基于边缘计算设备的手写数字图像识别系统
2022-10-19段莉莉索珈顺
章 磊,段莉莉,索珈顺
(1.湖北理工学院 a.电气与电子信息工程学院,b.智能输送技术与装备湖北省重点实验室,湖北 黄石 435003;2.湖北师范大学 计算机与信息工程学院,湖北 黄石 435002)
近年来,手写数字图像识别系统的应用越来越广泛,例如手写数字统计、试卷分数扫描等[1]。目前,手写数字识别大多是基于云计算实现,存在网络延迟、数据泄露等问题,不能满足对实时性和安全性要求较高的应用环境[2]。随着边缘智能(Edge Intelligence, EI)技术的发展,部署在边缘设备上的实时手写数字系统不受传输网络的限制,且数据可以不上传到云端,在保证实时性的同时又保护了数据的安全,可以较好地满足对实时性和安全性要求较高的手写图像识别应用环境。Zhou等[3]描述了EI的发展以及边缘端在人工智能(AI)领域的重要性。Li等[4]提出了用Edgent框架来优化深度神经网络在边缘设备上的推理。He等[5]提出了一种Resnet网络模型,利用Residual结构解决了当模型层次加深时错误率提高的“退化”问题。Howard等[6]提出了一种专为移动设备设计的Mobilenet网络模型,通过可分离卷积大幅减少了DNN的计算量。
在低性能的边缘计算设备上能否有效地运行手写数字图片识别系统仍是一个亟待解决的问题。因此,本文设计一个轻量级手写数字识别神经网络,并基于其构建一个手写数字识别系统,将系统运行在低成本的边缘计算设备Jetson Nano上,以期能够满足低成本边缘计算设备的需求,为其他边缘计算设备上的AI应用提供经验。
1 系统结构
基于边缘计算设备的实时手写数字图像识别系统由图片预处理模块、边缘设备上的神经网络推断模块和图片后处理模块组成。图片预处理模块将输入图片中数字的位置等有效信息提取出来,以便神经网络推断。在图片推断过程中,由于边缘计算设备的计算能力低、储存空间有限,目前主流的图像识别神经网络无法运行,因此专门设计了一个轻量级神经网络,并选择合适的边缘部署框架,以保证系统的AI性能。图片后处理模块则将预测结果、位置信息等在图片中标出,并最终输出可视化的视频流。系统处理流程如图1所示。
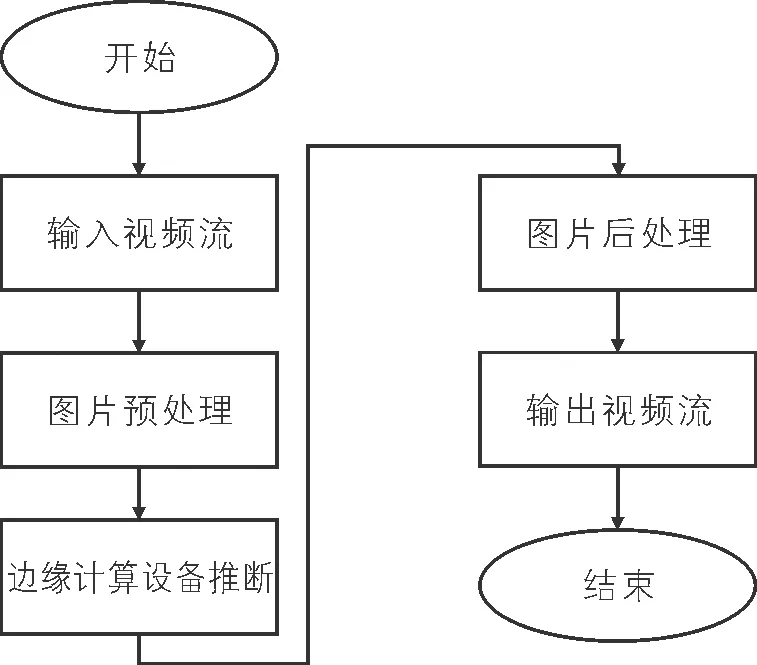
图1 系统处理流程
2 图片预处理
为解决实际拍摄到的手写数字图片样式与训练模型使用的MNIST数据集中图片样式不同而导致识别不准确的问题,首先对图片进行预处理,将拍摄到的图片处理为类似MNIST数据集中图像的样式,然后再送入神经网络进行推断。图片处理步骤如下:①从灰度图读取图片,并缩放为100×100的分辨率,从而加快后续图像处理速度;②对图像进行二值化处理;③提取出图像中数字部分的有效区域,并将其裁剪出来;④将裁剪出来的区域中长边缩放为18个像素,短边等比例缩放,并在其周围填充白色像素点,使图像变为28×28的分辨率;⑤将像素点颜色反转,生成类似于MNIST数据集中的图像样式。图片预处理过程如图2所示。
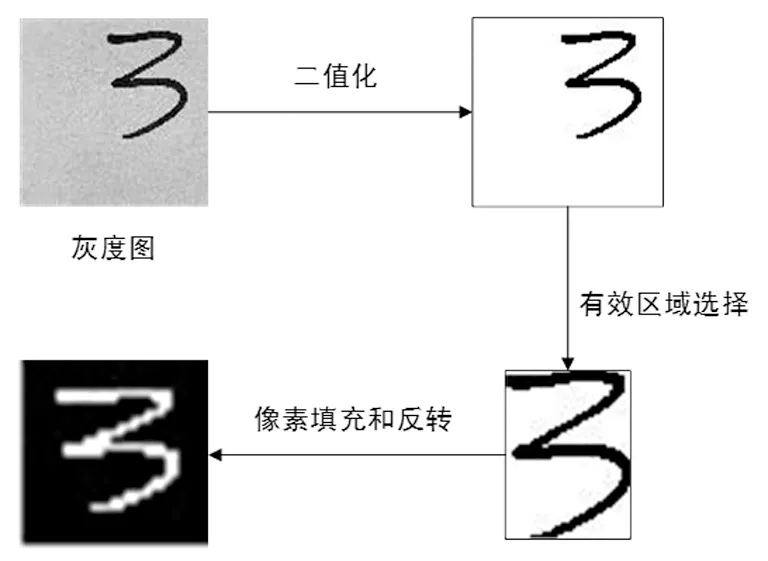
图2 图片预处理过程
3 改进型手写数字识别神经网络
为适应边缘计算设备的计算能力弱、存储量小等特点,在激活函数、模型参数、模型泛化能力、模型训练等方面对经典卷积神经网络(CNN)模型LeNet-5[7]进行改进,提出一种用于手写数字识别的改进型神经网络模型LeNet-C。改进后的神经网络模型包括卷积层1(c1)、池化层1(p1)、卷积层2(c2)、池化层2(p2)、全连接层1(f1)、全连接层2(f2)和输出层(out)。利用奇异值分解(SVD)的方式压缩模型,以减少模型的计算量和模型大小。LeNet-C网络模型结构如图3所示。
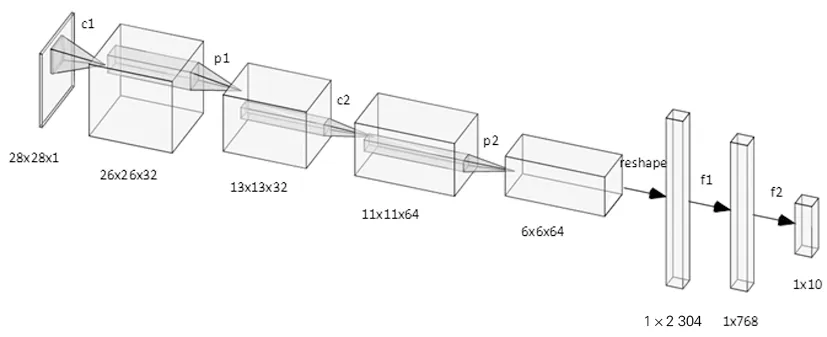
图3 LeNet-C网络模型结构
3.1 模型改进
利用ReLu激活函数替代LeNet-5中的Sigmoid激活函数,避免指数预算和梯度消失,提升计算速度。对模型参数做如下优化:①将卷积核大小减小为3×3,并减少1层卷积,以加速网络在卷积操作时的速度;②增加卷积层(c1,c2)的通道数,以提升网络的特征提取能力;③增加1层全连接层,以提升网络的分类能力。改进后的模型参数见表1。

表1 改进后的模型参数
为提高模型的泛化能力,在训练时加入L2正则化和“Dropout”[8]方法,以提升模型面对现实数据时的分类正确性。训练时采用指数衰减学习率的方法,以使模型更容易训练到最优参数。
3.2 模型压缩
边缘计算设备储存空间有限,且受传输网络带宽的限制,为使模型更适合边缘平台,需要在精确度允许的范围内对模型进行压缩。LeNet-C模型各层参数数量见表2。其中,f1层参数的数量占整个模型参数数量的99.52%,因此,只需对f1层进行压缩,即可有效减小模型的大小。

表2 LeNet-C模型各层参数数量
借鉴奇异值分解(SVD)的思想,对模型进行压缩,可在保留模型大部分信息的同时,有效减小模型的大小。假设对任意实矩阵,利用SVD可被分解为:
Wm×n=Um×mSm×nVTn×n
(1)

取最大的前k个奇异值(σ1,σ2,…,σk)近似地还原矩阵Wm×n,即可对矩阵Wm×n进行压缩:
(2)
未压缩时的计算过程为Y=XW,通过奇异值分解,将矩阵W分解为矩阵U,S,V后,再将S和V相乘得到T,则计算过程变为M=XUT。压缩之后,在计算方面,增加了1次矩阵乘法运算;在参数数量方面,由mn变为了mk+kn=k(m+n),空间复杂度由O(mn)变为了O(m+n),只要选取不同的k值,即可以不同的压缩率对矩阵Wm×n进行压缩。SVD压缩模型示意图如图4所示。

图4 SVD压缩模型示意图
4 实验结果与分析
4.1 模型检验
采用MNIST手写数字数据集对模型进行训练,训练批量大小batch_size=100,学习率初始值μ′=0.05,学习率衰减率r=0.99,正则化率R=0.0001,损失函数采用交叉熵定义。经过30 000轮训练后,损失收敛,训练完成。对比LeNet-C与其他主流神经网络在边缘计算设备Jetson Nano上的性能,推断框架为Tensorflow。各神经网络在Jetson Nano上的性能对比见表3。由表3可以看出,在精确度相差不多的情况下,LeNet-C的推断时间和模型大小都大大优于其他模型,并且准确率达到了99.37%,更适合应用在边缘计算设备上。

表3 各神经网络在Jetson Nano上的性能对比
为找到合适的模型压缩率,对f1层保留的参数数量分别设置为原来的75%,50%,25%,20%,15%,10%,5%进行实验,比较压缩后模型在测试集上的精确度以及在Jetson Nano上运行1 000次的推断时间和模型大小。模型压缩后性能比较见表4。由表4可以看出,随着模型压缩程度增加,推断时间逐渐减少,精确度也逐渐下降。这是因为模型的参数主要集中在f1层,所以模型的大小也基本随着模型压缩程度的增加而等比例减小。为了保证系统的实用性,需要在精度、推断速度以及模型大小之间取舍。本文选择f1层保留程度为15%的模型进行部署,其精确度相比原模型只减小了3.36%,但推断时间为原来的87.54%,减少了12.46%;模型大小为原来的16.26%,减小了83.74%。

表4 模型压缩后性能比较
4.2 模型部署
在边缘计算设备Jetson Nano[9]上,进行模型部署实验,3种框架部署模型对比结果见表5。由表5可以看出,OpenCV和TensorRT相比于Tensorflow拥有更快的推断速度和更小的内存占用。同时,OpenCV比TensorRT的推断速度快了近1倍,内存占用仅为其8.08%。实验结果表明,OpenCV更适合部署本文所提出的LeNet-C网络模型,其在边缘计算设备上具有更好的性能。
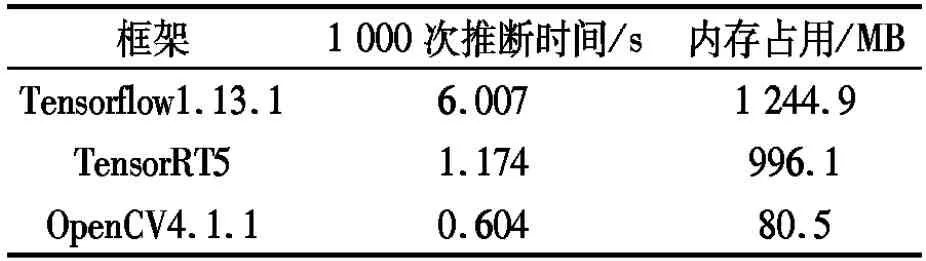
表5 3种框架部署模型对比结果
4.3 系统检验
为检验系统性能,分别利用不同分辨率的输入视频流测试系统实时性。不同分辨率输入视频的FPS见表6。由表6可以看出,本文提出的系统在性能较低的边缘计算设备上对不同分辨率输入的视频都有良好的适应性,其FPS能较好地满足系统需求。

表6 不同分辨率输入视频的FPS
同时,通过表5的推断时间和系统运行时的FPS分析Jetson Nano上的时间消耗,发现其计算瓶颈主要集中在图像处理方面。这是因为其CPU能力较弱,导致了图像处理的时间较长;而在神经网络推断方面,因为本文提出的系统是利用GPU推断,其消耗的时间远远低于图像处理。检验结果证明了在Jetson Nano这类边缘计算设备上运行一些简单的神经网络,其GPU性能已经可以满足需求。
5 结束语
设计了一种适用于边缘计算设备的手写数字识别系统。为了保证其在边缘计算设备上的性能,在图像预处理、神经网络的设计、模型推断框架选择等方面做了一些改进,保证了系统的实用性。分析实验结果可知,利用类似于奇异值分解的方式来对神经网络全连接层进行加速,其在边缘设备上能获得更好的性能。在边缘设备上使用Open CV作为网络推断框架会有更好的效果。在Jetson Nano这类低成本的边缘计算设备中执行轻量级AI任务时CPU的限制要大于GPU。
