深度学习驱动的跨模态视觉数据搜索研究综述*
2022-10-24朱维乔广州航海学院广州510725
●朱维乔 (广州航海学院 广州 510725)
随着人工智能技术发展的一日千里,以及移动终端与社交网络的日益普及,互联网上的多媒体数据呈现指数级激增。包括图像、文本、音视频等不同类型的数据通常用于描述同一事物[1],这些不同种类的数据称作多模态数据,其在形式上表现出底层特征(如文本关键词、视频的帧、图像颜色等)的异构性和高层语义的关联性[2]。相互关联的多模态海量数据使用户跨模态检索的需求与日俱增。如图1所示,左图通过文本搜索出相关图像,右图通过图像搜索出相关文本,表达同一事物的图像和文本属于不同模态数据,此类跨模态数据间的互检索方式即为跨模态检索[2]。移动视觉搜索属于跨模态数据搜索,指通过移动智能终端摄像头获取现实对象的图像、视频、3D模型以及音频等视听觉数据,在互联网检索上述多模态数据的关联信息,并在智能终端显示出来的一种信息获取方式。其难点在于对文本、视频等跨模态数据的时序信息的理解,以及构建跨模态数据之间匹配关系的方法[3]。跨模态数据搜索的实现过程,是提取不同模态的数据特征并对特征之间的关联表示建立模型;通过模型与相关算法获取检索结果并进行排序。其中的主要问题在于如何度量表示相同语义主题却处于不同特征空间的跨模态数据之间的相似性,并在它们之间建立语义关联,即难点是语义鸿沟的跨越[4]。
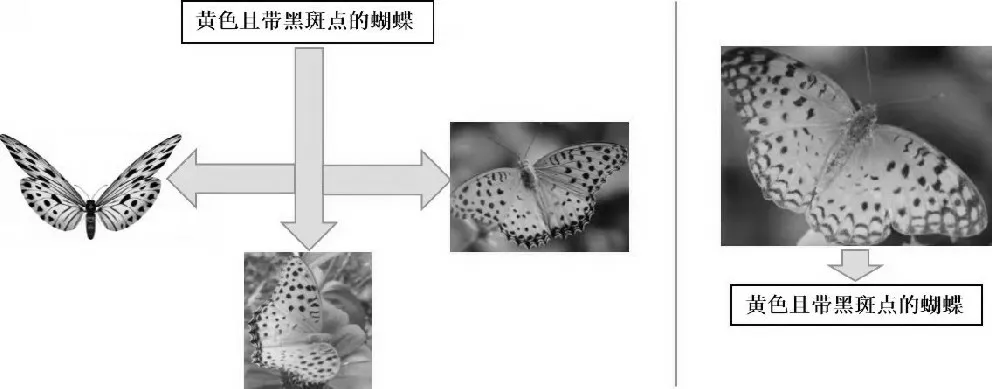
图1 跨模态数据搜索示意图
深度学习作为人工智能领域最热门的技术之一,近年来在语音分析、自然语言处理与计算机视觉等领域的推广运用都取得了突出的成效。其卓越的特征学习与特征表达能力为跨模态数据融合问题的解决提供了新途径,成为多模态数据语义理解与移动视觉搜索领域的重要工具,对异质鸿沟问题的解决和跨模态检索性能的提升提供了一种有前景的方案[5],能利用数据的本质特征解决各种问题[6],有利于实现跨模态搜索结果的精确度和可靠性[7]。
1 跨模态视觉数据搜索问题定义
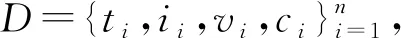

最终,跨模态数据搜索达成的目的是在给定任意模态数据时,能够检索出语义相似的其他某类或某几类模态的数据。
2 基于深度学习的跨模态视觉数据搜索研究现状
不同种类的跨模态视觉数据具备相似的语义信息,这种潜在相关性使搭建公共空间并将跨模态数据映射至此,进而生成统一的特征表征方式并进行相关性度量匹配具有可行性[8]。如图2所示,跨模态视觉数据搜索的过程架构,是在抽取多模态数据特征的基础上学习其公共表征,并实现跨模态匹配和排序。由此可见,图像、文本以及视频等跨模态视觉数据能够在公共语义空间中互相接近[9]。
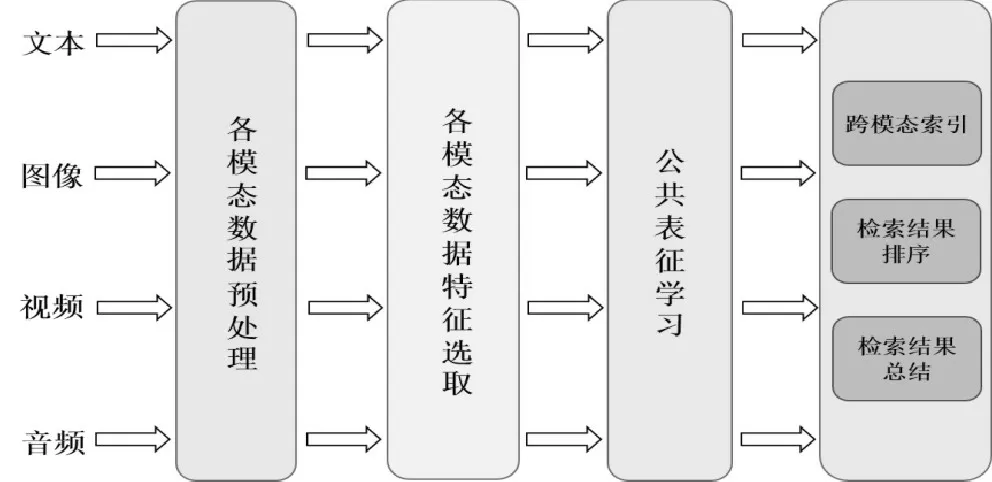
图2 跨模态视觉数据搜索过程架构
深度学习技术驱动的跨模态数据搜索研究获得了较大突破,检索准确性得以明显提升。下文以深度学习技术应用为切入点进行综述,将跨模态数据搜索研究划分为基于卷积/循环神经网络的方法、基于图网络表示的方法、基于生成对抗的方法以及基于深度哈希编码的方法。其中,前三种方法侧重于应用深度学习技术提升跨模态检索的准确性,而基于深度哈希编码的方法融合了深度学习技术与哈希算法,侧重于检索效率与精确度的同步提升。
2.1 基于卷积/循环神经网络的方法
神经网络结构包括卷积神经网络(Convolutional Neural Network,CNN)与循环神经网络(Recursive Neural Network,RNN)。其中,前者主要用于抽取图像数据特征[10],后者主要用于抽取文本数据特征及挖掘其语义。而对于视频数据特征,通常使用三维CNN进行抽取;对于音频数据特征,需要首先进行数据信号的降噪处理,再使用CNN抽取数据特征。
在应用深度学习技术实现数据特征抽取时,研究者们根据不同目标提出相应的改进组合方法。由于文本数据和图像数据之间语义鸿沟的存在,使用文本对所需图像进行精准描述存在着较大难度,Vo N等提出了TIRG(Text Image Residual Gating)模型,该方法通过查询文本数据特征修改图像数据特征,运用剩余连接对文本与图像特征进行重组,形成全新的数据查询特征[11]。例如,将文本或图像数据作为输入,通过文本对图像数据特征进行修正调整,使其与预测的输出结果相符。如图3所示,输入为一组图像和文本,最终输出结果是图像。TIRG模型以输入图像为基础,通过改变某些特征,使语义鸿沟问题得以有效缓解[9]。

图3 TIRG模型效果示例[11]
对于视频数据的特征抽取,二维CNN的局限性体现在抽取视觉空间特征而遗漏时间特征,应用三维CNN则可以使视频数据的时间特征得以保留。因此,Yamaguchi M等使用二维CNN和三维CNN相结合的方式抽取视频数据特征[12]。对于音频数据的特征抽取,Google公司通过实验发现CNN架构不但擅于处理图像数据,而且在音频数据分类任务方面也卓有成效[9]。此外,Guo M等提出文本和音频数据之间跨模态检索架构,运用语音特征参数MFCCs抽取音频数据特征[13]。
排序加权机制在跨模态数据搜索领域的应用近年来得以推广,促进了检索性能的提升。其运行机理是根据不同的数据搜索任务,通过权重排序的方式对关键数据进行抽取,使不同模态数据特征的重要性得以平衡。该机制在特征抽取阶段发挥了显著的作用,有效保存了关键数据的特征信息[9]。如Li S等提出采用递归神经网络算法RNN模型进行数据特征抽取,输入信息包括人物图像数据及其描述语句,输出的是二者之间的匹配度[14],该算法对公共场所密集人群的安全监控具有较高的应用价值。Dey S等提出使用长短期记忆网络LSTM(Long Short-Term Memory)为图像数据计算注意力图,将其映射至公共子空间同其他模态数据的查询特征相比较,并进行权重排序以及相关性度量[15]。
2.2 基于图网络表示的方法
深度神经网络具备强大的视觉关系学习与推理功能,在数据内容相关性匹配过程中发挥着重要作用。图像数据的语义信息包括图像中的对象、属性以及相互关系,对语义信息的识别与表示有利于加强对数据内容的理解。图网络表示模型在视觉数据搜索中显示出卓越的性能,使图像数据中对象之间的关系得以更清晰地呈现和表达,具有更强的鲁棒性,并有效填补了语义鸿沟。为了解决同一场景内对象之间关系的复杂性问题,Johnson J等构建了面向视觉场景的条件随机域模型CRF(Conditional Random Field),用场景图代替文本对图像数据进行检索并获取详细语义信息[16]。Yang J W等提出了graph RCNN模型,采用图网络建模的同时度量对象之间的相似性[17]。对于视频时刻检索问题的处理方法,Liu B B等提出时序模块网络模型(Temporal Modular Networks),通过查询的底层语言结构对相应的神经网络模块进行动态组装,进而组合推理视频数据,输出查询与视频数据之间的对应关系[18]。
2.3 基于生成对抗的方法
生成对抗模型作为深度学习研究方向的聚焦点,自被提出以来一直热度不减。Peng Y X等发现的跨模态GAN结构[19]和Wang B K等研究的对抗性跨模态数据检索[20]极为相似,二者均以跨模态数据的联合分布为对象构建模型。不同模态数据间的相关性在生成模型中进行匹配,同一模态内的数据内容相关性通过判别模型进行探索,通过对抗博弈促进跨模态数据的相关性学习。其中,生成模型的构成选取卷积自动编码器,以实现跨模态数据相关性与重构信息的有效利用[21]。
Wang H等提出的对抗性跨模态数据嵌入法,是运用对抗性学习方法进行模态对齐,进而学习不同模态之间的公共映射特征空间[22]。此外,Gu J X等也将跨模态特征嵌入与生成过程相结合,实现局部基础特征与整体抽象特征的同步学习[23]。
综上所述,生成对抗模型通过文本生成图像的方式来检索图像数据,使跨模态差异得以有效降低。其中,生成模型用于记录样本数据分布,判别模型验证生成数据的真实性。二者通过互相对抗博弈,使模型最终达到平衡。
2.4 基于深度哈希编码的方法
跨模态多媒体数据的爆发式激增使检索系统的存储空间面临着巨大压力,为了摆脱这一困境,研究人员以哈希算法作为解决问题的工具,将跨模态数据转换为二进制哈希编码后投影至公共空间,实现检索速度的提升与存储空间的压缩。然而手工特征的哈希算法虽使检索速度与存储性能得以改善,但在一定程度上损失了检索精度。为了实现平衡检索效率与精确性的目标,近年来有学者将深度学习技术与哈希算法相结合,即应用深度哈希编码方法[24]。 Salakhutdinov R等学者最早提出了语义哈希方法,使用基于深度学习的受限玻尔兹曼机模型学习哈希编码以实现可视化数据搜索[25]。Xia R K等[26]和Liong V E等[27]提出包括数据特征学习与哈希编码生成的二阶段深度哈希方法,采用深度神经网络学习多模态数据中的非线性表征转换,实行统一的二进制哈希编码并以其为依据对隐变量进行建模。董震等设计了深度异构哈希网络用于检索跨模态人脸数据,使人脸图像与视频这两种位于异构空间的跨模态数据可以映射至同一公共空间,进而生成二值哈希编码表示[28]。此模型提供了深度哈希方法的通用架构,适用于多种跨模态数据的搜索任务。
深度哈希方法的训练需要多模态海量数据的支撑,当新数据出现时需要重新训练卷积神经网络模型生成哈希码。为了解决这一增量学习难题,Wu D Y等设计了深度增量哈希网络模型,在原有图像哈希码表示不变的基础上,以增量方式对哈希编码进行学习,在无须重新训练模型的条件下,使新数据能够直接进行哈希编码,并且保持训练数据间的相似性,进而学习查询数据集的深度哈希算法,既减少了训练时间又保证了检索精准度[29]。
3 跨模态视觉数据搜索常用数据集
在跨模态视觉数据搜索方法研究与评价的过程中,数据集有助于实现评估检索性能的目标,具有举足轻重的作用,下文对常用数据集进行重点介绍。
Wikipedia数据集。该数据集来源于Wiki维基百科,包含两种模态特征,在跨模态数据搜索研究过程中使用较为广泛。其包括两千余个语义互为关联的文本/图像数据对,每一个文本/图像数据对标注相应的语义类别[5]。
Flickr数据集。该数据集来源于雅虎的相册网站Flickr,内容涉及各项人类日常活动的相关场景和事件。其中Flickr8k数据集与Flickr30k数据集分别包含8 000张、31 783张来源于Flickr网站的图像,每张图像有对应的五个独立文本注释语句进行描述,描述语句由网站用户进行编辑[30]。
MS COCO(Microsoft Common Objects in Context)数据集。该数据集由微软公司收集构建,与Flickr数据集相比较,该数据集包含更多数量的日常生活场景图像与文本标签数据,并提供了数据的视觉描述特征,其中有123 287 张用于训练与验证的图像,每张图像有对应的五个注释语句进行描述[31]。
PKU XMedia Net数据集。该数据集来源于YouTube、Wikipedia、Flickr等,由北京大学多媒体信息处理研究室通过网络爬虫抓取采集,是当前数据量最大、模态种类最多的跨模态检索数据集。其中包括二十个语义类标注,每一类包括图像、文本、语音、视频以及3D 模型等五种不同类型的跨模态数据,数量分别为250、250、50、25、25[32]。可将上述语义类标注作为查询进行数据搜索,并截取与标注内容相符合的片段。
4 深度跨模态数据搜索研究展望
近年来,研究者设计出一系列基于深度学习的跨模态数据搜索算法并取得了较为卓越的性能,然而,算法应用效果仍与用户期待之间存在差距。因此,跨模态数据搜索的研究工作仍有待向纵深方向开展。
(1)搜集海量多模态数据集。研究人员构建的复杂深度学习算法亟须跨模态基准数据集验证支撑,然而当前的如NUS-WIDE与Wiki仅包含两种模态数据且体量有限,难以精准描述模态特征。为此,亟须搜集海量数据集以提升跨模态数据搜索的性能[5]。
(2)充分利用语义标注有限且含有噪声的多模态数据。在互联网技术飞速发展的大数据环境下,YouTube、微信微博等社交媒体产生的海量多模态数据是以松散组织的方式分布在互联网中,数据标注有限且包含庞杂噪声,无法对全部数据进行标注。因而怎样充分利用标注有限且包含噪声的多模态数据进行检索有待研究者继续深入探索。
(3)设计高效轻量级跨模态数据搜索算法。海量多模态数据的剧增使用户对跨模态数据搜索的需求日益提升,对搜索算法的要求也愈加苛刻。研究者设计的复杂性较高的算法在提升检索性能的同时,却无法保证数据搜索的效率[5]。故而,设计轻量级高性能的跨模态数据搜索算法是极具挑战性的研究课题。
(4)跨模态数据的细粒度相关性建模。基于深度神经网络的一般算法是在跨模态数据共同表示学习时,将不同模态数据进行非线性映射至共同表示空间后进行相关性度量。然而此类方法在建模时欠缺精细度,导致跨模态数据之间的一致性部分难以深入发掘。为了解决这一难题,研究者近年来提出了细粒度相关性的一系列建模方法[8],以深入挖掘文本数据和图像数据之间片段级的对应关系,并取得了较为理想的相关性建模效果。由此可见,针对不同模态类型数据的片段级表征进行提取,并进行复杂性更高的细粒度关系建模将成为未来的研究方向。
