在线教育中的学习情感计算研究 *
——基于多源数据融合视角
2022-10-10翟雪松许家奇王永固
翟雪松 许家奇 王永固
(1. 浙江大学教育学院,杭州 310058;2. 浙江工业大学教育科学与技术学院,杭州 310023)
一、引言
现阶段,实现规模化与个性化的有机结合,是落实《中国教育现代化2035》的主要任务。特别是在后疫情时代,在线课程成为规模化教育教学的有效补充形式,然而在线课程尚未解决师生及生生间的“温度”问题,即无法实时对学习者的情感进行分析和精准干预。这一困境致使学生的学习情感得不到及时有效地回应,学习绩效、学习感知和高阶思维能力也难以提升(周进, 叶俊民, 李超, 2021)。如何在在线教育中实现有效个性化情感分析,成为亟待破解的难题。同时,教育部等六部门强调以人工智能支撑网络学习空间和平台建设,构建高质量教育体系(教育部等, 2021)。如何利用智能技术促进在线课程教学是未来规模化教育的重要挑战。因此,探讨优化现有情感计算技术,进行有效情感识别,适应新需求下的在线教育具有重要理论价值和实践意义。
先前的情感计算技术路径主要有两类:一是基于重量级生理反馈技术;二是单源的面部表情、声纹等数据的测量。然而,这两类情感计算路径难以有效应用于在线教育场景。一方面,重量级生理反馈技术主要是通过分析脑电、核磁共振等重资产生理传感器,对多维生理参数进行融合分析来判断情感状态(Zheng & Lu, 2015);虽然重量级生理反馈技术能实现内部神经与外部行为信息相结合,提高情感识别的准确率。然而,重量级生理反馈技术投入大、实验环境复杂,与实际教学场景和学习环境相距较远,难以常态化及规模化的运用 (翟雪松等, 2020)。并且在大规模在线开放课程中采集到的生理数据有限,部分生理数据的采集需要与学习者接触,具有侵入性和操作复杂性,易对学习者产生影响。另一方面,单源数据如面部表情的采集较为简便,是情感表达最主要和直接的呈现方式,基于面部表情可以实现较为广泛和准确的情感识别(陈子健, 朱晓亮, 2019)。然而,单源数据的可解释性较弱,如面部表情具有部分微表情的特征,动态性和伪装性使其难以满足实用性需求(殷明等, 2016)。在在线学习环境下,学习者往往处于一种无监督、自由放松的状态,表情特征不明显且易受身体姿态的影响。单一数据源难以实现数据信息的交叉印证和相互补偿,从而影响情感识别准确度(武法提, 黄石华,2020)。结合情感计算研究优势与局限,本研究预构建基于多源数据的人工智能分析路径,以期符合大规模开放教育的情感计算应用场景。
本研究首先综述了在线学习情感特征、情感计算的方法及多源数据融合的应用,借鉴现有情感计算的研究设计,构建了面向在线教育的中学生面部表情和人脸姿态情感双维数据集;其次,运用深度学习和数据融合的方法,构建单源数据和多源数据融合的学习情感计算模型,进而比较得出最优模型;最后进行在线情感计算的反思和挑战论述,以期为在线教育学习者情感计算研究带来新的视角和启示。
二、研究现状
情感计算的研究主要集中在数据采集、模型构建、情感识别以及算法分析等方面。随着人工智能、学习分析技术的兴起和发展,教育领域的情感计算逐渐转向数据多源化和分析智能化,利用机器学习、深度学习等智能算法,从数据融合的角度分析学习情感成为当前研究的前沿(刘智等, 2019; 唐汉卫, 张姜坤, 2020; 尚俊杰, 王钰茹, 何奕霖, 2020)。
(一)情感计算在教育中的相关研究
情感计算涉及计算机科学、认知科学和心理学等多个研究领域,通过计算机实现人类情感的识别、解释、建模和分析(权学良等, 2021)。情感计算的概念最早由皮卡德教授在《Affective Computing》一书中提出,她认为情感计算是由情感产生、与情感相关联且能够对情感产生影响的计算(Picard,2003)。我国学者罗森林和潘丽敏(2003)认为情感计算是使计算机具有识别、理解、表达和适应人类情感的能力,与情感、情感的产生、影响情感的方面紧密相关。
在教育研究中,情感计算的主要应用为学习情感识别,即准确判断学习者的情绪,一般通过心理测量、生理测量与行为测量等方法开展(钟薇等, 2018;叶俊民, 周进, 李超, 2020)。首先,心理测量是通过分析被试填写的情感评定量表和与之相关的问卷,判断其学习情感。如利用学习情感量表对学习者的课堂学习情感进行测量(韩颖等, 2019)。其次,生理测量是通过传感器获取学习者的不同生理信号(脑电信号、体温信号、心律信号等)进行情感判别(王丽英, 何云帆, 田俊华, 2020)。喻一梵和乔晓艳(2017)采集被试的脉搏和心电数据,基于深度学习算法对被试的正负性情绪进行识别研究。最后,行为测量是基于表情、姿态、语调等外在表现动作识别学习者的情感。基于学习者面部表情数据,通过卷积神经网络深度学习模型,实现对学习过程中的常态、开心、愤怒、悲伤、惊恐、专注、厌倦等情感的有效识别(徐振国等, 2019);基于人的面部表情和周围环境信息,通过深度学习网络进行有效情感识别(Lee, Kim, Kim, Park & Sohn, 2019);利用多模式传感器测量与情感相关的身体姿态从而分析姿态和情感状态的关系(Dragon, Arroyo, Woolf, Burleson, Kaliouby & Eydgahi, 2008);监测学习者键盘和鼠标的操作行为数据,对学习者在线情感状态进行感知(孟雄, 郭鹏飞, 黎知秋, 2015)。综上,基于心理、生理、行为的测量方法均可以实现学习情感分析,通过轻量级人工智能技术对学习者外显行为进行分析是有效的情感计算方式。
(二)在线教育学习情感特征及其影响相关研究
学习情感是学习者在学习过程中产生的情感体验,具体表现形式为学习情绪的表达,存在于大规模在线开放课程的各个阶段,具有多样性、复杂性、多变性的特征。一方面,学习情感以主体的需要、愿望等倾向为中介,具有多样性的特征。董妍和俞国良(2007)指出在教学过程中, 学生的学习情感包括开心 、厌倦 、失望 、焦虑、气愤等。德梅洛(D’Mello, 2013)对5个国家1 740名中学、大学和成人学生的14种离散情感状态进行精细监测,发现学习过程中常出现的情感有困惑、投入、沮丧、厌倦、悲伤、焦虑、开心、恐惧等。另一方面,学习情感是一种复杂的情感体验,受学习动机、学习期望、物理学习环境等因素的影响(郭龙健, 申继亮, 姚海娟, 2012)。合理的期望和学习动机能够促使学习者产生积极情感,使学习者主动地学习;相较于师生、生生间互动性更强的线下学习环境,在线学习环境下的情感变化较为稳定,较少发生大幅度的学习情感变化(钟志贤, 邱娟,2009;王云等,2020)。再者,学习情感在某一节点或学习阶段会发生变化。如在线学习初始阶段,学习情感多为积极情感,情感状态较为稳定,然而随着在线学习时间的增长,学习者的消极情感也随之增加(赵宏,张馨邈, 2019)。
学习情感是在线教育中影响学习认知、学习成效和心理健康的重要因素(Artino & Jones, 2012)。首先,学习情感影响学习认知。研究者在学习者在线参与学习任务的研究中发现学习情感影响学习者的学习认知方式(Robinson & Kathy, 2013)。谭金波和王广新(2017)在学习情感对网络信息认知搜索行为和搜索绩效的影响研究中发现,积极情感能增强学习者的认知搜索行为。其次,学习情感影响学习成效。积极的学习情感能够提高学习者的学习情绪,降低学习者理解学习内容的难度,提高学习效果(Um, Plass, Hayward, & Homer, 2012)。消极的学习情感对学习者知识能力的掌握及最终学业成就具有潜在负面影响(刘智等, 2018)。最后,学习情感影响学习者的心理健康。疫情期间的居家隔离使得学习者产生较大的心理压力,长时间的在线学习使学习者在学习时空和媒体使用两个层面产生情感问题,从而影响学习者的心理健康。在学习时空方面,在线学习的时空分离使学习者之间交流互动匮乏,容易产生厌烦、孤独等负面情感,产生的负面情绪如果得不到有效的识别和干预,将影响学习者的身心健康(黄昌勤等, 2021; 蔡红红, 2021)。在媒体使用方面,学习者在线学习平台和个人学习空间的来回切换容易导致焦虑和不适情感的产生(李文昊, 祝智庭, 2020)。综上分析,学习情感对学习认知、学习成效和心理健康的影响反映出在线学习情感计算的重要性,要针对特定的环境、个体特征和情感特征,采用合适的方法进行有效的在线学习情感计算。
(三)多源数据融合在情感计算中的有效性研究
当前,多源多模态的学习情感分析逐渐代替单一数据源的分析,数据融合成为学习情感计算的有效方法。数据融合最早被称为信息融合技术,通过将多种信息进行综合、分析、处理,为模型决策提供更多信息,提高总体决策结果的准确性(何俊等, 2020)。第一,数据融合的方法。何俊、刘跃和何忠文(2018)根据与模型的关系分为模型无关的方法和基于模型的方法两大类。其中模型无关的方法包括早期融合(特征融合)、后期融合(决策融合)和混合融合三种;基于模型的方法包括多核学习方法、图像模型方法、神经网络方法等。第二,多源数据的分类。多媒体数据分析涵盖的多源数据类型包括文本、图片、音频和视频等类型的数据。在线数据分析领域的多源数据包括服务数据、个人共享数据、行为数据等(梁韵基, 2016)。学习分析领域,多源数据包括生理层数据、心理层数据、行为层数据三类(吴永和, 李若晨, 王浩楠, 2017)。
随着数据类型的不断丰富及数据量的几何式增长,多源数据融合应用于情感计算的研究越来越丰富。一方面,同一层级内的数据融合能够有效识别情感,表现在:第一,生理数据的融合。通过呈现交互性和非交互性的刺激,收集被试的脑电和心电数据,基于决策融合和机器学习的方法(朴素贝叶斯、支持向量机)对被试的情感进行分类和识别(Bandara, Song, Hirshfield & Velipasalar, 2016)。第二,行为数据的融合。通过收集被试面部表情和语音信息数据,采用混合融合的方法识别网络学习者的学习情感(Bahreini, Nadolski & Westera, 2016);通过收集被试面部表情和上半身行为数据,基于特征融合方法和卷积神经网络模型,得到比单独面部和上身行为更高的情感识别效果(Ilyas, Nunes, Nasrollahi, Rehm &Moeslund, 2021)。
另一方面,不同层级间的数据融合能够有效识别情感,表现在:生理数据和行为数据的融合。有些计算机研究者提出了一种决策融合脑电图数据和面部表情数据的方法来识别快乐、中性、悲伤和恐惧四种情感,该方法得到的识别准确率高于单一面部表情或脑电图的准确率(Huang, Yang, Liao & Pan,2017)。行为数据和心理数据的融合。我国教育研究者融合在线学习者的面部表情、语音和文本数据,对在线学习过程的学习情感进行识别(薛耀锋等, 2018)。心理数据、生理数据和行为层数据的融合。教育研究者基于后期融合策略和卷积神经网络,将面部表情数据、脑电数据和文本信息数据进行融合,实现学习参与度的有效识别(曹晓明等, 2019)。综上分析,在线学习者生理、心理、行为数据的融合能够实现学习情感计算,基于深度学习的数据融合方法能够有效提升学习情感计算的准确度。
三、研究过程与方法
本研究的目的在于构建面向在线教育的中学生多源学习情感数据集,比较基于单源数据和多源数据情感计算模型的情感识别效果,为学习情感计算的推广、应用与实践提出建议。
(一)实验组织
1. 实验对象
本研究在杭州市某中学通过方便取样法抽取高一年级的36名中学生,其中男生19名,女生17名。被试年龄范围在14—16岁之间,均为自愿参加本次实验,同意并知情实验内容。
2. 实验工具
本研究的实验工具如下:(1)基本信息问卷。包括实验对象的姓名、性别、年龄和班级。(2)实验过程学习情感问卷。该问卷的作用是及时记录学习者观看不同教学视频时最直接的情感表现和状态,为后续的学习情感标注提供较为科学的参考依据。(3)摄像头。该摄像头为具有自动对焦功能的高清摄像头。(4)在线课程资源。课程资源来自网络中的在线视频,包括《新闻联播剪辑版》《一元二次不等式及其解法》《关于新冠肺炎的一切》《Using language》,四个视频时长均在6—15分钟,教学视频内容完整且趣味程度各不相同。(5)ELAN6.0标注工具。该工具的作用是帮助被试标记自己的学习情感。(6)学习情感标注工具。该工具为基于PyQt5自主开发的一款简易情感标注软件,包括文件导入、图像基本信息、标签按键三个部分。
(二)数据收集
1. 数据采集和筛选
面部表情和人脸姿态数据收集主要包括数据采集、数据筛选、数据标注和数据集划分四个阶段。第一,数据采集。数据采集包括被试观看课程视频、被试自评打标签、数据保存。第二,数据筛选。数据筛选是对视频数据和图片数据的筛选,包括人工筛选视频数据、机器获取人脸图像数据、手动删除不合格数据三部分。不合格图像数据(图1),包含图像不完整、面部被遮挡、图像不清晰。

图1 不合格图像
2. 数据标注
数据标注包括被试评价标注和研究人员评价标注两部分。被试评价标注是被试通过ELAN6.0对自己不同时间的情感状态进行评判并标注对应的情感标签,其目的是为研究人员的标注提供参考依据。研究人员评价标注是研究人员借助开发的学习情感数据标注软件,以面部活动单元(FACS)和表情运动特征作为情感特征参考(Cohn, Ambadar, & Ekmansen, 2007;程萌萌, 林茂松, 王中飞, 2013),结合被试自己标注的情感示例和实验过程学习情感问卷,对收集到的图像进行标注(表1)。本研究标注的情感标签包括开心、困惑、平静、厌倦四种,示例(图2)。

图2 学习情感示例(某个被试)
本研究的学习情感划分为开心、困惑、平静、厌倦四种类型,主要划分依据有以下三点:首先,在一般意义上的情感计算中,情感类型较为丰富,本研究的情感计算环境为在线学习环境,学习形态是从教师到学生的单向传播,学习者与知识的交互方式单一,学习者的情感波动较小,情感类型比较集中 (余胜泉, 王慧敏, 2020);其次,D’Mello (2013) 通过对5个国家1 740名中学、大学和成人学生的14种离散情感状态进行精细监测发现,学习者在学习过程中常出现的学习情感有困惑、厌倦、沮丧等;最后,本研究在分析采集视频和图像数据以及结合被试情感问卷发现,被试在观看本研究提供的在线视频后,表现出了平静、困惑、厌倦、开心四种情感类型,好奇、悲伤等情感出现次数很少。因此,本研究最终聚焦开心、困惑、平静、厌倦四种情感类型,并进行情感的标注和分析。
4. 数据集划分
面部表情和人脸姿态数据集的总数据量各为3 939张。两个数据集都包含训练集、验证集和测试集。其中,训练集的图像数量2 363张,约占总数据量的60%;验证集的图像数量为788张,约占总数据量的20%;测试集的图像数量为788张,约占总数据量的20%。面部表情数据集局部如图3所示,面部表情数据为体现学习者平静、困惑、厌倦、开心的面部图像,数据更聚焦面部的特征;人脸姿态数据集为体现平静、困惑、厌倦、开心四种情感状态时的人脸姿态特征图像,包含脸部轮廓、眼睛、眉毛、嘴巴和鼻子人脸姿态特征点,聚焦这些特征点构成的姿态特征。人脸姿态特征点生成过程如图4所示。

图3 面部表情数据集(局部)

图4 人脸姿态特征点生成过程
(三)多模态数据融合模型设计
1. 深度学习神经网络模型选择
本研究面部表情和人脸姿态的特征提取基于卷积神经网络模型。卷积神经网络的基本结构是由输入层、卷积层、池化层、全连接层和输出层构成的。卷积神经网络常用于文本分类、二维图像数据提取和预测,在大型图像数据处理方面具有优势。本研究选取了VGG-16和ResNet-50卷积神经网络作为情感计算的深度学习神经网络并比较了其效果。VGG-16经过2次卷积、5次池化和3次全连接操作,最后输出预测的情绪类别,过程(图5)。ResNet-50 经过5个STAGE阶段,共49次卷积、2次池化和1次全连接操作,输出预测结果,过程(图6)。

图5 VGG-16模型处理数据的过程

图6 ResNet-50模型处理数据的过程
2. 多源数据融合的方法
在数据融合过程中,不同融合方法对情感计算的结果会有不同影响。本研究采用基于权重规则的决策融合实现多源数据融合,通过将面部表情单源数据模型和人脸姿态单源数据模型的结果赋予不同权重,得到不同的融合结果。权重赋值需要考虑:(1)不同识别模型的能力不同,对最终结果的贡献有差异;(2)不同模型中对不同情感的识别能力有差异。基于此,本研究采用模型整体输出赋予不同权重和模型整体输出中不同情感概率赋予不同权重两种方式进行权重赋值融合,具体内容如下:
在我国,除了广泛关注外,国家在政策上也给予了支持的态度。在开发上,除高校外,中小学、培训机构、网络运营商等都在致力于开发大量的网络课程,内容十分广泛。在应用上,除了学校教师、培训机构等聘请教师授课外,还有大量的个人用户也基于平台进行授课。由于网络课程是为了满足人们的需求,因此听众具有多样性。
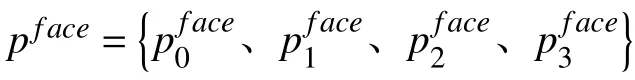
模型整体输出赋予不同权重的计算公式为:

xm,xn分别表示面部表情和人脸姿态的权重。
模型整体输出中不同情感概率赋予不同权重的计算公式为:

3. 多源数据融合模型总体架构
多源数据融合的学习情感计算模型总体框架(图7),包括采集模块、识别模块和融合模块三个主要模块。其中,采集模块为采集中学生学习过程中的面部表情数据和人脸姿态数据;识别模块为基于卷积神经网络构建面部表情学习情感计算模型和人脸姿态学习情感计算模型;融合模块为基于决策融合策略的多源数据融合,通过权重规则的方法,将面部表情识别结果和人脸姿态识别结果进行融合,得到最终的融合模型结果。

图7 多源数据融合的学习情感计算模型总体框架结构
四、结果分析
通过模型训练,提取面部表情和人脸姿态的特征,得到不同情感识别模型的结果。模型训练中设定的参数主要有优化器(optimizer)、损失函数(loss)、批量大小(batch size)、遍历次数(epoch)。
(一)卷积神经网络模型结果比较
经过训练,基于VGG-16和ResNet-50的面部表情识别模型和人脸姿态识别模型的损失函数都达到收敛,趋向于一个稳定的值,两个模型的结果(表2)。

表2 不同模型的识别结果
可以看出在相同的学习情感数据集和训练次数设定情况下,VGG-16的识别效果整体优于ResNet-50的识别效果。此外,VGG-16卷积神经网络结构规整简洁,能够通过不断加深网络结构来提升模型的性能,且没有太多的超参数。已有研究利用VGG-16模型在学生课堂行为的识别和学生学习情绪识别中得到了较高的准确率。因此,本研究最终选用VGG-16作为面部表情和人脸姿态的深度学习神经网络模型。
(二)单源数据的情感识别结果
基于VGG-16的面部表情模型和人脸姿态模型在验证集上对不同情感的识别准确率情况,如表3所示。其中,面部表情模型对厌倦情感的识别效果最好,准确率为77.83%。可能的原因是厌倦的特征表现单元较多,多为眼皮闭合、嘴唇上抬或下拉,容易被正确识别。其次是开心,准确率为77.39%。开心的表情特征为嘴角向上、眉毛弯曲、脸颊提升、露出牙齿等特征,比较容易被识别。平静和困惑的识别准确率相对较低,为73.89%和71.72%。人脸姿态模型厌倦的识别效果最好,准确率为73.40%。可能的原因是厌倦的人脸特征表现多为脸部倾斜、偏移等特征比较明显。其次是开心,准确率为73.04%。开心的人脸姿态特征多为下颚拉长、嘴部拉长等特征,容易被识别。平静识别准确率相对较低,为71.32%。困惑的识别准确率最低,为57.07%,这可能与困惑的人脸姿态特征表现不明显有关。

表3 不同学习情感的识别结果
(三)多源数据融合模型结果
1. 模型整体输出赋予不同权重
多源数据融合模型的结果为基于权值规则的单源面部表情模型结果和人脸姿态模型结果的融合,其中模型整体输出赋予不同权重结果(表4)。

表4 模型整体输出赋予不同权重的准确率情况

2. 模型整体输出中不同情感概率赋予不同权重
(四)最优模型选择及情感识别结果
1. 单源数据模型和多源数据融合模型比较结果
本研究不同模型在测试集上的准确率情况(表5),基于多源数据融合模型(模型整体输出中不同情感概率赋予不同权重)准确率最高,为77.79%;其次是多源数据融合模型(模型整体输出),为77.54%;再次是基于面部表情的识别模型,为74.87%;基于人脸姿态的模型识别准确率最低,为68.53%。可见,多元数据融合模型(不同情感概率赋予不同权重)为最优的情感识别模型。

表5 不同模型测试集的识别准确率情况
2. 最优模型情感识别结果
最优情感识别模型对四类情感识别的准确率情况(表6),其中厌倦情感的识别效果最好,为82.27%;其次是开心、平静、困惑情感,依次为80.00%、78.31%、71.21%。

表6 最优模型不同学习情感的识别结果
上述结果表明:(1)基于多源数据融合的学习情感识别模型比基于面部表情和人脸姿态的单源数据学习情感识别准确率高、效果好;(2)多源数据融合模型中,模型整体输出中不同情感概率赋予不同权重要比模型整体输出赋予不同权重的准确率要高;(3)多源数据融合模型对厌倦情感的识别效果最好,其次是开心情感、平静情感、困惑情感。
五、反思挑战
学习情感计算从小范围的实验室研究走向规模化、常态化应用才是情感计算落地的体现。本研究从情感计算的基础环节、有效方法和最终目的三个方面进行在线学习情感计算的反思,从学习者个体、数据融合和人工智能伦理三个方面论述在线情感计算面临的挑战。
(一)在线学习情感计算反思
多源数据集的构建是在线学习情感计算的基础环节。首先,情感表达的数据类型包括面部表情、语音、姿态、生理信号、文本信息,构建多源数据集才能有效支撑在线情感计算研究。其次,随着学习情感计算的应用场景逐渐增多,解决的问题更加深入细化,现有支撑情感计算的数据集已经不能满足日益增长的教育场景需求和常态化的应用,需要构建符合特定教育场景需求的多源数据集以解决个性化的学习情感计算问题。最后,数据集的数据量越大,数据标注越准确,其在学习情感计算研究中的应用效果就越好。大规模多源数据集将有效推动学习情感计算的规模化、常态化应用。本研究针对中学生在线课程学习,系统设计了中学生学习情感数据集的构建方案,构建了中学生在线课程学习面部表情数据集和人脸姿态数据集。通过模型实验验证了数据集的可用性,能够作为中学生在线学习情感计算研究的多源数据集支撑。
基于深度学习的多源数据融合是在线学习情感计算的有效方法。首先,深度学习神经网络已经实现了远超过传统机器学习方法的精确度,利用深度学习进行情感计算可以实现情感特征的自动提取,简化数据的处理步骤,降低准入门槛,提升算法的效率。同时,深度学习神经网络中的卷积神经网络在图像数据提取、预测及大型图像数据处理方面具有优势(王永固等,2021)。其次,多源数据融合能够提升在线学习情感计算的准确性。在线学习者会经历自学、问题提出、交流讨论等多个环节,学习情感更加多样、复杂,一种数据往往很难准确反映学习者的情感状态。数据融合能够将传感器提供的多源数据进行组合,提升获取、分析信息的能力,得到更加准确的识别和判断结果,从而实现最终的信息优化(张琪, 武法提, 许文静, 2020)。本研究构建的多源数据融合学习情感计算模型可以有效识别中学生的学习情感,识别的准确率高于单源数据的学习情感识别模型。可见,基于深度学习的多源数据融合方法能有效提升学习情感计算模型的准确度,推动了学习情感计算在教育教学的应用和实践。
学习情感计算的最终目的是应用于教育教学的不同场景,从而提升教师教学质量,促进学生学习。在大规模在线教育中,学习情感计算将在个性化学习资源推荐、自适应测验、无差错学习等教育场景应用中发挥重要作用。首先,如何基于学习者个体特征,实现个性化学习资源推荐成为在线学习的难点问题。当前,在线教育平台汇集了大量学习资源,但是这些资源仅在静态的存储于平台中,无法与学习者形成一种动态匹配关系,即实时根据学习者的在线学习状态推荐合适的学习资源。通过学习情感计算,可根据学习者实时的情感状态推荐匹配的个性化学习资源。如当学生处于厌倦情感时,系统将为其提供有趣的教学活动;当学生处于困惑情感时,可以为其推荐与所学内容相关的文本资料、视频等,帮助学生解决遇到的问题(江波等, 2018)。其次,自适应测验中,以项目反应理论为基础的自适应测验可以根据学习者的能力水平给以相应难度测题,能够较为真实的反映学习者的潜在能力。然而自适应测验仍存在以下问题:一是测量能力结构简单,缺乏好奇、问题解决、创造等能力的评估;二是测验结果的可解释性较低,仍以分数为标准(郑旭东, 高守林, 任友群, 2016)。因此,将学习情感计算应用于自适应测验研究,一方面可以通过测量情感丰富测验考察的能力结构。另一方面可以从情感的角度解释学习情感的测量结果,提高测量结果的科学性。最后,无差错学习是指在学习过程中使用多样、连续的学习线索或提示刺激学习者,从而消除错误的学习条件,获得好的学习效果,常用于学习障碍人群的干预治疗(Clare & Jones, 2008)。将学习情感计算应用于无差错学习可以持续关注学习障碍者的情感需求,通过在线索提示中增加情感补偿,为学习者带来较好的心流体验,实现对学习障碍者的人文关怀,降低学习障碍者的辍学率。
(二)在线学习情感计算面临的挑战
面向教育现代化远景目标,人工智能将随时、随地、随需对学习者的成长产生影响,开启教育领域个性化的新浪潮(伍红林, 2019;伏彩瑞等, 2017)。在线情感计算作为人工智能教育研究领域的高地,在具备巨大研究价值和应用前景的同时还要面临学习者个体差异、数据融合以及伦理问题的挑战。
从个体层面看,学习者的性格、认知方式、学习策略、动机等在一定程度上会影响在线情感计算的效果。不同学习者的个体差异往往表现出不同的学习情感特征,这使得在线情感计算难以普遍适用于所有类型的学习者。因此要充分考虑学习者的个体差异,提供多样化、个性化的在线情感服务,既适用普通学习者,又能满足特殊学习者的需求;既保障在线教育,又能为其他类型的教育提供支撑。同时,构建基于学习者个体差异的情感评价体系,以学习者为中心,多方面多角度考虑不同因素对学习情感带来的影响,实现过程性、动态性和差异性的学习情感评价。
情感计算本身是一个多源数据问题,基于何种数据,使用什么融合方法关乎情感计算的准确性(牟智佳, 符雅茹, 2021)。当前,现有的数据类型和数据融合方法已经不能满足大规模在线情感计算的需求,从数据的类型和融合方法层面进行创新,从而提升情感计算的准确度将是在线情感计算的重要挑战。一方面,探究表征学生行为、生理、心理等的数据,如声纹数据、眼动数据、交互数据等,从多源异构的底层数据中发现学习者的在线情感特征(吴永和等, 2021)。另一方面,尝试多种数据融合方法,从特征融合、决策融合、模型融合、混合融合等多视角探索适用于在线学习情感计算的数据融合方法。
在线学习场景下的情感计算需要建立在人工智能伦理框架体系内。在线情感计算获取学习者的表情、行为、语音等多源数据,虽然在一定程度上提升了教学和管理,但其背后产生的个人数据隐私、信息泄露等问题不可忽视(李青, 李莹莹, 2018)。目前,算法和大数据已经出现了,如信息自由、传播权、信息隐私权、信息触达、数字身份及其保护等诸多问题,这些问题的进一步传导会带来身份认同、伦理边界、信息安全、歧视偏见等争议(赵瑜, 2019)。因此,在人工智能伦理层面,一是要关注在线教育中数据的采集和使用安全问题。包括学生个人信息数据,视频、音频等数据的采集和使用,明确数据的收集、存储和使用规则。二是要重视数据分析算法安全。确保学生学习底层数据和个人数据的上传算法安全以及数据分析算法的安全。
