具有姿态变化鲁棒性的行人检测跟踪算法
2022-10-17王丽园肖进胜熊闻心
王丽园,赵 陶,王 文,肖进胜+,熊闻心
(1.中交第二公路勘察设计研究院有限公司 工程技术研究院,湖北 武汉 430056; 2.武汉大学 电子信息学院,湖北 武汉 430072)
0 引 言
行人检测跟踪是视觉领域研究的热点问题,应用广泛。然而对于行人姿态变化、行人间遮挡以及低照度等问题,仍然没有较好的解决方案。
近些年,基于深度学习的目标跟踪算法得到长足的发展。Wang等[1]将重点放在特征学习上,通过调整特征提取器和分类器,适应运动目标的外观变化。Danelljan等[2]将深度学习网络在特征识别数据集上训练的特征融入到相关滤波器中。HDT算法[3]根据不同卷积层的特点来表征运动目标。DeepSORT[4]多目标跟踪算法,利用行人重识别中的数据集建立基于深度卷积神经网络的表观模型。Maksai等提出一种训练模式改进了多目标跟踪算法中目标交叠时身份切换问题[5],Siamese-RPN[6]采用两种类型的子网络将分类与回归进行融合。但以上算法在抗姿态变化和遮挡问题上仍然存在缺陷。
针对复杂的监控场景,本文提出了一种抗姿态变化的行人目标鲁棒性检测跟踪算法。针对低照度对跟踪性能的影响,本文改进了Retinex图像增强算法以提高图像的质量。针对视频中的行人遮挡和姿态变化,本文引入抗姿态变化的行人特征以提高监控视频中行人检测跟踪的准确性和鲁棒性。测试结果表明,本文算法在实际监控环境下有较好的鲁棒性检测和跟踪效果。
1 鲁棒的检测跟踪算法
行人跟踪目的在于将每个行人进行ID标记并在后续时间中持续匹配并保持ID编号不变。由于行人姿态和应用场景的复杂性,行人检测跟踪面临诸多挑战。结合YOLOv3和DeepSORT的行人检测跟踪算法在光照条件变化、行人数量较多、行人之间存在遮挡和姿态变化的复杂监控环境下,难以取得良好效果,存在大量跟踪ID编号跳变。针对以上问题,本文提出了一种抗姿态变化的行人目标鲁棒性检测跟踪算法。如图1所示是整体框架流程图。
首先对输入图像进行简单判断,对于低照度图像序列,通过改进的Retinex算法进行图像增强预处理,然后利用检测算法对行人目标进行检测,通过对目标进行卡尔曼滤波轨迹预测获取运动信息,通过特征提取获取目标表观信息,最后进行数据的有效关联实现跟踪匹配,流程图中虚线部分是本文改进部分。
1.1 基于增强的行人检测
YOLOv3[7]是现阶段基于深度学习的目标检测代表算法之一,它结合了特征金字塔FPN (feature pyramid networks)的思想,将不同分辨率的特征图自上而下融合,能够有效共享低层特征和高层特征,该网络有3个尺度的输出,兼顾了不同尺度目标的检测效果。
光照条件不足会对图像分析造成干扰,影响目标检测跟踪的准确性。因此增加图像增强预处理模块有重要意义。针对带色彩恢复的多尺度Retinex算法(MSRCR)存在的色彩失真、噪声放大等问题,我们在实验室早期研究的基于不同色彩空间融合的图像增强算法[8]上,使用改进的Retinex图像增强算法,用于视频图像序列的预处理。原始的Retinex算法分别处理RGB这3个通道实现图像增强,然而如果RGB这3个通道的增强幅度不一致,会导致例如颜色失真、光晕伪像等问题。为了解决这些问题,提出一种改进的Retinex图像增强算法。首先在图像的HSV空间中,提取出亮度分量V进行增强处理
Venh=log[V(x,y)]-log[F(x,y,z)*V(x,y)]
(1)
式中:V(x,y) 是待调节图像亮度值,F(x,y,z) 为环绕函数,滤波采用窗口无关快速均值滤波算法,提高了滤波效率。同时为了解决亮度分量有了较大增强后图像暗区出现大量噪声和亮区失去部分细节的问题,提出增强调整因子,公式如下
S(x,y)=β·sin[π·V(x,y)/255]
(2)
其中,β是调整因子的调整幅度值.根据处理前后的亮度分量求得亮度增益K(x,y)
(3)
当K(x,y) 小于1时取1,然后通过原图的RGB以及亮度增益得到增强后图像的RGB空间的值,能有效避免MSRCR算法中的色彩失真,提升了图像的整体色彩对比度。低照度图像增强效果如图2所示。
1.2 抗姿态变化的行人跟踪
针对多目标跟踪算法DeepSORT存在的鲁棒性差问题,本文引入抗姿态变化的行人重识别算法,通过提取人体14个关键骨骼点构成不同的感兴趣区域,多个感兴趣区域的表观特征,通过融合构成鲁棒的全局表观特征,提高跟踪准确性。
1.2.1 基于运动和表观信息的关联匹配
数据关联匹配是目标跟踪至关重要的部分,部分跟踪算法只考虑运动信息的关联,匹配不准确。一些算法提取目标的Haar或Hog等表观信息进行关联,特征简单但鲁棒性差。为了进行更准确的目标跟踪匹配,本文算法将运动信息关联和目标外观信息关联结合起来作为数据关联指派的标准。
卡尔曼滤波首先预测目标在下一时刻的位置,然后基于检测来更新预测的位置。在位置度量上,通过对卡尔曼预测结果和检测结果计算马氏距离,马氏距离通过计算当前检测的目标位置和预测值之间的标准差来进行运动度量
(4)
其中,D′(i,j) 表示第j个检测结果和第i条跟踪轨迹预测结果之间的匹配程度。si是由卡尔曼预测的协方差矩阵,dj表示第j个目标位置的实际值,pi表示第i个跟踪器对目标位置的预测值。
在外观度量上,对每一个检测目标提取抗姿态变化的表观特征,计算特征向量。保存每个跟踪结果的特征集,计算该特征集与检测结果特征向量的最小余弦距离,进行表观信息的度量。计算公式为
(5)
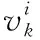
1.2.2 抗姿态变化的表观特征提取
针对视频中行人的姿态变化和遮挡导致的跟踪ID跳变问题,本文通过人体部件模型,提取人体不同区域特征,通过多阶段特征融合形成抗姿态变化的特征用于后续的关联匹配。利用RPN网络输出响应图Ri∈RW×H, 其中W、H表示RPN网络输出特征的尺度大小。骨骼关节点 (xi,yi) 就是响应图中响应值最大的点
(6)
根据骨骼关键点对人体区域进行划分[9]。将14个关键点PAPBPC1PC2,PD1PD2PE1PE2,PF1PF2PG1PG2PH1PH2构成7个不同的点集J1,J2,J3,J4,J5,J6,J7,如图3所示。
对应的头部、四肢(左上肢,右上肢,左下肢,右下肢)、上半身和下半身用Bn来表示,n∈(1,…,7)
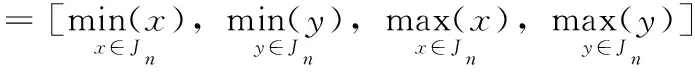
(7)
其中, (xlt,ylt) 和 (xrb,yrb) 分别表示矩形左上角的坐标和右下角的坐标。
将输入的行人图像划分成7个不同的人体区域,包括头部、上半身、下半身以及四肢。根据人体区域构建抗姿态变化的行人特征提取融合网络,网络结构如图4所示。
其中特征提取网络由卷积神经网络组成,特征融合网络由多个最大值池化层级联组成。将得到的7个不同区域的图像,以及行人全局的图像输入特征提取网络中提取局部的表观特征,共8个表观特征。最后通过特征融合网络,将得到的局部表观特征在不同网络深度上进行融合。通过对身体多阶段的划分和特征的融合,获取更加鲁棒的行人特征向量用于匹配,提高跟踪的鲁棒性,减少ID编号跳变,保持同一行人的持续跟踪。
2 实验与结果
2.1 数据集与评价指标
本文实验采用MOT数据集和实际监控视频数据作为数据集进行训练和测试(校园监控视频、城市监控视频数据等)。本文的实验使用的计算机配置了NVIDIA Tesla K40c显卡和16 G内存的Intel(R) Core i7-7700K @ 4.20 GHz。并在此基础上搭建Tensorflow深度学习环境。本文采用平均精确度(average precision,AP)和召回率(average recall,AR)作为衡量模型检测性能的评价指标。使用单帧检测跟踪时间来衡量算法的效率。采用MOT16[10]的评价指标跟踪ID跳变次数(ID_SW)来衡量目标跟踪的鲁棒性和精确度。
2.2 行人检测跟踪实验结果分析
2.2.1 多种算法对比
本小节在真实的监控视频数据下进行实验,选用CenterNet-DeepSORT、YOLO_Tracking 和YOLOv3-DeepSORT作为对比算法。为保证公平性,在统一的实验平台下测试不同算法在该数据分布下的检测跟踪效果。我们仅截取第100帧和第150帧的跟踪结果用于展示,本文算法和对比算法的实验结果如图5~图8所示。
从结果中可以看出,CenterNet-DeepSORT算法对监控视频图像序列中远处小目标的检测跟踪效果较差,存在较多的漏检。YOLOv3-DeepSORT算法可以检测到远处的行人目标,但是仍然存在行人编号跳变较多的问题。YOLO_Tracking算法几乎不处理行人之间存在的遮挡和姿态变化,一旦存在遮挡行人标号就会改变。本文提出的方法可以检测到视频序列远处行人目标,同时对行人间的遮挡和姿态变化具有较好的鲁棒性,对远处的小目标检测效果较好,能够实现对目标的持续性跟踪。
通过测试不同视频,对结果进行量化处理,同时分析算法的时间复杂度,统计见表1,其中YLT表示YOLO_Tracking目标跟踪算法,CDS表示CenterNet-DEEPSORT目标跟踪算法,YDS表示YOLOv3-DeepSORT目标跟踪算法。
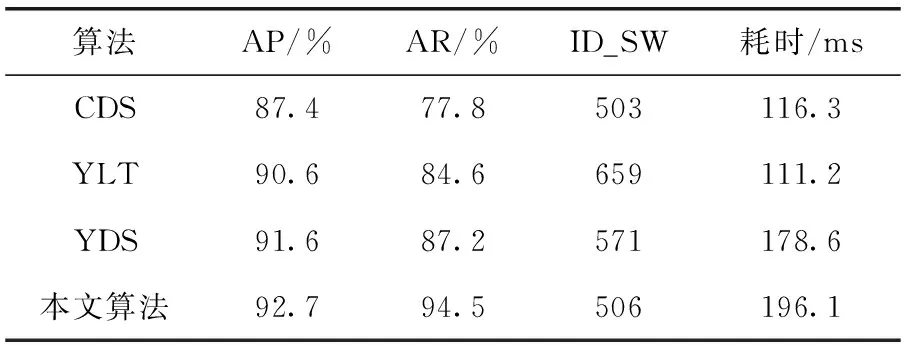
表1 不同算法跟踪结果对比
从统计结果中可以看出,本文改进的算法相较于CenterNet-DeepSORT来说,行人编号跳变几乎相同(503 vs. 506),然而具有更高的精确率(87.4% vs. 92.7%)和召回率(77.8% vs. 94.5%)。相对于YOLO_Tracking来说,行人编号跳变明显较少(659 vs. 506),精确率高2.1%,召回率高大约10%。和YOLOv3-DeepSORT算法相比,召回率提升约6.7%(94.5% vs. 87.2%),同时AP提高1.1%,ID编号跳变也有一定的减少(506 vs. 571)。从单帧耗时上对比来看,本文改进算法虽然时间复杂度相对其它算法较高,但仍然满足实际应用需求,同时有更准确的检测跟踪效果。
除此之外,为了测试算法在实际应用中的稳定性,我们接入实际监控的视频流数据,并利用本文算法实现对行人的检测跟踪,可长时间稳定运行。
2.2.2 低照度及姿态变化实验
本小节将研究本文提出算法和原始算法YOLOv3-DeepSORT在低照度和行人姿态变化情况下的性能对比。本小节选择MOT16和实际场景拍摄数据作为实验数据集。MOT16数据集是专门用于衡量多行人目标跟踪效果的公开数据集。MOT16数据集中包含大量行人目标和行人姿态变化,同时数据采集时间多样,包含多种不同光照度的图像。本文在MOT16数据集上对改进前后的算法分别进行测试分析,实验结果见表2。
由表2可知,在低照度场景下,加入图像预处理后,ID跳变次数减小为原先的一半以上(134 vs. 279),精确度提升7.4%(91.6% vs. 84.2%),召回率提高30.9%(83.5% vs. 52.6%)。可见在低照度场景下,对图像的低照度增强预处理是很有必要的操作,能大幅度提高算法的跟
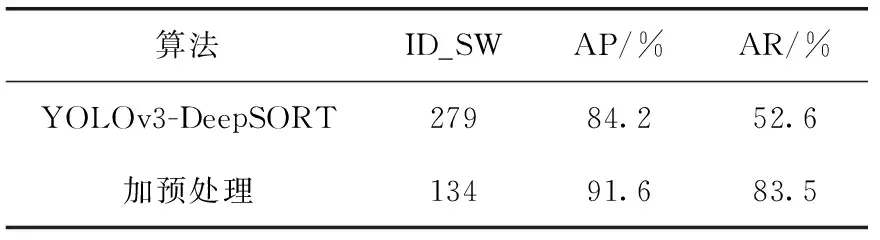
表2 低照度下跟踪结果对比
踪性能。
利用采集于实际场景的数据测试算法的抗姿态变化性能,实验结果见表3。

表3 姿态变化下的跟踪结果对比
从统计表中可以看出,加入抗姿态变化特征后,ID跳变次数明显减少(958 vs. 1256),这也符合我们引入抗姿态变化特征的初衷。同时,跟踪的精确度和召回率分别提升了0.7%和1.8%。
以上实验,分别在低照度和行人姿态变化情况下对本文提出的算法和原始YOLOV3-DeepSORT进行了实验对比分析,从实验结果中可以得出,本文提出的算法相比于原始算法,能明显提高行人目标检测跟踪的准确性,可较好消减由于光照不足和行人姿态变化为跟踪带来的影响,能够满足现实生活之中对行人的检测跟踪任务。
3 结束语
现实监控系统视频中,光照不足、行人姿态变化和行人遮挡都会影响行人检测跟踪的准确性。针对以上问题,本文提出了一种抗姿态变化的行人目标检测跟踪算法,提高行人检测跟踪的鲁棒性。针对光照不足问题,在HSV空间对图像进行增强,同时设计增强因子,减少颜色失真问题。为了减少因行人姿态变化及行人之间遮挡导致的目标ID频繁跳变的问题,引入行人重识别模型,基于人体部件模型的思想,分别提取人体多个区域的特征,以提取更加鲁棒的特征,从而提高跟踪准确性和鲁棒性。
