面向遥感图像的建筑物轻量化语义分割方法
2022-10-01王一琛王海涛钱育蓉
王一琛,刘 慧,王海涛,钱育蓉+
(1.新疆大学 软件学院,新疆 乌鲁木齐 830046;2.新疆大学 信息科学与工程学院,新疆 乌鲁木齐 830046;3.新疆大学 新疆维吾尔自治区信号检测与处理重点实验室,新疆 乌鲁木齐 830046;4.新疆大学 软件工程重点实验室,新疆 乌鲁木齐 830046)
0 引 言
基于遥感影像的建筑物解译在城市规划、地图服务、自动驾驶、商业规划、变化检测等方面应用,语义分割在遥感图像解译中扮演重要角色,是低高层遥感图像处理及分析的重要衔接[1]。语义分割是一种图像像素级标注技术,指为图像中的每一个像素分配对应的像素标签,基于这些像素标签将图像分割为若干具有语义信息的区域[2]。
近年来,使用场论和集合论的语义分割方法[3-6]建立在数学模型的基础之上,不同数据集上结果相差较大。Long等[7]提出的FCN模型将端到端的卷积神经网络框架结构引入语义分割任务中。基于编码器-解码器[8-11]和基于候选区域[12-15]的方法现在被广泛使用,由于遥感图像易受到类别分布不平衡、建筑物边缘细节信息难以分割等因素的影响,Minh[16]使用卷积神经网络对道路和建筑物进行检测。Li等[17]将密集连接添加到U-Net模型的编码器和解码器之中。Zhang等[18]使用层次密集连接的网络用于提高网络提取图像特征能力。近年来注意力机制也被应用在遥感图像语义分割领域,将注意力机制加入网络以提升模型的灵敏度并降低无关区域的影响[19,20]。上述模型通过对模型添加密集连接模块或注意力机制的方法用于增加图像分割质量,但也随之增大了模型参数量,难以在大规模部署和实时环境下进行有效的应用。针对遥感图像地物信息复杂导致模型分割完整度低和模型参数量大的问题,本文设计了以编码器-解码器为结构的轻量化语义分割模型LED-Net。
1 LED-Net
1.1 LED-Net结构
为了使网络得到更准确的分割结果图和更少的模型参数量,LED-Net采用端到端的编码器-解码器结构,结构如图1所示,输入图像经过网络可以直接得到分割结果图。
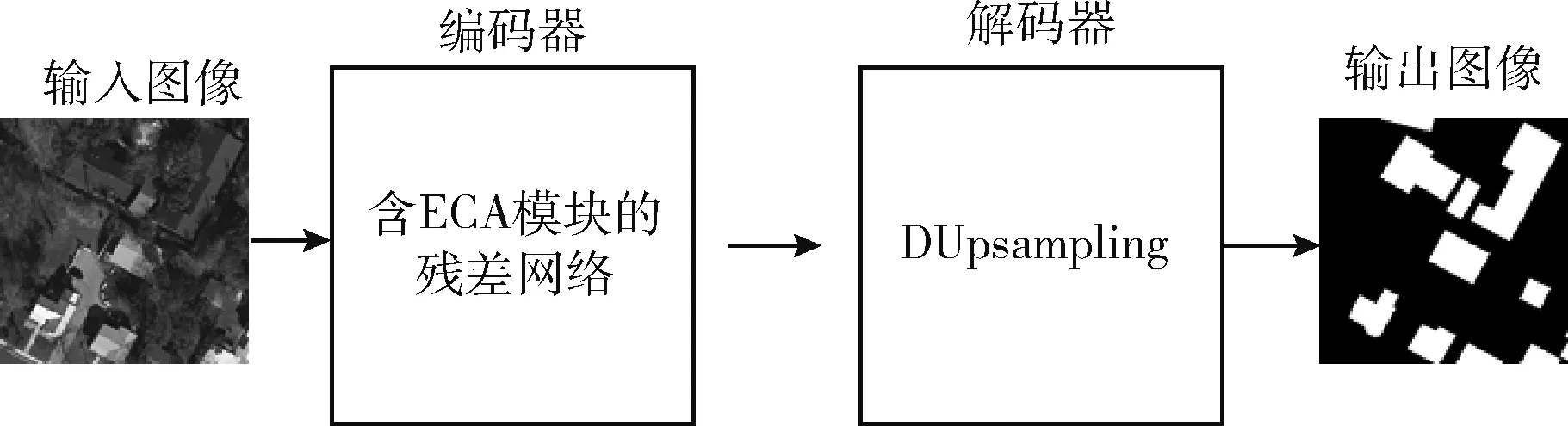
图1 LED-Net结构
在编码器部分使用含有通道注意力机制的ResNet网络用于图像的语义信息提取,提高模型对于建筑物的特征提取能力;为了使结果图得到准确的建筑物分割预测,解码器部分使用轻量化的DUpsampling模块将编码器生成的特征图进行解码操作,生成最终的预测结果。
1.2 高效通道注意力残差网络
语义分割编码器中的骨干网络可以自适应地从输入图像中学习到图像的类别信息和位置信息,网络提取特征的能力影响最后分割结果的精度和性能,语义分割基于编码器-解码器结构的模型中,通过添加注意力机制的模块用于进一步提升模型获取特征图能力[21]。注意力机制主要分为通道(channel)注意力机制和空间(spatial)注意力机制,通道注意力机制相较于空间注意力机制,参数量少,节省网络运行时间。
ECA-Net[22]中的通道注意力ECA模块通过一维卷积来获取特征图中通道间的交互信息,这种模块在图像分类和目标检测领域被证明能提升网络特征提取能力并且不会增加过多的额外参数,ECA模块可以由式(1)~式(3)表示
(1)
式中:Ic为输入的特征图,c为输入模块内的通道数。式(1) 将H×W×C的特征图通过Fga全局平均池化模块进行全局平均操作,其中H、W、C代表特征图的高、宽、通道数量,输出Zc特征图的大小为1×1×C
Qc=σ(Dk(Zc))
(2)
式中:Dk代表为一维的卷积核,k为卷积核的大小。σ为Sigmoid激活函数。特征图Zc经过卷积和Sigmoid激活函数之后得到各通道的权值Qc
Oc=Ic·Qc
(3)
式中:将注意力模块的输入特征图Ic与通道权值Qc相乘,最终得到与Ic大小相同的输出特征图Oc。
LED-Net采用改进的ResNet网络作为骨干网络,去除了ResNet中的全连接层,并在其中加入ECA模块和空洞卷积,网络结构如图2所示。高效通道注意力残差网络主要由1个7×7卷积、1个最大池化层(Max Pooling)和4个高效通道注意力残差块(efficient channel attention residual block,ECARB)构成。每个ECARB进行不同数目1×1、3×3的卷积(convolution,Conv)操作,每个Conv由BN(batch normalization)、ReLU(rectified linear unit)和卷积核(Convolution Kernel)共同组成。通过ECARB使得网络的每一层都可以获得前面传递下来的特征图,实现特征传递,提高每层之间像素特征和梯度流的传递。由于语义分割任务与分类任务的不同,语义分割任务需要进行上采样恢复到与输入图像分辨率相同的大小,并兼顾图像分割目标的类别信息和位置信息提取,与PSPNet[23]和DeepLabV3+[24]网络相同,本文在ResNet的第3个和第4个ECARB中将标准3×3卷积核的空洞率分别改为2和4。
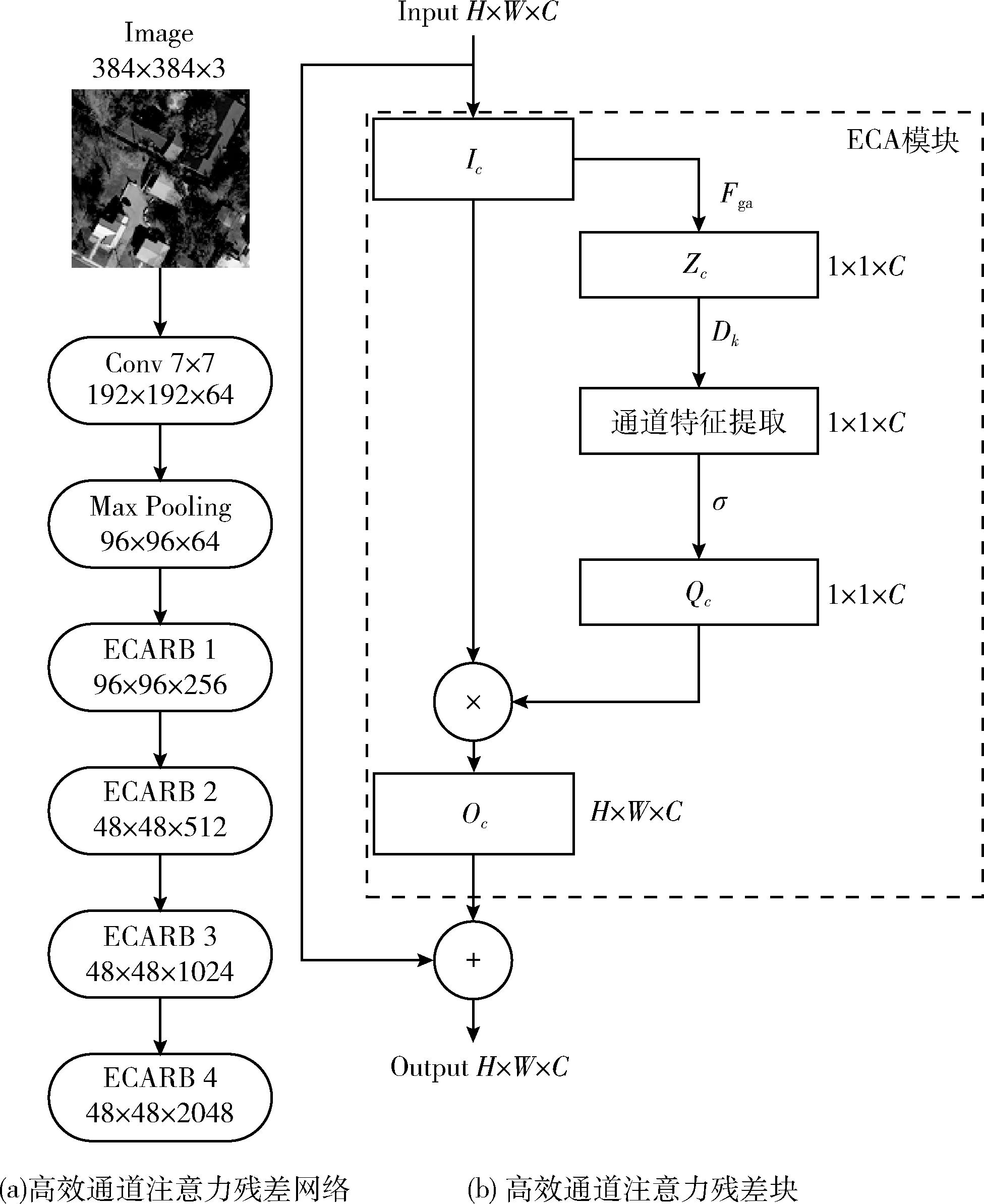
图2 编码器骨干网络结构
1.3 DUpsampling模块
语义分割模型在编码器部分通常将输入图像缩小为原始尺寸的1/8或1/16,解码器部分常使用双线性插值算法或堆栈式反卷积,将图像分辨率扩大8倍或16倍,两种方法的优劣势各在于:双线性插值算法模型参数量小,但图像边缘分割能力较弱;而使用反卷积对于目标的边缘信息恢复能力强,但模型参数量较大。为解决解码器的精度和模型参数量平衡问题,LED-Net使用数据依赖上采样(data-dependent upsampling,DUpsampling)模块[25]用于替代传统的解码器。
DUpsampling是一种将编码器输出特征图进行语义编码的模块,如图3所示,F为编码器输出尺寸大小为H×W×C的特征图,之后将特征图中每个1×1×C大小的像素转变为1×C矩阵,并将其乘上C×N大小的待训练矩阵W,乘积结果生成1×N的特征,通过重新排列(Rearrange)将1×N的特征变为R×R×(N/R2) 的特征,其中R代表DUpsampling输出所扩大分辨率的倍数,经过对输入特征图F内每个像素点进行DUpsampling操作,最终得到 (R×H)×(R×W)×(N/R2) 大小的输出分割图像O。

图3 DUpsampling结构(图中R=2)
DUpsampling模块的损失函数被定义为
P=Sigmoid(DUpsampling(F))
(4)
BCELoss(P,T)=-TlogP-(1-T)log(1-P)
(5)
其中,F为输入的特征图(feature map),T代表target的二分类值,其中T=1代表此像素点为建筑物,T=0为背景。DUpsampling模块将F的分辨率扩大到与T相同的尺寸,并经过Sigmoid激活函数进行类别预测,将分割图中每个像素值P归一化到0~1之间,之后使用二分类的交叉熵(binary cross entropy,BCE)损失函数P越接近于1代表网络判断此像素点时建筑物的概率更大,反之则代表网络判断像素点为背景的概率更大。DUpsampling模块通过网络训练迭代,将输出分割图和标签图的损失减少,使解码器DUpsampling模块输出更加准确的分割预测图。
由于LED-Net中高效通道注意力残差网络将输入图片下采样到1/8分辨率大小,而语义分割结果图需要与输入图片保持相同的分辨率大小,所以LED-Net将DUpsampling扩大倍率R设为8,以获取最终的分割结果图。
2 数据集和预处理
2.1 INRIA Aerial Image 数据集
INRIA Aerial Image数据集[26]由按像素手工标记的航空图像组成。数据集由3波段正射RGB图像组成,标签由含有两个语义类别的地面真实数据组成:建筑物和非建筑物。数据集涵盖了Austin、Chicago、Kitsap、Western Tyrol和Vienna的城市区域,空间分辨率为30 cm,每个城市各有36张5000×5000像素分辨率的高分遥感图像和标签,每个高分遥感图像和标签中包含地面1500×1500 m2的区域。数据集作者将每个城市的前5张图片作为测试集,剩余图片作为训练集,由此我们共可获得155张训练图片,25张测试图片用于网络的训练和测试对比。
2.2 Massachusetts Buildings数据集
Massachusetts Buildings数据集[16]由波士顿城市和郊区的航拍图像组成。每张航拍图像拍摄面积为2.25平方公里,标签图由OpenStreetMap项目中获得的建筑标签获得的,该数据平均遗漏噪声水平仅约为5%,图像的标签由含有建筑物和非建筑物这两类的地面数据组成。数据集包含151张1500×1500像素分辨率的高分遥感图像,每个高分遥感图像和标签中包含地面2250×2250 m2的区域。训练集包含137张图像及标签,测试集包含10张图像及标签。
2.3 数据切分和增广
由于数据集中图像和标签均为高分辨图像,若模型直接使用这些图像和标签进行训练,会因高分辨率遥感图像尺寸较大,导致训练过程出现内存不足而导致无法训练,所以需要对数据集图片进行切分。切分使用重叠切片(overlap-tile)策略,对于INRIA Aerial Image数据集,首先将图像和标签边缘处进行188像素的镜像填充,以确保等分切分,之后将遥感图像及标签切分成384×384大小的小尺寸图像,每张图片由此可以切分成196张小尺寸图像,数据集被切分为30 380张图片用于训练和4900张图片用于测试。对于Massachusetts Buildings数据集,将图像和标签边缘进行18像素的镜像填充,之后将遥感图像及标签同样切分成384×384大小,每张图片由此可以切分成16张小尺寸图像,此数据集被切分为2192张训练图片和160张测试图片。
为增加模型的鲁棒性,本文在训练过程中加入了数据增广操作,对训练集中切分好的图像和标签随机进行逆时针旋转90度旋转180度、270度、沿X轴上下翻转和沿Y轴左右翻转的处理。
3 建筑物语义分割实验
3.1 实验环境
本实验在NVIDIA TeslaV100 GPU服务器上搭建基于Pytorch的语义分割框架,操作环境为64位Windows 10,编程语言为Python3.7,主要函数库包括OpenCV、PIL、Numpy等。模型训练过程使用的优化器Adam,训练参数设置见表1。当训练次数进行到50次时,学习率减少为0.005。
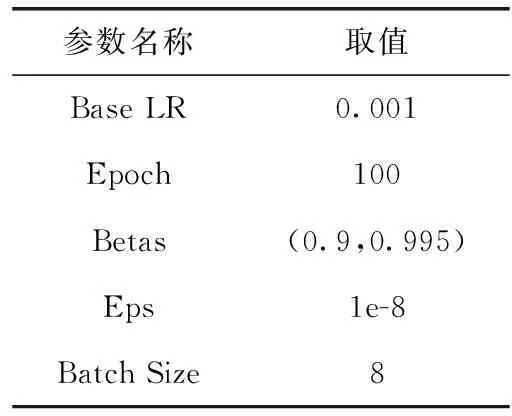
表1 训练参数设置
3.2 性能指标
为了公平的比较LED-Net与同研究模型在两个数据集上的准确率,本文使用与数据集相关文献一致的评价指标。对于INRIA Aerial Image Dataset使用Acc.(overall accuracy)和IoU(intersection over union)这两个评价指标,用于在对比实验中进行模型准确率的比较[26],Acc.如式(6)所示,IoU如式(7)所示。标签图中的正类代表建筑物,负类代表背景,TP(true positive)表示正类被判定为正类;FP(false positive)表示负类被判定为正类;FN(false negative)表示正类被判定为负类;TN(true negative)表示负类被判定为负类
(6)
(7)
而Massachusetts Buildings Dataset采用了一种松弛(relaxed)F1-score用于评价各模型的分割性能,宽松系数(relaxed factor)ρ代表在预测图中的每一个像素点在四周范围允许有ρ个像素点的误差,当ρ=0及代表传统的F1-score,我们在对比实验使用ρ=0和ρ=3的F1-score对各模型的准确率进行比较[16]。F1-score如式(8)所示
(8)
在建筑物语义分割实际应用任务中,不仅需要对比模型的准确率,而且还要考虑模型的大小,为此我们计算了LED-Net与其它模型的参数量进行综合性能对比。
3.3 消融实验
为了验证LED-Net中所设计的ECA模块和DUpsampling模块的有效性,我们使用编码器骨干网络为加入空洞卷积的ResNet-50,解码器为双线性插值的网络模型作为基础模型,并分别对基础模型的编码器网络添加ECA模块和解码器替换为DUpsampling模块。值得注意的是,与对比实验不同,消融实验为说明ECA模块和DUpsampling模块在两个数据集中的效果差异,实验中的各模型使用F1-score、Acc.、IoU这3个评价指标对比准确率,并对各模型的参数量做综合性能考量。
表2展示了在INRIA Aerial Image 数据集消融实验的准确率和模型参数量对比,相较于基础模型1、模型2和模型3分别添加ECA模块与DUpsampling模块,对于准确率的提升基本相同,其中IoU指标提升0.68%。LED-Net通过同时添加两个模块使得IoU指标提升1.67%,表明了我们设计的模块在准确率提升方面的有效性。图4为INRIA Aerial Image 数据集上各模型的分割结果,3张图片块的建筑物均包含大小和形状不同的建筑物模型1,存在建筑的误分类和边缘分割效果差的情况,而添加了ECA模块的结果图误分类现象更少,使用DUpsampling模块增加了建筑物边缘的分割精确度,同时使用两种模块在可视化效果图中达到了最优。
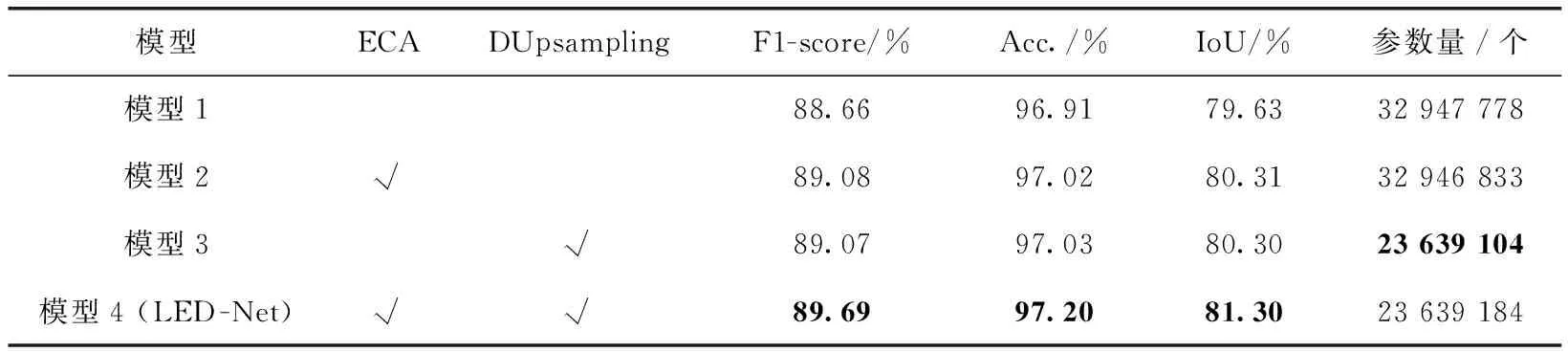
表2 INRIA Aerial Image数据集消融实验性能对比

图4 INRIA Aerial Image数据集消融实验分割结果
Massachusetts Buildings数据集的消融实验准确率结果对比见表3,添加我们设计的两个模块同样在3个指标上都取得了提升。添加DUpsampling模块的IoU指标增加4.04%,而添加ECA模块IoU指标增加1%。可视化分割结果如图5所示,添加ECA模块的模型2减少了城市中密集建筑物之间的误分类像素,与INRIA Aerial Image数据集不同,Massachusetts Buildings数据集中的建筑物数量更多且更加密集,模型3和模型4在此数据集上的分割准确率和可视化结果图效果更好,这是由于DUpsampling模块通过可学习的上采样矩阵,对建筑物的边缘和细节特征进行精确的分割,从而达到准确率和可视化效果的提升。

表3 Massachusetts Buildings数据集消融实验性能对比

图5 Massachusetts Buildings数据集消融实验分割结果
在表2和表3参数量对比中,添加ECA模块的编码器网络仅通过增加很少的参数数量达到了准确率的提升,而解码器使用DUpsampling可以在减少28.2%参数量情况下增加分割准确率。结合准确率和参数量对比,ECA模块和DUpsampling模块达到了预期的设计效果。
3.4 对比实验
我们选择了一些最先进的研究,包括语义分割和建筑物检测领域的FCN-50[7]、U-Net[8]、Building-A-Net[17]、PSPNet[23]、DeepLabV3+[24]、E-FCN[26]。本文与数据集文献和Building-A-Net使用的评价指标相同,使用3.2节中的Acc.和IoU这两个评价指标用于在INRIA Aerial Image Dataset比较准确率、松弛(Relaxed)F1-score指标,用于评价各模型在Massachusetts Buildings数据集上的准确率,并计算出各模型参数量用于综合性能对比。
3.4.1 INRIA Aerial Image数据集对比实验
INRIA Aerial Image数据集上各模型的准确率和模型参数量对比结果见表4,LED-Net在城市数量更多且地物信息更加复杂的遥感图片上,相较于其它模型在Acc.和IoU两项指标上取得了最高的准确率,相较于次优准确率的DeepLabV3+,模型参数减少41%。可视化分割预测图对比如图6所示,其中LED-Net对比其它模型,在建筑物的边缘处分割效果更加精细和准确,PSPNet和DeepLabV3+由于直接采用双线性插值算法,对于图片中形状不规则的建筑物分割效果较差,LED-Net使用DUpsampling增加了模型对于建筑物边缘和细节信息的处理能力。相对于U-Net,LED-Net通过在骨干网络增加ECA模块使得特征提取能力增强,分割图中的建筑物误分类像素也更少。
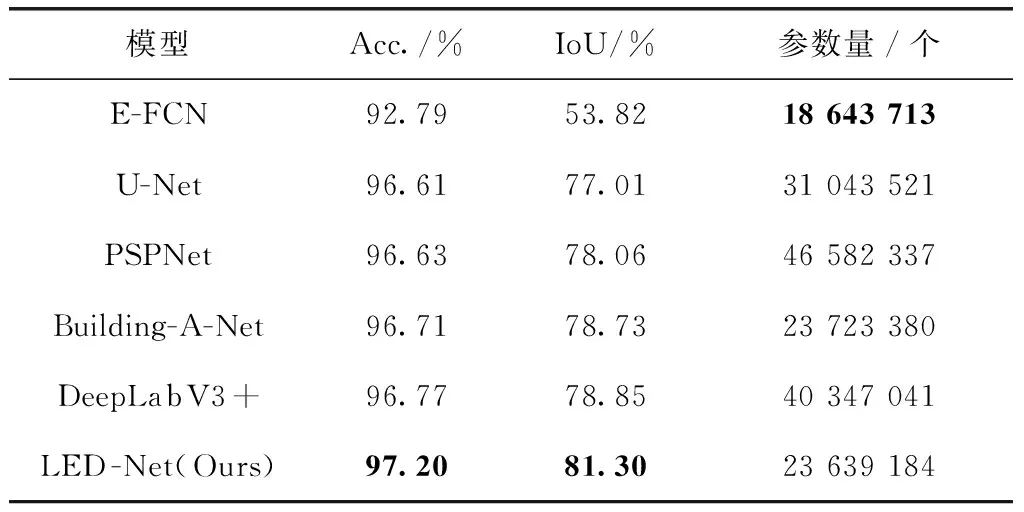
表4 INRIA Aerial Image数据集上各模型性能对比

图6 INRIA Aerial Image数据集上各模型分割结果
3.4.2 Massachusetts Buildings数据集对比实验
Massachusetts Buildings数据集上各模型的准确率和模型参数量对比结果见表5,LED-Net在建筑物数量更多且更加密集的遥感图片上,相较于其它模型在ρ=3的Relaxed F1-score取得了最高的准确率,在ρ=0的Relaxed F1-score取得了次优的准确率,且相对于使用GAN网络的Building-A-Net,模型参数量减少84万个。我们在测试集中挑选3张图片作为可视化分割预测图对比,如图7所示,LED-Net对建筑物的误分类像素更少,边缘细节分割效果也更好。
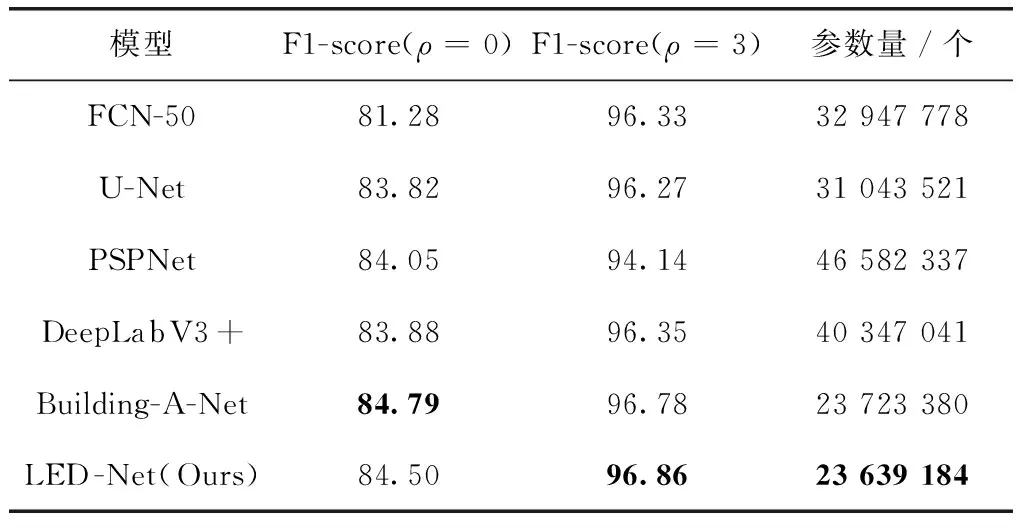
表5 Massachusetts Buildings数据集上各模型性能对比

图7 Massachusetts Buildings数据集上各模型分割结果
综合两个数据集上的实验,表明了我们设计的LED-Net模型可以在减少的参数量的情况下,增加分割准确率,并且可以生成可视化效果更好的分割预测图,以满足实际应用需求。
4 结束语
本文针对高分遥感图像建筑物语义分割模型,存在建筑物的整体和边缘分割完整度低和模型参数量大的问题,提出了一种轻量化的遥感建筑物语义分割网络LED-Net。LED-Net使用编码器-解码器结构,其中编码器骨干网络使用带有ECA模块的ResNet网络,提高模型在遥感图像中的特征提取能力;解码器使用轻量化的DUpsampling模块,通过这个模块提高建筑物的边缘分割能力并减少模型参数量。实验结果表明,与同研究模型相比,LED-Net在INRIA Aerial Image Dataset和Massachusetts Buildings Dataset均取得了更好性能。LED-Net对于背景复杂和边缘信息要求高的目标物分割效果较好,且模型参数量较少,后续考虑推广到遥感图像的道路、水域、农田等语义分割实际应用中去。
