基于NSGA Ⅱ的生鲜品冷链配送联合调度优化
2022-09-30梁桂云陈淮莉
梁桂云,陈淮莉
(上海海事大学物流科学与工程研究院,上海 201306)
0 引 言
近年来,随着互联网技术日益成熟、用户消费习惯和理念的转变,生鲜电商行业得到迅速发展。2020年受新冠疫情影响,消费者对于生鲜到家的需求急速增长,中国生鲜电商交易额达到1 821.2亿元。由于生鲜品具有易腐性和保质期短的特点,生鲜电商企业须在完成对生鲜品的流通加工后立即组织安排配送。然而,目前生鲜电商企业大多凭经验来判定各岗位的员工调度,由此带来加工环节混乱、配送延迟和各种资源的紧缺与冲突等众多问题。因此,如何协同优化流通加工与配送这两个环节,在降低总成本的同时保证交付产品的新鲜度,一直是生鲜电商企业关注的问题。
关于生鲜品的生产加工和配送联合调度(production and distribution integrated scheduling,PDIS)问题的研究如下:AMORIM等研究分批和批量两种生产模式下的生鲜品PDIS问题,通过算例验证了批量生产能够降低总成本。BELO-FILHO等设计了一种自适应大邻域搜索算法求解生鲜品PDIS问题。SEYEDHOSSEINI等提出了一种考虑批量生产和库存路径的生鲜品PDIS模型,并开发了启发式算法进行求解。DEVAPRIYA等研究了保质期约束下的生鲜品PDIS问题,通过遗传算法对所构建的生鲜品PDIS模型进行求解。吴瑶等基于路网交通状况的时变性,构建了以配送成本与产品价值损耗总和最小为目标的优化模型,并设计了混合遗传算法进行求解。马雪丽等考虑生鲜品的需求和配送时间的随机性,研究了生产商和零售商两级供应链模式下的生鲜品PDIS问题,并利用基于随机模拟的混合遗传算法进行求解。LACOMME等研究了单一生鲜品生产和多车运输一体化问题。王旭坪等根据在线订餐问题特点,将生产环节和配送环节分别抽象为并行机调度问题和带时间窗的车辆路径问题(vehicle routing problem with time window, VRPTW),以服务所有订单需要的总时间之和最小为目标,构建并行机生产多车多任务配送联合优化模型,并设计了三阶段启发式在线调度算法进行求解。李畅等在关于生鲜品PDIS问题中考虑了生鲜品保质期和客户购买行为,并通过算例验证了所建模型的有效性。DAYARIAN等根据生产人员配置建立了生鲜品PDIS优化模型,再根据模型特点设计了新的分支定价算法进行求解。LIU等以最小化配送时间为目标建立了生鲜品PDIS优化模型,并设计了一种改进的大邻域搜索算法进行求解。LI等研究了考虑食品包装因素影响的生鲜品PDIS问题,利用混合整数线性规划方法来描述这个新问题,提出了两种分支切割算法,计算结果表明包装与生产路线的集成优化可以带来经济效益。SOLINA等考虑生产加工的转换时间和产品易腐性约束,以最小化生产和配送成本为目标建立了一个生产和分销的综合调度优化模型。
以上关于生鲜品PDIS的文献大多考虑单目标或者将多个目标转化为单目标进行研究。经济的发展和生活质量的改善使得人们对商品品质的要求逐渐提高,而新鲜度作为决定生鲜品品质的重要指标越来越受到重视。少数学者开始在关于多目标生鲜品配送路径优化的研究中考虑产品交付时的新鲜度:李畅等在生鲜品配送路径优化的研究中构建了以最大化新鲜度和最小化配送成本为目标的生鲜品配送路径优化模型,并利用基本自适应差分进化算法进行求解;李善俊等将生鲜品新鲜度与多目标VRPTW进行结合,建立最大化生鲜品新鲜度和最小化配送成本的多目标车辆路径优化模型,并设计了非支配排序遗传算法(non-dominated sorting genetic algorithm,NSGA)进行求解。然而,少有文献将生鲜品的新鲜度与多目标生鲜品冷链配送联合调度问题相结合。因此,本文在以往文献研究成果的基础上,以产品交付时新鲜度最大和总成本最低为目标,建立多目标生鲜品冷链配送联合调度优化模型,并利用第二代非支配排序遗传算法(NSGA Ⅱ),获得满足产品交付时新鲜度最大和总成本最低的相对较优解。
1 问题描述和模型建立
1.1 问题描述和模型假设
结合生鲜品加工和配送的特点,将多目标生鲜品冷链配送联合调度问题描述为:如图1所示,一个生鲜电商配送中心向多个客户提供生鲜品送货上门服务。生鲜电商企业在平台接收客户订单后,根据订单需求安排多名加工人员进行加工,每个订单产品种类不同且不可拆分。订单加工完成后立即分批组织车辆进行配送,忽略装车时间。针对生鲜品易腐和保质期短的特点,需要将流通加工环节与配送环节进行联合调度。同时,为了提高客户满意度和生鲜电商企业的利润,需要在追求产品交付时新鲜度最大和总成本最低两个目标的基础上决策:订单分配给加工人员、各加工人员的订单加工顺序、已完成加工的订单生成合理的配送车次,以及各车次的订单交付顺序。本文采用文献[15]中定义的()表示产品新鲜度。根据生鲜品价值随运输时间加速递减的特点,令()为生鲜品的价值损耗系数,为订单产品的保质期,则()=eln(2)-1,从而()=1-()。

图1 生鲜品加工配送流程示意图
由于多目标生鲜品冷链配送联合调度的复杂性,为便于模型的构建和求解,假设:(1)客户地理位置、客户要求服务的时间窗、产品的需求量和保质期等信息已知;(2)每个客户只被服务一次,每个订单只包含同一类产品且加工时间均不同;(3)加工中心采取并行机加工模式,由多个能力相同的加工人员进行加工,不考虑订单加工的等待时间;(4)每个订单仅由一名加工人员负责加工,订单不可拆分且只被加工一次,忽略不同订单之间的切换时间和成本;(5)有多辆车(其容量是相等的)负责配送,不存在等待配送情况;(6)每车次负责配送一条路径,该车次从配送中心的发车时刻不早于对应路径上最后一个订单的加工完成时刻;(7)车辆完成一次配送后立即返回配送中心;(8)生鲜品离开配送中心时新鲜度最大。
1.2 参数定义

1.3 模型构建
本文将流通加工环节抽象为并行机调度问题,将配送环节抽象为VRPTW。由于每个订单的加工成本是固定的,而配送成本不是固定的,因此将配送总成本作为目标之一。配送总成本主要包括运输成本、固定成本、延迟成本、等待成本和产品价值损耗成本。基于上述分析和参数定义,模型建立如下:




(1)

(2)
s.t.

(3)

(4)

(5)

(6)

∀,∈,≠,∈
(7)

(8)

(9)

(10)

(11)

(12)

(13)

∀,∈,∈
(14)

(15)

(16)
()≥
(17)
={0,1}, ∀,∈,∈
(18)
={0,1}, ∀,∈,∈
(19)
={0,1}, ∀∈,∈
(20)
式(1)表示配送总成本最低;式(2)表示产品交付时平均新鲜度最大;式(3)表示最多只有一个订单是由加工人员第一个加工的;式(4)和(5)表示所有订单均被生产加工;式(6)表示加工人员的订单加工顺序;式(7)表示订单的后续紧邻订单的生产加工完成时间;式(8)和(9)表示所有客户均被服务且只访问一次;式(10)表示路径流量平衡;式(11)表示每辆车配送完成后必须返回配送中心;式(12)表示每条路径满足车辆容量约束;式(13)表示每条路径的开始配送时间不早于该路径上所有订单的生产完成时间;式(14)~(16)表示每条配送路径上的时间关系约束;式(17)表示交付的产品满足最低新鲜度要求;式(18)~(20)为0-1变量约束。
2 NSGA Ⅱ设计
本文提出的多目标生鲜品冷链配送联合调度问题是传统PDIS问题的延伸,PDIS问题已被证明是NP难问题,因此多目标生鲜品冷链配送联合调度问题也是NP难问题。CPLEX只适合求解现实生活中较为简单的小规模算例,因此无法通过CPLEX在合理的时间内获得本文问题的解。而智能优化算法已被广泛地应用于大规模、复杂度高的算例中。与单目标优化问题的不同在于,在考虑多个目标时,这些目标通常都是相悖的,很难在不降低一个目标性能的前提下提高另一个目标性能。在实际的经营活动中,决策者会根据不同的场景和自身的经验以及偏好在所得的帕累托最优解集中选择一个或者多个相对合适的帕累托最优解作为实际问题的解决方案。因此,为得到多目标生鲜品冷链配送联合调度问题的帕累托最优解集,本文根据所提问题和模型的特点,利用NSGA Ⅱ对构建的模型进行求解,算法流程见图2。

图2 NSGA Ⅱ流程
2.1 染色体编码和种群初始化
根据所建模型的特点,设计以下编码方案:染色体采用自然数编码;染色体包含3个子串(订单加工顺序子串,负责加工各订单的加工人员子串和配送路径子串)。这种编码方式的优势在于可以十分便捷地将信息直接输入染色体中,不需要复杂的计算和解码过程。例如,加工配送中心有6个客户订单待服务,有2名加工人员,若生成的染色体如图3所示,则该染色体表示加工人员1需要依次加工订单3和6,加工人员2需要依次加工订单1、2、4、5,配送中心共需要发出3个车次。在配送路径子串3中0用于分隔不同车次,表示车辆从配送中心出发最终又回到配送中心。

图3 染色体示意图

2.2 快速非支配排序和个体拥挤度比较
2.2.1 快速非支配排序
快速非支配排序是NSGA Ⅱ的关键步骤之一,其基本原理是根据种群中染色体之间的支配关系对种群进行等级划分,从而使算法可以快速向帕累托前沿方向进行搜索。将本文问题转换为最小化问题后,假设支配染色体的染色体的数量为,被染色体支配的染色体的集合为。快速非支配排序的主要步骤如下:
分别计算种群中每一个染色体的和,如果染色体支配染色体,即<,则=∪{};如果染色体支配染色体,则=+1;直至种群所有染色体均进行了比较。
遍历种群中所有的染色体,当染色体不受任何其他染色体支配,即=0时,将染色体纳入第一非支配层,并令中所有的染色体的非支配序=1,令=0。
=+1,当第非支配层不为空集时,对于中的每一个染色体以及被染色体支配的任一染色体,令=-1。当=0时,则令染色体的非支配序=+1。
判断第+1非支配层+1是否为空:若为空,快速非支配排序终止,否则转步骤3。
由上述步骤可以得到≻≻…,其中中的解比中的解具有更高的优先度。与非支配排序相比,快速非支配排序的优点在于不仅能够快速对种群进行等级划分,而且能够将算法的复杂度由()(为目标函数数量)降到(),极大地提高了算法的运算效率。
个体拥挤度比较是NSGA Ⅱ的另一关键步骤,其基本原理是首先计算同一非支配层中所有个体的拥挤距离,然后根据拥挤距离的大小对同一非支配层中的个体进行优先级排序。个体的拥挤距离是指在目标空间中紧邻的两个个体与之间的距离。本文中,目标函数的数量=2。个体拥挤度比较主要步骤如下:
初始化同一非支配层中所有个体的拥挤距离:令为同一非支配层中任意个体的拥挤距离,令=0。
计算同一非支配层的所有个体的第′个目标函数值,并按照目标函数值升序排列。
令排序在边缘的个体的拥挤距离值等于最大的距离值,使得排序在边缘的个体具有选择优势。
对任意排序在中间的个体,计算其拥挤距离:


2.2.4 自卑心理:当肠造口开放,患者容易感觉到该病不仅对自身的形象构成严重影响,甚至还给家人带来了较大的麻烦,严重时甚至还会导致家庭、社会关系破裂,如朋友远去、夫妻离婚等,从而导致其产生自卑、自闭心理。
循环执行步骤2~4,直至计算出该非支配层中所有个体在第′个目标函数下的拥挤距离。
为使帕累托最优解集分布更加均匀以及提高解的多样性,拥挤距离较大的个体被选中的概率更大。同时采用锦标赛方法从父代种群中选择染色体进行交叉和变异操作,生成新的子代。在每次锦标赛选择过程中,当被选中的染色体属于同一非劣等级,即值相同时,优先选择拥挤距离较大的染色体;当被选中的染色体属于不同非劣等级,即值不同时,优先选择非劣等级较低,即值较小的染色体。
2.3 交叉和变异操作
算法在进化过程中主要通过交叉和变异操作生成新的个体,因此交叉和变异操作对于算法的全局搜索能力具有重要影响。本文交叉操作采用基于位置的交叉(position-based crossover,PBX)方式和单点交叉方式。按照设置的交叉概率,对染色体的子串1和子串3进行PBX操作,对子串2进行单点交叉操作。
如图4所示,PBX的操作步骤如下:①随机选择一对染色体(父代)中的几个基因,位置可不连续,但两条染色体被选位置相同。②生成初子代 1和初子代 2,使得父代中被选中的基因保持位置不变被遗传到初子代 1和初子代 2中,其他基因位暂时空置。③先找出父代1(2)中选中的基因在父代2(1)中的位置,将其该位置上的基因删除,再将剩余的基因按顺序放入初子代1(2)中,即得到子代1(2)。

图4 PBX操作示意图
本文在进化过程中的变异操作主要包括次序逆转变异和随机变异。按照设置的变异概率,对染色体的子串1和子串3采用次序逆转变异的方式。若经交叉后得到的子代染色体的子串1和子串3满足次序逆转变异的条件,则分别在子串1和子串3上随机选择两个变异点,对变异点之间的基因段进行倒序排列;对子串2采用随机变异的方式,即在子串2中选择任意基因位进行变异,基因取值不超过加工人员的总数量。
当算法的最大迭代次数达到1 000时,算法终止并输出结果。
3 算例分析
3.1 算例设置
目前还没有PDIS的标准测试算例,本文构建的模型的加工环节为并行机调度问题,配送环节为VRPTW,因此借鉴关于VRPTW研究的Solomon算例中R101类数据。因为Solomon公开的研究数据均无量纲,所以本部分所有数据均无量纲。假设订单加工时间服从均匀分布,~[2,5],订单的保质期在客户时间窗结束时刻的基础上随机加减60。
NSGA Ⅱ的参数设置:种群规模为100,最大迭代次数为1 000,交叉概率为0.8,变异概率为0.2。为提高算法的收敛速度和效率,一开始不考虑产品交付时最低新鲜度约束,在算法迭代结束后再考虑该约束,具体表现为在所得的帕累托解集中剔除低于最低新鲜度的解。算法采用MATLAB 2016b编程实现,程序在核心参数为4核CPU,2.10 GHz主频,16 GB内存和Windows 10操作系统的计算机上运行,其他实验参数见表1。

表1 实验参数
3.2 实验结果与分析
3.2.1 考虑新鲜度和总成本的多目标生鲜品冷链配送联合调度方案分析
以订单规模为30、加工人员数量为3为例进行计算,算法运行10次。算例进化过程如图5所示,其中总成本的进化曲线随着迭代次数的增加呈现稳定下降的趋势,新鲜度的进化曲线在迭代到150次左右已收敛到最优解附近,后又经过将近100次迭代跳出局部最优,说明NSGA Ⅱ在多目标求解过程中具有良好的搜索能力和收敛性。

a)总成本
对于实际的生鲜电商企业来说,总成本与新鲜度之间存在着相互制约的关系,增加配送车次可以在一定程度上减缓产品新鲜度的降低,但也意味着总成本的增加,反之亦然,难以找到使两者均达到最优的解。因此,本文求解的是帕累托最优解集,见图6。在帕累托最优解集中的解都是相对较优解,不能简单地比较解的优劣。表2给出了从帕累托最优解集中随机选择的一个解(即其中一个多目标生鲜品冷链配送联合调度方案),其中在第2列“加工配送时间”中分别列出了各加工人员的加工结束时间和各车次访问对应客户点的时间。这个联合调度方案的总成本为2 655.22,产品交付时的平均新鲜度为0.843,共需要发出6个车次。根据联合调度方案绘制出配送路径图,见图7。

图6 帕累托最优解集

表2 多目标生鲜品冷链配送联合调度方案

图7 配送路径图
3.2.2 实验结果对比分析
为测试算法的性能,分别利用NSGA Ⅱ与NSGA对所建模型进行计算和对比。实验共设置3种情景:情景1的种群规模为100,最大迭代次数为800;情景2的种群规模为150,最大迭代次数为800;情景3的种群规模为150,最大迭代次数为1 000。在R101类数据中分别选取客户规模为30和60的数据进行测试。NSGA Ⅱ与NSGA的计算结果见表3。
由表3可得,NSGA Ⅱ与NSGA得到的帕累托解的个数均随着迭代过程中产生的邻域解的个数的增加而增加,且计算时间均越来越长,但是NSGA Ⅱ的耗时比NSGA的短,说明NSGA II的计算效率高。在客户规模为30的情景1下,与NSGA相比,用NSGAⅡ计算得到的总成本增加了5.73%,但新鲜度提高了9.06%;在客户规模为30的情景3下,与NSGA相比,用NSGA Ⅱ计算得到的总成本减少了5.15%,但新鲜度降低了4.06%;在其他客户规模和情景下,用NSGAⅡ计算得到总成本和新鲜度均优于用NSGA计算得到的结果,验证了NSGAⅡ和本文所建模型的有效性。
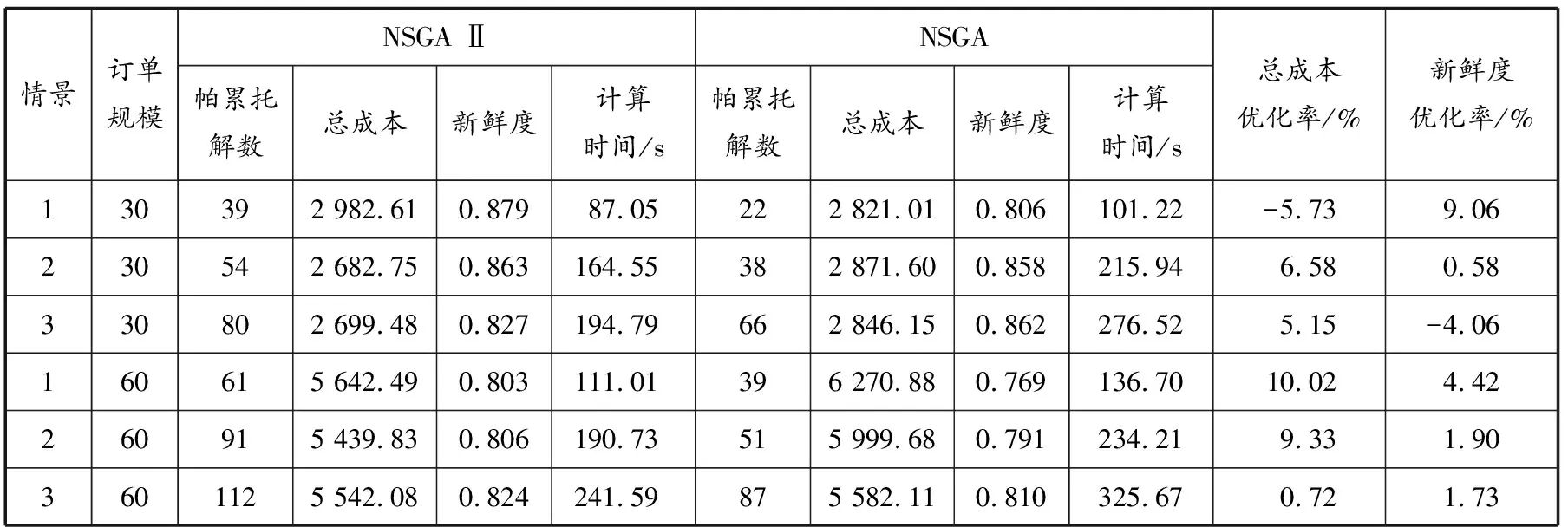
表3 NSGA Ⅱ和NSGA计算结果和算法性能指标对比
为进一步探究本文模型和算法的适用场景,从调度范围随机均匀分布的R1实例和调度范围较小的RC1实例中分别选取客户规模为30、50、80和100的算例进行对比。将本文多目标优化模型与传统的不考虑新鲜度的单目标生鲜品冷链配送联合调度优化模型(简称“单目标优化模型”)进行对比,利用遗传算法对单目标优化模型进行求解,得到的结果见表4。

表4 多目标优化模型与单目标优化模型结果对比
由表4可得,基于传统单目标优化模型所得的总成本要略低于基于多目标优化模型所得的总成本,这是因为单目标优化模型不考虑新鲜度约束,所获得的解可能是局部最优解。然而,从表4可以明显看出,多目标优化模型对新鲜度的优化效果较好:基于单目标优化模型所得的总成本比基于多目标优化模型所得的总成本降低了2.18%~4.81%,但基于多目标优化模型的新鲜度结果比基于单目标优化模型的提高了5.03%~12.92%。这表明,生鲜电商企业在采用单目标优化模型时只需要略微提高经营成本就能够得到较高的客户满意度,在越来越注重服务水平的生鲜电商行业中获得更显著的竞争优势。由图8可知:无论是R1的客户类型还是RC1的客户类型,随着客户规模的增加,多目标优化模型对新鲜度的优化效果更佳,说明本文提出的多目标优化模型更适合于客户规模较大的场景;对调度范围随机均匀分布的R1实例的新鲜度优化率整体高于调度范围较小的RC1实例的新鲜度优化率,这说明本文提出的多目标优化模型更适合调度范围较大的场景。

图8 本文多目标优化模型的新鲜度优化率
4 结 论
本文提出基于新鲜度最大和总成本最低的多目标生鲜品冷链配送联合调度问题,考虑了产品的易腐性、配送延迟、交付时间窗、配送路线、订单加工排序以及加工人员调度。对于这个复杂的问题,本文利用第二代非支配排序遗传算法(NSGAⅡ)得到了满足新鲜度最大和总成本最低的相对较优解,验证了本文模型的有效性。同时实验结果表明,本文所建的多目标优化模型在客户规模和配送调度范围较大的情景下优化效果更佳,这对生鲜电商企业在不同情景下的决策具有一定的参考价值。该模型是在假设可获得的数据是确定的前提下提出的,没有考虑实际活动中的不确定因素,因此在未来研究中可以在此基础上考虑不确定性等情况。
