基于无人机图像和改进YOLOv3-SPP算法的森林火灾烟雾识别方法
2022-09-28祖鑫萍李丹
祖鑫萍,李丹
(东北林业大学信息与计算机工程学院,哈尔滨 150040)
近年来,随着地球气候的不断变化,森林火灾在世界各地频繁发生,对人类生命财产安全和生态环境构成严重的威胁。森林火灾通常蔓延极快,成灾范围广,难以控制,因此在森林火灾早期进行积极有效的探测和预警至关重要。
传统的监测技术有传感器监测、红外监测、卫星遥感监测等。传感器(烟雾、温度探测器等)无法提供火势大小、具体位置等火情信息,且在开阔的林区安装成本较高,因此并不适用于森林火灾监测。红外监测方法对监测距离要求较高,易受周边环境的干扰,从而发生漏判、错判等现象。卫星遥感监测技术的时间和空间分辨率较低,扫描周期长,无法探测早期区域火灾[1]。
随着图像处理技术的发展,研究人员开始寻求新的森林火灾智能探测方法。例如,Çelik等[2]基于YCbCr构建了用于火焰颜色分类的色度模型,该算法复杂度低,可用于实时监测。Zhao等[3]通过融合烟雾的颜色特征、颤振特征和图像能量特征构建了用于识别早期森林火灾的烟雾模型,该模型能够排除森林水雾的干扰从而准确识别森林火灾早期烟雾。Chino等[4]提出了一种新颖的用于识别静态图像火灾算法BowFire,该算法通过集成颜色特征与超像素区域纹理特征,降低静态场景的误报率。综上所述,目前传统图像处理方法的特征学习过程很烦琐并且探测效果十分依赖于人工选择特征的优劣[5]。
近年来,基于卷积神经网络(convolutional neural networks,CNN)的深度学习技术得到越来越多关注,深度学习凭借其强大的特征提取能力,能够获取更深的图像语义信息,并且具备端到端的模型训练过程,能够有效避免人工选取特征的复杂性和局限性[6-7]。随着深度学习的发展,有研究人员将深度学习算法应用于森林火灾探测领域。Lee等[8]提出了一种基于Faster R-CNN(Faster Region-CNN)算法的火灾探测模型,该模型考虑图像的全局和局部特征,结果表明,该算法的假阳性检测率降至0.1%左右,明显低于传统方法,具有良好防误判能力。Liu等[9]基于HOG-Adaboost和CNN-SVM提出了一种多层次的火灾识别方法,该模型通过对火区二次识别,在训练样本较少情况下提高了森林火灾识别率。Majid等[10]提出了一个基于关注的CNN模型,该模型融入注意力机制并使用Grad-CAM方法,帮助网络对真实图像中的火灾进行更好的可视化和定位。Cheng等[11]基于多尺度卷积神经网络开发了一种稳健的VFD(video fire detection)融合模型,有效解决因裁剪导致图像特征丢失的问题,从而提升火灾的探测效果。
现有算法虽然探测准确度较高,但网络层数较深,识别速率较慢。本研究拟将Focus模块、解耦头、无锚框(anchor-free)检测机制和SimOTA(simplified optimal transport assignment)动态标签分配策略引入YOLOv3-SPP(you only look once version three-spatial pyramid pooling)模型中,利用无人机拍摄的森林火灾遥感影像对改进的YOLOv3-SPP模型进行训练、评估,以提高森林火灾识别的准确度与时效性。
1 材料与方法
1.1 试验环境
本试验基于Keras 2.2.4学习框架搭建森林火灾烟雾识别模型,操作系统为Ubuntu 18.04.2,GPU为NVIDIA GTX1080,Python版本为3.6。

图1 基于无人机的森林火灾烟雾数据集Fig. 1 UAV-based forest fire smoke dataset
1.2 数据集
试验所使用的数据来源于两方面,一方面是从文献[12]中获取的广泛用于评估森林火灾烟雾识别模型的公开数据集,包括1 400多幅烟雾图像;另一方面是基于无人机采集的西昌地区近10年的森林火灾烟雾视频(图1)。为将视频分解成模型输入所需图像,利用OpenCV图像处理库将视频进行分帧处理,即每15帧截取一张图像。通过对数据进行筛选整理最终获得约5 500幅图像。
首先将森林火灾烟雾图像调整为608×608像素,然后利用LabelImg工具对图像中烟雾进行标注,标签为smoke,最后从数据集中随机取出1/10作为测试集,剩余图像数据按照9∶1的比例随机分为训练集和验证集。
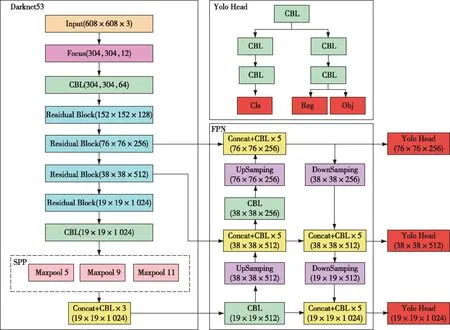
图2 改进的YOLOv3-SPP网络结构Fig. 2 Network structure diagram of improved YOLOv3-SPP
1.3 YOLOv3-SPP网络模型
YOLOv3作为YOLO系列的第三代网络,是目前最常用的One-stage目标识别算法之一[13]。YOLOv3的网络结构主要分为三部分,分别是基于DarkNet53的主干特征提取网络、特征金字塔融合结构(feature pyramid networks,FPN)和预测结构(Yolo Head)。DarkNet53结构由5个残差块(Residual Block)跳跃连接,每个残差块由两个卷积构成,卷积核为1×1和3×3,缓解了卷积层数增加导致的梯度消失问题。YOLOv3模型中,每一个基本卷积单元(CBL,CBL=Convolutional+Batch Normalization+Leaky Relu)由卷积、批量标准化层和Leaky Relu激活函数构成。在特征金字塔融合阶段,对DarkNet53结构输出3个有效特征层进行融合,即通过上采样的方式将不同尺度的特征层进行拼接,扩宽网络的感受野,实现多尺度目标检测。融合后的3个加强特征层最终输入Yolo Head中进行预测,通过对预测结果进行解码,得出最终边界框的中心点坐标和高宽等信息,计算公式如下:
bx=α(tx)+cx
(1)
by=α(ty)+cy
(2)
bw=pw+etw
(3)
bh=ph+eth
(4)
式中:bx、by、bw、bh为边界框的中心点位置及宽和高;α为sigmoid激活函数;tx、ty、tw、th为模型输出结果偏移量;cx、cy为该点对应网格的左上角坐标;pw、ph为先验框的宽和高。
YOLOv3-SPP模型在YOLOv3主干特征提取网络后增加了一个空间金字塔池化结构(spatial pyramid pooling,SPP)模块,此模块利用多个并行分支学习不同尺度的特征,拓展了模型感受野,提升对不同尺度图片的识别效果。
1.4 改进的YOLOv3-SPP网络模型
本研究对YOLOv3-SPP网络模型从4个方面进行改进(图2)。首先在主干特征提取网络中使用Focus网络结构,在扩展每个像素点感受野、减少火灾图像原始信息丢失的同时,减少后期卷积运算量,加快网络特征提取速度。其次,在Yolo Head中使用解耦头,将分类与回归拆分成两个独立的模块进行,避免二者产生冲突,提高模型预测准确度。再次,利用无锚框检测器对物体边界直接预测,减少计算锚框的参数,简化解码过程。最后,在模型训练过程中采用SimOTA动态标签分配策略动态为不同目标选取不同数量正样本,避免额外的参数优化,从而加快模型训练速度。
1.4.1 Focus模块
改进的YOLOv3-SPP模型在图片输入预处理完成后,利用Focus模块对其进行切片处理,Focus模块结构如图3所示。首先,将图片每隔一个像素取一个值,这些值通过整合形成4个独立的特征层,这些特征层完好保留了图片所有信息;之后,将4个特征层纵向通道进行拼接,此时高、宽维度上的信息便集中到通道空间。输入图片尺寸设定为608×608×3,经过切片处理形成304×304×12的特征层,输入通道扩大4倍,减少之后卷积运算的计算量,提升模型特征学习速度。
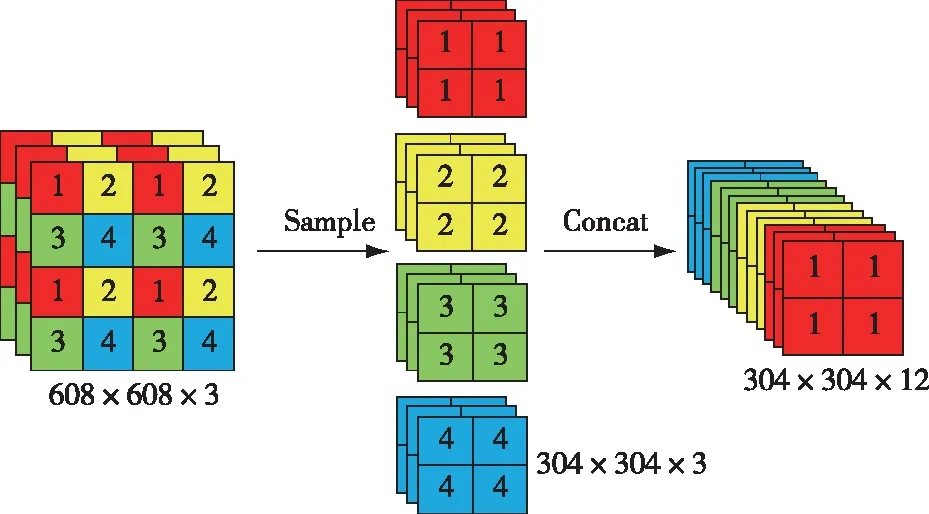
图3 Focus模块结构Fig. 3 Module structure diagram of Focus
1.4.2 解耦头
原始YOLO系列算法的Yolo Head分类与回归任务通过一个1×1卷积完成。但分类更关注每一个样本的纹理内容,回归更关注物体图像的边缘特征,二者的关注点不同,会在预测过程中出现冲突,导致模型性能降低。因此利用解耦头将分类与回归任务进行解耦。
解耦头网络结构图如图4所示:对于输入的特征层,解耦头会利用1×1卷积对其进行降维,然后利用两个平行通道分别进行对象分类和目标框坐标回归任务。为降低解耦头复杂度,提高模型收敛速度,每个通道使用了2个3×3卷积。通过处理可以获得Cls、Reg和Obj 3个输出值,其中,Cls为目标框对应的种类,Reg为目标框的位置信息,Obj为每个特征点是否含有物体。将3个输出值进行融合,得到最终的预测信息。
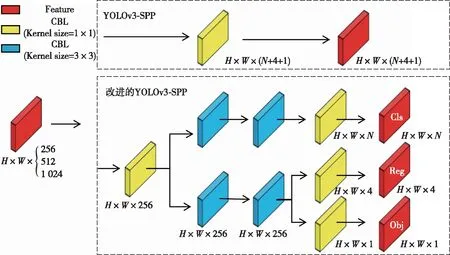
图4 解耦头网络结构Fig. 4 Network structure diagram of Decoupling Head
1.4.3 无锚框检测器
YOLOv3-SPP模型基于锚框检测器每个特征层的3个预测结果Cls、Reg和Obj进行解码,提取预测框的位置并计算与真实框的差距。然而在实际训练中,锚框检测器需要计算锚框与真实框的重合程度值,复杂度较高[14]。因此,利用Anchor-free检测器代替锚框检测器,使预测网络能依据Reg中目标位置信息直接预测网格左上角的两个偏移量和预测框的高宽,从而将每个锚框的预测参数减少2/3。同时,设定每个物体中心点为正样本并定义一个比例范围,便于指定每个物体FPN水平,减少模型GFLOPS的参数量计算,提高模型的识别速度。
1.4.4 动态标签分配策略
在训练过程中,由于标准动态分配策略中的经典Sinkhorn-Knopp算法需反复迭代才能挑选出正样本锚框,时间成本较高。因此引入SimOTA方法[15]。SimOTA方法通过引入Cost代价矩阵计算每个真实框和预测框IoU(intersection over union)值、种类预测精确度和真实框中心点与特征点半径位置关系,使每个特征点能够自适应地寻找应去拟合的真实框。
SimOTA方法主要分为3个步骤:第一,将候选框数量设定为10,并根据Cost值选出重合度最高的10个特征点;第二,将这10个特征点构成的预测框分别与真实框进行IoU计算,并将结果进行求和从而得到每个真实框对应的特征点数k(k≥1);第三,为每个真实框选取Cost最低的k个锚框作为正样本。
1.5 模型评价指标
在目标识别任务中,采用交叉熵损失函数(cross-entropy Loss,L)、精确率(precision,P)、召回率(recall,R)、F1分数(F1-score,F1)、平均精度均值(mAP,MAP)、识别速率评估所提出的方法。交叉熵损失函数(L)用来度量模型的预测结果与真实值之间的差异程度,值越小,模型鲁棒性越强,其计算公式为:
(5)
精确率是指在所有识别到的样本中,被正确识别的样本所占比例;召回率指在所有应该被正确识别的样本中,被正确识别的样本所占比例;F1分数兼顾了假阳性与假阴性,并结合了精确度和召回率两个指标;识别速率代表每秒钟模型处理图片的帧率,值越高,识别速率越快。
(6)
(7)
(8)
式中:TP为正确识别森林火灾图像的数量,即真阳性;FP为错误识别的森林火灾图像的数量,即假阳性;FN为未能识别的森林火灾图像,即假阴性。
(9)
式中:ΣAPclasses为各类别平均精度的总和;Nclasses为所有类别的总数。mAP值越高,模型性能越好。
由于森林火灾识别要求实时性,所以算法的识别速率也是衡量模型优劣的重要指标之一。公式如下:
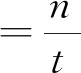
(10)
式中:n为处理的总帧数;t为处理相应帧需要的时间。
2 结果与分析
2.1 试验参数设置与网络训练
本实验在训练模型时,将alpha设置为1,训练批次大小设置为16,初始学习率设置为0.001。为提高训练速度,将主干网络冻结并进行50 epoch的网络训练,然后将其解冻并将学习率设置为0.000 1,训练批次大小设置为8,训练150轮次。采用迁移学习的手段对模型进行训练。由于前50轮次训练网络被冻结,训练参数改变较少,训练速度较快。根据训练日志,描绘出模型损失函数值的变化曲线如图5所示。由图5可知,YOLOv3-SPP模型和改进后的YOLOv3-SPP模型在解冻后均快速收敛,而改进后的YOLOv3-SPP模型的损失值最终稳定在3.5左右,较改进前降低了6,这表明改进的YOLOv3-SPP模型的鲁棒性更好。
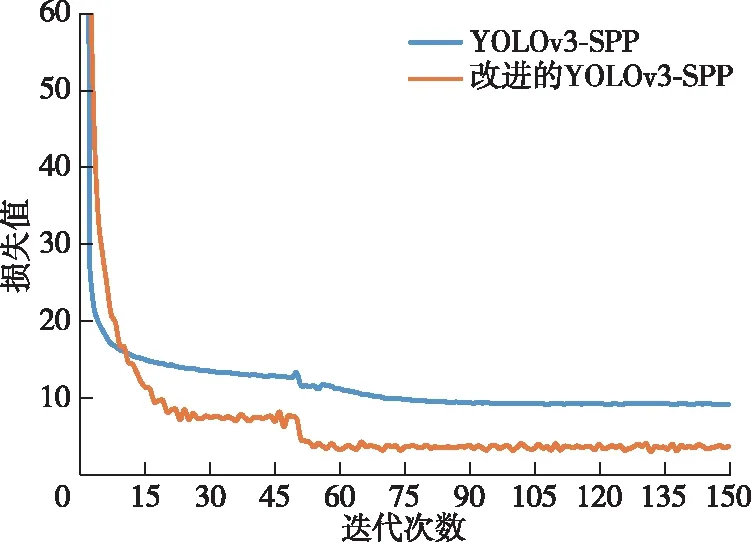
图5 模型训练损失曲线Fig. 5 Model training loss curves
2.2 消融实验
为验证改进部分对森林火灾烟雾识别模型性能的影响,对基于YOLOv3-SPP网络仅使用Focus模块改进的模型(YOLOv3SPP+F)、仅使用解耦头改进的模型(YOLOv3SPP+DH)、仅使用无锚框检测器改进的模型(YOLOv3SPP+AF)和仅使用SimOTA策略改进的模型(YOLOv3SPP+S)分别实验,结果如表1所示。
从表1数据可知,引入Focus模块的烟雾识别模型检测帧率提高了11 帧/s,说明通过扩张特征层输入通道有效减少了卷积运算量。在预测网络中引入解耦头,虽然模型识别速度有所下降,但精确率和mAP分别提升了0.86%和1.75%,说明该模块能有效提高模型对烟雾识别的准确性。利用无锚框检测器代替锚框检测器,降低了计算锚框参数量,检测帧率提升了13帧/s。引入SimOTA策略避免了通过反复迭代挑选正样本锚框过程,减少计算量,精确率和mAP分别提升了0.28%和0.53%。实验结果表明,同时引入上述4种改进策略可有效提升模型对森林火灾烟雾识别的准确性和识别速率。
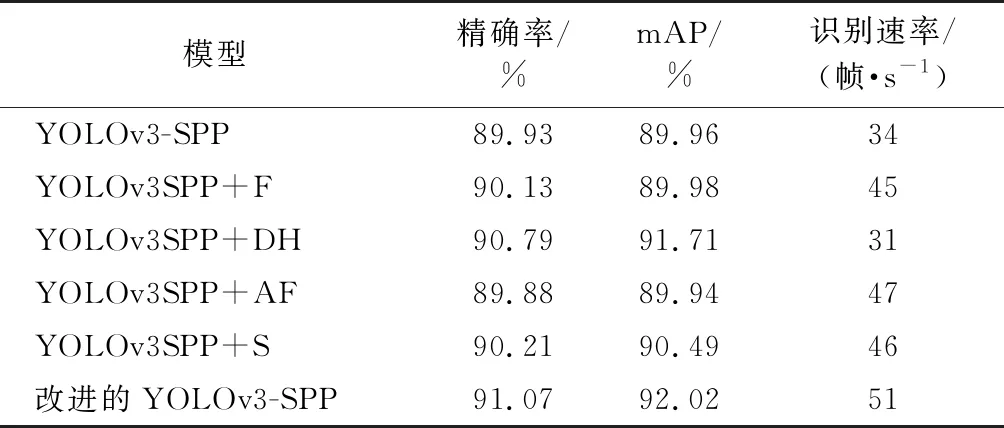
表1 消融实验结果Table 1 Ablation experiment results
2.3 模型对比分析
模型训练完成后,将YOLOv3-SPP和改进的YOLOv3-SPP模型在测试集上进行对比实验,模型输出参数见表2。改进的YOLOv3-SPP模型精确率、mAP、F1分数、召回率和识别速率较改进前分别提高了1.14%、2.06%、0.04、15.03%和17帧/s,这表明改进后的模型识别效果更好、识别速率更快,具有更高的森林火灾烟雾识别工程的实用性。
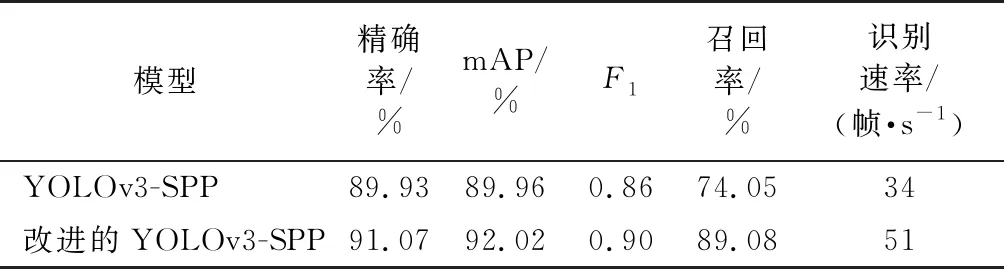
表2 2种模型进行烟雾识别综合性能对比Table 2 Comprehensive performance comparison of two models for smoke recognition
根据训练模型对森林火灾烟雾进行识别得到的预测效果见图6。可以发现,YOLOv3-SPP和改进的YOLOv3-SPP模型都完成森林火灾烟雾的识别,包括定位烟雾区域、输出预测框置信度和类别,但YOLOv3-SPP模型对于浓度较低的烟雾存在漏检情况,而改进的YOLOv3-SPP模型能够全部检出。综合多张图像识别可视化结果分析,相比于YOLOv3-SPP模型,改进的YOLOv3-SPP网络模型对低浓度烟雾识别效果较好,有效提高了森林火灾烟雾识别任务的准确度。

图6 YOLOv3-SPP与改进YOLOv3-SPP预测可视化结果Fig. 6 The prediction visualization results of YOLOv3-SPP and improved YOLOv3-SPP
将本试验提出的方法与其他深度学习模型进行比较,其中包括Faster R-CNN、YOLOv4[16]、YOLOv4-Mobilenet[17]、YOLOv4-lite[18]、YOLOv4-tiny[19]、YOLOv5[20]、SSD(Single Shot MultiBox Detector)[21]、M2det(Detector built upon multi-level and multi-scale features)[22]、Retinanet[23]。经过对比分析这几种模型在测试数据集上的各个检测指标,得出一种准确率较高、检测时间能够满足实际需求的最优模型。9种模型的识别精确率、召回率、mAP、F1、识别速度见表3,对烟雾遥感图像预测可视化结果见图7。结果表明,Faster R-CNN、YOLOv5、SSD、M2det都较完整地识别出森林火灾烟雾,但它们的预测置信度以及精确率、mAP、F1分数、召回率、识别速度均低于改进的YOLOv3-SPP模型。YOLOv4、YOLOv4-Mobilenet、YOLOv4-lite、YOLOv4-tiny和Retinanet网络模型的预测可视化结果存在明显错误,对部分烟雾存在漏报问题,不适合作为森林火灾烟雾识别模型。改进的YOLOv3-SPP模型在预测精确率、mAP、F1分数、召回率方面均取得了最优结果,且帧率达到51帧/s,满足森林火灾识别任务的实时性要求。虽然YOLOv4-tiny模型的识别速度略高于改进的YOLOv3-SPP模型,但它其余评价指标值较低,且在烟雾图像识别可视化结果中存在严重漏报现象。总体看来,本研究提出改进的YOLOv3-SPP模型兼顾了识别精确率和识别速率,对森林火灾烟雾识别效果最好。
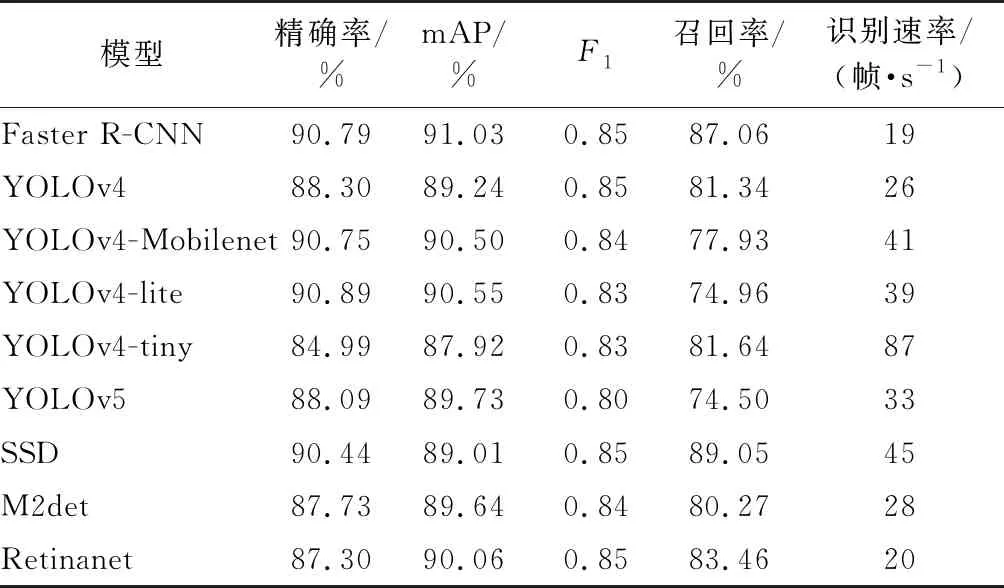
表3 9种模型进行森林火灾烟雾识别的综合性能对比Table 3 Comprehensive performance comparison of nine models for smoke recognition

图7 9种模型预测可视化结果Fig. 7 The prediction visualization results of nine models
综上,与其他深度学习算法相比,改进的YOLOv3-SPP模型在识别精确度和识别速率方面均具有较大的优势,具有良好的泛化能力,能够满足森林火灾烟雾识别任务高准确率和实时性要求,在森林火灾烟雾识别方面有一定的现实应用价值。
3 结 论
本研究针对当前森林火灾烟雾识别存在的问题,提出了基于改进的YOLOv3-SPP森林火灾烟雾识别方法。该方法在YOLOv3-SPP算法的基础上使用Focus模块,解耦头、无锚框检测机制和动态标签分配策略,提高了烟雾识别的速率以及准确率。利用自建的无人机森林火灾遥感影像数据集进行训练和测试,所提出模型的烟雾识别精确率、mAP、F1分数、召回率分别达到91.07%,92.02%,90%和89.08%,识别速率达到51帧/s。该模型识别速率是YOLOv3-SPP模型识别速率的1.5倍。并通过设置对比实验,验证了本研究所提模型的有效性和准确性。实验结果表明,改进的YOLOv3-SPP模型实现了森林火灾图像中烟雾区域的实时精准定位,为大面积、高效率、低成本的森林火灾监测研究提供了一种重要的方法。
考虑到森林火灾烟雾识别过程中,水雾或云等具有与烟雾类似特征的目标会影响识别准确度,且带来的干扰鲜有人研究,因此后续将进一步对烟雾特征与其他相似目标特征进行对比分析,以提升模型抗干扰性。
