基于卷积神经网络-长短时记忆神经网络的磨煤机故障预警
2022-10-17杨婷婷高乾李浩千吕游陈晓峰
杨婷婷,高乾,李浩千,吕游,陈晓峰
(1.华北电力大学控制与计算机工程学院,北京 102206;2.华北电力科学研究院有限责任公司,北京 100045)
“十四五”以来,我国电力结构持续优化,新能源发电所占比重逐渐提升。火电机组将越来越多地承担电网调峰等辅助服务,因此很难在额定负荷工况下长时间连续运行。火电机组频繁地在各种工况条件下运行将成为常态,机组设备会因频繁变负荷而更容易发生故障[1]。磨煤机作为火电机组中的重要设备,其工作状态将直接影响锅炉能否正常工作[2]。在磨煤机即将出现故障时,对其进行预知性维修,避免故障进一步扩大,对保障电厂生产安全以及提升电厂经济效益将具有重要意义[3]。
文献[4-6]采取多元状态估计方法,对电站辅机设备进行正常状态建模,分析监测参数实际值与估计值之间的误差,对设备进行故障预警。文献[7-13]分别采用了不同的深度学习网络针对不同设备进行建模实现了对设备的故障预警。以上文献均采取单一的深度学习网络,为了进一步提高模型的性能和预测精度,一些学者[14-15]选择将不同网络模型相结合,充分利用不同网络的优点。文献[16-17]将长短时记忆(long short-term memory,LSTM)神经网络以及卷积神经网络(convolutional neural network,CNN)结合搭建一个复合神经网络,并建立文本分类模型,试验结果表明该模型的预测准确度优于单一的模型。文献[18]针对同步电机励磁绕组的物理特性建立LSTM 神经网络与CNN 的复合神经网络,并在短路故障预警试验中取得了理想的效果。
由于磨煤机运行工况复杂,各监测量存在长期时序变化规律且耦合性强。传统的深度学习模型和时间序列预测方法对磨煤机监测量的预测效果并不理想。本文选择深度学习中应用广泛的LSTM 神经网络和CNN,针对磨煤机时序数据特征,提出一种CNN 联合LSTM 神经网络的预测模型,利用磨煤机正常工作状态下的运行数据进行训练,实现对多测点参数变化趋势的预测。融合多元时间序列残差作为偏离度,设置合理的预警阈值进行磨煤机故障预警。分别利用某660 MW 火电机组的中速磨煤机的正常数据与故障数据进行故障预警试验,试验结果表明CNN-LSTM 模型相较其他模型具有更高的精确度,可对磨煤机故障进行有效预警从而进行预知性维修,具有一定的工程应用价值。
1 CNN-LSTM 模型原理
1.1 卷积神经网络原理
卷积神经网络(CNN)是一种专门处理具有类似网格结构数据的神经网络,具有稀疏连接、参数共享等特征[19]。
CNN 由卷积层、池化层和全连接层组成。卷积层的主要作用是提取输入数据的特征。一维卷积的计算公式为:
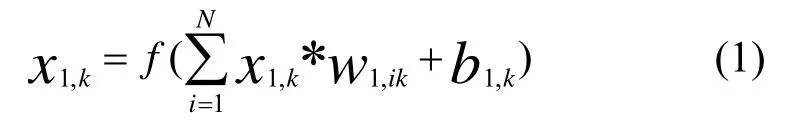
式中:x1,k为第l 层第k次卷积运算;w1,ik为第l 层第k个卷积核做第i次运算的权值;f为激活函数;N为输入做卷积映射的数量;b1,k为第l 层第k个卷积核的偏置;*表示卷积运算,当处理时间序列数据时,通过卷积操作可以得到一个由输入中出现不同特征的时刻所组成的时间轴。
池化层的作用是通过压缩参数的数量实现特征降维,从而减小模型过拟合。通过CNN 提取多元时间序列数据的特征,掌握数据之间的关联性。再将处理后的时间序列数据输入LSTM神经网络进行时间序列预测[20]。
1.2 LSTM 神经网络原理
LSTM 神经网络是在循环神经网络(recurrent neural network,RNN)的基础上改进得到的一种神经网络,弥补了RNN 不能处理长序列数据缺陷[21]。LSTM 神经网络通过加入记忆门、学习门、遗忘门来控制信息的传输。LSTM 神经网络的内部结构如图1 所示,其中各量可由式(2)—式(6)计算得到:
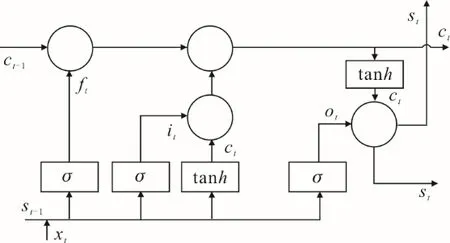
图1 LSTM 神经网络内部结构Fig.1 Internal structure of LSTM neural network
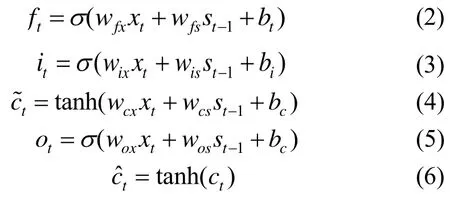
式中:ft为遗忘门的输出信号,表示记忆单元c的遗忘比例;it为输出门的输出信号,表示当前输入信息到记忆单元中的比例;记忆单元中的信息由与it运算得到;ot为输出门的输出信号,表示记忆单元的信息输出到当前状态st中的比例;隐含层状态st中的信息由与ot运算得到。
t时刻的记忆单元ct经过输出门的筛选可得到隐含状态st[22]:

CNN 提取多元时间序列特征,去除干扰信息后输入LSTM 神经网络进行预测。既减少LSTM 神经网络的步长,又保留了有效的记忆信息,解决了因步长过长导致的梯度弥散问题。
2 CNN-LSTM 模型构建与预警策略
2.1 模型预测量的选择
煤质的不稳定和机组工况频繁变化是导致磨煤机出现故障的主要原因。根据不同故障对磨煤机监测参数的影响情况,磨煤机的故障可划分为3 类:1)与单一测点相关的故障,如加载油压过低、磨煤机出口温度高等;2)与多个测点相关的故障,如磨煤机断煤、磨煤机堵煤等;3)无测点可测的故障,如磨煤机振动大等。
本文所建立的模型针对多个测点相关的故障进行预警。因此需要从多个参数变化的角度提取特征。以磨煤机堵煤故障为例,与堵煤故障相关的测点参数见表1[23]。

表1 磨煤机堵煤故障相关变量Tab.1 Variables related to coal blockage fault
2.2 模型结构设计
根据上述分析,本文采用磨煤机7 个测点参数的时间序列数据作为CNN-LSTM 模型的输入,未来一段时间的预测值作为输出。
多元时间序列数据先输入CNN,通过64 个卷积核来进行特征提取,可以得到一段具有时间依赖性的序列,随后通过最大池化处理。在池化层之后采用dropout 方法进行正则化处理。CNN 的激活函数选择Relu 函数。之后,这段数据按照时间顺序输入LSTM 神经网络中作为每个时间步的输入。
LSTM 神经网络采用双向LSTM 神经网络结构。激活函数选择Relu 函数。依靠CNN 提取的数据特征,学习数据间的关联性,从而对多元时间序列进行有效建模。LSTM 神经网络后面接全连接层,激活函数选择Sigmoid 函数,最终得到多元时间序列输出预测值。
模型优化算法采用Adam(adaptive moment estimation)算法[24]。Adam 算法利用梯度的一阶矩估计和二阶矩估计来实现学习率的动态调整,通过加入偏置校正使每一次迭代学习率都有确定范围,使得调参过程比较平稳。Adam 算法参数见表2。

表2 Adam 算法参数Tab.2 Adam algorithm parameter table
2.3 偏离度定义与预警策略
本文所构建的CNN-LSTM 模型经过训练,学习磨煤机正常工作状态下各变量之间的关系特性。模型接收到新的时间序列数据后,根据学习所得关系特性输出预测数据。当磨煤机出现发生故障的趋势时,相关监测参数将相对正常状态数据出现一定偏差,当这个偏差值超过某一阈值时,可以认定磨煤机出现堵煤故障。
通过计算得到CNN-LSTM 模型输出的预测值与实际值之间的残差序列,该序列每一时刻的残差数据构成一个长度为7 的向量。由式(9)计算该向量的2 范数e,作为该时刻磨煤机偏离正常工作状态的偏离度。计算每一时刻的偏离度进而得到一个偏离度序列。

由于磨煤机的工作环境复杂,在正常工作状态下相关测点参数也会出现不同程度的波动。为了有效地消除随机因素的影响,采用滑动窗口法对偏离度序列进行处理。
预警阈值的计算采用核密度估计法。由于偏离度序列存在多峰情况且不遵循正态分布的规律,因此利用核密度估计技术确定偏离度序列的概率密度函数,选取0.99 分位数作为预警阈值。其中,核函数选用Gaussian函数。概率密度函数计算公式为:

式中:m为偏离度序列长度;h为带宽宽度;σ为偏离度序列的标准差。
根据式(12),计算逆累计积分函数,得到置信区间为α时,预警阈值t的上限。

磨煤机在运行时若平均偏离度序列维持在预警阈值以内,则判定磨煤机工作状态正常,若偏离度超出预警阈值,则认为磨煤机有发生故障的趋势,此时模型做出预警。图2 为基于CNN-LSTM 模型的磨煤机故障预警试验流程。
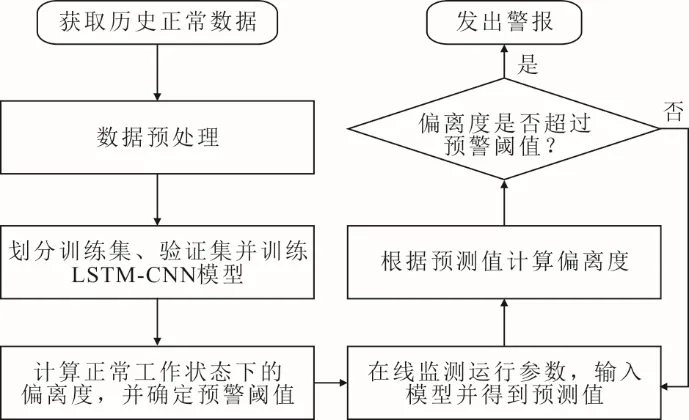
图2 基于CNN-LSTM 模型的磨煤机故障预警试验流程Fig.2 Flow chart of the coal mill fault early warning experiment based on CNN-LSTM network
3 试验验证
3.1 数据采集与处理
为了验证本文模型的有效性,取某660 MW 火电机组的中速磨煤机2020 年5 月1 日0 时0 分至2020 年5 月7 日23 时59 分的运行数据作为试验数据,该设备在2020 年5 月7 日8:53 发生了堵煤故障,数据采样间隔为1 min。选取5 月1 日至5 月5日共7 200 组数据作为训练集和验证集,选取5 月6 日的1 440 组数据作为测试集。5 月6 日与5 月7日的数据共同作为用于故障预警试验的样本数据集,这2 880 组数据称为样本时刻。磨煤机5 月6日与5 月7 日的运行数据如图3 所示。
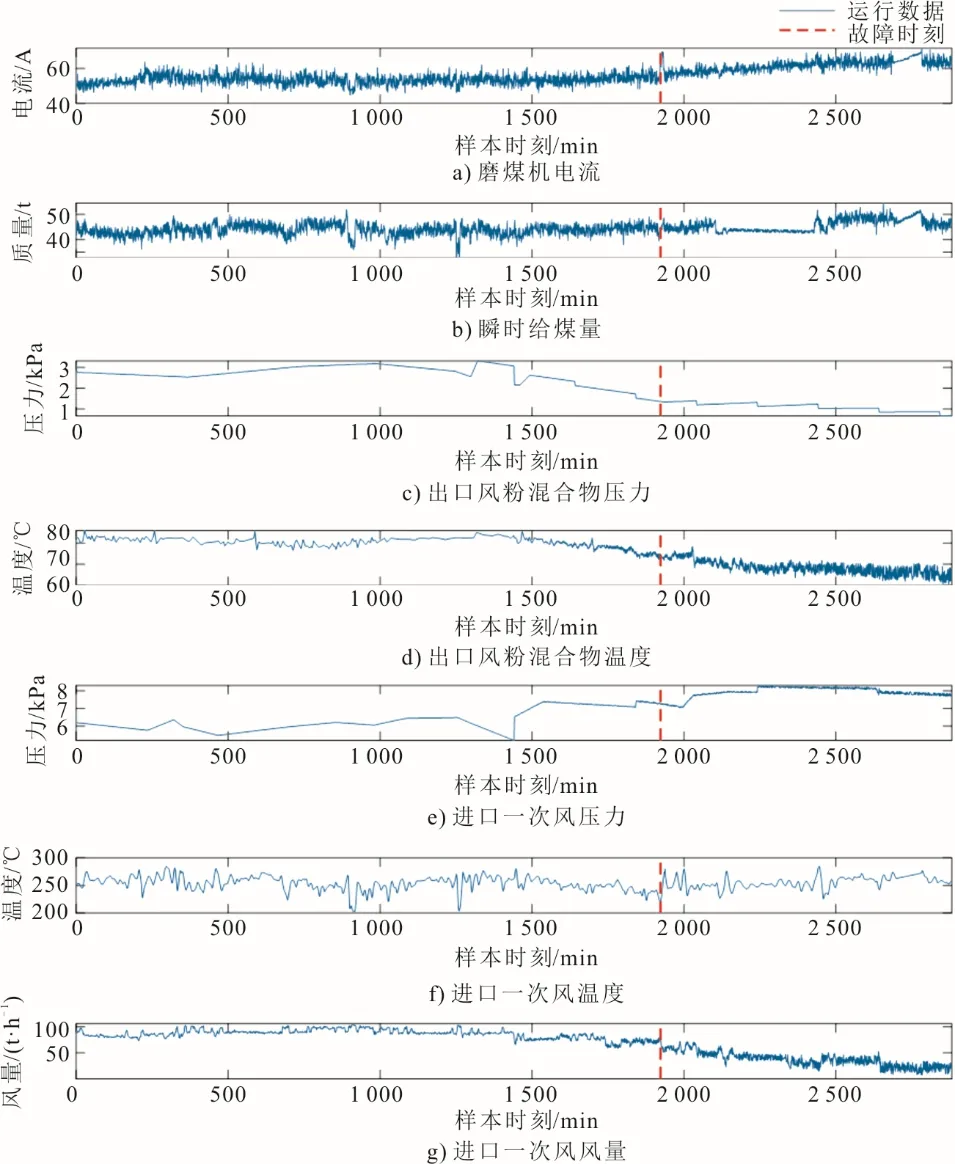
图3 磨煤机堵煤故障数据Fig.3 Parameter data of coal blockage fault of the pulverizer
由图3 可见,磨煤机发生堵煤的原因主要是进口一次风风量偏低造成风煤比不匹配,表现为磨煤机出口风粉混合物温度降低,出口风粉混合物压力降低,磨煤机电流增大,进口一次风压力增大。
在对CNN-LSTM 模型训练前,首先将训练数据集进行数据清洗,去掉异常数据和空白数据,随后利用式(13)进行归一化处理。数据归一化处理既可以提高模型收敛速度,又能一定程度上提升模型精度。

随后将训练集转化为适用于监督学习的数据集[25]。具体方法为将某一测点的时间序列数据xi=[xi(t1),xi(t2),…,xi(tn)]依次前移一个时刻,得到xi-1=[xi(t0),xi(t1),…xi(tn-1)]。相当于创建了各列数据的前驱观察序列,并将该前驱观察序列作为模型输入,这就转化为监督学习的数据格式。
3.2 模型训练
在搭建好CNN-LSTM 模型并选取合适的超参数后,将训练集输入模型进行训练,训练次数为300 次,模型训练的损失值如图4 所示,CNN-LSTM模型在测试集上的预测结果如图5 所示。
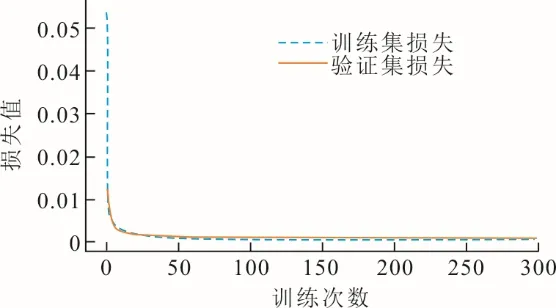
图4 CNN-LSTM 模型训练损失值Fig.4 Training loss value of the CNN-LSTM model
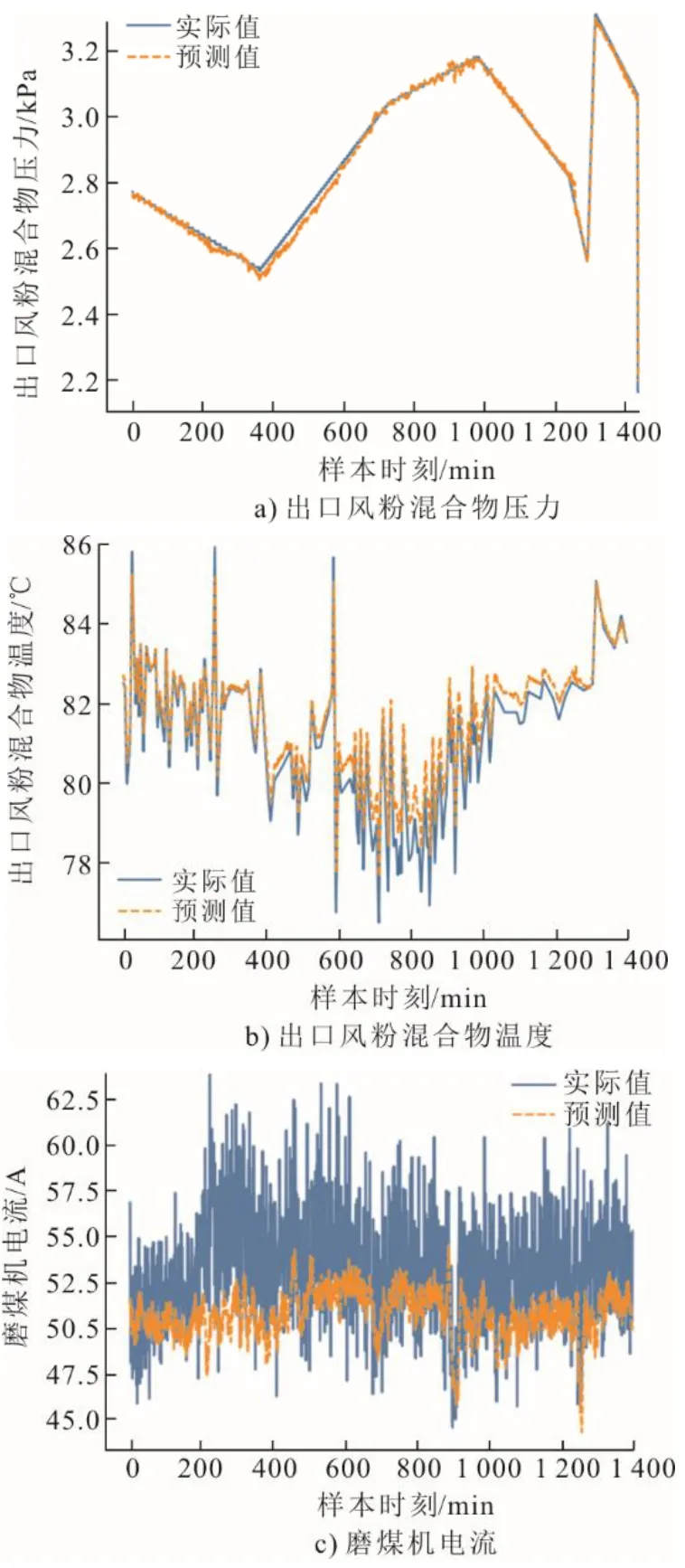

图5 CNN-LSTM 模型在测试集的预测结果Fig.5 Prediction results of the CNN-LSTM model using test set
作为与CNN-LSTM 模型对比,将该训练集输入相同层数的LSTM 神经网络进行训练,采用均方根误差δRMSE、平均百分比误差δMAPE、相关系数R2对训练结果进行评价。
模型评价指标分别为:
1)均方根误差δRMSE

2)平均百分比误差δMAPE
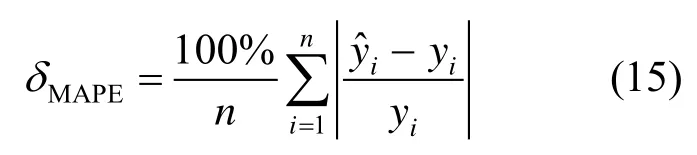
3)相关系数R2
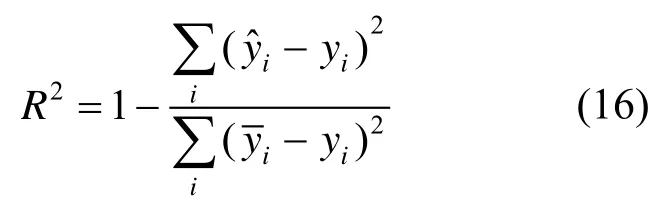
CNN-LSTM 与LSTM 神经网络模型训练结果对比见表3,根据表3 结果可以得出:CNN-LSTM模型与LSTM 神经网络模型相比,均方根误差降低了17.0%,平均百分比误差降低了21.7%,相关系数提升了18.5%。CNN-LSTM 模型结合了2 个模型的优点,一定程度上综合了多元时间序列数据的全局特征与局部特征,因此模型拟合精度更高,可以用于故障预警。

表3 LSTM 与CNN-LSTM 模型训练结果对比Tab.3 Comparison of training results between the LSTM and the CNN-LSTM neural network model
3.3 故障预警试验
测试集的数据作为设备正常状态下的运行数据将用于计算预警阈值。根据式(9)分别计算CNNLSTM 模型和LSTM 神经网络模型在测试集上的偏离度序列并采用滑动窗口法处理,窗口宽度设置为50。运用核密度估计法计算不同模型的偏离度序列的概率密度函数,结果如图6 所示。


图6 不同模型偏离度序列的概率密度函数Fig.6 Probability density function of deviation degree series of different models
根据式(12)计算得到CNN-LSTM 模型的偏离度序列概率密度函数的0.99 分位数为45.27,LSTM神经网络模型的偏离度序列概率密度函数的0.99分位数为31.86,分别将该值设置为预警阈值。不同模型的偏离度序列与预警阈值如图7 所示,不同模型下的磨煤机故障预警实验结果如图8 所示。
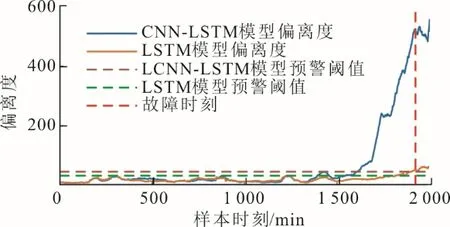
图7 不同模型的偏离度序列与预警阈值Fig.7 Deviation degree series and fault warning threshold of different models
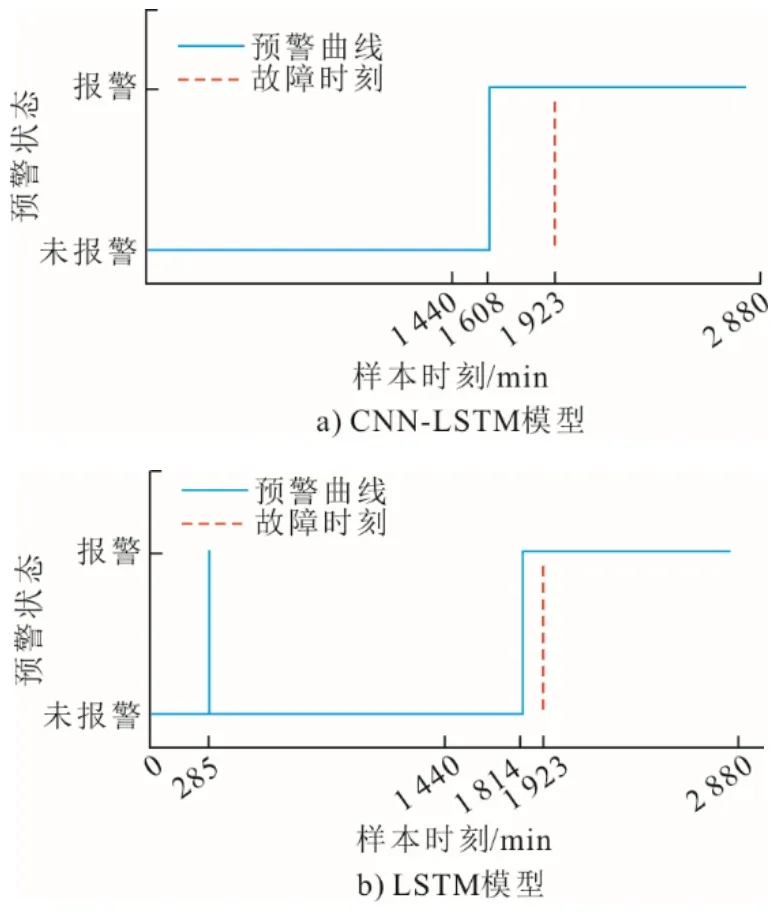
图8 不同模型下的磨煤机故障预警实验结果Fig.8 Experimental results of the coal mill fault early warning test using different models
由图8 可见,试验中故障时刻为第1 923 个样本时刻,CNN-LSTM 模型的预警时刻为第1 608 个样本时刻,提前315 min 发现磨煤机出现堵煤故障趋势并发出警报。LSTM 神经网络模型预警时刻为1 814 个样本时刻,提前109 min 发出警报,落后CNN-LSTM 模型206 min,且在第285 个样本时刻出现了一次误报警。根据试验结果可以看出基于CNN-LSTM 模型的磨煤机故障预警效果优于单一的LSTM 神经网络模型。试验结果表明本文所提出的模型能够提前对磨煤机堵煤故障做出预警,在故障发生前争取一定的时间进行维护,可为磨煤机设备状态监测提供参考依据。
4 结语
基于磨煤机故障预警方法的研究,本文提出并验证了一种基于CNN-LSTM 模型的磨煤机堵煤故障预警方法。通过CNN 初步提取数据特征后,再用 LSTM 神经网络进行多元时间序列数据的预测。在不同模型的对比实验中,本文提出的模型在3 种评价指标上均优于其他模型。且在故障预警试验上提前315 min 发现磨煤机堵煤故障趋势,有助于企业提前进行设备检修维护,保证发电效率,减少经济损失。
本文利用某660 MW 机组中速磨煤机堵煤故障数据对模型进行验证,结果表明该模型能够实现对磨煤机堵煤故障的早期预警。验证了本模型对于渐变故障识别的准确度。本文所提出的模型及预警方法不仅适用于磨煤机的故障预警,还可应用于其他辅机设备、风力发电等多变量工业过程。实验表明该模型能够对磨煤机多参数耦合类的故障做出有效预警。
