变化区组随机化及其SAS宏实现
2022-10-12谢金亮何韵婷王筱金王炳顺
谢金亮 何韵婷 王筱金 何 豪 王炳顺Δ
【提 要】 目的 非固定区组长度可有效降低随机对照临床试验(RCT)中区组随机化分组的可预测性,为此编制全自动SAS宏程序实现变化区组随机化。方法 结合变化区组随机化的原理编制SAS宏程序,通过模拟实例演示程序的使用。结果 输入设定的宏变量参数,运行SAS宏程序即可生成变化区组随机化的受试者分配方案。此外,该SAS宏能实现多臂不等比RCT的分配问题,提供了受试者随机分配序列重现的功能。结论 多区组长度的设置和区组长度的随机选择能够降低分组可预测性,避免随机分组阶段选择偏倚的产生。本文的SAS宏为随机对照临床试验实现变化区组随机化提供了便利。
随机化是随机对照临床试验(RCT)设计的基本原则之一。适宜的随机化方法可以避免选择偏倚的产生和平衡未知因素的影响[1]。RCT常用的经典随机化方法有简单随机化、区组随机化及分层随机化等。区组随机化能够确保各组样本量均衡,达到最大的试验效率[2-3],以及消除入组时间差异对处理效应的影响。因此,区组随机化常受到临床试验研究者的青睐。
不可预测性是随机化的要旨之一,是指试验相关人员在随机分配实施前不能预先知晓治疗分配的相关信息。不可预测性的破坏会导致RCT的分配隐藏(allocation concealment)措施受损,处理组治疗效果甚至会被放大高达40%[4-5]。传统区组随机化的运用会增加随机分配序列的可预测风险[6]。基于传统区组随机化的原理,以随机选择的区组长度替代固定区组长度的设置,能够有效降低随机分组的可预测性,该随机分组方法称为变化区组(varying block sizes)随机化[7],现已越来越多地运用于临床研究。
已有一些便利实现变化区组随机化的SAS程序公开发表。然而,此前报道的变化区组随机化SAS程序存在诸多局限,主要有①不是基于宏的程序显得冗长,参数需做较多修改;②适用范围较局限,多用于最简单的1∶1平行组对照设计;③无法实现自动生成种子数并据此种子数重现分组的需求[7-9]。2021年9月8日国家药监局发布的《药物临床试验随机分配指导原则(征求意见稿)》明确提出,可以在同一研究中设置多个区组长度以尽可能减少分组的可预测性[10]。为此,本文旨在开发简单易用的SAS宏,帮助临床研究者更好理解变化区组随机化以便更好地应用。
方 法
1.变化区组随机化
区组随机化是指将具有相似属性(如接受治疗时间、体重、种族等)的受试者划分成若干个大小相等的区组,区组内的各组别受试者比例与总的各组别受试者比例相等。各区组内的受试者按一定比例(通常为1∶1)随机分配至各处理组,最后得到各组样本量符合预期比例的随机分配方案。区组随机化与其他随机化方法的显著区别在于增加了区组的设置,通常以“区组长度”或“区组大小”来描述各区组内的受试者数量。
变化区组随机化是相对于传统区组随机化而言的,其以随机可变的区组长度代替固定长度的区组,即相邻区组的样本量不一定相等且研究者无法知晓各区组的区组长度。研究者可以根据方案中设定的样本量和设置的多个“区组长度”,将受试者随机划分成若干个大小不等的区组。“区组长度”通常设置为2类或3类,区组长度一般取比较组数的倍数。例如,当试验为双臂RCT时,区组长度可取4、6、8[11]。
2.SAS宏程序
(1)SAS宏的各类变量说明
本文通过结合循环语句、ranuni函数以及proc rank步骤实现变化区组随机化,运用SAS 9.4进行SAS宏的开发。在变化区组随机化程序执行过程涉及两类变量:宏变量和运行过程中生成的新变量,变量的名称和含义如表1所示。

表1 SAS宏主体中变量的设置和含义
(2)SAS宏主体及解释
%macro RdmVBsize(samplesize=, trtnames=,blksizes=, outrtf=, seed=);
/*1.检查是否定义了所有必选宏参数*/
%if %length(&samplesize)=0 %then %do;%go to ENDIT1;%end;
%if %length(&trtnames)=0 %then %do;%go to ENDIT1;%end;
%if %length(&blksizes)=0 %then %do;%go to ENDIT1;%end;
/*2.自动生成种子数*/
%if %length(&seed)=0 %then %do;
%let seed=%sysfunc(floor(%sysfunc(datetime())));
%end;
/*3.确定区组长度的数量和各个区组长度*/
%let Numblksize=%sysfunc(countw(&blksizes,%str()));
%do i=1 %to &Numblksize;
%let blksizes&i=%scan(&blksizes,&i,′ ′);
%end;
/*4.随机分配区组长度*/
data work.plan;
sum=0;blk_id=0;sub_id=0;
do while(sum<&samplesize);
r=mod(input(ranuni(&seed)*100000000000,3.0),&Numblksize.);
%do i=1 %to &Numblksize.;
if r=%eval(&i.-1)then do;
size=&&blksizes&i.;
blk_id=blk_id+1;
sum=sum+size;end;
%end;
if sum>&samplesize then do;
sum=sum-size;
size=&samplesize-sum;
sum=sum+size;end;
do j=1 to size;
rand=ranuni(&seed);
sub_id=sub_id+1;
output;end;
end;
run;
/*5.确定各区组内序列*/
proc rank data=plan out=plan;
by blk_id;var rand;
ranks rank;
run;
/*6.将各区组受试者随机分配入组*/
%let trtnum=%sysfunc(countw(″&trtnames″,%str()));
%do i=1 %to &trtnum.;
data treat&i;
set plan;
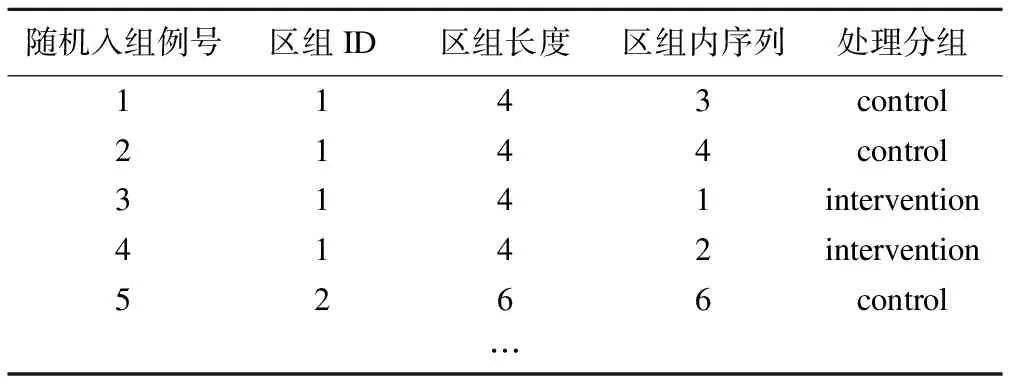
if(size/&trtnum)*(&i-1) treatment=scan(″&trtnames″,&i,″ ); output treat&i;end; run; %end; /*7.输出分配方案*/ data allocation;set treat:;by sub_id;run; proc datasets lib=work noprint; delete plan Treat:; run;quit; ods rtf file=“&outrtf.”bodytitle; title1 “变化区组随机化分配方案”; title2 “样本量=&SampleSize.区组长度=&blksizes种子数=&seed.”; proc report data=allocation nowd headline; column sub_id blk_id size rank treatment; define sub_id/“随机入组例号” center; define blk_id/“区组ID” center; define size/“区组长度” center; define rank/“区组内序列” center; define treatment/“处理分组” center; run; ods rtf close; %goto ENDIT2; %ENDIT1: %PUT ERROR:MACRO STOPPED-MUST ENTER THE RIGHT PARAMETERS.; %ENDIT2: %mend RdmVBsize; 本研究通过模拟两个RCT的随机化情境,展示如何利用变化区组随机化SAS宏程序,生成不同RCT情境下的受试者随机分配序列。 示例1:一项单中心平行对照临床试验,计划招募48名受试者,运用变化区组随机化方法,将受试者以1∶1的比例随机分配至处理组和对照组。研究者设置两个区组长度(4、6),执行SAS宏得到受试者随机分配表,部分结果如表2所示。 表2 示例1变化区组随机化的部分分配方案样本量=48 区组长度=4 6 种子数=1950126068 %RdmVBsize(samplesize=48, trtnames=intervention control, blksizes=4 6, outrtf=D:RdmVBsize1.doc; seed=); 假若有存档或验证方面需求,将自动生成的种子数填入对应宏参数位置,即可重现上述随机分配序列。如: %RdmVBsize(samplesize=48, trtnames=intervention control, blksizes=4 6, outrtf=D:RdmVBsize1Rep.doc; seed=1950126068); 示例2:一项三臂RCT,计划纳入200例患者,将患者以2:2:1的比例随机分配至A药组、B药组及安慰剂组。研究者设置的三个区组长度(5、10、15),运行变化区组随机化SAS宏,得到的部分分配结果如表3所示。SAS宏调用如下: 表3 示例2变化区组随机化的部分分配方案样本量=200 区组长度=5 10 15 种子数=1950126168 %RdmVBsize(samplesize=200, trtnames=drugA drugA drugB drugB Placebo, blksizes=5 10 15, outrtf=D:RdmVBsize2.doc; seed=); 1.传统区组随机化存在的风险和改进 区组的设置使得比较组间保持均衡,同时避免入组时间趋势对受试者分配的影响,提高了试验效率。但区组长度的设置固定且较小[12],使随机分配序列的可预测风险增加并可能提前被揭秘,进而产生选择偏倚。若应用于开放性RCT,盲法的缺失会进一步增加可预测风险,产生更严重的选择偏倚。Rosenberger和Lachin提出以随机变化的区组长度取代固定的区组大小,即使相关人员知晓区组长度也无法预测分配序列[13]。既往研究表明,变化区组随机化的区组长度不小于相应传统区组随机化时,前者的不可预测性明显优于后者[7],在多数医疗器械或外科手术类开放性临床试验中更加适用。 2.既往区组随机化SAS编程思路及局限 临床试验实际工作中,通常采用权威的SAS统计软件编程生成随机化序列。Lei Li结合随机化过程proc plan和if函数实现变化区组随机化[8],其编程思路主要是:①重复执行proc plan语句产生不同区组长度的区组的组内序列,并整合分配序列数据集;②通过if函数指定各序列号的受试者入组。该编程思路存在一定局限:该SAS程序非宏程序,使用过程需要修改多处程序,智能化欠佳;使用者需要提前计算相关参数,确保产生的序列数量与研究预设样本量相等;区组长度的分配非随机,即通过proc plan语句同时输出区组长度相同的区组的组内序列,导致最终分配方案中,区组长度相同的区组接连进行分组。 Jimmy Efird的变化区组随机化SAS宏较简洁[9],其编程思路如下:①区组长度随机分配:ranuni函数产生并分配给区组随机数,if函数根据随机数大小从预设区组长度中选取一个,作为该区组的区组长度;②区组内序列确定:循环语句和ranuni函数联用,逐一分配随机数,随机数排序后得到区组内序列;③分配入组:构建序列与区组长度一半比较的不等式,将受试者以1∶1分配至不同处理组;④循环输出各中心的各区组序列。Jimmy Efird的SAS宏,使用较繁琐,需要在宏程序内部修改多处参数;区组长度的分配方法易出现序列数量与样本量不一致的问题。此外,只能预设三个区组长度且并未整合所有区组的序列,不利于结果的重现。国内学者的宏程序和Jimmy Efird的主要编程思路一致,程序语句和函数略有差异[7]。以uniform函数联用产生随机数,接着proc rank语句进行排序并输出区组内序列。该宏程序冗长且可读性欠佳;区组长度选择少,只能预设两个区组长度,其中一个已固定为2,区组长度小,不可预测较差。 由上可见,既往报道的变化区组SAS实现程序存在如下不足:无法满足自动生成种子数并据此种子数重现分组的需求,不能对生成的随机序列进行核验;仅适用于平行组设计(1∶1)的RCT,适用范围较窄;程序本身并非完全自动化,参数需在宏程序内部进行修改和填写。 3.其他软件变化区组随机化的实现 除SAS外其他统计软件也有实现变化区组随机化的相关程序。R语言中的随机化程序包randomizeR,内含能够实现变化区组随机化的程序rpbrPar[14]。程序中blockrand函数能够通过设置不同的参数实现区组长度随机化分配,但它可能导致组间比例分布不均,以及产生的随机化序列可能会超过预先指定的样本大小,而且无法自动生成种子数。另一个程序包randomizr也存在类似问题[15]。Stata中也有实现变化区组随机化的类似程序,但同样可能会产生序列过多的问题[16]。 4.本文SAS宏的优势 本文SAS宏具体编写过程前文已展示,其主要编程思路及相应优势如下。①核验宏变量和生成程序参数:检验宏变量的输入格式,确保程序正确运行;根据系统时间自动生成随机化种子数,提取预设的区组长度。②区组长度的随机选择:各区组通过循环语句和MOD函数从预设的区组长度中随机选取一个,作为该区组的区组长度;比较区组长度的总和与样本量的大小,判断是否停止循环,确保二者的一致性。③确定各区组内序列:循环语句和ranuni函数联用,逐一分配随机数,proc rank语句输出区组内序列。④分配入组:宏变量trtnames既能表示处理组数,也能体现各处理组样本量的比例。结合循环语句,使程序不再局限于双臂(1∶1)RCT的受试者分配,能够实现多臂及各比较组不同比例RCT的受试者随机化分配。⑤输出分配方案:方案输出过程,自动生成的随机化种子数将显示于随机分配表的副标题。倘若有重现性需求,在宏变量seed处输入此前自动生成的种子数,即可重现随机序列。 目前,随机对照临床试验常常是多中心临床试验,且各中心样本量一般不相等。为此,可以根据方案中各中心样本量分别设置相关参数分别执行本宏,可以生成相应的分配方案。该SAS宏的使用可能随机出现小区组的情况,即最后一个区组的区组长度小于研究者预设的区组长度。但试验相关人员无法知晓是否存在该区组,且该小区组的区组长度仍为比较组倍数,同样能将受试者以既定比例均衡分配至各组,并不会破坏预期的随机分配比例和均衡性。 总之,变化区组随机化通过提高随机分配序列的不可预测性,尽可能避免受试者随机入组阶段选择偏倚的产生,尽可能确保随机对照试验尤其是开放性临床试验研究结果的真实性。本文的SAS宏可以很方便地实现变化区组随机化,可以满足实际临床研究中各组比例多样化的需求,而且满足随机分配序列可重现性的要求,提升了程序的适用性和应用的规范性。结 果

讨 论
