基于深度卷积注意胶囊网络的微表情识别方法
2022-10-01曾岚蔚许青林
曾岚蔚,许青林
(广东工业大学 计算机学院,广东 广州 510006)
0 引 言
目前微表情识别任务的主流方法是基于CNN的深度学习方法,通过自动学习微表情特征以提高识别效率[1]。文献[2]通过对微表情图像序列使用EVM(Eulerian video magnification,EVM)方法,解决微表情面部运动的低振幅问题。文献[3]提出基于微注意力与残差网络相结合的微表情识别网络,使得网络在特征提取阶段更关注发生微表情运动的区域,解决微表情的局部性问题。然而,以上方法并没有同时考虑到人脸的结构特征和特征方向信息,忽视了AUs之间的相对关系。Sabour等[4]提出的胶囊网络深入理解图像整体与部分的关系,具有旋转不变性,擅于探索特征之间的关系,可与卷积神经网络结合使用,提高图像空间信息的利用率。Lei等[5]在高光谱遥感图像分类中结合胶囊网络与深度卷积,Xu等[6]运用注意机制和胶囊网络捕捉在线评论的情感信息,均取得了较好的识别效果。
基于胶囊网络的概念与技术应用,本文提出一种微表情分类模型——深度卷积注意胶囊网络。以胶囊网络为基础架构,采用EVM方法突出细节特征,引入注意力机制和深度卷积层,使网络筛选出有效信息;同时利用胶囊之间的动态路由对表情特征进行编码,提高网络空间信息表达能力和微表情识别能力;最后在数据集CASME II[7]和SAMM[8]进行实验,实验结果表明,DCACNN的识别准确率分别达到64.43%、59.91%,提高了2.29%和3.28%。
1 深度卷积注意胶囊网络
针对卷积网络不擅长捕捉面部AUs之间的相对关系和微表情呈现局部性的问题,通过借鉴注意力图的生成方法和具备更强特征提取能力的胶囊网络,设计了深度卷积注意胶囊网络。如图1所示,DCACNN主要由3部分组成:①对原始微表情图像帧序列进行预处理,包括人脸检测与裁剪、运动幅度放大、帧序列归一化;②结合AU感知注意力的特征提取网络(AU-VGG),提取人脸面部微表情的深层特征,得到具有AU感知变化的特征映射图;③胶囊网络层,结合胶囊的概念,将AU-VGG得到的特征图通过胶囊之间的动态路由进行编码,再由全连接层进行解码,最后使用压缩函数获得微表情的识别结果。
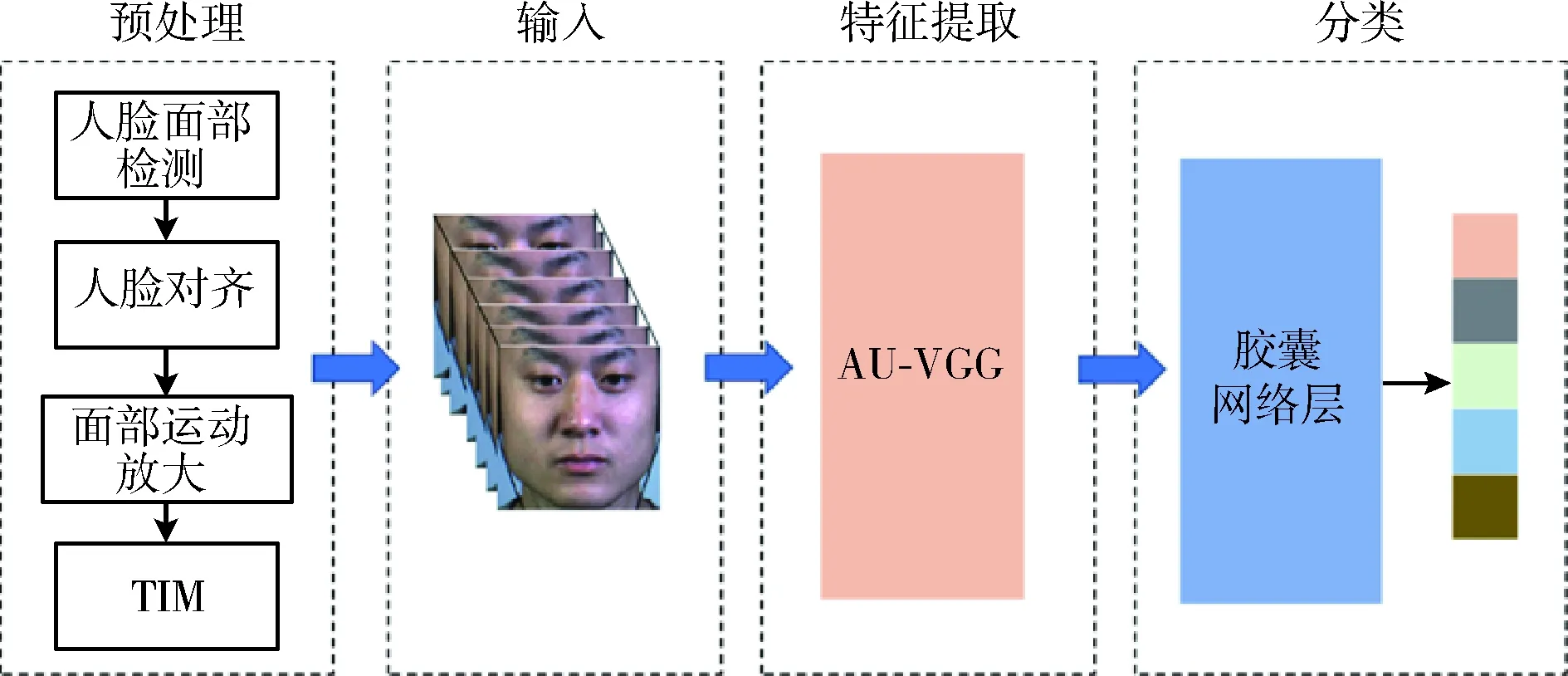
图1 DCACNN模型框架
1.1 预处理
图像预处理可以有效降低无关特征对微表情识别的影响,如图2所示,预处理包括人脸检测与裁剪、放大面部运动以及统一帧长。首先选取起始帧到顶点帧作为微表情有效表情段,对首帧使用人脸检测器[9]进行人脸检测,确定人脸区域切割框架。其次,自动校准面部5个关键点,根据关键点将两眼调整到同一水平线,进一步裁剪对齐后的人脸,裁剪后的大小为224×224。然后使用EVM算法对微表情样本进行处理,放大微表情面部运动,使其更容易识别。最后,为了统一帧序列大小,满足网络输入样本帧数一致的要求,采用TIM方法将裁剪后的图像进行归一化处理。
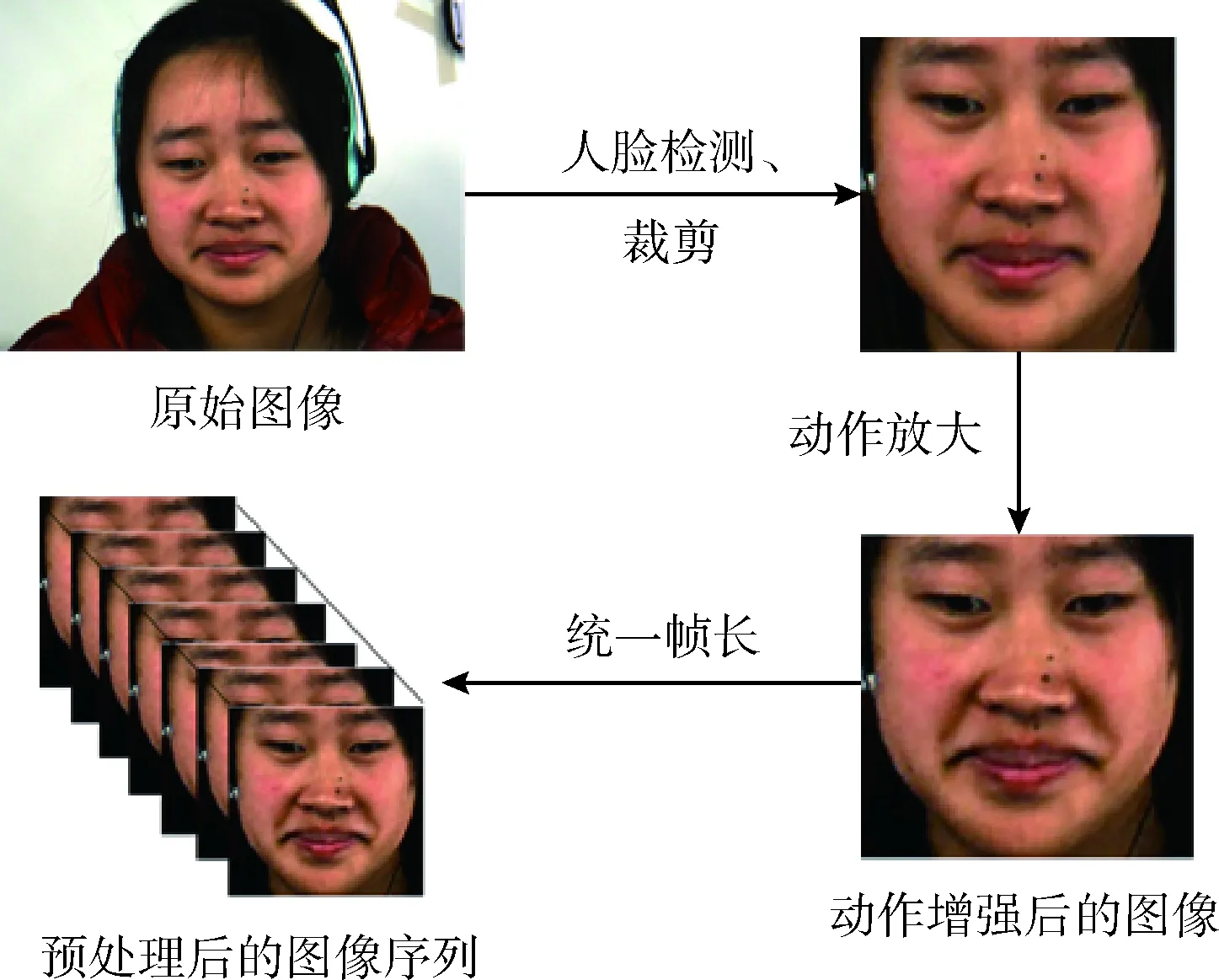
图2 微表情预处理过程
1.2 结合AU感知注意力的特征提取网络
为了提高网络提取高维信息和筛选关键特征的能力,DCACNN使用AU-VGG提取人脸微表情特征,AU-VGG的网络结构与参数如图3所示,特征提取网络以传统CNN为主要架构,仿照Residual Net的跳跃层结构,在卷积层上应用了注意层。
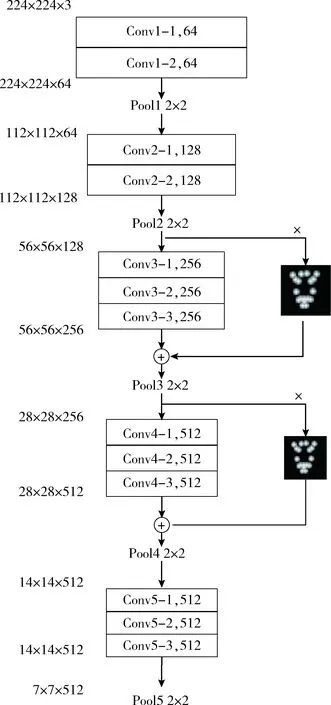
图3 AU-VGG网络结构与参数
如图3所示,AU-VGG的卷积部分包括13个卷积层,5个池化层,对输入图像进行下采样,最终得到7×7的特征图。将AU-VGG网络描述为5个阶段,包括卷积层和池化层。其中,阶段一和阶段二包括两个卷积层,阶段三、阶段四和阶段五包括3个卷积层,且每个阶段之间应用stride=1的2×2卷积核进行池化操作。从图3可知,人脸微表情图像的特征信息从224×224×3调整到7×7×512,人脸特征融入到各通道上,提高了网络提取信息的能力。
AU-VGG的注意力机制参照文献[10],引入跳跃结构,将低层特征先与注意层相乘,再与卷积后的高层特征相加,使得低层特征和高层特征都能被表示。
对于单个AU区域,不同位置具有不同的重要性,AU中心点以及区域内部分的改变对检测结果具有较大影响,为此需要基于关键面部地标构建AU注意力图。如图4(a)所示的面部地标关键点是获得注意力图的必要条件,AU中心不可直接使用检测到的面部关键点,而是通过计算两眼外眼角的距离,定义一个比例距离作为人脸像素移动的参考。为了使移动距离更适合于所有人脸图像,以内角距离作为缩放距离,有利于定位AU中心。由于人脸的对称性,AU中心是成对的,因此每个AU定义一对点,再根据AU中心建立如图4(b)所示的注意力图。
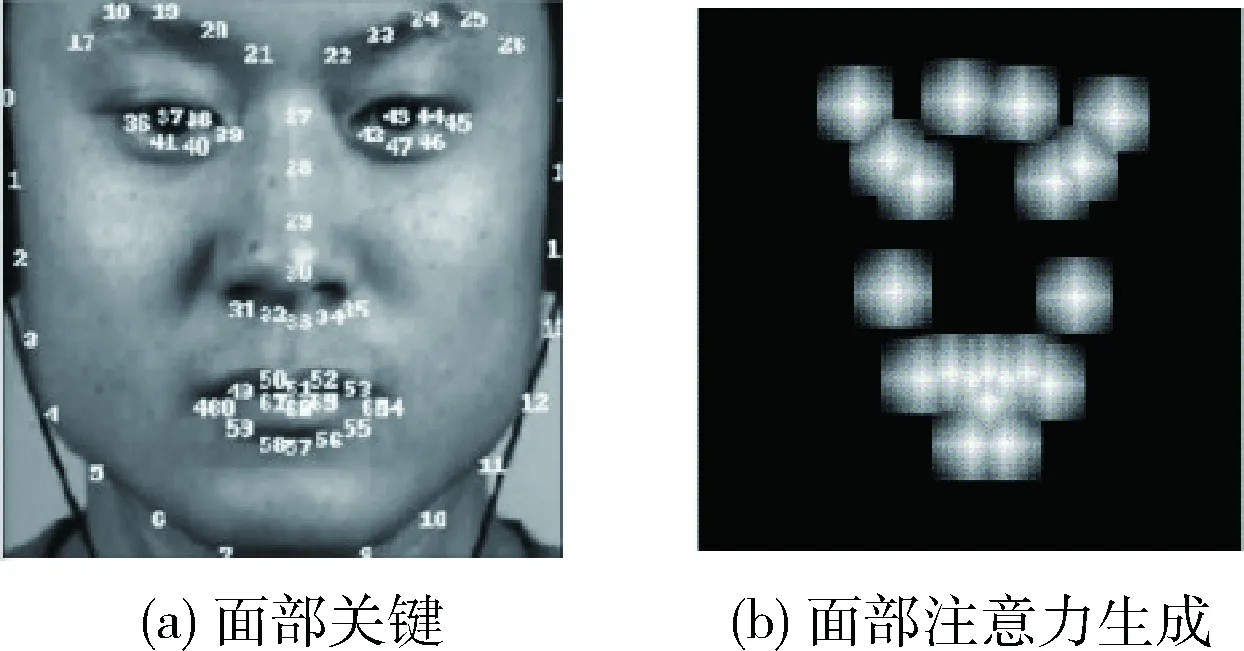
图4 注意力映射的生成
首先将人脸图像的大小调整为100×100,以确保相同的比例在所有图像中共享。然后,使用AU中心点附近属于同一区域的7个像素为一个AU区域,因此每个区域的尺寸为15×15,越靠近AU中心的点其权重越大,关系式如下所示
Wa=1-0.07dm
(1)
式中:dm是某位置距离AU中心的曼哈顿距离。注意图中权重值较高的区域是人脸微表情中的AU活跃区域,较高权重值可以增强AU的活性区域,生成注意力映射图的算法见表1。

表1 注意力映射图生成算法
如图3所示,生成的注意力图被嵌入到第三阶段和第四阶段中。具体操作是将第二阶段的池化层生成的feature map与attention map相乘,然后与第三阶段的卷积并列进行,最后将第三阶段的卷积结果逐个元素相加,作为这一阶段的池化层的输入。同样,在第四阶段中,注意力映射图与卷积层共同执行相同的操作,其生成的模型直接作用于微表情的活动区域。
1.3 胶囊网络层
胶囊网络的具体参数和结构如图5所示,主要工作是利用动态路由机制,将AU-VGG得到的feature map进行编码。通过AU-VGG后feature map大小为512×7×7,应用stride=1的2×2卷积核后得到256×6×6的feature map,然后调整到具有32个卷积8维通道的PrimaryCaps层,在PrimaryCaps层和MECaps层之间执行动态路由。每个微表情类别对应16维的胶囊单元,其中每个胶囊从上一层的所有胶囊接收输入。最后,通过三层全连通层重构图像,分别是全连通ReLU层(size=512)、全连通ReLU层 (size=1024)和全连通的Sigmoid层(size=150 528)。
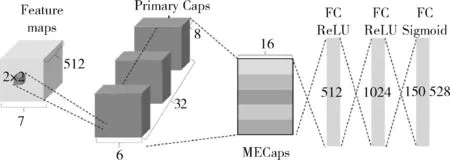
图5 DCACNN中胶囊层的具体结构和参数
PrimaryCaps层和MECaps层之间的动态路由过程如图6所示。当前层胶囊的输入来自前一层胶囊的输出,底层胶囊单元通过权重矩阵与高层胶囊单元连接,计算和判断胶囊层之间的相关性,动态更新权重矩阵,重复这个过程直至收敛,并更新耦合系数。其中,耦合系数通过SoftMax计算得到,计算公式如下
(2)
式中:bij表示主胶囊层的第i个低级胶囊到第j个高级胶囊耦合的对数概率,其初始值设置为0,cij则通过动态路由过程迭代细化。第j个胶囊的输入向量xj计算公式如下
(3)
为了使输出胶囊的模长表示概率,确保输出向量长度位于[0,1]区间,方向保持不变,应用“squash”函数进行归一化得到的输出向量,胶囊最终输出向量vj计算公式如下所示
(4)
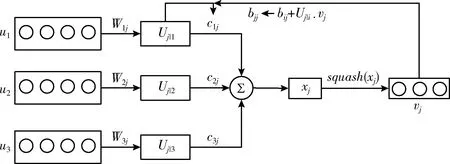
图6 胶囊之间的层级结构和动态路由
在MECaps层之后,有3个完全连接的层用于图像重构,这是解码阶段。需要尽量减少重建损失,以重建图像更好地从MECaps层。在训练中使用真实标签作为重建目标,通过计算FC Sigmoid层输出像素与原始图像像素之间的欧氏距离,构造图像重构的损失函数。
网络损失函数Lnet包含边际损失Lmargin和重构损失Lrec, 本文将重建损失的规模扩大到0.0005,使其在训练过程中不会主导边际损失。损失函数的计算公式如下所示
(5)
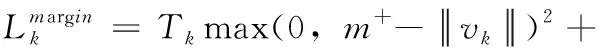
(6)
Lrec=(xrec-x)2
(7)
其中,k表示分类类别,Tk表示分类的指示函数;当k存在时Tk为1,不存在则为0;m+表示正确分类的边界,m-表示错误分类的边界;x表示原始图像,xrec表示重构后的图像;λ表示调节图像中微表情是否存在所导致的损失。实验中,m+和m-的值分别为0.9和0.1,λ设置为0.5以控制其效果。
2 实验结果与分析
2.1 数据集
CASME II是一个200 fps摄像机记录的255个微表情视频序列,平均年龄22.03岁,共26名亚洲参与者,由中科院傅小兰团队提供。SAMM是一个由200 fps的高分辨率摄像机记录的159个微表情视频序列,平均年龄33.24,共32名参与者。CASME II和SAMM数据集样本均由AU编码,并且提供起始帧、峰值帧和结束帧位置。
两个数据集的微表情分类均为7类,但类别和样本数量存在差异,因此实验对两个数据集采取不同的样本分类。CASME II数据集中,恐惧和悲伤的样本量太少,不能满足特征学习的训练要求,因此使用高兴、厌恶、惊讶、压抑和其它5个类别的微表情样本进行实验。SAMM数据集中,使用消极、积极和惊讶3个类别,其中消极类由愤怒、轻蔑和悲伤组成。微表情样本具体归类和数量见表2。
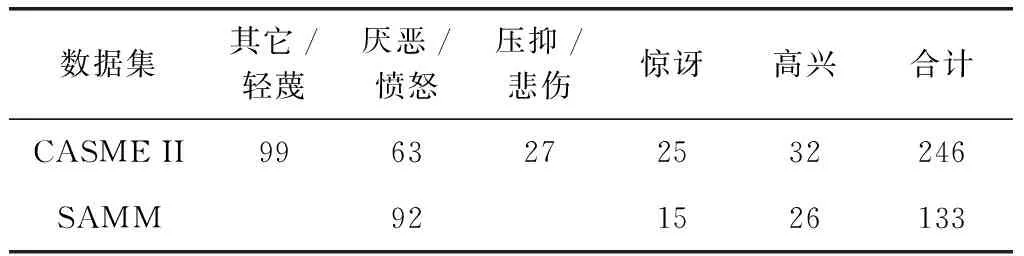
表2 CASME II和SAMM数据集样本归类参照
实验训练测试使用的是留一受试者交叉验证方法(leave-one-subject-out,LOSO)协议,该协议将受试者的数据作为实验的测试集,将其余受试者的数据作为训练集。其中CASME II数据集使用该协议进行26次训练测试,取26组实验的识别率平均值和F1-Score作为最终评价结果。SAMM数据集进行32次实验后,所得到的结果平均值为最终评价结果。
2.2 实验设置
在数据预处理时,EVM方法选用的放大频段为[0.2 Hz,2.4 Hz],合理的放大系数需要通过比较不同放大系数对结果的影响来设定,否则会放大噪声,甚至导致面部表情失真,在CASME II数据集上测试的最终结果如图7所示。由图7可知,当参数为8时获得最佳结果。
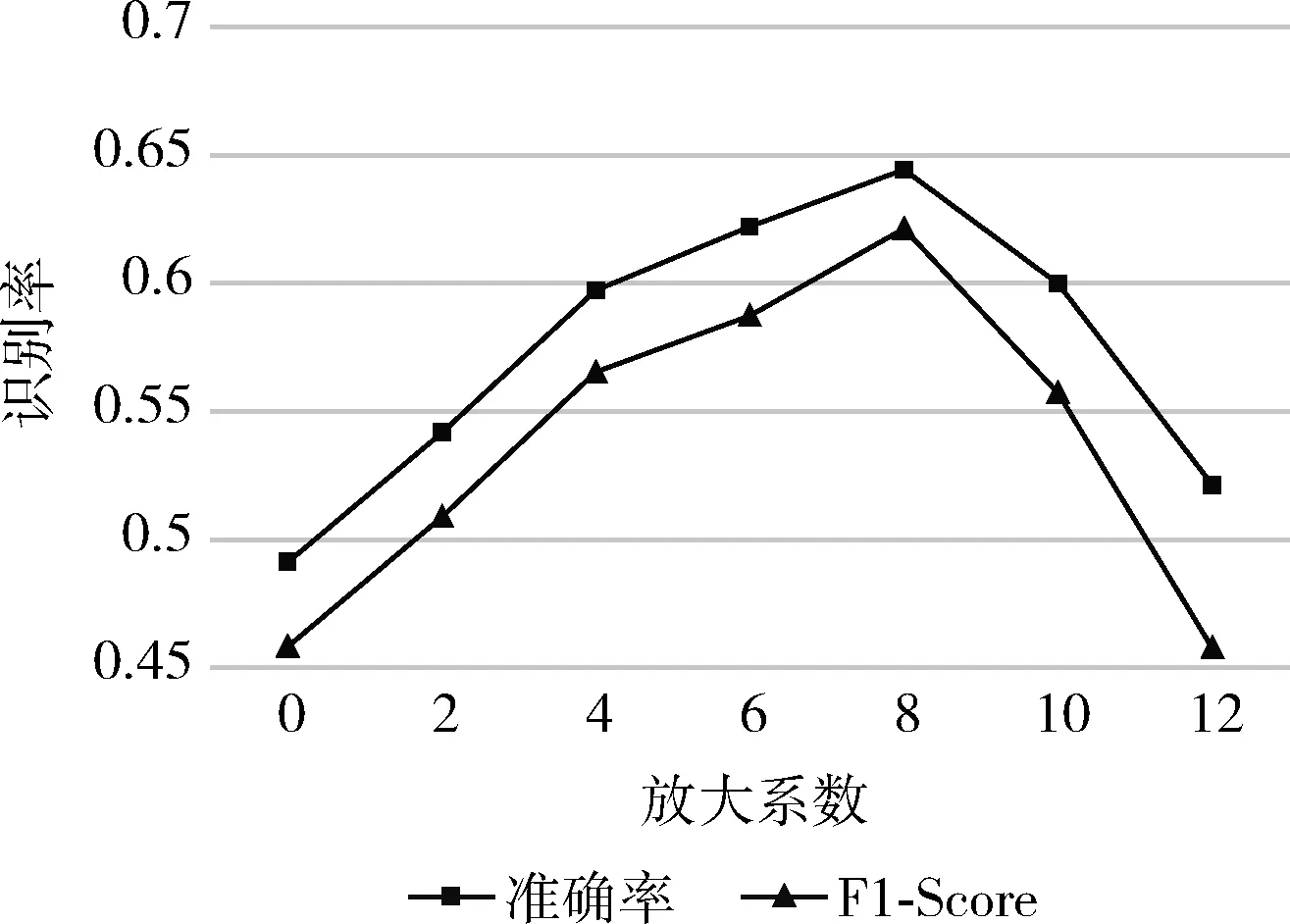
图7 不同放大系数的准确值和F1-Score
本实验选取微表情有效表情段为输入,并将输入网络所有图像大小统一调整为224×224,采用放大倍数为8的图像,统一帧长为50。实验训练过程中使用Adam优化网络学习算法,其中学习率设置为0.0001,β1=0.9,β2=0.999,ε=10-8(一个极小值,防止它除以零的实现)。批大小和迭代次数分别设置为16和100。
2.3 实验结果与分析
为了验证AU注意力机制和动态路由的有效性,将分别对结合AU感知注意力的卷积网络(AU-VGG)、具有丰富卷积层的胶囊网络(deep convolutional capsule neural network,DCCNN)、DCACNN的实验效果进行对比评估,以上方法在CASME II和SAMM数据集的实验结果见表3。

表3 CASME II和SAMM数据集消融实验结果
由表3可知,DCACNN在CASME II和SAMM数据集上都取得了比AU-VGG和DCCNN更好的实验结果。胶囊之间的动态路由使模型的准确率分别提高4.79%、4.15%,引入注意力约束使模型的准确率都提高1%。动态路由机制能够捕捉关键特征之间的变化,获取更好的深层特征表示,因此DCACNN准确率比AU-VGG高,验证动态路由的有效性。具有AU注意机制的模型比不具有注意机制的模型更能捕捉到细微的肌肉运动,因此DCACNN准确率比DCCNN高,验证AU感知注意力的有效性。通过人脸地标生成AU注意力图,有助于提升模型筛选出关键局部区域特征的能力,使模型获取需要关注的活跃区域。因此,基于人脸地标生成的AU注意力图和具有深度卷积层的胶囊神经网络都有效增强DCACNN的特征提取能力,都有利于提高微表情识别的准确率。
进一步评价模型对数据集的分类和识别能力,采用混淆矩阵对微表情识别模型的准确性进行评估,AU-VGG、DCCNN、DCACNN在CASME II和SAMM数据集上的实验结果混淆矩阵分别如图8、图9所示。混淆矩阵的列表示模型预测类别,行表示该类的模型预测结果,斜对角线为微表情被正确分类的样本数量占该类别样本总数的比重。由图8和图9可知3个模型均具有微表情分类识别的能力,且DCACNN取得了更好的结果,具有更强微表情识别能力。综合比较图8可知,CASME II数据集中,高兴和其它的微表情分类比其它分类结果好,原因在于不同情绪的生物力学性质不同,产生高兴表情时具有较强面部运动强度;其它分类的微表情大多为自然表情,训练样本占比最高,是简单样本学习。而厌恶和压抑两种情绪有很多相似之处,区分度较低,且样本分布不平衡;惊讶表情则训练样本数量较少。在SAMM数据集中,消极类样本在数据集中占较大比重,因此识别效果最佳,积极类样本即高兴类,其面部肌肉运动幅度较大因此得到较好的识别效果。
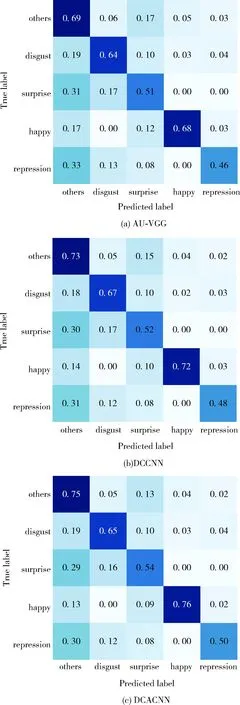
图8 不同方法在CASME II上的混淆矩阵
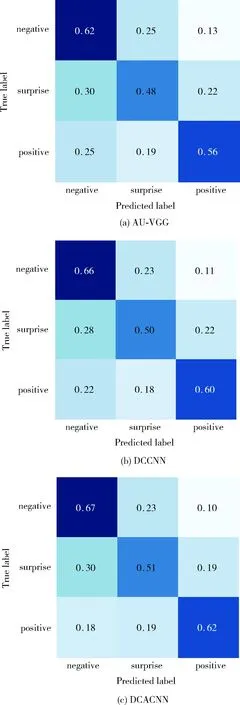
图9 不同方法在SAMM上的混淆矩阵
为验证模型的有效性,将DCACNN与主流微表情识别算法进行对比,见表4和表5。
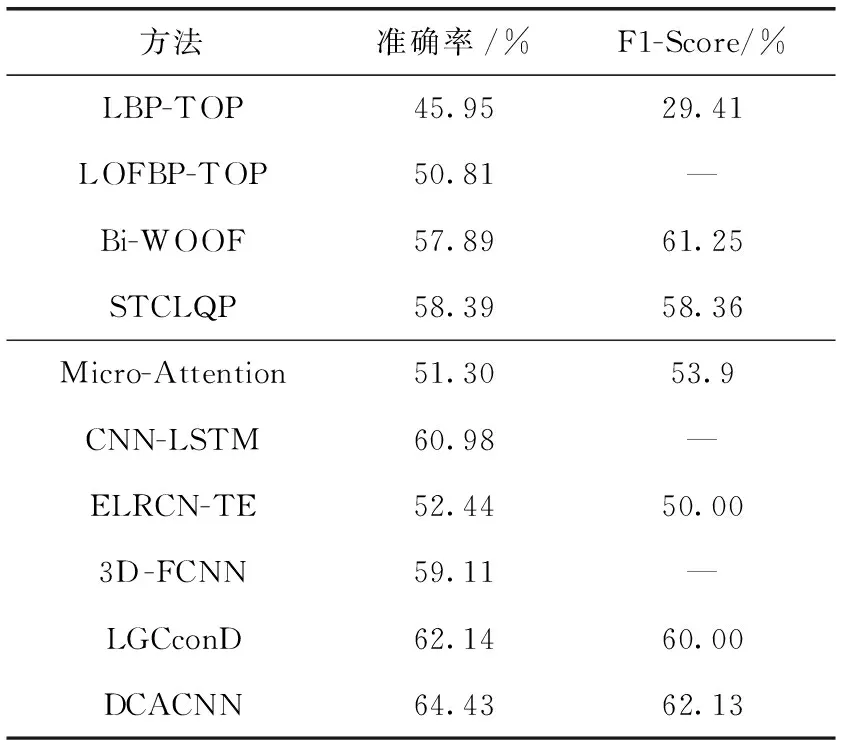
表4 CASME II数据集的实验结果对比
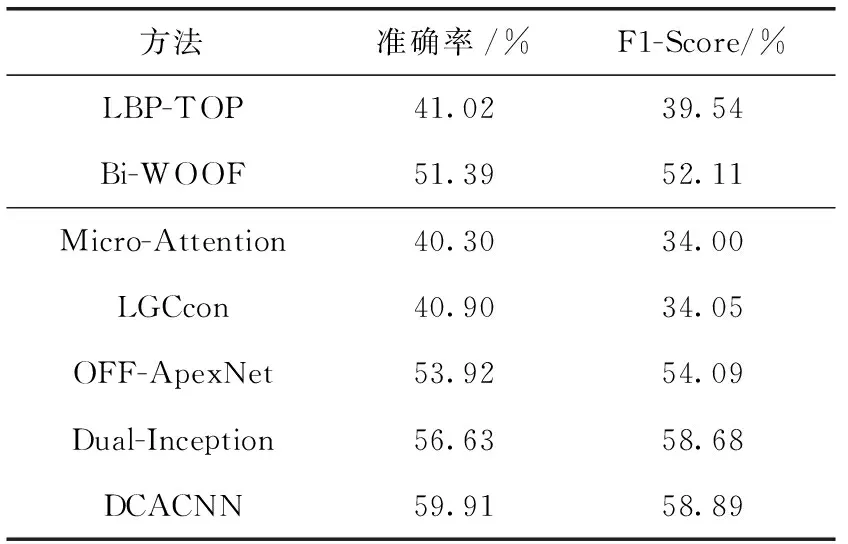
表5 SAMM数据集的实验结果对比
LBP-TOP[11]、LOFBP-TOP[12]、Bi-WOOF[13]、STCLQP[14]是传统提取特征方法。其中,LBP-TOP是微表情识别的基线方法,其作用机制是在相互正交的3个平面中,采用局部二进制对微表情图像进行特征表示,从而达到分类的目的。LOFBP-TOP是一种将光流和LBP-TOP相结合的微表情识别方法,利用LBP-TOP对光流编码来获取微表情特征并进行分类。Bi-WOOF是通过光应变全局加权、光流强度局部加权的双加权方向光流直方图获取微表情特征的方法。STCLQP是基于时空完全局部量化模式的识别方法,在进行微表情识别时考虑了信号、大小和方向等因素。
Micro-Attention[3]、CNN-LSTM[15]、ELRCN-TE[16]、3D-FCNN[17]、LGCconD[18]、LGCcon[18]、OFF-ApexNet[19]、Dual-Inception[20]是基于深度学习的微表情识别方法。其中,Micro-Attention是基于微注意力与残差网络相结合的网络,在residual block中集成微注意单元。CNN-LSTM是结合时域和空域的微表情识别方法,采用CNN提取图像序列的状态获得空间维度信息,使用LSTM长时记忆网络获取时间维度信息,将二者结合并进行微表情分类识别。ELRCN-TE引入增强的长期递归卷积网络,由空间特征提取器和捕获时间信息的时态模块组成。3D-FCNN同时提取光流帧序列和原始帧序列的时空特征,在全连接层对时空特征进行融合。LGCcon使用结合局部信息和全局信息的联合特征学习网络来识别微表情,LGCconD是经过顶点帧定位的LGCcon方法。OFF-ApexNet构建一个顶点帧网络框架,使用微表情的起始帧、顶点帧和结束帧获取人脸图像特征,将光流特征图像输入浅层CNN进行识别和分类。Dual-Inception将光流特征的水平和垂直分量输入双流Inception网络进行微表情识别。
表4表示DCACNN在CASME II数据集上的对比结果。由表4可知传统手工特征识别算法中识别率最高的是STCLQP,F1-Score最高的是Bi-WOOF,深度学习算法中识别率和F1-Score最高的是LGCconD。DCACNN在CASME II上的微表情识别准确率比STCLQP和LGCconD分别提高了6.04%和2.29%,DCACNN在F1-Score指标上比Bi-WOOF和LGCconD分别提高了0.88%和2.13%。与手工描述特征的识别方法相比,深度学习的方法能够省去手工特征提取过程,直接从原始的微表情图像帧序列中提取特征,并且通过逐层学习的方式不断地调整模型参数和权重,以优化提取到的特征,在简化了特征提取步骤的基础上取得了较好的识别效果。因为DCACNN采用的胶囊网络充分利用人脸结构空间信息,以及引入AU注意力机制,使DCACNN对于数量较少的样本也有一定的识别准确率,进一步提高F1-Score。
表5表示DCACNN在SAMM数据集上的对比结果。由表5可知DCACNN在SAMM数据集上的识别准确率比Bi-WOOF和Dual-Inception分别提高了8.52%和3.28%,在F1-Score指标上分别提高了6.78%和0.21%。对比表4和表5可知,由于SAMM数据集样本数量较CASME II少,且样本分布不均衡,导致微表情方法SAMM数据集上的识别效果整体低于CASME II数据集,可见微表情识别的进一步发展还需要构建更大的微表情数据集和更均衡的样本分类分布。
3 结束语
本文提出了一种用于微表情分类的深度卷积注意胶囊网络DCACNN。针对微表情运动的局部性和传统卷积空间信息特征提取能力不足的问题,①将AU注意力约束融入传统卷积网络中,提高网络提取高维特征和微表情活跃区域特征的能力;②采用胶囊网络的动态路由机制,提高网络获取空间结构信息的能力,更有效地表示微表情特征。理论分析和实验结果表明,DCACNN识别准确率在CASME II和SAMM数据集上分别达到64.43%、59.91%,分别提高2.29%和3.28%。但是微表情数据集较少、微表情样本类别数量不均衡的问题仍然是导致识别率较低的主要原因,研究如何在长视频中发现微表情以拓展微表情数据集是下一步可以研究的方向。
