基于重采样和Voting异质集成的分类模型在肝硬化并发肝性脑病风险预测中的探索性研究*
2022-10-12王旭春翟梦梦李美晨全帝臣张岩波刘近春仇丽霞
王旭春 翟梦梦 任 浩 李美晨 全帝臣 张岩波 刘近春 仇丽霞△
【提 要】 目的 针对肝硬化并发肝性脑病风险预测的因素具有高维性、冗余性及类间不均衡的特征,研究变量筛选后的重采样和Voting异质集成分类模型的风险预测性能。方法 收集2006年1月-2015年12月某三甲医院消化内科肝硬化住院患者950例,68例并发肝性脑病,采用logistic 逐步回归进行风险预报因子初筛;再采用SMOTE重采样技术及其改进算法处理不平衡数据;最后采用SVM、MLP、随机森林以及综合以上三种算法预测结果的Voting异质集成分类算法构建肝硬化并发肝性脑病的风险预测模型。结果 logistic回归筛选了7个风险预报因子,采用重采样技术后的分类模型的预测性能整体上优于不平衡数据模型,以SVM-SMOTE最优;相同重采样技术后的Voting异质集成与随机森林分类模型的预测性能优于SVM和MLP,其中Voting异质集成分类模型的性能略高于随机森林。综合各模型性能可知,采用SVM-SMOTE重采样技术处理的Voting异质集成模型在识别肝硬化并发肝性脑病的效果最好,测试集各评价指标值分别为:AUC=0.947、准确率=0.877、精确度=0.898、召回率=0.855、F1分数=0.876。结论 针对肝硬化并发肝性脑病风险预测因素的高维性、冗余性及类间不均衡的特征,本文所提出的基于logistic逐步回归特征筛选、SVM-SMOTE重采样的Voting异质集成模型的预测效果较为满意。
肝性脑病(hepatic encephalopathy,HE)是一组以代谢紊乱为基础的中枢神经系统功能失调的综合病征,是肝硬化患者常见的并发症及死因之一[1],HE1年存活率<0.5,3年存活率<0.3[2]。因此,建立合理的HE风险预测模型,辅助临床医生对HE进行早期预警并及时采取有效的预防措施有着重要的临床意义。
国外研究表明肝硬化并发HE的发生率为30%~45%[3-5],我国从10%到50%不等[1]。目前,我们收集到数据中HE发生率较低,为7.2%,属于类间不平衡的问题.另外,与HE发生相关的因素较多,具有高维性和信息冗余性等特征。传统的风险预测模型常常使用某一种分类算法建模,忽略了类间样本量相差悬殊或者变量冗余的问题,导致风险预测性能明显下降。
目前,重采样中的SMOTE(synthetic over-sampling techniques for small samples)算法[6]是处理不均衡数据较好的方法,但其在新样本合成过程中,具有一定的盲目性,近年来更多的方法是关注最优化决策函数边界的一些少数类样本,如Borderline1-SMOTE、Borderline2-SMOTE 和SVM-SMOTE。本研究尝试对比不同的重采样方法,并比较他们在解决HE不均衡数据中的应用效果。
在分类算法上,多层感知器(multilayer perceptron,MLP)[7]因其具有较好的自学习和建模能力,以及较强的鲁棒性而被广泛应用;而支持向量机(support vector machines,SVM)[8]在解决小样本、非线性及高维模式识别问题中表现出特有的优势;随机森林(random forest)[9]通过收集多棵决策树的结果来降低模型总体方差,是一个相对稳健的分类算法。但是不同的分类算法的适用范围有一定差异、泛化能力有限。
本研究针对HE风险预报因子存在的高维特征空间、高度特征冗余以及类间不平衡问题,首先采用logistic逐步回归模型筛选出与HE发生相对较密切的特征变量,以减少信息冗余;之后采用SMOTE及其改进的(Borderline-SMOTE、SVM-SMOTE)类平衡处理算法,对原数据进行重采样,以消除类间不平衡;最后以Voting投票聚类的方式,将多层感知器MLP[7]、支持向量机SVM[8]、随机森林[9]分类算法进行异质集成,构建组合模型,以提高模型的分类预测性能。同时探讨不同的重采样技术及Voting异质集成对模型性能的影响,为肝硬化并发肝性脑病的风险预测提供更合理的建模方法,为HE的早期干预提供辅助决策。
资料与方法
本研究数据来源于2006年1月-2015年12月山西医科大学第一附属医院消化内科具有完整病历资料且被诊断为肝硬化的住院患者,各生化指标以入院后24小时内的第一次检测结果为准。经整理,有效病例950例,并发肝性脑病者68例,HE发生率为7.2%,属高度不平衡数据。同时收集了肝硬化患者的人口学信息、临床表现及生化等15个可能与HE相关的指标,具体变量名称及赋值见表1。利用Epidata建立数据库,采用双录入方式,逐一核对。
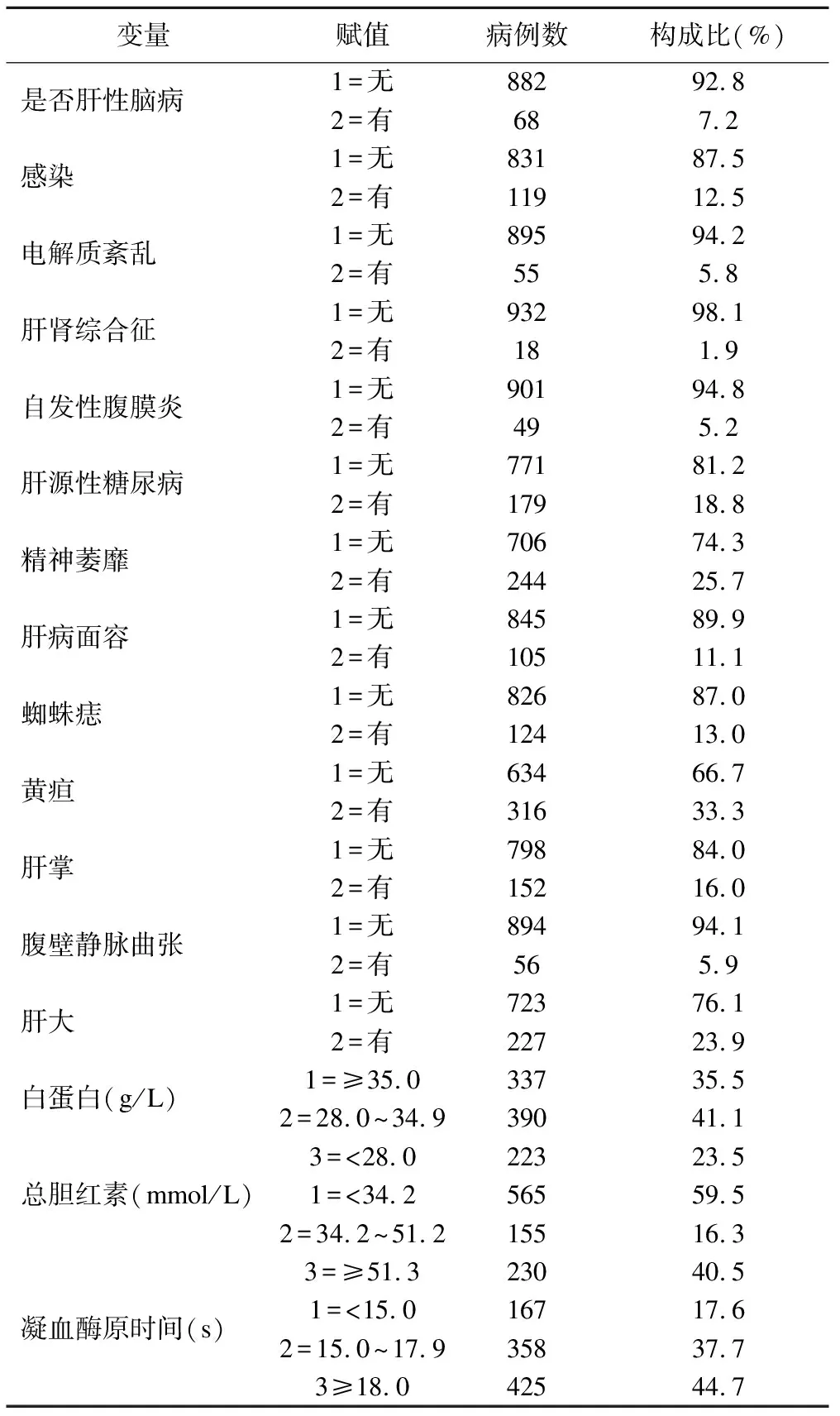
表1 950例肝硬化患者基本特征及赋值
原理及方法
1.特征筛选
本文收集了肝硬化患者15个可能与HE发生相关的指标,采用逐步logistic回归模型进行变量初筛,排除与结局不相关的变量,增加数据的信噪比,以提升下一步所构建的分类模型的泛化能力。适当放宽纳入、排除标准,对变量进行合理选择,采用SPSS 22.0 软件实现。
2.重采样技术
SMOTE算法是通过增加随机噪声的方式来改善过拟合的问题,在原始数据上通过算法根据每个少数类样本来生成新样本,以实现数据集的扩展[10]。Borderline1-SMOTE、Borderline2-SMOTE和SVM-SMOTE方法更多关注最优化决策函数边界的一些少数类样本,而后在最近邻类的相反方向生成样本:①Borderline-SMOTE[11]方法的思想是首先依据一定规则把少数类样本划分为安全样本、边界样本和噪声样本3类,只针对边界样本进行近邻线性插值,使得合成后的少数类样本分布更为合理,Borderline1与Borderline2的区别在于选取最近邻中的随机样本时Borderline1中必须与该少数类样本来自于不同的类;Borderline2可以属于任何一个类;②SVM-SMOTE[12]则是直接使用支持向量机产生支持向量,针对产生的支持向量来生成新的少数类样本。采用Python软件Imblearn package包中SMOTE、Borderline SMOTE和SVMSMOTE语句实现重采样。
3.支持向量机
支持向量机通过核函数将数据点映射到高维空间(Hilbert 空间),使线性不可分数据变为线性可分。并在特征空间中建立最大间距最优分离超平面,使最优超平面与两类样本间距离最大[13-14],其中结构风险最小化思想使学习器经验风险与泛化误差均较小。采用Python软件sklearn.svm学习库中的SVC语句,其中kernel 选项设定为rbf,即为高斯核。
4.MLP多层感知器
多层感知器[15]是一种前向结构的人工神经网络,包含输入层、输出层和多个输入与输出之间的隐藏层,映射一组输入向量到一组输出向量。可以被看作是一个有向图,由多个节点层所组成,在每一层接收输入之后全都连接到下一层形成全连接。除了输入节点,每个节点都是一个带有非线性激活函数的神经元[16]。采用Python软件sklearn.neural_network学习库中的MLPClassifier来进行模型构建,其中max_iter选项设定为500,即迭代次数为500。
5.集成学习
集成学习又被叫做基于团体的学习(committee-based learning),团体中的学习器被称为个体学习器。根据个体学习器的种类,可分为同质集成和异质集成。它能够从多样化的模型中平衡噪音,从而强化模型的泛化能力。随机森林[17]原理是在总的训练样本中随机有放回地抽取训练集,从所有样本特征中随机不放回地选择部分样本特征进行训练及测试,形成多个决策树,每个决策树分别得出相应的预测结果,综合考虑各个决策树的投票结果,以少数服从多数的原则,来判定待测样本的类别,属于同质集成。软投票法的Voting[18]算法是通过对本文涉及到的三种分类算法的对比,获得三种算法的分类结果后,以每个个体分类器测试结果的正确率作为权重,对每个类进行加权平均,返回一组概率的加权平均值,最后取得分最高的类别作为分类结果,该方法综合考虑前文提及的三种分类算法预测结果,属于异质集成。采用Python软件的sklearn.ensemble学习库中的分类算法语句实现集成学习的模型构建。
6.评价指标
模型预测性能评价指标为AUC、准确度(accuracy)、精确度(precision)、召回率(recall)、F1分数,均为越大越好。但在类别不平衡时,会出现模型预测准确度高而阳性类预测能力不足的现象。由于本文重点考虑分类模型对肝硬化并发HE的预测性能,故以精确度、召回率及二者的调和平均数F1-分数作为主要评价指标。
结 果
1.logistic回归变量初选
以7∶3比例将数据分为训练集和测试集,在训练集中,将与肝性脑病有关系的15个因素进行多因素logistic逐步回归分析,变量选入和剔除标准分别为0.1和0.15。
结果显示电解质紊乱、肝肾综合征、感染、精神萎靡、肝源性糖尿病、凝血酶原时间延长及总胆红素升高7个因素最终进入回归模型;其中,电解质紊乱与肝硬化并发HE的关系最密切,电解质紊乱的肝硬化患者并发HE的风险提高了5.836倍;其次是肝肾综合征,并发HE的风险提高了3.375倍;感染、精神萎靡、肝源性糖尿病、凝血酶原时间延长、总胆红素升高并发HE的风险基本上提高了1.5倍左右,分别是1.726倍、1.373倍、1.443倍、1.043倍、1.021倍,见表2。
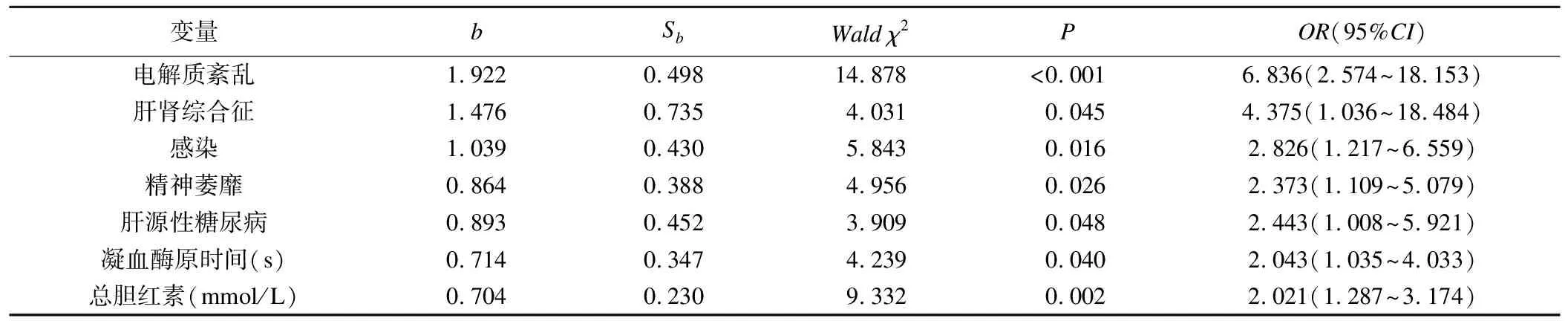
表2 肝硬化并发肝性脑病多因素logistic回归分析
2.多种重采样技术下的各分类模型性能比较
将logistic回归结果中筛选出的7个变量作为特征变量,并发HE作为结局变量,采用训练集训练模型,并在训练集中以十折交叉验证的方式进行内部验证,最后以测试集来进行外部验证,采用表3中的5个指标评价模型的预测性能。本文采用5种重采样方法对原数据进行重采样处理,包括:(1)未重采样的不平衡数据,(2)经过SMOTE重采样,(3)Borderline2-SMOTE重采样,(4)Borderline1-SMOTE重采样,(5)SVM-SMOTE重采样;之后分别构建4种分类算法的模型,包括MLP、SVM、随机森林模型和Voting异质集成模型。
为了评估模型的稳健性,避免出现局部极值的现象,采用十折交叉验证法对模型进行内部验证,结果显示:不进行重采样、直接利用包含7个变量的数据库建立的4种分类模型,虽然AUC和准确度不低,但对于肝硬化并发HE的预测能力却较低,而采用了重采样技术后的分类模型对肝硬化并发HE的预测能力有了明显的提升,且SMOTE改进算法的各项指标均高于SMOTE本身,其中SVM-SMOTE重采样后分类模型的预测性能最优,其次为Borderline1-SMOTE和Borderline2-SMOTE。相同采样技术下,总的来说Voting异质集成模型与随机森林的5项评价指标较SVM和MLP分类模型要高,而且Voting异质集成模型的效果略好于随机森林模型。结合重采样技术,SVM-SMOTE重采样后构建Voting异质集成分类模型预测性能最好,10次交叉验证各评价指标均值分别为AUC=0.952、准确率=0.884、精确度=0.900、召回率=0.863、F1分数0.881。SVM-SMOTE重采样后构建随机森林模型也较为满意,其性能略低于Voting异质集成模型,AUC为0.950、准确率0.882、精确度0.898、召回率0.861、F1分数0.878,且重采样后不同分类模型预测值的标准差减小,说明模型的预测结果具有稳健性。详见表3。

表3 十折交叉验证预测结果
为了保证模型的泛化能力,本文进一步用测试集来对各模型进行外部验证,研究结果与训练集十折交叉验证的整体结论基本一致,经重采样技术处理后的分类模型对肝硬化并发HE的预测能力有所提升。SVM-SMOTE重采样后构建的Voting异质集成分类模型得到最优的预测性能,测试集各评价指标值分别为:AUC=0.947、准确率=0.877、精确度=0.898、召回率=0.855、F1分数=0.876。详见表4。

表4 肝硬化并发HE的模型预测结果
讨 论
对于高维度、高冗余、类间非均衡的医学数据建模,传统统计学方法在预测性能上受限。本文探索了经logistic逐步回归特征筛选和多种重采样技术处理后的不同分类算法在肝硬化并发HE中的应用研究,讨论了四种重采样数据处理下的四种分类模型的预测性能。
研究结果显示,经不同重采样技术处理后所构建的分类模型性能整体上都得到提升,尤其是精确度、召回率、F1-分数三类指标值,与未平衡数据所构模型相比得到明显提高,这意味着更多的肝硬化并发HE的样本得到了正确的分类,与文献[19]的研究结果一致。而且,两种SMOTE 改进算法相较于SMOTE均得到了一定提升。SMOTE算法在新样本合成过程中,具有一定的盲目性,不能对新合成样本数量进行精确控制,也不能对少数类样本进行区别性的选择,而其改进算法更多关注最优化决策函数边界的一些少数类样本,能够弥补SMOTE算法存在的一些不足。经比较分析,SVM-SMOTE的算法性能最优,与Hien M.Nguyen等在2011年[12]关于边界过采样方法在不平衡数据分类中的实验研究结果一致。
在分类算法上,Voting异质集成分类模型与随机森林的预测性能优于传统单一分类器模型SVM和MLP,因为集成分类模型能够从多样化的模型中平衡噪音,强化模型的泛化能力,因此有更好的预测结果,在很多集成模型的应用研究中都得以验证[9,20-21];而Voting异质集成分类模型的性能略高于随机森林,因为Voting异质集成综合考虑了所有基分类器(MLP、SVM、random Forest)的预测结果,并以其结果准确率作为权重进行加权平均,理论上应该优于任何一类基分类器的预测性能,与赵培培[18]关于多种分类器在糖尿病检测分类中的应用研究结果一致。单一分类器模型中MLP优于SVM,与2017年陈钦界基于机器学习的智能医疗诊断辅助方法中的研究结果[22]一致。
总之,针对高维度、高冗余、类间非均衡的医学数据,本文提出的通过logistic逐步回归进行特征筛选,采用SVM-SMOTE重采样技术处理的Voting异质集成模型在识别肝硬化并发HE患者方面的效果最好,该模型有助于临床医生对HE进行早期预警并及时采取有效的预防措施。但是本文所收集数据仅为山西某医院住院患者数据,还需收集多中心的数据进行分析;其次本研究的分类模型的超参数采用网格搜索算法寻优,其余均采用软件默认参数,在今后的研究中将着重探索参数寻优方法,以期更好的提高模型性能。
