基于深度神经网络的点击率预测模型
2022-10-14刘弘历魏桂英高晓楠
刘弘历,武 森,魏桂英,李 新,高晓楠
北京科技大学经济管理学院,北京 100083
在信息时代,庞大的数据总量一方面加剧了人工筛选信息的难度,导致信息过载[1],另一方面也为大数据技术的发展提供了基础.随着大数据技术逐步在各个领域展开应用并取得了极佳的效果[2],用大数据技术解决信息过载问题成为学术界和工业界关注的问题之一.推荐系统、搜索引擎等基于信息检索的应用能够一定程度上解决信息过载问题,点击率(Click-through-rate,CTR)预测则在这类应用中提供支持与保障[3].CTR 预测[4]根据用户、项目及上下文的特征,预测用户点击该项目的概率,帮助搜索引擎、推荐系统等向用户展示更加个性化、更加精准的内容.
解决CTR 预测问题的模型可以分为传统机器学习模型和深度学习模型[5].传统机器学习模型中逻辑回归[6]思路简单、易实现分布式计算,是该领域基础模型.但它作为线性模型,难以捕获高维非线性特征[7].Rendle 提出因子分解机(Factorization machine,FM)[8]用以解决特征组合问题,FM 监督学习不同特征的隐因子向量,用内积完成特征交叉,但模型复杂度高,一般只用于2 阶特征交叉.
深度神经网络(Deep neural network,DNN)可以很好地提取特征之间的非线性关系,使用大量数据完成模型训练,在图像识别、自然语言处理等领域已经得到广泛应用,将DNN 应用于CTR 预测的研究越来越受到关注.基于DNN 的CTR 预测模型大多基于“嵌入+多层感知机(Embedding+MLP)”范式.如Zhang 等提出FNN(Factorization-machine supported neural network)[9],将FM 的输出拼接后作为全连接层的输入,每个特征的嵌入向量预先采用FM 模型训练得到,DNN 训练开销低,收敛速度快.但该模型难以克服FM 的计算复杂度限制,同时没有对低阶特征建模.Qu 等提出的PNN(Product-based neural networks)模型[10]使用外积、内积实现特征交叉,在DNN 的基础上使用特征提取层,完成高阶特征组合的同时融入低阶特征,无需进行两阶段训练.Cheng 等提出的Wide&Deep 模型[11]将传统的逻辑回归和DNN 以并行方式组合,充分发挥了逻辑回归模型的拟合能力和DNN 的泛化能力.但上述DNN 模型依赖于人工特征工程.Guo 等提出的DeepFM 模型[12]不需要人工特征工程,它令FM 与DNN 在嵌入层共享,同时学习高低阶特征组合.
以上DNN 模型都为推动CTR 预测的进一步发展做出了重要贡献,但均将用户兴趣视为整体.现实中用户的兴趣可能随着时间发生变化,如何通过用户历史点击行为探索其兴趣变化趋势,进而准确预测该用户对待预测项目的点击概率,成为一个需要解决的问题.自然语言处理领域广泛使用的“注意力机制”为解决该问题提供了有益启示.Zhou 等提出的DIN(Deep interest network)模型[13]使用注意力机制设计激活单元,针对不同待预测项目自适应调整赋予每条历史记录的权重,提升了嵌入层的表达和感知能力.该模型将注意力机制应用于CTR 领域的候选项目感知,但该模型在捕捉用户历史记录间的相对顺序时面临困难,难以关注某一记录的上下文信息.
自然语言处理领域处理词语和句子的方式对提取用户历史点击行为的上下文信息和顺序信息,建模用户长、短期兴趣两个问题具有重要参考意义.自然语言处理领域的DNN 模型中,基于循环神经网络(Recurrent neural network,RNN)的模型和基于卷积神经网络(Convolutional neural networks,CNN)的模型是两个重要类别.传统RNN 模型以序列数据作为输入,节点间按链式结构串联,但在实际应用中受限于梯度消失.长短期记忆网络(Long short-term memory,LSTM)[14]能够通过门控制在一定程度上解决梯度消失问题[15],但其结构复杂,训练所需时间较长.门控循环单元(Gated recurrent unit,GRU)[16]使用更简单的结构取得了与LSTM 接近的效果,在自然语言处理等领域被广泛应用.CNN 使用卷积和池化操作,具有很强的语义特征捕捉能力[17],结构合理的CNN 在自然语言处理任务中已经表现出良好的性能[18],但CNN 偏向关注相邻信息,容易忽略局部与整体信息的关联性.谷歌研究团队的Vaswani 等提出Transformer 模型[19]在机器翻译任务中使用自注意力和注意力机制,显著提升了训练速度的同时取得了更好的效果.
本文提出长短期兴趣网络(Long and short term interest network,LSTIN)点击率预测模型,解决CTR 预测中基于用户历史记录建模时上下文信息和顺序信息难以高效提取和充分利用的问题,提升点击率预测精准性,并通过对用户长、短期兴趣分别建模进一步提高训练效率.具体地,首先借鉴Transformer 模型的自注意力机制,提取用户行为上下文信息,并使用基于注意力机制的激活单元结构建立用户行为与待预测项目之间的关系,构建兴趣提取层.接着,构建信息融合层,将用户历史行为序列划分为长期和短期,对短期序列中的项目使用GRU 进一步处理.在亚马逊公开数据集上开展实验,结果表明LSTIN 模型与对比模型相比,获得了更准确的点击率预测结果.此外,本文对比了在短期序列项目处理时使用CNN 和GRU的效果,信息融合层使用CNN 的LSTIN 与使用GRU 的LSTIN 效果相近,训练效率更高.
本文所提出的LSTIN 模型主要有以下创新点:
(1)针对CTR 预测问题设计结构,借鉴自然语言处理领域模型完成序列数据建模,使用激活单元结构建立用户历史行为与待预测项目的联系.
(2)模型大量使用以注意力机制为基础的并行结构,训练效率较高.
(3)LSTIN 对同一用户长期和短期序列采用不同处理方式,使模型能够对用户长期兴趣和短期兴趣分别建模.
(4)LSTIN 在信息融合层可根据需要选用不同方法,具备灵活性和可拓展性.
1 相关定义和模型结构
1.1 长、短期序列定义
用户历史点击行为能够体现其特征和兴趣.将用户的历史点击序列定义如下,并在此基础上提出长、短期序列定义.
(1)历史点击序列.
对于某一特定用户,按照时间顺序排列的历史点击项目组成该用户的历史点击序列.其中最近N个项目定义为历史点击序列的短期部分.
给定共有n条历史点击行为的用户u,记其历史点击序列为 hsu,ti表示第i条点击行为发生的时刻,该时刻被点击的项目记作,则用户历史点击序列可表示为式(1).选取短期部分长度为l(l≤i),可以表示为式(2).“项目”在数据集中即为商品.
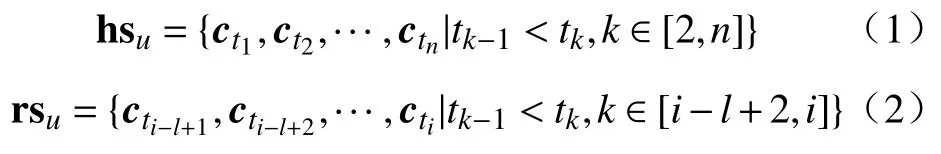
(2)长、短期序列.
长期序列:由用户历史点击序列 hsu通过编码器和激活单元结构(即后文中的兴趣提取层)处理后得到的向量序列为长期序列.
短期序列:短期部分 rsu通 过编码器和激活单元结构(即后文中的兴趣提取层)处理后得到的向量序列为短期序列.
1.2 模型结构
LSTIN 的模型结构如图1 所示,该模型主要由五部分构成,从下至上依次为输入层(Input Layer)、嵌入层(Embedding Layer)、兴趣提取层(Interests Extraction Layer)、信息融合层(Information fusion layer)、评分层(Scoring layer).输入数据自下而上经过输入层映射为独热编码(one-hot)向量,经过嵌入层映射为低维向量,通过兴趣提取层建模后按点击行为发生时间将序列划分为长期和短期两部分,分别在信息融合层合并为固定长度的向量用以表示用户的长、短期兴趣,将这两个向量与表示候选项目的嵌入向量拼接(Concat)后输入评分层,最终输出一个评分 score∈{0,1}表示预测用户点击候选项目的概率.兴趣提取层和信息融合层是LSTIN 模型提取用户兴趣、组合用户长短期兴趣的核心.

图1 LSTIN 模型结构Fig.1 Structure of an LSTIN
(1)输入层和嵌入层.
特征的选取对于模型的预测精度会产生显著影响[20],为验证模型结构的有效性,减少特征工程的影响,选择项目ID 和项目所属类别的ID 作为输入,统一使用one-hot 编码后通过嵌入层映射到低维、稠密的向量空间中并进行拼接.以项目ID为例,设该特征有k种取值,其第i项取值的onehot 向量与权重矩阵进行点乘得到嵌入结果,以特征取第3 个可能取值为例,其嵌入向量记为 i_idi,原理如式(3)所示,d表示希望得到的低维向量维度,0 的不同下标只为说明其所在位置.
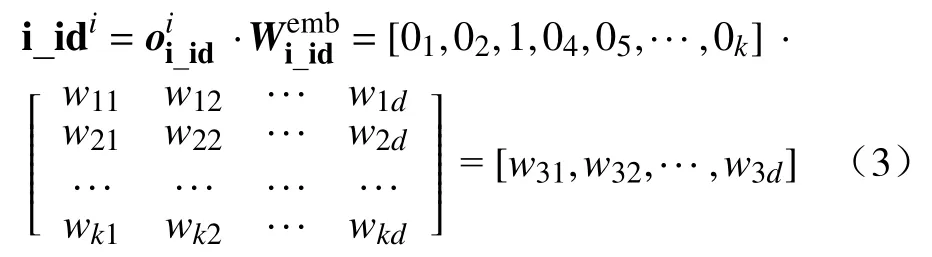
用户历史点击序列 hsu表示若干个项目按点击行为发生时间排序后的序列,序列中每个向量均由表示该项目的ID 和其类别ID 两部分向量拼接而成.用户u的 历史点击序列 hsu可表示为式(4).

(2)兴趣提取层.
兴趣提取层可以细分为一个编码器(Encoder)部分和一个激活单元(Activation unit)部分.
编码器部分的结构借鉴Transformer,其中自注意力(Self-attention)机制能够关注上下文信息和顺序信息,并且高效地完成长序列建模,克服梯度消失的问题.编码器结构如图2 所示.
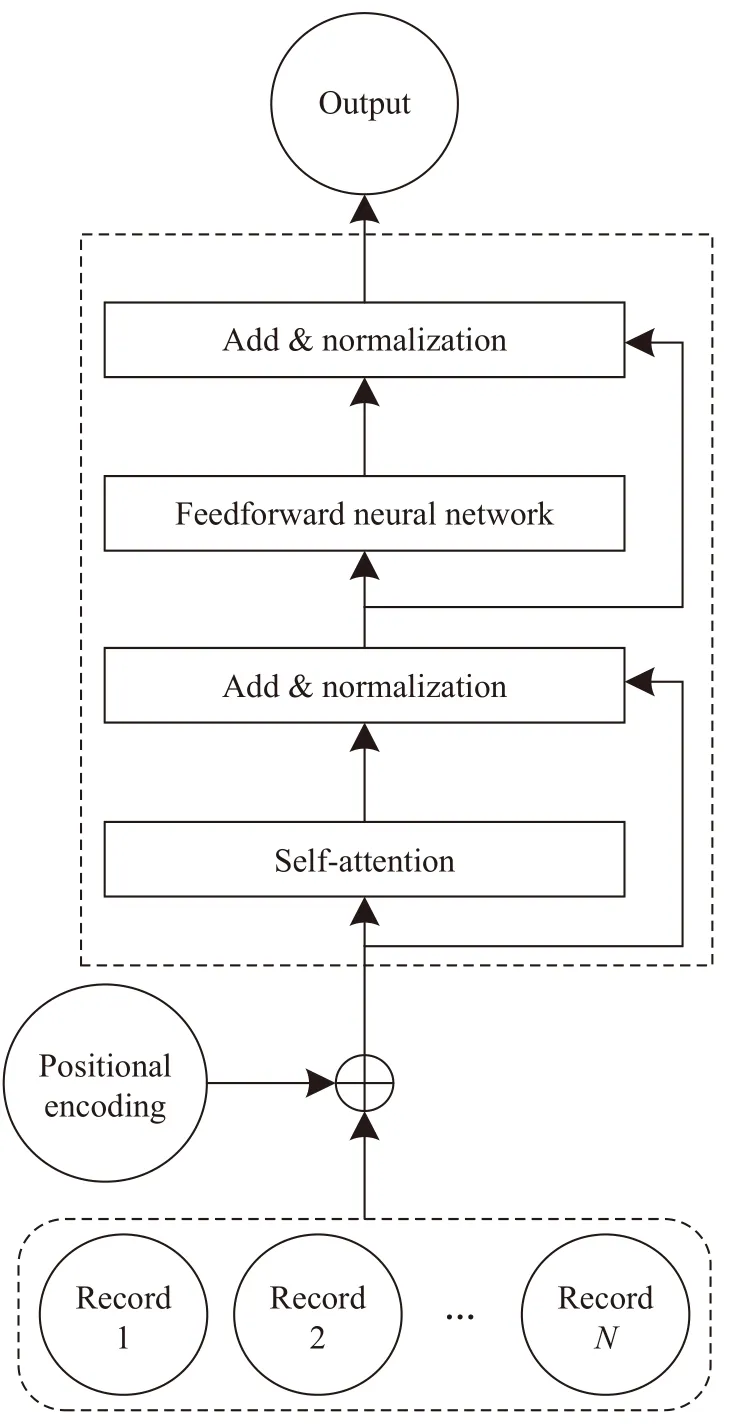
图2 编码器结构Fig.2 Structure of an encoder
通过输入层和嵌入层后,用户历史点击序列已经被映射为固定长度向量组成的序列,序列中每一个向量表示一次点击行为.编码器部分的作用是使得序列中的每个向量不仅包含本次点击行为的信息,也包含其在整个序列中的位置信息和上下文信息.
首先对得到的序列进行位置编码(Positional encoding),并将位置编码得到的向量序列与原序列相加.采取正余弦位置编码[19],如式(5)所示,将向量序列第p个位置映射为一个维度是dpos的向量,该向量的第k个值记作 PEk(p).应用中,一般令dpos和嵌入层得到的低维向量维度d相等.
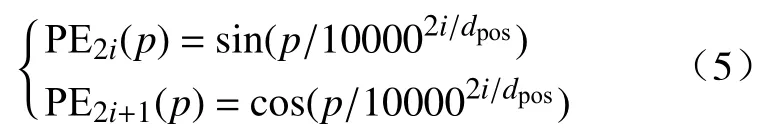
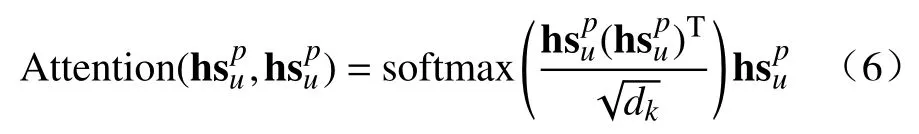
自注意力机制的输出与其输入进行残差连接后进行归一化(Add &Normalization),为增加模型的非线性能力,将数据继续输入一个前馈神经网络(Feedforward neural network)中.残差连接的作用是缓解梯度消失的影响,避免模型退化.前馈神经网络的输出与输入仍然进行残差连接并归一化,结果即为编码器部分的输出 E_out.该结果随后进入激活单元部分.
在编码器部分,可视作模型感知了每一次点击行为的上下文信息,在激活单元部分,模型进一步感知待预测候选项目信息.该部分仍使用注意力机制,思想与编码器部分注意力机制相似,但计算过程不同,将候选项目向量vc=复制,并将其与编码器部分的输出 E_out及二者的差三个矩阵拼接后输入三层全连接神经网络,如图3.该结构的目标是学习每个历史项目与候选项目的关系.
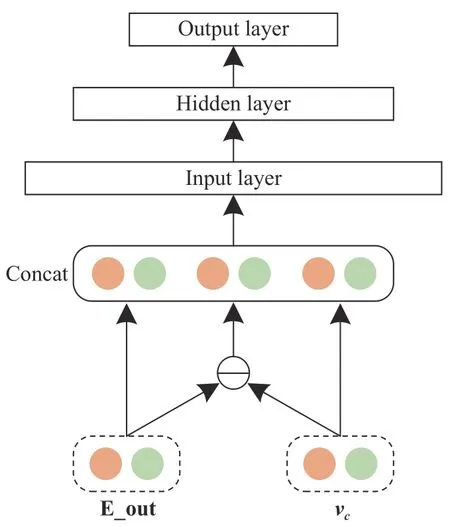
图3 激活单元注意力机制原理示意图Fig.3 Attention mechanism in an activation unit
(3) 信息融合层.
在本层,此前结构输出的向量序列被分为长期和短期序列,对长期序列建模关注用户长期以来相对稳定的兴趣,不同用户历史点击序列长度不同,为保证后续结构接收到的数据结构统一,采用平均池化的方式处理为定长向量,该结构输出的向量记作h.学习短期兴趣时,进一步使用GRU 处理短期序列,输出单个的定长向量r.
此外,针对短期序列建模,考虑将GRU 替换为一维CNN.CNN 最初为解决图像识别问题[21],后被应用在多个领域,自然语言处理任务常用一维CNN[22],它具有并行度高、提取局部信息能力强的特点.借鉴Kim[23]及Zhang 与Wallace[24]将CNN用于自然语言处理的经验,设置LSTIN 中的CNN网络第一层为卷积层,卷积核的长度为2,宽度为输入向量宽度,滤波器个数为100,输出矩阵的每一列包含一个滤波器的权值.第二层为平均池化层,第三层为与第一层结构相同的卷积层.最后,进行全局池化并抛弃一定数量的输出防止过拟合.
(4)评分层和损失函数.
至此得到了表征用户长、短期兴趣的向量和表征候选项目的向量,将三个向量拼接后输入评分层.评分层采取三层全连接神经网络,含输入层、隐藏层和输出层.全连接层输入层的处理过程可以表示为式(7),式(7)~式(9)中的下标1、2、3 分别表示变量位于全连接层神经网络的第几层.其中,[h,r,vc]由表征长期兴趣的向量、短期兴趣的向量和候选物品的向量拼接得到.在式(7)中,W1为输入层的权重矩阵,b1是偏置向量,lf1是输入层神经元的数量.o1∈是输入层的输出.
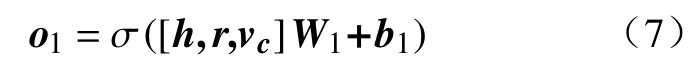
全连接层隐藏层原理与输入层相同,输出层使用softmax 函数,如式(8),最终需要得到点击或不点击的二分类结果.softmax 函数进行归一化,o3第一维表示用户不会点击该候选项目的概率,第二维则表示用户会点击该候选项目的概率.随后通过argmax 函数选择o3中最大的值并输出其索引,如式(9)和式(10)所示.最终∈{0,1}表示模型预测用户是否会点击该候选项目,0 表示不会点击,1 表示会点击.

预测模型的目标函数为最大似然估计的对数损失(Logloss),如式(11)所示.N是训练样本的样本总数,yi∈{0,1}代表用户的真实点击,取值含义与xi相同.pi为预测输入实例属于类别1 的概率.

2 实验设置
2.1 数据集、优化器和超参数设置
实验在亚马逊产品数据集(Amazon dataset)上开展,该数据集包含来自用户对产品的评论数据和产品自身的属性数据,是CTR 预测领域常用的开源数据集,如表1 所示.实验在其中一个电子类商品子集(Electronics 5)上进行,该子集包含19.24 万名用户、6.3 万项商品、801 个类别和168.92 万条行为记录.每个用户和商品都有5 条以上的评分.DIN 模型曾使用本数据集验证效果,在本数据集上进行实验有助于更加直观地对比模型效果.数据集仅包含正样本,随机抽取与正样本数量相同的负样本,选取每个用户行为序列中最后一条样本作为测试集,其他样本作为训练集.

表1 数据集统计信息Table 1 Statistical information of a dataset
使用Adam 优化器[25];学习率初始为0.001,并且设置学习率随着迭代次数增加而衰减;训练和测试的批尺寸(Batch size)设置为128.为公平起见,本文模型和对比模型在嵌入维度上保持一致,均为32;全连接层每层的神经网络单元数分别为4×32,1×32,1.短期序列长度设置为固定值5.
2.2 指标和对比方法
AUC(Area under curve)是CTR 预测领域常用效果度量方法[26],将样本根据预测点击率由大到小排列,随机取出一个正样本和一个负样本,正样本排在负样本前的概率即为AUC.计算公式如式(12)所示,x1和x2表示任取两个样本,X+和X-分别表示正、负样本的集合,N+和N-分别代表正负样本的数量,rank(i)指样本i的预测点击率的排名.
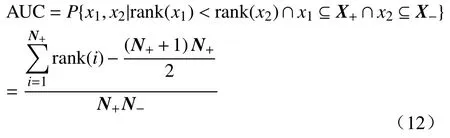
对比模型选用BaseModel、DeepFM 和DIN.BaseModel 是CTR 预测领域的基础DNN 模型,是最简单的Embedding+MLP 范式模型[13],遵循该范式的模型与之对比可以清晰地展示出结构改变后的效果提升.DeepFM 是FM 的衍生算法之一,提出后便成为CTR 预测研究领域经典算法之一.DIN 成功将注意力机制应用到CTR 预测中,建立了候选项目与用户历史记录的联系,与DIN 对比可以得出LSTIN 模型扩大模型感知范围并赋予模型序列数据建模能力后的效果提升.
为验证区分用户长短期兴趣对最终预测结果和训练效率的影响,首先构建不区分用户长、短期兴趣的模型,在兴趣提取层使用注意力和自注意力机制建立用户历史记录与候选项目和自身上下文之间的联系,信息融合层使用平均池化的记作LIN,信息融合层使用GRU 的记作LINr,使用CNN的记作LINc.接着,对于分别考虑用户长、短期兴趣的LSTIN 模型,在信息融合层,长期序列建模采用平均池化,依据短期序列建模采用的方法,将短期序列建模使用GRU 和CNN 的模型分别记作LSTINr和LSTINc.
3 实验结果
对每个模型重复5 次训练,取每次训练最高AUC,5 次训练平均值记为该模型AUC.Best AUC 是5 次训练中AUC 最高值.记RP(BaseModel)为某一模型AUC 对BaseModel 的相对提升,计算方式如式(13)所示,AUC(mesuared model)表示测试模型的AUC 指标.同理,记RP(DIN)为某一模型AUC 对DIN 的相对提升,结果如表2 和图4所示.

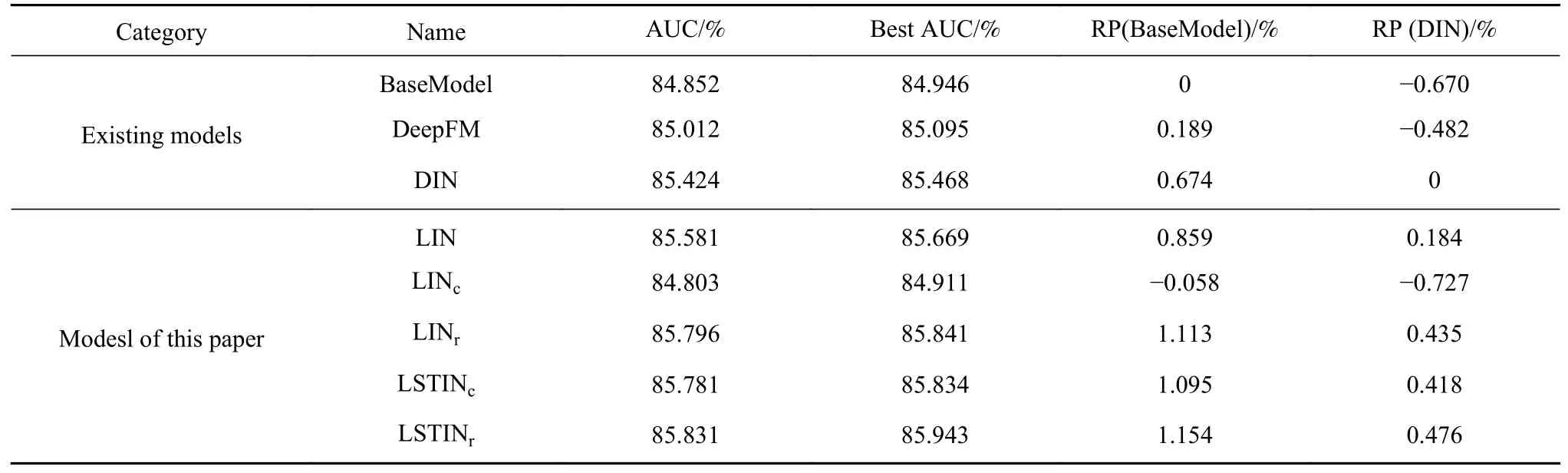
表2 算法性能对比Table 2 Algorithm performance

图4 算法AUC 对比Fig.4 AUC of various algorithms
LIN 相比DIN,结构上的差异只是在信息融合层前加入编码器结构,因此LIN 的AUC 指标高于DIN 可以证明模型获得感知上下文信息的能力后能够取得更好的效果.LINr效果进一步提高,证明GRU 结构相比平均池化能够更充分地提取和保留信息,使模型获得更强的学习和表示能力,但LINc效果不佳,效果低于BaseModel.在对长期和短期兴趣采取不同的处理方式后,LSTINr和LSTINc均取得了良好的效果.LSTINc相比LINc的效果提升,可进一步验证CNN 更加偏向关注局部信息,适用于处理长度固定的短序列.平均AUC 和最高AUC 的最大值均由LSTINr取得.
图5 对比了部分模型在达到最佳效果前AUC 随时间的变化.从AUC 的角度看,性能最佳的三个模型为LINr、LSTINr、LSTINc,LINr尽管性能较好,但需耗费超过60000 s 的训练时间取得最高AUC,此外LINr将用户全部历史数据通过GRU 处理,需要占用较多的内存资源.LSTIN 通过区分用户长、短期兴趣,对用户长、短期兴趣采取不同的处理方式,实现训练效率提升的同时保障并提升模型效果.在相同的实验环境下,LSTINr和LSTINc均在11000 s以内达到最高AUC,LSTINc略快于LSTINr.从模型效果及训练效率两个角度综合来看,将用户历史点击行为分为长期和短期两部分都是十分有价值的.
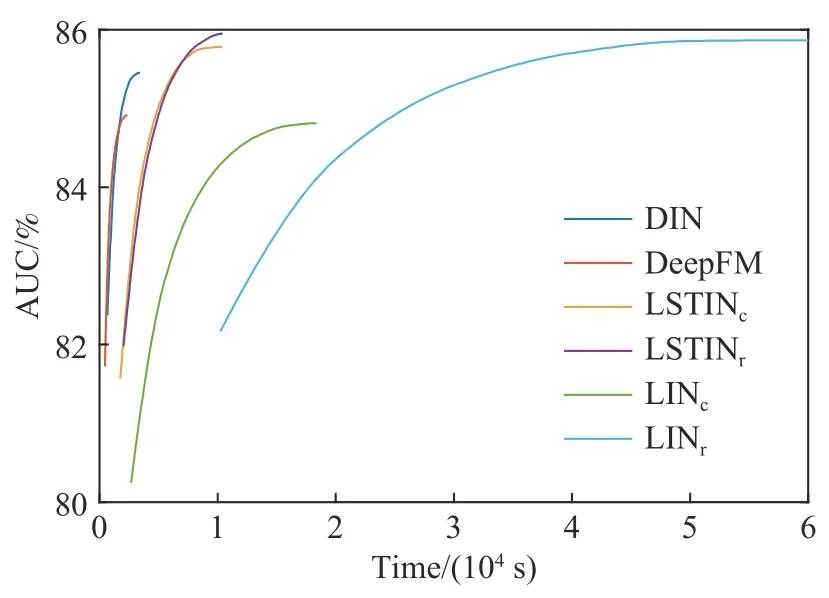
图5 部分模型训练时间对比Fig.5 Training time comparisons
4 结论
(1)针对点击率预测问题中,建模用户兴趣时用户历史记录上下文信息和顺序信息难以有效提取的问题,提出长短期兴趣网络模型,使用基于注意力机制的结构解决了以上问题.
(2)针对序列数据建模方法效率较低的问题,将用户行为分为长期和短期两部分,分别采用平均池化、RNN/CNN 进一步处理,保障模型效果的同时提高了模型训练效率.
(3)基于亚马逊公开数据集的对比实验表明,LSTIN的预测精度有明显提升.
