基于GPU并行计算的快速视觉惯性里程计方法*
2022-10-11陈财富
陈财富, 汪 双, 陈 波, 张 华, 王 姮
(1.西南科技大学 信息工程学院,四川 绵阳 621000; 2.西南科技大学 特殊环境机器人四川省重点实验室,四川 绵阳 621010)
0 引 言
港科大开源的VINS-Mono[1]是视觉惯性里程计(visual inertial odometer,VIO)[2]系统,它的前端主要包括均值化预处理[3]限制对比度的自适应性直方图均衡化(CLAHE)、Shi-Tomasi角点特征提取和光流跟踪[4]。虽然VIO系统前端适用性强以及鲁棒性高,但它计算成本较高且计算耗时不稳定,在要求十分苛刻的虚拟现实(VR)/增强现实(AR)和无人机机器人平台上实时运行困难。针对上述系统实时性的问题,考虑尺寸重量大小满足应用要求,本文选用较小的尺寸和重量中央处理器(CPU)-图像处理器(GPU)组合的NVIDIA TX2处理器,TX2不仅在成本上有一定的经济>效益,而且在GPU加速处理非常出色[5,6]。同时本文改进VINS-Mono前端,提出了一种基于GPU并行加速VIO方法,采用FAST特征提取和特征点光流跟踪进行并行加速,以获得更高实时且耗时稳定的VIO前端;并且对文献[7]特征提取查表方式进行了改进,占用更少的内存空间。本文方法还在特征提取之前通过GPU对CLAHE加速,在特征提取后采用非极大值抑制[8],消除周围非极大值元素,使特征点分布相对均匀。最后,采用多层金字塔平均强度反向光流法进行角点跟踪,求解特征点匹配。实验部分,本文将改善后的前端系统与VINS-Mono后端结合,选用EuROC数据集[9],在嵌入式CPU-GPU异构平台TX2上进行了全方面的评估。
1 总体系统设计
本文提出的GPU并行加速VIO前端方法包括图像灰度化、CLAHE、FAST特征点提取并进行非极大值抑制、FAST特征点光流跟踪以及特征点跟踪误差剔除,再结合VINS-Mono中IMU处理部分和后端部分构成一个完整的即时定位与地图构建(simultaneous localization and mapping,SLAM)系统。整个系统框图如图1所示。其中,自适应直方图均值化、特征点提取、特征点跟踪都通过GPU进行并行加速运算,其他都将在CPU下进行处理。

图1 总体系统框图
2 方法设计
2.1 GPU并行处理
英伟达(NVIDIA)公司的GPU架构是由可扩展的多线程多处理阵列构建[10]。每一个多处理阵列又被划分为若干个流处理器,每一个流处理器又包含若干个处理器。为了更容易进行GPU并行处理开发,采用NVIDIA公司提供的CUDA并行计算框架,它包含重要的指令集架构、层次化线性模型以及并行的计算引擎。CUDA编程模型包含以下层次结构:线程、线程块、块网格以及线程Kernel。一个并行计算有多个Kernel,一个Kernel处理一个块网格,一个块网格由若干个线程块组成,一个线程块又由若干个线程构成,线程与线程之间并行运行[11]。整个系统的运行采用CPU与GPU串并结合协同工作、各司其职的工作方式,如图2所示。

图2 CPU-GPU异构模型
2.2 CLAHE并行化设计
CLAHE的核心思想是先对图像均匀分成等份矩形,再对每部分矩形区域求解累计分布直方图并进行对比度限幅,最后求解每个区域块的变换函数对每一个像素点进行像素值转换,对于相邻区域的像素值需进行插值操作,以消除块状效应。并行化设计具体过程如下:
1)图像分块:将图像划分成等大小的矩形区域块,本文划分为8×8的区域块。
2)计算每一个区域块的分布直方图
(1)
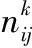
3)对每一个区域块分布直方图进行对比度限幅,并调整像素点
(2)

4)计算第i,j区域块下直方图累计变换函数
(3)
式中Wij,Hij为第i,j区域块的宽度和长度。
5)根据整个图像每一个像素点在不同区域的分布情况,执行不同的像素点映射(直接映射,线性插值映射,双线性插值映射),本文直接采用插值的方式,有效防止if else指令的发散,计算如下:
a.确定某个像素点(m,n)相邻的4个映射函数si0j0,si0j1,si1j0,si1j1,如果在边界不满足映射函数则按照取最近的映射函数操作
(4)
b.确定不同映射函数的占比
(5)
c.对像素点进行映射
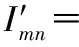
si1j0(Imn)×(1-α)×β+si1j1(Imn)×(1-α)×(1-β)
(6)
6)GPU加速设计:GPU加速过程采用两个核Kernel进行,第一个Kernel_1处理上述过程(1)~(4),分为64个线程分别求解每一个区域块的映射函数;第二个Kernel_2处理上述过程(5),分别对图像中每一个像素点进行映射插值操作,最后得到映射后的图像。
2.3 FAST特征检测并行化设计
FAST算法是一种检测局部像素灰度变化明显的特征检测方法。本文在CPU-GPU异构平台上采用GPU并行设计实现FAST角点快速检测,最后再通过GPU对检出的角点进行非极大值抑制加速处理。FAST特征检测核心思想是一个像素与领域像素的光度强度差别较多或较大时,该像素点即为FAST角点。
本文特征检测并行化设计过程如下:
1)对图像遍历取像素点(不包括边界为3的像素点),设第i行第j列的像素点灰度值为Iij。
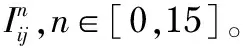
3)设置阈值T,并将像素点与其周围16个像素点进行比较,区分出更亮、更暗或者相似的像素点,并进行标记
(7)
4)对上述计算出的16个像素点得出的标签进行分类,如果有连续的N个像素点的Ln=darker或者Ln=brighter,则像素点为Iij特征点。对于上述判断连续N个点是更亮或者更暗的点,在CUDA编程处理的过程中if else指令将会频繁调用,并且不同线程之间if else活动范围不一致,会降低GPU并行处理吞吐量,效率会下降。文献[7]先通过计算16个像素点更亮和更暗值,再通过01二进制的方式保存,第0个像素点对应低位,第1个像素点对应位加一,依此类推,将更亮和更暗的数据分别保存在216位并作为地址,最后,通过预先设计8 K字节查询表,直接查询是否是角点。而本文则是设计一个快速查询角点的函数,节约空间,并且这个函数具有少量运算指令、少量参数和无if else指令,通过输入更亮和更暗的地址直接快速计算出是否为角点。计算更亮和更暗查询地址(addr_brighter和addr_darker)
(8)
快速角点查询函数设计
(9)
式中 Ξ&为连续求与符号,CN为连续N个角点查询数据库,共16个字节数据大小。如果F(Addr)=1,则为非角点;反之,F(Addr)=0,则为角点。最后,对每个像素点计算出角点得分,非角点为0,角点则根据像素差进行计算。
5)进行非极大值抑制,对图像栅格化划分为32×32等分进行非极大值抑制筛选。
6)GPU加速设计:特征检测过程GPU设计上需要分为两个Kernel。第一个Kernel处理上述过程(1)~(4) ,通过快速角点提取函数对角点判断,并执行计算得分角点响应得分,整个过程分为128个线程并行运行,每一个线程平均处理图像像素点。第二个Kernel处理上述过程(5)非线性抑制过程,先对图片划分32×32的单元格区域,线程分为32个,每一个线程处理一行单元格像素点,线程中并行执行像素点抑制,并在全局共享内存中保存在该单元格中响应得分最大值。
2.4 光流跟踪并行化设计
本文采用多层金字塔平均强度反向光流法作为特征跟踪。多层光流有效克服局部最小值,同时平均强度能有效提高跟踪效果,而反向光流则可以节省计算时间。本文光流跟踪并行化设计过程如下:
1)设置金子塔层数,并设定跟踪规则:在计算光流时,先从顶层的图像跟踪计算,再把跟踪结果作为下一层光流跟踪的初始值,直到最底层。
2)建立光流跟踪:光流跟踪其实是解决以下最小二乘问题
(10)
(11)
式中I1(x),I2(x)分别为上帧图片和当前帧图片某像素的光度强度。1,2分别为上一帧图片和当前帧图片某像素在指定范围内像素点的平均光度强度
(12)
求解最小二乘问题,得雅可比
(13)
求解像素位移增量
(14)
其中,H为海森矩阵
(15)
最后,更新位移量。
3)GPU加速设计:在这一过程中GPU并行加速运行存在两个主要的问题:内存合并和运行发散。为了解决这些问题,本文采用一个FAST角点跟踪占用一个线程,并设定迭代相同的迭代次数克服运行发散。整个并行过程只采用一个Kernel,并创建128的线程同时处理这些FAST角点,处理完成后将结果合并在一个内存块中,最后交给CPU处理。
3 实验验证分析
本文实验硬件平台为NVIDIA嵌入式处理器TX2。TX2的GPU采用NVIDIA Pascal架构,配有256个计算核心,算力高到6.2,它的CPU采用双核Denver2 64位和4核ARM A57,内存为8 GB 128位LPDDR4,TX2较小的尺寸和重量非常适用于无人机等轻负载机器人。本文实验分为两部分:1)系统耗时对比;2)系统精度对比。本文评估的数据选用数据集EuROC Machine Hall(MH)序列集,该数据序列集包括2 273帧图片。
3.1 系统耗时实验
图3进行4组耗时统计实验,选用MH—05数据集测试。图3(a)~(c)分别表示CLAHE,FAST和光流跟踪耗时对比曲线,每一个曲线分别进行OpenCV-CPU,OpenCV-GPU和本文GPU耗时对比实验;图(d)为本文前端与VINS-Mono前端耗时对比曲线。分析图(a)~(c)可知,本文Clahe-GPU耗时与OpenCV-GPU耗时基本一致但更平稳,同时比CPU耗时更低;而本文FAST和光流跟踪耗时明显低于OpenCV-GPU和CPU;两者都具有较高的运算速度。分析曲线图(d)可知,VINS-Mono前端平均耗时为0.017 65 s,而本文前端平均耗时为0.005 62 s,具有更快的计算速度;曲线中VINS-Mono前端多帧耗时明显大于0.035 s,而本文前端耗时比较平稳。
3.2 系统精度实验
本文以EuROC中MH_01,MH_02,MH_03,MH_04和MH_05作为实验数据集,采用均方根误差来评估本文前端结合VINS-Mono后端的里程计轨迹精度,并与VINS-Mono系统进行对比。误差计算采用EVO评估工具[12],计算结果如表1所示。

表1 轨迹均方根误差 m
根据表1所示,在MH—04和MH—05运动比较剧烈的数据集下本文精度略高于VINS-Mono,在其他数据集本文精度与VINS-Mono相近,平均均方根相差0.008 963 m。本文保持了较好的定位精度,与VINS-Mono相差很小。
4 结 论
本文设计了一种基于GPU并行加速视觉里程计前端方法,对系统中CLAHE、FAST角点提取和光流跟踪进行GPU并行化设计。实验结果表明:本文系统在不降低整体定位精度的情况下,明显提高算法的实时性效率,能保证定位导航的实时性要求。虽然实现性能得到了提升,但精度却保持了原来的精度。下一步工作将在本文的基础上对VIO前端算法改进,提高系统的精度,最后在实际情况下进行定位测试。
