基于RBBLC模型的中文事件抽取方法
2022-09-27杨登辉
杨登辉,刘 靖
(内蒙古大学计算机学院,内蒙古 呼和浩特 010021)
伴随着互联网、物联网技术飞速发展,各式数据的规模爆炸式增长,大数据时代已然到来,大数据处理技术也应运而生. 各行各业都已经受到大数据思维的影响,开始依托大数据及其处理技术进行生产流程的优化. 大数据包含的结构化、半结构化和非结构化数据中都存在着丰富的知识等待发掘,也催生了对不同结构数据的大量处理方法和技术. 在许多典型应用场景中,图像、视频、音频等非结构化数据是主要的分析数据类型,但在公检法、纪检监察等领域融入大数据分析时,对结构化数据和非结构化文本大数据的处理需求也是十分迫切的,并且是更加常用的. 基于这类数据进行业务分析时,需要重点提取数据背后的隐型关联,而事件抽取是对此类文本数据进行关联分析的核心基础. 事件抽取作为自然语言处理中的一项重要任务,其目标是从含有事件信息的半结构化、非结构化数据中以结构化的形式将事件信息呈现出来,进而支持如自动文摘、自动问答、信息检索等丰富的下游应用.
当前的事件抽取任务研究中,事件抽取被分成了事件检测和要素识别两个子任务,二者相互承接共同完成事件信息的抽取. 事件检测子任务的目标是在非结构化的文本信息中进行触发词识别进而确定事件的类型,而事件要素识别子任务的目标是在事件检测得到的事件类型的基础之上完成不同事件要素的抽取. 当前多数研究工作中将事件抽取任务分步执行的方式也带来了一些隐患,误差会在两项任务之间进行传播,事件要素抽取的准确率严重依赖于事件触发词识别和事件类型识别的准确率. 而少数以联合抽取方式进行事件抽取的研究工作中,也因Word2Vec等经典文本向量化工具无法获取文本中存在的相关上下文信息的缺陷,造成抽取效果不佳的问题.
本文提出并构建了一种新的联合事件抽取模型RBBLC. 针对两级子任务的误差传播问题,本文提出的RBBLC模型以序列标注的方式同时完成事件检测和事件要素识别,最大限度避免了误差的传播并能有效地捕捉触发词与事件论元之间的相互依赖. 文献[1]提出了一种基于变压器的双向编码表征(bidirectional encoder representation from transformers,BERT)模型,而针对联合抽取模型中因经典文本工具缺陷造成的抽取效果不佳,本文基于鲁棒优化的BERT预训练方法(a robustly optimized BERT pretraining approach,RoBERTa)模型进行文本的向量化,解决经典文本向量化工具存在的上下文特征缺失问题,其经过在大量数据上进行的无监督训练,能够在提取出词向量的同时,保留句子中存在的上下文相关信息. 进而利用融合双向长短时记忆网络与卷积神经网络(Bi-directional long short-term memory and convolutional neural network,BiLSTM-CNN)网络结构进一步捕捉文本上下文关联信息,最后以序列标注的方式完成事件抽取任务.
1 相关工作
1.1 事件抽取基本概念
事件是包含时间、地点、主体、行为等不同元素信息的综合概括,是事件抽取任务中最重要的知识单元结构. 而事件抽取就是要提取出文本数据中所包含事件的触发词、类型及其他事件相关元素,以结构化形式应用到下游的信息检索、智能问答、阅读理解等工作中. 事件抽取任务可细分为两个相互承接的子任务:事件触发词抽取和事件类型识别子任务,目标是从非结构化文本数据中定位事件,并识别出事件的触发词,进而将事件分类. 事件论元抽取子任务,目标是依据触发词和事件类别,在非结构化文本数据中进一步挖掘时间、地点、参与者等事件要素. 针对事件抽取任务,当下的主流方式包括两类:管道方式,以顺序方式进行两项子任务,在触发词识别和事件分类的基础之上完成要素抽取. 联合抽取方法,采用端到端的模型,同时完成触发词识别和论元识别任务.
1.2 基于管道方法事件抽取的研究
依据ACE会议对事件抽取的定义,当前许多工作将事件抽取任务分为两步进行. 早期的事件抽取多基于模板匹配的方式,需要人工依据预设的规则制定抽取模板. 文献[2]提出了一种利用语言模型发掘事件信息的方法. 文献[3]提出了一种利用模板匹配新闻文本,挖掘事件信息的方法. 但模板匹配的方式成本高,拓展性差,因而事件抽取伴随着机器学习的快速发展和神经网络在自然语言处理(natural language processing,NLP)领域的广泛应用也开始了神经网络时代. 文献[4]提出了一种基于动态多池卷积神经网络(dynamic multi-pooling convolutional neural networks,DMCNN)以管道方式实现事件抽取,并引入词向量和卷积神经网络卷积神经网络(convolutional neural network,CNN)以自动学习词汇和句子级别的特征. 文献[1]文中提出了一种BERT模型和图卷积神经网络(graph convolution network,GCN)网络的触发词检测模型BGCN. 文献[5]提出了一种利用卷积化双向LSTM模型神经网络识别中文事件触发词并分类的方法,并对比了基于词和基于字的2种向量嵌入方法. 文献[6]提出一种事件要素注意力与编码层融合的事件触发词抽取模型,能够有效地利用事件要素信息,提高触发词抽取性能. 文献[7]为了提高自动特征选择和分类能力,提出了一种端到端卷积公路神经网络和极限学习机框架来检测生物医学事件触发词. 文献[8]提出了一种基于隐马尔可夫模型和多阶段的中文事件抽取方法.
1.3 基于联合抽取方法事件抽取的研究
虽然神经网络的应用已经让事件抽取任务的效率和准确率大幅度提升,但以管道方式进行事件抽取会产生级联错误的弊端已经成为制约事件抽取效果的重要因素,且事件要素抽取子任务获得的事件要素信息本可以对触发词识别和事件类型识别提供较大的辅助,但因两级子任务分离无法反馈而失去作用. 因而,联合抽取成为了一个不错的选择,不仅解决了两级子任务间的错误传递问题,还充分利用了触发词与事件要素的相互依赖关系提升了抽取效果. 文献[9]提出一种基于树结构长短期记忆网络(tree-structu red long short-term memory networks,TREE-LSTM)和门控循环单元网络(gated recurrent unit,GRU)的模型,模型中加入了触发词的依存句法分析. 文献[10]提出了一种混合神经网络模型,同时对实体和事件进行抽取,挖掘两者之间的依赖关系. 模型采用双向LSTM识别实体,并将在双向长短时记忆网络(long short-term memory,LSTM)中获得的实体上下文信息进一步传递到结合了自注意力和门控卷积的神经网络来抽取事件. 文献[11]提出了一种组合卷积神经网络CNN与双向长短期记忆网络的中文事件抽取模型. 文献[12]提出了一种基于深度学习的文档级无触发词的事件抽取联合模型.
2 RBBLC模型
2.1 RBBLC模型架构
RBBLC模型以文本数据为输入,以序列标注的形式给出文本的触发词及论元识别结果和各触发词及论元所属事件类别的分类结果. 在事件抽取过程中,RBBLC模型通过RoBERTa组件将输入文本数据中每个汉字转换为768维的字向量. 而RoBERTa输出的由字向量组成的句子将送入模型的LSTM-CNN部分,由LSTM网络捕捉文字之间存在的长距离和短距离依赖关系,同时由CNN网络进行局部上下文关联特征提取. 最后将LSTM和CNN的输出进行融合,经两个线性层分别输出对句子中文字的触发词及论元类别标签预测结果和事件类型预测结果. 本文构建的RBBLC模型架构如图1所示.
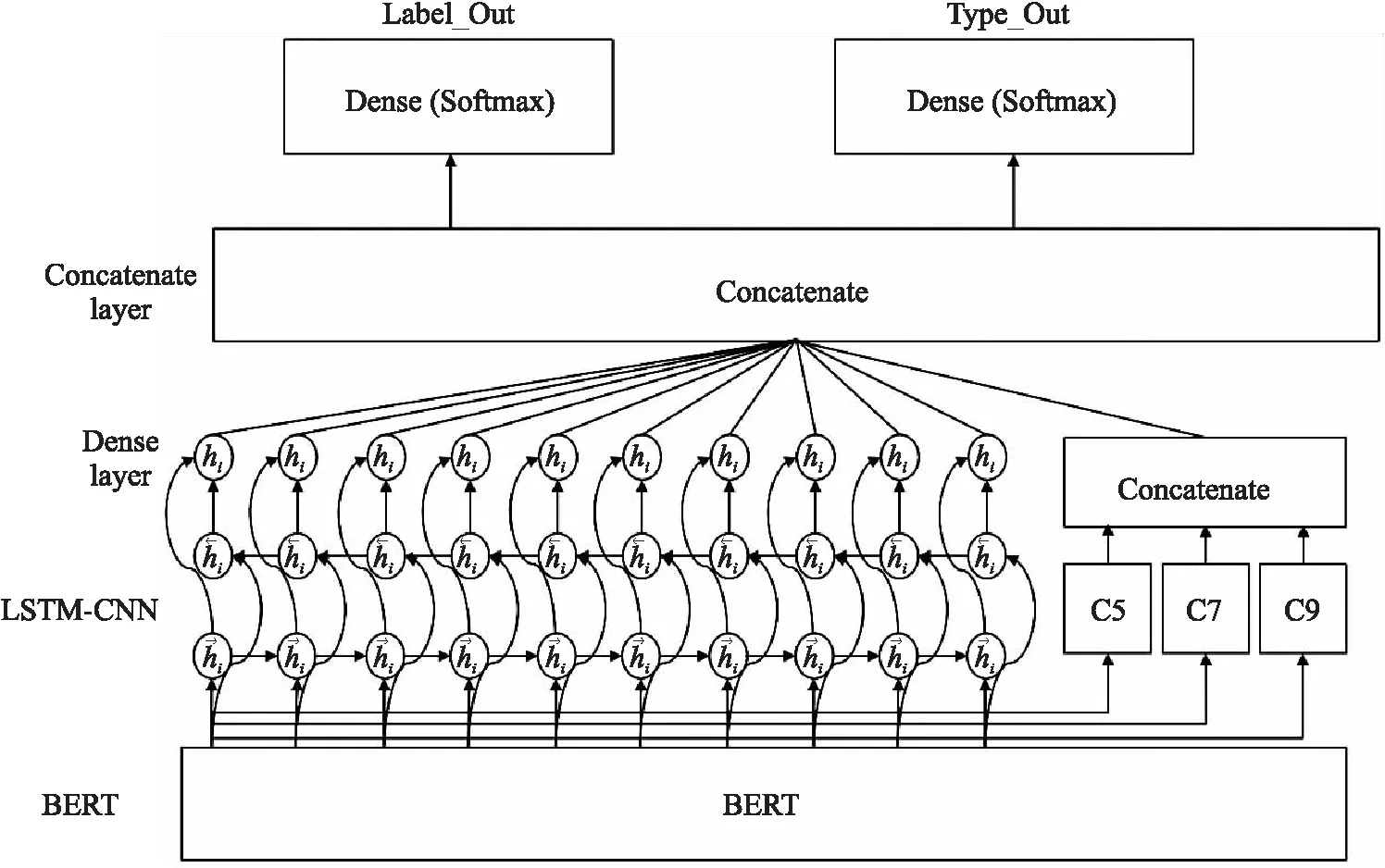
图1 RBBLC模型结构图
2.2 RoBERTa模型
RBBLC模型需要基于一种能比经典文本向量化工具捕捉更多文本信息和上下文关联信息的文本向量化模型,而近期受到很多研究者关注的BERT模型系列模型成为了最优的选择[13]. BERT是一种预训练语言表示的方法,在大量文本语料上以无监督的方式训练了一个通用的语言理解模型. BERT模型的结构如图2所示,BERT选用Transformer作为基础的算法框架,其能够捕捉语句中深层的双向关系,这很好得契合了本文模型基于文本中存在的上下文关系进行标签预测的序列标注工作的特点. Facebook提出的RoBERTa作为BERT的改进版本,以动态掩码的方式在更大规模的语料集上以更大的步长对模型进行了训练,从而在多项任务中获得了比基础BERT更好的效果,因此本文选用了由哈工大讯飞联合实验室构建的中文RoBERTa模型,RBBLC模型将原始输入文本数据以句子为单位,将句子中的每个文字通过查询字向量表转化为一维向量并计算每个字对应的段向量和位置向量,共同作为BERT模型的输入,进而产生各字对应的融合全句语义信息后的向量表示,在此过程中也同时规避了由中文分词工具带来的误差.
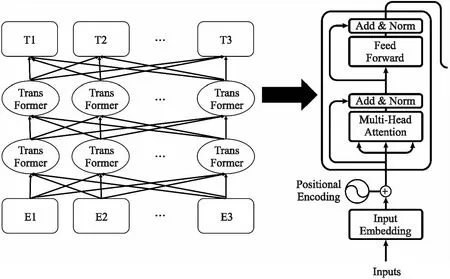
图2 BERT结构图
2.3 BiLSTM-CNN神经网络
RBBLC模型的任务是根据文本信息以序列标注的方式为句子中的每个文字分配正确的论元标签和事件类型标签. 而词性标注、命名实体识别等同样可以通过序列标注完成的任务,已经证明了能够学习并利用文本上下文信息的循环神经网络是最优的选择. 循环神经网络的单元结构保证了其可以保存序列输入之间的关联关系,并依据序列各输入的关联关系和当前输入进行输出. 因此RBBLC模型中引入了LSTM网络层对句子中存在的上下文关联关系进行学习. LSTM是循环神经网络(recurrent neural network,RNN)的改进,解决了长序列在训练过程中可能出现梯度消失或爆炸的缺陷. 但单向的LSTM网络只能依据之前的时序信息预测下一刻的输出,在本文的序列标注任务中,上下文信息也就是之前时刻的时序信息和未来的时序信息同样重要. 因此本文选用双向的LSTM网络捕捉语句中词语前后两个方向的长距离和短距离依赖,双向LSTM网络的结构如图3所示. RBBLC模型将RoBERTa组件输出的由字向量组成的句子送入双向LSTM网络,从前后两个方向对句子中存在的上下文关联信息进行学习.

图3 双向LSTM结构
同时因中文词汇多是由几个文字共同组成,一个中文词汇中文字对应的标签需要保持一致. 因此在进行标签预测时,每个文字前后几个文字和其本身组成的范围内的局部特征就具有了重要价值,RBBLC模型引入CNN网络层来提取局部特征. 卷积神经网络(convolutional neural networks,CNN)是机器学习的重要基础算法,它是包含卷积和其他相关计算并具有深度结构的前馈神经网络,其对局部特征的获取和处理能力,对自然语言处理也具有很大的现实意义. RBBLC模型对每个输入文字进行标签预测时,紧密结合句子中该文字和前后几个文字组成的窗口部分的局部特征. 所以本文模型将RoBERTa组件输出的字向量分别送入多个一维卷积层来获取文字的深层局部特征. 本文选择舍去池化层,因为池化层的最强特征选择可能会导致其他重要信息的丢失,本文方法选择直接将卷积结果与双向LSTM网络的输出结果相结合,共同决定输出标签的种类.
3 实验结果分析
3.1 实验数据集及数据预处理
ACE会议发布的ACE2005数据集构建出了中文、英语、阿拉伯语3种语言的事件抽取数据集,被众多论文用于实验评估. 我国对事件抽取领域的重视程度也在逐步提升,上海大学语义智能实验室构建了中文突发实践语料库(Chinese emergency corpus,CEC)数据集.
CEC的标注格式为XML语言,共设定了6个最重要的数据结构也就是标记:Event、Denoter、Time、Location、Participant和Object. 此外每一个标记还具有与之相关的属性,CEC语料库的整体结构如图4所示.
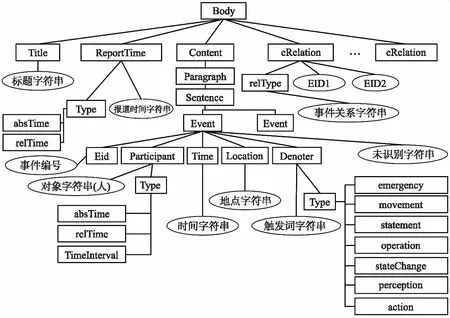
图4 CEC语料库结构
本文使用BIO标注法对文段进行标注,共定义了13类标签,分别对应触发词、相关论元和其他元素. 文本的标注形式如图5所示,而事件触发词及论元的标签及其含义如表1所示. 同时对每个事件所对应的触发词和论元根据事件类型进行事件类型标注,事件类型标签及其含义如表2所示. 最后将数据以7∶1∶2的比例划分了训练集、验证集、测试集.

图5 BIO标注及事件类型标注

表1 事件触发词及论元标签
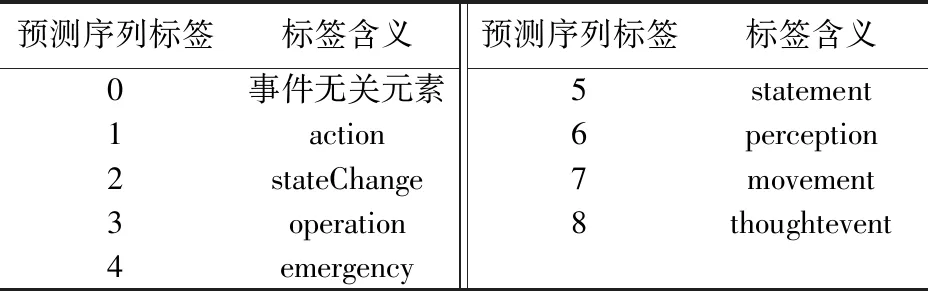
表2 事件类型标签
3.2 实验参数设定
本文参数的设定均基于实验比较. 采用OAT参数敏感度分析法可以发现模型中LSTM单元个数、训练迭代次数和输入序列长度3个超参数对模型的影响最大,本文对这3个参数进行了实验分析比对,最终参数的设定如表3所示.
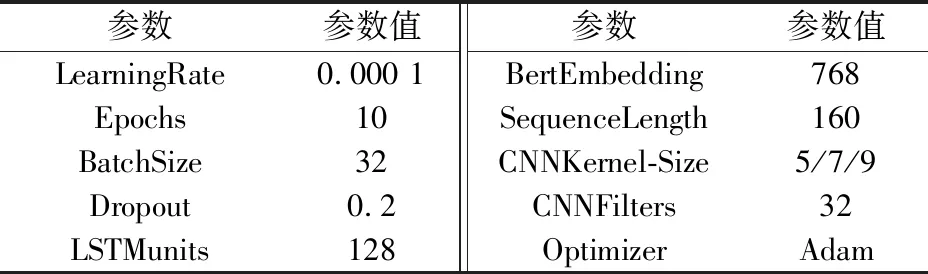
表3 参数设定
在多次训练过程中发现模型在10轮训练之后会存在过拟合问题,因而设定模型训练迭代次数为10. 序列长度设定会影响长序列超长部分的保留,设定太小会导致信息丢失,设定太大无法提高模型性能,反而影响模型训练速度,在经实验对比和对全部句子长度的分析之后,序列长度设置为160取得了最好的效果. LSTM的单元参数设定会对实验结果产生较大的影响,如单元数量太多将导致参数数量过多,在有限的数据集上难以取得最优的训练效果,而单元数量太少,会导致训练过程中信息丢失,影响模型最终效果,经试验LSTM单元数量设定为256时,模型取得了最佳效果. CNN主要用于提取更多的局部上下文特征,如卷积核大小设定太大,将导致远距离上下文对标签预测结果产生更大的影响,进而产生负面效果,因而本文选定卷积核大小分别为5、7、9的3个CNN网络提取局部上下文信息,而局部特征信息量有限,过滤器数量太多也无法产生实际的有效信息,因此设定为32.
3.3 实验评价标准与评估方法
实验的评估度量指标为准确率(precision,P)、召回率(recall,R),F1值(F1-measure),其中,序列标注是基于字级别的多分类任务,而评估时论元是基于词级别的,所以词语的BIO标签预测都计入评估.
(1)
(2)
(3)
Score=Type×Role×F1_Word,
(4)
(5)
(6)
(7)
Type表示论元事件种类预测结果是否正确;Role表示论元角色预测结果是否正确;Matching_Num代表预测论元和人工标注论元共有字的数量;Predict_Num表示预测论元字数;Artificial_Num表示人工标注论元字数. 其中Score、F1_Word、P_Word、R_Word分别为预测论文得分、字级别匹配F1值、字级别匹配P值、字级别匹配R值.
3.4 实验结果与分析
在实验中,将本文模型与7个对照模型进行了对比,本文模型与其对照模型的实验结果如表4所示. 本文方法在准确率P、召回率R和F1值上均表现最好. 本文分别设置了4类对照模型:第一类对照模型设定为基线方法Embedding-BiLSTM,用以评定本文方法的有效性. 第二类对照模型用BERT模型和Embedding层代替本文使用的RoBERTa模型,用以评定RBBLC模型选用RoBERTa模型进行文本向量化的正确性. 第三类对照模型用BiGRU-CNN网络和BiLSTM网络代替本文的BiLSTM-CNN网络,用以评定RBBLC模型中BiLSTM-CNN网络的上下文关联信息的抽取能力. 第四类对照试验为目前 CEC数据上优秀的事件抽取模型,用于证明本文方法对事件抽取性能的提升.

表4 事件抽取模型对照
在第一类对照模型实验中,RBBLC模型与基线方法相比,F1值大幅度提升了23.7%,证明了本文模型的有效性.
在第二类对照模型实验中,与BERT-BiLSTM-CNN模型和Embedding-BiLSTM-CNN的对比,本文方法的F1值分别提升了4.2%和21.6%,有力证明了RoBERTa在文本表示中能够更好的获取上下文语义,为后续序列标注提供更好的支撑.
在第三类对照模型实验中,通过与RoBERT-BiLSTM模型的比较可以发现,F1值提升了1.5%,因而本文提出的加入CNN以提取更强的局部特征的方法,可以更好的帮助模型确定标签种类. 而与RoBERT-BiGRU-CNN模型对比,LSTM获得了比GRU更好的准确率、召回率和F1值,虽然GRU作为LSTM最成功的变体,其结构更为精简,收敛也更为迅速,但在训练充分的情况下,LSTM仍旧可以保存最完整的长距离依赖信息.
在第四类对照模型实验中,Joint-RNN是在具有双向递归神经网络的联合框架中进行事件抽取的模型[14]. Lattice LSTM是一种网格结构的长短时记忆网络中文紧急事件抽取模型,该模型利用预训练模型进行字符向量嵌入,并使用条件随机场捕获触发词和事件元素间的相互作用[15]. 本文所提RBBLC模型得益于RoBERTa更为强大的文本信息表达能力和LSTM-CNN网络结构对更深层语句上下文关联信息及局部特征的获取能力,在CEC语料库上的F1值较Joint-RNN模型提升3.21%,较Lattice LSTM模型提升1.11%,证明了本文所提RBBLC模型对事件抽取性能的提升.
综上所述,本文提出的RBBLC模型在CNN数据集上的性能较其他模型有所提升.
4 结论
本文构建了一种RBBLC模型用于以序列标注的方式完成文本数据的联合事件抽取任务,以RoBERTa作为文本向量化工具,最大限度提取并保留句子中存在的上下文关联信息,进而利用BiLSTM-CNN的网络结构获取句子中存在的语义关联和局部特征,最后输出文本的序列标注结果. RBBLC模型经对比验证,在CEC数据上具有优于其他模型的事件抽取性能. RBBLC模型联合抽取的方法最大限度减少了误差的传播,并充分利用了事件触发词和论元之间的相互依赖关系,取得了良好的效果. 但受限于训练语料规模较小,后续应用时仍需对模型进行相应适应性调整. 且考虑后续在扩大的语料库中训练时,引入Attention机制,进一步捕捉句子级词语级的关联性信息,辅助触发词和论元识别分类.
