基于深度学习的视觉里程计方法综述
2022-10-17职恒辉尹晨阳李慧斌
职恒辉,尹晨阳,李慧斌
西安交通大学 数学与统计学院,西安 710049
为了使智能体可以像人类一样感知和探索世界,在环境中实现对智能体位置和姿态的估计即定位问题变得非常关键[1]。为达到该目的,各种不同的系统和方法被相继提出,通常包含全球定位系统(GPS)、惯性导航定位(INS)、激光雷达定位、人工标志定位等。然而,上述系统和方法均存在一定缺陷,例如GPS只能用于室外定位;惯性导航系统存在累计漂移问题;激光雷达定位成本昂贵。随着计算机视觉技术的发展,仅使用视觉传感器实现定位得到了研究者们的广泛关注。视觉传感器成本低、精度高,同时可以得到大量图像数据进而实现目标检测等其他计算机视觉任务。
视觉里程计VO(virual odometry)指从视觉传感器所拍摄的视频中实时恢复出其本身的位姿。最早的VO思想在1980年由Moravec[2]提出,他指出可以从滑动相机所采集的连续图像中实现机器人的位姿估计。随后Matthies等人[3]提出基于特征提取、匹配、帧间运动估计的经典框架,后续基于模型的算法大多由该框架发展而来。VO的概念由Nister等人[4]正式提出,该系统真正意义上实现了机器人的室外定位导航。此后,基于模型的VO算法因其发展时间长、理论模型健全,目前已在火星探测、自动驾驶、无人机、AR、VR等领域[5-8]得到了广泛应用。基于模型的方法虽然取得了丰硕的成果,但其在面对遮挡、动态物体等挑战性的场景时仍然鲁棒性较差,特别的,单目VO方法还存在尺度不确定性问题。而且此类方法高度依赖手工设计的低级特征,不能很好地表示现实世界中的复杂场景。此外,基于模型的方法假设世界是静态的,而在实践中,现实世界的场景几何形状和外观会随着时间发生一定的变化。
近年来,随着深度学习技术在目标检测、图像分类、语义分割等领域得到了成功应用,展现出其在VO中的巨大潜力。相比于基于模型的方法,基于深度学习的方法有以下优势:第一,相比于人工设计的低维特征,深度学习从大量数据中学习的高维特征在面对挑战环境时具有更强的鲁棒性;第二,基于深度学习的方法不需要复杂的参数标定和几何变换,而是使用端到端方式进行位姿估计;第三,基于深度学习的方法随着数据集的持续扩大,可以继续学习和适应新的环境,就像人类依靠直觉而不是准确的模型来探索新环境一样。诸多研究表明,基于深度学习的方法可在挑战性场景中取得更好的性能,展现了深度学习在解决VO任务中的潜力[9]。
虽然目前已有一些VO方法的综述,但大部分仅针对于基于模型的算法[10-13],或针对某个特定的领域如机器人定位[14],有些基于深度学习的SLAM综述包含了早期的深度学习VO方法[15-17],一些研究性文献的背景调研部分也对深度学习VO方法的研究现状进行了总结[18]。陈涛等人[19]虽然对深度学习方法进行了综述,但其发表时间较早,相对缺乏对各种方法的综合性对比分析以及基本数学原理、评价指标等的介绍,且只从三个方面展望了未来的发展趋势,对目前该领域仍存在的问题缺乏充分的总结和探讨。随着近两年深度学习方法的迅速发展,越来越多的基于深度学习方法被提出。因此,本文对近年来有代表性的、最新的有监督、无监督、模型与深度学习相结合的方法进行全面详细的综述,并对各类方法进行综合性的对比分析,介绍了该领域的基本数学原理、常用数据集、评价指标等必要知识。在此基础上,指出了深度学习方法仍然存在的一些问题,并对未来发展提供了一些建议。
1 基于模型的方法
通常,基于模型的方法通过数学模型和几何计算进行位姿估计,经过30年的发展,已得到了广泛应用。VO在实现方法上依据是否需要提取图像特征点主要分为两种方法:特征点法和直接法。
1.1 视觉里程计问题的数学描述
假设一个智能体搭载相机在环境中运动并采集连续的图像{I1,I2,…,In},VO的目的是计算出相邻图像Ik-1和Ik之间的刚体变换Tk-1,k∈ℝ4×4,见图1。进而由Tk-1,k恢复出相机的整体运动轨迹。刚体变换Tk-1,k由平移量和旋转量构成:
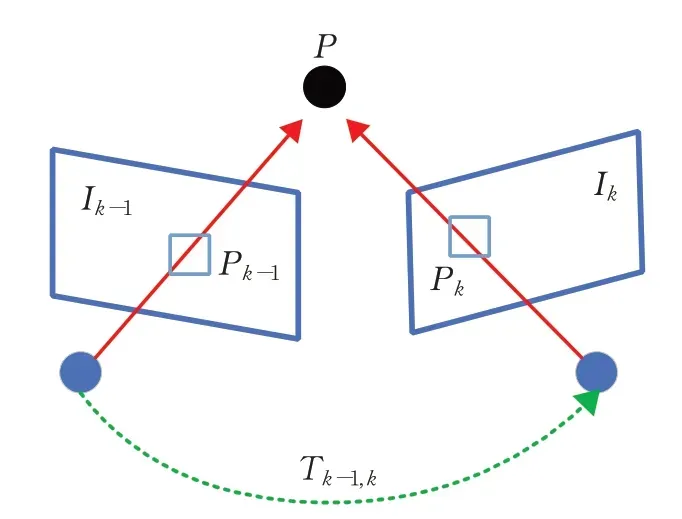
图1 刚体变换Fig.1 Rigid body transformation

其中,Rk-1,k∈SO(3)表示旋转矩阵,tk-1,k∈ℝ3×1表示平移向量。假定所有时刻图像对的相对变换集合为{T1,2,T2,3,…,Tn-1,n},则相机在时刻k的空间位姿Pk为:

其中,P0是相机在初始时刻的空间位姿。因此,可以递推得到整个相机的运动轨迹{P1,P2,…,Pn}。在增量计算运动轨迹时,某个时刻的估计误差不可避免地会随着时间累计。为了消除累计误差,根据计算得到的前k个位姿进行滤波或束调整(bundle adjustment)优化,从而估计更准确的局部轨迹。
1.2 基于特征点的方法
特征点法首先在图像中提取特征,这些特征在相机视角发生少量变化时保持不变,于是可通过特征匹配实现图像间的数据关联,从而对相机的相对变换矩阵进行求解。基于不同类别的数据关联,可以得到不同的位姿求解方法。当得到2D-2D的对应关系时,可使用对极几何法计算相对运动;当得到3D-2D的对应关系时,可使用PnP(perspective n point)、EPnP(efficient perspectiven-point)、P3P(perspective three point)等方法求解;当得到3D-3D对应关系时,则可使用ICP(iterative closest point)算法进行求解。求解得到相对变换矩阵后,再计算重投影误差对相机位姿以及空间点的三维坐标进行优化:
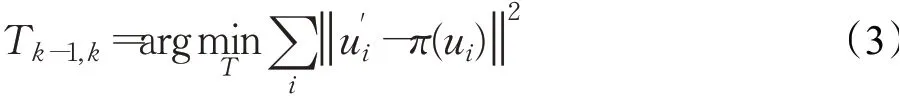
其中,ui表示Ik-1中的像素点,它投影到空间点的坐标为pi,u′i表示经过特征匹配得到的Ik与ui对应的特征点,π表示相机重投影模型。特征点法的基本流程如图2所示。
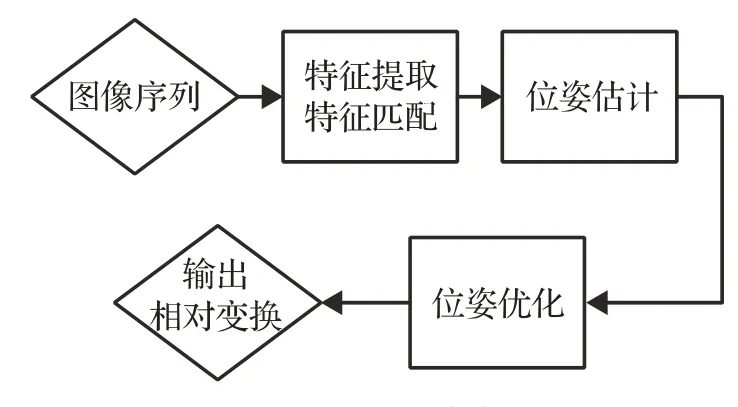
图2 特征点法基本流程Fig.2 Pipline of feature point-based method
特征表达对于基于特征点的方法至关重要,早期的方法使用图像中易于区分的角点作为特征,常用的有Harris角点、FAST角点、GFTT角点[20]等,角点虽然可以较好地与图像中的其他区域区分开来,但对于旋转、尺度、光照变化的鲁棒性不强。因此,研究人员提出了更加稳定的特征表达方法,如SIFT[21](scale invariant feature transform)、SUFT[22](speed-up robust features)、ORB[23](oriented FAST and rotated BRIEF)、BRISK[24](binary robust invariant scalable keypoints)等。
2007年Davison等人提出了MonoSLAM系统[25],是第一个仅利用单目相机实现实时定位与建图的方法,其使用扩展卡尔曼滤波器对相机位姿和特征点的三维坐标进行优化求解,但扩展卡尔曼滤波器假定了马尔可夫性,忽略更久远时间域上的信息,且计算复杂度较高。为解决该问题,Klein等人在2008提出了PTAM算法[26],该算法首次提出以非线性优化作为SLAM的后端,使用BA[27]处理关键帧。其也是第一个引入关键帧的算法,并将跟踪和建图两个子任务分别通过不同的线程处理。以该结构为基础,发展出许多优秀的开源SLAM系统,包括目前广为使用的ORB-SLAM系列[28-30]。ORB-SLAM算法由Mur-Artal等人2015年提出,整个流程都使用计算速度快、方向与旋转不变性的ORB特征,同时加入了回环检测模块,极大地提升了位姿和特征点三维坐标的精度,同时提供单目、双目、RGB-D相机的多个输入接口,成为了易用性最强之一的SLAM系统。
1.3 直接法
针对特征点法的缺点,直接法被提出,其利用灰度不变性假设从光流中完成数据关联,然后最小化光度误差估计相机运动:
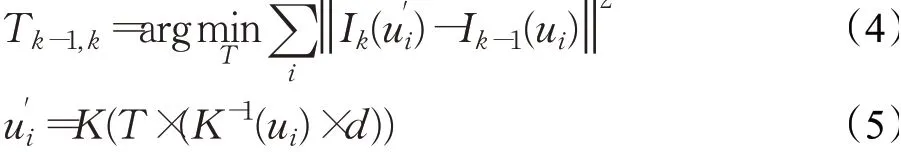
其中,ui表示Ik-1中的像素点,它投影到空间点的坐标为pi,u′i表示Ik与ui对应同一个空间点的像素点,Ik表示灰度值,K表示相机内参,d表示像素点对于当前帧的深度值。直接法的基本流程见图3所示。
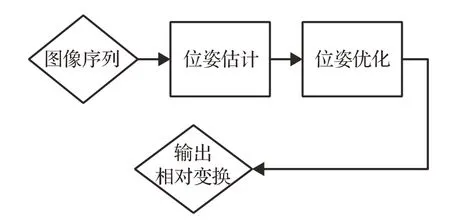
图3 直接法基本流程Fig.3 Pipline of direct method
DTAM[31]是Newcombe等人在2011年提出的基于关键帧的SLAM算法,该算法是真正意义上的第一个直接法,它不使用稀疏的特征点,而是使用图像中的每个像素。该算法首先通过立体测量完成地图初始化,然后根据重建的地图估计相机运动和像素深度,最后通过空间连续性对其优化,在实时几何计算方面取得了重大进展,但需要GPU才能完成实时计算,因此无法被部署到实际的移动设备上。LSD-SLAM[32]由Engel等人在2014年提出,它可从姿态跟踪中恢复半稠密的三维地图。该算法包含姿态跟踪、深度估计和全局地图优化三个线程,并可在全局地图上维护和跟踪,包括关键帧的地图和相关的半稠密深度地图,从而提升了精度和效率,可在无GPU加速的情况实时运行,但其使用卡尔曼滤波器进行优化计算,一定程度上忽略了时域信息。DSO[33]算法也是由Engel等人在2017年提出的,它使用光度误差来最小化几何和光度学误差,采用新的深度估计机制优化代替卡尔曼滤波器,并对图像中有梯度、边缘或亮度平滑变化的点均匀采样以降低计算量,进一步提高了精度和效率。
1.4 小结
基于特征点的方法通常具有较强的鲁棒性、较高的准确性、较快的运算速度,因而得到了广泛应用,但也存在下述问题和局限性。首先该类方法的性能取决于特征的设计方式,复杂的特征可以提高性能,但计算复杂度也会增加,因此需要在计算复杂度和实时性之间做出取舍;其次,在少纹理和重复纹理场景下,如天空、墙面、走廊等,精度会大幅下降甚至无法工作;再者,该类方法仅可恢复特征点的深度,因此无法构建稠密地图;最后,人工设计的特征仅使用了图像的局部信息,没有考虑全局信息,因此容易受到动态物体、遮挡的影响。
直接法不需提取特征点和描述子,因此不但效率得到了提高,在少纹理区域仍能正常运行。相比于特征点法仅利用稀疏特征点,直接法可使用任意多的像素进行位姿和三维坐标估计,因此其具有构建稀疏、半稠密以及稠密地图的能力。但其也存在一些局限性,首先直接法依靠梯度搜索来求解位姿,但大部分场景下的图像灰度是关于像素坐标的非凸函数,因此会导致优化过程陷入局部极小,无法得到最优解;其次直接法所依赖的灰度不变性是强假设,在相机的曝光参数发生变化、环境亮度发生变化的情况下,算法的精度会下降,因此其研究和应用仍然没有特征点法成熟,目前只适合于运动较小,图像整体亮度变化不大的情形。
基于模型的方法经过多年的发展,具有完善的数学模型支撑,不依赖于训练集的数据,计算量较小,可在未见过的场景中实时运行,因此其在精度、实时性、模型部署方面都有很好的表现,得到了广泛的实际应用,成为当前工业界主要应用的方法。但目前基于模型的方法依然存在以下问题:
(1)在相机运动速度较快、旋转角度过大的时候,基于模型的方法可能会出现“跟丢”的情况。
(2)基于模型的方法假设场景是静态的,对于环境中常见的动态物体如人、车等没有很好的处理方法,会造成模型精度的下降。
(3)对于光照强度变化剧烈、亮度较低、环境特征纹理不丰富等挑战性场景的鲁棒性不高。
(4)需要复杂的人工几何标定,过程繁琐。
2 基于深度学习的方法
基于深度学习的方法利用深度网络,通过端到端的方式直接从图像对中回归出六自由度的相机位姿。依据在训练时是否使用带标签的数据集,将其分为监督学习方法和无监督学习方法。除此之外,可以将基于模型的方法和基于深度学习的方法结合,得到模型-学习融合方法。
2.1 监督学习方法
Kendall等人在2015年提出的PoseNet[34]是首个利用CNN完成VO任务的方法,其采用端到端的方式从单目图像序列中回归出相机位姿。其在GoogleNet[35]的基础上进行修改得到23层网络结构,并使用了迁移学习和SFM(structure from motion)方法解决标签数据少的问题。该方法在光照改变、运动模糊等挑战性场景中的鲁棒性较强。但PoseNet的损失函数需要人工设置平移项和旋转项之间的平衡因子,可能会带来经验误差。为解决该问题,Kendall等人[36]又提出了两种新的损失函数,一种是通过网络自动学习平衡因子,另一种通过多视图几何融合平移项与旋转项,从而进一步提升了准确率。但上述的方法使用的损失函数仅考虑了单帧的信息,视觉里程计具有很强时间依赖性,Saputra等人[37]提出的方法使用复合相对位姿变换约束来构建损失函数,更好地利用了长序列间的时间相关性。
为了充分利用深度学习提取高维特征的能力,不同的基础网络架构被进一步提出。PoseNet等早期的深度学习方法利用CNN网络预测相机位姿,然而VO任务的输入为连续的图像序列,CNN无法很好地对其建模,因此可更好处理序列数据的RNN网络被引入到VO中。2017年Walch等人[38]首先使用了LSTM网络进行位姿预测,他们先使用CNN提取特征,然后将特征输入到LSTM单元中,从而使网络自动选出最适宜于位姿估计的特征,该方法虽然使用了RNN网络,但却只用于特征选择,没有充分利用其处理序列的相关性。在此基础上,Wang等人在2017年提出了DeepVO[39],该方法依然先用CNN提取特征,将特征排列为时间序列,然后通过双层的LSTM网络输出相机位姿,实现了序列相关性的建模,提高了基于学习方法的精度,其网络结构如图4所示,该结构也成为了监督学习方法的通用结构,但DeepVO使用的LSTM网络仅利用了之前帧的信息,而实际上当前帧后面的帧和当前帧具有共视关系。因此,Clark等人提出了Vidloc[40],将上述方法中的LSTM层替换为双向LSTM进一步提升了序列建模的能力。MagicVO[41]在此基础上将网络的输入由单帧图像替换为了堆叠的图像对,进一步提升了预测精度。ESP-VO[9]、Costante等人[42]和Kendall等人[43]分别引入不确定性度量进一步完善了上述工作,但他们的不确定性度量是由几个网络层简单的回归而来,并且没有合理利用得到的不确定性。受到他们的启发,Kaygusuz等人[44]使用混合密度网络将位姿作为混合高斯分布进行回归,并将不确定性作为预测结果稳定性的准则。现有方法使用的CNN和RNN网络的参数较多,导致模型训练、预测速度较慢,Koumis等人[45]使用3D卷积神经网络进行序列信息的建模,可以在更少的网络参数下实现更快计算。
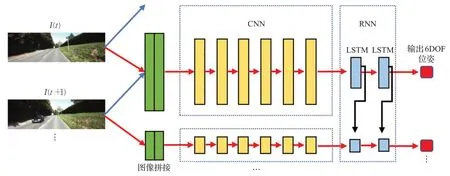
图4 DeepVO方法流程Fig.4 Pipline of DeepVO
由于里程计估计的是相邻帧间的相对变换,在最终计算整个运动轨迹时会不可避免地累计先前帧的误差,因此在长时间的预测中会出现误差累计、轨迹漂移问题。为解决该问题,Lin等人在2018年提出了DGRNet[46],该方法采用两个LSTM子网络分别预测运动的相对变换和绝对位姿,然后将二者进行融合,并提出基于交叉变换约束的损失函数,一定程度解决了累计漂移问题。相比于前者仅利用序列图像信息的方法,Peretroukhin等人[47]提出的方法使用贝叶斯神经网络学习每帧图像中的光照方向,然后将其与双目视觉里程计进行融合,从而减少累计漂移。LS-VO[48]将光流估计和VO预测整合到一个网络中进行联合计算和优化,提升了算法在光照改变、遮挡等场景下的鲁棒性,但其仅使用了相邻帧之间的光流,忽略了时间域上的信息。Huang等人[49]扩展了该方法,他们使用RNN来对隐空间的光流进行建模,且使用了自监督的方法来训练光流网络,加快了算法的整体收敛速度,得到了更加精确的运动轨迹。但上述方法在简单地使用RNN建模时间信息时,也会将时域上的错误信息进行累计,从而影响结果。因此,Xue等人[50]通过神经模拟记忆的方式逐步和自适应地保存从局部到全局的信息,并采用时空注意力的方法,利用共视性为每个视图动态的选择特征,从而解决了错误累计问题。
视觉里程计通常假设场景是静态的,因此当场景中存在动态物体比如行走的人和车时,会造成精度的下降。Kuo等人[51]在2020年提出的方法中使用注意力机制来减少动态物体的影响,其将相邻帧的光流图作为注意力子网络的输入,同时与语义分割后的图像结合,得到可衡量静态与动态物体重要性的注意力特征图,该特征图参与损失函数的计算,从而减少动态物体的影响。Xue等人[52]在2018年提出的方法中,使用上下文注意力机制选择适用于不同运动模式的特征,从而提升了网络面对动态物体时的鲁棒性。
由以上综述可知,监督学习的基本流程是使用CNN和RNN构建能提取高维图像特征的网络,然后通过全连接层或卷积层回归出六自由度的相对变换,最后通过带标签的数据集来训练网络,实现相机位姿的估计。学者们在此流程上,从网络基础架构、轨迹漂移问题、损失函数设计问题、动态物体问题等方法出发,提出了各种方法进一步提升了网络的精度。
2.2 无监督学习方法
无监督学习方法不需要人工标注的数据集,因此具有更好的泛化性与适应性,近年得到了广泛关注。
得益于图像仿射变换技术(affine transformation)的发展[53],Garg等人[54]在2016年第一次使用无监督方法获得了单帧图像的深度,该方法输入两个已知位姿的图像对A和B,利用深度网络回归出图像A的深度图,然后与图像B经过仿射变换得到假图像A′,根据A与A′之间的差异构造光度一致性损失函数,从而实现了无监督学习,但该方法仅可预测深度。为了同时预测深度和相机相对变换,Zhou等人[55]提出一个可以同时预测深度和帧间相对变换的无监督学习算法,该算法输入相邻图像对,分别称为源图像和目标图像,目标图像由深度估计子网络提取深度,同时将两张图像拼接后输入位姿估计子网络估计相对变换,然后经过warping计算:

其中,t和s分别表示目标图像和源图像,p表示像素点位置,K、T̂、D̂分别表示相机内参,网络估计的帧间变换矩阵,深度图。最后使用计算得到的假源图像和真实源图像构建损失函数,实现了深度和位姿估的联合估计,其网络结构如图5所示,该结构也成为了无监督学习方法的基本框架。
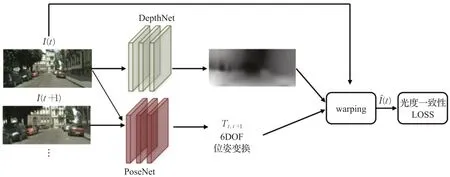
图5 文献[55]方法流程Fig.5 Pipline of literature[55]method
为了进一步增强深度学习提取高维特征的能力,不同的基础结构被提出。SFM-Net[56]通过增加语义分割网络和光流网络,将语义信息和光流信息融合到位姿和深度预测中。Wang等人[57]提出的方法首次将光流作为网络输入,并利用前向后向光流一致性约束构建损失函数,进一步提升了精度。D3VO[58]将光照变换、位姿不确定性估计整合到VO框架中,提升了网络在面对光照变化、遮挡等情况下的鲁棒性。虽然上述的方法通过整合多种信息来提升精度,但这也会使网络参数过多,训练时间过长。为解决该问题,Kim等人[59]仅使用单一的Mask-RCNN网络提取特征,即可同时实现位姿估计、深度估计、目标检测、语义分割,该工作降低了多任务训练时的计算量。为进一步提升位姿预测的效率,Zhang等人[60]仅用网络获得初始的位姿,而在后续的推断步骤中仅对姿态进行最小化光度误差的梯度更新,从而在降低计算量的同时得到了精确的结果。然而,他们虽然更好地利用了网络学习高维特征的能力,但在初始的信息关联阶段,只是简单地对原始图像进行了拼接。Liang等人[61]使用孪生网络分别提取单帧图像的特征,并在高维的特征空间完成了相邻帧的信息关联,充分地利用了深度学习学习高维特征的能力,进一步提升了网络的精度。
大多数基于深度学习的方法使用光度一致性来实现无监督学习,但光度不变性是强假设,在光照改变、相机曝光改变等情况下该假设会遭到破坏,导致精度下降。使用光度一致性假设构建的损失函数仅考虑了像素级的差异,对于离群点较敏感。因此,Godard等人[62]使用结构一致性度量SSIM[63]构建光度一致性损失函数,从图像结构的层次考虑了真实图像和重建图像的差异。但上述的方法仅从图像层次直接比较了真实图像和重建图像之间的差异,忽略了高维的信息。因此,Almalioglu等人[64]提出使用对抗生成网络GAN[65]实现无监督学习,该方法的生成器从随机数据中采样,得到当前帧的深度图,然后判别器计算warping得到的假图像与真实图像间的差异,从而提升网络在光度一致性假设被破坏时的鲁棒性。Li等人[66]扩展了该方法,他们的生成器直接回归单帧图像深度图和帧间相对位姿变换。为了更好地利用高维图像特征,在上述工作的基础上,Feng等人[67]提出了一种新颖的堆叠式对抗生成网络,底层网络用于回归单目深度图和相机位姿,而高层网络则用于判别假图像和真图像的差异,该方法可以更好地提取高维特征,从而提升网络的精度和鲁棒性。上述的方法依然是从真实图像和重建图像间的差异出发来实现无监督训练,一定程度上依然依赖光度一致性假设,为彻底抛弃该框架,Iyer等人[68]提出使用复合变换约束来构建损失函数,该方法分别估计出一段图像序列中每个图像对的相对变换,将这些相对位姿通过复合变换约束:

构建的损失函数实现了无监督学习。
单目视觉里程计面临尺度不确定性的问题。为解决该问题,Zhan等人[69]提出使用基线校准过的双目图像进行训练,该方法将左右图像对的光度一致性构建损失函数,并使用了图像的稠密特征表达来辅助训练,从而将校准双目图像的尺度带入预测结果中,但该方法仅简单地利用了双目图像的光度一致性约束,没有更深层次地考虑双目图像间的几何关系。在此框架上,UDeepVO[70]和Undemon[71]分别使用双目图像的位姿一致性约束和双目视差光滑约束来构建损失函数,进一步消除了尺度不确定性。不同于上述使用双目图像的方法,Liu等人[72]在2019年提出的方法中通过雷达获取的深度信息来辅助训练,赋予网络绝对的尺度。基于深度学习的方法除了不能获得绝对的尺度,预测的每一帧尺度也是不固定的,因此在长序列的轨迹预测中精度会下降。为解决该问题,Bian等人[73]将前一帧的深度投影到当前帧中,与当前帧的深度值对比,从而构建深度一致性约束,迫使相邻的帧具有一致的尺度,从而一定程度上解决了该问题,但他们的方法没有考虑到投影值的可靠性,因此结果存在一定的误差。为解决该问题,Almalioglu等人[74]对投影的深度赋予正视角等约束,并且提出了可以处理遮挡的遮挡感知损失函数,进而得到了一致的尺度和更精确的结果。
视觉里程计面临的另一个问题是当场景中存在动态物体或遮挡时比如行走的人、车时,会导致方法的精度大幅下降。为解决该问题,Yin等人在2018年提出了GeoNet[75],该算法分为三个阶段,第一阶段回归出相对变换和深度图,然后通过几何变换计算出图像间的光流。第二阶段的子网络以计算得到的光流作为输入,输出消去动态物体影响的全光流图,最后通过仿射变换损失对两个阶段进行联合优化,从而提升了网络对于动态物体的鲁棒性。但该方法仅考虑了动态物体,当图像中存在遮挡时,无法充分地提取特征,会造成精度的下降。为解决该问题,2020年Zou等人[76]借鉴了基于模型算法中关键帧的思想,建立一个双层的LSTM网络,第一层LSTM用于预测初始的相机变换,第二层LSTM使用记忆力模块[77]实现了不同帧重要性的筛选。
基于深度学习的方法在与训练数据不一致的场景中测试时,会出现精度下降的问题,对于不同场景泛化性较低。为解决该问题,2020年Li等人[78]引入了在线学习技术,使用在线元学习的方式使网络不断适应与训练数据集不同的新环境,并提出使用特征对齐来处理不一致的数据分布,从而提升网络面对新场景时的泛化性。之后,他们又将贝叶斯建模推理[79]和高斯牛顿优化融入到在线学习中,在保证泛化性的同时提升了网络的精度。
由以上综述可知,无监督学习方法的基本框架是由位姿估计和深度估计两个子网络构成,然后通过几何变换、图像仿射变换实现整个网络的无监督训练。在此框架基础上,各类方法从基础架构、损失函数设计问题、尺度不确定性问题、动态物体问题、场景泛化性问题等方面入手,逐渐提升了无监督学习方法的准确性和鲁棒性。
2.3 模型-学习融合方法
基于模型的方法虽然有一些缺点,但经过多年发展并得到了广泛应用,具有其本身的优势,因此将基于模型的算法和基于深度学习的算法相结合,也是当前发展的趋势之一。
基于深度学习的方法缺乏几何建模,可解释性较差。因此,Prasad等人[80]将对极约束引入到深度学习方法中,该方法对仿射变换后假图像和真图像提取SURF特征,并进行特征匹配,然后计算本征矩阵来构造两幅图像的对极约束,用其构造损失函数,可以提升方法的鲁棒性。在此基础上,Shen等人[81]使用PnP[82]算法从网络估计的深度信息中计算绝对位姿,并构建绝对位姿约束来提升算法的精度。VlocNet++[83]不仅使用几何约束,而且融合了语义分割的信息,其通过多任务学习的方法,同时估计相对位姿、绝对位姿、语义分割图,并使用自适应加权来融合各个子任务,实现空间域上的一致性。但上述方法忽略了时间域的信息,因此Li等人[84]提出的方法直接从单目图像序列中输出一个局部窗口的姿态图,然后通过图优化和回环检测来提升精度。
上述方法仅将更多的几何约束引入到基于学习的方法中,为了实现更深层次的融合,可以将一种方法的结果整合到另一种方法的具体步骤中。D3VO[58]首先通过深度网络分别得到深度图、光度不确定性和相对变换,然后将深度图融合到直接法中的双目几何约束计算步骤,将光度不确定性用于直接法的光度能量损失计算步骤,将相对变换用于前端追踪和后端优化的初始化步骤,可以有效提升直接法的精度。Iyer等人[68]提出的方法中使用ORB-SLAM对网络进行预训练,为后续的无监督学习提供良好的参数初值,加速收敛。
基于模型的方法依赖静态场景假设,因此其面对动态物体、光照改变等场景时的鲁棒性较差,造成精度下降。为解决该问题,2018年Barnes等人[85]使用深度学习对场景中的动态物体生成掩码从而消去其影响,该算法分为两个阶段,第一阶段是通过深度网络得到动态物体的mask,在此阶段通过对同一场景进行多次遍历,可以得到带动态物体标签的数据集,用于训练网络。第二阶段将网络产生的mask用于特征点法和光流法的局部地图优化中,对优化函数进行像素加权提升效果,该算法在包含大量动态物体的实际场景中仍能稳定运行。但上述方法仅利用简单的mask消去动态物体的影响,没有充分考虑动态物体对视觉里程计问题本身的影响。因此,Wagstaff等人[86]提出的方法不是直接估计帧间相对变换,而是回归出由于违反建模假设而导致的系统错误,将得到的系统错误与位姿变换进行融合,可以得到更精确的结果,该方法可以与任何基于模型的方法进行结合,提升其准确性和鲁棒性。模型与学习融合算法因为可以结合模型法与深度学习方法的优点,得到了研究者们的关注。研究者们从将几何约束引入到基于学习的方法中、将二者按步骤融合、利用深度学习方法解决模型法出现的问题三个方面出发,提出了一些出色的工作。
2.4 小结
监督学习方法网络结构相对简单,不需要同时预测深度即可获得相对变换,因此训练和测试速度较快。且随着数据集的扩大,其精度在理论上会持续提高。表1按时间发展顺序对监督学习的一些重要工作的特点以及性能指标进行了总结。从表中可以看到,随着深度学习的快速发展,更加先进的基础网络结构、多任务辅助训练、不确定性估计等方法被逐渐引入到视觉里程计任务中,使得监督学习方法的精度进一步提高,在一些场景下甚至超过了基于模型的方法。但同时,监督学习方法也有一定的缺陷。其需要大量带标签的数据集才能取得不错的效果,传感器位姿的标签通常是由搭载高精度GPS等传感器的移动设备在实际运行中收集而来,这需要很高的成本。因此监督学习方法的应用被限制,无监督学习成为新的研究热潮。

表1 监督学习方法Table 1 Supervised learning methods
无监督学习方法无需人工标注的数据集,它可以通过预测的位姿和深度实现网络的无监督训练。这成为无监督方法的最大优势。此外,无监督学习方法通过几何变换、仿射变换的方式将位姿和深度联系起来,更符合真实的物理模型,具有一定的可解释性。并且在构建损失函数的过程中,可以更好对动态物体、遮挡进行处理。因此无监督方法具有更强的鲁棒性和易用性,成为当前最受关注的深度学习方法。但无监督学习方法的网络结构较复杂,需要同时使用两个子网络来预测位姿和深度,参数量会大幅上升,因此训练和推理的速度相对较慢,在实际场景中较难部署。表2按时间发展顺序对无监督学习的一些重要工作的特点以及性能指标进行了总结。
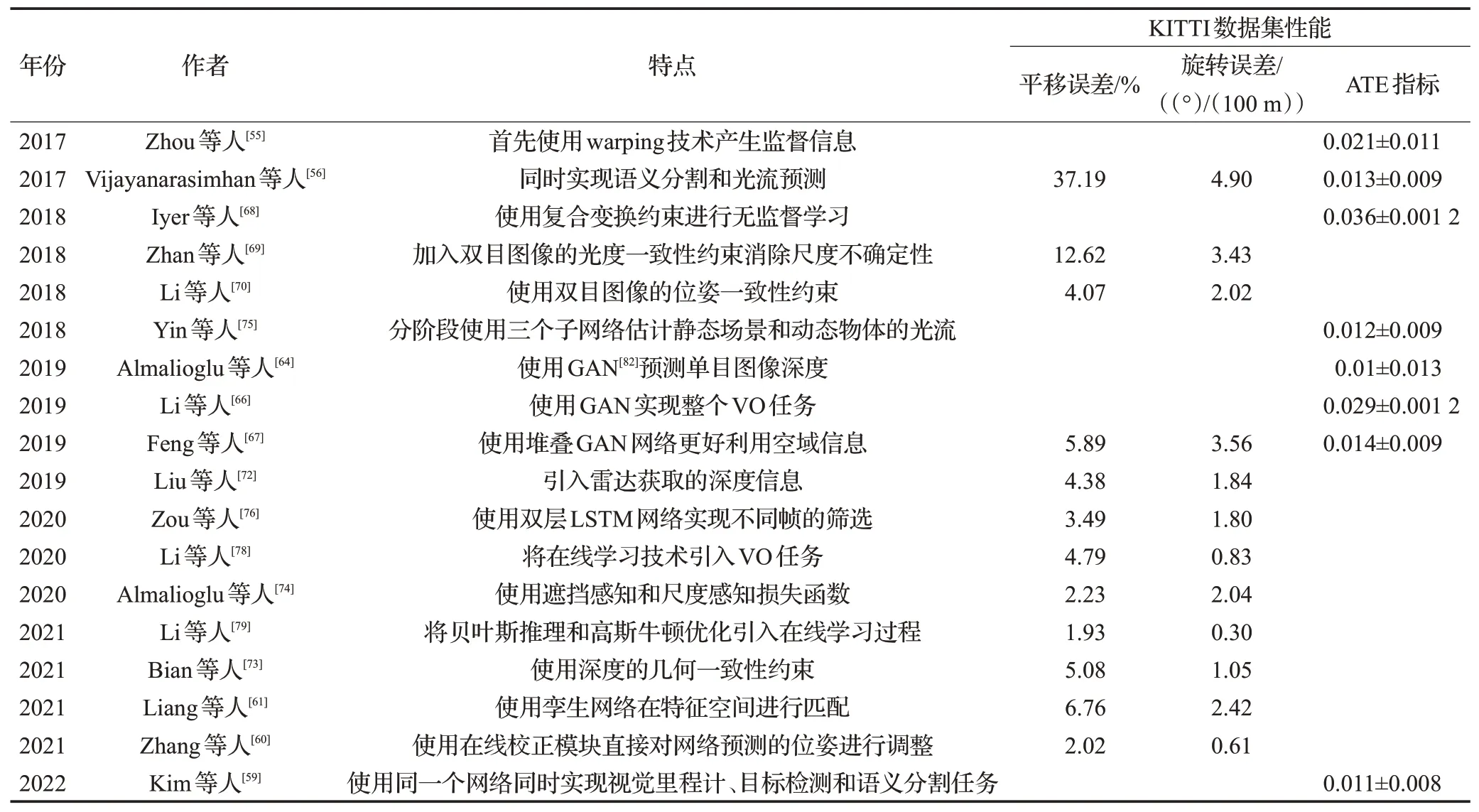
表2 无监督学习方法Table 2 Unsupervised learning methods
模型-学习融合方法可以结合基于模型的方法和基于深度学习方法的优势,在一定程度上提高了模型法对挑战性场景的鲁棒性,也提高了深度学习方法的可解释性。但该类方法也同时具有二者的局限性,其深度学习的部分推理速度较慢,影响实时性,而将二者融合在一起需要复杂的参数设置,影响易用性。
3 数据集、评价指标及方法性能比较
3.1 常用数据集
(1)KITTI数据集
KITTI数据集[87]由德国卡尔斯鲁厄理工学院和丰田美国技术研究院联合创办,是目前国际上最大的自动驾驶场景下的算法评测数据集。KITTI包含市区、乡村和高速公路等场景采集的真实图像数据,一共有22个视频序列,其中11个视频序列带有ground-truth标签。每张图像中最多达15辆车和30个行人,还有各种程度的遮挡与截断,以10 Hz的频率采样收集而得。
(2)EuRoC数据集
EuRoC数据集[88]由苏黎世联邦理工学院创办,由搭载双目相机和IMU的微型无人机在两个室内场景和一个大规模的工业场景搜集而得。整个数据集包含11个双目视频序列,采集的帧率为20 Hz。数据集由无人机的飞行速度、光照、遮挡、场景纹理的情况一共分为简单、中等、困难三个难度。
(3)TUM RGB-D数据集
TUM数据集[89]是德国慕尼黑工业大学Computer Vision Lab创办,数据由手持Kinect相机采集,是目前应用最为广泛的RGB-D数据集,包含了depth图像和rgb图像,以及对应的ground-truth等数据。该数据主要包含了不同纹理、光照、结构和采集帧率的多个类别室内环境视频序列。
(4)Cityscapes数据集
Cityscapes数据集[90]是由2015年德国奔驰公司推动发布的城市景观数据集。该数据集由搭载多种类别传感器的汽车在德国的50个城市的不同季节收集而得,Cityscapes拥有5 000张精细标注的城市环境的驾驶场景图像,它具有19个类别的密集像素标注以及高精度GPS采集的视觉里程计标注。该数据集不仅在可以用在VO算法的训练测试评估,也是最具权威性和专业性的图像分割数据集之一。各个数据集的图片样例如图6所示。
3.2 评价指标
假设算法估计的位姿为P1,P2,…,Pn∈SE(3),真实的位姿为Q1,Q2,…,Qn∈SE(3),其中下标代表时间。通常使用以下评价指标对估计的准确性进行衡量。
(1)相对位姿误差RPE(relative pose error)
相对位姿误差可用来衡量运动轨迹中相隔固定时间的局部准确度,其描述了在固定时间间隔Δ中,两帧位姿差相比于真实位姿差的精度。第i帧的RPE定义如下:
当已知视频帧总数n与时间间隔Δ时,共可得到n-Δ个RPE,此时可通过平均值、中位数或更常用的均方根误差RMSE进行统计,得到整个轨迹的总体RPE:

其中,tran(Ei)表示取相对位姿误差中的平移部分。通常会将其除以整个轨迹的长度(单位为100 m),得到更为通用的平均平移误差terr(%)。当需要衡量旋转部分的误差时,只需从Ei中取出旋转部分进行相同的计算,得到平均旋转误差rerr((°)/(100 m))。
(2)绝对轨迹误差ATE(absolute trajectory error)
绝对轨迹误差可衡量估计位姿和真实位姿的直接差值,非常直观地反应了算法精度和轨迹全局一致性。然而,估计的位姿和真实位姿通常不在同一坐标系中,因此需要先将两者对齐。对于双目SLAM和RGB-D SLAM而言,尺度是统一的,因此只需通过最小二乘法计算从估计位姿到真实位姿的变换矩阵S∈SE(3);对于单目相机,其尺度具有不确定性,因此需要计算从估计位姿到真实位姿的相似变换矩阵S∈Sim(3)。第i帧的ATE定义如下:

与RPE类似,依然可以使用平均值、中位数、均方根误差RMSE来统计整个轨迹的ATE,常用的RMSE统计为:
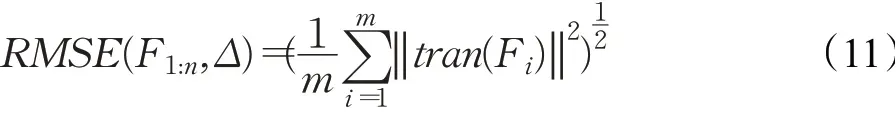
RPE和ATE具有强烈的相关性,但却各有不同,在实际应用中,可选择合适的指标进行算法评价。
3.3 总结与对比分析
同时,为了横向比较基于模型的方法和基于深度学习的方法,从方法的准确性、对于挑战性场景的鲁棒性、实际部署中的运行效率、对于新场景的泛化性、训练测试过程中所需的数据量、实际的应用场景六个方面衡量了各类方法的效果,并对其进行对比分析,结果见表3。
从表3中可以看出,在方法的准确性方面,基于模型的方法因为依赖静态场景假设,因此当场景中存在动态物体时,精度会明显下降。此外基于特征点的方法依赖特征点的质量和可区分性,当场景纹理单一时,精度无法得到保证。而直接法依赖灰度不变性假设,在光照改变、相机曝光值改变时,灰度不变性假设遭到破坏,方法精度下降。基于深度学习的方法因为可以提取高维的图像特征,因此可以较好地处理上述问题,但当测试场景与训练集的场景风格差异较大时,方法的精度也会下降。
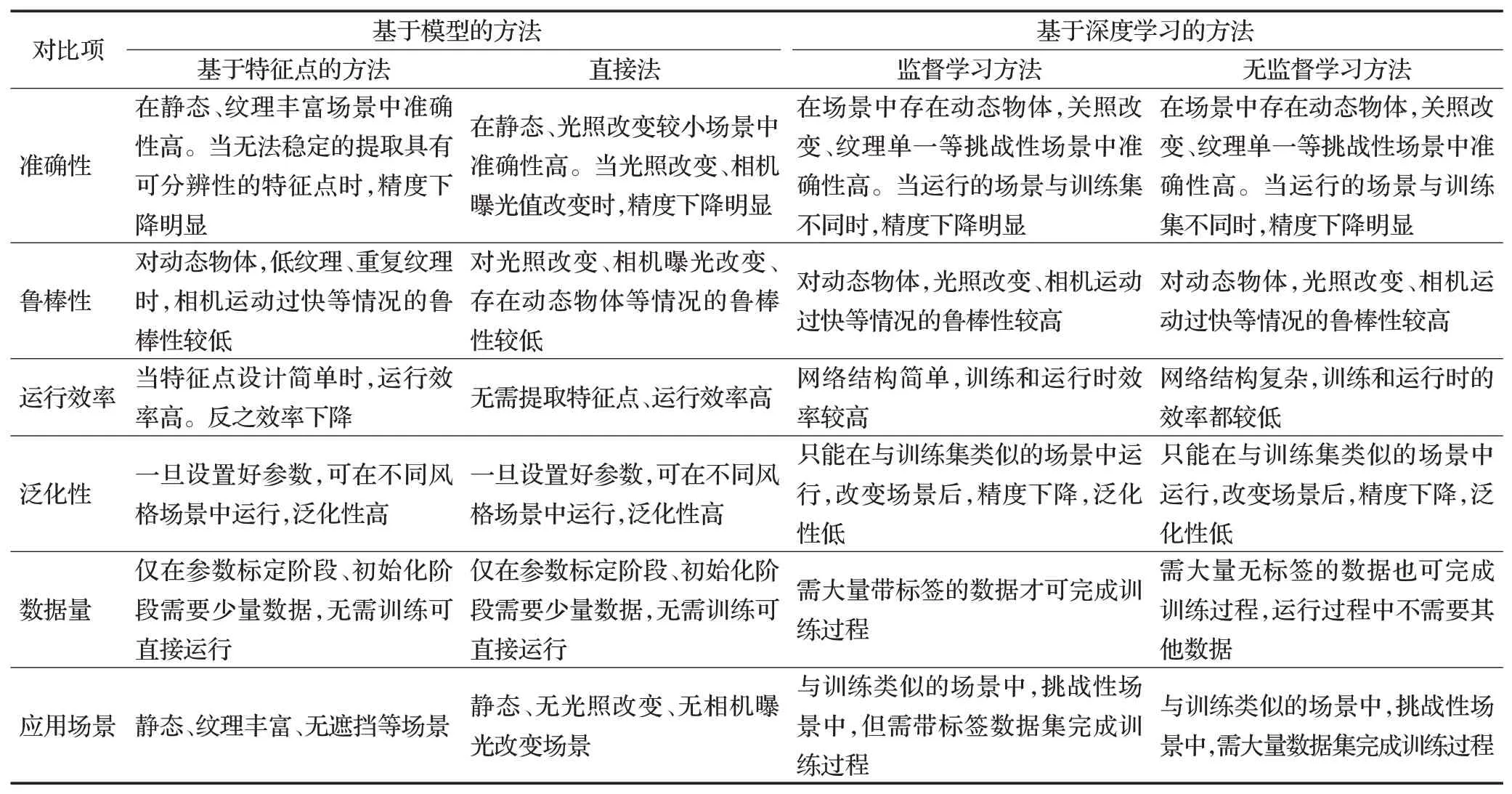
表3 模型法和深度学习法对比Table 3 Model-based methods versus deep learning-based methods
在鲁棒性方面,由于基于模型的方法依赖静态场景假设,因此对于违反该假设的情况,比如动态物体、低纹理、光照改变等情况的鲁棒性较低。而基于深度学习的方法因为可以自动地学习高维的特征表达,也不依赖于静态场景假设,因此对于上述情况的鲁棒性较强,可以稳定运行。
在运行效率方面,基于特征点方法的计算时间主要花费在特征点的提取和匹配上,因此当设计的特征点较简单时,运行效率很高,但同时精度会相应地下降。直接法无需提取特征点,使用光流完成图像间的信息关联,因此运行效率很高。对于基于深度学习的方法,深度学习网络具有大量的参数,需要进行长时间的训练才能取得令人满意的效果,因此运行效率较低。特别的,无监督学习方法通常包含了位姿估计和深度估计两个子网络,因此运行效率相对比监督学习方法更低。
在泛化性方面,基于模型的方法依赖几何或概率模型,因此一旦建立好模型、设定好参数后,该类方法可在不同的场景中运行。而基于深度学习的方法对数据敏感,在面对与训练场景差异较大的场景时,泛化性较低。
在所需数据量方面,基于模型的方法只在初始阶段需要少量的数据进行相机内参标定以及初始化等。而基于深度学习的方法需要从数据中进行学习,因此需要大量的数据进行网络的训练。特别的,监督学习方法所需的数据需要带有高成本的人工标签。
在应用场景方面,基于特征点的方法适用于静态、纹理丰富、无遮挡的场景。直接法适用于静态、无光照改变、无相机曝光改变等场景。当有带标签数据集,并且测试场景与训练场景相差不大时,使用监督学习方法可以更好地处理动态物体等挑战性情况。而当缺乏带标签的数据集时,使用无监督学习方法可以取得更好的效果。
4 问题与展望
4.1 当前存在的问题
(1)用于训练的数据集依然不足。大规模的数据集对于基于深度学习算法至关重要,然而在当前的V-SLAM或VO领域并不存在规模足够大,质量足够高的数据集用于训练网络。经常使用的KITTI等数据集虽然在基于模型的方法中足够用于测试和评估,但对于深度学习方法的训练仍有所欠缺。此外,当前数据集采集场景比较单一,导致训练的网络对于新场景的泛化性较差。因此如何收集到大规模、高质量的数据集依然是当前的一个问题。
(2)网络结构依然较简单。近年CNN在计算机视觉的各个领域中扮演了重要角色,因此CNN也是第一个被用于视觉里程计任务的深度学习框架。然而CNN对于学习序列数据的相关性是不足的,因此RNN网络得到了广泛应用,然而RNN网络虽能很好地学习序列图像间的相关性和依赖性,但其却不能像CNN网络一样从图像中提取合理的高维特征表达。因此,如何设计出既能建模序列相关性又能提取高维特征的深度学习框架是当前存在的重要问题。
(3)运行效率较低。深度学习的方法往往具有大量的网络参数,尤其是无监督学习方法,通常包含位姿估计和深度估计两个子网络,因此需要大量的时间进行训练。在测试时相对比于基于模型的方法也稍慢。但实时性是视觉里程计任务的一个重要需求,因此如何提升基于深度学习方法的训练和测试效率是一个亟待解决的问题。
(4)模型在移动设备上的部署相对困难。基于深度学习的方法通常需要借助GPU等高性能计算设备进行训练和测试。视觉里程计模型在实际的应用中通常需要部署在移动设备上,但在移动设备中,计算资源有限,无法提供GPU等设备进行加速计算。因此当前基于深度学习方法的移动端部署是需要解决的问题。
(5)深度学习方法可解释性差。基于模型的算法每个步骤都有严格的数学理论指导,尽管这种基于静态场景的假设使得基于模型的算法在面对光照改变、动态物体等挑战性场景的鲁棒性较低,但算法执行的过程却是“透明的”和可控的。深度学习却是一个“黑盒”模型,通常只能依赖训练好的模型来得到结果,而无法从理论上进行预测,因此当网络预测得到的结果不符合预期时,无法进行根本性的调整。
(6)缺乏统一、合理、广泛的评价指标。当前通常使用RMSE、ATE、RTE等指标来评估算法的准确率,然而当算法被部署在实际中运行时,它通常难以达到论文中所提到的准确性。这是因为算法的实际表现受到多种因素的影响,例如面对实际场景的鲁棒性、泛化性等,但当前却无法定量评估这些因素。因此需要一个合理的评价指标,不仅可以评估算法准确,还能反应其面对真实场景的表现,从而更加全面、合理地对各个算法进行比较分析。
(7)泛化性和鲁棒性仍然有待提高。与基于模型的算法相比,基于学习的算法在实际运行时不过度依赖先前所估计的位姿,因此通常不会出现初始化或者追踪失败的情况,然而当输入网络的场景图像与网络在训练时的图像差异过大时,算法会产生精度下降的问题。因此怎样提升学习算法在面对新场景时的泛化性和鲁棒性,仍然是一个大的问题。
4.2 未来发展方向
(1)使用无监督方法来训练网络。无监督的方法通常只需要增加数据集的规模,即可获得一定的性能提升,而基于监督学习的方法则需要大规模的人工标注数据集,其通常是高成本和难获得的。此外,无监督方法使用几何变换、光度一致性等约束作为损失函数来指导网络的训练,更符合真实的运动模型,可解释性更好。
(2)利用语义信息获得语义推理能力。理解语义信息是获得高层次理解和语义推理的重要步骤,而当前的方法仅理解低级的几何特征而没有真正利用到语义信息。一方面,利用语义信息可以形成语义层次的定位约束,从而提高准确性和鲁棒性。另一方面,将语义信息集成到VO中可以让设备推断出周围的情况,例如可以根据检测到的车辆方向和位置来推断自身的运动方向。因此理解高级语义信息、并将其与VO任务进行融合是未来重要的发展方向。
(3)使用深度学习实现多传感器融合定位。由于图像数据存在光照改变、相机曝光改变等问题,因此许多基于模型的算法使用概率或非线性优化方法将相机、IMU等多类传感器的数据融合来进行位姿估计,极大的提升了预测精度。然而使用深度学习实现数据融合[91-92]的方法却相对较少,与传统融合方法相比,基于学习的方法不需要进行复杂的人工标定等步骤,因此基于学习的融合方法在未来具有很大的发展潜力。
(4)将基于模型的方法和基于深度学习的方法进行融合。基于模型的方法建立在严格的数学建模之上,其在静态、充足的光照和富足的纹理等场景下更加可靠和准确,然而在具有挑战性的场景中运行时,该类方法会面临跟踪丢失、初始化失败等许多问题。虽然基于深度学习的方法可以在挑战性的场景中良好运行,但其在正常场景中却缺少可靠性与准确性。因此,合理、高效、巧妙地结合这两种方法在提升VO系统的准确性和鲁棒性方面具有巨大的潜力。
(5)减小网络的参数和计算量。当前,基于深度学习模型的参数过多,计算量过大,难以在实际的移动设备上进行部署运行。因此,可以考虑从网络的设计上出发,使用网络蒸馏等方法减小网络的参数量,提升网络的计算速度,以便于更好地在移动端部署。
(6)提升深度学习方法的泛化性。基于深度学习的方法从数据中进行学习,因此其在面对与训练集场景差异较大的场景时,精度会有所下降,导致方法的应用受限。因此可以考虑使用域泛化、域自适应等方法使网络在面对新场景时,依然保持高准确率。
(7)构建大型的多场景数据集。基于深度学习方法的精度和鲁棒性很大程度上取决于数据集的规模和质量。因此收集更大、包含场景更多的数据集可以有效地提升基于深度学习方法的准确性和鲁邦性。
(8)使用更加先进和新颖的深度学习方法。随着近年深度学习技术的蓬勃发展,其在各个领域的使用也越来越广泛,然而在VO任务中,大多只使用一些简单和通用的深度学习框架和方法,如CNN、RNN、GAN等。因此将更多的深度学习技术引入到VO任务中,例如图卷积神经网络GNN等来实现更准确、速度更快的位姿图优化,使用attention机制来处理动态物体等。
5 结束语
近年来,基于深度学习的视觉里程计取得了蓬勃的进展,其在移动机器人、AR/VR、自动驾驶中得到了广泛应用。本文分析总结了基于深度学习的视觉里程计的发展路线,通过回顾这些重要的工作,可以看到一些重要的问题得到了解决,但目前仍然存在许多挑战性的问题待学者们研究攻克。相信在从弱人工智能时代向强人工智能时代转变发展的历史进程中,基于深度学习的视觉里程计将在人与环境、机器与环境的交互中发挥越来越重要的作用。
