基于多光谱遥感与SPXY的采煤沉陷水域水深反演
2022-10-17徐良骥王明达吴剑飞
徐 阳,徐良骥,张 坤,王明达,吴剑飞
(1.安徽理工大学 空间信息与测绘工程学院;2.深部煤矿采动响应与灾害防控国家重点实验室;3.安徽理工大学 矿区环境与灾害协同监测煤炭行业工程研究中心,安徽 淮南 232001)
1 引言
两淮矿区是我国重要的煤炭基地,地下潜水位高,加之多煤层重复开采,导致地表大面积沉陷积水。据统计,淮南采煤沉陷区面积已超过200km2,沉陷水域面积达到110km2[1]。为合理开发利用采煤沉陷水域水资源,需要对沉陷区水深进行精准勘测,从而获得采煤沉陷水域水资源量。
相较于以往实地测量的方法,遥感反演可以快速高效地获取大面积水域的水深信息[2]。利用遥感数据反演水深方面的研究和应用始于上世纪70年代,Tanis等构建了水质较清水体反射率较高的单波段理想水体深度反演模型[3];Tripathi等利用IRS-1DLISS-III卫星遥感资料构建基于最小二乘法的经验反演模型,并引入浊度影响因子对印度Kakinada海湾地区的水下地形进行了精确地反演[4];张鹰等利用Landsat-7 ETM+遥感影像构建动量BP人工神经网络水深反演模型,对长江口北港河道上段水深进行了准确的研究[5];王艳姣构建了基于波段组合的水深反演模型,实现了对有悬浮泥沙的水体深度的准确反演[6];邓军通过分析水深值和水体反射率的关系建立了多元回归反演模型,以徐州九里坍塌湖为实验对象,验证其精度明显优于单因子反演模型[7];彭苏萍等使用相关系数最大的TM4波段建立水深值与像元反射率的回归模型,将水深两米作为阈值应用于淮南潘一矿的沉陷水域得到了较为精确的结果[8]。
遥感反演是快速获取大面积水域水深数据的理想手段,学界在建立和优化不同环境条件下水深反演模型方面做了大量研究。但是建模数据集的划分对模型精度影响很大,这方面还需要深入研究。本文采用随机样本集划分法和SPXY样本集划分法划分样本数据集,建立水深反演模型,对淮南矿区谢桥煤矿采煤沉陷水域水深进行了反演。
2 研究区概况及研究方法
2.1 研究区概况
淮南矿业(集团)谢桥煤矿位于安徽省颍上县东北部,距颍上县城约20km,井田东西走向长11.4km,南北宽4.5km,面积约为50km2。全井田划分两个水平,第一水平-610m,第二水平-900m。研究区内年均降雨量约为1040mm。沉陷水域丰水期的最大水深为15.38m,平均水深为2.10~8.40m;沉陷水域枯水期的最大水深为14.50m,枯水期平均水深为1.50~7.50m[9]。
2.2 样本数据集划分方法
2.2.1 随机样本数据集划分法(RS)
该方法是最简单的样本数据的划分方法,其基本思想就是根据建模组与检验的分配比例,随机选取一定数量的样本作为检验组,其余样本作为建模组[10]。该方法操作简便,无需进行任何计算,易于实现,是广泛用到的一种划分方法。但是由于数据集选取的随机性使得该方法的缺点也极为明显,当样本过少时无法确定所选样本的代表性,从而令拟合模型达不到理想的精度要求[11]。
2.2.2 光谱—理化值共生距离法(SPXY)
SPXY算法是一种基于统计基础的样本划分方法,因其在覆盖多维向量空间上的有效性,所以能够显著地提高所建立模型的预测精度[12]。该算法的基础是KS(Kennard-Stone)算法,KS算法考虑选取光谱差异最大的样本,计算待选样本与已选样本之间的最大欧氏距离依次选取足够数量的样本[13]。但是使用KS算法进行样本数据集划分时只考虑光谱特征变量(x)忽略了待测目标(y)对数据选取的影响,于是Galvao等人提出了兼顾光谱信息与理化目标值的SPXY算法[14]。SPXY在计算样本间距离时会同时考虑x变量和y变量上的欧氏距离,其距离计算公式如下:
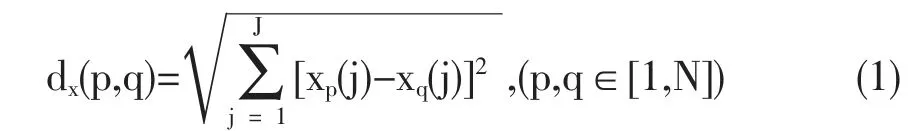
式中J表示光谱中的波段数。xp(j)和xq(j)分别表示p,q两个样本在第J个波段上光谱反射率的值,N为样本的总数。dx(p,q)代表两个样本在x空间(光谱特征空间)的欧氏距离。
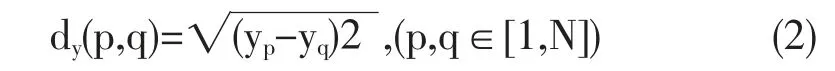
式中yp和yq分别表示样本待描述的理化特征值(本文为水深),为两个样本在y空间(水深特征空间)的欧氏距离。
同时考虑x和y空间,该算法计算公式用dxy(p,q)代替了KS算法中的dx(p,q),并且为了确保样本数据在x和y空间上的权重相同,用dx(p,q)和dy(p,q)分别除以样本空间的最大值得到标准化后的距离公式如下:
式中dxy(p,q)为示考虑两个空间的欧氏距离,和分别表示p与q两个样本在x和y空间欧氏距离的最大值。
SPXY算法选择样本的步骤如下:
假设样本总数为N,需从中选取M组样本。
(1)计算所有待选样本两两之间的欧氏距离dxy(p,q),选取距离最大的两个样本记为M1,M2。
(2)计算剩余N-2个样本与两个已选样本之间距离。
(3)选取剩余样本与已选样本的最小值min(dxy(p,M1),dxy(p,M2))作为待选组。
(4)从待选组中选取与已选样本的距离最大的样本作为M3。
(5)重复上述步骤,直至选出M组样本。
2.3 模型精度检验
为了确定经SPXY算法划分样本数据集后的水深反演模型的预测精度,引入决定系数(Coefficient of Determination),均方根误差(Root-meansquare error,RMSE),以及平均绝对误差(Meanabsolute error,MAE)三个反映模型拟合效果的指标对水深反演模型进行精度评价[15,16]。

2.4 水深遥感反演模型
沉陷区水深反演的原理在于,根据光在水中传播的衰减性质建立波段值与实测水深值之间的线性或非线性的拟合模型[17,18]。
2.4.1 单波段模型
单波段模型的提出是基于Bouguer定理,在水体的衰减系数以及底质的反射率为常量的理想条件下,传感器接收的辐射量随着水深的增加以指数形式衰减[19],即:


式中:IZ与I0分别表示光在水深Z处和水体表面的辐射亮度;α为水体中的辐射衰减系数;RE表示传感器接收到的辐射亮度;k是由太阳辐射和大气水体折射等因素影响的综合因子;Rb为底质反射率值;RW为深水区辐射亮度。
由上式变形可得水深表达式:


根据影像波段值与实测水深值进行线性拟合可获得待定系数a、b的值。
2.4.2 多波段模型
多波段模型是为了破除单波段模型只适用于水质较清、底质单一且水深较浅水域的局限性,由Paredes等于1983年提出的,理论上不受水深和底质的影响,提高了反演模型的适应性[20]。
根据单波段模型推导过程可得多波段模型公式如下:

2.4.3 神经网络模型
神经网络通过已有的训练集来“学习”以达到预期效果,因其在非线性拟合中具有较好的逼近能力,被广泛应用于水深的遥感反演[21]。在进行反演是一般采用三层神经网络即:输入层、输出层、隐含层,来表示光谱反射率值与水深的非线性映射关系。神经网络模型如图1所示。

图1 神经网络模型示意图
神经网络模型的训练过程包含误差的逆向传播和输入信息的正向传播,当输出结果与期望结果误差小于阈值或训练次数达到既定上限,学习完成。
3 水深遥感反演
3.1 水深控制点选取
课题组于2018年使用智能测深无人船对该水域进行了实地观测,研究区域由于多年煤矿开采沉陷积水面积较大,由于矸石堆积淋滤水以及生活污水汇入积水区使得该区域水质相对较差,为水深反演带来一些阻碍。故选取合适的590个实测数据,作为反演基础。
3.2 数据源及预处理
本文选取2018年9月份Sentinel-2B高分辨率多光谱影像作为反演影像。该影像涵盖13个不同的波段,幅宽可达290km。
获取遥感数据时会受到大气、光照等多种因素的影响,因此在进行实验前需要对获取的数据进行一定的预处理。此次预处理步骤主要包括:辐射定标、大气校正、坐标配准等。最后将遥感数据与水深实测点的坐标进行匹配,进而获得水深实测点对应遥感影像各波段的辐射亮度值。
3.3 波段值与水深相关性分析
遥感光谱的各个波段均能与水深建立相关的反演模型,但多光谱乃至高光谱数据量较大,全部建立模型再比较反演精度耗时太长,因此在建立模型前对各个波段与水深的相关性进行分析可大大简化模型建立的过程。通过分析可知Sentinel-2B影像波段2、3、4、8反射率的值与水深的相关性较高,因此选用这四种波段进行模型的构建。四种波段反射率与水深的相关性如表1所示。

表1 波段反射率与水深相关系数
3.4 模型的建立与分析
分别采用随机样本数据集划分法和SPXY样本数据集划分法将通过像元坐标法对各点光谱数据集提取后不同深度的590个水深样数据集划分为5:1的建模组和检验组,然后建立基于不同样本数据集划分方法的线性拟合模型和神经网络预测模型,并计算每种模型在检验组中的水深反演精度,结果如表2所示。从表2中可以知道,经过SPXY方法进行样本数据集划分以后的模型对沉陷区水深反演的精度明显高于基于随机样本数据集划分的模型。其中两种线性拟合模型的R2分别提高了0.008和0.022,单波段线性拟合模型的RMSE和MAE分别降低了0.02m和0.043m,多波段线性拟合模型的RMSE和MAE降低了0.019m与0.024m;神经网络模型的精度提高较为明显其R2提高了0.05,与此同时RMSE和MAE分别降低了0.097m和0.065m。由此可知多波段线性拟合模型和神经网络预测模型在淮南矿区沉陷水域水深遥感反演的应用中有着较好的反演能力。为更好的体现每种算法的反演精度,将检验组的实测水深值作为横坐标反演水深值作为纵坐标,绘制出该反演模型的散点图,图3为基于不同样本数据集划分方法的线性拟合模型和神经网络预测模型的散点图。从图3中可以看出,多波段线性拟合模型和神经网络模型的点大多分布与y=x这条线上或在其周围,离散程度较小,拟合效果良好,表明反演的水深值与实测的水深值相差较小,反演效果较好;相比之下,单波段线性拟合模型的散点图离散程度较大,尤其是在深水区,偏离较为明显,拟合精度不高。可以推测,单波段模型不适用于两淮矿区沉陷积水区水深反演。

图3 水深实测值与反演值比较

表2 水深反演模型精度验证参数
对比RS样本数据集划分法与SPXY样本数据集划分法的三种不同模型的散点图可以看出,基于SPXY建立的三种反演模型其拟合线的斜率明显增大,在散点图上表现为拟合线更趋向于y=x这条线。说明经过SPXY进行数据集划分,模型的反演能力有所提升。其中单波段线性拟合模型在深水区的离散程度也明显变小说明,该方法对深水区反演效果较差的问题也有的一定的改进。
3.5 分段精度分析
为了进一步分析SPXY样本数据集划分法在不同水深的情况下对模型的优化程度,故将检验组划分为0-3m、3-6m、6-9m三个区域,计算三个水深范围内的RMSE,以此验证精度。经计算得出水深分段后各模型RMSE如表3所示。

表3 不同水深模型反演精度对比
由表3可知,经SPXY算法优化后在多数情况下反演效果较随机样本数据集法好,其中单波段线性拟合模型在0-3m的浅水区反演效果较差,分析其原因是由于较浅水域受水产养殖、水体富营养化等因素影响,单个波段在此区域内有较大的衰减系数;随着水体深度增大,在6-9m范围内悬浮泥沙较多,水体混浊,因此各反演模型均难以取得较好的反演效果。鉴于沉陷水域深水区占少数,整体精度依然较为理想。综合考虑,认为基于SPXY样本划分的神经网络模型能够对两淮矿区沉陷水域水深进行较为精确的反演。
4 结论
本文利用Sentinel-2B多光谱影像,选取相关性较高的波段,分别使用随机样本数据集划分法和SPXY样本数据集划分法通过单波段线性拟合、多波段线性拟合与神经网络模型三种方法建立水深值与波段反射率之间的拟合关系,开展淮南矿区沉陷水域水深反演研究,对比随机样本数据集划分与SPXY样本数据集划分得到模型的反演精度,得到结论如下:
(1)多波段线性拟合和神经网络模型在淮南矿区沉陷水域水深反演应用中效果较好(随机样本数据集划分法与SPXY样本数据集划分法的RMSE基本都在1m以下),单波段线性拟合反演效果不理想(SPXY与随机样本数据集划分法的RMSE分别为1.455m和1.475m)。
(2)沉陷水域积水较深地区(6-9m),水深反演的精度较差,分析其原因是由于水中悬浮泥沙较多,浓度,粒径也有较大差异,使得光谱反射率产生了较大的影响,导致水体的辐射衰减异常改变,导致水深反演精度降低。
(3)基于SPXY样本数据集划分法对建模样本进行选择后建立的遥感水深反演模型相对于基于随机样本数据集划分法建立的模型的R2、RMSR、MAE均有明显的改进,其中神经网络模型的改进效果最为明显,其R2提高了0.05,RMSE和MAE分别降低了0.097m和0.065m。
