基于ALBERT预训练模型的通用中文命名实体识别方法
2022-10-13吕海峰冀肖榆陈伟业邸臻炜
吕海峰,冀肖榆,陈伟业,邸臻炜
1.梧州学院 大数据与软件工程学院,广西 梧州 543002;2.梧州学院 广西机器视觉与智能控制重点实验室,广西 梧州 543002;3.梧州学院 广西高校图像处理与智能信息系统重点实验室,广西 梧州 543002)
提取文本序列某些特定标签诸如机构、地点、时间、人名等实体的过程称为命名实体识别(Named Entity Recognition,NER)[1]。NER是关系抽取、对话系统、自动问答、信息检索等任务的重要组成部分,NER是自然语言处理研究的一个基础且重要的问题。
现阶段主流的深度学习命名实体识别方法,大多利用循环神经网络(Recurrent Neural Network,RNN)或卷积神经网络(Convolutional Neural Network,CNN)作为编码层抽取上下文特征,接着采用条件随机场Conditional Random Field,CRF)解码出正确标签序列,如(Collobert[2]、Peters[3]、Shao[4]、Rei[5]、Patrick[6]等),与条件随机场模型[8-10]、隐马尔可夫模型[7](Hidden Markov Model,HMM)。英文与中文在该任务不同,基于分词的中文实体抽取不能处理分词错误、数据稀疏、OOV(out-of-vocabulary)和过拟合问题,并且传统如Word2vec、glove的静态词向量不能处理一词多义问题[11]。因此,研究动态词向量刻不容缓。(Embeddings from Language Model,ELMO )预训练语言模型被Matthew等[12]提出,能够按照当前上下文动态调整字或词向量,可有效解决上述问题。2018年Google则提出一种双向Transformer[19]的编码表示方法(Bidirectional Encoder Representation for Transformers,BERT)[13],在文本分类、依存分析、序列标注、相似度等11类NLP任务上均取得了很好的效果。尽管BERT应用广泛、效果很好,对各项NLP任务的提升都很显著,但存在模型参数量大、效率低等问题。于是Lan等[14]提出了一个精简版BERT模型,简称ALBERT,因式分解词向量矩阵,对下游任务中所有层实现参数共享,不仅具有较少参数量,而且在SquAD、RACE、GLUE等任务表现方面取得最佳效果。
当前,尽管有不少针对中文的实体识别方法,但识别效果依然不够理想,有必要进一步研究,通过改进以及优化现有实体识别模型,构建基于预训练语言模型融合自定义词典的新实体识别模型,以进一步提升实体抽取效果。
1 相关工作
基于深度学习、统计机器学习以及规则字典方法是NER任务中常用的3种方案。基于规则字典的方法需要依赖大量先验知识,通过设计规则模板以提取对应的实体信息,存在任务难度大、不可移植、效率低等缺点。结构化单一数据集采用基于规则字典的方法比较可行,但在实际场景里,非结构化数据往往占据大多数比例,建立规则模板难以覆盖所有的非结构化数据范围。以隐马尔可夫模型HMM和条件随机场CRF等为代表的统计机器学习方法在实体识别任务上取得一定的效果,具备一定泛化能力。但即便如此,这些统计机器学习方法仍然依赖特征模板,不能自动提取特征,需要标注大量的样本,识别效果不够明显。
构建基于深度学习的序列标注模型识别实体被认为是序列标注任务。基于CNN网络结构的序列标注模型由Collobert等[15]提出,并且拥有良好的提取效果。序列长距离上下文信息、固定长度输入等问题得以解决是由于RNN的提出。由RNN派生出的各种版本,能够在一定程度上降低反向传播过程中出现梯度消失问题,有效保存和获取序列上下文信息,最典型的RNN变体如GRU和LSTM。以BiLSTM作为编码层,CRF作为解码层的模型由Huang等[16]提出,实体抽取效果达到了当时SOTA表现。
近年来,自然语言处理技术发展迅速,尤其是得益于深度神经网络方法在自然语言领域的广泛应用。以利用预训练字/词向量技术的Word2vec、Glove等神经网络模型[17,18],较好地捕获文本序列的上下文特征,但不能处理一词多义问题,未有效考虑词在序列的位置对词意义的影响,属于典型的静态词向量。于是ELMO模型被提出,能够按照此刻上下文动态调整词向量权重,有效解决上述问题。但ELMO还是使用LSTM结构进行特征抽取,上下文特征提取能力弱。2018年Devlin等人提出了在众多测试集上获得新SOTA表现的深度双向表示预训练模型BERT[13]。尽管BERT应用广泛、效果很好,对各项NLP任务提升都很大,但存在模型参数量大、效率低等问题。于是Lan提出了一个精简版BERT模型,简称ALBERT,因式分解词向量矩阵,对下游任务中所有层实现参数共享,不仅具有比BERT更少参数量,而且在SquAD、RACE和GLUE等任务表现获得当时最佳效果。故在命名实体任务中怎样高效融合ALBERT,以提高实体识别性能,无疑是当前研究的热门主题。
现阶段实体抽取的研究存在问题主要有:(1)仅依赖词或字符级别特征,长距离语义信息因为梯度弥散,导致文本语义信息容易丢失;(2)早期的类似Word2vec等上下文无关、静态词向量,导致不能解决一词多义的问题。针对上述问题,本文提出了一种基于ALBERT-Attention-CRF模型的中文实体识别方法。采用ALBERT在命名实体任务进行微调,不仅解决了一词多义问题,而且处理了词级别出现数据稀疏、OOV、过拟合等问题,提升了模型对文本序列特征抽取能力。结合Attention机制编码文本语义信息,不仅有效处理实体边界模糊问题,而且比经典BiLSTM模型利用更多文本语义信息、捕获更长的距离依赖,最后在输出层采用CRF模型,该方法能考虑到序列标注直接的依存关系,有助于提高模型对实体识别准确率。模型在人民日报数据集进行验证,测试集总体命名实体识别F1值达93.72%,结果表明本文所提方法与BERT相比,参数量更小,效率更高,有效降低模型大小和提高命名实体识别的整体效果。
2 模型
2.1 BERT模型
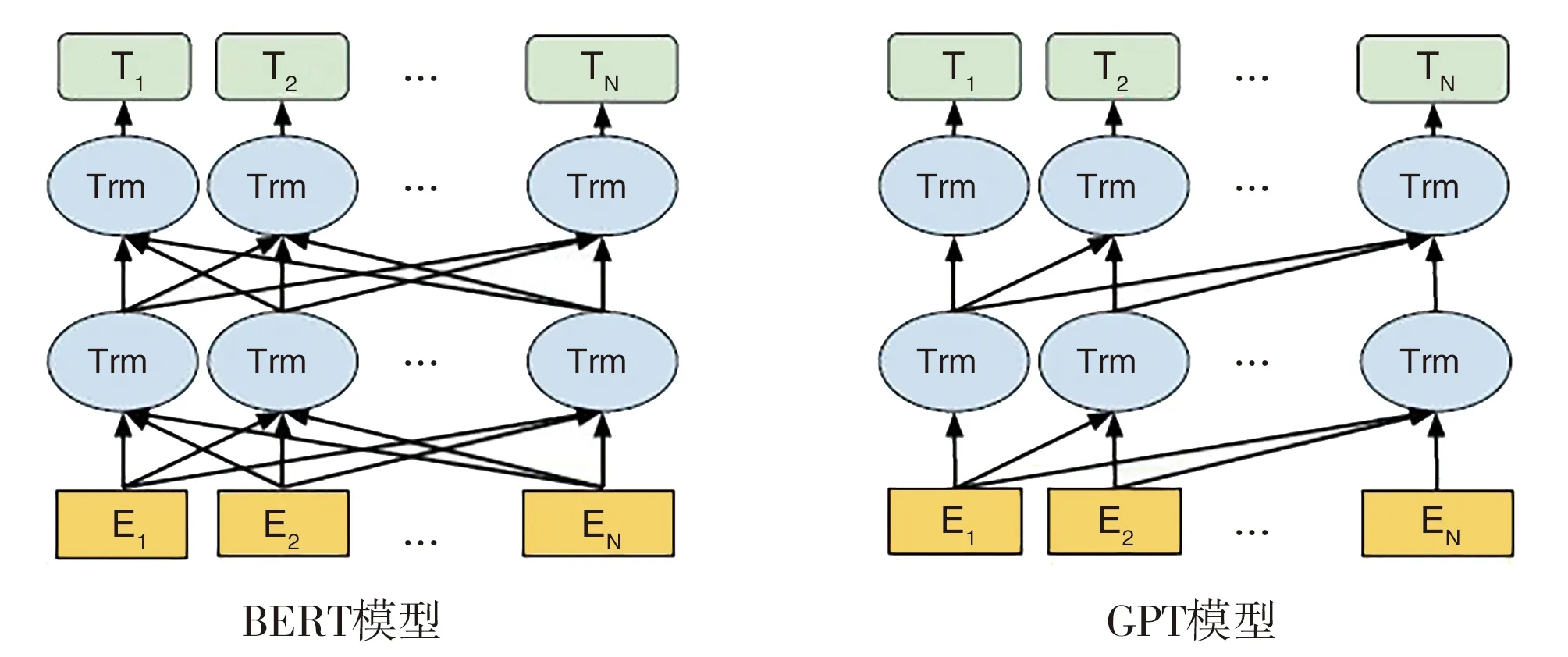
传统如Word2vec静态词向量仅考虑词的局部信息,不能处理一词多义问题,且缺少词与局部窗口外词的联系。基于LSTM结构模型预训练词向量,有效捕获长间隔的语义特征,于是Matthew等[12]提出了有效捕获序列两侧上下文信息的ELMO模型,它是基于两层两向的长短期记忆网络结构,有效缓解单向信息学习的问题。Radford等[20]提出(Generative Pre-Training,GPT)模型。不同于ELMO,GPT采用单向Transformer预训练,下游具体NLP任务以微调模式实现。与LSTM相比,GPT缺点是单向的,但能够捕获更长上下文语义信息。使有效学习句子两侧上下文信息,基于双向Transformer的BERT模型被提出,句子两边的上下文在全部层中得到相同依赖,双向语言模型、特征提取能力得到改进和提升。BERT模型就其他模型而言,达到了去粗取精的效果。在多种NLP任务上获得了当时的SOTA效果。BERT与ELMO、GPT模型结构见图1[13]。
2.1.1 BERT输入表示
输入表示可以是单个句子或者一个句子对构成的词序列。对给定的词,其输入表示由3个Embedding组成。Embedding可视化表示见图2[13]。

图2 BERT模型输入表示
其中,本文以中文字向量作为Token Embeddings;首个Token是用在后续分类任务的CLS标志;常用在句子级别分类任务的Segment Embeddings分割两个句子;人为设置的序列位置向量是Position Embeddings。
2.1.2 BERT模型预训练任务
BERT模型分别使用Masked Language Model(Masked LM)和预测句子这两个无监督预测任务进行预训练。在Masked LM任务中,为了训练编码器是双向Transformer深度表示,随机遮掩15%字符(Token),然后对被遮挡的Token进行预测。遮掩规则:(a)以符号Masked替代80%已遮掩的字符;(b)随机字符代替10%;(c)被遮掩字符的10%不变。
此外,自然语言处理中有很多需要理解两个句子之间关系的句子级别任务,如自动问答、推理等任务。通常是以随机替换方式,判断两个句子是否连贯的分类任务被加入到BERT预训练中。预测格式见表1。

表1 句子对预测格式
2.2 ALBERT模型
在学习文本表示时,一般预训练模型的参数越多,下游任务的效果就越好,如BERT模型。但是,有时候受到训练时长、TPU/GPU内存制约等因素影响,模型参数增加导致模型使用效率低。针对上述难题,Google提出了参数量大大低于BERT的简化版本 (A Lite BERT,ALBERT)[14]。
预训练模型扩展的关键瓶颈在ALBERT中提出的2种参数消减技术得到解决。一是因式分解向量参数:将大词向量矩阵变为2个小矩阵,因而相互分离词向量与隐藏层的大小。该技术使得词向量参数增加不明显,且便于扩展隐藏层。二是可以共享不同层之间的参数:它不会因扩大网络层数而增多参数量。这2项技术都大大提高了参数效率,且明显减少了BERT 的参数量。BERT-large配置与ALBERT相似,但前后者参数量之比约为18∶1,训练速度之比约为1∶1.7。上述削减参数技术提升泛化能力,使得训练比较稳定,并具备一定正则化效果。
为了提高ALBERT性能,基于句子层面预测的(SOP)自监督损失函数被研究者提出。SOP旨在处理传统BERT中NSP任务loss效率低的问题,关注句间的连贯性。鉴于上述改进,ALBERT可以支持不同版本扩展,以明显提升性能且参数量远低于BERT-large为目标。
2.3 Attention机制
尽管通过Encoder的语义表示涵盖充分的上下文特征,但由于其权值相同,难以对实体类别进行有效区分。Attention 旨在捕获上下文语义特征,它根据编码层输出的每个词隐向量xi,通过S=∑αi·xi。其中αi为预设权值,s为由x1,x2,…,xn组成的文本序列。在注意力机制中,权值αi呈现字符间的关联性,因为每个字符距离都是1,实体界限容易得到有效区分,因此字级别样本集实体界限不易划分的问题得到有效缓解。
2.4 CRF模型
多分类任务常用Softmax输出每个类别的概率,由于Softmax分类器的输出相互独立,并未考虑标签之间的依存关系。因此,条件随机场,即CRF模型[21]被常用来做序列标注任务。该方法有效考虑到序列相邻词的标注信息,能够更全面预测标签。给定输入序列X(x1,x2,…,xn),Y(y1,y2,…,yn)都是线性链的随机序列。如果给出X前提下,Y的条件概率分布P(Y|X)是条件随机场,如果符合下面假设,则P(Y|X)为线性链条件随机场。
P(Yi|X,Y1,Y2,…Yn)=P(Yi|X,Yi-1,Yi+1)
(1)
设P(n,k)为输出层的权重矩阵,输出标签序列Y的总得分S(x,y),即
(2)
其中,A是转移得分矩阵,n表示句子长度,k表示标签种类个数。
对所有可能的序列路径用softmax函数计算,产生关于输出序列y的概率分布,即:
(3)
在训练过程中,常使用极大似然法求解P(y|x)的最大后验概率,即
(4)
在解码阶段,预测最高总得分的序列即为最优序列,即
(5)
CRF训练和解码一般采用动态规划算法Viterbi[22]来求解最优序列。
2.5 ALBERT-Attention-CRF模型
模型由5层构成,分别是输入层、嵌入层、ALBERT特征编码层、注意力层、CRF层。模型最先采用ALBERT向量化表示每个字符,获取对应字向量;然后利用ALBERT预训练模型中的双向Transformer结构对输入字向量序列进行特征提取;为了加强上下文语义表示,采用Attention机制获取语义向量;最后使用CRF解码语义向量,CRF能够有效考虑到序列相邻词的标注信息,得到概率最大的标签序列,进而解析出序列中的实体。模型结构如图3所示。

图3 ALBERT-Attention-CRF模型结构
其中,x1,x2,…x7表示输入文本“北京是我国首都”经过ALBERT预训练语言模型向量化后的字向量;接着为ALBERT预训练语言模型编码层,主要由多层双向Transformers结构组成,得到包含上下文信息的语义向量h1,h2,…h7。Fchar是计算2个字符之间关系权重的Attention层加权函数,拼接向量为V。最后为CRF层,输出输入序列对应的实体标签,如地点(LOC)、时间(T)等,其中“B-”为实体起始标志,“I-”为实体中间或结尾。
3 试验及结果分析
3.1 数据与评价指标
为了检验模型有效性,本研究利用北京大学公开的1998年《人民日报》语料进行验证。该语料不仅已经分词,还标注了地名、人名、组织机构名等实体。标记方式为“BIO”,实体起始标志为B,实体其他部分为I,O表示该词不是实体。地名采用LOC标记,开始位置为B-LOC,其余位置为I-LOC;人名记为PER,开始位置为B-PER;组织机构实体为ORG,开始位置为B-ORG。试验中,取45 000条标注数据作为训练集和验证集,3 432条标注数据作为测试集。
模型评价指标采用精确率(Precision,P)、召回率(Recall,R)和F1值(F1-score)进行衡量。
3.2 模型训练与参数设置
本研究采用Tensorflow深度学习框架构建和训练所提出的ALBERT-Attention-CRF模型。参数设置有:输入文本序列长度seq_length设为64,验证集、训练集batch_size均为32,学习率为1e-10-5。为降低过拟合风险,设置dropout=0.8。为预防在模型拟合中产生梯度爆炸,利用梯度裁剪技术(Gradient Clipping)并设置大小为5。
3.3 试验结果
在数据集上,对CRF,BiLSTM,BiLSTM-CRF,BERT-CRF,ALBERT-Attention-CRF模型进行性能分析,结果见表2。
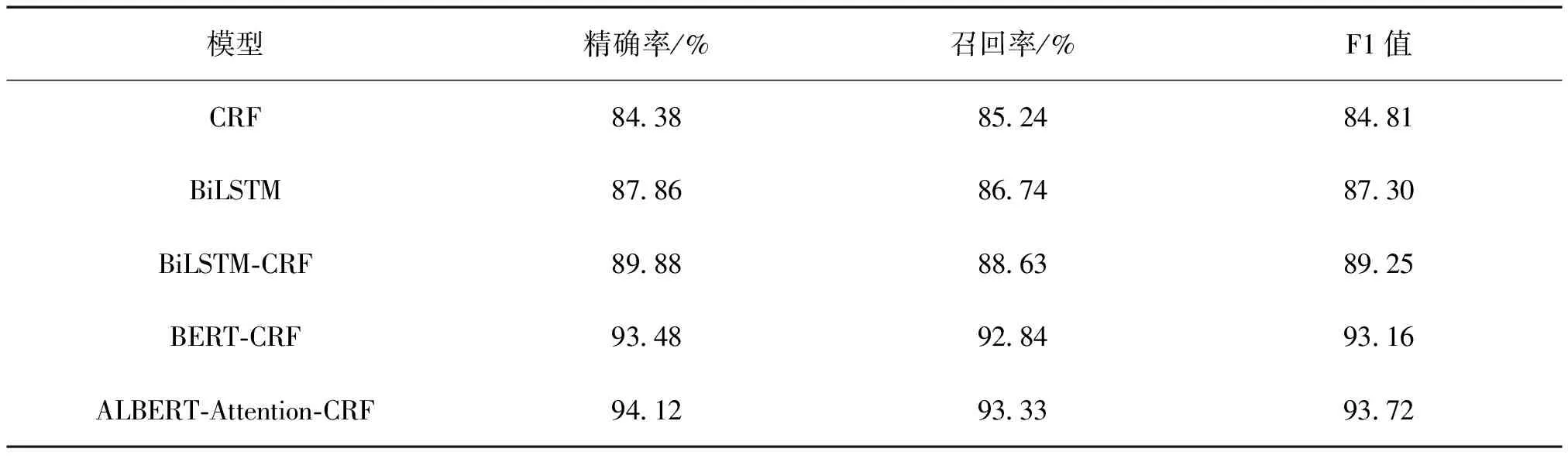
表2 模型的实体识别试验结果
由表2可知,基于神经网络的模型在各个指标均优于CRF模型。在BiLSTM和BiLSTM-CRF模型的对比中,采用CRF进行实体识别的BiLSTM-CRF模型表现优于前者,说明CRF在解码时考虑了序列中全局标注信息,因而提升了模型表现。在BiLSTM-CRF模型和BERT-CRF的对比中,后者比前者有接近4%的表现提升,说明基于Transformer架构的BERT模型充分学习了文本序列上下文关系特征,比BiLSTM学习到更长的距离依赖语义关系。ALBERT-Attention-CRF模型比BERT-CRF高0.6%,两者在精确率、召回率、F1值这3个指标表现接近,但前者模型在效率上更高效,BERT-large配置与ALBERT相似,但前后者参数量之比约为18∶1,训练速度之比约为1∶1.7。在同样的超参数设置下,本研究提出的ALBERT-Attention-CRF模型训练所得模型大小仅为BERT-CRF模型的1/10,运维部署比后者更便携,效率更高。
4 结语
本研究提出一种端到端神经网络命名实体识别模型ALBERT-Attention-CRF,采用ALBERT预训练语言模型对输入文本序列进行向量化和特征抽取,使模型能够充分学习文本包含的语义信息,使字符之间的推理能力得到增强、实体识别效果得到进一步提升。同时,为了进一步增加上下文相关的语义信息,模型还使用注意力机制进行有效区分实体类别,以及利用CRF模型作为输出层,有效通过全局信息进行预测实体标签,在1998年上半年《人民日报》语料上取得了理想的效果。试验结果表明,基于ALBERT预训练模型的命名实体识别模型不仅能够提升实体识别的效果,而且与BERT模型相比,存在参数量小、训练速度快、效率高等优点,有一定的参考价值。
