改进YOLOv3的轻量级车辆目标检测算法
2022-10-19陈义平刘世圣
陈义平, 刘世圣, 时 颖
(黑龙江科技大学 电子与信息工程学院, 哈尔滨 150022)
0 引 言
车辆检测与车型识别是智能交通系统运行中的核心技术,能为智能交通调度和交通状态数据分析提供有效支撑。传统车辆检测算法如背景更新法[1]、帧差法[2]和光流法[3]等通过提取视频中运动目标来识别车辆,在精度、计算量和适用场景等方面均存在着较大缺陷,无法满足智能交通系统所需的实时、高精度车辆检测需求。随着人工智能技术的迅速发展,深度学习成为智能交通领域中解决车辆检测及车型识别问题的有效方法。
车辆检测技术主要依赖于目标检测算法,而目前基于深度学习的目标检测算法分为双阶段和单阶段两种。在双阶段方案中,典型的网络有R-CNN[4]、Fast R-CNN[5]、Faster R-CNN[6]和SPP-Net[7]等,尽管这一类网络具有较高的准确性,但是候选框选择时间过长,导致检测速度较慢,无法满足智能交通的实时性要求。在单阶段方案中,具有代表性的是YOLO系列算法[8],该系列算法直接通过CNN预测目标物体的方位和类别,不再选取候选框,检测速率有了很大提升,但是准确度低于双阶段算法。YOLOv3[9]目标检测算法能有效协调检测速度与准确率之间的关系,综合性能较好,与其他网络模型相比,在速度和准确率方面均处于较高水平,但对于车辆数量大、车型种类多的交通系统,该算法仍存在网络模型臃肿、计算量过大的问题。为此,笔者通过引入新特征提取网络减少参数量,优化特征损失函数,运用非极大值抑制算法,提高车辆检测与车型识别性能。
1 YOLOv3结构与检测算法
YOLOv3网络结构主要由两部分组成,分别是图片特征提取网络Darknet-53和检测层,其利用的是全卷积层,调整或修改特征图尺寸均由卷积层实现。该特征提取网络是一种典型的深层网络,既能够确保对特征进行表达,还可以防止网络过深带来的梯度问题,通过利用ResNet增加网络的层数来提高网络检测的准确率。在检测网络中还引进了FPN,对三种尺度不相同的特征图进行检测,增强了对各种尺度目标的检测能力。网络结构如图1所示。
针对车辆识别网络模型的臃肿和计算量过大的问题,通过引入一个优化特征提取网络MobileViT-HS来减少YOLOv3的参数量,其次考虑到车辆检测漏检的情况,结合特征损失函数和非极大值抑制算法进一步优化车辆检测与识别算法。
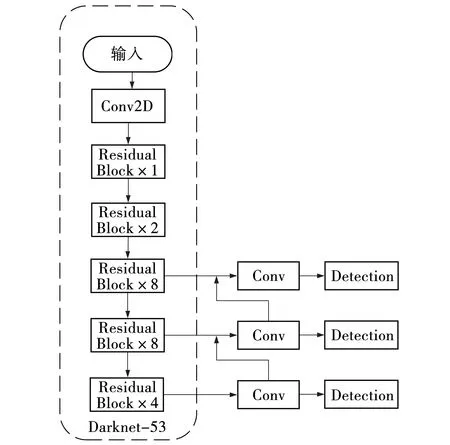
图1 YOLOv3网络结构Fig. 1 YOLOv3 network structure
1.1 特征提取及网络优化
YOLOv3中特征提取网络是Darknet-53,但该网络在进行特征提取时会增加网络的参数量和计算量,而且其网络过深,会出现冗余参数、梯度消失等问题。由于移动设备的计算资源有限,使网络模型移植愈发困难,整个网络的训练难度也会更大,因此文中将Darknet-53替换为MobileViT网络,以此进行优化网络性能。
1.1.1 MobileViT网络
文献[10]提出了MobileViT结构,将CNN和ViT的优势结合起来,既满足轻量化要求,同时还能保证低延迟的网络。MobileViT可以通过不同的角度来学习全局表征,在不同任务和数据集上的效果明显优于CNN和ViT网络。MobileViT的结构图如图2所示。MV2是MobileNetV2模块的缩写,如图3所示。执行向下采样操作标记为↓2,对于输入张量中的局部和全局信息,该模块能够用较少的参数对其进行建模。给定一个输入张量X∈RH×W×C,MobileViT先通过一个n×n标准卷积层对局部空间信息进行编码;接着进行逐点(或1×1)卷积,利用学习输入通道的线性组合将张量投影到高维空间中,得到XL∈RH×W×d;接着将XL展开,变成N个互相不重叠的图像块XU∈RP×N×d,其中,P=WH,N=HW/P。通过Transformer实现各个图像块之间的编码,其关系为
XG(p)=T(XU(p)),1≤p≤P。
(1)
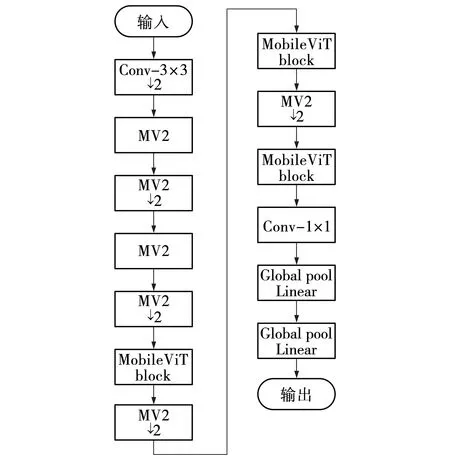
图2 MobileViT结构Fig. 2 MobileViT structure
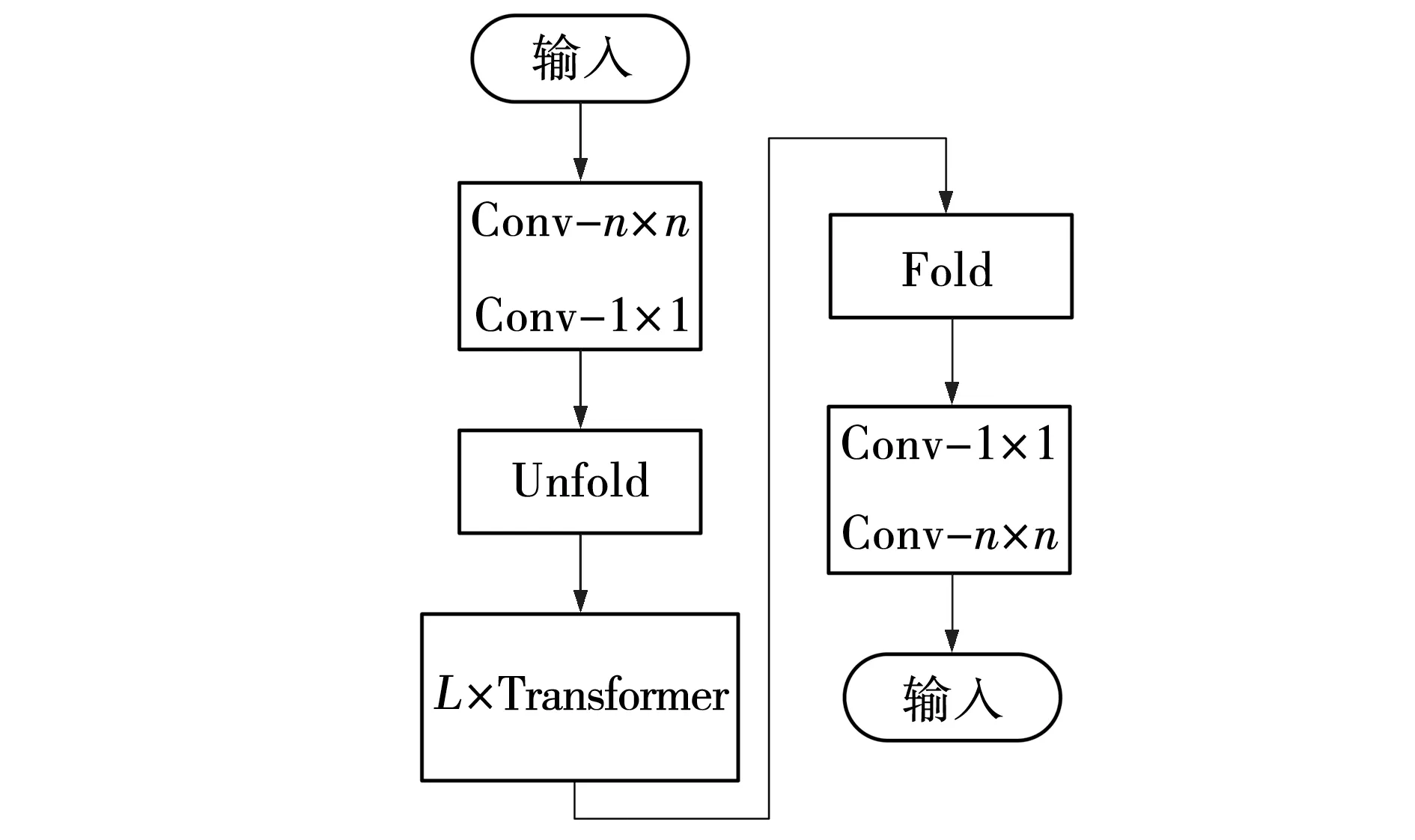
图3 MobileViT模块Fig. 3 MobileViT block
在MobileViT中,各个像素都可以感知到其他像素,如图4所示。中心的红色像素利用Transformer模型能够感知到其他图像块中对应位置的像素(蓝色像素)。由于蓝色像素已经通过卷积的方法对相邻像素的信息进行了编码,这就为红色像素对该图片中所有像素信息的编码提供了前提条件。
MobileViT模块用更深的全局处理来替代卷积中的局部处理,所以MobileViT具有卷积类似的特性。MobileViT模块通过标准卷积和Transformer分别学习局部表征和全局表征时,用这些层设计出的网络参数量非常大,但MobileViT利用卷积和Transformer,使MobileViT模块不但有卷积的特性,还能够对全局进行建模,因此MobileViT能够以更少的通道数和更浅的网络去实现更好的网络性能[11]。

图4 MobileViT block中的各个像素Fig. 4 Individual pixels in MobileViT block
1.1.2 MobileViT网络的优化
由图2可知,MobileViT算法中MobileNetV2模块几乎贯穿整个MobileViT算法。 MobileNetV2中的Swish[12]激活函数相当于是Sigmoid函数与输入x二者的结合,Swish激活函数及其导数的表达式为
(2)
(3)
由于Swish激活函数中包含着Sigmoid函数,而Sigmoid函数在反向传播中的求导运算比较复杂且收敛情况不够稳定。H-Swish函数相当于Swish激活函数的简化版[12]。由于ReLU6激活函数比较简单,在计算成本方面远低于Swish激活函数,因此H-Swish激活函数Swi(x)把Swish激活函数的思想与ReLU6激活函数R(x)相结合,其计算公式为
(4)
R(x)=min(6,max(0,x))。
(5)
H-Swish整体是通过ReLU变体得来的,利用ReLU6限制ReLU输出的最大值,使其变为6,此后当输出大于6时,其导数则变为0,降低了该函数的计算量。式(4)中的(R(x+3))/6可近似看成Si(x),但它的计算方式更简便,有助于提升计算效率。其导数为
(6)
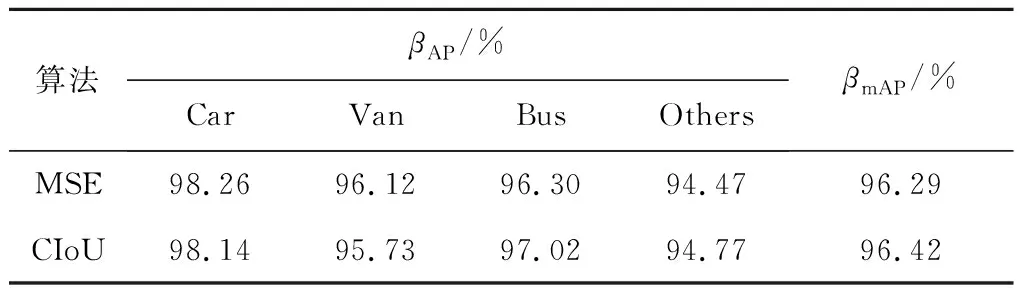
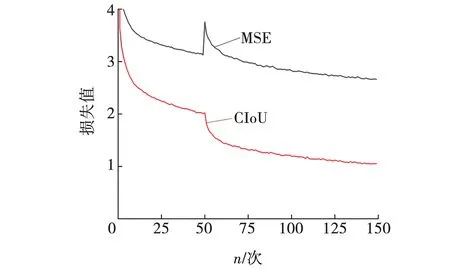
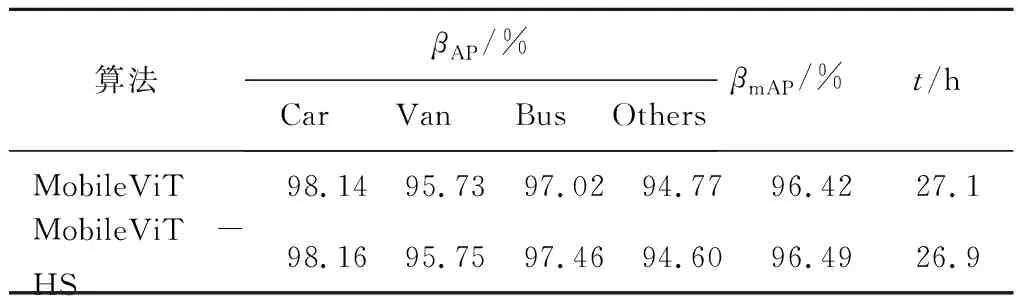
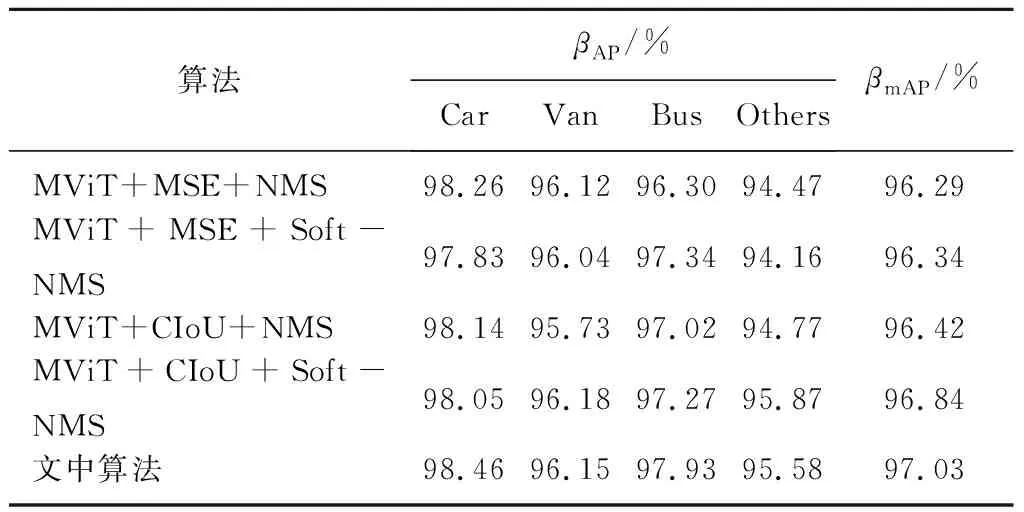
由式(6)可知,H-Swish是一个分段函数,当-3 传统的目标检测一般采用均方误差损失函数在预测框的中心位置坐标和宽高上直接进行回归预测,但是估计预测框每个点的坐标数值只是将这些点视为独立的变量,并没有把目标看作一个整体去进行预测。研究者们给出了一种方法:用IoU损失函数取代MSE损失函数,在诸多IoU类型的损失函数中,CIoU引入了长与宽的比值,所以收敛速度更快,目标框的回归也变得更加稳定,计算公式为 (7) LCIoU=1-βIoU+βCIoU, (8) 式中:ρ2(b,bgt)——真实框中心点与预测框中心点之间的欧氏距离; c——同时包含A框和B框的最小封闭图形中的对角线距离。 α和ν的公式为 (9) (10) 式中:wgt、hgt——真实框的宽和长; w、h——对应预测框的宽和长。 由于CIoU考虑了真实框与预测框的中心点间距、重叠率和长宽比,使其对预测框的回归变得更加稳定,不会出现训练发散问题。而且CIoU对预测框尺度的改变并不敏感,具有尺度不变特性,故选取CIoU Loss替代文中车辆识别算法中的回归损失,完成损失函数的优化操作。 YOLOv3使用非极大值抑制算法(Non-maximum suppression,NMS)对区域候选网络输出的冗余候选框进行筛除。在车辆检测任务中,道路上容易出现车辆较为密集(车辆重叠)的情况,该情况下NMS算法会抑制原本属于两个车辆的边框,导致出现漏检现象。 针对NMS的缺点,Bodla等[13]提出了Soft-NMS算法。该算法能有效提升模型的容错率,NMS计算公式为 (11) Soft-NMS计算公式为 (12) 式中,σ——n个预测框的计算复杂度。 Soft-NMS算法是在原始总的预测框列表B中取出一个预测框bi,先计算这个框和框M的IoU,其与NMS不同的是,如果IoU大于预先设定的阈值Nt,列表B和检测得分列表S并不会直接将预测框bi及其得分si进行删除,而是将框bi与框M的IoU值和该预测框的检测得分si相乘,然后把相乘得到的值重新作为该预测框bi的检测得分继续执行检测。利用该方法能够逐渐降低预测框bi的检测得分,而不是像NMS算法那样直接被删除,所以文中在检测阶段引入了Soft-NMS算法来避免原有的NMS中对大于阈值的候选框直接进行删除的情况,Soft-NMS在车辆密集情况下能有效避免车辆重叠的区域候选框,减少误检和漏检问题,从而提高车辆检测的精度。 基本实验环境为:Win10系统,NVIDIA GeForce RTX2070 Super显卡,PyTorch深度学习架构,编译环境为Python3.8,开发环境为PyCharm Community Edition 2021.1.3。 2.1.1 数据集 UA-DETRAC数据集是一个有14万多帧和8 000多张人工注释的汽车数据集,该数据集中将汽车种类分为四类,分别是car(轿车)、bus(公共汽车)、van(面包车)和others(其他)。为了防止数据集样本过于单一,本实验的数据集中还加入了VOC数据集,减少过拟合现象的同时,还能增加训练样本的全面性,其车辆类型有轿车、公共汽车、自行车等。实验中所有网络的训练和测试,一共包含16 573张图像。将这16 573张图像划分成3个子集,分别用于训练、验证以及测试。 2.1.2 数据增强 文中对数据集使用Mosaic数据增强,它是一个比较综合的增强方法,核心思想则是随机裁剪多张图片,再加以拼接从而形成新的图像(将4张图片按一定的比例组合成1张新的图片)。该方法将图像缩放、裁剪和旋转相结合,不仅提高了图片背景信息的多样性,还增加了每次输入网络的图像批量,使每次获取到的信息量也更多,其流程如图5所示。 图5 Mosaic数据增强流程Fig. 5 Mosaic data enhancement flow 为保证结果公平性,文中实验模型均使用同一数据集。文中每次实验均训练150轮(epoch),该150轮分成了两个阶段,前50epoch都采用冻结训练,学习率为0.001,步长为1,gama为0.98,这个阶段的模型主干都被冻结,网络只进行微调,既可以提高训练效率,又能避免权值被破坏,剩下的100轮则是解冻训练,模型的主干将不再被冻结,网络参数均会发生变化,学习率为0.000 1,长为10,gama为0.9。 2.2.1 直接训练 直接使用传统的YOLOv3与文中提出的轻量化模型进行训练,训练后模型用于检测,本次实验均使用Mosaic数据增强,对比实验结果如表1所示。 从表1可知,文中提出的轻量化算法相比于YOLOv3算法准确度略有提升,提高了0.46%,在模型参数量方面表现优异,参数量不足原来的二分之一,仅为YOLOv3参数量的42%,因此训练时间也缩减了约30%,FPS也得到了很大提升。这说明通过Mosaic数据增强、优化YOLOv3网络提取特征等方法进行训练后,提升了算法效率,并在一定程度上提高了该算法的准确度,其检测效果如图6所示。 表1 直接训练结果对比 图6 车辆检测效果Fig. 6 Vehicle detection 由图6可以看出,即使在车辆图片模糊的状态下,文中算法依旧可以精确地检测。 2.2.2 损失函数优化实验分析 为了验证损失函数优化的有效性,针对两种损失函数在算法中的性能表现进行了对比实验,实验均使用Mosaic数据增强、NMS算法,设置相同置信度等参数进行测试,实验结果如表2所示。 表2 损失函数优化的AP和mAP对比 由表2可知,MobileViT经过损失函数优化后性能略有提升,mAP提高了约0.13%。 损失函数对比曲线如图7所示。由图7可以看出,训练刚开始时,两者的损失值比较接近,随着epoch的增加,这两个损失值也逐渐下降,在epoch达到50时,损失值的收敛速度变快, YOLOv3算法中的损失值最终稳定在2.7左右,而改进后算法的损失值大约是0.91。相对于YOLOv3算法中的MSE损失函数,将其替换成CIoU作为边界框回归损失后,模型的损失有所减少,检测效果也就更好。 图7 损失对比曲线Fig. 7 Loss contrast curve 2.2.3 特征提取网络优化实验分析 为了验证特征提取网络优化的有效性,对MobileViT和MobileViT-HS网络性能进行比较,实验均使用Mosaic数据增强和NMS方法,损失函数为CIoU,结果如表3所示, 表3 特征提取网络的AP、mAP和训练时间对比 总体来看,整体准确度比原算法提高了0.07%,在此基础上,优化后算法的训练时间比原算法缩减了0.2 h,证明了H-Swish激活函数在计算量方面占有优势,该激活函数更适合应用在移动设备上。 2.2.4 综合实验分析 为了验证优化网络轻量化模型的有效性,对MobileViT与采用MobileViT-HS优化网络的轻量化模型进行比较,实验均使用Mosaic数据增强,实验结果如表4所示。 从表4可以看出,随着算法的不断改进,准确度也在不断提高,与最原始的算法相比,文中提出的算法在识别各种车型时的精确度均有所提升,整体的精确度提高了0.77%。针对车辆漏检的情况进行优化,其结果对比如图8所示。 表4 综合实验结果 图8 算法优化前后效果对比Fig. 8 Comparison of effect before and after algorithm improvement 由图8可见,MobileViT+MSE+NMS算法会由于车辆重叠或遮挡等原因易产生车辆漏检问题,而文中在使用CIoU损失函数和Soft-NMS算法后,车辆漏检得到了有效的解决,达到了预期目标,证明了文中对算法优化的有效性。 (1)从车辆识别算法准确度的提升、网络模型参数的减少以及实际应用场景中面临的各种问题三个方面进行了深入研究。通过将YOLOv3算法的特征提取网络调整为MobileViT网络,并对MobileViT网络的激活函数进行优化,使改进算法的参数量仅为YOLOv3的42%,训练时间减少了约29%,FPS提升了近40%。 (2)针对车辆目标漏检问题,文中对车辆识别算法进行了有针对性的优化,对其损失函数和非极大值抑制算法进行调整,实验证明,改进后的算法在保证检测精度的情况下,收敛速度更快且漏检问题得到了有效改善。1.2 损失函数优化
1.3 非极大抑制算法优化
2 实验与分析
2.1 数据集及数据增强
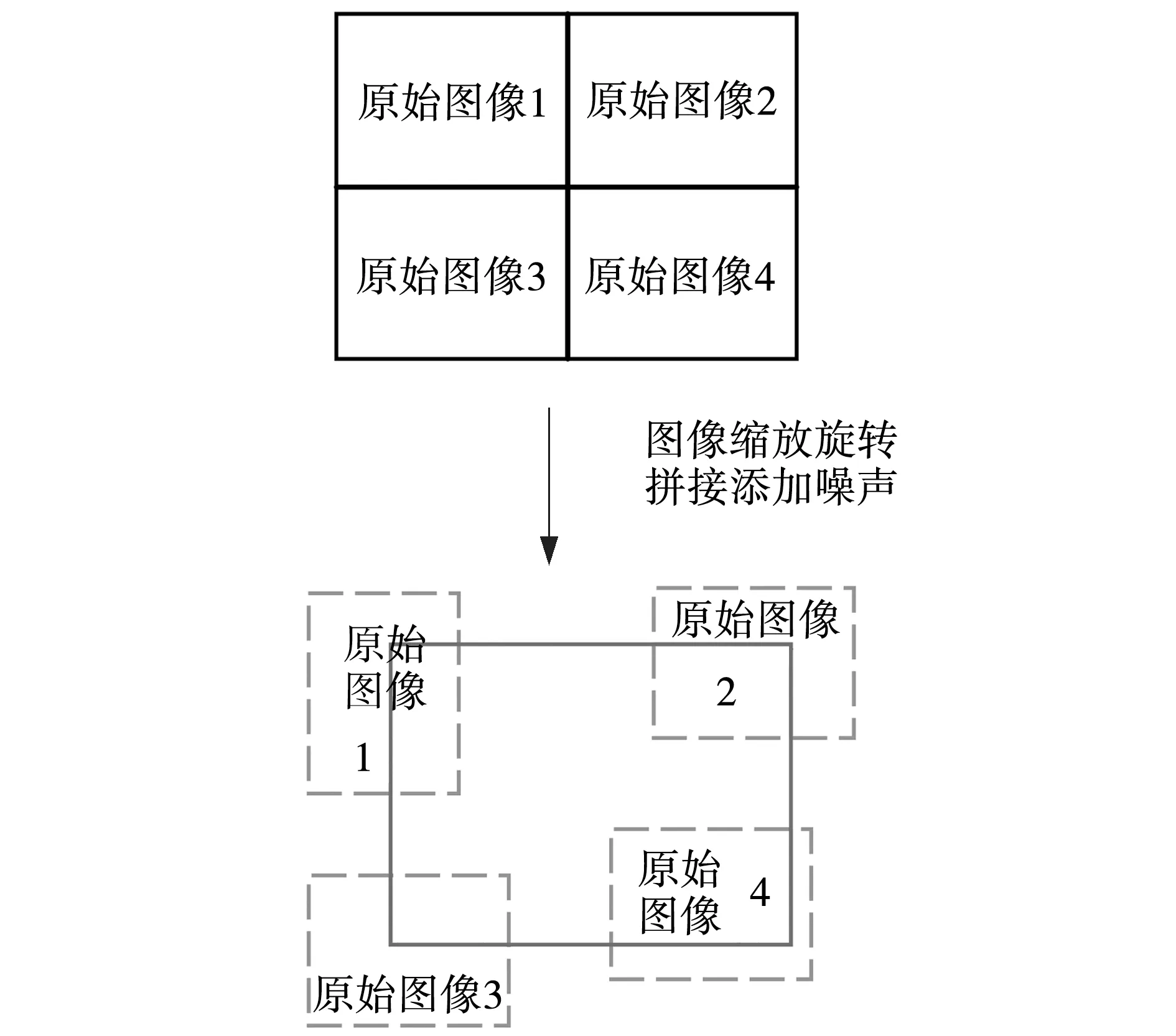
2.2 实验结果与分析



3 结 论
