基于数据依赖图聚类的开源软件静态分析系统
2022-10-12许睿超狄跃斌柴赫求
寿 增, 许睿超, 马 骁, 狄跃斌, 柴赫求, 徐 剑
(1.国网辽宁省电力有限公司,辽宁 沈阳 110003;2.南瑞集团有限公司(国网电力科学研究院有限公司), 江苏 南京 210061;3.北京科东电力控制系统有限责任公司,北京 100192;4.东北大学,辽宁 沈阳 110169)
0 引 言
目前,开源软件已经广泛应用到信息技术的各个领域。Gartner公司的调查报告显示,99%的组织在其IT系统中使用了开源软件,来自Sonatype公司的调查报告显示,在参与调查的3 000家企业中,每年每家企业平均下载5 000个开源软件。Github报告指出,超过360万个开源项目依赖Top50的开源项目。同时,开源项目平均有180个第三方依赖组件,具体的依赖组件数量从几个到上千个不等[1]。
然而,开源软件带来巨大便利的同时,也带来了极大的安全挑战。Snyk公司通过扫描数以百万计的Github代码库和对超过500个开源项目的维护者进行调查发现:只有8%的开源项目维护者认为自己拥有较高的信息安全技术水平,接近半数的开源项目维护者从不审计自己所写的代码,只有11%的维护者能做到每季度审核代码。另据Linux基金会发布的《开源软件供应链安全报告》显示,大量开发人员在开发软件时并未遵守应用程序安全最佳实践。
开源软件作为软件生态中的重要组成部分,其安全性一直是工业界和学术界研究的重点和热点。近年来,诸多开源软件频频曝出高危漏洞,包括Jenkins、JBoss、Apache Tomcat、Docker、Kubernetes、Strusts2、OpenSSL、Jackson等。这些组件很多都应用于信息系统的底层,并且应用范围非常广泛,因此漏洞带来的安全危害极其严重。国家互联网应急响应中心的年度报告也显示,开源项目依赖组件漏洞数量逐年增长,2019年组件漏洞数量较2018年环比增长72.99%[2]。面对日益严峻的开源软件安全问题,越来越多的软件研发人员意识到了开源软件的安全与否极大地决定了整个信息系统是否安全。
软件静态分析是指在不执行代码的情况下,通过词法分析、语法分析、控制流、数据流分析等技术对程序代码进行扫描,验证代码是否满足规范性、安全性、可靠性、可维护性等指标的代码分析技术。软件静态分析可以帮助软件开发人员、质量保证人员查找代码中存在的设计性错误、代码编写错误、代码编写不规范以及安全漏洞等问题,从而保证软件的质量和安全。显然,对开源软件进行静态分析可以彻底而一致的检查开源软件的代码,并可以及时地发现安全漏洞根源。因此,设计并实现一个高效的开源软件静态分析系统是非常必要和迫切的。
1 相关工作
静态分析和动态分析是代码审计的重要方法。
静态分析是在不运行代码的情况下,直接分析源代码,常用的技术有基于正则表达式的关键字匹配、基于AST的模式匹配[3]、数据流分析[4]、抽象解释[5]等。这些静态分析技术各有优缺点,基于正则表达式的关键字匹配和基于AST的模式匹配局限于关键字和模式的限制,不仅维护成本大,而且漏报率和误报率也很高;数据流分析是最常用的静态分析技术,文献[5]是基于静态分析技术的商业源代码审计工具的典型产品,它的检测效果优于其他的基于静态分析技术的产品,但是这类工具在面对大型开源项目时,其性能表现并不理想。
动态分析是在代码运行过程中发现漏洞,常见技术有污点追踪[6]、符号执行[7]等。符号执行是动态分析的代表性技术。然而,在早期,由于计算能力的限制,符号执行技术只被应用于程序自动测试。近年来,随着计算能力的提高,符号执行技术得以取得长足的进步,出现了动态符号执行技术。动态符号执行实际运行被分析的程序, 在实际运行的同时收集运行路径上的路径条件, 然后翻转路径条件得到新的路径条件,通过对新的路径条件进行求解得到新的程序输入以再一次地运行被分析程序, 从而探索与之前运行不同的程序路径[8]。动态分析技术对环境依赖高,不能保证源代码的覆盖率,且有可能产生路径爆炸等问题。
随着人工智能技术的发展,机器学习、深度学习被应用于代码审计中。文献[9]应用双向LSTM模型,从易受攻击的代码段中学习模式,然而这类方法的主要缺点是需要花费大量的精力来收集、清洗和标记大量的训练样本。文献[10]提出了一种帮助安全分析人员进行源代码审计的方法。它可以通过检查一小部分代码来识别漏洞。文献[11]指出不同的开发人员在实现相似的功能时,代码具有相似性,因此,可以通过代码不一致性检测来发现软件中的异常行为,进而找出软件中的漏洞。然而,文献[11]中的方法往往只针对某一类具体的漏洞,不具备漏洞检测的通用性。文献[12-13]提出了检测代码中语法不一致的通用技术。这些工作依赖于抽象语法树来查找不一致的代码。然而抽象语法树不具备语义感知功能,无法在更深层次上检测代码间的不一致性,因此能检验出的漏洞种类有限。
2 系统设计与实现
2.1 系统设计
基于代码不一致性检测思想,利用数据依赖图,并结合图神经网络聚类,本文设计了开源软件的静态分析系统,该系统主要面向由C语言编写的开源软件。但是,其设计思想同样适用于其他语言编写的开源软件系统。系统业务流程如图1所示。
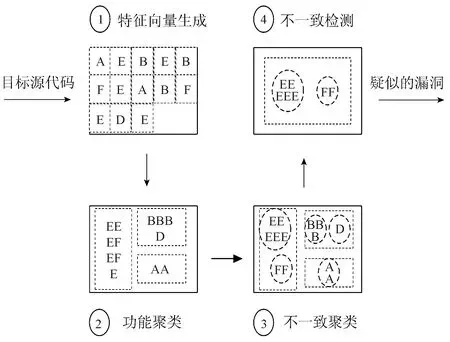
图1 系统业务流程
系统的业务流程主要包括特征向量生成、功能聚类、不一致聚类以及不一致检测。
(1)特征向量生成
首先,将目标开源软件使用LLVM编译,得到字节码;然后,使用过程内数据流分析技术从每个函数中提取代表函数内的基本操作或运算的程序依赖图。针对数据依赖图进行抽象,去掉控制依赖边,仅保留数据依赖边,得到数据依赖图。
(2)功能聚类
针对生成的数据依赖图,使用图神经网络进行聚类,得到具有相似结构的图,即代码中功能相似的部分。
(3)不一致聚类
对具有相似结构的图进行进一步聚类,得到相似结构中不一致的部分,即代码中功能相似但实现不一致的部分。
(4)不一致检测
并不是所有的不一致结果都是漏洞,因此,基于相关规则对聚类的结果进行过滤,得到疑似的漏洞。
系统的检测流程如图2所示。
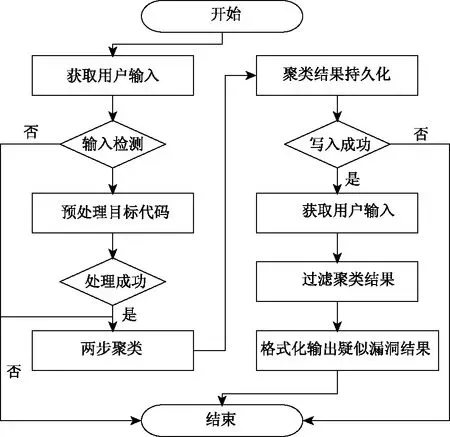
图2 系统检测流程
基于系统业务流程,系统所设计的功能包括:输入处理、源代码预处理、聚类与持久化、漏洞检测与格式化输出。其中输入处理包括输入检测模块;源代码预处理包括预编译模块、程序依赖图生成模块、数据依赖图生成模块;聚类与持久化包括功能聚类模块、不一致聚类模块、持久化模块;漏洞检测与输出部分包括漏洞检测与输出模块。
1)输入处理模块:负责从用户的输入获取参数,并检测是否合法,如果参数合法则调用系统其他模块,实现对应的功能。
2)预编译模块:主要负责将目标开源代码转换成便于使用机器学习方法进行分析的数据结构,该部分使用Clang将源代码编译成LLVM格式的中间代码。
3)程序依赖图生成模块:使用文献[14]中的工具将LLVM格式的中间代码转换成程序依赖图。
4)数据依赖图生成模块:对程序依赖图进行抽象,将其转换成数据依赖图。
5)功能聚类模块:将数据依赖图转换成特征向量,并通过聚类算法得到功能相似的数据依赖图。
6)不一致聚类模块:将功能相似的数据依赖图通过聚类算法得到实现不一致的部分。
7)持久化模块:将聚类的结果存入数据库中。
8)漏洞检测与输出模块:将系统聚类检测的结果从数据库中取出,进行过滤,找到其中包含的漏洞,并且将疑似的漏洞格式化输出。
2.2 系统实现
(1)特征向量生成
用户指定参数,判断参数是否合法,如果用户输入合法,进行后续的系统功能调用,如果不合法,提示用户需要输入的参数并退出。通过用户的输入获取目标程序源代码文件夹。调用Clang前端将目标源码从高层源码转换成底层的LLVM的中间代码。示例程序以及其生成的LLVM中间代码如图3所示。

图3 LLVM中间代码
系统生成LLVM中间代码之后,调用开源工具,将LLVM中间代码转换成程序依赖图。程序依赖图是一种包含大量的语义信息的程序表示方法,因此更适合以此为基础再进行特征向量的提取,进行后续的功能相似性聚类。
如果仅仅使用程序依赖图进行后续的聚类,由于程序依赖图包含的语义信息过多,聚类的效率会比较低。对程序依赖图进行简化,可以得到抽象的数据依赖图。示例程序的数据依赖图如图4所示。
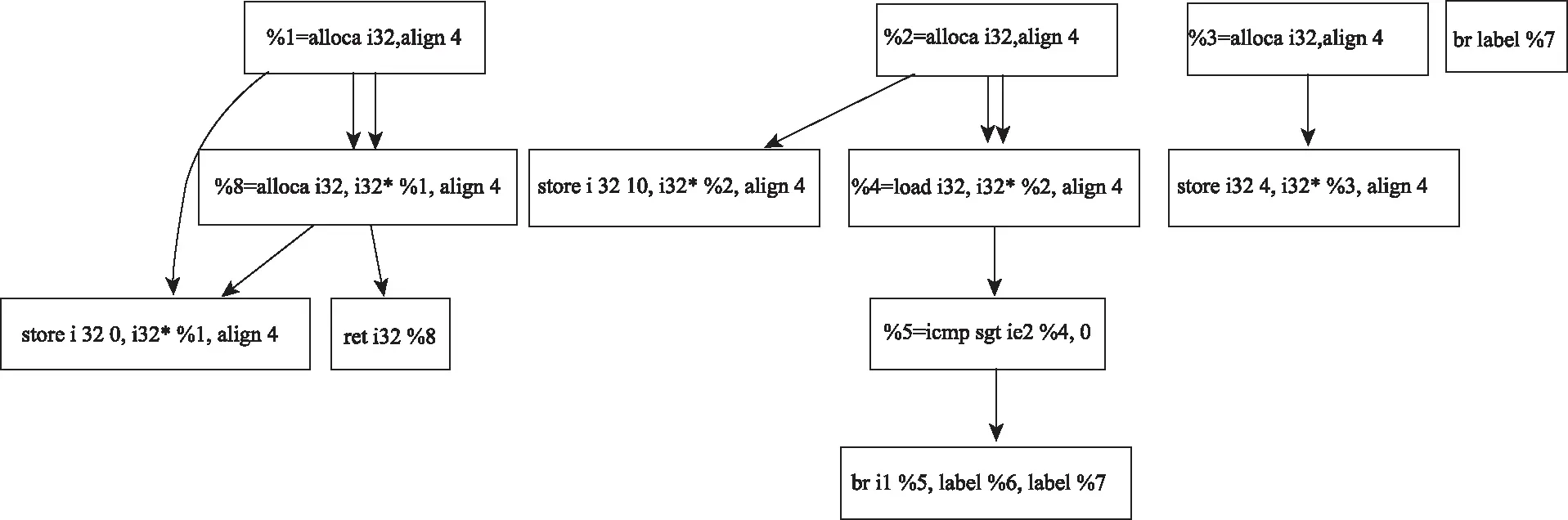
图4 数据依赖图示例
(2)功能聚类
功能聚类模块对抽象的数据依赖图进行聚类,得到相似的图结构,即代码中相似的功能,如图5所示。

图5 功能聚类
经过功能聚类模块的处理,可以得到结构相似的数据依赖图,为后续的不一致聚类做准备
(3)不一致聚类
不一致聚类模块进行更精细的聚类,得到结构相似的数据依赖图中不一致的部分,如图6所示。

图6 不一致聚类
系统使用两步聚类,得到功能相似但实现不一致的代码的数据依赖图,为后续的漏洞检测准备。
(4)不一致检测
系统需要满足用户随时查询漏洞检测结果的需求,所以持久化模块是非常必要的,该模块负责将聚类的结果存入数据库中,方便用户随时获取结果。该模块将查询的结果采用类似JSON的形式进行存储。
用户需要获取疑似的漏洞,并结合人工确认漏洞是否存在,所以系统需要一个漏洞检测与格式化输出模块负责筛选聚类的结果并将结果输出。因为并不是所有的不一致结果都是漏洞,所以系统在得到两步聚类的结果之后,还需要一些规则来将不一致的结果进行过滤。该模块基于三个规则:如果不一致集群中的所有结构重叠,则忽略;如果一个不一致集群包含超过某一固定数量的偏离节点,则降低优先级;如果不一致聚类的数量超过某一个值,则降低优先级。
3 系统测试
系统测试环境如表1所示。
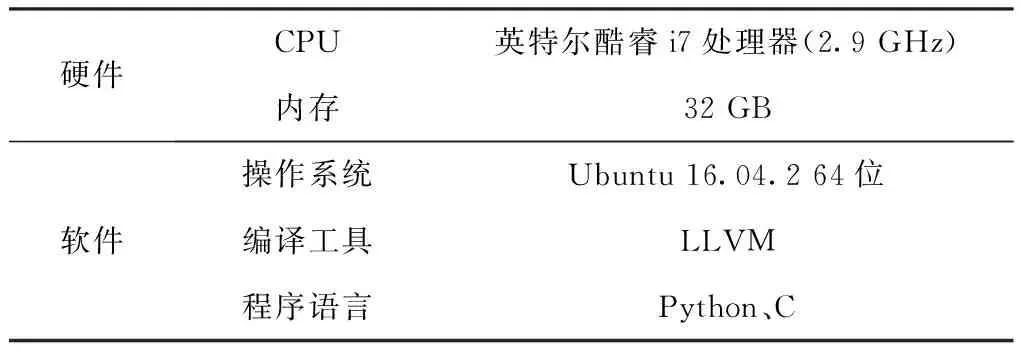
表1 测试环境
本文使用三个不同规模的数据集LibTiff[15]、libmp3lame[16]、bzip2[17]对系统进行功能测试和性能测试。
在功能测试中统计了系统生成的DDG数量、聚类的结果数、疑似漏洞数以及经过人工验证后确认的漏洞数,来验证系统的有效性。系统功能测试结果如表2所示。
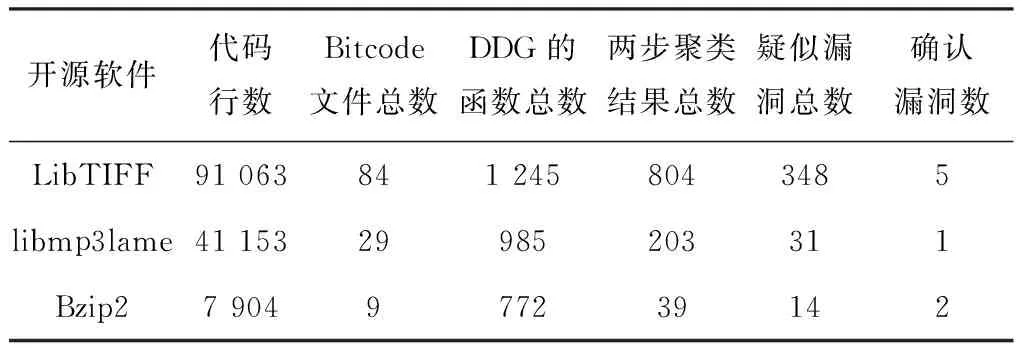
表2 系统功能测试结果
在性能测试中,重点测试了代码分析时间,如表3所示。
由表2和表3获得的结果可知,系统可以在可接受的时间范围内给出了疑似的漏洞,并辅以少量人工分析,则可以得到较好的漏洞发挖掘结果。

表3 系统性能测试结果
4 结 语
在现有开源软件静态分析技术基础上,设计了一个基于数据依赖图聚类的开源软件静态分析系统。与其他基于机器学习的软件静态分析系统不同,本系统并不需要外部数据集,仅从开源软件自身的代码就可以进行学习,并检测其代码实现的不一致性;利用这些不一致性,并辅助少量的人工分析,就可以发现其中的安全漏洞。因此,该系统在开源软件静态分析方面具有一定的应用价值。
