基于网络嵌入的农产品销售推荐系统
2022-10-24臧玑珣徐鑫航
臧玑珣,徐鑫航
(1.西安外国语大学 信息技术中心,陕西 西安 710061; 2.西安电子科技大学 计算机科学与技术学院,陕西 西安 710071)
0 引 言
农业生产作为国家的第一产业支撑着国民经济的建设和发展。农产品由于产地与保质期等因素的限制导致其流通能力较差,不同品种的农产品种植地区、口味、价格等属性特征都有所差异,因此如何根据品种特征选择合适的销售区域和影响力最大化的销售商,以及发现最具购买潜力的买家已经成为农业发展的重要问题[1]。在数字经济日益繁茂的时代,如何将农产品在生产、流通、售后等各环节产生的海量历史信息进行收集整合和使用是一项重要的任务。
推荐系统[2]是一种广泛应用的信息过滤系统,它通过对历史数据和物品属性的分析来预测用户偏好,已经在网络购物、内容咨询等线上平台获取了巨大的成功。传统的推荐算法主要有基于内容的推荐[3]、基于协同过滤的推荐[4]和混合推荐[5]等。此外,也有使用深度学习、知识图谱等技术来解决推荐任务的尝试。近年来,也有一些研究着眼于农产品销售的推荐系统。针对协同过滤在推荐时难以及时捕捉用户兴趣变化的问题,李建军等[6]考虑用户行为及用户访问数据,提出基于改进权值的用户兴趣推荐算法,深入挖掘用户对农产品的喜好趋势。李亚峰等[7]借助K最邻近算法构建用户浏览矩阵,进而通过Jaccard相似度来实现对用户的农产品推荐过程。邹诗雨等[8]利用PMI-VL算法分析农产品评论的情感值以寻找潜在的购买者。苏启琛等[9]提出一种基于内容的生鲜产品推荐算法,利用产品特征与购买记录创建用户模型以预测用户喜爱的Top-N生鲜产品。这些方法提供了农产品推荐算法的设计思路,但其推荐精度以及各销售环节的完整性上仍有优化空间。
针对农产品的推荐问题,结合数据挖掘、词嵌入及网络表示学习等技术,该文构建了农产品销售途径推荐系统。该系统通过用户输入的预售农产品特点向用户推荐适合销售的地区、销售商及有潜力的买家,有效提升了农产品销售与流通环节的效率。最后通过对比实验验证了该方法的有效性。
1 基于词嵌入的AP-GloVe方法
大规模生产农产品的种类、品种、繁育地区、销售区域往往具有较高的稳定性。在进行自然语言处理任务时需要将词汇转换为计算机可以理解的向量形式,如One-hot将每个词汇转换为一个词表大小维度的、稀疏的独热向量。词嵌入则将词转化成一种分布式表示,它使得离散表示的向量从高维空间映射为低维稠密的连续向量,不仅可以提升计算效率还使得嵌入后的词汇特征可以表示词与词之间的关系。常用于词嵌入的分布式表示方法包括Word2Vec[10]、BERT[11]以及Glove[12]。
为了从非结构化的文本信息中捕捉待售农产品特点与地区等语义信息的词向量,提出词嵌入模型AP-GloVe(Global Word Vector Representation for Agricultural Products),可以在生成农产品向量表示时保留全局词频统计信息与局部上下文信息。
该方法首先从中国植物主题数据库、中国国家地名信息库以及爬取果蔬类文章等多个来源获取农产品类别的原始文本信息,并对得到的源数据进行预处理,如数据清洗与数据集成等操作,目的是获取标准、连续的农业文本数据,进而建立“地区”与“果蔬品种”两个专业词库。然后,对预处理后的文本进行jieba分词以获取农业领域的中文词汇,进而可以得到描述不同词汇间临近关系的共现矩阵。
根据每个词汇与其他词汇在规定窗口中出现的次数构造共现矩阵X,矩阵中的元素Xij表示词汇j在中心词i的上下文中出现的次数。当词j再次出现在中心词i的上下文中时,通过Xi,j=Xi,j+1更新矩阵中的元素Xij,然后循环计算直到每个词都作为中心词更新过共现矩阵。例如分好词的语料:“菠萝,很,好吃”,“荔枝,和,菠萝,很,甜”,“荔枝,非常,甜”,设置窗口大小为3,即取中心词前后各一个词作为上下文,分词共现矩阵如图1所示。
设Pi,k代表词k作为词i上下文出现的概率,即:
由于Pi,k=Xi,k/Xj,k会随着单词i、j、k之间相关度的变化而变化,所以GloVe设定了一个由词向量计算得出的函数g(vi,vj,vk)来逼近Pi,k=Xi,k/Xj,k,使得词向量同样可以蕴含共现矩阵所蕴含的信息。GloVe中设计的g(vi,vj,vk)=exp((vi-vj)Tvk),即尽可能使得以下等式:

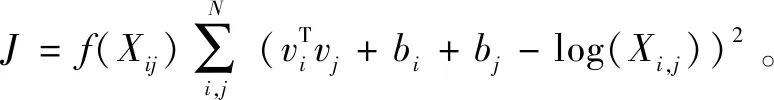

图2 函数f(x)图像
2 基于影响力的图神经网络模型IAGNN
社交影响力[13]是指一个人或事物会对网络中另一个人的行为偏好产生影响,在网络中寻找具有影响力的中心节点并刻画其对邻居节点产生的影响具有重要意义,其已被广泛应用于社交推荐[14]和广告传播[15]等领域。为了在社交网络中学习出紧凑的网络信息特征,并使其保留复杂的网络拓扑结构,提出了一个基于影响力的图神经网络模型IAGNN (Influence-Aware Graph Neural Networks),如图3所示。首先,IAGNN以图数据作为输入,根据节点间不同的拓扑结构关系得到拓扑信息D,然后将入度作为节点vi的基本影响信息B。再集成节点vi的拓扑信息D和基本影响信息B后获得该节点的综合影响力信息矩阵W,最终模型会从注意力层输出学习到的节点表示形式并用于下游任务。

图3 IAGNN模型
社交网络中任意两个节点vi和vj之间不同类型的边可以表示节点vi在节点vj上的不同影响。如图4所示,从左向右依次表示节点vi和vj之间存在三种类型的边,即:vi单向跟随或转发vj,vj单向跟随或转发vi,以及vi和vj互相跟随。在社交网络中,大多数主动关注或转发都可以视为接受另一方行为的影响,并且另一方应对其自身施加影响。此外,节点vj对vi的影响还取决于vj被关注的数量[16]:

图4 节点vi和vj的三种不同拓扑
其中a、b和c为常数,Ii表示节点vi的直接前驱节点数量,并且根据上述分析的三种情况在实验中分配了它们的值。该公式能表示当vj受到更多关注时,vj对其他节点的影响更大。
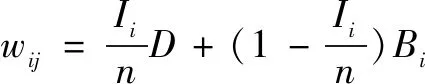
通过标准化wi={wij1,wij2,…,wijN}生成权重矩阵w∈Rn*n来获得wij,该权重矩阵表示其他节点对网络中每个节点vi的影响。
在嵌入过程中,每个节点都通过注意力层实现自注意力机制。多头注意力机制[17]先对权重矩阵进行线性变换,然后将其输入到按比例缩放的点积注意力。每个线性变换的参数W是不同的。此外,按比例缩放的点积注意力进行了N次。该文的注意力层利用的注意力机制表示为:
a:RF′×RF′→R
之后计算相似系数eij:
eij=a([Whi‖Whj])
为了方便统计注意力系数,经过Softmax对节点vj和vi正则化:
αij=softmax(eij)
对于这样一个单层前馈神经网络,使用非线性函数LeakyReLU进行激活,并通过规范化不同节点之间的注意力系数来获得归一化注意力。在IAGNN模型中,利用节点之间的关系以及节点vi本身的受众规模来获得相应的节点综合影响矩阵W。在通过注意力机制计算了影响力系数之后,对系数进行正则化和激活函数操作。此外,每个头的聚合特征被级联,并且进一步通过非线性激活函数σ输出低维节点表示:
在卷积的每一层中,k个注意机制独立工作,并最终将其计算串联起来。IAGNN的算法流程如算法1所示。训练嵌入网络后,所学习的节点表示不仅可以表征节点的潜在特征,还可以探索网络中的影响信息。此外,学习低维节点表示会用于后续的节点分类和链接预测任务等下游任务,建立各种农产品与销售商、销售地区以及潜在买家等节点的关联关系,进而用于销售推荐策略。
算法1:IAGNN

1:fori=1,2,…,ndo
2:forjinNido
αij=softmax(wijeij)
4: end for
5:end for
3 基于AP-GloVe与IAGNN的农产品销售途径推荐方法
该文以农产品特征数据和销售数据为基础,实现了一个农产品销售途径推荐系统。其中,销售地推荐基于面向农产品的全局词向量表示方法AP-GloVe设计实现;而销售商推荐模块在获得待推荐销售地的基础上完成;潜在买家推荐则基于IAGNN模型实现。
为实现销售地与销售商推荐,从构建的数据集与自定义语料库中提取文本特征,并计算根据提出的AP-GloVe方法所生成嵌入向量的相似度,为特定的农产品推荐top-N个适合的销售地点。该结果不仅成为最终展示给用户的销售地推荐结果,也会输入销售商推荐模块成为销售商推荐过程中的一个决定性因素,流程如图5所示。
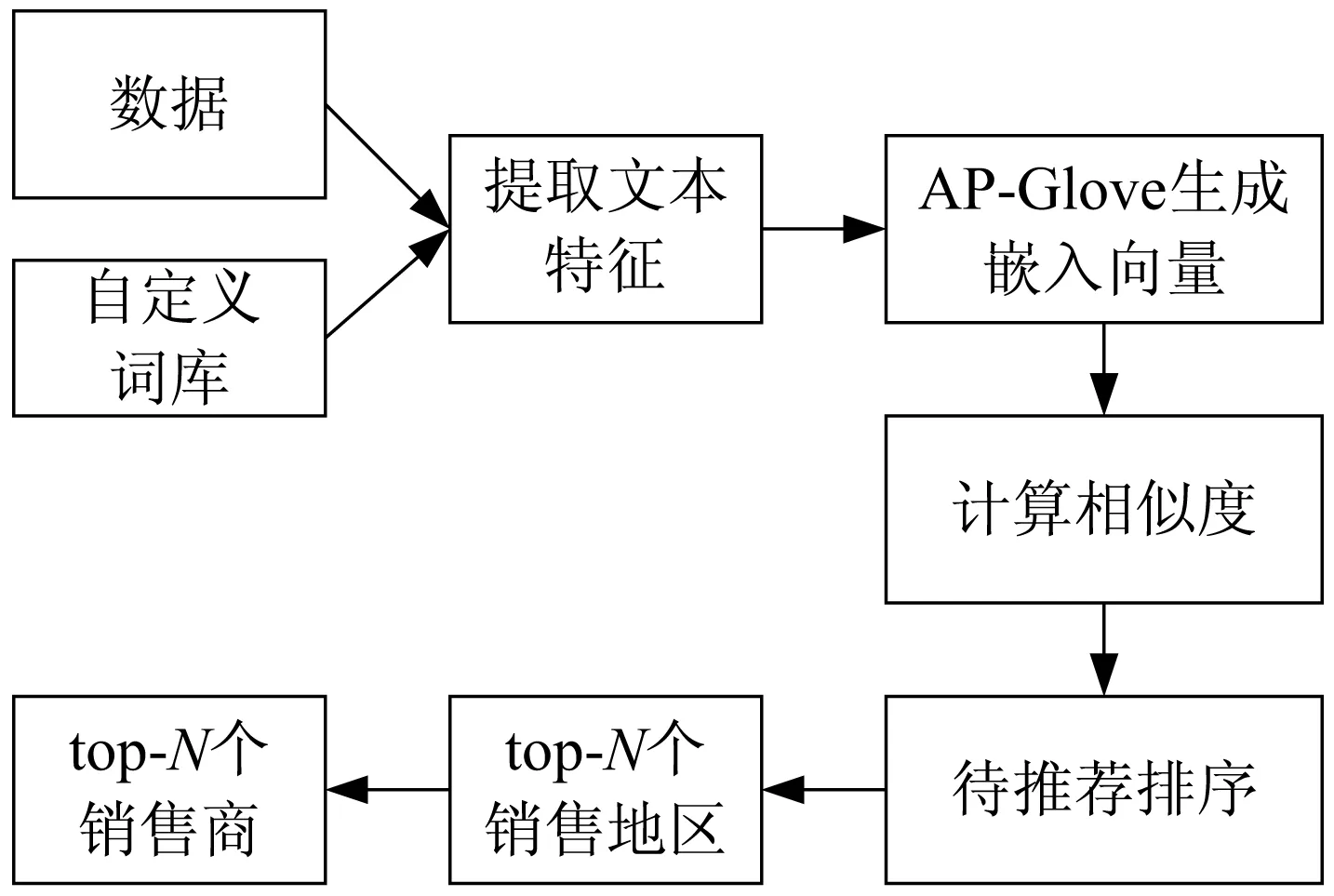
图5 销售地销售商推荐流程
销售商推荐主要负责在给定果蔬品种时,根据获取的销售商数据对销售商进行筛选,具体流程如图6所示。输入的销售商信息经过销售品种过滤、销量过滤、销售额过滤以及销售地过滤四个筛选环节输出最终待推荐的top-N销售商。在每个环节执行前判断待推荐列表大小,来防止推荐结果为空或过多的情况。如果列表为空则输出该环节执行前待推荐列表的前N行;如果大于N则继续执行下一个筛选环节;否则直接输出当前待推荐列表。销售地过滤是将先前在销售地推荐模块获得的结果作为限制条件进一步缩小待推荐销售商范围,使最终推荐结果尽可能符合预销售方向和预售地区,并且保证一定的销量与口碑。
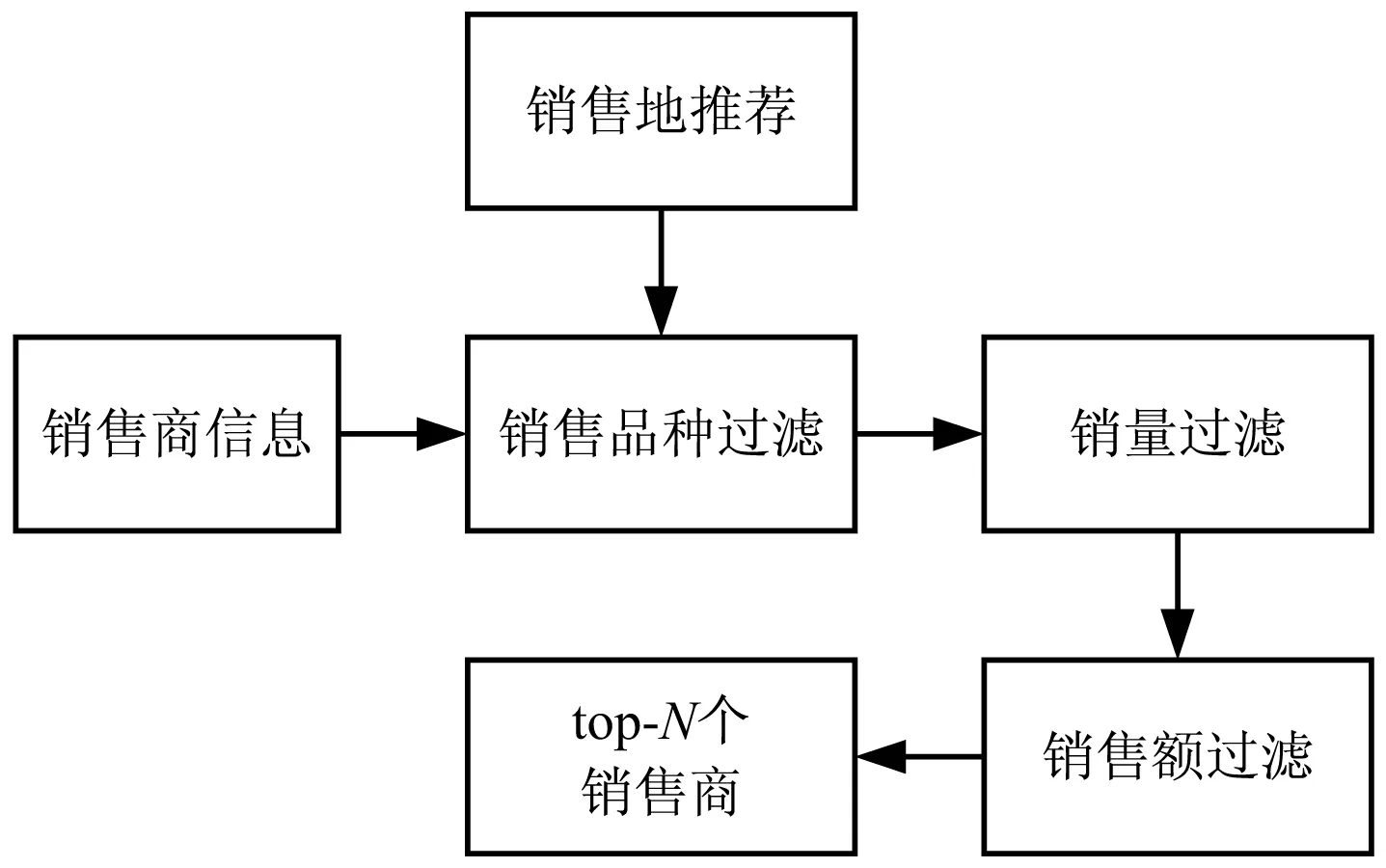
图6 销售商推荐流程
潜在买家推荐模块根据给定社交网络中节点与节点的社交关系以及节点的社交行为,通过设计的IAGNN模型得到蕴含行为与关系语义的节点特征表示向量,然后该向量通过相似度计算实现节点分类与链路预测任务,完成对预售农产品推荐有相似喜好和行为的潜在消费者,模型总体流程如图7所示。

图7 潜在买家推荐流程
4 实验结果及分析
4.1 基于AP-Glove的词嵌入
为验证AP-GloVe模型生成词嵌入的准确性,将Word2Vec的CBOW和Skip-Gram、GloVe、Skip-Gram模型与提出的AP- GloVe模型,在SimLex-999、Wordsim-240和Wordsim-296等词的相似性任务数据集上进行了对比分析,这些数据集包含了词对间的相似性评分。通过计算出词向量间的余弦相似度与数据集中相似度评分的Pearson相关系数来评估词嵌入的准确性,相关系数越大表示嵌入结果相似度与词对本身相似度越贴合,得出的Pearson相关系数如表1所示。

表1 AP-GloVe方法在词相似任务上的Pearson相关系数
可以看出,提出的AP-GloVe在具有296组中文词对的Wordsim-296数据集上明显优于其他方法,并且在其他数据集上与其他方法的差距也较小,说明该方法保留低共现词对信息也可以得到效果相似的嵌入向量。GloVe也有较为稳定的效果,说明GloVe综合了全局词汇的共现信息和Word2Vec局部窗口上下文的优势是有效的,而且不需要计算共现次数为0的词对,在矩阵计算中有效的减少了计算量。
4.2 基于IAGNN的节点表示
为了验证IAGNN模型生成节点表示的准确性,在多个数据集上使用IAGNN与几种相似的图网络进行比对,具体通过节点分类与链路预测这两个下游任务进行衡量。
实验基本设置如下:当应用L2正则化时,α=0.2,λ=0.000 5。对于所有方法和数据集,epochs设置为10 000,dropout设置为0.6,初始学习率为0.005。根据样本量,用于计算节点之间拓扑影响的常数a、b和c分别设置为60、10和40。为了公平起见,该文按照对比算法原文的默认参数进行设置,包括GAT[18]、GCN[19]、GraphSage[20]和AGNN[21]。
表2显示了在Twitter、Weibo、Digg和Cora四个数据集上的五种图网络表示学习方法在节点分类任务上的实验结果。总体而言,实验结果表明提出的IAGNN模型的性能优于其他比较算法,这表明在节点嵌入训练过程中,IAGNN保留了网络中节点的拓扑结构和基本影响。除此之外,由表中结果可以观察到GAT的性能也较好,这可能是由于GAT和IAGNN涉及的注意力机制促进了预测精度的提升。在非社交网络形式的Cora和CiteSeer数据集上的结果表明,所提出的IAGNN可以适用于更为广泛的业务领域。总之,IAGNN通过在生成影响信息矩阵时保留了图的拓扑结构来提高节点嵌入的准确性。
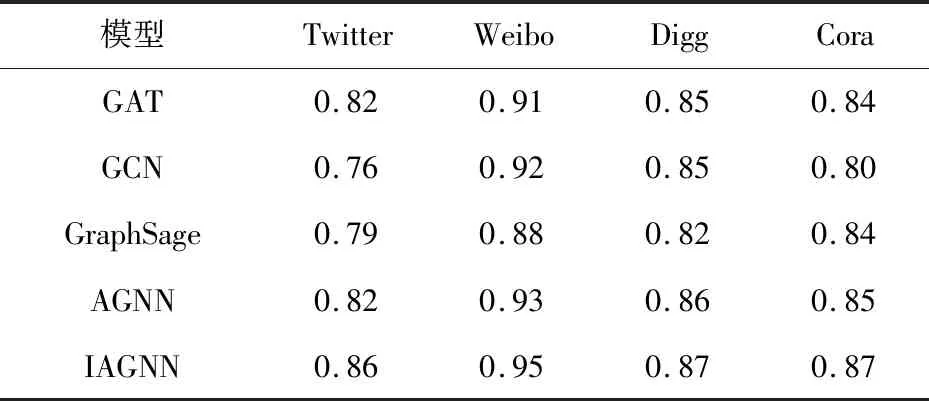
表2 节点分类算法精度比较
链路预测任务可以描述两个节点之间建立连接关系的可能行。表3显示了GAT、GCN以及提出的IAGNN三种算法在不同数据集上进行链路预测任务的AUC性能比较。可以看到,IAGNN模型的AUC性能在链路预测任务中明显优于所有基线。
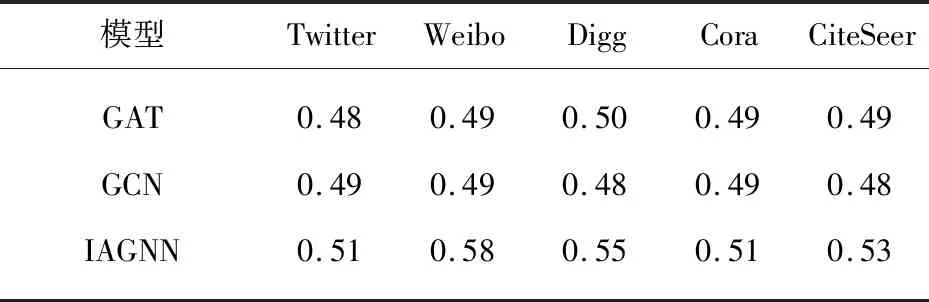
表3 链路预测算法AUC性能比较
5 结束语
针对农产品销售特征设计了一个农产品销售途径推荐系统。系统通过 AP-GloVe方法为用户推荐预售产品适合的销售地,并借助销售地模块结果对销售商等数据分析处理来为用户推荐预售产品的销售商,最终利用IAGNN网络模型解决预售产品潜在买家推荐问题,在相关实验中取得了优于基线的效果。然而实际的农产品销售还面临政策、资金、环境等多方面的影响,随着数据越来越多元化与技术的不断革新,农产品线上销售的道路上还有很多方面值得去研究。
