改进YOLOv4的红外行人检测方法
2022-10-19史健婷安祥泽
史健婷, 安祥泽, 李 旭
(黑龙江科技大学 计算机与信息工程学院, 哈尔滨 150022)
0 引 言
随着新一代计算机科学和人工智能的发展,无人驾驶在日常生活中得到了广泛的应用,但无人驾驶引起的道路安全问题越来越受到关注,事故的受害者多是缺乏安全保护的行人。为了减少此类事故的发生,在无人驾驶领域引入了车路协同技术来辅助行人检测,车路协同技术利用路边单元传感器获取道路上的行人信息并传输给车辆,帮助无人驾驶车辆提前感知前方路况进行决策。
虽然常见的路边检测设备无法在夜间检测行人,但可以使用红外辐射捕捉所需的行人信息。早期行人检测算法主要包括HOG+SVM[1]、DPM[2]等,近年来,随着深度学习的逐步发展,计算机视觉领域中深度学习模型逐渐取代传统机器学习算法。目前,目标检测算法有基于候选框的“两步走”方法,包括Fast RCNN[3]、Faster RCNN[4]、Mask RCNN[5],准确率高但耗时严重;还有一种是直接从图片获得预测结果的“一步走”方法,包括SSD[6]、YOLO系列算法,相比“两步走”方法,检测速度快,可以满足实时检测的需求。“一步走”方法中最具代表性的是YOLO系列算法,YOLOv1[7]其输入尺寸固定,但对小目标物体的检测效果较差,YOLOv2[8]去除全连接层,提高了检测速度。YOLOv3[9]得到了较好检测性能,能够有效检测出小目标物体,但检测速度没有显著提升,YOLOv4[10]不仅在运算速度上明显提升,检测精度上也有同样提升。笔者通过改进YOLOv4算法,以实现红外图像中行人检测速度和精度的双重提高。
1 YOLOv4网络算法结构
2020年,Alexey等[10]提出的YOLOv4相比YOLOv3,准确率明显提升。YOLOv4输入端采用了Mosaic对输入图像进行数据增强,以达到数据集扩充的目的。主干网络采用CspDarknet53,运用mish激活函数和dropblock缓解过拟合,在Neck层加入空间金字塔池化(SPP)模块,显著提高了感受野,模型通过路径聚合网络(PANet)对参数进行聚合。YOLOv4主要由输入层、主干特征提取网络、路径聚合网络和输出层组成,网络结构如图1所示。

图1 YOLOv4网络Fig. 1 YOLOv4 overall network
YOLOv4的主干特征提取网络采用CSPDarknet53,由5个残差模块组成,每个残差模块由多个卷积、标准化和Mish函数组成。由于主CSPDarknet53由大量的卷积组成,这必然产生大量的计算开销,为提升检测精度,却耗损牺牲了检测速度。目前,主流的提升检测速度的框架有YOLOv4-tiny、以Mobilenetv3[11]为Backbone的YOLOv4-lite,虽然检测速率提升了,但是却耗损牺牲了检测精度。为了均衡检测网络的精度与速度,文中采用Ghostnet[12]提取特征,不仅实现了检测网络的轻量化以及灵活性,而且在保持高检测精度的情况下,实现了模型检测速度的提高,同时在Ghost net的基础块中添加CBAM注意力模块[13]增强网络的特征获取能力从而提升精度。
2 改进的YOLOv4检测算法
2.1 Ghost net网络
相比传统卷积层,Ghost模块由两部组成如图2所示。在第一部分中,利用普通的卷积层得到简化的特征映射,并与第二部分的廉价操作得到的特征映射进行拼接,得到最终的特征。Ghost模块为了最大限度减少网络中参数的冗余,会通过降低参数的规模和滤波器的数量获得更多特征图层。

图2 Ghost模块Fig. 2 Ghost module
Ghost bottleneck(G-bneck)是以Ghost模块的优点为基础构建出来的。它由两部分组成,第一部分是两个顺序串联的Ghost模块;第二部分是一个残差边,如图3所示。前一个Ghost模块增加特征通道,为了符合shortcut通道,后一个模块减少特征通道,最后将原始输入与第二个模块的输出连接[14]。G-bneck中的第二个Ghost模块之后只使批量归一化(Batch normalization,BN),其余各层在每层之后均采取了BN和ReLU激活函数(文中将ReLU替换为LeakyReLU)相结合的方式。当步长为2时,会在原始Ghost模块间加入相同步长的深度卷积。
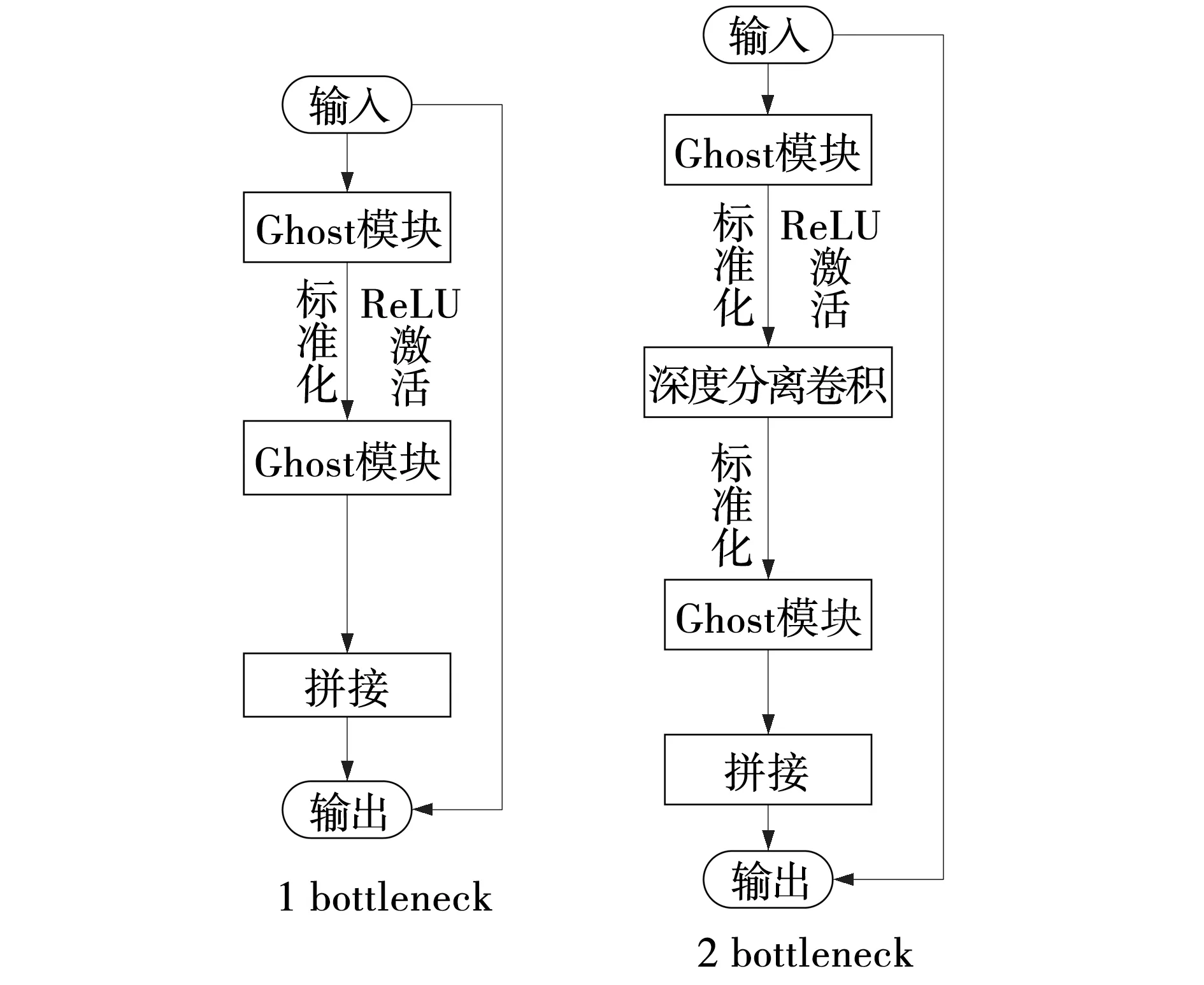
图3 Ghost bottleneckFig. 3 Ghost bottleneck
Ghost模型中使用的ReLU激活函数有一个缺点,即当输入值为负时,其输出始终为0,则神经元无法继续学习,神经元“死亡”,而在LeakyReLU中,神经元可以继续学习。Leaky ReLU消除了当输入小于零时Relu所导致神经元“死亡”的现象,LeakReLU的计算公式为
(1)
式中,ai——区间内的固定参数,ai∈(1,+∞)。
2.2 CBAM注意力模块
为了进一步提升行人检测的准确率,将CBAM引入Ghostnet的GhostNetBottle中,对特征进行自适应细化处理[15]。
CBAM基于空间和通道维度分为通道注意力模块(Channel attention module,CAM)和空间注意力模块(Spatial attention module,SAM)[16]。按顺序组合这两个模块,如图4所示。
输入特征图F∈RC×H×W,CBAM将首先获得CAM特征图Mc∈RC×1×1,经过张量积后,再得到二维SAM特征图Ms∈R1×H×W,公式为
F′=Mc(F)⊗F,
(2)
F″ =Ms(F′)⊗F′,
(3)
式中:⊗——张量积;
F′——通过张量计算Mc∈RC×1×1与F获得;
F″——通过张量计算Ms∈R1×H×W与F′获得。

图4 CBAM注意力模块Fig. 4 Convolution block attention module

(4)
式中:σ——sigmoid函数;
PA(F)——将平均池化的F放入感知机;
PM(F)——将最大池化的F放入感知机。
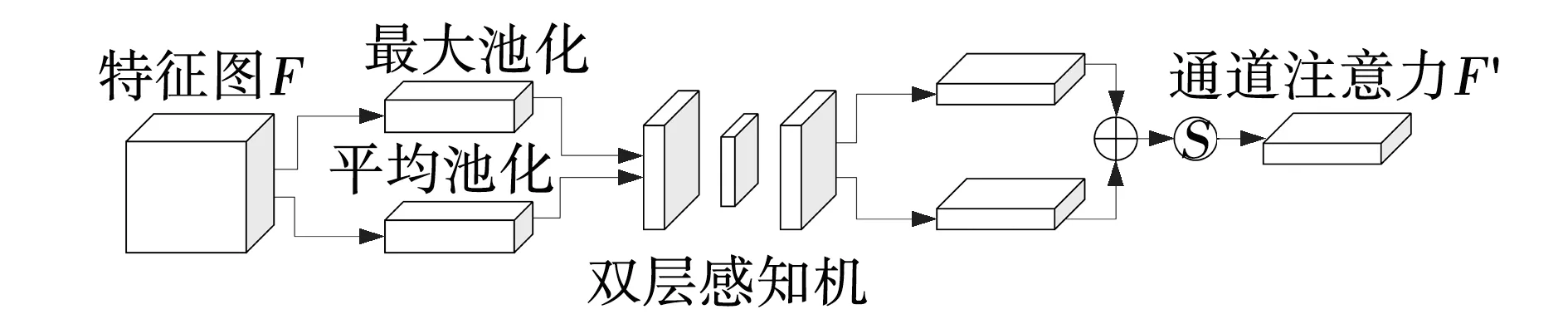
图5 通道注意力模块Fig. 5 Channel attention module
SAM关注输入的图像特征中有意义的位置,由式(2)中获得的特征图F′为SAM的输入,如图6所示。
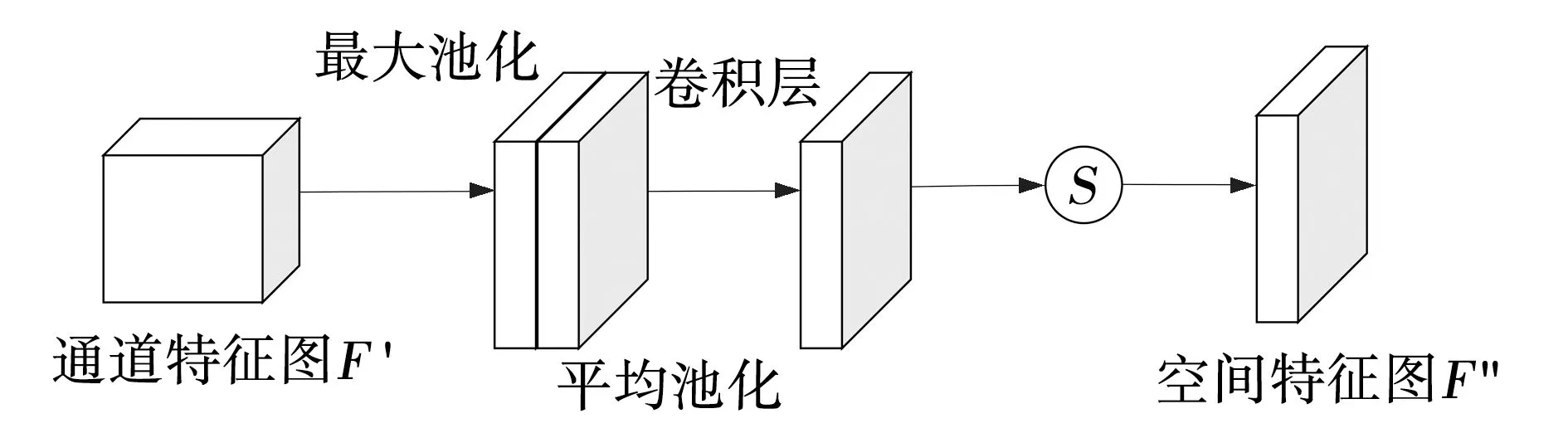
图6 空间注意力模块Fig. 6 Spatial attention module
(5)
式中:σ——sigmoid函数;
f7×7——7×7过滤器的卷积。
2.3 整体架构
YOLO-Ghostnet整体结构如图7所示。在图像输入到网络之前,将其尺寸调整到416×416×3再输入到网络,图像经主干网络Ghostnet后得到不同层的图像特征,其中,图像特征分别在Ghost Bottleneck(GBN)为第5、11、16层时进行提取。
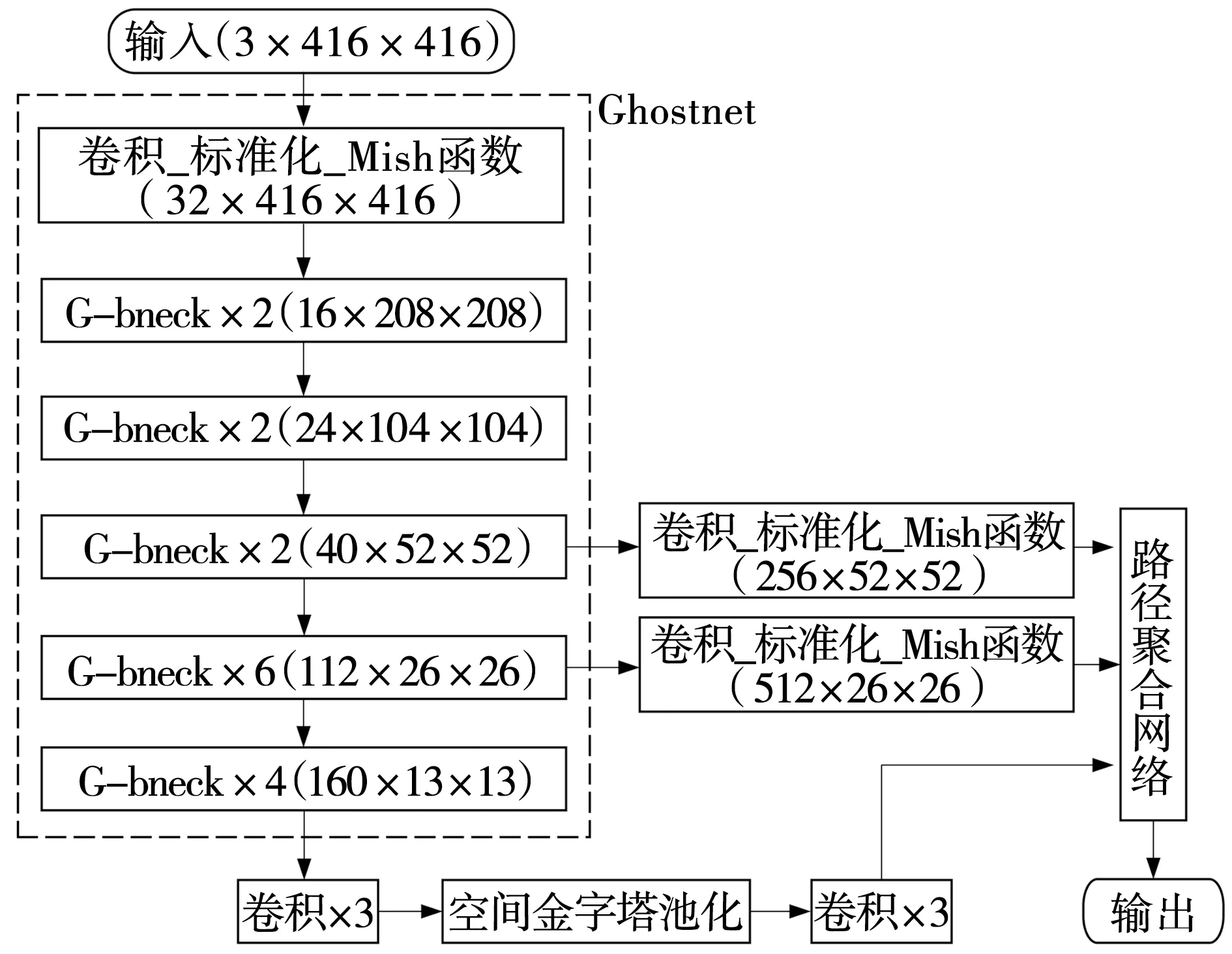
图7 YOLO-GhostnetFig. 7 YOLO-Ghostnet
G-bneck提取图像特征,通过SPP池化堆叠,利用特征金字塔结构从上下采样中重复提取特征。分离出最显著的上下文特征[19],获得尺度分别为52×52、26×26和13×13的特征层。每个特征层有三个先验框,包括先验框的坐标、置信度和一类的概率,最后,得到了3个尺寸分别为52×52×18、26×26×18和13×13×18的特征层。
3 实验结果与分析
实验环境为Win10系统,使用Pytorch(1.7.1)框架进行网络结构修改,CPU为AMD Ryzen7-4800H,GPU为Nvidia RTX2060,Cuda 版本为11.0。
3.1 实验参数
实验采用数据集来自OSU Thermal Pe-destrian Database[20],此数据集共有7 942张,经数据清洗后筛选出1 825,训练集和测试集比例为5∶1。在实验的训练和测试中,图片输入格式为416× 416 的JPG文件,轻量化后的YOLO-Ghostnet batchsize 可以提升至8。训练时网络batchsize均为4 ,学习率初始设置为0.001,同时,开启余弦退火衰减学习法调节学习率,平滑标签 smooth_label设置为0.001。
3.2 模型性能对比
实验中使用初始权重对行人检测网络从零开始训练100个epoch,分别对YOLOv4、YOLOv4-lite、YOLOv4-Ghost、YOLOv4-Ghost+cbam、YOLOv4-Ghost+cbam+leaky(改进后的YOLOv4模型)进行训练和测试,呈现YOLOv4-lite和改进的YOLOv4模型的效果如图8所示。

图8 检测结果对比Fig. 8 Comparison of detection results
图8a、c是YOLOv4-lite的实际结果,图8b、d是改进的YOLOv4结果。从图8可以看出,在两种不同的真实场景中,改进后YOLOv4模型检测精度优于YOLOv4-lite模型,面对复杂多行人场景,YOLOv4-lite模型会丢失目标,而改进后的YOLO v4模型会检测到所有目标,精度更高,整体鲁棒性更强。
对YOLOv4、YOLOv4-lite、改进的YOLOv4和YOLOv4-Ghostnet在性能指标上进行比较,如表2所示。文中单类目标检测精度由平均精度值αAP来衡量,AP是PR曲线上准确率的平均值,通过FPS评估检测帧率βFPS以及单张照片检测时间t评估实时速度。
从表2可以看出,YOLOv4网络具有很高的检测精度但是需要比较长的检测时间,检测的FPS也偏低。YOLOv4-lite在牺牲了5.9%的精度后将FPS提升了14.46,检测时间减少了12.72 ms。再经过更换Ghost网络、添加cbam注意力模块、改成LeakyRelu激活函数后AP仅下降了0.84%,FPS提升了13.35,单张照片检测时间降低了12.07 ms。即改进后的模型在维持精度的情况下,大幅降低了检测时间并提高了检测时的FPS。

表2 模型检测性能对比
4 结 论
(1)改进了YOLOv4的原网络模型,采用Ghostnet取代原有骨干网络,保留原有的路径聚合网络的情况下,相比于传统方法检测速度提升24%,与同类型轻量化网络相比准确率提升了2.7%。改进的模型提升了检测速度并且维持检测精度。
(2)为进一步实现红外行人的准确识别,改进了Ghostnet,将CBAM注意力模块和LeakyReLU激活函数与Ghostnet网络相结合,使用文中改进的Ghostnet后,模型降低了82%的参数量,更加方便在移动嵌入式设备上部署检测网络。相比原网络,改进后的模型不仅在实时检测速度方面提升了32.8%,而且保留了原网络的高精度的优点,比同类型轻量化网络准确率提升了5%。
