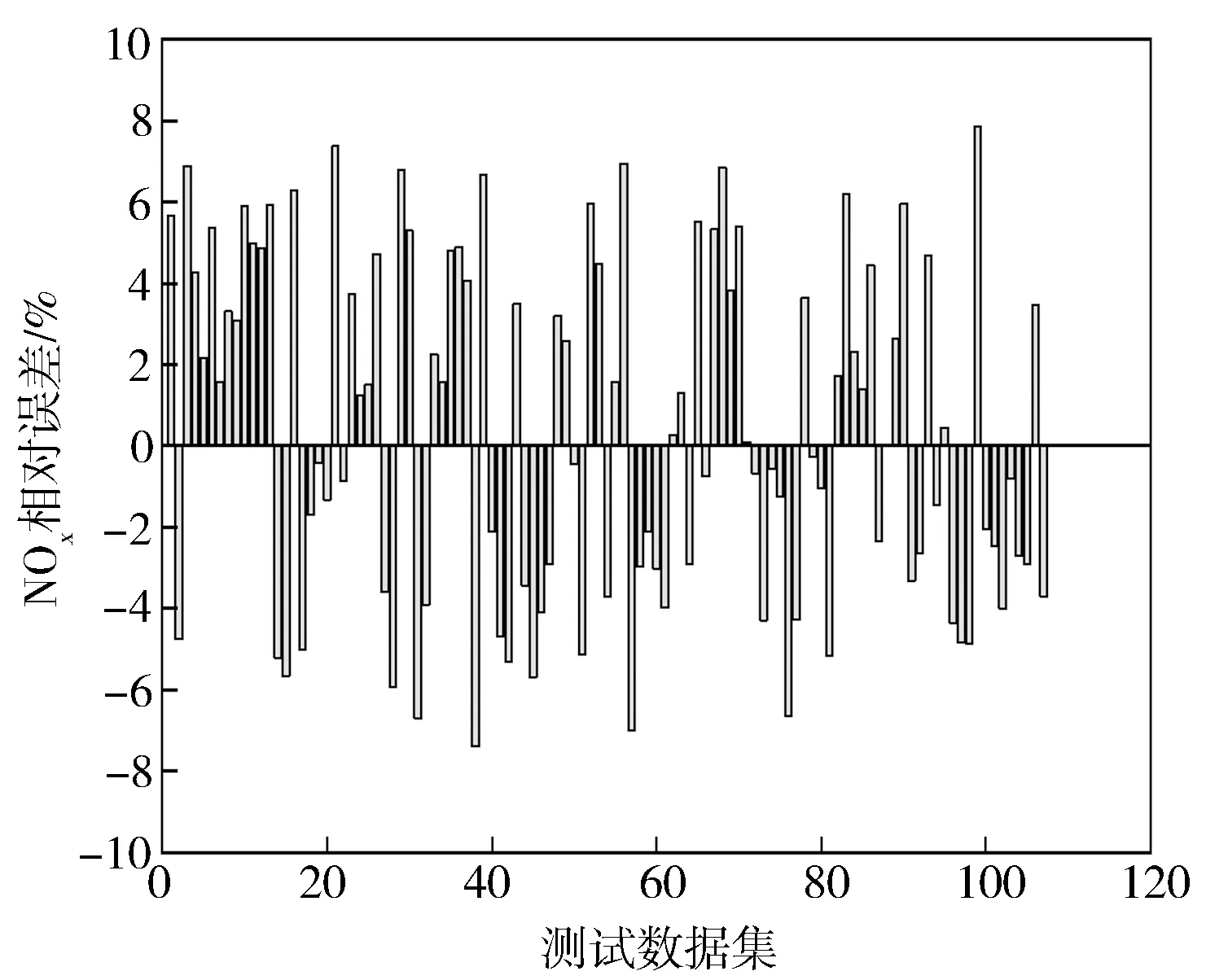
图11 NOx预测值相对误差分布
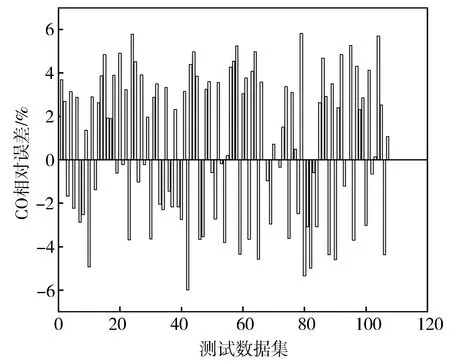
图12 CO预测值相对误差分布
模型性能评价指标如表3所示。可以看出,GBDT柴油机预测模型具有较高的可行性与可信度。

表3 模型性能评价指标
3.2 模型响应生成分析
将主喷正时、预喷正时、预喷油量MAP作为特征参数矩阵输入GBDT模型进行计算,得出基于转速和扭矩的BSFC,NO,CO响应图(见图13至图15)。通过将主喷正时、预喷正时、预喷油量固定为常量进行降维处理,每个转速和扭矩下喷油参数由原机MAP决定,得到基于转速和扭矩的BSFC,NO,CO预测值三维曲(见图16至图18)。基于少量试验数据点绘制原机真实物理响应图与预测曲面进行对比,可以看出,GBDT模型生成的BSFC,CO,NO响应过渡平滑,与真实数据高度拟合,变化趋势一致。
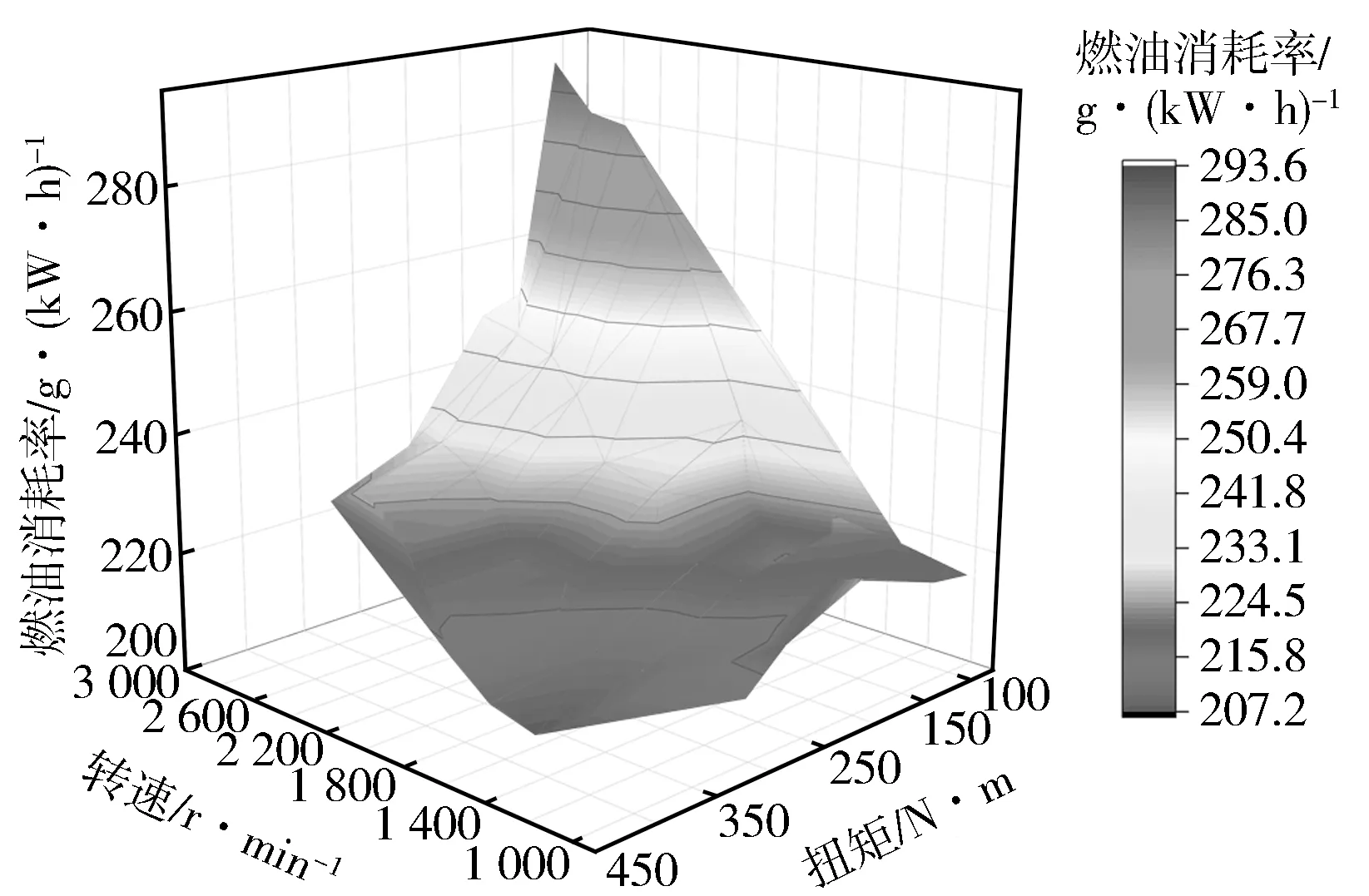
图13 BSFC试验数据插值响应

图14 NOx试验数据插值响应
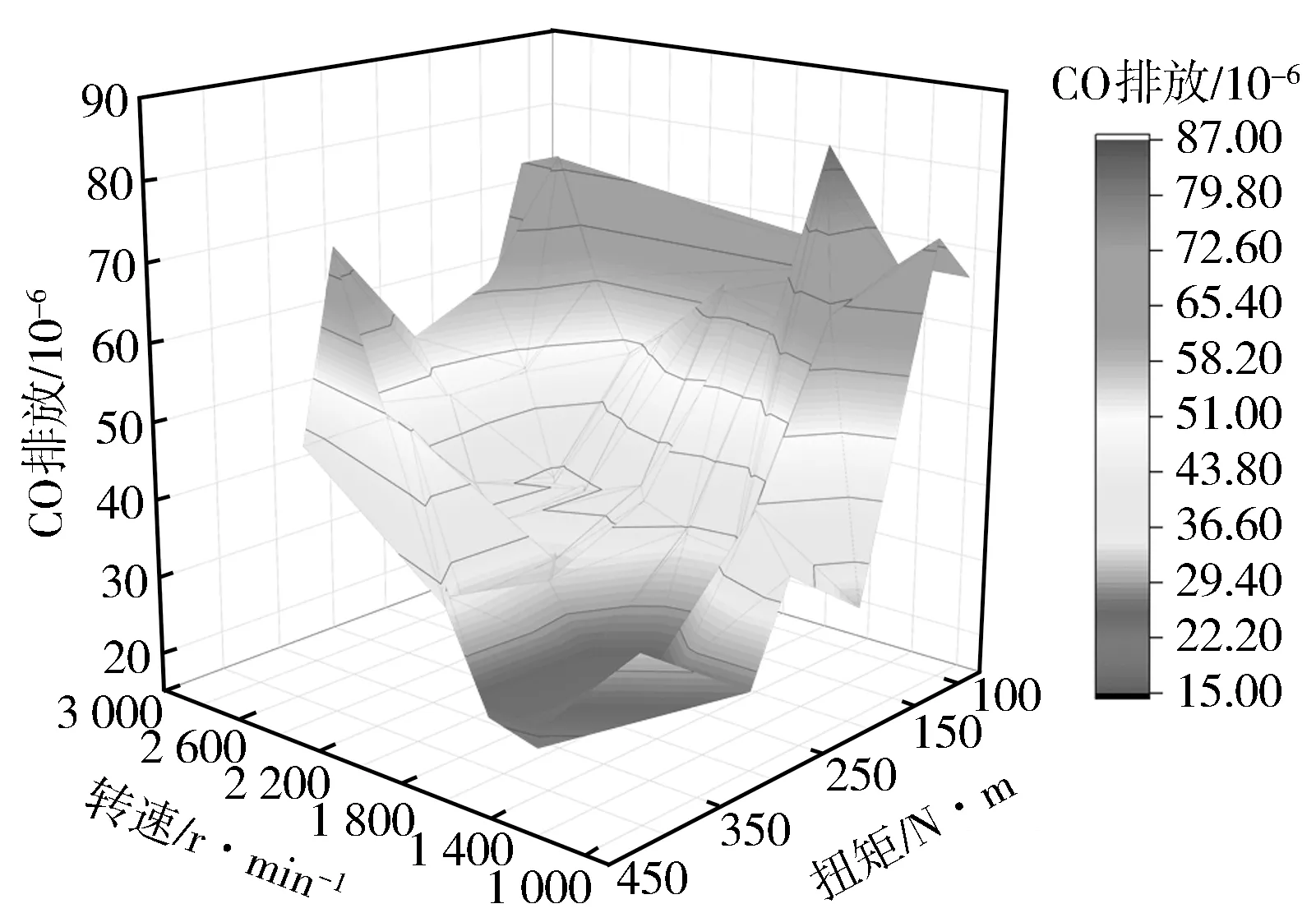
图15 CO试验数据插值响应
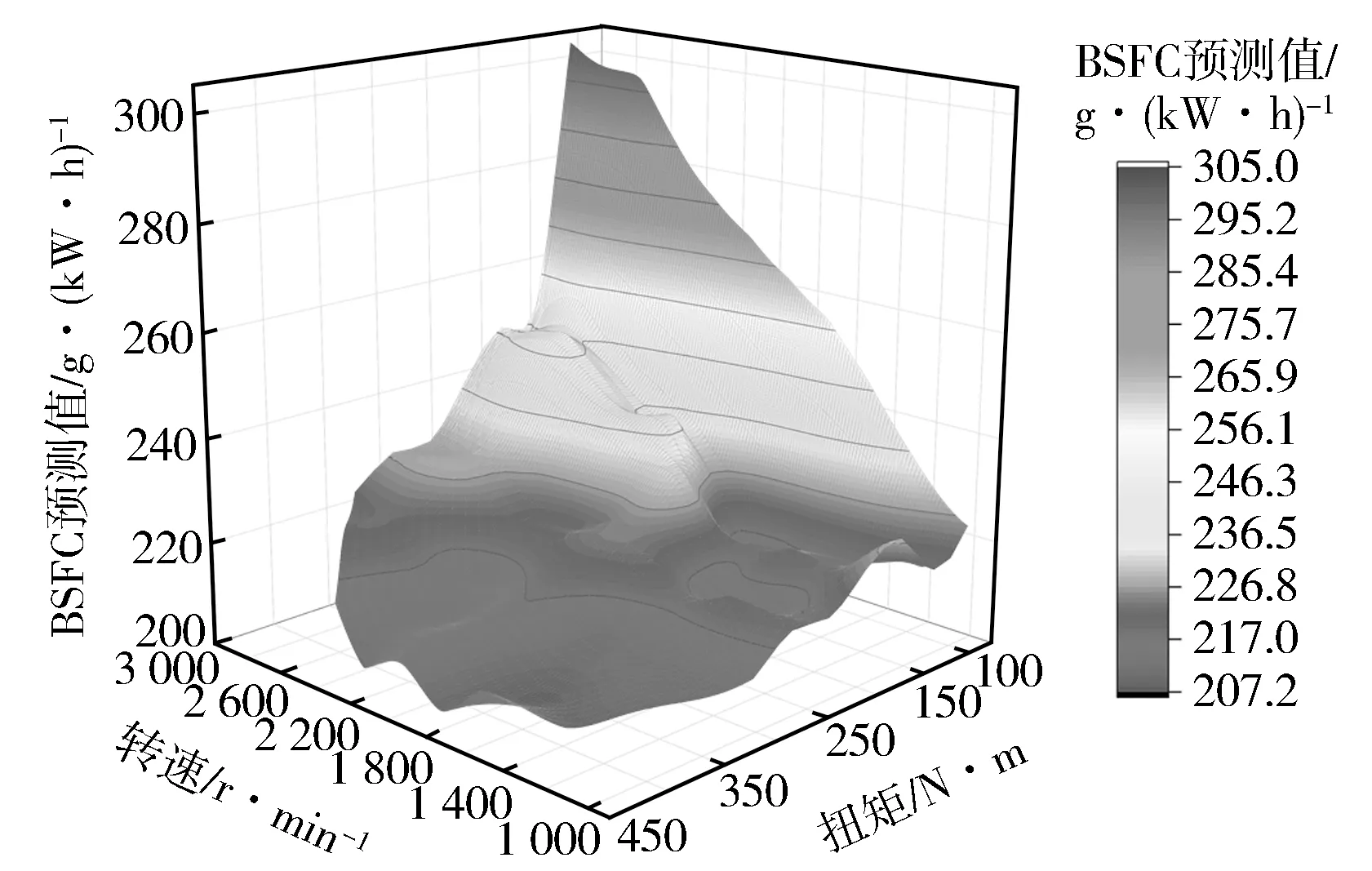
图16 BSFC基于转速和扭矩的三维预测曲面

图17 NOx基于转速和扭矩的三维预测曲面
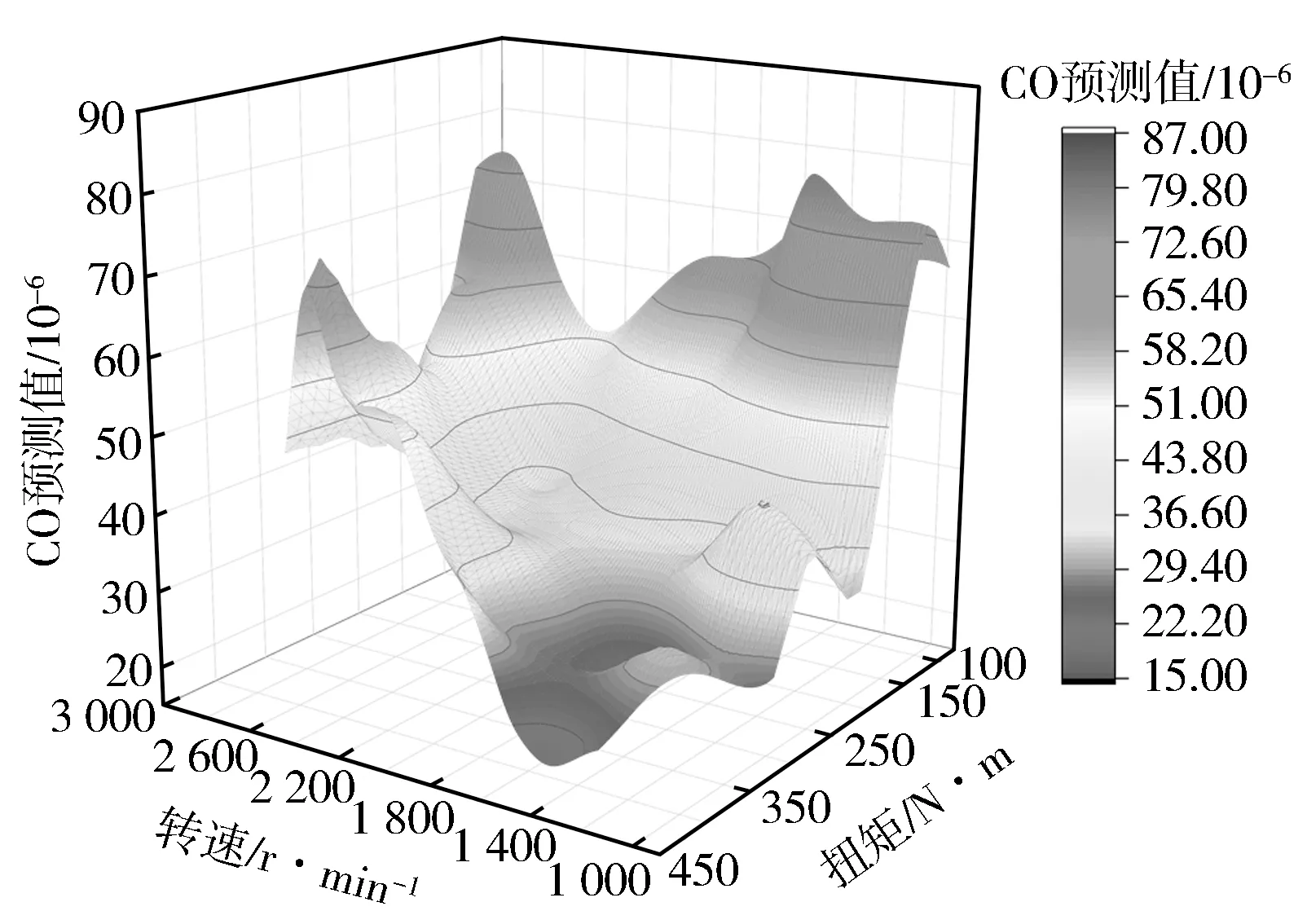
图18 CO基于转速和扭矩的三维预测曲面
4 结论
a)GBDT柴油机预测模型在迭代24次后,>0.90,迭代105次后>0.95,模型收敛速度较快,用时较短;GBDT方法虽具有较高的预测精度,但由于采用了梯度下降全局求解方法,针对不同的预测问题需要对迭代步长和训练次数等算法参数进行优化,以提高模型拟合程度和准确度,减少模型训练时间;
b)基于GBDT算法建立的柴油机性能预测模型,在BSFC,NO,CO预测方面具有较高的准确度和稳定性;拟合程度=0.981,NO=0.993,=0.992;预测值平均相对误差分别为0.81%,3.68%,2.95%;
c)GBDT算法对柴油机建模有较高的适应度,能够有效解决多特征高维非线性柴油机性能预测问题,为柴油机性能预测建模提供了一种行之有效的方法。
