医学信息领域人工智能技术的主题漂移与未来展望
——基于JCR 26本医学信息期刊文本的命名实体识别
2022-10-08徐璐璐杨嘉乐康乐乐
徐璐璐 杨嘉乐 康乐乐
(1.南通大学图书馆,江苏 南通 226019;2.南京大学信息管理学院,江苏 南京 210023; 3.江苏省数据工程与知识服务重点实验室,江苏 南京 210023; 4.南通大学信息科学技术学院,江苏 南通 226019)
医学信息是面向基础和临床医学为基础,融合计算机技术智能化应用为代表的一门新兴交叉学科。其中的智能化释义:事物在网络、大数据、物联网等人工智能技术支持下,具有能动满足人各种需求的属性,推进现代人类文明深度和广度不断发展的拓展趋势。人工智能(Artificial Intelligence)是研究、开发用于模拟、延伸和扩展人类智能的理论、方法、技术及应用系统的一门新兴技术科学,也已成为推动国家持续发展的主要动力,各国(地区)纷纷启动人工智能战略规划,旨在提升国家层面技术创新能力,扩大本国(地区)与其他国家(地区)之间的差异。。
1956年,达特茅斯大学一次会议上,学者们正式提出“人工智能”一词,迈出研究机器如何模拟人类智能活动新课题的第一步。随后,人工智能不断渗透教育、医疗等各个领域,不断刷新人们的想象。自21世纪,人工智能的5个标志性事件相继发生:2004年,美国国防部高等研究计划署举办DARPA机器人挑战赛;2008年,IBM提出“智慧地球”的概念;2012年,深度学习在图像和语音方面产生重大突破,人工智能真正具备走出实验室步入市场的能力;2016年,Google DeepMind开发人工智能程序“AlphaGo”与围棋冠军对决战胜,引起全世界对人工智能的聚焦目光;2020年,生物界“AlphaGo”精准预测蛋白质结构,解决生物学50年来重大挑战,成为显著推动医学信息领域的重大进步[1-6]。
在此时代潮流下,人工智能一步一步地融入了医学信息的各个层面。欧美成为医学信息智能化业界研发应用领跑者,NIH投资320亿美元进行医学信息智能化改造;英国10年投入60亿英镑,建设5个区域、300多家医院和诊所的国家信息化工程[7-8];立足国内,宏观政策层面,2016年国家连续出台《“健康中国2030”规划纲要》《“十三五”全国人口健康信息化发展规划》《关于促进“互联网+医疗健康”发展的指导意见》等[9]。
值得注意的是,医学信息也随着人工智能高技术、高门槛、高附加值的显著特征发生了深刻变革。这些变革主要体现在:一方面,人工智能与医学信息相关产业、政府和社会相互协同并交互升级,创造出新兴的医学生态系统,服务于更为复杂的基因组、细胞学等基础科研和疾病的诊断、治疗及并发症等临床医疗的现实场景之中;另一方面,由于精准医学范式引领和需求不断扩大,医学信息越发依赖于人工智能的各类优化算法和模型,不断改变医生的工作模式,提高医学领域的准确性和效率,创新医疗服务高品质发展,助力医学信息领域各个环节。
综上所述,人工智能在医学信息领域多年来一直扮演着极其重要的角色。21世纪以来,人工智能如何分阶段地步入医学信息领域,主题漂移内容和呈现有何特征和区别,人工智能在医学信息领域的演化脉络又如何对于人工智能在医学信息领域的未来有何展望呢。本研究以2000—2019年20年间的医学信息发展为背景,以人工智能标志性事件为阶段,观察医学信息领域中人工智能技术的整体布局,通过3种深度学习的方法对医学信息领域中人工智能技术进行命名实体识别,并对其进行词频对比统计并深度分析,实现人工智能技术命名实体识别的较优效果。从而深入厘清人工智能技术在医学信息领域的主题漂移特征和规律、重要发展趋势及演化轨迹,并提出3点未来可行性建议以做参考,更可为人工智能技术在其他领域实体识别及其如何发展变迁提供有价值、有意义的科学探讨和研究借鉴。
1 相关研究述评
进入20世纪,焕发活力的人工智能作为一种高效的技术工具,从获取处理基础的基因数据,到调控识别各类蛋白质等网络通路,再到面对复杂临床疾病、文本图像识别及药物筛选等,不断将先进文明的科幻与现实场景加速融合,势在必行地推动人类进入新时代,为医学信息相关领域的重大突破做出了巨大贡献。2004年,国际人类基因组测序组织(IHGSC)在《Nature》上发表一文描述人工智能如何利用强大潜能,建立一个新系统处理大量数据和临床相关解释,从最初的核心项目200个全人类基因组测序(WHGS)项目,扩展到了750个WHG,帮助人类基因组计划走出困境[10]。随后,Pržulj N等和Fortney K等利用人工智能在医学信息领域进行更丰富、更可行的操作,他们将数据信息与各类网络(蛋白质相互作用网络、转录调控网络、microRNA基因网络、代谢和信号通路)整合在一起,识别数据孤岛之间的关系,使用图论算法或知识工具进一步分析和深入了解这些数据与网络结构,进而表征这些蛋白质、转录因子和microRNA的功能,最大限度地提高对转化研究的影响,实现更准确和可解释的建模,增加对复杂疾病的理解,最终支持P4(精准、个性化、参与式、预防性)医学[11-12]。2011年,IBM研究人员利用名为沃森(Watson)的开放智能问答系统来参加比赛,达到了一个具有象征意义的里程碑,即可以梳理电子病历和医学文献(如期刊),为人类疾病做出临床决策,并最终战胜了排名最高的两名人类选手,获得了胜利[13]。2013年,Abràmoff M D等利用Messidor数据库对患者识别眼底虹膜等结构,通过人工智能的计算机检测程序诊断糖尿病视网膜病变(RDR)相关信息,其准确性与专家阅读器的诊断准确性相当[14]。随着模式识别工具数量和数据集大小的增加,人工智能在医学图像相关领域的分析呈指数级增长,2016年,Gillies R J等通过分析复杂系统内生理参数、实验室和影像数据,将图像转换为可挖掘的数据,并随后对这些数据进行分析以提供决策支持,推动智能在线问诊及预测疾病等,支撑各类医学信息及相关研究得以正常运行[15]。2020年,Stokes J M等在《Cell》发文中基于深度神经网络模型引导的人工智能建模先进方法,从庞大的化学文库中预测新的候选抗生素,从而开始有机会影响药物发现的全新范式,扩展对于抗生素库的效用[16]。
基于上述文献回顾可见,人工智能所驱动的相关技术正迅速演化为适用于医学信息领域中精准和高效的解决方案,越来越多地引起学术界的重点关注和聚焦。但是,人工智能在医学信息领域的学术研究仍主要集中于国外文献,且针对某个具体领域逐一地进行探讨,国内文献也相对较少。特别是,鲜有研究能够较为全面地追溯人工智能在医学信息领域的主题漂移,系统探讨其不同的主题特征,并通过时间维度来展示这些人工智能方法在医学信息的发展脉络。因此,很有必要重点聚焦与人类生存和发展密切相关的医学信息领域,着力关注人工智能作为一种“赋能”强大引力,如何不断碰撞、融合、腾飞发展甚至重构医学信息的外延和内涵,促使医学信息在临床和科研工作中愈加发挥不可估量作用。
2 研究设计与方法
针对所提出的研究问题,本文首先采集了医学信息学相关的学术论文。使用论文而非专利的主要原因是,论文更具有前沿性,往往引领着技术发展。通过分析学术论文,更能够把握人工智能技术的发展趋势;其次,通过对论文数据利用VosViwer进行分析,判断该领域人工智能技术发展的时间脉络;最后,使用命名实体相关方法进行主题漂移研究,从细粒度上分析医学信息学领域具体人工智能技术的发展和应用。
2.1 研究思路和框架
首先,本文依据2020年4月30日科睿唯安Journal Citation Reports(JCR)分区中Medical Informetrics类目,确定26本Medical Informetrics英文期刊并获取2000—2019年全部文献题录信息。然后,借助上述2000年、2004年、2008年、2012年、2016年人工智能标志性事件,按照5个时间段全部题录数据,进行数据清洗,利用VosViewer可视化观察人工智能技术在医学信息领域的分布,接着对其进行BIO文本标注,再通过BERT对文本数据预处理,再由CRF、Bi LSTM-CRF和基于Attention的Bi LSTM-CRF 3种深度学习的命名实体方法[17-22],经五折交叉实验对训练集和测试集来训练并识别医学信息领域人工智能技术相关词汇,从而最终对人工智能技术在医学信息领域如何应用和发展,探讨和挖掘相应的主题漂移和演化脉络。整体研究思路和框架流程如图1所示。
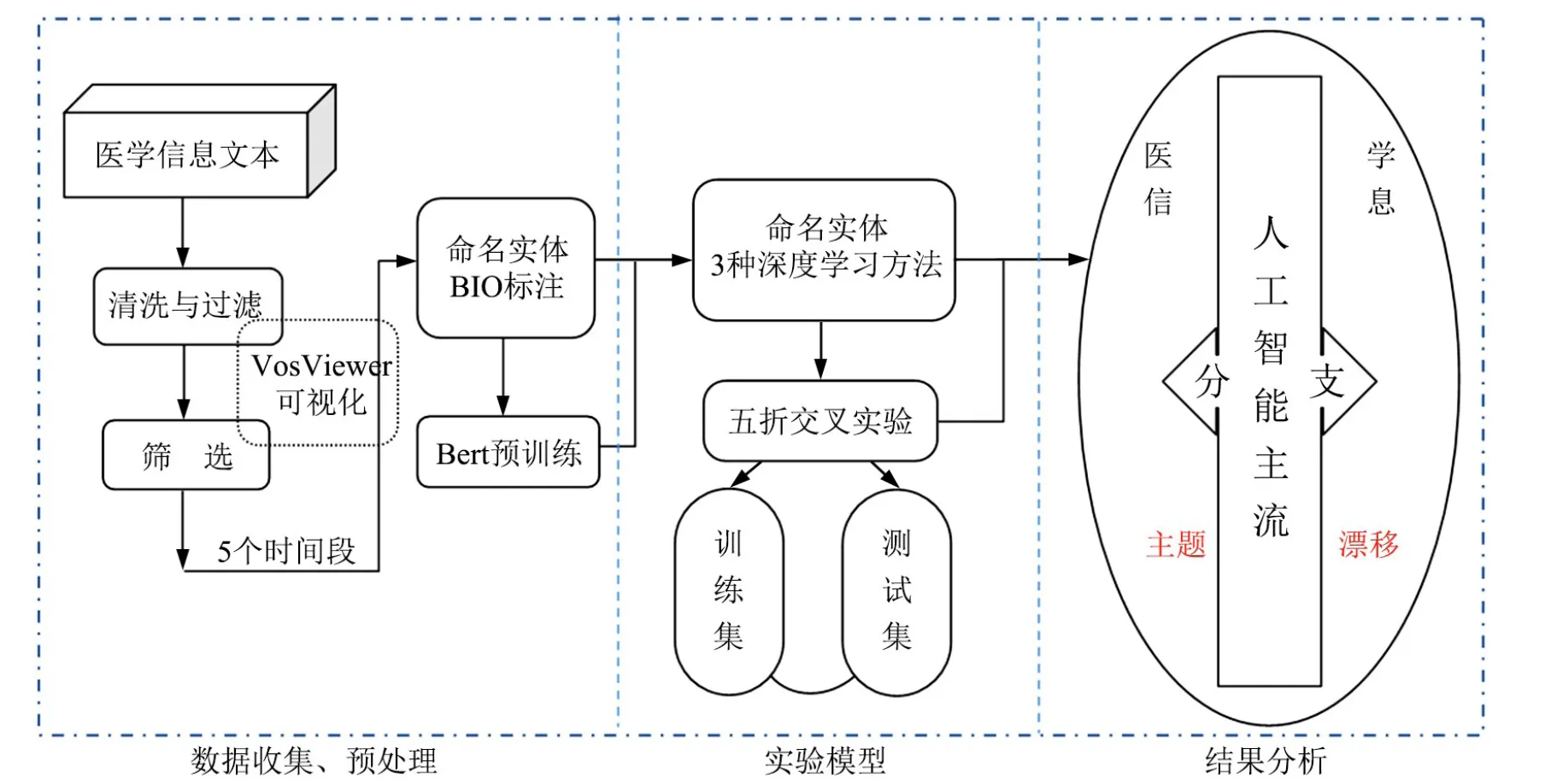
图1 研究思路和框架流程
本文采用Guitub人工智能等合计782个关键词构建本研究的标注词典,词典对数据集进行自动BIO标注,标记序列(“B:开始”,“I:内部”,“O:外部”的缩写)是一种对给定句子中的单元做序列标注的方式,即从给定句子中抽取连续字/词块构成有意义短语,提取类似于命名实体识别经典问题。并且,设计Python程序,利用标注词典对数据集进行自动标注,其中80%训练,20%验证,以人工方式对标注语料进行审核,按照该语料标注方法,构建医学信息领域涉及人工智能技术与方法语料库。
2.2 Bi LSTM-CRF-Attention 3种命名实体识别方法
基于上述剔除英文字母、乱码句段、特殊字符、统一标点符号等,得到人工智能技术相关内容有效文本集含40 124条句子,26 052 241个字符,后本文进行3种深度学习的命名实体识别实验,对有效文本集进行BIO文本标注,后通过BERT对文本数据进行预处理,最后由3种CRF、Bi LSTM-CRF和基于Attention的Bi LSTM-CRF 3种命名实体识别医学信息领域人工智能技术相关词汇,核心步骤和框架流程如图2所示。
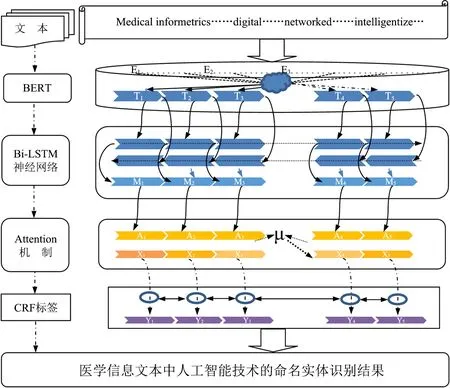
图2 医学信息领域人工智能技术命名实体核心步骤和流程
2.2.1 BERT预训练
任何模型的训练和预测都需要有一个明确的输入,利用语言模型将文本表示为可以被计算机识别的输入是进行命名实体识别重要一步。2018年,提出BERT(Bidirectional Encoder Representation from Transformers),作为Word2Vec替代者,通过双向Transformer的Encoder,捕捉更长距离的依赖,含有词的向量(Token Embeddings)、语句分块张量(Segmentation Embeddings)、位置编码张量(Position Embeddings),将上述3个向量直接做加和形成最终的Embedding向量,在NLP测试中创造了当时的最佳成绩[23-24],如图3所示。

图3 基于BERT的文本向量化表示的示意图
2.2.2 Bi LSTM
模块长短时记忆网络(LSTM)是一种特殊的循环网络(RNN)模型,克服传统RNN模型由于序列过长而产生的梯度弥散问题[25-26],通过特殊设计的门结构使得模型可有选择地保存上下文信息,具有适合命名实体识别的特点,其网络的主要结构可以形式化地表示为:
it=σ(wixxt+wihht-1+bi)
(1)
ft=σ(wfxxt+wfhht-1+bf)
ot=σ(woxxt+wohht-1+bo)
ht=ot⊗g(ct)
其中w代表各个权重矩阵,wix是输入门到输出的权重矩阵,b代表偏置向量,bi是输入门的偏置向量,σ是Sigmoid函数,i、f、o、c分别代表输入门、忘记s门、输出门以及Cell状态更新向量,⊗代表点乘,g、h分别为Cell的输入、输出激活函数,通常为tanh。
由于单向LSTM模型无法同时处理上下文信息,Graves A等提出Bi LSTM(Bidirectional Long-Short Term Memory,双向长短期记忆网络),对于每一个时刻而言都对应着前向与后向的信息,对每个句子分别采用顺序(从第一个词开始,从左往右递归)和逆序(从最后一个词开始,从右向左递归)计算得到两套不同隐层的表示,然后通过向量拼接得到最终的隐层表示[27-28],其中输出ht表示t时刻的输出,具体结构如图4所示。
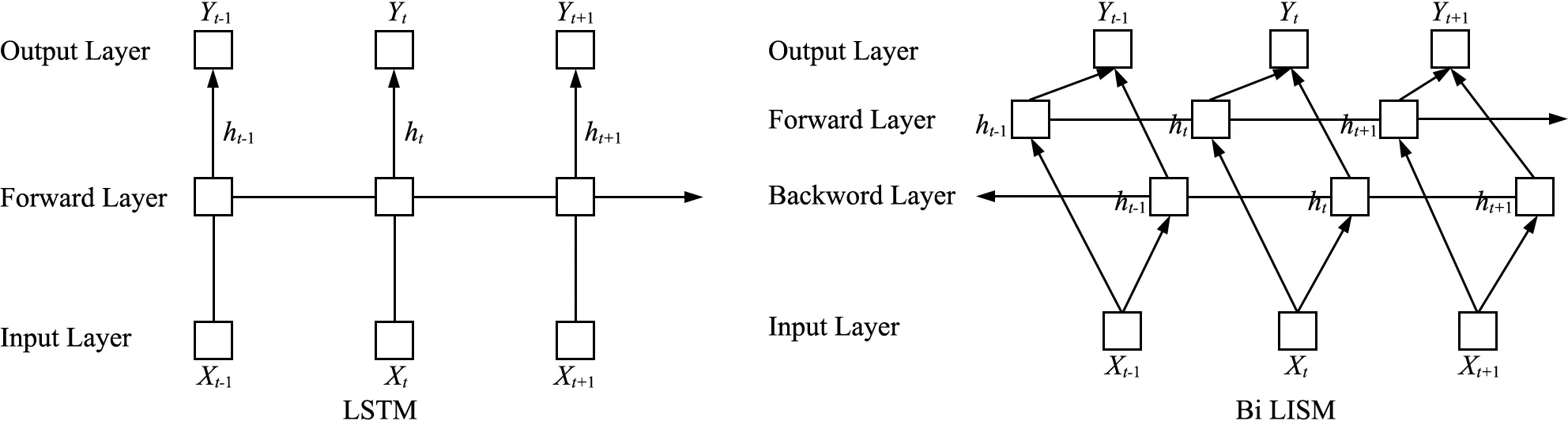
图4 LSTM和Bi LSTM神经网络的结构图
2.2.3 线性CRF模块
命名实体识别任务中,Bi LSTM善于处理长距离的文本信息,但无法处理相邻标签之间的依赖关系。CRF能通过邻近标签的关系获得一个最优的预测序列,可以弥补Bi LSTM的缺点[29],故本文进一步将CRF融合到Bi LSTM模块中,对Bi LSTM输出进行处理,获得全局最优的标记序列。对于任一个序列X,在此假定P是Bi LSTM的输出得分矩阵,P的大小为n*k,其中n为词的个数,k为标签个数,Pij表示第i个词的第j个标签的分数。对预测序列Y(y1,y2,…,yn)而言,得到它的分数函数为:
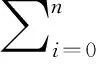
(2)
式中,矩阵A是转移矩阵,例如:Aij表示由标签i转移到j的概率,y0、yn则是预测句子起始和结束的标记,A是一个大小为k+2的方阵。所以在原序列X的条件下产生标记序列y的概率为:
(3)
(4)
其中,YX表示所有可能的标记集合,包括不符合BIO标记规则的标记序列。通过式(4)得到有效合理的输出序列。预测时,由式(5)输出整体概率最大的一组序列:
(5)
2.2.4 Attention机制
2014年,Bahdanau D等在论文中第一次提出把Attention机制应用到神经网络机器翻译上[30],其通过模仿人类注意力而提出一种解决问题的办法,从大量信息中快速筛选出高价值信息,保留LSTM的中间结果,用新的模型对其进行学习,并将其与输出进行关联,从而达到信息筛选的目的。在Bi LSTM层之后添加Attention层,用矩阵T来计算当前目标字与输入文本中所有字的相似性。注意力权重系数tj(矩阵T的第t行第j列)表示第t个目标输出与第j个输入的相似性,tj值越大,表示在生成第t个输出的时候受第j个输入的影响也就越大,计算如下:
(6)
(7)
stj被定义为括号中的两种形式,分别表示为欧式距离,为b-a的值,当xt和xj越相似的时候,余弦距离的值会越大,相反,欧式距离值会越小。
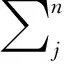
(8)
用一个全局变量ut表示解码阶段的第t时间序列,hj为Bi LSTM层的输出编码的权重之和,如下:
zt=tanh(wu[ut;ht])
(9)
将全局变量ut与Bi LSTM层的输出ht合并成一个向量[ut;ht],再将其喂给一个tanh函数作为Attention层的输出。
在Attention层之后用一个tanh层预测神经网络输出的标签得分:
在超声的引导下,甲状腺结节粗针穿刺活检能够准确的诊断出结节的良性与恶性,且因粗针穿刺组织取样足,检测成功率高,对甲状腺CNB的诊断精准性高,并发症的发生率低,值得大力推广。与细针穿刺相比,粗针活检取出的组织充足,在病理分析的难度上明显低于细针的细胞学分析,更易于在基层医院开展。
et=tanh(wezt)
(10)
总之,自底向上:①长度为N的输入序列将获得的3种不同的向量表示,分别为:Token Embeddings表示词的向量;Segment Embeddings表示辅助BERT区别句子对中的两个句子的向量;Position Embeddings让BERT学习到输入的顺序属性;②利用Bi LSTM获取每个词长距离的上下文特征;③CRF层考虑单词标签之间的制约关系,加入标签转移概率矩阵,给出全局最优标注序列;④最后引入Attention模型对Bi-LSTM层输入与输出之间的相关性进行重要度计算,根据重要度获取文本整体特征,有助于取得更好的性能指标。
3 实验设计和结果分析
3.1 实验数据和预处理
本文依据上述科睿唯安JCR分区中Medical Informetrics类目中确定26本相应英文期刊并获取2000—2019年全部文献题录信息,将21世纪以来的20年数据划分5个时间段(2000年、2004年、2008年、2012年、2016年人工智能标志性事件),并利用VosViewer软件提取共现关键词清晰可见:2000—2003年model、models、meta-analysis、longitudinal data等;2004—2007 年model、models、logistic regression、longitudinal data等;2008—2011年model、models、algorithm、clustering等;2012—2015年model、models、regression、networks等;2016—2019年 model、models、machine learning、automatic detection等。20年来,医学信息领域人工智能技术的发展大致围绕模型、算法与聚类分析(model、algorithm、clustering),临床前期研究(meta-analysis),临床实验和数据管理(clinical trail、longitudinal data、networks),机器学习和自动化技术(machine learning、automatic detection),大规模流行病预测(prediction)等方面,可视化结果显示人工智能技术明显簇拥于虚线区域并在医学信息领域持续占据重要地位,具体如图5所示。
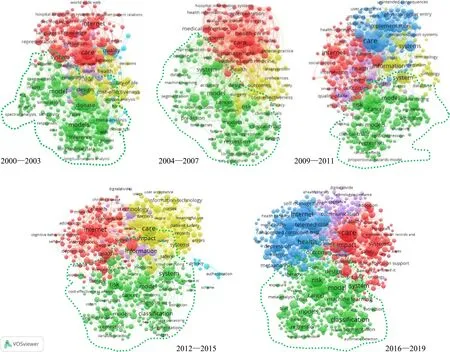
图5 2000—2019年5个时间段医学信息领域关键词的总体分布占比
3.2 实验平台
本文中医学信息人工智能技术语料处理利用Python程序存储Google云端硬盘,采用计算平台为Google Colaboratory,提供免费云端Jupyter Notebook环境,支持Python 3.8运行,使用GPU便于硬件加速,实验平台参数Tesla K80,NVIDA驱动版本418.67,CUDA版本10.10,显存11.00GB。字符向量化由Google BERT训练得到,通过多轮测试,语言模型及序列标注模型参数设置暂定为表1所示。编写Python程序调用Kashgari开源框架中的BERT-Base Uncased_L-12_H-768_A-1模型进行Bi LSTM、Bi LSTM—CRF和基于Attention机制Bi LSTM—CRF的3种实验方法。
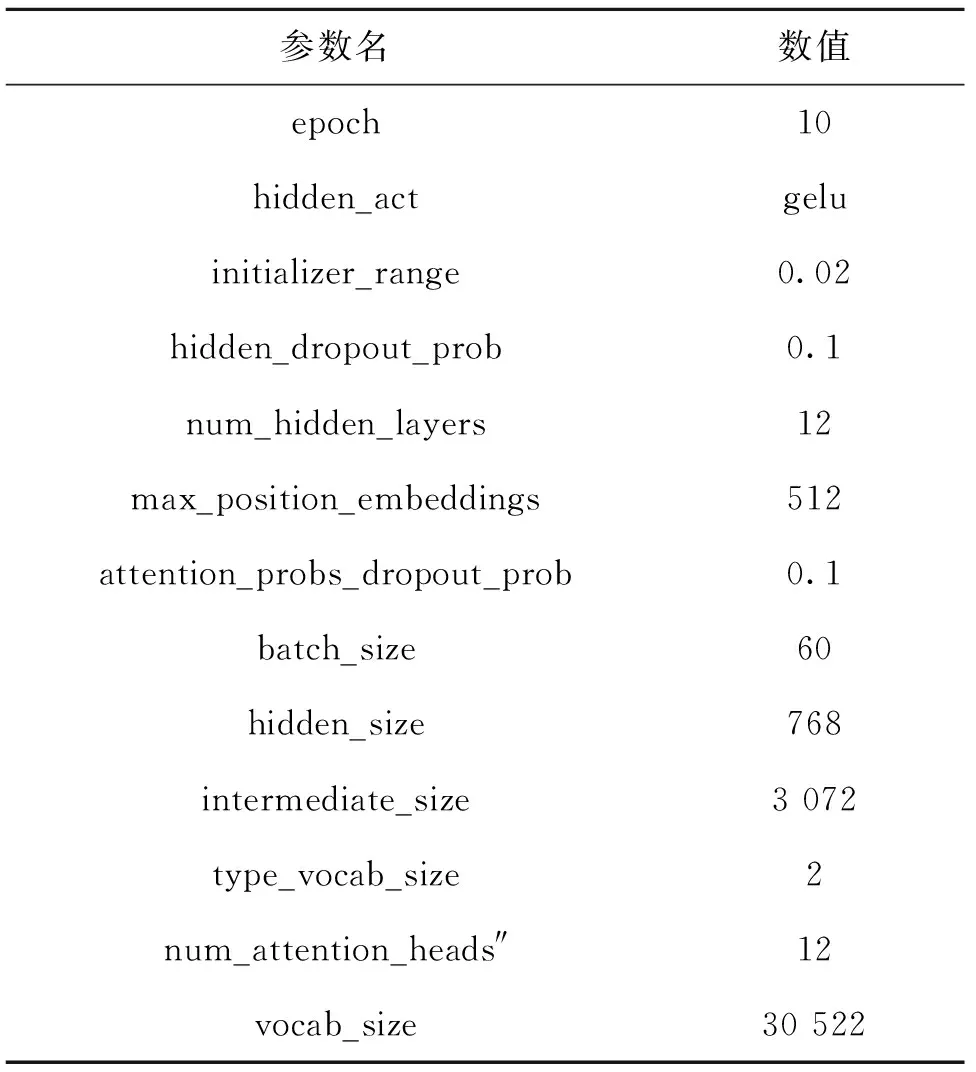
表1 3种深度学习模型的参数
3.3 结果分析和解读
3.3.1 3种命名实体结果对比
在这项研究中,对于所抽取出来医学信息人工智能技术的实体知识,本文主要采用准确率(Precision,P)、召回率(Recall,R)、F1值(F-Measure)这3个指标进行判定Bi LSTM、Bi LSTM-CRF和基于Attetion机制Bi LSTM-CRF 3种模型性能。使用F1值评分来评估模型的性能,同时考虑精度和召回率。将实验语料按照4∶1比例划分出训练集和测试集。采用五折交叉验证的方法,每次实验随机选择其中4份进行训练,余下1份进行测试,对5次实验的结果求平均值,结果如表2所示,具体计算公式如下:
表2 医学信息领域人工智能技术的3种命名实体实验结果
(11)
(12)
(13)
从表2可以看出,本研究在不使用任何人工特征的情况下,基于BERT模型为输入的深度学习模型在医学信息领域中人工智能的实体识别任务上,避免传统机器学习方法导致系统成本提升、泛化能力下降的不良后果,获得了比使用大量丰富特征和领域知识的浅层机器学习方法相对理想的性能结果。特别是,后两种深度学习模型相对更为优化,得益于双向长短时记忆网络拥有两个相反方向的并行层特征,能够同时考虑上下文信息。第二种模型Bi LSTM-CRF的准确率均值提高到89.04%,召回率均值提高到75.60%,F1值均值提高到81.61%;第三种模型Bi LSTM-CRF-Attention的性能整体上更优,准确率提高到89.08%,召回率提高到88.13%,F1值提高到88.40%。
尤其是第三种模型,不再仅以简单词向量,使用BERT语言模型通过3部分Embedding求和组成来对文本进行特征训练取得更好输入,利用Bi LSTM提取上下文信息,避免丧失连接到远处信息的能力,同时结合CRF模型提取全局最优序列,继而通过Attention机制,提炼那些比较重要的单词,赋予权重以提高他们的重要性,处理文本分类的相关问题具有较好的效果,该方法可以聚焦到最重要的词,从而捕获到句子中最重要的语义信息。在一定程度上,说明集成了链式CRF模型后,能够充分利用相邻标签之间的关系特征,考虑上下文的关系,并利用Attention机制本质加权求和,从而比较稳定地提高了整个序列化标注的性能,最终识别医学信息领域人工智能技术相关命名实体,从而为进一步准确地分析医学信息领域中人工智能技术的主题漂移不同特征和发展脉络提供重大帮助。
3.3.2 主题漂移的结果分析
基于命名实体识别结果,本文把20年来在医学信息领域的人工智能相关技术进行词频统计,用于探索与寻找在5个时间阶段中人工智能在医学信息领域的主题漂移特征规律和演化轨迹。
1)人工智能的主题漂移轨迹主流相对稳固——高、中频关键词
通过词频统计发现,高频次(1~5)排名前3位的一直集中是回归(Regression)、分布(Distribution)和计算程式(Algorithm),即医学信息领域涉及的人工智能方面的主要技术较为稳定,改变并不明显。中频词(6~10)选取有特征性,如:精确(Precision)、干预(Inference)、假定(Hypothesis)、聚类(Clustering)、零散值(Odd)、ROC曲线、准确性(Exact)等,总体也相对集中稳定,且变化不大,代表性举例结果如表3所示。
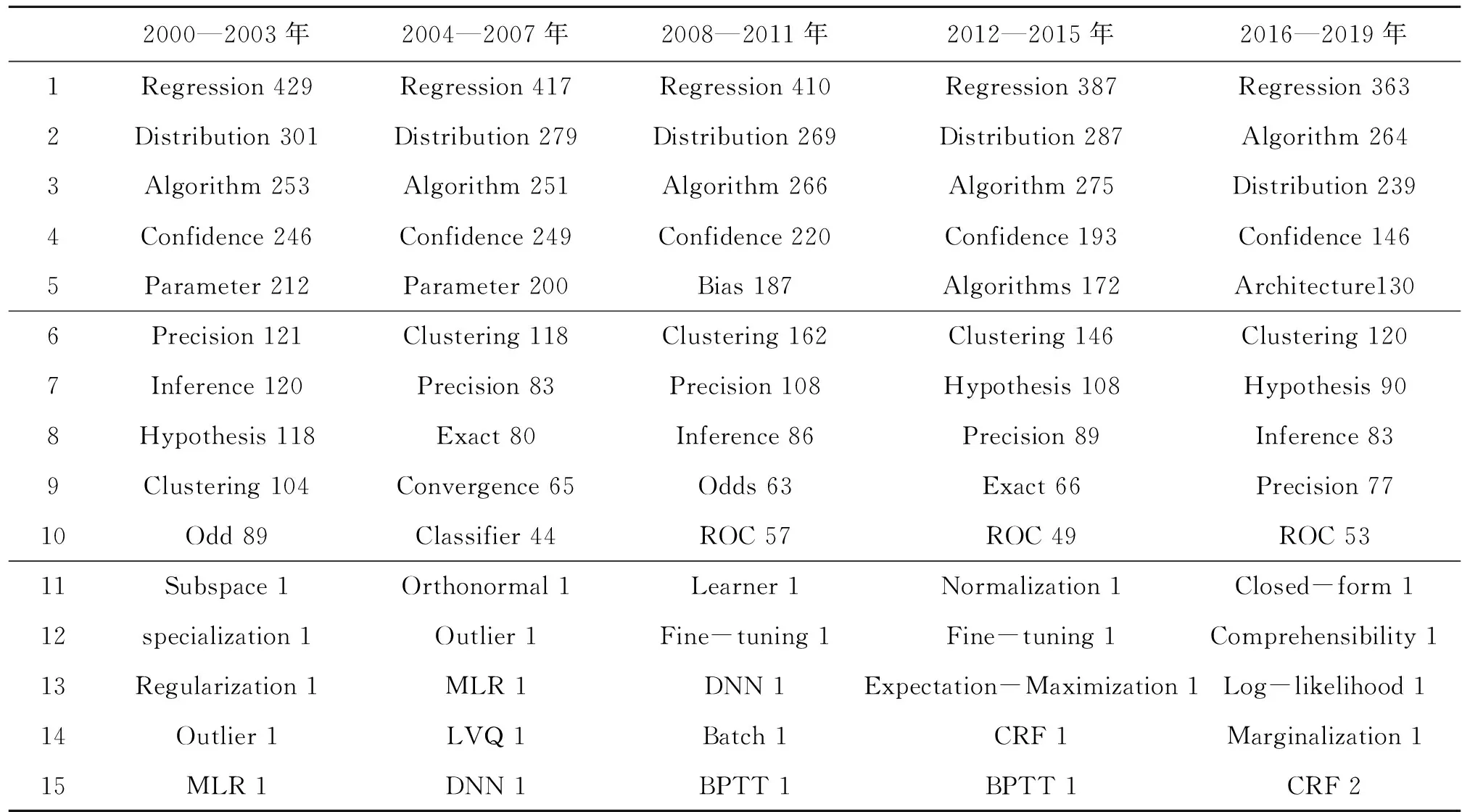
表3 具有代表性意义医学信息领域人工智能技术的高、中、低频词
由此可见,自21世纪以来的20年,人工智能在医学信息领域历经多年的碰撞和磨合,高频词较为集中地围绕在运用各种简单回归(Regression)等模型,同时中频词也相对稳定地使用聚类、假设等算法。同时,这些持续占比较重的高、中频词,正是相对比较传统型的人工智能技术,20年来一直持久并深入地应用于医学信息领域的各个方面,相对固定且变化并不明显。也就是说,人工智能的主题漂移轨迹主流呈现出尚缺乏带动性、爆发性的超级应用融入基础和临床医疗领域,整体技术和研究流程依旧保持成熟稳固的风格,进入比较理性和务实的主题状态。
2)人工智能的主题漂移轨迹分支确有变化——低频关键词
基于上述高、中频词的观察和分析可见,医学信息领域人工智能的主题漂移轨迹主流集中于基础性相关技术,整体进入相对理性和务实状态。进一步基于5个时间段进行命名实体识别训练,并对医学信息领域人工智能技术低频词进行词频统计(11~15),却呈现不同的结果:2000—2003年离群值(Outlier)、机器学习之则化(Regularization)、多元线性回归模型(MLR)、向量子空间(Subspace);2004—2007年多元线性回归模型(MLR)、深度神经网络(DNN)、学习向量量化(LVQ);2008—2011年深度神经网络(DNN)、随时间反向传播(BPTT)、BERT模型及微调(Fine-tuning);2012—2015年最大期望(Expectation-Maximization)算法、标准化(Normalization)算法;2016—2019年最大似然法(Log-likelihood)、边缘化算法(Marginalization)、条件随机场模型(CRF),详见表3结果。
由此可见,低频词变化从多元线性回归模型,到深度神经网络、学习向量量化,再到各种标准化算法、边缘化算法、BERT模型等,人工智能技术在医学信息领域明显表现出由机器学习过度较为复杂深度学习的主题漂移分支特征。由于人工智能中具有难度的深度学习等相关技术尚未能高频、全面使用,故对于其在医学信息领域可能产生突破性的成果依然存有大量空间且尚需努力。因此,本文继续对于低频词的典型性事例从主题、对象、方法、技术、目的和效果归纳如表4所示。
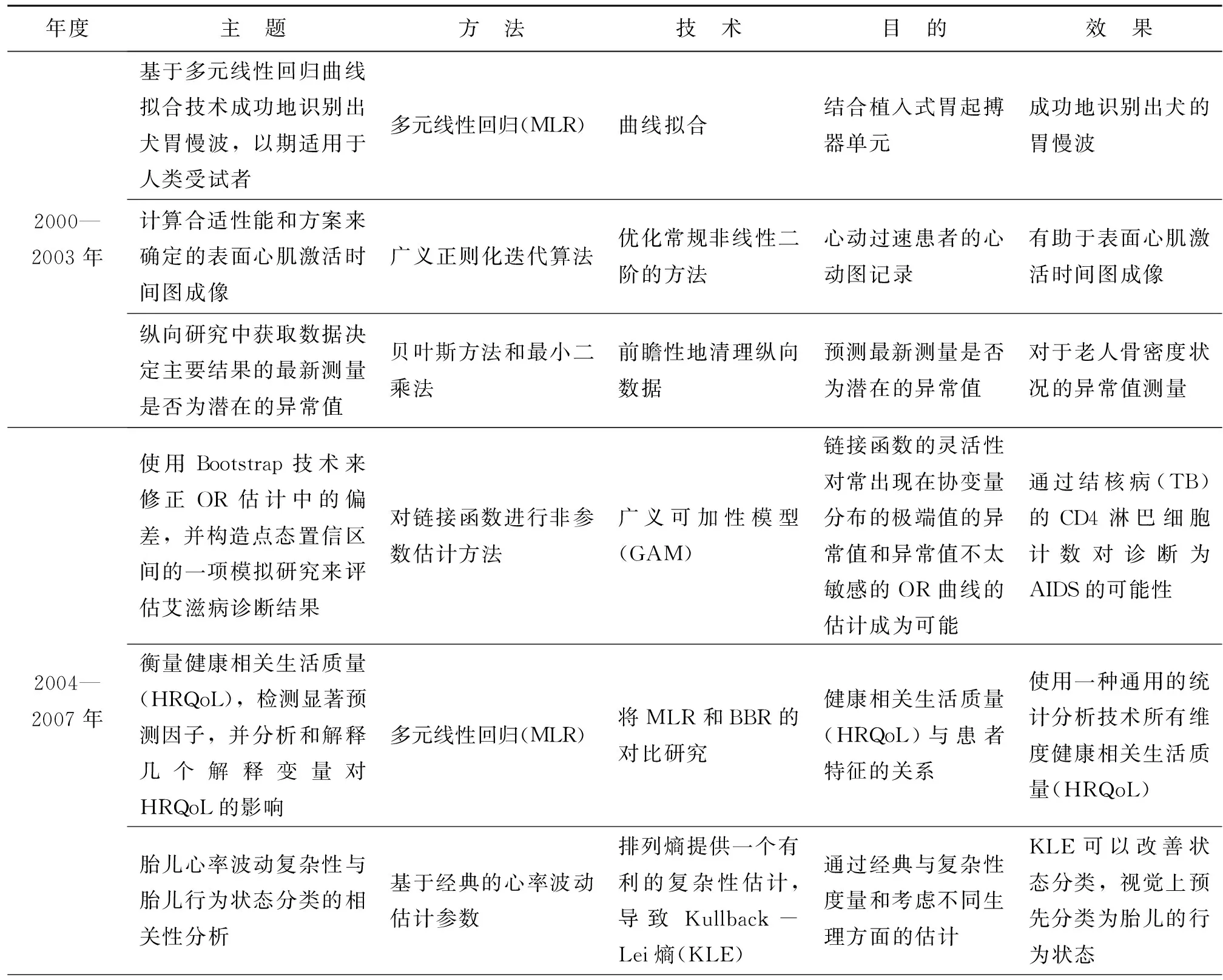
表4 人工智能技术在医学信息领域低频词的典型性事例
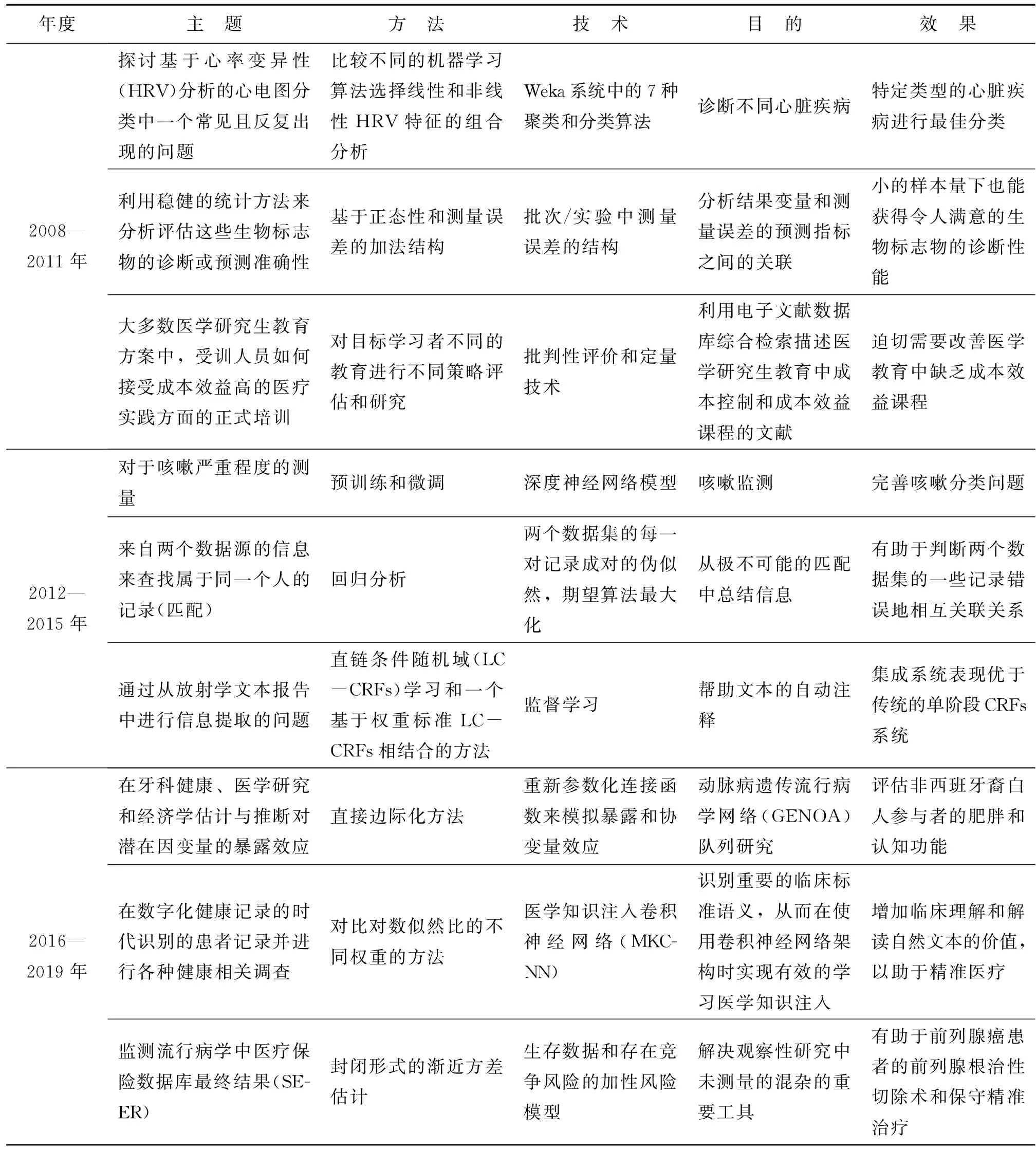
表4(续)
3)主题漂移部分呈现直觉→支持→策略→后推理→前推理发展趋势
通过上述人工智能技术的低频词典型性举例的变化,清晰可见其由浅入深地融入医学信息相关领域之主题漂移的部分发展趋势:①从选取动物进行实验,早期运用回归模型处理简单事实的经验知识,生成简单的规则,得出某种医学结论;②逐渐发展为面对多个及特殊问题,通过对病患至少两种以上的数据进行分析,为医生给出相对准确的诊断建议;③充分利用数据,利用各种回归模型,对误差进行分析,处理复杂问题,让医生再结合自己的专业进行判断,使诊断更快、更精准;④基于已经掌握的数据和事实,运用标准化算法不断地将各类信息进行多次加工整理,前推理地形成相应的医学知识,进行分类、分析关联关系,实时辅助医生医疗决策;⑤在数字健康时代,当事实于结果并无确定关系,利用文本数据、各种数据库等多元性的数据,为医学知识注入卷积神经网络,借助人工智能里边缘性的多源算法,为医生提供可信度较高的后推理,进行各种健康管理,提高生活质量,延伸至精准医疗。
情报学领域经典理论是由事实(Facts)→数据(Data)→信息(Information)→知识(Knowledge)→智能(Intelligence)5个链环构成的信息链,即它是以信息为中心环节,描述信息运动的一种逻辑构造。而上述医学信息领域中人工智能技术低频词的发展规律部分呈现,直觉(经验发掘)→支持(深入理解)→策略(强化分析)→后推理(支撑决策)→前推理(提前预测),清晰可见其主题漂移的演化脉络,这与情报学领域经典理论“信息链”的完整逻辑链不谋而合[31]。也就是说,人工智能相关技术通过直觉感受可感事实信息→自动理解数据并接收认知信息→系统化、有逻辑地、有策略地分析既可感又可知信息→基于各种客观信息的升华后做出决策→智能掌握分析海量数据并传递信息提前预测,逐步发挥不可替代的重要作用,覆盖诊前、中、后全流程,极大促进医学信息及相关领域的成熟,步步助力精准医学的飞跃顶端,如图6所示。
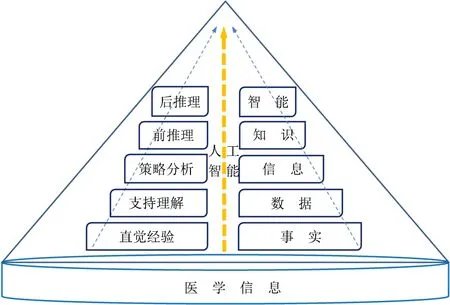
图6 人工智能技术在医学信息领域中主题漂移的部分发展趋势
4 建议与结论
综上所述,基于5个人工智能在医学信息领域具有不同主题漂移特征和演化趋势。一是,高、中和低频词基本集中于较为传统型的人工智能技术,低频词分阶段涉及不同类型的深度学习等较为复杂性人工智能技术;二是,高频词变化小,最为稳固,中频词整体相对稳固,低频词随着不同阶段确有一定程度改变;三是,人工智能在医学信息领域中主题漂移的演化脉络呈现总体相对稳固尚未能发生颠覆性的变革,但部分呈现直觉(经验发掘)→支持(深入理解)→策略(强化分析)→后推理(支撑决策)→前推理(提前预测)的发展趋势。
由此可见,目前医学信息领域中人工智能尚处于弱人工智能时代,尚未完全具备沟通、引领、创新及突破的承载功能。未来,期望通过人工智能技术来挖掘医学信息领域强大内在功能和多样异质特征,以最新研究技术和方法推动其进步与发展,有望将医学传统疾病检测、诊断和治疗转变拓展为以数据为导向、面向技术的学科引领与创新,取得与人类智能相媲美的成就。因此,根据上述人工智能在医学信息领域主题漂移主流和分支不同特征和演化脉络,现有3点展望和建议,以供参考和验证。
4.1 技术层面:更好理解人工智能的优、缺点处理复杂问题
在技术层面上,全面系统地学习人工智能各类方法,将传统型的技术更好地发挥和应用于医学信息领域。AlphaGo最主要研发人员David Silver博士曾经表示:强化学习+深度学习=人工智能。基于学习充分理解人工智能现状优势和潜在局限,将狭义人工智能通过“学习如何学习”,把人工智能传统型的技术优化为更具有广泛价值及通用人工智能,继而对其进行有效选择,通过单个项目到多任务地实战演练和掌握处理复杂性和多样性的医学数据。一步步深刻理解人工智能全方位的特殊性质,不断强化学习和自我对弈来提升人工智能的传统技术,更好理解其优、缺点,才能构建丰富的医学领域知识库,合理利用、分类选择、预测结果,获取更公平、更少偏见的决策。也只有这样,才能从根本上利用人工智能中传统型技术更好地处理医学信息领域复杂问题和任务。产生令人印象深刻的翻天覆地的变化及突破,从而打开通向卓越医疗保健的有效途径。
4.2 应用层面:更精准地挖掘多源数据提供优质医学诊断
在应用层面上,不断开发具有复杂性的人工智能技术,将其更精准地应用于医学信息领域。由于医学信息数据可分为大量结构化数据(例如,国际疾病分类代码、实验室结果和药物),非结构化数据(医师笔记、大多数记录的数据),以及各类数据的产生真实世界证据(关于医疗产品的使用、潜在益处或风险的临床证据)。对于结构化数据完全可用现有科学技术进行全面处理,但对于非结构化数据和各类数据产生的证据则需要进行更为复杂的处理,人类光靠自己是做不到的。因此,不断开发具有难度和深度的人工智能技术,搜集大量外部数据信息,进行患者检查、数字格式保存、收集和分析病历、药物治疗、处理各类大型数据集等,并将其转换为可分析的格式,确保一定程度的准确性和可靠性,通过不带有个人情绪和环境影响的人工智能技术,引出各类数据和证据更为深刻的内在含义,大量减少漏诊与误诊的几率,分门别类地精准执行医学任务。人工智能技术不断提升和拓展,给予医学信息领域强大赋能,提取具有异质症状的疾病本质,获得更高质量决策应用和监督管理,有助于对基础研究和临床诊断提供优质解决方案。
4.3 并行层面:更高的业务效率驱动富有成效的可持续互动
基于实践驱动和理论方法并行为特征的双向层面,人工智能技术的不断深入和互动于医学信息领域。一方面,利用人工智能技术的精细化、多样化手段进行患者检查,创新针对性、个性化的疗法,尝试独特用药及外科手术治疗,帮助复杂医疗案件做出相对高效的优化决策和精准治疗;一方面,人工智能赋予医疗行业更可靠的技术,借助人工智能技术预约、跟踪、检测、调查在线患者,对健康预测提供便利和支持,普及到每家每户,让人们足不出户做到日常预防监测,这样不仅能够提升医疗人员的工作效率,也从源头上节约了医疗成本;另一方面,随着人工智能扩散到医学信息各个领域,务必利用其强大的先发优势预测解决数据隐私、数据安全、数据保护等潜在危险及社会影响,可持续性地对人民群众身心安全起到强有力的保障作用。
自21世纪以来,医学信息领域不断壮大、发展和挑战,人工智能技术不断更新、嵌入及融合。基于医学信息领域的人工智能技术现有整体相对稳固,但尚缺乏颠覆性变革的现状,部分呈现直觉(经验发掘)→支持(深入理解)→策略(强化分析)→后推理(支撑决策)→前推理(提前预测)的发展趋势。未来期待通过上述技术、应用及并行层面的3点展望,以人工智能强力崛起高技术、高门槛、高附加值的显著特征,呈现从单一简单到复杂多样地整理分析现实生活中的医学信息,优化临床策略和精准治疗,协调医学信息整体规划,开发提供健康预测,制定相关国家政策法规等,迈向具有革命性影响且意义深远的美好未来。
