基于相似日匹配及TCN-Attention的短期光伏出力预测
2022-10-11陈禹帆温蜜张凯余珊
陈禹帆,温蜜,张凯,余珊
(上海电力大学 计算机科学与技术学院,上海 200090)
0 引 言
近年来,中国光伏发电规模持续扩大。2019年全国光伏发电累计装机达到20 430万千瓦,全国光伏发电量达2 243亿千瓦时[1]。随着大规模光伏并网发电在电网中占比的不断增加,光伏出力固有的随机波动特性给电力系统的安全稳定运行和电能质量带来严重挑战[2-3]。目前,中国、美国和欧洲都在大力推进大规模光伏并网,短期光伏出力预测成为了电网调度和光伏市场主体的关注重点[4]。
目前,短期光伏出力预测方法主要分为三类:物理方法、统计方法和机器学习方法。物理方法是指直接构建光伏发电近似物理模型[5]得到光伏出力,该方法依赖详细的电站地理信息和准确的数值天气预报(Numerical Weather Prediction,NWP)数据,所采用的物理公式本身存在一定的误差,导致模型的抗干扰能力差、鲁棒性低。统计方法主要采用时间序列[6]、序列分解[7]等方法对大量历史数据进行统计和建模预测,该方法未能考虑到气象因素对光伏出力的影响,预测精度通常不高。机器学习方法主要有支持向量机[8]和神经网络[9]等,可以直接从气象、光伏出力历史数据和NWP数据中挖掘出变化规律进行预测,是目前光伏出力预测的主要方法和研究热点。
随着深度学习的快速发展[10],基于深度学习的短期光伏出力预测方法目前受到广泛关注[11]。其中,基于长短期记忆网络(Long Short-Term Memory,LSTM)的模型可以有效捕捉时间序列的长期依赖关系,在短期光伏出力预测上取得良好效果[12-13],成为了深度学习中的主流预测模型。然而,该方法存在梯度问题和模型训练时间较长的问题。卷积神经网络可并行计算的结构优势可以有效避免上述问题。其中,时序卷积网络(Temporal Convolutional Network,TCN)已经在风电功率预测[14],太阳辐射预测[15]等领域表现出了较好的预测效果。
光伏出力在典型天气类型中表现出明显的相似性。相似日模型[16]被提出和广泛应用来解决数据冗余带来的误差。文献[17]提出一种晴朗系数将历史数据划分为晴天和非晴天两种类型,通过多层次相似匹配方法选取相似日构建ARIMA时间序列预测模型。文献[18]采用模糊C均值聚类算法将预测日按照6种特征进行划分,然后构建深度信念网络模型进行预测。上述相似日模型通过主观筛选特征进行分类,将气象数据分为几类建立模型。但是此类方法对于天气类型的划分没有考虑到天气的动态变化,仅由某些时刻的天气特征难以捕捉整日光伏出力的相似性。
针对上述文献中存在的问题,为了提高光伏出力预测精度和模型的训练速度,文章提出一种基于相似日匹配及TCN-Attention的短期光伏出力预测方法。首先,采用K-Shape聚类算法对光伏出力历史数据进行基于形态特征的聚类,在考虑整日光伏出力曲线形状的情况下将训练集划分成不同天气类型下的相似日训练子集。然后,使用最大信息系数(Maximal Information Coefficient,MIC)根据待预测日的NWP数据为待预测日匹配合适的相似日训练子集。最后,以历史相似日数据和待预测日NWP数据作为共同输入,采用可并行计算的TCN网络进行建模学习,并引入Attention机制为隐藏层中不同特征设置不同的权重,以加强关键特征对光伏出力的影响,从而得到更好的预测效果。最后,通过基于真实数据集的实验验证了文章所提出的方法具有更高的预测精度和更快的计算速度。
1 基于形态特征和气象相关性的相似日匹配
光伏出力受到太阳辐射、温度、湿度等诸多气象特征的影响具有很大的时变性和不确定性。各种气象特征在不同的天气类型中对光伏出力影响的程度并不相同,合理的相似日匹配有助于突出关键特征,从而使模型训练更具有针对性[19],有效提高预测精度。文中采用K-Shape聚类算法与MIC相结合的方式进行相似日匹配。
1.1 光伏出力形态特征分析
文中以全球能源预测竞赛提供的国外某地区光伏电站数据集为研究对象[20]。该数据集记录了从2013年1月1日到2013年12月31日的光伏出力数据和温度、湿度、风速、总云量、太阳辐射等NWP数据,时间间隔为1 h。
受到日地运动和天气动态变化的影响,光伏出力整体上表现出显著的间歇性和波动性。其中,间歇性主要是受到地球自转的影响,地球的自转造成了昼夜交替现象,导致夜间的光伏出力为零,日间的光伏出力呈抛物线趋势。光伏出力的波动性则是由天气动态变化的相对不确定性造成的,如环境温度会影响光伏组件温度,云层会影响光伏面板受到的太阳辐射等。
图1描绘了典型天气类型中的光伏出力曲线各十条。其中,晴天光伏出力曲线较为平滑,呈半波型;多云天的光伏出力曲线在体量上与晴天相似,但是云层遮挡会造成一定的随机波动;阴天光伏出力体量明显减少,并伴有随机波动;雨天光伏出力体量较小,并可能伴有大幅度随机波动。可以看出,光伏出力曲线在不同天气类型中存在较大差异,在相同天气类型中具有相似性。
1.2 基于形态特征的历史相似日聚类
K-Shape算法在整体设计上有聚类中心的计算过程和簇迭代的过程。该方法使用一种新的时间序列形态距离度量方案(Shape-Based Distance,SBD)来描述聚类中的距离。该方法的距离度量不受时间尺度缩放和位移的影响[21],从而能够有效地聚类出相似的光伏出力序列。

图1 典型天气类型中光伏出力曲线
对于两条光伏出力序列X=[x1,x2,...,xm]与Y=[y1,y2,...,ym],K-Shape算法的距离为:
(1)
式中Cω(X,Y)是光伏出力序列X和Y的互相关序列;R0为两光伏出力序列不发生相对位移时其对应的互相关系数值。
K-Shape迭代的过程是不断地求取聚类中心并依据到聚类中心的距离为光伏出力历史日序列进行簇划分的过程。K-Shape算法将聚类中心的计算转化为一个优化问题,是使聚类中心与该簇中每一条光伏出力序列之间的DSBD取得最小值,如式(2)所示:
(2)
式中Pk为第k类簇;ui为Pk中的第i条光伏出力序列;ck为该方法所提取的聚类中心。
K-Shape算法的整体计算步骤如表1所示。K-Shape聚类算法可以使光伏出力历史日数据基于整日形态特征的差异划分为多个相似日簇,各簇之间光伏出力具有较大差异,簇内光伏出力较为相似。针对特定的相似日簇建立模型进行特征学习,可以使预测模型的训练更具有针对性。
1.3 MIC匹配相似日训练子集
MIC是一种新型的相关性度量方法。相较于pearson系数等传统统计学方法,该方法能较好地反映数据中的非线性相关性强度且具有较好的鲁棒性[22]。根据MIC的基本原理,对于待预测日某一气象特征序列S=[s1,s2,…,sn]与历史日该气象特征序列T=[t1,t2,…,tn]组成的一个二元数据集D∈R2,将其划分为x列y行的网格G,则数据之间的相关性可以体现在网格内数据的分布上,其互信息值为:
(3)
式中p(s,t)为S和T的联合概率密度;p(s)和p(t)分别为S和T的边缘概率密度。

表1 K-Shape算法流程
由于网格G的划分有多种方案,则互信息值MI(D,x,y)有多种取值。取其中的最大值作为网格划分G的最大互信息值:
I(D,x,y)=maxMI(D,x,y)
(4)
将求得的最大互信息值归一化,并求得最大信息系数如下:
(5)
式中B是一个关于样本规模n的函数,通常情况下B=n0.6,分母log2(min(x,y))为归一化操作。MIC的取值范围是[0,1],MIC越大表明该待预测日气象特征与历史日气象特征的相关性越强;反之,则越弱。
通过MIC将K-Shape聚类得到的历史相似日簇与待预测日进行基于气象相似性的匹配,避免历史日与待预测日气象差异过大引起的误差。采用MIC匹配历史相似日簇训练子集具体过程为:
(1)定义待预测日n种NWP气象特征序列(如温度序列、湿度序列等)组成的矩阵为A=[a1,a2,…,an],其中向量at(t∈[1,n])为该日第t种气象序列。定义聚类中心对应气象特征序列组成的矩阵为B=[b1,b2,…,bn],其中向量bt(t∈[1,n])为该聚类中心所在簇中所有历史日第t种气象序列的均值序列;
(2)通过MIC计算待预测日与聚类中心相应气象特征的相关性得到相关性向量M=[m1,m2,…,mn],其中mt=MIC(at,bt),t∈ [1,n];
(3)根据相关性向量求得待预测日与聚类中心的综合气象相似度Z如式(6)。选择综合气象相似度最大的聚类中心所在历史相似日簇作为该待预测日的训练子集。
(6)
2 基于相似日匹配及TCN-Attention的预测模型
2.1 TCN卷积结构
时序卷积网络是一种序列建模结构,融合了一维全卷积网络、因果卷积和扩张卷积,有效地避免了循环神经网络面临的梯度消失或者梯度爆炸问题,具有并行计算、低内存消耗、通过改变感受野来控制序列记忆长短等优势。
TCN卷积结构如图2所示。与传统卷积不同的是,TCN卷积结构允许卷积时的输入存在间隔采样,采样率为图2中的d。最下面一层的d=1,表示输入时每个点都采样,中间层d=2,表示输入时每2个点采样一个作为输入。由此可见,越高的层级使用的d的大小越大。所以,TCN卷积结构中有效窗口的大小随着层数呈指数型增长。因此,时序卷积网络用比较少的层,就可以获得很大的感受野。
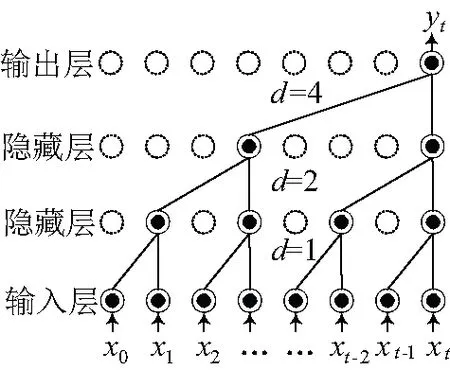
图2 TCN卷积层结构示意图
由TCN卷积结构可知,该网络的记忆长度,即每个神经元的特征学习范围,与核大小、扩张系数、模型深度均有关。设输入的序列为x,模型设置的一系列卷积核为f:{0,…,k-1},则经过扩张卷积计算后第s个神经元输出值的表达式为:
(7)
式中k为卷积核尺寸;d为扩张系数;“*”为卷积运算;f(i)为卷积核中的第i个元素;xs-d·i为与卷积核中元素对应相乘的序列元素。
2.2 Attention机制
Attention机制是对人脑分配注意力形式的一种模拟,其本质是改变隐藏层中特征的权重[23]。Attention机制能够从大量特征中合理地筛选出少量关键特征,并对他们赋予更多的权重,减少非关键特征的权重从而突出关键特征的影响。将Attention机制与TCN进行融合可以更好地突出影响光伏出力的关键特征、提高预测精度。Attention机制结构原理如图3所示。

图3 Attention机制原理示意图
其中,xt(t∈[0,n])表示TCN网络的输入,ht(t∈[0,n])对应于每一个输入通过TCN得到的隐藏层输出,at(t∈[0,n])为Attention机制对TCN隐藏层输出的注意力权重,yt(t∈[0,n])为引入Attention机制的输出值。Attention机制的权重系数计算公式可表示为:
et=utanh(wht+b)
(8)
(9)
(10)
式中et表示第t时刻由TCN网络输出层向量ht所确定的注意力权重;u和w为权重系数;b为偏置系数;yt为Attention层在第t时刻的输出。
2.3 组合预测模型设计
针对短期光伏出力预测问题,文章将前述相似日匹配方法与引入Attention机制的TCN模型相结合,提出一种基于相似日匹配及TCN-Attention的组合预测模型(以下简称KTCNA),模型流程图如图4所示。
在相似日匹配阶段。首先,通过K-Shape聚类算法基于整日光伏出力形态特征将光伏出力历史数据划分为多个相似日簇;然后,采用MIC计算待预测日NWP数据与各个聚类中心NWP数据的相关性,为待预测日匹配训练子集。

图4 KTCNA组合模型流程图
在预测模型阶段,将待预测日对应的训练子集及其NWP数据输入到TCN-Attention预测模块中进行模型训练,再输入待预测日的NWP数据预测出光伏出力预测值。TCN-Attention预测模块如图5所示。

图5 TCN-Attention预测模块
该模块由输入层、TCN残差模块、Attention机制、输出层组成。模块中每层描述如下:
(1)输入层输入历史相似日训练子集及其NWP历史数据进行训练,然后输入待预测日NWP数据进行预测;
(2)TCN残差模块在TCN卷积层的基础上加入了WeightNorm层、激活函数和Dropout层,并在输入经过两层TCN卷积层后增加输入的直接映射。WeightNorm层能有效加快计算速度,Dropout层使神经元随机失活防止模型出现过拟合现象。添加输入的直接映射构建残差连接使模型能够进行更深层次的训练。为了让模型训练充分,文中模型包含了多个TCN残差模块,并通过加入一个1×1卷积,解决残差模块输入输出数据可能具有不同维度的问题;
(3)Attention机制为深层特征自动计算相应的权重分配并与其合并为新的向量。该层输入为TCN的输出向量,Permute层将输入的维度按照给定模式进行重排,Multiply层将Attention的输出与TCN残差模块的输出完成位与位相乘输出,实现了对隐层单元的动态加权过程,从而突出关键特征对光伏出力的影响;
(4)输出层为全连接层,接受来自Attention机制加权处理后的输出向量,将其处理为光伏出力预测值。
由此可见,输入向量从输入层开始,经过多个TCN残差模块处理后进入Attention机制。Attention机制会依据当前输入的向量计算注意力权重向量,并将两者合并得到新的向量,输入到全连接层中输出预测值。
3 算例分析
文章选取全球能源预测竞赛提供的国外某地区光伏电站数据集为研究对象。选取2013年1月1日至2013年12月15日数据为训练集,2013年12月16日至12月31日数据为测试集。文中依据所提KTCNA模型对测试集中的待预测日进行日前预测,即根据NWP数据对未来一天的光伏出力值进行预测。为说明文章所提出的KTCNA组合模型的有效性,文中与TCN、LSTM和无相似日匹配的TCN-Attention(以下简称TCNA)对光伏出力的预测精度进行对比,并按照簇的划分,以均方根误差(Root Mean Square Error,RMSE)和拟合系数(R2)两种指标对TCN、LSTM、TCNA和KTCNA的预测精度进行评价。
3.1 数据预处理及预测评价指标
对原数据集按照4种典型的天气类型进行相似日匹配后得到4个簇,其情况统计如表2所示。
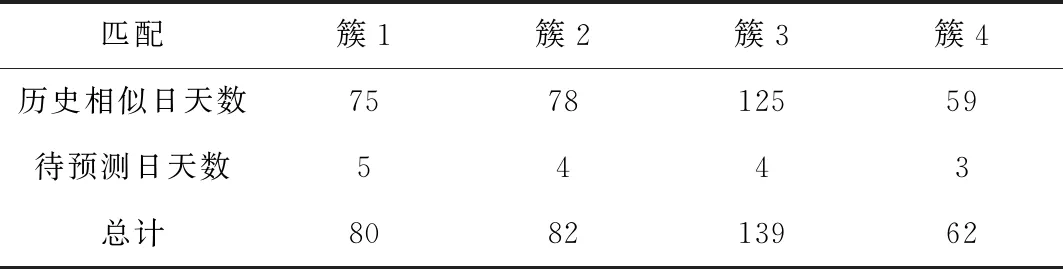
表2 相似日匹配结果统计
为防止各特征量纲不同对模型的训练造成影响,在输入模型前对原始数据进行标准化处理,使其处在(0,1)之间,其计算公式为:
(11)
式中x为各特征原始数据;xmax和xmin为各特征的最大值与最小值;xnormal是标准化处理后的各特征数据。
为验证模型的有效性,采用RMSE和R2对预测效果进行评价,其计算公式分别如下:
(12)
(13)
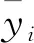
3.2 不同方法定量对比分析
本实验平台硬件配置为处理器是Intel Xeon E5,GPU显卡是Tesla P100的工作站。模型开发基于Python语言。实验中基于TCN的模型在设计上均采用7个残差模块,卷积层的卷积核个数均设置为128个。相对应的,基于LSTM的模型在设计上包含了7个隐藏层,隐藏层的神经元个数均设置为128个。所有模型防止过拟合的dropout率均设定为0.3。由于LSTM无法进行并行计算,其速度较慢,为最大限度提高LSTM计算速度,文中采用TensorFlow框架的GPU加速版开发LSTM模型。详细实验结果如表3所示。

表3 预测误差定量对比
3.2.1 待预测日各簇整体误差对比
图6为表3中的各簇误差指标平均值的可视化展示。在图6(a)中,对于绝对误差RMSE而言,KTCNA的误差在各簇中都是最小的,其效果最好;TCNA与LSTM各具优势,在簇3与簇4中LSTM误差较小,而在簇1与簇2中TCNA误差较小;TCN只在簇2中好于LSTM,在其他簇中的误差都较大。在图6(b)中,从拟合系数R2分析,簇4的拟合程度整体低于其他簇,表明其预测难度较大,其中KTCNA拟合程度明显优于其他方法;簇1的预测难度较小,各方法均能在该簇取得较好的效果。
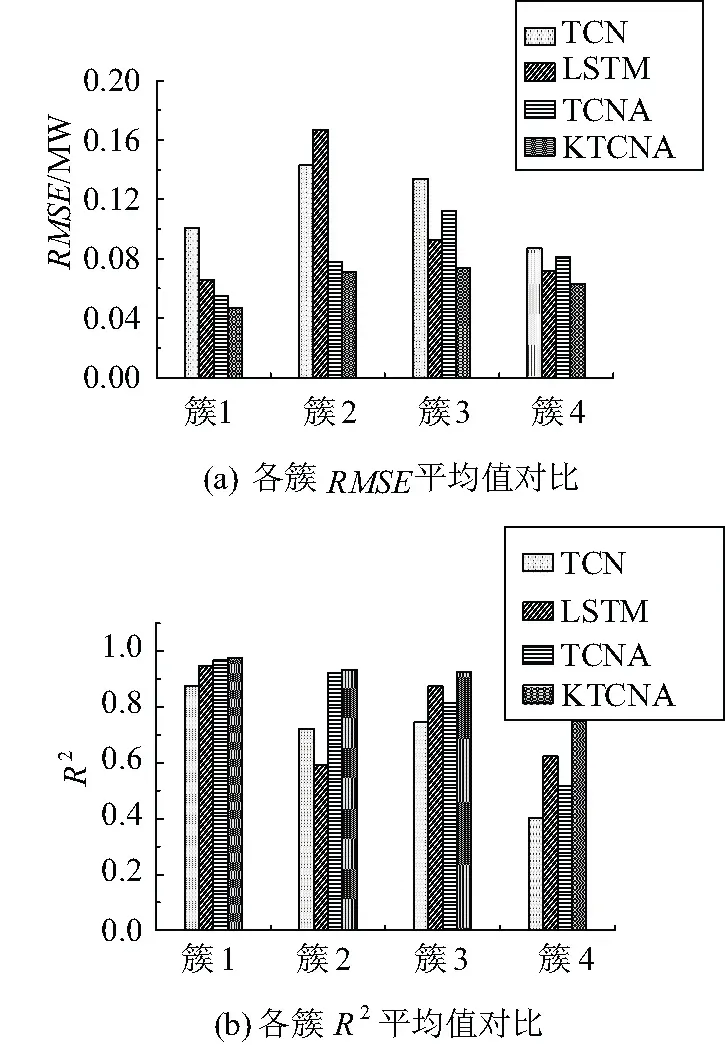
图6 评价指标平均值对比
由此可见,文中所提基于相似日匹配的组合模型KTCNA较之其他模型更具有针对性,在待预测日各簇中均能取得较好效果。
3.2.2 各簇中某待预测日具体光伏出力预测对比
图7中分别为TCN,LSTM,TCNA和KTCNA对簇1中12月19日,簇2中12月18日,簇3中12月16日,簇4中12月23日的光伏出力预测曲线。
如图7(a),在对簇1中12月19日的预测中,在光伏出力较为平稳的情况下,LSTM,TCNA和KTCNA都能相对稳定地进行预测。就拟合程度而言,KTCNA的R2值为0.965,这表明该方法在出力平稳时具有较好的预测效果。
如图7(b),在对簇2中12月18日的预测中,KTCNA在大部分采样点处都能较好地预测出力(RMSE为0.045MW,R2为0.976),但对于14:00处的波动未能预测准确。
如图7(c),在对簇3中12月16日的预测中,光伏出力波动较大。此时TCN的预测效果显著降低,但是由于Attention机制的引入,TCNA和KTCNA的预测效果得到了较大提升。

图7 某日具体光伏出力预测误差对比
如图7(d),在对簇4中12月23日的预测中,光伏出力整体缩减且剧烈波动。但是KTCNA(RMSE为0.054 MW,R2为0.733)能够较好地学习到曲线“双峰”的特征,LSTM(RMSE为0.065 MW,R2为0.615)也能学习到该特征,但是效果较差,TCNA(RMSE为0.077 MW,R2为0.481)和TCN(RMSE为0.086 MW,R2为0.333)不能学习到该特征。
3.2.3 不同方法整体预测效果对比
文中在考虑预测精度的同时,也考虑到了各方法存在的时间成本。由于深度学习方法的时间成本在于模型的训练过程,因此文中通过对各方法训练多次,求取训练时间的平均值来量化模型的时间成本。
表4为所有预测日的RMSE、R2和模型训练时长的平均值。可见,KTCNA的精度是最高的,其RMSE平均值相对于其他方法分别降低了44.83%、35.35%和20.99%,其R2平均值明显高于其他方法。对于模型的平均训练时长来说,LSTM模型训练速度最慢,消耗的时间最长,其次是TCNA和TCN。得益于相似日匹配的效果,数据集复杂度得到有效降低,在不损失精度的前提下提高了模型训练速度,减少了平均训练时长,使得KTCNA精度高、速度快。

表4 不同方法整体对比
4 结束语
文章提出了一种基于相似日匹配的TCN-Attention组合预测方法。采用K-Shape算法和MIC对光伏出力数据进行相似日匹配降低训练集的数据冗余,让模型训练更具有针对性,有效地减少了模型的训练时长。该模型融合了TCN网络与Attention机制,在进行特征学习的同时能够调整不同深层特征的权重,与基于LSTM的方法相比,避免了梯度问题并且可以大规模并行处理数据。此外,从预测效果可知,文章所采用的方法具有精度高、速度快的特点。
文中采用相似日匹配进行预测的思想为光伏出力预测提供了新的研究思路,具有一定的实用性。在文章中,仅用该方法进行了确定性预测,下一步可以考虑将该方法应用于光伏出力概率预测。
