图马尔可夫卷积神经网络半监督文本分类研究
2022-10-25李社蕾杨博雄
李社蕾,周 波,杨博雄
(三亚学院信息与智能工程学院 海南 三亚 572022)
1 引言
文本分类作为新闻过滤、信息检索、搜索引擎、文本数据库、数字化图书馆、数据挖掘等领域的技术基础,是自然语言处理的一个基本问题。其中,文本表示是影响文本分类性能的重要因素之一,在传统方法中,用手工制作的特征来表示文本,比如稀疏的词汇特征(例如BoW(Bag of words)(词袋)模型)。由于传统文本表示模型的高维度性和高稀疏度等特点,这个阶段的研究主要关注于高效的文本表示模型和降低文本表示维度。随着深度学习的崛起,深度学习开始应用于文本分类问题,目前基于深度学习的文本分类方法已成为主流Kim等在预训练的词向量上训练卷积神经网络(CNN)用于语句文本分类;Lai等提出了一种无人工特征的循环卷积神经网络分类方法;2016年Liu等人针对文本多分类任务,提出了基于 RNN 的三种不同的共享信息机制对具有特定任务和文本进行建模;Yang等提出了一种用于文档分类的层次注意力机制网络,简称 HAN。随着CNN在图接结构上的成功泛化,2017年Kipf & Welling提出了图神经网络模型(GCN:graph convolutional networks ),将深度神经网络应用于图结构数据上,该模型在大量基准图数据集上获得了最先进的分类结果; 2019 Yao等提出Text GCN 模型,异构图结构包括单词和文档两类节点,包括单词-单词,单词-文档两类边,单词-单词的权重为PMI值,单词-文档的权重为TF-IDF。2019年,Hu等提出了一种灵活的异构信息网络(HIN)框架来对短文本建模,并在此基础上,提出一种基于两级注意力机制的异构图注意力网络(HGAT),嵌入异构信息网络(HIN)进行文本分类。上述基于深度学习的研究中,目标都是学习单词或文本的有效表示对文本进行分类,上述模型都没有考虑文本标签之间依赖性。在统计关系学习中利用用概率图模型建模标签的依赖关系,进行半监督节点分类,2019年Yoon等利用图网络在概率图模型中进行推断。提出GMNN模型,该模型使用了两种不同的图神经网络,一种用于建立标签相关性模型,另一种用于逼近后验标签分布,并且该方法可以用变分EM算法进行有效训练。本文在GMNN模型的启发下,将利用马尔可夫随机场和图卷积神经网络相结合,在文档和单词构成的异构图上进行训练,模型使用两种不同的图卷积神经网络,分解建立标签的依赖性和节点特征的相关性,利用变分EM算法在异构图上进行训练,TextGMCN模型取得了更优的节点分类性能。
2 构图与问题描述
2.1 构图
对于图=(,,),其中为节点集合,||=为文档数目(语料库大小)与词的数目(词汇表大小)之和。为节点间边的集合,如果词出现在文档中,该文档和词之间有边,两个词在语料库中存在共现关系,则两个词之间存在边,边的权重由下面公式确定

(1)

TF-IDF(term frequency-inverse document frequency),TF是词频(Term Frequency),IDF是逆文本频率指数(Inverse Document Frequency)。TF-IDF模型的主要思想是:如果单词j在一篇文档中i出现的频率高,并且在其它文章中很少出现,则认为单词j具有很好的区分文档i和其它文档的能力。TF-IDF定义为
-=,×

2.2 问题描述
将文本数据构造成图结构之后,文本分类问题可看作基于异构图结构的半监督节点分类问题,对于图,设为已标注节点的标签,⊂,目标是预测剩余的未标注节点(⊂)的标签。
对于上述问题的研究主要有两种方法:统计关系学习(Statistical Relational Learning,SRL)和图神经网络,这两种方法目的都是根据对象属性和图结构对节点的标签分布进行建模,即(|,)
在这个问题中是固定不变的,为了简单起见,后面的公式中省略。
3 图卷积神经网络(GCN:Graph Convolutional Networks)
GCN采用两层GCN处理半监督节点分类问题,模型中的层间递推关系为
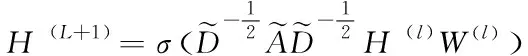
(2)

两层模型定义为:
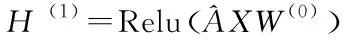
第二层:

(3)
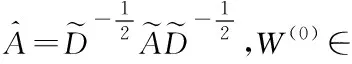
4 图马尔科夫神经网络(GMNN:Graph Markov Neural Networks
SRL利用条件随机场来对图节点标签的以来进行建模;图卷积神经网络以端到端的方式学习有效的节点表示,从而解决半监督节点的分类问题,但忽略了各个节点的标签之间的依赖性。GMNN结合CRF和GCN的优势,既能学习到有效的节点表示,预测未知节点的标签,又能对节点标签之间的依赖性进行建模。
GMNN利用CRF以节点特征为条件建模节点标签的联合分布为
(|)
其中,是模型参数,目标是是优化这个参数来求已知标签的最大似然:(|)。由于存在大量的未知标签,直接最大化对数似然很困难,下面考虑最大化对数似然的证据下界()
(|)=log(,|)-log(|,)
(4)
(|)log(|)
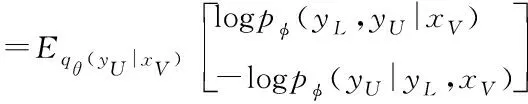
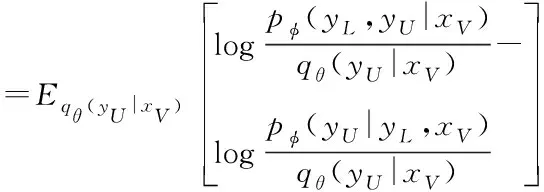

(5)
因为:
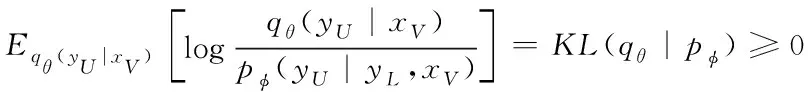
所以
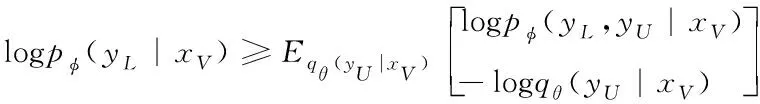
(6)
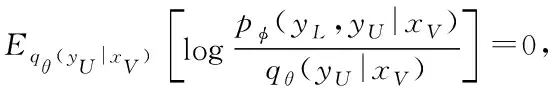

图1 基于图马尔可夫卷积神经网络的文本分类模型
利用伪极大似然变分算法进行优化。其中:
-: 使用一个来学习节点的特征表示以预测未知节点标签;
1)方法:固定更新(|)最大化后验分布(|,)
2)模型:基于平均场理论((|)=∏∈(|))用参数化(|),学习有效的节点嵌入来预测标签
(|)=(|oftmax(,))
(7)
其中,(|)表示为类别分布,节点嵌入,通过模型学习得到,节点的属性作为特征,作为参数,即模型的参数为,利用可以通过节点自身的特征和局部连接关系学习有用的节点嵌入来改进推断结果,另外通过不同节点共享,可以大规模简少推断所需的参数数量。
3)目标函数:目标函数如下
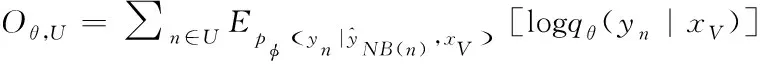
(8)
另外,也可以训练预测标注节点的标签,因此也可以让最大化监督目标函数如下
,=∏∈(|)
(9)
这里,为节点的标注标签,通过式(8)和(9)相加,可以得到所有节点的最优化
=,+,
(10)
-: 使用另一个来建模节点标签之间的依赖关系。
1)方法:固定,更新最大化似然函数

=(|)∑∈log(|(),)
(11)
其中()为节点的邻居集合。
2)模型:用另参数化条件分布

(12)
其中,的分布特征是一个分类器,将其作为特征通过模型学习节点嵌入,这里的记为,学习节点嵌入的时候,将所有()的标签作为节点的特征,因此,本质上建模目标节点的局部依赖关系,基于上述公式,不需要再定义势函数。
3)目标函数
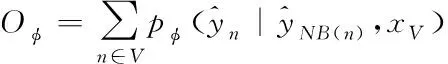
(13)
5 图马尔可夫卷积神经网络的文本分类模
由于图结构为异构图,一层特征聚合,只能聚合到一阶邻居的特征,即文档节点只能聚合到与其连接的单词节点的特征,无法聚合到其它文档节点的特征;采用两层模型,在第二层文档节点可以聚合到与其包含相同单词的文档的特征,为了是节点能够聚合到更大范围节点特征,本文模型和两个网络均采用三层模型,基于图马尔可夫卷积神经网络的文本分类模型如图1所示。
具体算法如下:
1)以文档和单词作为节点,构造异构图=(,,);
2)模型输入:异构图,和标注节点的标签(,);
3)模型输出:未知节点的标签;
4)利用(,)根据式(9)预训练;
5)-:学习阶段
6)-:推断
令预测的标签分布为(),根据()和利用式(8)、(9)更新,判断是否收敛,不收敛则返回步骤5);
7)根据(|)确定未知节点的分类。
6 实验
下面验证图马尔可夫卷积神经网络的文本分类模型(Text GMCN)进行半监督文本分类的性能。
6.1 实验设置
6.1.1 数据集
对5个基准文本数据集进行实验:20NG,R8,R52,Ohsumed和MR。首先对所有数据集进行预处理,按照(Kim 2014)对文本进行清洗并进行标注,然后删除了NLTK6中定义的停用词和在20NG,R8,R52及Ohsumed数据集中出现少于5词的低频词。数据集MR因为文档非常简短,所有数据集进行预处理之后没有删除单词。预处理数据集的统计信息如表1所示。
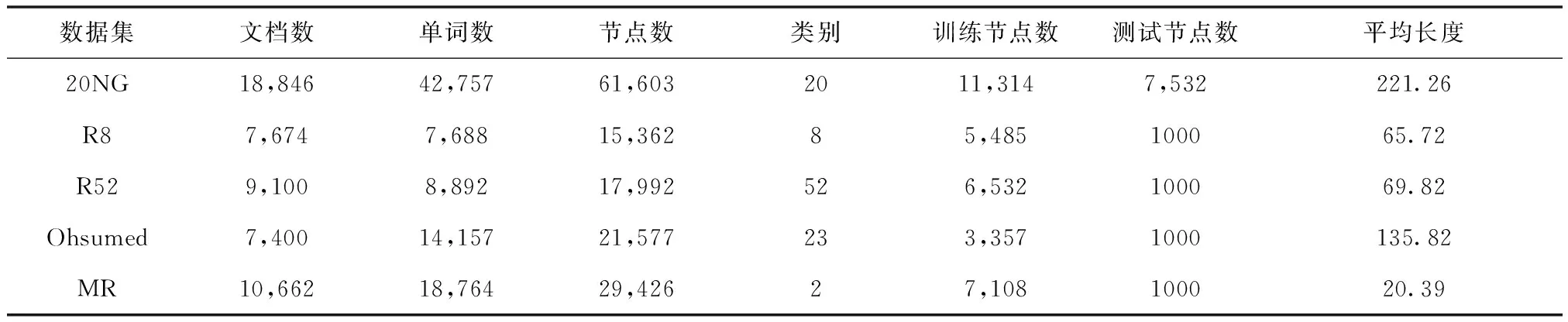
表1 数据集统计信息
6.1.2 对比模型
TF-IDF+LR: TF-IDF词袋(bag-of-words)模型,采用逻辑回归分类器。
TextCNN: 2014年Kim et al.将CNN用于语句文本分类,CNN-rand随机生成单词嵌入。
LSTM: 2016年Liu et al.利用LSTM进行文本分类。
PTE: 2015年Tang et al.提出了预测文本嵌入(PTE)模型,(在异构图由三个二分图组成,包括单词-单词,单词-文档和单词-标签等二分图。)首先单词、文档和标签三类节点构成的异构文本网络上学习单词嵌入,然后将单词嵌入均值作为文档嵌入进行文本分类。
TextGCN: 2019年Yao et al.提出Text GCN 模型,异构图结构包括单词和文档两类节点,包括单词-单词,单词-文档两类边,单词-单词的权重为PMI值,单词-文档的权重为TF-IDF。
WC+GCN:2020年提出了申艳光等提出了WC+GCN模型,该模型基于词的共现关系,利用引入注意力机制的图卷积神经网络模型进行了半监督文本分类。
6.1.3 参数设置
本模型设置层数为3,根据已有研究,第一隐藏层的维度为200,第二层隐藏层的维度为100,设置学习率为0.02,为了防止过拟合,取Dropout rate=0.5,并设置了Earlystopping,保证正确率当在验证集上面开始下降的时候中断训练。
6.2 实验结果
本实验的硬件环境为:64位Win10 系统,处理器为:intel® Core(TM) i7-9700k CPU @3.60GHz,内存为:16GB,显卡为:NVIDIA 2070。软件环境为:Python3.7结合Pytorch深度学习框架。
本文选择准确率作为性能评价指标,为了防止模型运行的随机错误,每个模型均运行10次取平均值,结果如表2所示。

表2 不同模型在五个基准数据集上的准确率,[*]意味着结果来自于对应的论文
实验结果表明,本模型20NG、R8 和 R52 的分类性能均优于其它方法,在数据集Ohsumed和MR上性能TextGCN相近。
7 结束语
本文利用两个图卷积神经网络,利用节点标签的依赖性,更有效地训练节点的特征表示,提出了一种基于图马尔可夫卷积神经网络的半监督文本分类方法——TextGMCN。将语料库构建成有文档-单词作为节点的异构网络,从而将文本分类问题,转化为文档节点的半监督分类问题。TextGMCN利用变分EM算法进行训练,学习有效的特征表示,对文档节点进行分类。实验表明,在E-step使用两层GMCN,在M-step使用三层GMCN网络结构在五个基准文本数据集中的 20NG、R8 和 R52 的分类性能均优于TF-IDF+LR、SVM、TextCNN、PTE、WC-GCN、TextGCN等分类方法。
