基于GRU-Glove算法的文本分类方法
2022-10-16阿音嘎顾悦公安部第一研究所
阿音嘎 顾悦 公安部第一研究所
引言
近年来,我国互联网技术与行业飞速发展,在方便人民群众生产生活的同时,也出现了各种新的网络犯罪形态和生态。2017年至2021年,网络犯罪案件数量呈逐年上升趋势,2018年单年网络犯罪案件数量增幅甚至达到了50.91%。在网络犯罪案件中,金融诈骗类、电子色情服务类、网上非法交易类案件数量占比较大,这些网络犯罪案件普遍存在文本交互信息量大、社交媒体类媒介依赖度高、犯罪信息集中度高等特点,因此在办理此类案件过程中,自然语言处理技术得到了广泛应用。文本分类方法是自然语言处理技术的主要应用方法之一,各类文本分类方法已经广泛应用于公安信息化行业,有效提高了公安队伍对网络犯罪的执法效率[1]。
中文分词方法是文本分类方法的重要组成部分。常规的中文分词方法主要包括基于词典的分类方法[2,3]、基于统计的分词方法[4]和基于构词的分词方法[5]。上述方法在中文分词上应用较为广泛,但是上述方法主要根据词典规则、统计特征和局部语义特征进行分词处理,并未考虑长序列文本中词与词之间的语义关系特征,导致这些方法在复杂文本的分词效果上表现一般。中文分词任务本质上是一个序列化建模任务,近年来,随着机器学习的发展,利用机器学习算法处理序列化建模任务引起了广泛研究,在机器学习算法中,循环递归神经网络(Recurrent Neural Network,RNN)是处理序列化建模任务的一种有效算法[6]。例如,Fan等人提出了基于多级上下文的RNN算法,利用RNN的序列处理特性,有效解决了图像全局序列的识别问题[7];Nallapati等人将基于注意力机制的RNN应用于序列化文本内容翻译过程中,有效提升了文本翻译质量[8]。然而,由于RNN算法使用链式求导法则求取导数,在处理较长序列时会出现梯度爆炸问题,导致长距离特征在RNN网络中的作用较小,影响了长序列任务处理效果[9]。对此,Hochreiter提出了LSTM算法,利用遗忘门、输入门和输出门作为调节单元来调整长序列对RNN的影响程度,从而有效解决了RNN的梯度爆炸问题,并在文本分词领域和文本分类都有着一定的应用[10]。例如,Alharbi等人在LSTM基础上,提出了组长短期记忆网络算法,并将算法应用于亚马逊手机评论情感状态识别,取得了较好的效果[11];任智慧等人将LSTM算法应用于中文分词过程中,取得了较好的分词效果[12]。在2014年,Chung等人在LSTM基础上提出了GRU网络,在性能与LSTM持平的基础上,有效简化了计算负担,在分词和分类任务上得到了肯定[13,14]。LSTM算法和GRU算法在分词和分类任务上都取得了不错的效果。然而LSTM和GRU在中文分词过程中仍然需要依赖既有训练语料,随着网络的发展,大量网络新词的出现,训练语料更新不及时,导致上述算法在处理含有新型词汇复杂文本时仍然存在分词失败的可能性,进而影响分类任务效率。
为解决新词较多、训练语料更新不及时导致的文本分类任务执行效率较低问题,文中设计了一种基于GRUGlove分词算法的文本分类方法。首先,在分词阶段,该方法利用GRU算法对文本进行初始分词,并利用Glove模型对分词结果进行补充修正,从而获得分词结果;其次,在分类阶段,使用GRU算法作为分类器算法对文本进行分类;最后,将该分类算法应用于中文分词任务和文本分类任务,来验证算法的有效性。结果表明,该算法能够有效识别到含有新型词汇的疑似网络犯罪文本信息,并能够为公安部门打击网络犯罪工作提供有效帮助。
一、需求分析
在利用自然语言处理技术办理一些网络犯罪案件的过程中,文本分类方法起到了关键作用。文本分类方法会将案情资料中包含的大量文本信息,按照公安部门制定的需求进行筛选和分类处理,能够一定程度上缩短公安民警梳理案情资料的时间,提高案件办理效率。
常规的文本分类方法包含文本预处理、特征提取、文本表示和类别划分四个任务。文本预处理任务是文本分类方法中的关键任务之一,该任务主要目的是去除文本中不必要的停用词,并将文本信息进行中文分词和词性标注,为后续任务提供精确语料。中文分词是文本预处理任务的关键阶段之一,目的是将给定文本信息的中文字符串,按照指定算法,分割为一个个具有语言意义的单位。中文分词的数学描述如下:在给定一组文本序列S={w1,w2,…,wm} 中,寻找一个标注序列T={t1,t2, …,tn}使得概率p(t1,t2,…,tn w1,w2,…,wm)最大,T中值取自{B,E,M,S},B表示词首(Begin),E表示词尾(End),M表示词中(Middle),S表示单字成词(Single)。一个基本的分词示例如图1所示。
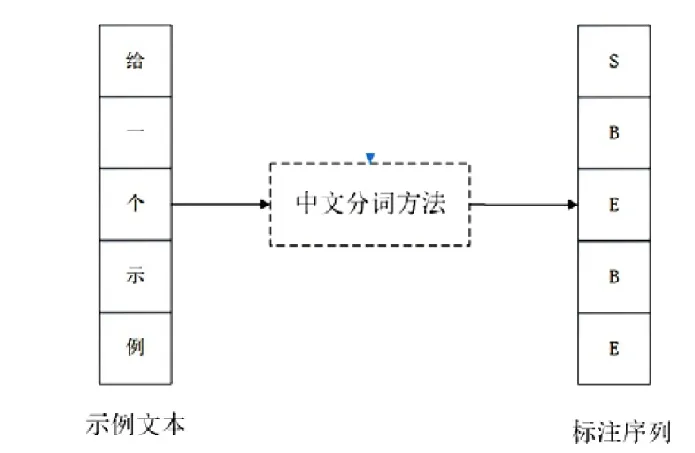
图1 中文分词过程示例
随着案情信息形式多样化、安全信息文本复杂化和疑似犯罪词汇新颖化,传统的中文分词方法和基于机器学习算法的中文分词方法在处理此类案情信息时存在着未考虑词之间的语义特征和分词过程依赖于既有词库的问题。因此,需要设计一个新的文本方法,解决上述方法存在的两个问题,提高公安部门打击网络犯罪案件的效率。
二、整体架构
基于GRU-Glove算法的文本信息分类方法主要包括文本预处理和文本信息分类两个阶段。在文本预处理阶段,首先将给定文本划分为训练数据和测试数据,并进行分词标记和分类标记;其次,利用word2vec编码算法获取输入和输出序列,利用GRU对序列进行分词训练;最后,利用Glove算法对GRU分词结果进行修正,获得分词模型。在文本信息分类过程中,将完成分词的向量序列利用GRU算法来进行分类训练,获得文本分类模型。方法框架如图2所示。

图2 基于GRU- -Glove算法的文本信息分类方法示意图
三、关键技术:门控循环单元神经网络(Gated Recurrent Unit,GRU)
GRU是循环神经网络(Recurrent Neural Network,RNN)的一个变体算法。在RNN模型中,神经元在某时刻的输出在下一时刻可以直接作用到自身。一个基本的RNN模型如图3所示。

图3 RNN模型
由图3可以看出,RNN主要包括三个部分:输入层、隐含层和输出层。其中,Xt-1是(t-1)时刻输入,Qt-1是(t-1)时刻输出,U、V分别为输入层到隐含层、隐含层到输出层的权重值,W是相邻时刻信息传递的权重值,St-1是(t-1)时刻隐含层产生的结果传递给下一时刻隐含层值的值。
GRU网络在RNN的基础上,引入重置门和更新门两个概念,将隐含层神经元替换为门控循环单元,有效解决了RNN在处理长序列信息时的梯度消失问题。GRU网络的门控循环单元如图4所示。

图4 GRU网络结构图
其中xt和yt为t时刻隐含层的输入和输出,ht-1为(t-1)时刻的隐含层输出,rt为重置门,用于决定如何将新的输入信息和前面的记忆信息相结合;zt为更新门,用于决定前一时刻的信息被带入到当前时间步中的量,更新门的值越大,代表前一时刻状态信息带入越多;ht为候选隐含层状态,用于保存t时刻的记忆量,用于下一时刻计算。
四、功能实现
(一)基于GRU-Glove算法的预处理过程
给定一组文本信息T,将其划分为训练数据T1和测试数据T2,并做好分词标记和分类标记。利用word2vec编码方法将T1的原始数据和标记数据分别进行向量化表达,获得输入序列X={x1,x2,…,xn}和输出序列Y={y1,y2,…,yn}。将X和Y作为GRU的输入序列和输出序列来训练GRU,训练过程如图5所示。

图5 GRU训练过程
输入序列X进入GRU网络后,计算重置门rt和更新门zt的值:
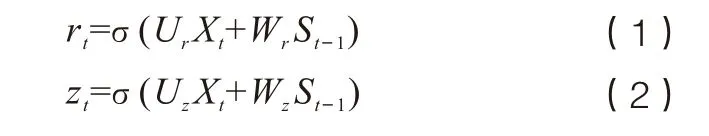
其中Xt为t时刻输入的文本向量,Ur、Uz为输入到更新门和重置门的权重值,Wr、Wz为上一时刻记忆到更新门和重置门的权重值,σ代表sigmoid函数,St-1为(t-1)时刻的隐含层输出。同时,计算候选隐含层状态值ht:
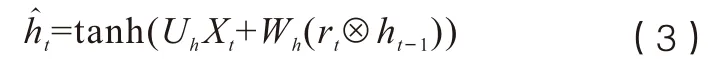
Wh为 输入到激活函数tanh的权重值,Uh为整合上一时刻信息到tanh的权重值。t时刻的隐含层输出St为:
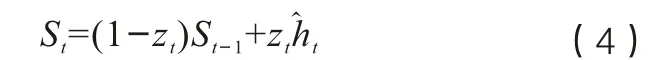
从而输出层输出Yt为:

其中V为隐含层输入到最终输出值的权重值。
前向计算完成之后,利用BP算法对参数Wr、Wz、Ur、Uz、Wh、Uh、V进行修正。重复上述迭代过程至训练结束,获得训练好的GRU分词模型。
利用GRU进行初步分词之后,采用Glove模型来修正分词结果。文中对原始Glove模型进行了修改:针对文本中的词向量Xi和Xj,构建共现矩阵Z={Z1,2,Z1,3,…,Zi,j},其中Zi,j为文本Xi和Xj在同一单词序列窗口中出现的次数,文本Xi和Xj的共现函数F(Xi, Xj)为:
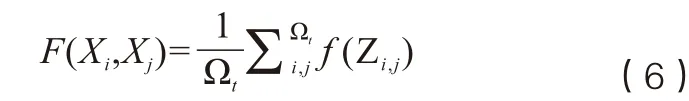
其中Ωt为t时刻的文本词集,f(Zi,j)为权重函数,定义为:

其中Zmax为最大词频阈值,目的是防止过高出现词频对于一般出现词频的影响,文中取当前分词结果的单词数量作为Zmax的值。最终,给出新词的组合判定依据:
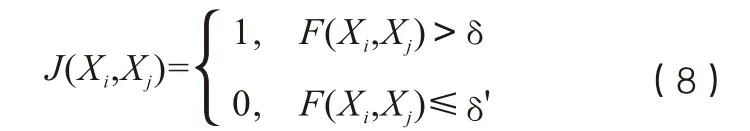
其中J(Xi,Xj)为新词判定状态,1代表XiXj为新词,0代表XiX j不成词,δ为判定阈值。重复上述过程直至所有J(Xi,Xj)值为0,获得最终的分词结果。
(二)文本信息分类过程
通过上述过程获得预处理分词结果后,利用word2vec对分词结果中的词汇进行向量化表达,并利用GRU网络对分类标记数据进行训练。前向计算过程如下:
重置门状态:
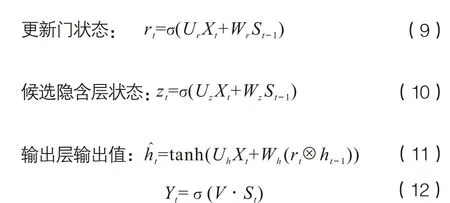
前向计算完成之后,利用BP算法对参数Wr、Wz、Ur、Uz、Wh、Uh、V进行修正。重复上述迭代过程至训练结束,获得训练好的GRU分类模型。
五、实验及结果分析
为充分验证GRU-Glove算法的有效性,文中分别进行了分词有效性验证实验和分类有效性验证实验。
(一)中文分词实验
1. 评价指标
为评价算法的有效性,采用正确率(P)、召回率(R)作为度量算法有效性的评估指标。文本分词各指标的具体定义分别为:

2. 实验参数
实验数据方面,中文分词实验采用NLPCC2015中的中文分词任务数据集[16]作为基准数据,将基准数据按训练数据(80%)和测试数据(20%)进行划分;训练数据仍以基准数据为准,测试数据中添加微博2022年热搜数据部分词汇。
对照算法方面,以LSTM、GRU、传统分词工具jieba作为对照算法,参数如表1所示。其中Glove模型的阈值δ选择为0.85,选择依据为Xu等人在[15]中对于Glove模型参数选择的论证:阈值δ选择越大,分词判定结果严格,新词不易被判定;阈值δ选择越小,分词判定结果宽松,分词质量降低。

表1 分词实验参数
3. 实验结果分析
表2给出了分词实验的实验结果。由表2数据可以看出,一方面,相比于jieba,LSTM、GRU和GRU-Glove能够取得不错的分数,这是由于他们能够对长文本进行语义分析,从而正确识别出词汇。另一方面,相比于LSTM、jieba和传统的GRU算法而言,GRU-Glove算法在处理含有新型词汇的中文分词中能够得到一个较高的分数(正确率87.63%,召回率85.25%)。

表2 分词实验指标结果
表3给出了几个算法的分词结果样例,本样例将网络犯罪中日渐增多的比特币交易信息放在了测试样本中。在本例中,“比特币钱包”和“比特币”都是在测试数据中新添加的数据,可以看到,GRU-Glove能够识别出“比特币”这一关键词信息,而LSTM、GRU都未识别到。这是由于GRU-Glove算法的Glove模型通过遍历文本,发现“比特”和“币”同时出现频率较高,因此判定该词为一个新词,并进行了分词处理。

表3 分词实验示例
(二)文本分类实验
1. 评价指标
为评价基于GRU-Glove算法的分词方法,对文本分类任务影响程度采用正确率(P)来评估分类任务的执行结果。文本分类任务的正确率定义为:

2. 实验参数
文本分类实验采用复旦大学中文文本分类语料作为基准数据,将基准数据按训练数据(80%)和测试数据(20%)进行划分,分类类别包括政治、军事、社交、法律、经济、交通共6个类别;训练数据仍以基准数据为准,测试数据中基于微博2022年热搜数据构成分类文本对测试数据进行补充。
对照算法方面,以GRU算法作为基本分类算法,以jieba、原始GRU分词和GRU-Glove分词分别作为分词阶段的方法,进行实验。分词过程的实验参数与上一实验一致,GRU分类器的实验参数如表4所示。

表4 分类实验参数
3. 实验结果分析
表5给出了分类实验的实验结果。由表5数据可以看出,相比于采用jieba和原始GRU作为分词器的GRU模型,采用了GRU-Glove作为分词器的GRU模型能够在文本分类上获得更高的正确率。图6给出了GRU-Glove-GRU模型和LSTM-GRU模型的训练过程,可以看到,相比于LSTMGRU,GRU-Glove-GRU的收敛速度更快。导致收敛速度快的原因是GRU-Glove-GRU采用GRU-Glove算法进行分词,相比于LSTM分词手段,GRU-Glove可以从待分类文本中获得更加精确的特征词,从而加快算法的训练速度。

表5 分类实验指标结果
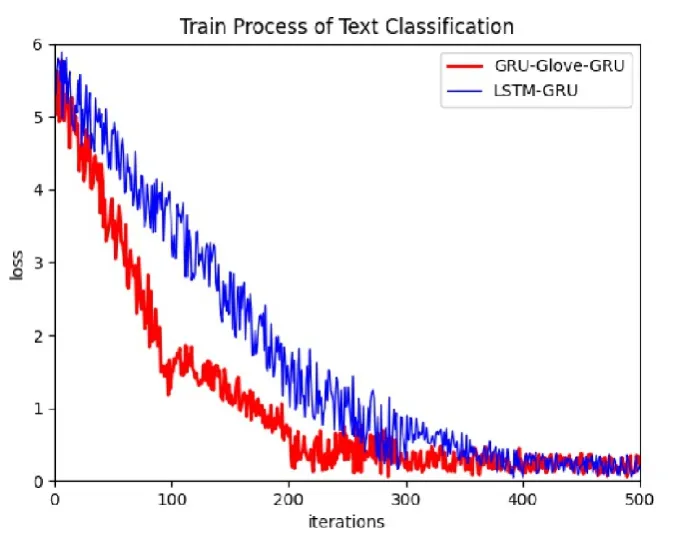
图6 文本分类实验训练过程
六、结语
在公安部门利用自然语言处理技术打击网络犯罪过程中,针对互联网新型词汇与日俱增现状、现有文本分类方法在相关案情信息分类任务上存在的低效问题,文中提出了一种基于GRU-Glove算法的文本分类方法。对比已有方法,文中提出方法的主要优势包括以下几个方面:(1)采用GRU网络对含有新词文本进行分词处理,避免了传统分词方法对词典的依赖性,提高了分词质量;(2)在GRU网络基础上,引入Glove算法,针对训练数据中不存在的新词进行了有效识别,进一步提高了分词结果的准确性。结果表明,采用GRU-Glove算法作为分词手段的文本分类方法,能够对含有新兴词汇疑似犯罪文本进行正确分词,并快速归类疑似犯罪文本,提高公安部门打击网络犯罪效率。
虽然该算法在一定程度上提高了文本分类的效率,但是也存在着计算复杂度高、稳定性亟待验证的问题。在未来研究中,会进一步优化算法的计算过程,论证算法的稳定性,并增加其在打击网络犯罪过程中的实践应用。
