基于神经网络的电力二次系统攻击预测
2022-10-19孙理昊
孙理昊
(北京科东电力控制系统有限责任公司 通讯与安全分公司 网络安全集成部,北京, 100192)
0 引言
近年来,我国经济、通信技术以及数字信息技术得到了快速发展,为数字化电网和智能电网提供了发展平台[1~3]。随着智能电网的大力建设,电网规模日益庞大复杂,使得电网的安全问题日益突出。此外,云计算、物联网以及大数据的加入,又使智能电网增加了网络攻击、病毒木马攻击、信息泄露等安全防护方面的挑战[4,5]。电力的持续供应及安全运行是我国经济平稳发展、社会和谐稳定以及工业的安全基本保障[6]。因此,需要对智能电网电力二次系统进行防护和预测研究。
目前的攻击形式主要是复杂多变、逻辑紧密的多步和连续攻击。除了对攻击产生的告警进行关联和排序并做出应对策略外,针对攻击的预测和采取针对性的预防操作也变得更加重要。电力二次系统中攻击预测方法有博弈论[7]、时间序列[8,9]、以及其他概率模型[10,11]等。然而随着近几年的智能算法的涌现,神经网络被广泛地应用到攻击预测中。夏勇军等人[12]根据二次系统的功能特点提出一种针对电力二次系统的智能配电网评估方法,实现了对智能配电网节点的可靠性评估。陈闻卿[13]通过对目前国家加密算法的研究,提出将SM2加密算法应用在电力二次保护嵌入式系统中,结果表明该算法可以有效实现用户身份真伪辨别,增加了身份认证的安全性。Tan[14]等人针对智能电网现有研究的缺陷,提出了一个基于GridLAB-D、ns-3和FNCS的智能电网攻击联合仿真框架。该仿真能够模拟智能电网基础设施的各种网络安全攻击功能,然后自动可视化其后果。QS[15]等人研究了动态负载攻击下智能电网的攻击检测问题。并设计了自适应滑模观测器,在阈值和残差对比的基础上,应用攻击检测逻辑来完成攻击的检测。但是,对于多目标的动态入侵研究较少,且针对此种攻击方式的攻击链获取方法和预测模型难以在电网中直接适用。
本文首先针对多目标、复杂的入侵,提出了通过节点信息结构化、聚合子节点、深度遍历三个环节来实现IP关联的攻击链提取方法;在此基础上,为了减少传统的攻击预测方法及模型存在的预测能力差、可移植性差和共享性低的问题,提出了自注意力改进的Bi-LSTM(Self-Attention-Bi-LSTM)预测模型,该模型基于前后文时序进行分析,预测速度快、攻击链学习时间短、自动识别攻击链中对预测贡献更高的信息。并在电网数据实验和DARPA数据的实验中证明了该模型的准确性和有效性。
1 IP关联的攻击链提取
入侵行为通常具有动态、多目标及协同攻击中的一种甚至多种特点。尤其是多目标入侵,它的攻击之间的逻辑关系、匹配顺序以及因果关系影响着入侵行为的判断。然而在电力二次系统中,复杂入侵行为表现为有规律可循告警序列,因此基于此特点提取的入侵行为攻击链有利于后续对入侵行为的预测。
在攻击链的提取可以分为节点信息结构化、聚合子节点、深度遍历三个环节来实现。其中节点信息结构化就是将告警日志以树状图的结构表达出来。把多个单步攻击经过特定的方法组合成完整的攻击过程,此过程以多步攻击的方式呈现。而攻击链则是攻击过程的结构化体现。
提取攻击链时,首先对节点信息进行结构化处理。在攻击链中,节点的地址用IP表示,告警信息用WM(warning message, WM)表示。四节点的攻击链可以表示为如图1所示。将图1中攻击链的告警日志整理成直观地表达,如表1所示。使用节点类对每一个节点进行建模,节点类包含自身的地址、父类节点地址、子类节点的告警信息等。采用节点类实现了表1中告警日志树状结构的表达,如图2所示。图中每一个地址由唯一节点表示,箭头表示从源地址到目的地址的告警。

表1 告警日志列举
告警日志经结构化处理后,形成了容易理解和遍历的树状图。从树状图中没有父类的节点处开始深度遍历,进行第一次的去重,则能够获得初步的攻击链。但是,初步的去重只是去掉了“无双亲”节点,告警日志中依旧存在信息冗余。为了减小冗余信息,加快攻击链的提取速度,在保留告警信息的前提下进行子节点聚合。聚会是在节点树状图的前提下,对所有节点进行遍历。聚合分为两种情况:
(1)若主机1对主机2在连续时间内触发一致的安全事件,且期间主机1有且仅有这一类安全事件,则认为连续时间内出发的事件系同一事件。基于这一前提采用如下聚合方法:遍历每一个节点的子节点,若发现同一个父类下的子节点的告警类型、源地址、目的地址均相同,则对它们进行聚合操作。图3(a)为第一种情况的聚合,子节点个数减少了3个,消减了冗余,除了进行时间合并外,告警信息没有缺失。
(2)设置较短的时间空隙,在此段时间内触发的相同告警都认为是一类安全事件。基于这一前提采用如下聚合方法:遍历每一个节点的子节点,若发现同一个父类下的子节点的告警类型、源地址、目的地址均相同,且时间范围小于设定的时间间隙,则对它们进行聚合操作。图3(b)为第二种情况的聚合,若设置时间间隙为1小时,则图中可合并两个子节点且开始与终止时间小于1小时。

图3 子节点聚合,(a) 第一种情况的聚合(b)第二种情况的聚合
在上述两个环节完成后,对获得的树状图进行深度遍历就能够得到最终的攻击链。在遍历过程中,需要先确定链首告警,表示在此时刻之前没有以该地址为目的的告警发生。与结构化处理相似,链首告警可以分为:无双亲节点和有双亲节点,因此可以分为两次循环。对于无双亲的源IP节点,将每次深度遍历得到的攻击链添加到最终的攻击链集合中;但对于双亲的源IP节点,源IP的告警时间应早于双亲节点的告警时间,同样也需要重复无双亲的操作。
2 神经网络攻击预测模型
神经网络攻击预测模型分为数据处理、编码和预测三部分,如图4所示。其中数据处理是将攻击链分解为能够识别的数据类型,包含攻击链的扩增和样本的分割。编码是抽取攻击链高阶特征,在进行高阶特征抽取时,模型首先用n维的向量把各个IP与WM表示出来,然后将两者拼接成一个2n维的向量(组合后的向量具有IP和WM的上下文语义信息),依次输入到神经网络预测模型中,最后经计算得到编码后的高阶特征。

图4 神经网络攻击预测模型框架
预测部分有两个模块,分别对应于IP和WM模块的预测。预测部分以攻击链的高阶特征作为输入,采用前馈神经网络分类算法进行计算得到预测值,使用梯度下降法进行反向传播,更新模型参数。
为了获取入侵者真实意图及攻击步骤背后所隐藏的状态,依据上文提取的攻击链,采用了LSTM、Bi-LSTM(Bidirectional Long Short-Term Memory, Bi-LSTM)以及自注意力改进的Bi-LSTM预测模型,并对比分析三者对下一步攻击的预测效果。
■2.1 LSTM攻击预测模型及改进
图5是LSTM的攻击预测模型图,LSTM通过内部状态cs记录细胞状态,在节点信息传输过程中,通过选择性遗忘与记忆实现对当前信息的积累和对过往信息的遗忘。

图5 LSTM的攻击预测模型图
Bi-LSTM攻击预测模型解决了LSTM记忆的问题,并充分考虑了正反向序列的相关性;攻击链的时序信息通过Bi-LSTM的双向性和门控机制进行提取,为下一步的攻击预测提供数据分析,图6是Bi-LSTM攻击预测模型。

图6 Bi-LSTM攻击预测模型
■2.2 Self-Attention-Bi-LSTM攻击预测模型
针对攻击链中告警信息的时变性,即不同时刻的信息权重不同,本文提出在Bi-LSTM基础上加入自注意力机制,该方法能够建立动态依赖模型并根据此基础,在告警信息之间生成时变的连接权重,从而获取序列内各元素的特征及其之间逻辑关系,如图7所示。

图7 Self-Attention-Bi-LSTM攻击预测模型
将IP和WM组合的2n维的向量依次输入到Bi-LSTM模型中获取攻击链中的时序信息,其中攻击链正向和反向的序列信息分别通过正向输入的LSTM层和后向输入的LSTM层获取,然后组合两者得到时序信息。在本文中获取每个隐藏单元的输出hi,hi
'通过式(1)拼接得到时序信息hi。

式中,W为自学习的参数矩阵。
然后把hi输入到自注意力层进行权重计算,在计算过程中每个单元的权值由键值对决定,用h=(h1,h2,…,hi)和v= (v1,v2,…,vi)分别表示键和值,用q= (q1,q2,… ,qi)表示查询序列。为了防止计算的sti梯度发散,通过式(2)和式(3)其进行缩放点积和归一化计算:
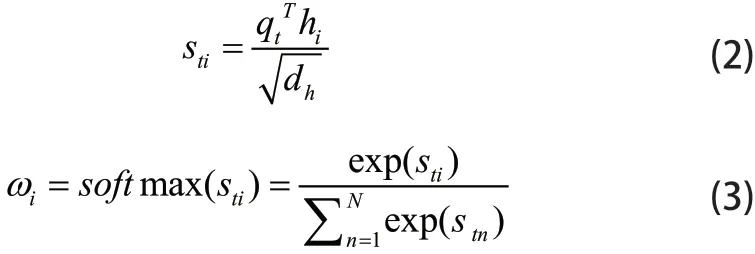
式中,dh为h的维度,sti是注意力得分。
在得到权值iω后,通过公式(4)得到最终的输出向量O(qi,h,v):

Self-Attention-Bi-LSTM利用Bi-LSTM获取攻击链中时序信息及序列的正反向信息,通过引入自注意力机制获取序列内各元素的特征及其之间逻辑关系,将得到的输出向量作为预测部分的输入,进行反向传播和参数训练。
3 实验分析
以国家电网华北区域电力二次系统两个月的告警日志为分析对象,对告警日志进行遍历提取到814条攻击链。为了满足训练的需求,需要进行攻击链的扩增。在本文中把攻击链看成一个集合,则集合中的所有子集都是一条攻击链,换言之,假如攻击链的长度为n,则可以切分为不同时刻下(n-1)条不同长度的攻击子链。对814条攻击链进行分割和扩增,最终得到8963条攻击链;在训练模型时,选用60%的数据集作为训练集,30%的数据集用来验证,剩余10%的数据集则用来测试。
由于攻击链的类别较多且分布不均匀,预测模型的训练会受到数据不均衡的影响,导致难以在准确率和召回率之间权衡。传统的做法是采取平衡数据集处理,但是降低了比重大的类别检测准确率且破坏了样本分布。为了提升模型的预测效果,提出了高级别攻击链ACU评价标准(High Level Chains AUC, HLC-AUC),它能够对模型在更高危的攻击链中的预测效果做出评价,自动识别攻击链中对预测贡献更高的信息。此外,它不仅能够保证高级别攻击链的预测效果,而且还能提升整体的预测精度和准确性。
HLC-AUC通过数值量化分析模型在HLC上的预测性能,但是,对于模型的优化方向却无能为力,因此本文设计了新的损失函数,见公式(5):

式中:iφ第i条攻击链惩罚项系数,L为交叉熵,m为样本个数。
新的损失函数以交叉熵函数为基础,增加高级别攻击链的检测系数,因此在训练过程中会有较大的概率检测到高级别攻击链的错分样本。
■3.1 Self-Attention-Bi-LSTM最优参数整定
Self-Attention-Bi-LSTM在进行参数的整定和择优时,往往依靠经验和多次实验的结果进行动态调整,严重增加运行负荷和预测时间。针对此问题,本文依据HLC-AUC对IP和WM向量长度、输出向量维度及学习速率进行最优参数整定。
Self-Attention-Bi-LSTM预测模型中IP和WM的向量化是利用Embedding层实现的,因此,IP和WM的向量长度sizeIP和sizeWM的选择对模型预测精度和准确性影响很大。为了分析向量长度对预测效果的作用,绘制了sizeIP和sizeWM与HLC-AUC的关系曲线,如图8所示。从图中可以看出,随着sizeIP和sizeWM的增加,Self-Attention-Bi-LSTM预测模型的HLC-AUC都是上升到最大值后维持在最大值附近。根据曲线关系,可以确定当sizeIP=96, sizeWM=64时,模型预测效果最好。

图8 各向量对HLC-AUC的影响
此外,模型中输出向量维度Odim一定程度上控制了模型容纳信息量的大小。为了研究Odim对预测效果的作用,Odim取32的整数倍作为变化范围,并观察HLC-AUC变化,如图8所示。从图中可以发现,当Odim在128~160范围内时,模型预测效果最好。但是在实际应用时,在保证预测效果较好的前提下,为了降低模型复杂度,在本设计中Odim取128。
模型更新采用梯度下降法,在更新模型时学习速率Le arnrate决定模型学习更新的速度,Le arnrate过小会造成学习速率慢甚至不学习;Le arnrate过大会造成模型发散。因此,选取恰当的学习速率对模型的更新速度和算法运算量尤其重要。本文Le arnrate分别取值0.0003,0.001,0.003并观察模型损失函数的变化趋势。
如图9所示,当Le arnrate= 0.0003时,损失函数下降缓慢,当训练到每批样本个数batch=1000时,损失函数数值仍在0.5以上;Le arnrate= 0.003时,虽然收敛速度最快,但在batch=600时,损失函数曲线就基本保持不变且数值较大。而当Le arnrate= 0.001时,前期收敛速度最快后期居中,在达到900batch时获得最小损失为0.12。另外,图中在batch=100之前三条曲线都具有较快的下降速度和收敛速度,因此可以去batch在100以内。

图9 学习速率和HLC-Loss关系曲线
综上所述,当sizeIP取96,sizeWM取64,Odim取128,Le arnrate取0.001,batch取62时,Self-Attention-Bi-LSTM攻击预测模型具有最好的预测效果和最快的预测速度。
■3.2 模型效果对比分析
本实验中,设置分类器1,2使用3层FNN对下一步的攻击进行预测,损失函数使用HLC-LOSS。神经网络的其他参数结合经验和实验结果动态调整,各预测模型的效果如表2所示。

表2 电网数据各预测模型的效果
从表2可以知道,Self-Attention-Bi-LSTM预测模型AUC值达到了0.753,比LSTM和Bi-LSTM分别增加了6%和10.1%。HLC-AUC也达到了最高的0.832,说明该模型在有效预测高级别攻击链的同时,也提升了总的预测效果。
为了进一步考证Self-Attention-Bi-LSTM模型的预测效果,进行DARPA数据集实验。由于实验中数据集的差异,设置分类器1,2使用2层FNN对下一步的攻击进行预测,损失函数使用HLC-LOSS,各预测模型的效果如表3所示。

表3 DARPA数据集试验下各预测模型的效果
根据表中数据能够明显地判断出,无论是在ACU还是HLC-AUC, Self-Attention-Bi-LSTM模型都达到了最好的预测效果。
综上所述,Self-Attention-Bi-LSTM模型既能在电网数据中有效预测高级别攻击链并提升总体预测效果,还能在DARPA数据集实验达到最优预测,证明了该模型准确性和有效性。
4 结论
(1)针对多目标、复杂的入侵,本文提出了通过节点信息结构化、聚合子节点、深度遍历三个环节来实现IP关联的攻击链提取方法,该方法无须标记样本、在少量的先验知识基础上就能成功提取攻击链。
(2)提出了Self-Attention-Bi-LSTM攻击预测模型和高级别攻击链AUC评价标准,并利用HLC-AUC对IP和WM向量长度、输出向量维度及学习速率进行最优参数整定,得到当sizeIP取96,sizeWM取64,Odim取128,Le arnrate取0.001,batch取62时,Self-Attention-Bi-LSTM攻击预测模型具有最好的预测效果和最快的预测速度。
(3)最后通过电网实验和行DARPA数据集验证了Self-Attention-Bi-LSTM攻击预测模型的准确性和有效性。
