自然语言处理技术赋能教育智能发展 *
——人工智能科学家的视角
2022-10-10董瑞海
张 博 董瑞海
(1. 华东师范大学教育信息技术学系,上海 200062;2. 都柏林大学计算机学院,爱尔兰,都柏林,D4)
一、引言
自然语言处理(Natural Language Processing, NLP)于20世纪50年代末兴起。“图灵测试”的出现被认为是自然语言处理发展的开端。60年代,人工智能领域的第一次发展高潮出现,孕育出自然语言处理和人机对话技术。70年代开始,基于统计的方法逐渐代替了基于规则的方法。90年代中期以来,计算机的运行速度和存储量大幅度增加,为自然语言处理技术的飞速发展提供了硬件基础。同时,随着互联网商业化和网络技术的发展,基于自然语言的信息检索、提炼,以及语言翻译和理解的需求日益增加,这些都促使语音和语言处理技术逐渐产品化并被广泛应用。到了21世纪,自然语言处理技术的突破进展,已经使人工智能(Artificial Intelligence,AI)系统的语音能力、语言能力等得到前所未有的提高,并开始对全球发展产生重要的经济影响。
人工智能尤其是自然语言处理技术的快速发展给教育领域带来了巨大的机遇(Alhawiti, 2014),并衍生出人工智能+教育。人工智能教育,又称智能教育(Artificial Intelligence in Education, AIED),是人工智能技术对教育的赋能,具体是指通过人工智能技术在教育领域的运用,来实现辅助、优化教与学过程,甚至是替代教师完成一些机械性工作,以提升教育质量,实现个性化学习等目标(吴永和,刘博文,马晓玲,2017)。作为人工智能最重要的一部分,自然语言处理的快速发展,对教育实现智能发展具有关键的促进作用。郑南宁指出自然语言处理技术有望帮助教师从简单重复的教学工作中解放出来,比如,降低教师作业批改的工作量,使他们有更多时间专注学生全面长远的发展(郑南宁,2019)。其次,自然语言处理技术可以促进传统教学方法、教学环境的变革,比如提供更多元化的教学材料、更丰富的交互方式、更加个性化的教育模式等(清华大学人工智能研究院,2020)。未来教师将不仅仅是知识的传授者,也将成为智能化满足学生个性化学习需求的教学实践者。本文旨在通过对国内外AI科学家近几年公开发表的访谈、演讲、会议报告、论文等数据进行分析,梳理自然语言处理关键技术的发展趋势,探讨其赋能教育智能发展的现状,以及在未来智能教育发展中的应用趋势与挑战。
二、人工智能科学家
人工智能的持续发展离不开AI科学家的不断探索和创新,他们是技术持续发展的推动者,是技术应用趋势的预测者,他们会在各种重要场合(例如,访谈、演讲、国际会议等)发表最新的研究,以及对人工智能未来发展趋势的看法。AI科学家乐观预测自然语言处理技术将进一步发展成熟,并在未来被应用到更多领域,尤其是教育领域。2019年,刘群在知乎专访中提到自然语言处理让机器变得善解人意(知乎,2019)。沈向洋在公开演讲时表示,下一个十年人工智能的突破在自然语言的理解方面(清华大学,2020)。2017年,吴达恩在斯坦福的人工智能年度报告中提出,随着深度学习的快速发展及其在自然语言处理领域的广泛应用,自然语言处理技术正在经历关键的革命时刻,这将促进新应用程序的繁荣(例如,教育机器人),并为其他领域的发展带来创新(Shoham, Perrault, Brynjolfsson, & Clark,2017)。2020年,Stuart Jonathan Russell在展望未来5—10年人工智能对人类社会的影响时强调,如果AI智能系统能更精确地理解人类语言,其将在人类日常的学习与生活中扮演更重要的角色,并认为未来十年将迎来语言理解的重大突破(Russell, 2020)。在2020年中国人工智能学会(Chinese Association for Artificial Intelligence,CAAI)的特约专栏中,宗成庆提出,自然语言处理最终要解决的是人类语言的理解问题,是可以使智能系统实现更精准的性能水平,是可以满足个性化用户需求,甚至让机器做到像人一样理解自然语言的问题(宗成庆,2020)。因此,了解自然语言处理技术的发展历程及其赋能教育智能发展的现状,探究其对未来智能教育发展的影响,是本研究的重点。
本文以自然语言处理的技术发展及其在智能教育领域中的应用与实践为主题,收集了44位AI科学家发表的相关观点与研究,旨在探讨AI科学家视角下自然语言处理技术赋能教育智能发展的现状。在收集到的数据中,国外AI科学家23名,主要来源于美国人工智能协会(the Association for the Advancement of Artificial Intelligence,AAAI);国内AI科学家21名,主要来自中国人工智能学会(Chinese Congress on Artificial Intelligence,CAAI)。
数据显示,本研究所涉及的AI科学家中,男性36人,占总样本的82%;女性8人,占总样本的18%,如图1 (a)所示。其次,AI科学家的工作单位所在国家分布情况如图1 (b)所示,中国科学家最多,占总样本的48%,美国科学家占39%,其余科学家分布在英国、爱尔兰、加拿大、智利、泰国和巴基斯坦。数据结果从侧面印证,中国和美国是目前全球研究自然语言处理及其在教育领域应用方面的两个主要国家(戴静 & 顾小清,2020)。
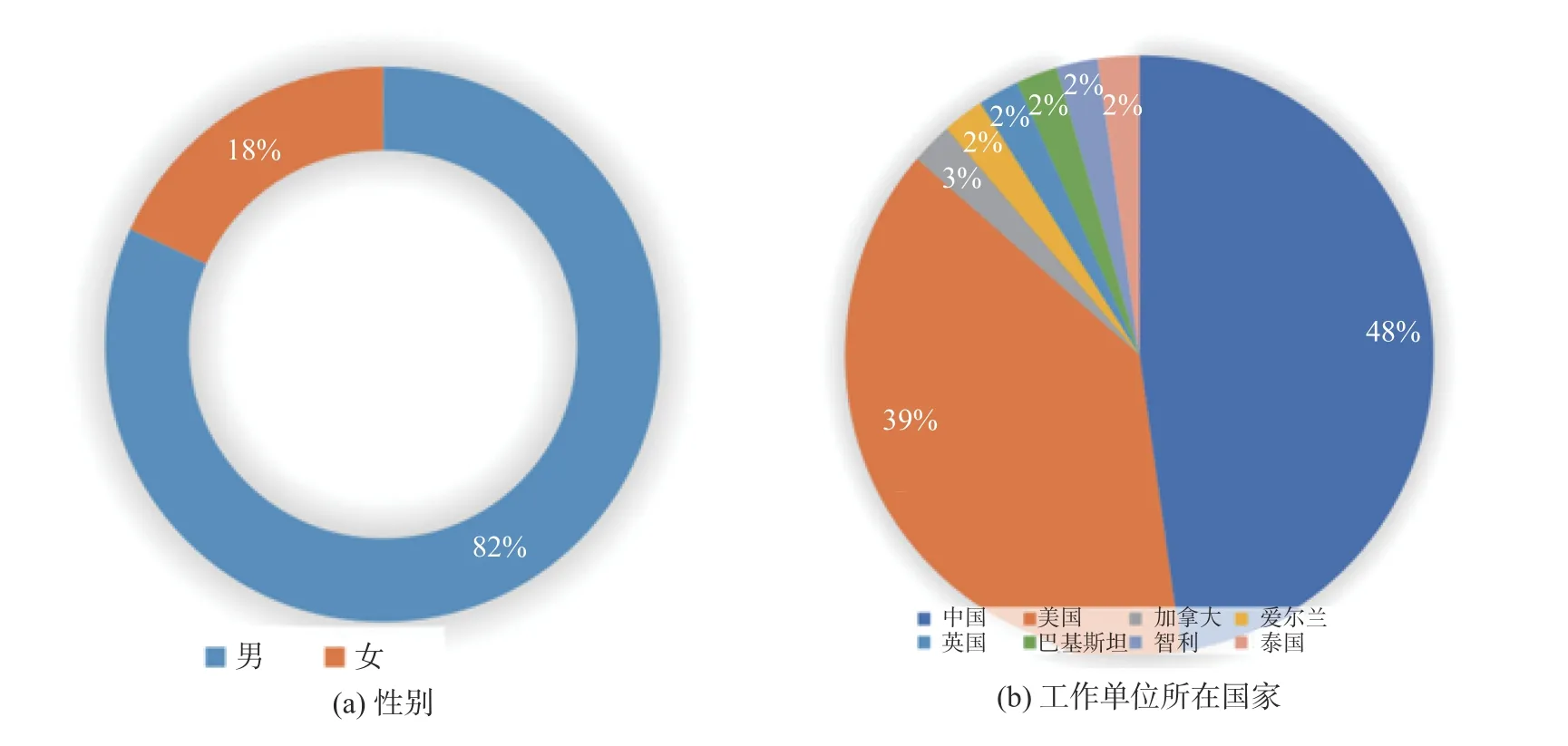
图1 AI科学家分布情况
三、对自然语言处理定义的理解
自然语言处理主要研究人与计算机之间用自然语言进行有效交流的各种理论和方法。自然语言是指汉语、英语等人们日常使用的语言,而语言是人类学习的重要工具。自然语言处理技术可以广泛应用于师生教与学的活动过程中,自然语言处理是教育智能发展的基础。由于自然语言处理技术涉及多种不同的任务,基于AI科学家的视角,我们可以从四个层次对自然语言处理的定义进行理解:
一是对文本进行处理,包括对自然语言进行分句、分词、词性标注(将文章中的每个词标注为名词、动词、形容词等)、命名实体识别 (识别出文本中的时间、地点、组织等)等。2019年,周明在全球人工智能与机器人峰会上提出,自然语言处理就是用计算机对人类语言进行处理,包括对字、词、句、篇章的输入、输出、识别、分析、理解、生成等,以使得计算机具备人类的听、说、读、写能力(微软亚洲研究院, 2019)。
二是对自然语言的理解。在对文本进行处理的基础上,自然语言处理技术会理解文本包含的意义,比如表达意图、情感、情绪等理解过程。刘群解释,自然语言处理的研究对象是人类语言,如词语、短语、句子、篇章等。通过对这些语言单位的分析,计算机不但可以理解语言所表达的字面含义,还可以理解人类语言所表达的情感以及语言所传达的意图(知乎,2019)。
三是交互,即人类通过自然语言与计算机进行交流对话,例如,人机问答-教育机器人、浏览器搜索、智能电子设备的信息沟通等。Dan Jurafsky认为,自然语言处理是实现人与计算机之间用语言进行有效通信的方法,是了解人类心理和态度的最佳途径(Dan,2017)。Dragomir Radev认为,自然语言处理可应用于人机问答、情感分析、机器翻译、语义分析、拼写纠错等教育活动,但是话语意图分析、习惯性表达、语义相关等方面的语言理解使得自然语言处理发展遇到挑战(Dragomir, 2017)。
四是创新,即计算机可以通过语言理解进行智能创作,包括写作辅助、图文自动生成等。例如,2021年,IIya Sutskever宣布,语言模型将开始了解视觉世界,通过自然语言的输入,系统可以智能生成各种具有创造性的图像(OpenAI, 2021)。
何晓东认为,自然语言处理作为人工智能的核心技术,主要用于连接人类和计算机世界的交流(何晓东,2019)。从自然语言处理定义的四个层次可以看出,基于自然语言处理技术可以开发出具有互动性、创新性、个性化的智能工具来赋能教育的智能发展。AI科学家期望随着自然语言处理技术的不断优化,相关智能工具的性能会被不断提高,并为未来的智能教育带来更好的体验。
四、自然语言处理关键前沿技术
随着自然语言处理技术的快速发展,它在教育领域的应用取得了突破性的进展,越来越多的智能工具与系统逐渐被广泛地应用于教学活动中。然而,这些突破性的进展离不开一系列关键技术的涌现。为了更好地理解自然语言处理的一些技术原理,基于AI科学家的研究进展,本节对自然语言处理发展过程中涌现的关键技术进行详细讨论。例如,随着新词嵌入方法的出现,计算机对自然语言的理解更加精准与高效,随着大规模语料库预训练模型的不断发展,多种自然语言处理任务的性能得到显著提高。这些自然语言处理关键技术的进步是智能教育不断发展的重要基石。
(一)新词嵌入方法的出现
依据上文的描述,计算机在基于自然语言处理学习读懂自然语言的过程中,最先开始学习的是文本中词汇的理解与表达。在深度学习出现之前,在自然语言处理问题的机器学习方法中,我们一般采用一种高维但稀疏的向量来表达词汇,比如 One-hot Encoding。然而这种方式不仅带来计算空间的浪费,还会影响系统模型的性能,因为系统不能理解单词之间的相关性。其次,早期的基于奇异值分解的LSI/LSA(Latent Semantic Indexing/Latent Semantic Analysis) (Hofmann, 1999)、基于概率分布的LDA(Latent Dirichlet Allocation)(Blei, Ng, & Jordan, 2003)等系统模型在对单词的语义理解上取得较大进步,但这类模型计算比较耗时,并需要对不同语料库的主题与数量进行合理的选择。2003 年Bengio等人提出神经语言模型(NNLM),使深度学习开始应用于自然语言处理(Bengio, Ducharme, Vincent, & Janvin,2003);2013 年,Mikolov 等人构建CBOW和Skip-Gram模型,通过观察共现词汇并引入负采样等可行性措施,实现了高密度词向量的表达方式(Mikolov, Chen, Corrado, & Dean, 2013)。GloVe(Pennington,Socher, & Manning, 2014)也是生成词向量的有效方法,它是一种基于词统计的模型,可使词向量拟合预先基于整个数据集计算得到的全局统计信息,从而能高效地学习词的表征。
其次,随着迁移学习技术的进步(庄福振, 罗平, 何清, & 史忠植,2015),AI科学家尝试构建多语言统一的词向量 (Multilingual Word Embedding, MWE) 方式(Ruder, Vulic, & Søgaard, 2019),也就是在统一词向量空间中表示来自多种语言的词汇。AI科学家尝试采用无监督的MWE方法来获得统一的词嵌入表达,与传统的监督方法相比,这一方法可以利用近似无限的未标注语料库,从而为低资源语言(应用范围比较小,缺乏标注的数据)开辟了许多新的可能性(Conneau, Lample, Ranzato, Denoyer, & Jégou,2017; Zhang, Liu, Luan, & Sun, 2017)。
(二)超越词袋模型
随着计算机对单词表达能力的提升,如何提取文本(例如句子、篇章)中的高级语义信息,是实现自然语言处理任务的关键,例如,基于文本信息的情感分析、问答系统、机器翻译等任务。随着文本提取技术的不断创新发展,自然语言处理的任务性能得到显著提高。早期的词袋(Bag of Words)模型忽略了语句中词语之间的依赖关系。比如,在词袋模型中,“我喜欢苹果,不喜欢鸭梨”和“我喜欢鸭梨,不喜欢苹果”两个句子是相同的表达。深度学习技术对语境和序列信息的捕获能力为语义的理解带来了变革。卷积神经网络(CNN)是早期被采用对自然语言词汇序列进行特征提取的模型,其擅长捕获局部语境信息,然而CNN无法满足语言序列长期记忆性的要求。因而,循环神经网络(RNN)被广泛应用。RNN的执行思路是通过系统中共享的参数进行序列信息的处理(Cho, et al, 2014)。原始的RNN模型容易出现梯度消失和爆炸的问题。因而,经过改良,LSTM和GRU模型(RNN的升级版)开始被广泛应用于各种自然语言处理任务中,它们通过门控制技术极大地提高了各种任务的性能。
此外,注意力机制(Attention)被提出并被应用到机器翻译的任务中,不仅改善了翻译的性能,还增强了模型的可解释性(Bahdanau, Cho, & Bengio, 2014)。2017年,Ashish Vaswani团队扩展了注意力机制,首次提出Transformer模型结构(Vaswani, et al, 2017)。Transformer模型完全去除了编码中的循环和卷积,仅依赖多头注意力机制和位置编码来分析语义信息,使翻译、解析等任务的训练时间大幅缩短。同时,注意力机制的Transformer模型是基于大规模语料库训练的预训练语言模型的重要基石之一,为自然语言处理技术的进一步发展带来重大突破。
(三)基于大规模语料库的预训练语言模型
随着基于大规模语料库的预训练语言模型的出现与不断创新,自然语言处理获得了跨越性发展,它可以实现的任务越来越多元化,并且任务性能更加精确与高效。Sebastian Ruder在2021年公开发表的报告中,对2018年到2020年自然语言处理预训练语言模型的发展进行了总结(Sebastian, 2021),如图2所示,预训练语言模型的发展越来越趋于大规模化。2018年,Alec Radford团队发布了GPT(Generative Pre-training Transformer)语言模型,这是一套人工智能的生成网络模型,可以通过文字、图片、音乐、一段程序或者数据分析结果来智能化生成新的内容。2018年,基于Transformer,Jacob Devlin团队发布了BERT (Bidirectional Encoder Representations from Transformers)预训练语言模型(Devlin, Chang,Lee, & Toutanova, 2018)。2019年,OpenAI发布GPT-2无监督的转化语言模型,它可以基于一个特定的线索,自动编写出文本内容。2020年,Tom Brown团队提出GPT-3语言模型,可以将学习能力转移到同一领域的多个相关任务中,既能做组词造句,又能做阅读理解(Brown, et al., 2020)。2021年,William Fedus团队首次提出一个1.6万亿参数的自然语言处理模型——稀疏激活专家模型(Switch Transformer)(Fedus, Zoph, & Shazeer, 2021)。Switch Transformer 模型的突破在于,它可以在使用相同计算资源的情况下使预训练速度提高7倍以上,同时保证模型质量得到30%的提升。

图2 自然语言处理近期模型规模发展史
由此可知,随着这些自然语言处理关键技术的不断优化,自然语言处理任务逐渐被简化,并实现应用的通用化,这对各领域尤其是智能教育领域的发展产生了重要的影响。数据显示,随着BERT以及BERT衍生模型的快速发展,自然语言处理任务在阅读理解、文本分析、语言翻译、情感分析等应用上都迎来了突破和创新(Matthew, 2020)。这些关键技术的优化发展对开发可以应用在教育领域的智能工具至关重要,因为智能工具可以实现教育系统中各环节要素的自动分析,实施精准干预,支持规模化教学与个性化学习等机制(彭绍东,2021)。因此,自然语言处理技术的快速发展会促进教育领域智能工具的开发,而这些智能工具在学、教、管、评的教育活动中不断创新优化与实践的过程,就是自然语言处理赋能教育智能发展的过程。
五、自然语言处理技术加快赋能教育智能发展
在过去近40年,自然语言处理领域逐渐出现10个研究热度较高的技术话题,包括情感分析、机器翻译、问答、语言模型、神经网络模型、语义表示、知识图谱、词对齐、条件随机场和词义消歧(清华大学,2020),如图3所示。其中,2003 年以后,情感分析的研究热度迅速增长,其基于自然语言处理的数据挖掘技术被应用于提取和分析用户生成语言中的主观信息,而机器翻译、问答系统等技术研究热度也一直保持上升态势。何晓东预测,自然语言处理技术在未来可能会从文本分析、文本创作、情感智能、机器翻译、智能对话(例如语音助手、聊天机器人)等方向取得重大突破;而这些技术方向的发展都与智能教育的未来发展密切相关(何晓东,2019)。具体来说,智能教育也是基于多元化的教育数据进行分析,以了解师生教与学过程中的各种需求,然后提供评估反馈和智能化的解决方案,并应用于“教、学、评、测、练”五大环节(前瞻产业研究院,2020)。结合上文中介绍的自然语言处理关键技术的原理知识,本节将基于AI科学家的研究实例,深入探讨五种在教育领域被广泛应用的自然语言处理技术,以及这些技术赋能教育智能发展的实践与创新。

图3 自然语言处理领域技术研究发展趋势
(一)情感分析与情绪分析
目前,基于自然语言处理的情感分析技术逐渐应用于教育领域。情感分析(Sentiment Analysis)是指利用自然语言处理的文本挖掘技术,对带有情感色彩的文本进行抽取、分析和处理,从而发现潜在的问题以用于预测或改进(Yang, Cunningham, Zhang, Smyth, & Dong, 2021)。郑耀威在2020年的AAAI会议上,提出了新的分析方法,使用语法信息增强了语句多方面情感分类的效果(Zheng, Zhang,Mensah, & Mao, 2020)。情感分析在教育领域的应用是,通过对学生的课程反馈、教师评价、课程论坛评论等文本信息进行分析,智能化预测学生对学校教育教学现状的态度,评估教师授课质量,等等。例如,Heather Newman等人使用情感分析工具VADER分析学校教与学的评价信息,以研究学习环境对改善学生学习的体验,以及对教师教学的体验(Newman & Joyner, 2018)。Quratulain Rajput等人基于情感分析指标,对某课程结束后学生提交的反馈报告进行多种方法的文本分析,使教师教学评估更加高效(Rajput, Haider, & Ghani, 2016)。因此,分析学生对学校政策、教学活动等事件的反馈与态度,可以使教育组织更加了解学生的需求,不断提高教学质量,提供更具个性化的教育环境。
而情绪分析(Emotioin Analysis)主要是分析用户的状态、情绪等(比如高兴、沮丧、失落、抑郁等)(Koelstra, et al., 2011)。情绪分析在教育领域逐渐被应用于学校舆情监督、心理观察等方面。例如,利用自然语言处理系统模型监督学校论坛上的评论、留言等信息,可以实时分析学生情绪,在观测到学生感到沮丧失落的时候,学校可以及时做出安抚和应对措施。Angelina Tzacheva等人基于计算机科学课程学生反馈的评估数据,通过为每个文本注释创建多个标签,自动检测学生反馈中的情绪以了解学生对课堂教学模式的感受,从而帮助教师改善教学(Tzacheva, Ranganathan, & Jadi, 2019)。
(二)文本分类
文本分类是自然语言处理在教育领域应用的另一个重要模块,它旨在通过分配不同的标签对文本信息(例如句子、段落)进行分类。文本信息可以有不同的来源,包括电子邮件、论坛留言、社交媒体、教学评价、教学材料等。自然语言处理的文本分类技术广泛应用于教育领域的不同任务中,包括问题解答、个性化学习推荐、图书馆内容管理、新闻分类、内容审核等(Minaee,et al., 2021)。随着技术的发展,文本分类技术的研究也在不断进步。2020年,阿里云推出的智能文本分类服务,可以按照给定的类目体系对用户提供的文本进行自动分类(阿里云,2020)。邱锡鹏团队提出的多尺度注意力的文本分类方法使语言的理解结果更优化(Guo, Qiu, Liu, Xue, & Zhang, 2020)。随着文本分类模型系统性能的提升,相关的智能工具性能也在不断优化,并被广泛应用于阅读等级分类、作文自动批改等方面。
阅读等级分类是衡量阅读难度的标准之一,文本可读性对于阅读教学材料、教材编排等有重要意义。自然语言处理在教育文本阅读方向的一个重要应用是阅读分级。阅读分级测评体系通过计算机对大量的文本、书籍进行自动处理并分析其难度,然后为不同水平的学习者提供不同难度的学习资料。例如,蓝思(Lexile)阅读测评体系(Ardoin,Williams, Christ, Klubnik, & Wellborn, 2010)基于书籍难度和读者阅读能力两个指标进行分级,使学习者可以轻松选择适合自己的书籍。迷雾指数(The Gunning FOG Index)(Swieczkowski & Kułacz, 2021)是一种针对英语文本的可读性测试,该模型系统可从词数、难度、完整思维的数量、平均句长等方面考察一篇文章的阅读难度,并评估出适合阅读此文章的阅读者的正规教育年限,比如,当读物的迷雾指数为12时,阅读者大概需要相当于高中生的阅读水平。2020年,唐玉玲等人提出结合语言难度特征的句子可读性计算方法,构建了规模更大的汉语句子可读性语料库,提高了评估准确率,优化了汉语材料的可读性应用(Tang & Yu, 2020)。
作文的自动批改评测是智能化对英语写作进行评分、纠错和指导的技术,是自然语言处理与语言教学结合的一个成熟应用。E-rater是一款成熟的智能英文写作评分软件,具有识别英文写作能力的功能,其评分水平与人工评分水平非常接近。校宝在线的1Course是基于人工智能技术开发的语言教学辅助测评系统,可以对写作等语言材料自动化批改、评测,并且给出学习总结与建议。2017年,许悦婷团队对E-rater、1Course等智能评测系统的性能进行对比时发现,E-rater性能仍然处于较高水平(Xu et al., 2016)。科大讯飞研发的RealSkill是针对雅思托福考试的智能批改软件。测试数据显示,Real-Skill的评分与考官评分一致率达96.91%,智能批改准确率达到92.64%,手写文字识别率达到95%(德勤,2020)。董瑞海团队提出了一种新型的、基于自然语言处理和深度学习技术的自动作文评分系统,并证明该系统在成绩预测方面达到了最先进的性能(Wang, Liu, & Dong,2018)。可见,自然语言处理的文本分类技术已经为师生的教与学过程提供了成熟的智能评价、测试、纠正、练习等应用。
(三)问答与对话系统
随着智能机器人逐渐被应用于教育领域,问答与对话系统的性能(例如,准确度、智能化、个性化)优化一直受到AI科学家的关注。问答系统(Question Answering System,QA System)是用来回答用户提出问题的系统,其设计思想是由计算机负责解析并理解由用户提出的自然语言(问题),并从当前收集的所有问答集中检索出最适合的答案返回给用户。目前,基于自然语言处理的问答系统任务的准确性已经可以超越人类水平的基准线,并逐渐达到专家水平。例如,基于斯坦福问答数据集(Stanford Question Answering Dataset,SQuAD)的文本理解挑战赛,就是检验计算机阅读理解水平的权威测试。2018年,Pranav Rajpurkar团队提出SQuAD 2.0,该数据集可以测试模型系统回答阅读理解类问题的准确度(Rajpurkar,Jia, & Liang, 2018)。基于SQuAD2.0官网数据,本文整理了从2018年到2021年,问答系统模型执行能力的变化趋势。如图4所示,随着模型系统的不断升级,一些模型系统获得的精确匹配度(Exact Match,EM)和准确度(F1)分值不断提高,逐渐超越人类水平的基准线(EM 86.831,F1 89.452),并达到了前所未有的新高度(EM 90.871,F1 93.183)(SQuAD2.0, 2021)。刘知远团队提出,基于Babel-Net(一种多语言的百科全书词典)为多种语言建立统一的义位知识库(Qi, Chang, Sun, Ouyang, & Liu,2020),可优化知识库的构建。2021年,严睿团队提出的检查模型优化了回答阅读理解问题的答案生成响应效能(Chen,et al., 2020)。这说明自然语言处理任务在智能化地执行阅读理解和问答测试方面的技术越来越成熟,这些技术衍生的智能工具可以在教育系统中帮助师生提高教与学的效率。

图4 基于SQuAD 2.0的测试结果
此外,对话系统属于多轮次对话的问答系统(例如,聊天机器人)。不同对话系统具有不同的复杂程度,有简单的单行响应对话系统(基于人工模板的聊天机器人),也有复杂的多轮次对话系统(数字语音助手)。现有的检索式对话系统可能会出现忽略上下文相关性而只能回答简单问题的情况,而严睿团队提出的基于预训练语言模型的文本-回复匹配模型,可以显著改善这个问题(Xu et al., 2020)。车万翔团队开发的目标管理模型使开放式对话能够获得更连贯且更有趣的多轮对话(Xu, Wang, Niu, Wu, &Che, 2020)。在个性化对话系统的创新中,张亦驰提出的一种基于多动作数据增强的学习框架,可以有效学习到多样化的对话策略(Zhang, Ou, & Yu, 2020)。黄民烈团队提出的个性化对话生成模型,可以在对话生成的时候控制回复中所展现的个性化属性(Zheng, Zhang, Huang, & Mao, 2020)。而随着自然语言处理中对话系统的不断创新与发展,AI科学家开始将智能对话系统实现在教育机器人领域。例如,麻省理工学院媒体实验室(MIT Media Lab)的Cynthia Breazeal团队设计的“社交机器人”,是可以与人合作的社交、情感智能机器,能满足从孩子到老年人各年龄段新技能的学习和情感需求(Cynthia,2019)。余胜泉团队开发的一个新颖实用的对话系统,专门帮助教师和家长为学生解决德育方面的困扰,可以精确理解用户的问题并实时推荐适合的解决方案(Peng, et al., 2019)。2021年,陈鹏鹤团队设计并创建了一个名为PBAdvisor的智能助手,它可以帮助没有心理学专业知识的老师和家长轻松地就学生的问题行为找到合适的解释方案,并解释问题行为形成的原因(Chen, Lu, Liu, & Xu, 2021)。同年,卢宇团队开发了新型智能辅导系统 RadarMath,以支持智能化的、个性化的数学学习教育。该智能辅导系统可以为学习者提供自动评分、个性化学习指导等服务(Lu, Pian, Chen, Meng, & Cao, 2021)。这些智能对话系统可以在不同的教学环境中提供人性化的交互方式和个性化的智能辅导与教学,可见,基于自然语言处理技术的教育机器人展示了其在未来智能教育发展中巨大的应用前景。
(四)机器翻译系统
机器翻译是另一个广泛应用于教育领域的自然语言处理技术。机器翻译(Machine Translation,MT)是利用计算机将一种自然语言(源语言)转变成另一种自然语言(目标语言)的自动翻译(Russell &Norvig, 2002)。随着技术的不断发展,神经网络机器翻译(Neural Machine Translation, NMT)于2013年被提出(Kalchbrenner & Blunsom, 2013)并迅速发展,它在文本翻译、对话系统和文字概括方面的性能不断得到优化和提升。在机器翻译任务中,双语互译质量评估辅助工具(bilingual evaluation understudy,BLEU)是非常重要的指标。2002年,Kishore Papineni首次提出BLEU指标,其设计思想是机器翻译结果越接近专业人工翻译的结果,模型系统的效果就越佳(Papineni, Roukos, Ward, & Zhu, 2002)。依据2018年斯坦福发布的人工智能年报,如图5所示,在2008年到2018年期间,模型系统在将新闻从英语翻译成德语的BLEU分数是2008年的3.5倍,而从德语翻译成英语的BLEU分数是2008年的2.5倍(Shoham, et al., 2018),这表明了机器翻译性能在过去十年的快速发展。

图5 新闻稿翻译——WMT竞赛
在2020年的AAAI会议上,冯洋团队提出了增强机器翻译的评估方法,对生成的译文从流利度和忠实度两个方面进行评估,以鼓励模型生成与译文有关联的单词(Shao, Zhang, Feng, Meng, & Zhou,2020)。除此之外,刘知远团队提出一种多通道反向词典模型,此模型在中英两种语言的数据集上都实现了当前最佳的性能,并首次实现了中文、英文跨语言反向查词的功能(Zheng, et al., 2020)。刘宇宸团队则提出一种基于交互式学习的方法,该方法能够在一个模型中实现同步语音识别和语音翻译任务,并且效果显著(Liu, et al., 2020)。随着这些机器翻译模型系统的不断进步与创新,它们对智能教育的发展产生了新的影响,例如,翻译狗、谷歌翻译等工具被广泛应用于学生的英文写作与语言学习中(Bin Dahmash, 2020; Tsai, 2020)。Marco Cancino表示,当教师能够意识到在线翻译的局限性,并在学生使用它们时提供足够的指导,那么智能在线翻译工具可以成为有效的教学工具(Cancino & Panes, 2021)。不仅如此,研究表明,使用谷歌翻译进行写作的实验组其写作质量更高,例如,句法复杂性和准确性得分更高(Cancino & Panes, 2021)。Angkana Patanasorn的研究也发现,谷歌翻译对高水平学术论文摘要翻译的可理解性和可用性均处于中上等水平(Tongpoon-Patanasorn & Griffith, 2020)。
通过以上分析可以发现,应用于教育领域的自然语言处理技术仍在快速发展,并不断赋能智能教育的发展与创新。随着智能工具的普及与成熟,越来越多的学生开始自主选择适合自己的智能学习工具,以满足个性化的学习需求。学校教师也开始在教学中应用智能批改、智能搜索、虚拟现实、智能学情分析等智能技术辅助备课、教学以及对学生的评估与管理,以增强课堂的趣味性、有效性和个性化。然而,自然语言处理技术赋能未来智能教育发展的过程中,机遇与挑战是共存的。
六、自然语言处理技术在智能教育发展中的应用趋势与挑战
基于上文的讨论,自然语言处理俨然已经成为智能教育未来发展过程中最重要的人工智能技术。同时,自然语言处理正在结合其他人工智能技术,给智能教育的未来发展带来新的机遇,同时也给传统的教育方法带来了新的挑战。
(一)智能教育未来发展趋势
走向多模态智能化教学 自然语言处理技术正在与其他人工智能技术相结合来一起推动未来智能课堂的建设,实现实体互动课堂、VR/AR课堂、全息课堂等(清华大学,2020)。未来的课堂教学将在传统课堂的基础上,利用视频系统、语音系统、智能终端等多模态智能技术更高效地进行智能互动。其次,由智能技术支撑的课堂将以学生为中心进行互动教学,这能更好地激发学生兴趣、提升教学质量,以适应新时代的教育目标。未来的智能化教学,将基于人脸识别、语音识别、动作识别、情绪识别、眼球识别等多模态技术构建智能课堂辅助系统,并做到课程全覆盖,既能对学生的考勤、课堂表现及专注度进行监测分析,也能对教师的教学质量进行智能评估,即时生成课堂评估报告并快速反馈,教师可及时调整授课内容和方式,以保证高质量的课堂体验,从而形成课上有行为、行为有识别、识别有分析的完整监课闭环(清华大学,2020)。基于人工智能技术,尤其是自然语言处理技术,未来的学习材料将更多元化,文本、语音、图像、视频识别等多模态学习材料将替代单一的文字类产品。教师教学的辅助产品将不仅仅局限于文字类题库,不同媒介(例如音、视、VR、AI、AR等)的产品都可以辅助教学,使智能测评提供不同题型,使教学风格更多样化,从而激发学生的学习兴趣(德勤,2020)。
迈向大规模个性化教育 个性化教育是智能教育时代变革的必然趋势。《教育信息化十年发展规划(2011—2020年)》指出要为每一名学习者提供个性化学习的信息化环境和服务。通过本文的讨论可以发现,基于自然语言处理技术的智能工具可以为师生的教与学提供智能化、个性化的解决方案。未来的个性化教育,将主要建立在师生充分交互的大数据获取基础上。通过对这些教育数据的统计分析,可实现学生个性化评估反馈、以学定教、自动化辅导与答疑,并智能化推荐适合学生的学习内容,以提升学习效率与质量,从而实现大规模因材施教。其次,基于自然语言处理技术的智能推荐系统将更精确地对师生的教与学活动进行赋能,将标准化、专业化的传统教育逐渐转型为个性化、多样化的智能化教育。
教育智能化的战略布局 2020年以来,疫情的蔓延加速了线上线下融合教学模式的普及:以学生为中心,通过智能技术连接线上和线下、虚拟和现实的学习场景,形成智能化教育场景生态,为实现个性化教学新样态提供了基础。在智能时代,教育组织、技术型企业机构以及社会相关部门应该密切沟通,相互合作,在分析人工智能最新技术范式和理念的基础上,明确教育智能化的发展方向,系统审视其应用场景,助力我国教育智能化建设。基于国家对智能时代教育发展的政策支持,结合我国国情,跨领域的合作应该从实践层面分析人工智能与教育系统各要素融合的路径,阐释智能教育理念下未来教育的体制机制、服务模式和治理体系,并形成有中国特色的人工智能教育发展战略布局。
(二)智能教育未来发展中的挑战
完善智能教育理论体系 与传统教育不同,智能教育时代的教学方法、评价模式等都需要进行改进,以建设与智能时代相适应的教育观念与理论。伍红林曾表示,在智能技术支持下,教育学的学科形态和使命都将发生转变,例如,一些新的跨学科分支将产生,并有可能成为研究主流(伍红林,2020)。人工智能的快速发展正在逐步推动教育学基本理论研究的新变化,而教育存在形态的变化可能引起教育学原有研究领域和理论内涵的转换与更新,这将迫使教育学主动对其他学科进行吸收与转化。因此,随着人工智能技术的快速发展,我们应该对传统教育学理论进行完善,抓紧建构适应人工智能时代的教育学理论体系。
加强教育数据治理 随着智能教育系统中自然语言处理技术的不断应用,教育数据的积累已经在一定程度上实现了教与学的自动化和智能化,然而,这其中也潜藏着风险。近年来,智能技术伦理、教育数据安全方面的一些问题受到很多关注,比如,个人数字信息的过分暴露可能会对教师与学生的隐私、安全等造成严重的负面影响(清华大学,2020)。因此,加强智能教育时代的数据治理研究已经刻不容缓。数据治理的能力决定着未来教育发展的水平和布局,所以教育组织应该:(1)搭建智能化数据资产平台,建立数据收集、整合、治理、存储的常态化监控体系;(2)建立有效的数据共享、管理与保障体系,通过对师生行为数据进行梳理,建立全局数据字典,完成数据的标准化和治理化;(3)建设跨校区统一支撑平台,加强统一身份认证、课程认证、学分认证、教师角色定位等问题的治理,保障数据的隐私性。因此,搭建智能教育数据资源及管理平台,构建智能教育大数据的治理体系,是人工智能时代未来智能教育建设的关键路径。
进一步优化教育智能技术 沈向洋曾表示:“人工智能要真正达到人类思维水平,特别是在认知方面,还有很长的路要走。”(沈向洋,2018)尽管人工智能依靠深度学习取得了快速的发展,却仍需要依赖大规模标注的数据进行监督训练,因此,要实现真正的人类智能,计算机还需要掌握大量的常识性知识,以人的思维模式和知识结构来进行语言理解、视觉场景解析和决策分析。刘群曾指出,关于自然语言处理模型系统的学习问题,尽管很多知识点的逻辑推理对人类来说不是问题,但是计算机理解起来却有困难;同时,自然语言处理还面临着标注数据资源贫乏的问题,例如,小语种的机器翻译、特定领域对话系统、多轮问答系统等,都将使自然语言处理在教育领域的应用面临挑战(知乎,2019)。在2021年麻省理工学院的人工智能会议上,Lex Fridman提出希望自然语言处理在未来智能教育的发展过程中可以使常识推理与语言模型相结合,通过上下文信息实现从有限的句子智能写作到包含数千个词语的段落篇章写作(Lex, 2021)。关于其他新兴智能技术,例如,智能教学机器人、脑机接口改善学习能力等,则还需要进一步成熟与优化,并加快应用于教育的智能发展。
