改进的YOLOv4复杂构件分类识别算法
2022-10-01沈建新
林 鑫,沈建新,秦 顺,潘 峰
(南京航空航天大学 机电学院,江苏 南京 210016)
0 引 言
飞机起落架、涡轮叶片、飞机机翼等复杂构件是航天设备的关键部件,对于保证装备的性能和可靠性具有重要作用。新一代航空航天装备的复杂结构件尺寸大、加工特征数量多、差异大,其形状复杂、成形精度难控制,而且其型面通常具有不规则的曲率分布。在生产过程中进行机器人自动化喷涂作业时,由于构件种类多、形状复杂[1,2],往往存在无法准确分类识别的情况。为了高效、准确地完成航天设备复杂构件自动化喷涂工作,其首要的任务就是对放在工作台上的构件进行准确的分类与识别。
目标识别分类与检测是深度学习技术应用最广泛的方向之一,近年来其主要的算法分为两类:基于感兴趣位置的方法和基于回归的方法。基于感兴趣位置的方法主要代表有SPP-Net与R-CNN系列算法;基于回归的方法主要代表是YOLO[3-6](you only look once)系列算法。
基于感兴趣位置的方法又叫两步走的方法,将目标检测分为两个步骤:提取感兴趣位置和进行目标检测分类。此类算法需要先在图像上提取若干个ROI(region of inte-rest)区域,再对这些区域进行特征提取以及目标检测。此类算法由于提取了大量的ROI区域,因此计算量大,步骤复杂,运行缓慢。
在这类两步走的方法遇到瓶颈时,YOLO系列算法为目标检测提供了一种新的思路。YOLO系列算法是基于回归的方法,又叫一步走的方法。其将物体检测作为一个回归问题进行求解,输入图像经过一次提取,便能得到图像中所有物体的位置和其所属类别及相应的置信概率。
近年来目标识别分类与检测技术蓬勃发展,但是其主要的应用方向是动物、行人、交通工具等生活中常见物体[7-11],其在航天航空复杂构件分类识别领域研究较少,原因在于神经网络模型的训练需要大量样本,而航天复杂构件没有公开的图像数据集。为此,本文首先制作了航天设备复杂构件的数据集,并采取平移、旋转、缩放、调整亮度和对比度等数据增强的方式对数据集进行扩充。其次,本文研究了深度学习目标检测算法,对现有的YOLOv4目标检测算法进行改进并优化,将原算法中残差卷积块的个数由5个调整为3个,并且各部分通道数缩减一半。只采用上采样结构而省略下采样结构,减少了训练参数,在保证检测准确率的同时,可以获得较短的训练时间,并且能有效降低对计算机的使用性能要求。同时在训练中采用余弦退火衰减方法,动态调整学习率数值。实验结果表明,本文提出的算法在验证集上的mAP值达到了97.63%,误差降至0.66,检测精度高、准确率高,训练速度快,性能优于其它同类的算法,应用于航天航空复杂构件喷涂作业的分类识别中具有重要的意义和使用价值。
1 数据集制作
1.1 实验数据集
由于航天设备复杂构件目标检测识别目前没有开源的数据集,因此首先在Solidworks2017三维建模软件上搭建三维模型,在各个角度进行截图制作图像数据集。在复杂构件分类识别任务中,分别截取自动倾斜器、发动机、机翼、涡轮、起落架5种构件不同角度的图像。在水平方向,依次将构件旋转不同角度,在每个角度上进行截图时,再将构件在竖直方向上旋转一定角度,在各个角度上获得相应的图像。构件部分图像数据集如图1所示。

图1 部分复杂构件数据集图像
在标签文件中,分别记录构件在图像中的位置坐标,并将5种构件的分类标签设为0、1、2、3、4。将图像绝对路径和标签值打包生成TXT标签文件,完成分类识别任务的标签数据集制作。标签文件内容由图片绝对路径、目标左上角点和左下角点坐标值(x,y)以及目标类别组成。目标分类值为0、1、2、3、4,分别代表自动倾斜器、发动机、机翼、涡轮、起落架5种航天设备复杂构件。制作完成的数据集中共有1662张样本。部分复杂构件标签TXT文件内容如图2所示。

图2 部分复杂构件TXT标签内容
1.2 数据增强
数据增强是非常重要的提高目标检测算法鲁棒性的手段[12,13]。数据增强的目的是让图片变得更加多样。若对于原始图像不进行变换,则某一个物体在训练时,网络能学习到的只有它固定的特征。但是实际上,从各个角度、在不同的背景、不同的光照条件去看同一个物体,也会具有不同的特征。在目标检测中若要增强数据,不仅是直接对图片进行调整,还要考虑到图片处理后物体回归框的位置,回归框的坐标要随着图片进行同步改变。数据增强后的图片放入神经网络进行训练可以提高网络的鲁棒性,降低各方面干扰因素对识别的影响。本文采用平移(translate)、旋转(rotate)、缩放(scale)、仿射变换(affine transform)、调整亮度和对比度(adjust brightness and contrast)等数据增强方法,将数据集从1662张样本扩充到21 259张样本。
数据增强算法如算法1所示。
算法1:数据增强
(1)# matshift为变换矩阵, 定义不同变换矩阵可完成
(2)# 图像平移、 旋转、 缩放、 仿射变换等不同操作
(3)# 读取图像
(4) img=cv.imread(‘D:/image.jpg’)
(5)# 图像平移、 旋转等操作
(6) dst1=cv.warpAffine(img,matshift,(640,640))
(7)# 调整图像亮度和对比度
(8)dst2=cv.addWeighted(img,a,blank,1-a,b)
(9)# 图像垂直翻转
(10)dst3=cv.flip(img,0)
(11)# 图像水平翻转
(12)dst4=cv.flip(img,1)
(13) cv.imwrite(‘D:/image.jpg’, dst)
2 改进的YOLOv4目标检测算法
2.1 算法网络框架
YOLOv4目标检测算法一共有6000多万参数,参数量十分庞大,计算耗时。尤其在输入图像大小采用608×608时,更要求计算机CPU显存在6 G以上。本文对YOLOv4算法进行改进,由于本次的复杂构件模型特征明显,构件种类少,因此分类识别的任务不复杂,可以对YOLOv4算法进行简化。在保证检测准确率的同时,可以获得较短的训练时间,并且能有效降低对计算机的性能要求。改进后的YOLOv4算法具有更简略的结构,将残差卷积块的个数由5个调整成3个,并且通道数缩减一半,仍然可以获得较好的特征提取效果。
由于复杂构件在工作台上的摆放方式、位置相对固定,所以网络中省略了SPPNet部分,图像中目标大小相似,因此无需提高网络的感受野。只采用上采样结构而省略了下采样结构,可以减少大量的训练参数,精简网络结构。整体的改进后,最终网络的总训练参数只有500多万,在原来的基础上缩小了近12倍。由于本次的分类检测任务不复杂,物体种类少,位置相对固定,对网络的优化会在保证结果精确度的同时,极大缩短训练与检测的时间。改进的YOLOv4目标检测算法框架如图3所示。
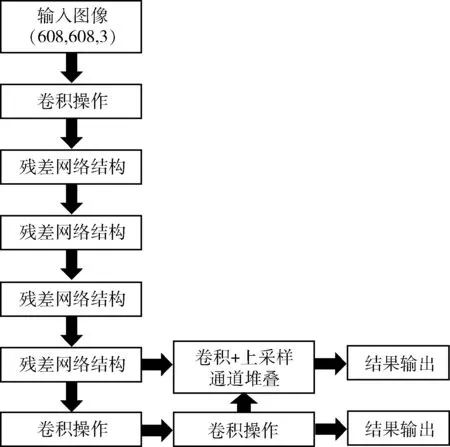
图3 改进的YOLOv4目标检测算法框架
该算法网络各部分组成主要包括输入层、卷积层、池化层、激活函数以及输出层等。在运算的过程中,采用Dropout[14]训练技巧,对神经元进行随机舍弃,防止训练过程中产生过拟合的现象。使用了残差跳跃结构,在增加网络深度的同时,减少梯度消失现象的发生。
2.1.1 图像输入层
输入层由二维图像的像素值组成,本次训练的输入参数是大小为[608,608,3]的张量。其中前两个数字代表了图像的长和宽,第三个数字代表了图像的通道数,本次训练采用的图像是R,G,B三通道彩色图像。
2.1.2 卷积层
卷积层由若干卷积单元组成,卷积单元的参数在不断的优化过程中不断的改变,最终达到一个最优值。卷积层的作用是特征提取,浅层的卷积层可以提取浅表的特征,如图像中物体的边缘、轮廓等,更深的卷积层可以在网络不断的训练中提取到更深层次、更复杂的特征。
2.1.3 池化层
池化操作是神经网络训练中一个重要的操作,它实际上是一种降采样的方式。本次模型训练采用最大值池化,在所给定的N×N的池化窗口中,筛选出最大的像素值将其保留,并舍去其余的参数。通过池化操作可以减小数据的空间大小,保留更多的有效信息,这在一定程度上也控制了过拟合。在卷积层之间会周期性地插入池化层。最大池化操作如图4所示。
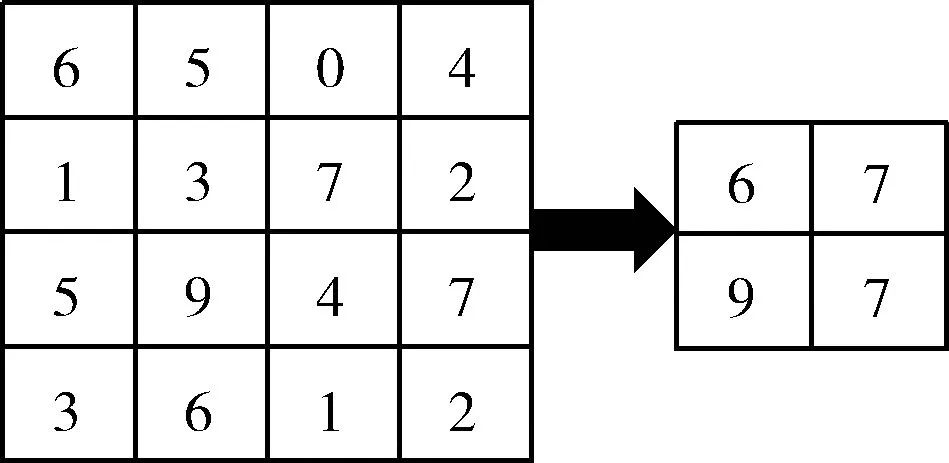
图4 最大池化操作过程
图4中,原始的输入大小为4×4,池化操作块的大小为2×2,步长为2,最终得到的结果大小为2×2,长宽均为原来的一半,在减少参数的同时,保留了更多的有效值。
2.1.4 Leaky-ReLU激活函数
神经网络训练过程中常使用ReLU激活函数。ReLU激活函数将所有的输入为负值的输出都设为零,所以在输入值小于0时不能起到激活的作用,容易导致梯度消失。Leaky-ReLU激活函数是对RELU激活函数的改进,给所有负值输入赋予一个非零斜率,在输入值小于0时依然可以起到激活的作用。Leaky-ReLU表达式为
(1)
式中:ai是(1,+∞)区间内的固定参数,xi为输入值,yi为输出值。
2.1.5 结果输出层
网络模型输出层将前端获取的结果转换为固定长度的张量,其尺寸根据不同的模型结构以及任务需求而改变。本次改进的YOLOv4网络模型输出层张量长度为10(5+4+1)。其组成依次为:经过softmax激活后的5种构件分类值、构件在图像中的位置坐标(左上角点与右下角点)、分类的置信度。输出层张量与标签值之间的差值即为反向传播时需要优化的损失,通过不断减小损失来使模型的效果达到最优。
2.1.6 卷积块
在深度学习神经网络算法中,卷积层、池化层、激活函数并不是单独存在,而是组合在一起形成卷积块[15]。因此在代码的编排中,将卷积块设计成函数直接调用,可以极大地节省算法编排的时间,优化算法的结构,使算法结构清晰明了。本文算法在Python3.6-TensorFlow1.13框架下编写,其卷积块函数如算法2所示。
算法2:卷积块
(1)def Conv2D_block(inputs) # 卷积块函数定义

(3) output=BatchNormalization()(x)
(4) output=Dropout(0.7)(x)
(5) return Activation(Leaky_ReLU)(output)
2.2 训练方法
2.2.1 学习率
学习率是深度学习中的关键一环,在神经网络的训练中,对学习率做出适当的调整十分重要。本次训练中,在神经网络训练时采用改余弦退火衰减法,学习率会先上升再下降。
在上升过程中,学习率数值随训练的轮次(Epoch)线性增长,模型训练速度逐渐加快。训练到指定轮次后,学习率开始逐渐衰减。在衰减过程中,随着学习率数值的减少,模型可以得到很好的细化,逐渐达到最优解。学习率上升时使用线性上升,下降时候模拟cos函数下降。学习率余弦退火衰减曲线如图5所示。
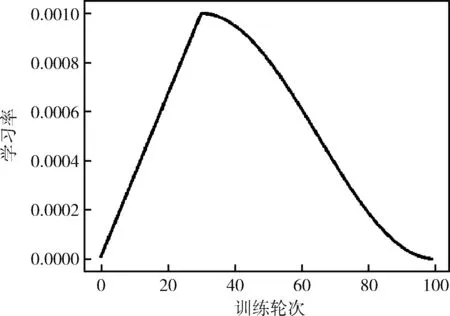
图5 学习率余弦退火衰减曲线
2.2.2 优化器
神经网络训练过程中的本质就是最小化损失,而在定义了损失函数后,优化器的作用就是对梯度进行优化。神经网络训练过程中常见的优化器有AdaGrad、RMSprop、Adam等。本次训练过程中使用Adam优化器进行优化。Adam优化器实现简单,计算高效,对内存需求少。其超参数具有很好的解释性,并且无需调整或仅需很少的微调。
2.2.3 损失函数
本文提出的算法损失函数由3个部分组成,分别是目标边框坐标损失(bounding_box_regression_loss)、置信度损失(condifence_loss)、分类损失(classification_loss),将3部分损失相加即为模型训练总损失。总损失函数公式如式(2)所示
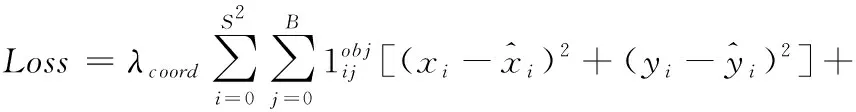
(2)
损失函数值中5项内容分别是:目标边框中心(x,y)坐标值损失、目标边框高与宽(w,h)的损失、置信度损失、无目标边框的置信度损失、分类损失(p),第一项与第二项组成目标边框坐标损失,第三项与第四项组成置信度损失,第五项为分类损失。其中,S为YOLO算法划分的网格数,B为每个网格预测的边界框数,C为分类数。一般取λc oord=5,λnoobj=0.5,使样本分布达到最优值,obj与noobj分别表示有目标与无目标的情况。
3 实 验
3.1 实验环境
本次训练图像工作站为PC机,实验采用WIN10 64位操作系统,CPU采用i9-9900k,显卡采用RTX2080Ti,在Python-TensorFlow1.13框架下进行,使用OpenCV4.2.0对图像进行数据增强,所有的样本尺寸为608×608×3。
3.2 改进的YOLOv4目标分类网络实验结果
对改进的YOLOv4目标检测中网络模型进行100轮迭代后,模型逐渐收敛到一个较好的数值。其中训练时学习率采用余弦退火衰减法,上升阶段采用线性增长,在第30轮迭代时学习率达到最大值0.001,随后模拟cos函数下降。改进的YOLOv4目标分类识别网络模型训练集和验证集上的损失值变化曲线如图6所示。
当迭次数达到100次时,模型在训练集上的损失降至0.65,在验证集上的损失降至0.66,模型能够有效的收敛。在5类样本验证集上的mAP值达到了97.63%,可见模型具有较好的分类检测性能,可以很好完成复杂构件分类的任务。5类样本验证集上的mAP值如图7所示。
验证集上的部分预测结果图像如图8所示。

图8 模型在验证集上的部分预测结果
3.3 算法性能评估
实验一:本文算法采用余弦退火衰减方法动态调整学习率,在算法迭代过程中,学习率会根据训练轮次不断调整,使模型训练效果达到最优。此操作缺点是在训练时需要不断更新学习率数值,增加了训练的时间。本次实验将固定学习率值(learning_rate=0.001)与学习率余弦退火衰减作对比,实验验证固定学习率虽然训练速度更快,但是在损失值以及mAP上远低于本文算法,检测性能差。其数据见表1。
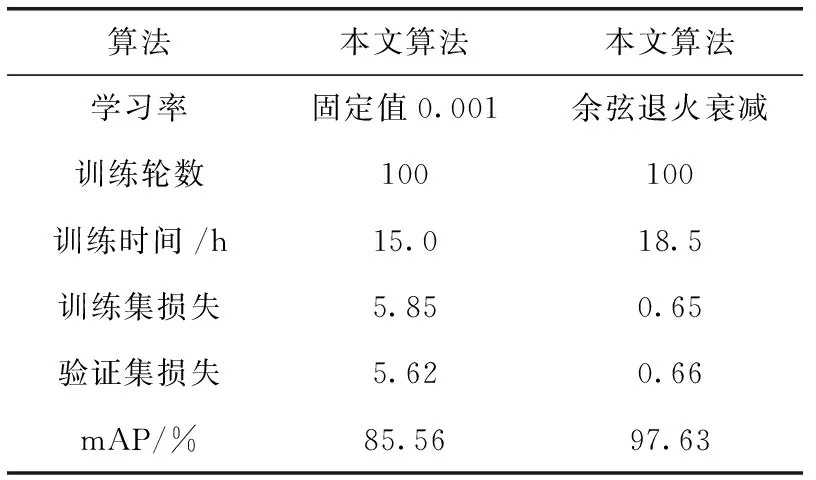
表1 学习率改进前后实验数据对比
实验二:本次实验将未经数据增强操作的原始数据集与经过平移、旋转、缩放、仿射变换的数据集分别送入本文提出的算法进行训练。原始数据集数据量少,训练时间短,但是模型训练效果差,泛化能力弱,对于一些角度变换、光照强度变化的图像样本检测能力弱,在验证集上的损失远远大于经过数据增强后的数据集。经过数据增强前后实验数据见表2。

表2 数据增强前后实验数据对比
实验三:本文将原YOLOv4算法进行改进,将原算法中残差卷积块的个数由5个调整为3个,各部分通道数缩减一半,同时只采用上采样结构而省略下采样结构,在不降低检测精度的前提下大大简化了网络结构。本次实验将本文算法与原YOLOv4算法用相同的数据集进行训练,实验结果表明本文算法在训练精度上与原算法持平,但在训练时间上远远低于原算法,有效地缩短了训练的时间。实验数据见表3。
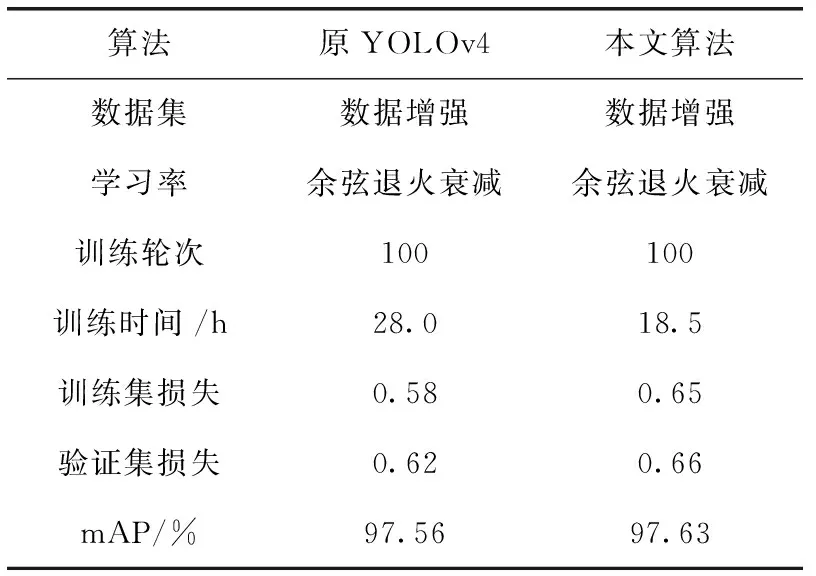
表3 原YOLOv4与本文算法实验数据对比
实验四:本次实验将本文算法与同类的目标分类检测算法YOLOv1、YOLOv3、SSD、RCNN等作综合对比。模型训练集与验证集所用图片均为本文所提出的复杂构件数据集,迭代次数为100轮。实验结果表明,本文算法在训练时间、检测精度上均高于同类算法,具有良好的性能。实验结果见表4。
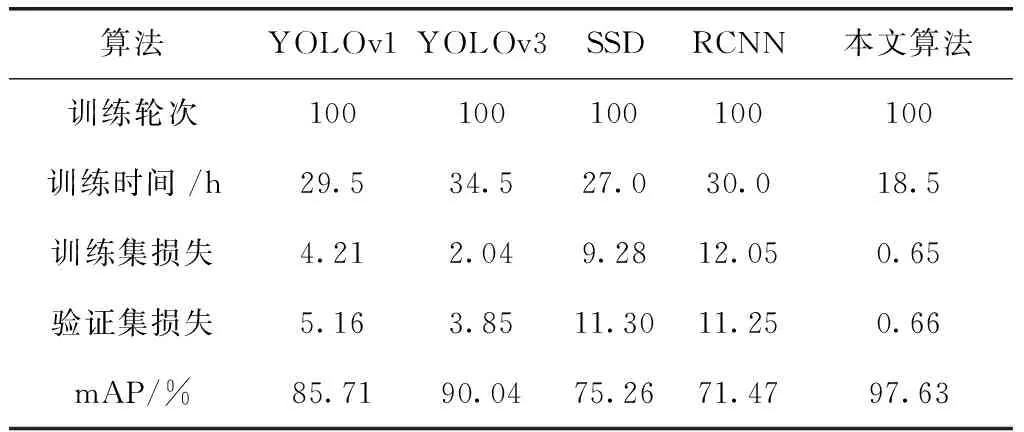
表4 不同算法实验数据
4 结束语
本文针对目前深度学习技术在航天设备复杂构件目标识别检测领域应用较少、缺少图像数据集等问题,首先在Solidworks三维建模软件上搭建复杂构件三维模型,通过在不同的角度截图制作复杂构件数据集,并采用平移、旋转、缩放、仿射等方式对图像进行数据增强。同时提出了一种改进的YOLOv4目标分类识别算法,将原YOLOv4算法中残差卷积块的个数由5个调整为3个,各部分通道数缩减一半,同时只采用上采样结构而省略下采样结构,在不降低检测精度的前提下大大简化了网络结构,节省了训练和预测的时间。实验数据结果表明,模型经过100轮迭代后,在训练集上的损失降至0.65,在验证集上的损失降至0.66,在5类样本验证集上的mAP值达到了97.63%,性能优于同类算法。检测速度快,检测精度高,可以很好完成复杂构件分类的任务,创新性地将深度学习目标检测技术应用到航天复杂构件的分类与检测。
