一种基于新型Unet-Canny网络的安全带检测方法
2022-10-14彭方达宋长明
彭方达, 宋长明, 李 阳, 王 浩
(中原工学院 理学院, 河南 郑州 450007)
随着社会的快速发展,机动车数量日益增加,与其相关的交通事故也越来越多[1]。机动车驾驶员和乘客在机动车行驶中若不系戴或者错误系戴安全带,就很容易在事故发生时受到伤害。每年都会有很多人因为驾驶或乘坐机动车未系戴安全带而受到伤害。当交通事故发生时,若机动车驾驶员正确系戴了安全带就能够从很大程度上保证驾驶员的生命安全。因此,及时判断机动车驾驶员是否正确系戴安全带,具有重要意义。
在早期的安全带检测方法中,Guo等提出的通过直线检测和基于车辆特征几何关系检测安全带的方法,对图像质量要求较高,不适合在复杂的外部环境中使用[2];唐恬等设计了结合直线检测和HOG(Histogram of Oriented Gradient)算子的多级安全带检测算法,但它对下雨天大型车辆的安全带检测很受局限[3];陈雁翔等提出的基于Adaboost的安全带检测系统,能够根据Haar-like特征、窗口、驾驶员和安全带的信息分别进行训练,将3个弱分类器连接成不同权重的强分类器,用高斯混合模型处理后进行安全带检测,但该系统对图像质量的要求很高而很难应用[4]。随着深度学习算法的兴起,卷积神经网络因在提取图像特征时能降低假阳率和漏报率,适应复杂的环境,在实践中应用越来越多,出现了许多优秀的检测网络,如SSD(Single Shot Multibox Detector)系列[5]、Fast R-CNN(Fast Region-based Convolutional Neural Network)系列[6]、YOLO(You Only Look Once)系列[7]。但是,在安全带检测中,用标注软件标注图像时,安全带区域只占标注框的很小部分,而其他物体例如人的肩膀却具有很大的面积占比,所以卷积神经网络学习时更多学习的是肩膀的特征而不是安全带,以这种习得权重进行安全带检测,效果往往很不理想。因此,单一的目标检测网络很难准确地完成安全带的检测任务。而计算机视觉的语义分割对图像的处理更为细致[8],它对图像的识别是像素级的,即能针对图像的每个像素点进行分类处理。本文试图通过语义分割来达到判断机动车驾驶员是否正确系戴安全带的目的。
为了提高对安全带的正确检测率,本文提出一种新的安全带检测方法,采用语义分割来实现安全带的检测。该方法结合SSD网络、语义分割网络Unet[9]和边缘检测算子Canny[10]的优点,首先利用SSD网络对机动车驾驶员进行定位,然后通过Unet-Canny网络分割安全带,达到检测效果。
1 选用网络和模块
1.1 SSD网络
图1所示为交通部门摄像头抓拍的图像。抓拍的图像中除安全带以外,道路的分割线、树木、防护栏以及车体边缘都具有和安全带类似的线条信息。这些信息给神经网络训练带来干扰的同时,会增加训练的难度,对训练权重产生负面影响。为了提升神经网络的训练效果,本文利用目标检测网络对抓拍图像进行预处理,剔除图像中的无关信息而提取车窗部分有用信息,以改善检测效果。

图1 交通部门摄像头抓拍的图像Fig. 1 Picture snapped by the camera of transportation
受交通部门装设硬件的限制,普通摄像头抓拍图像的分辨率较低,远距离拍摄的车辆图像会模糊不清,车辆中驾驶员的图像信息更是丢失严重。因此,应主要针对图像中近距离车辆的安全带系戴情况进行检测。研究发现,车窗在数据集中目标较大且具有很明显的特征,通过目标检测能较好地完成车窗检测任务。
SSD属于One-stage网络[11],其主干采用VGG(Visual Geometry Group)网络[12],能同时对物体信息进行检测和分类。它能够利用CNN(Convolutional Neural Network)提取图像特征,均匀划分图像区域并进行密集抽样,抽样时可使用不同长宽的预选框,使物体分类与预选框的回归同步进行。因此,可采用SSD网络实现对车窗的目标检测。SSD网络的结构如图2所示。
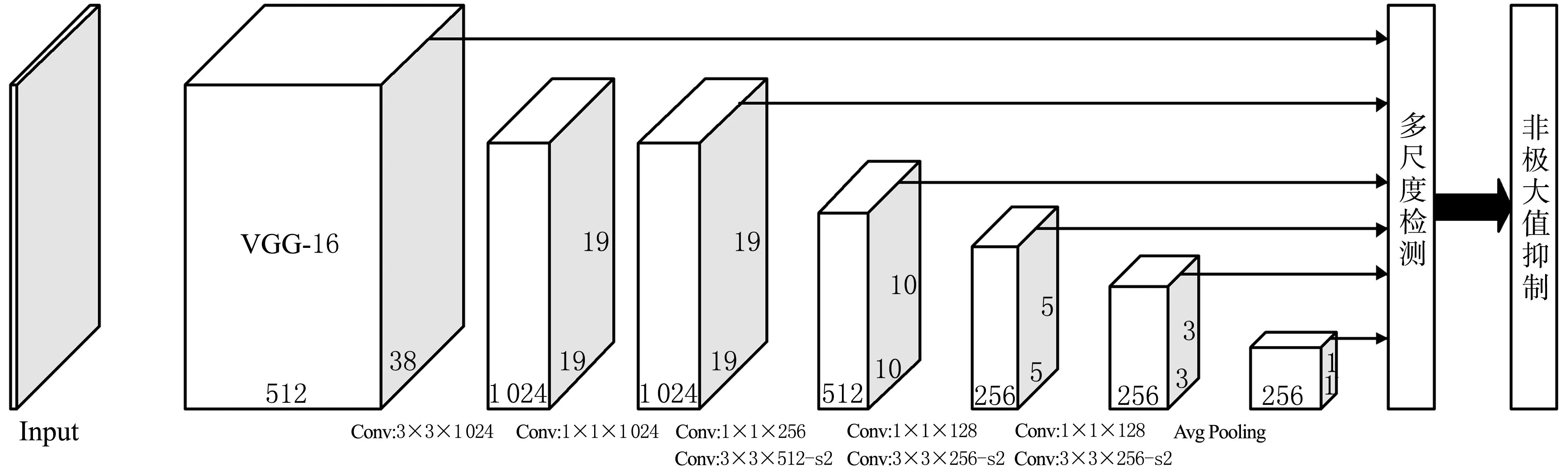
图2 SSD网络的结构Fig. 2 SSD network structure
1.2 Unet网络
语义分割网络能够在像素级别下对图像中的每个像素点进行分类。Unet是语义分割网络中一种典型的全卷积神经网络。Unet网络的结构如图3所示。
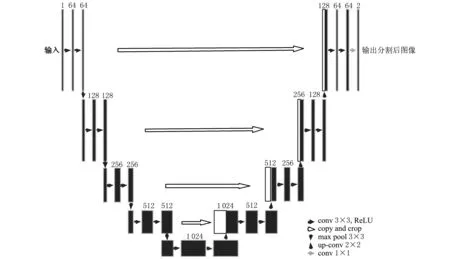
图3 Unet网络的结构Fig. 3 Unet network structure
Unet网络为U形结构,由左侧的卷积层(编码器)和右侧的上采样层(解码器)组成。其编码器采用对输入图像卷积再池化的方式进行特征提取;解码器能先对深层的图像进行上采样,然后与编码器传递来的特征层进行通道融合。这些特征层中,浅层用来分割,深层用来定位,两者结合才能很好地完成语义分割任务[13]。采用Unet网络进行图像像素点分类的过程包括3个步骤。
第一步,主干特征提取。首先,通过主干网络获得不同的特征层,其主干特征层与VGG网络类似,为卷积和池化操作的堆叠;然后,利用主干网络获取5个初步有效的特征层。
第二步,加强特征提取。对利用主干网络获取的5个初步有效特征层进行上采样,并在特征融合后确定1个能最终融合所有特征的有效特征层。
第三步,预测。利用所确定的能最终融合所有特征的有效特征层,对每一个像素点进行分类。
1.3 Res-Canny模块
受光照、遮挡、驾驶员着装的影响,安全带的数据集训练十分困难。增强安全带的边缘信息,可以提升对安全带的识别效果。对安全带进行图像分割时,一般网络的性能很大程度上取决于特征提取的效果,而网络结构决定着其提取特征的能力[14]。因此,应加强网络对边缘特征信息的提取能力。本文将Canny算子添加到网络中,以增强所选用网络的图像分割性能。采用Canny算子时,输入图像为单通道的二值图像。通过高斯滤波器生成滤波核,可降低图像噪声,使滤波曲线变得平滑。高斯滤波核(即高斯滤波后的像素点)为:
(1)
式中:x、y分别为像素点的横坐标和纵坐标;σ为控制图像平滑程度的参数。
图像本质是由像素点组成的矩阵,图像中各像素点梯度(包括为x方向和y方向)的变化对应实际图像中色差和纹理的变化。因此,可通过计算像素点的梯度来了解图像的变化。像素点H(x,y)的梯度值为:
(2)
计算梯度后会得到大量的边缘信息。对这些边缘信息进行筛选,才能得到真实的边缘特征信息。因此,在采用Canny算子时,应首先通过极大值抑制,去除多余的边缘;然后采用双阈值确定真实边缘以及潜在的边缘;最后抑制弱边缘,完成边缘检测[15]。
研究发现,若直接将Canny算子加入Unet网络,就会在提取边缘信息的同时丢失大量的原图像信息,对特征信息提取和网络训练都极为不利。若将图4所示的残差块结构[16]引入网络,就可从很大程度上缓解网络加深带来的退化现象,在保留完整输入信息的同时能够进行特征信息的提取。
本文将残差块结构与Canny算子相结合,构建了Res-Canny模块(其结构如图5所示),对输入特征层的3条通道(第一条,保持输入特征层不变;第二条,对输入特征层进行两次卷积;第三条,将特征层输入Canny算子中,提取边缘特征信息)进行计算,并对3条 通道的计算结果进行了特征融合。
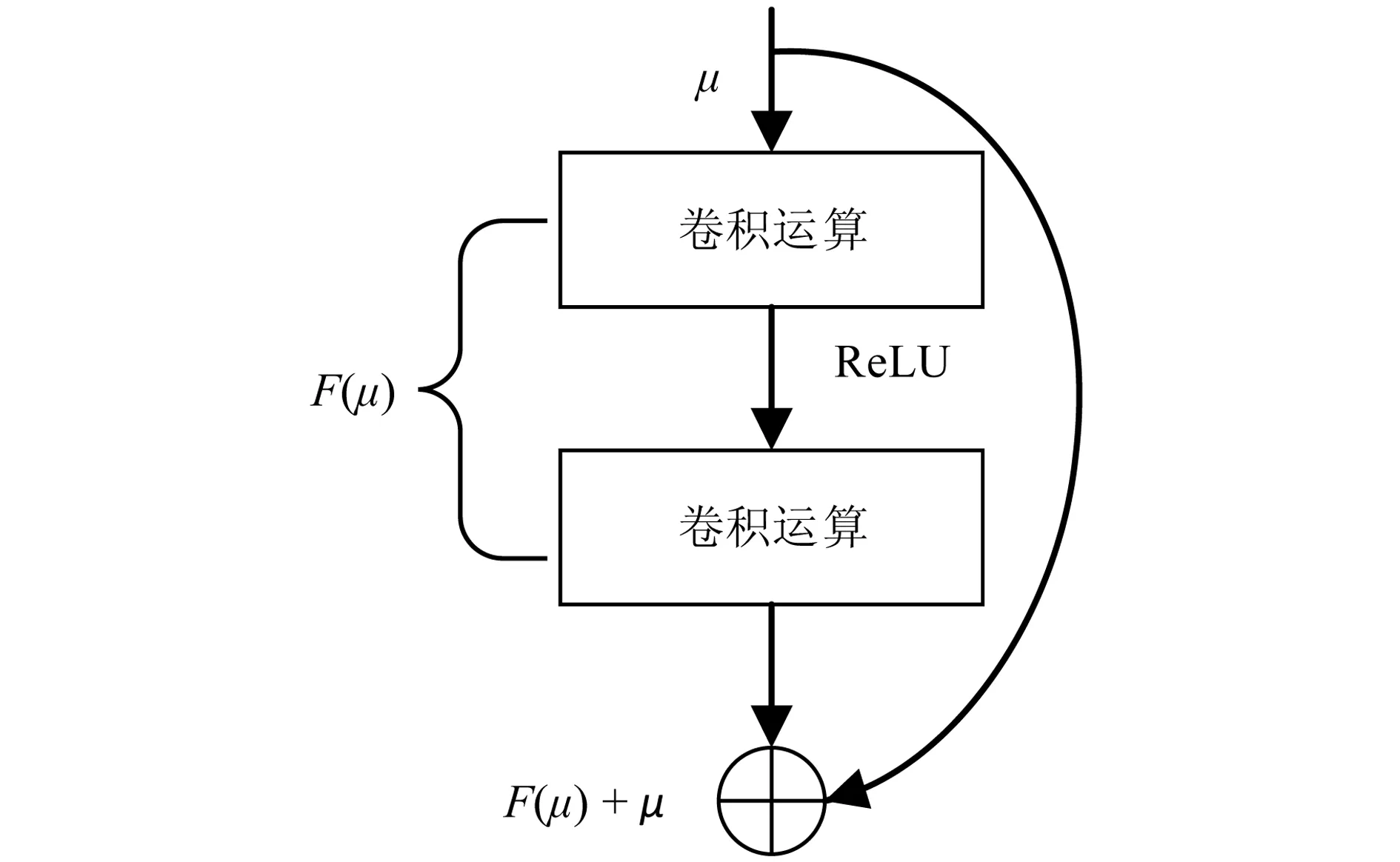
图4 残差块的结构Fig. 4 Residual block structure
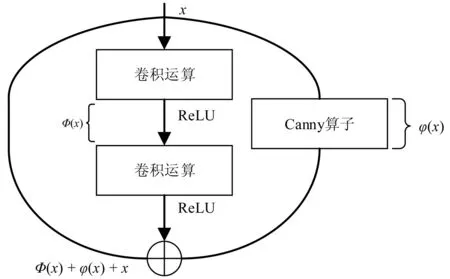
图5 Res-Canny模块的结构Fig. 5 Res-Canny block structure
2 搭建Unet-Canny网络模型
在图6所示的Unet-Canny网络识别流程中,先用SSD网络定位驾驶员图像(作为预处理),再将图像送入Unet-Canny网络,分割安全带图像。根据能否分割出安全带图像,可判断驾驶员是否正确系戴了安全带。

图6 Unet-Canny网络识别流程Fig. 6 Unet-Canny network recognition process
本文将Res-Canny模块加入Unet网络,以增强网络对边缘信息的学习和提取能力,改善对安全带图像的分割效果;根据图6搭建了图7所示的Unet-Canny网络模型。Unet-Canny网络模型整体上由左半部分的编码结构和右半部分的解码结构组成。
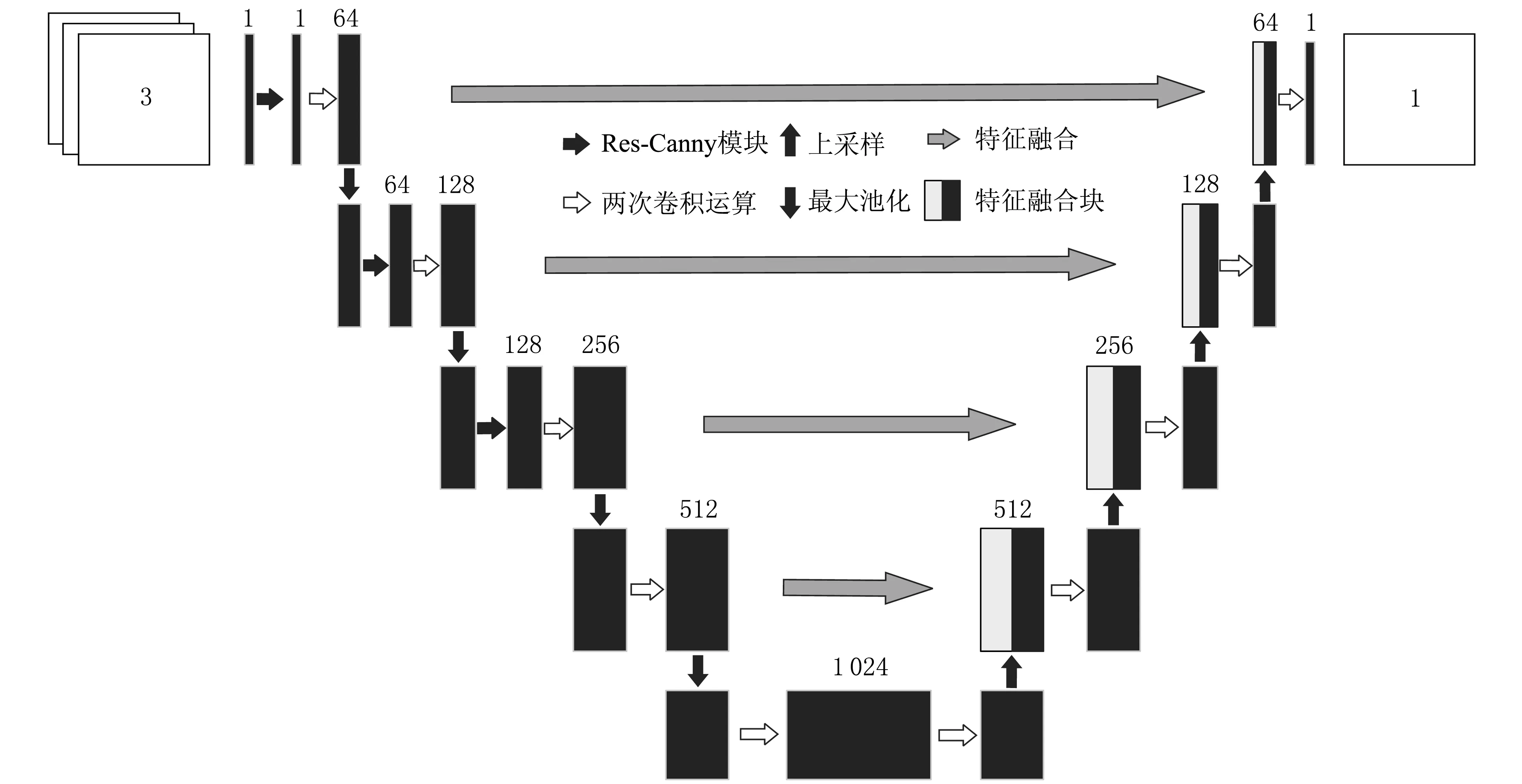
图7 Unet-Canny网络模型Fig. 7 Unet-Canny network model
通过cv2库可将RGB(R代表Red,G代表Green,B代表Blue)三通道图像变成单通道灰度图像。针对单通道灰度图像,用Res-Canny模块连续进行3次下采样(每次下采样都会将特征通道数量翻倍),并进行两次3×3的卷积运算;第四次下采样后,再进行两次3×3的卷积运算。经过下采样、上采样和卷积运算,新的图像与原图像大小一致时即可停止对Unet-Canny网络的操作。
安全带的语义分割实际上属于图像中每个像素点的二分类问题。基于二分类交叉熵损失函数,可列出安全带语义分割损失值L的计算公式,即
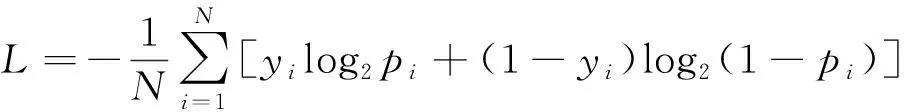
(3)
式中:N为图像中像素点的个数;yi是第i个像素点的所属类别;pi是第i个像素点的预测值。若yi=1,则(1-yi)log2(1-pi)=0,yilog2pi的值随log2pi的变化而改变,pi越接近1则损失值L越小;相反,若yi=0,则yilog2pi=0,(1-yi)log2(1-pi)的值随log2(1-pi)的变化而改变,pi越接近0则损失值L越小。
分析可知,在Unet网络编码层的浅层部分添加Res-Canny模块,构建Unet-Canny网络,能实现对浅层部分含有轮廓、边缘、颜色等低级语义信息的特征图像进行边缘信息的提取。随着层数的递增,深层特征网络的有效感受野变大,使得Unet-Canny网络能从特征图像中获取更为抽象的特征信息;但同时,从浅层信息传入的边缘信息就会逐步丢失,这时候再添加Res-Canny模块就不再有效果,反而会给特征信息的提取带来干扰。因此,在最后两次下采样的编码层不宜再添加Res-Canny模块。
3 实验验证
3.1 创设实验条件
(1) 确定数据集。本文根据交通部门拍摄的公路行驶机动车图像数据库确定了实验用数据集,并采用labelme软件进行标注。共标注图像850张,其中700张作为训练样本,150张作为测试样本。这里给出了数据集中的4张图像(见图8)。

(a) 图像一 (b) 图像二
(2) 预处理。训练时将原图像尺寸缩放至512×512(像素),用SSD网络检测车窗位置后对其进行裁剪,将裁剪好的图像再放大至512×512(像素),并输入Unet-Canny网络,进行图像分割。
(3) 设定参数。所用代码是在一台主频为1.7 GHz的Intel Xeon Bronze 3104型处理器,容量为16 GB的NVIDIA Quadro P5000型显存上实现的。在所用pytorch框架中,将Epoch设为1 000次、学习率设为1×10-5,并将所用RMSprop优化器的权重衰减项设为1×10-8,momentum数设为0.9。
3.2 添加Res-Canny模块和Unet-Canny网络
用Canny算子提取图像边缘的效果如图9所示。从图9可看出,用Canny算子处理原图像,能够有效提取原图像中物体的边缘信息。这些边缘信息包含了安全带信息,有助于提高对安全带图像分割的效果。
3.2.1 添加Res-Canny模块
Unet网络的整体可分为5层,从最上边的第一层到最下边的第五层。各特征层的通道数量分别为64、128、256、512、1 024(个)。随着卷积神经网络层次的加深,图像提取的特征层包含的信息会发生变化。通道数量为64个和通道数量为128个的2个特征层包含了边缘、轮廓、颜色等浅层语义信息;通道数量为256个、512个、1 024个的3个特征层包含了抽象的深层语义信息。显然,浅层网络保留了较多的原图像语义信息,能从中观察到驾驶员和安全带;随着卷积神经网络层次的加深,深层网络提取的语义信息更为抽象且不包含边缘信息。因此,本文在设计网络结构时并没有在所有的特征层添加Res-Canny模块,只在输入过程和通道数量为64个、128个的两个特征层添加该模块,以便有效增强边缘信息并避免对硬件计算性能的浪费。
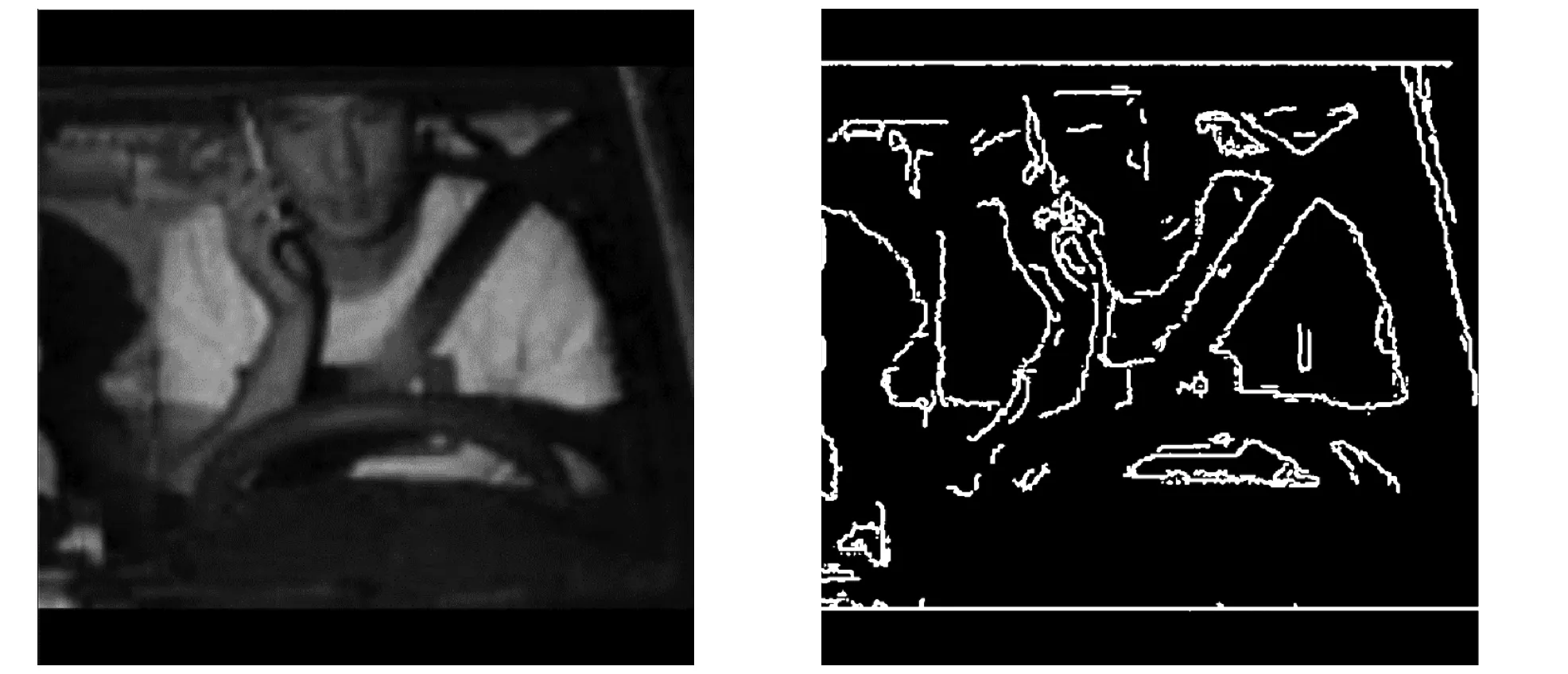
(a) 原图像 (b) 从原图像提取的图像边缘图9 用Canny算子提取图像边缘的效果Fig. 9 Effects of Canny operator
3.2.2 添加Unet-Canny网络
用Unet网络处理图像与用Unet-Canny网络处理图像的对比情况如图10所示。其中,中间层代表的是第一次卷积从通道3到通道64的中间层。由图10可看出:Unet网络和Unet-Canny网络的输出图像均显示了安全带的轮廓;Unet-Canny网络的输出图像中有车窗的框架。这里的特征层包含了许多浅层语义信息,有利于从网络输出图像中观察车窗、驾驶员、方向盘、安全带的轮廓。

图10 Unet网络和Unet-Canny网络处理图像的对比Fig. 10 Comparison of image processing with Unet and image processing with Unet-Canny
卷积神经网络能够用于提取图像特征,其输出图像可包含安全带的信息。与Unet网络相比,添加Canny算子的Unet-Canny网络的输出图像具有更完整的语义信息,且添加边缘算子的Unet-Canny网络的中间层输出图像的轮廓更为明显。实验发现:添加Canny算子后,神经网络的学习效果和最终检测结果都有改善;采用Unet-Canny网络,不仅使输出图像中安全带轮廓更明显,而且能增强驾驶员、车窗、方向盘的图像边缘信息;在Unet-Canny网络的最终输出图像中,局部车窗的图像边缘信息也同时被增强,可见添加Canny算子在增强网络学习能力的同时也带来了多余的干扰信息。
3.3 对比不同网络的训练损失值
为了验证本文提出的Unet-Canny网络结构的有效性,这里将其与FCN[17]、PSPNet[18]、SegNet[19]、Unet 4个网络进行了对比。5种网络的训练损失值下降曲线如图11所示。
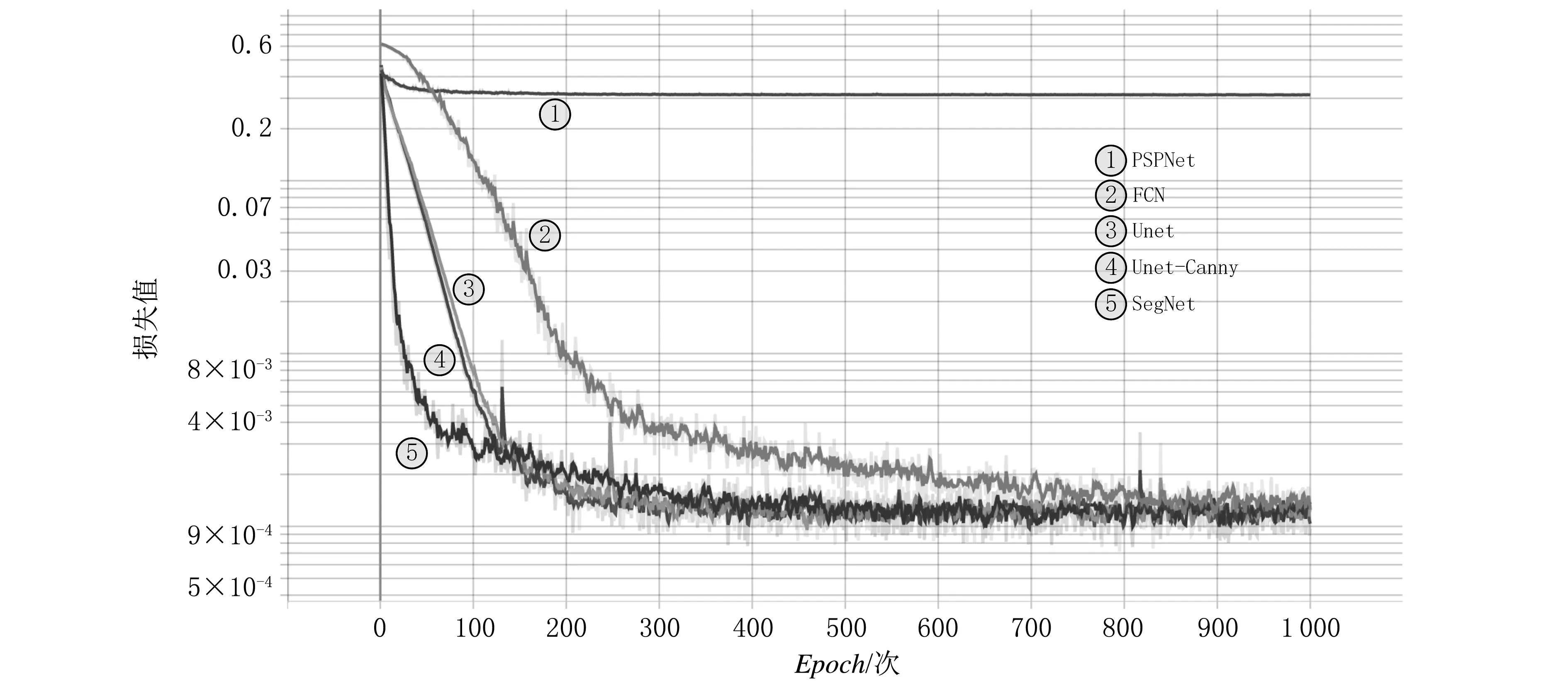
图11 5种网络的训练损失值下降曲线Fig. 11 Comparison of five network training loss value graph
由图11可看出:收敛效果最差的是PSPNet网络,损失值收敛在0.3附近;其他收敛效果从差到好依次为FCN、SegNet、Unet、Unet-Canny网络,损失值都收敛在0.001以下,其中训练损失值下降最快的是SegNet网络,收敛后损失值最小的是Unet-Canny网络。
分析可知,PSPNet网络采用不同的步长和不同的卷积核进行卷积,能得到大小不同的特征层,引入了特征金字塔,在融合不同区域的多尺度特征后得到了分割结果,分割含有不同形状物体的图像时具有良好的效果。本文的图像处理任务是单一地分割安全带,且虽在标注数据集中安全带规则不一但大小变化不大,因此使用PSPNet网络的效果不理想。FCN、SegNet、Unet、Unet-Canny网络采用的都是编码-解码结构,针对损失值训练时都能获得很好的收敛效果。SegNet网络相比FCN网络具有更完善的编码-解码结构,因此训练时损失值下降较快。Unet网络和Unet-Canny网络训练的损失值下降快于FCN网络而慢于SegNet网络,是由于前两种网络增加了卷积层和特征金字塔的结构,导致收敛速度慢于SegNet网络,但它们最终的收敛效果优于SegNet网络。
将Res-Canny模块添加到Unet-Canny网络的每个采样层(包括上采样层和下采样层),并将该网络称作Unet-Canny1。Unet-Canny网络和Unet-Canny1网络训练损失值下降曲线的对比如图12所示。
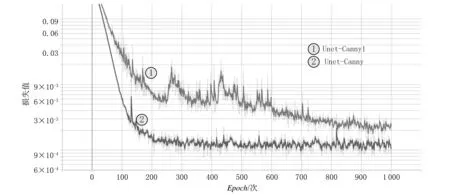
图12 Unet-Canny网络和Unet-Canny1网络训练损失值下降曲线的对比Fig. 12 Comparison of loss value graph of Unet-Canny network and Unet-Canny1 network
由图12可看出,Unet-Canny1网络的训练损失值下降较慢,且其损失值下降曲线的局部有大幅度波动,而Unet-Canny网络的训练损失值下降较快且损失值下降曲线较平滑,最终的收敛值低于Unet-Canny1网络。这一结果表明,过量添加Res-Canny模块并不会提高网络的性能,相反会因过多的冗余信息而导致网络震荡甚至其最后学习效果的不理想。
3.4 对比不同网络对安全带检测的效果
利用目标检测网络对抓拍图像进行处理,检测公路上行驶机动车的驾驶员是否正确系戴安全带的过程中,存在假阳性和假阴性两种类型的误差。当网络检测到驾驶员没有系戴安全带而实际上系戴着安全带,就会出现假阳性误差;当网络检测到驾驶员系戴着安全带而实际上并没有系戴安全带时,就会出现假阴性误差。实际中,假阳性误差比假阴性误差的负面影响更大,对一个遵守交通规则、系戴着安全带的无辜驾驶员按照违章处理是不公平的[20]。为了定量评价安全带检测网络,可用精确率和召回率来表示网络的正确检测率。
精确率为:
(4)
式中:T为真阳性的次数;F为假阳性次数。
召回率为:
(5)
式中,N为假阴性次数。
FCN、PSPNet、SegNet、Unet、Unet-Canny、Unet-Canny1 6种网络对安全带的正确检测率如表1所示。

表1 6种网络对安全带的正确检测率
从表1可看出:用目标检测网络检测安全带时,精确率和召回率最高的是Unet-Canny网络,精确率达90.7%,召回率达91.9%;其次是未添加Res-Canny模块的Unet网络,精确率达87.3%,召回率达87.8%;最低的是PSPNet网络,精确率为63.0%,召回率只有42.6%。
分析可知:PSPNet网络采用多尺度特征融合的特征金字塔结构,对本文小目标不规则的物体检测效果是不理想的;FCN网络采用的是编码-解码结构,在图像分割方面有显著效果,但因为结构简单,训练损失值的下降偏慢、收敛值偏高,检测效果也不理想;Unet网络和SegNet网络具有更完善的编码-解码结构,检测效果较好;Unet-Canny网络的效果比Unet-Canny1网络好,再次证实了Unet-Canny1网络添加过多的Res-Canny模块并不合适,因为这会导致检测效果不升反降,甚至不如原网络Unet;Unet-Canny网络添加了适量的Res-Canny模块,在FCN、PSPNet、SegNet、Unet、Unet-Canny、Unet-Canny1 6种网络中具有最佳的检测效果;使用所提出方法检测安全带的精确率比用Unet网络提高了3.4个百分点。
需要说明的是:因为所选数据集较小,只有700张图像,很可能会导致一些神经网络的学习效果不佳;随着数据集的增大,Unet-Canny网络的学习效果会更好;处理图像时,神经网络会加强图像中所有物体的边缘信息,使网络性能的提升受到限制。
4 结语
本文针对机动车行驶中驾驶员是否正确系戴安全带的图像检测问题,在传统Unet网络的基础上,提出一种融合目标检测和语义分割的新型Unet-Canny网络的安全带检测方法,并通过设计新的Res-Canny模块给Unet-Canny网络添加边缘信息,改善了对安全带图像分割的效果。
关于处理图像的神经网络中添加Res-Canny模块问题的后续研究,可从以下两方面展开:第一,Res-Canny模块对于边缘信息的加强是全图范围的,但通过人眼观察发现,安全带出现的位置不是随机的,会有规律地出现在一定的范围,因此如果能让Res-Canny模块有针对性地进行边缘信息加强,则可大大提高最终的图像分割效果;第二,Res-Canny模块中的Canny算子存在两个确定的边缘阈值,研究中往往是人为设定的,若能将这两个阈值加入神经网络的训练过程,自适应地调整阈值大小,则可更有效地提取图像的边缘信息,提高网络的学习速度,进一步改善检测效果。
