聚焦“抽象”和“建模”的高中人工智能教育实践
——以“监督学习中的预测和分类”教学为例
2022-09-26陈智敏黄细光宋新波广东省中山市中山纪念中学
陈智敏 黄细光 宋新波 广东省中山市中山纪念中学
人工智能教育实践已成为我国推动人工智能发展的重要战略之一,探索中小学人工智能教育相关内容与策略对其未来发展具有一定的指导性作用。人工智能教育不等同于程序设计教育,也不仅仅是学习如何调用库函数并调整参数实现想法,清华大学从2021年开始发起人工智能大中衔接课程培训,以期帮助中学生系统了解人工智能前沿发展方向并学习相关的核心知识、原理,掌握人工智能的基本概念、思想方法和重要算法等,并从科学的视角观察和理解前沿科研成果,熟悉典型的人工智能系统,了解有关机器学习与人工神经网络的基本原理,初步具备用经典人工智能方法解决一些简单实际问题的能力,涉及的主要内容包括监督学习、非监督学习、深度学习以及强化学习等。
中学不仅是大学的生源基地,更是大学教育的前端基地,能否把中学和大学的人工智能教育有效贯通、相互衔接,将最终影响人工智能教育领域综合改革的深入开展和国家重大战略发展。衔接贯通大学中学人工智能拔尖创新人才培养的高中人工智能课程侧重于理解前沿发展方向中的核心原理,并具体表现为计算思维中的问题“抽象”与“建模”。“抽象”与“建模”对于智能时代的学生而言是非常重要的思维,其中“抽象”是指通过对复杂的现实问题进行有针对性的分析挖掘,发现关键、本质的特征要素,并符号化、数字化为计算机可以处理的特征,从而将复杂问题简化为数学问题;“建模”则是根据抽象出的问题中特征要素之间的关系,采用适合的方式进一步表达为数量关系和空间关系以建立机器模型。然而,目前高中人工智能教育重技能轻思维,真正深入探讨核心原理的还比较少,因而难以体现出人工智能教育的基本思想,学生也很难领悟到关键知识和其中的技术原理。因此,如何在教学实施过程中聚焦培养学生的“抽象”和“建模”思维,最终培养和发展学生的计算思维并完成对相关人工智能应用的核心原理的理解,非常值得探究。
● 监督学习中的预测和分类
监督学习是通过让机器学习带有标签的训练数据,进而通过特定的算法令其学习和挖掘数据所包含的特征或者关系等,总结规律,进而训练出相应的机器模型并使该模型可以实现具体的预测和分类功能等。需要注意的是,在利用监督学习训练机器模型进行相关事件预测时,如果预测的变量是连续的,如想要预测一下明天的气温是多少摄氏度,摄氏度的取值在数轴上是“连续不间断”分布的,这个过程称为“预测”;而如果预测的变量是离散的,如想要预测一下是晴天或者阴天还是下雨,取值只有有限种可能,这个过程称为“分类”。监督学习的实现正体现了问题抽象、问题建模、设计算法、描述算法等过程,其中“抽象”与“建模”是关键,对问题的解决至关重要,引导学生尝试抽象特征,简化问题并构建模型,有助于深入认识和理解监督学习的核心原理,因此,“抽象”与“建模”也可以视为衔接贯通大学中学人工智能拔尖创新人才培养的高中人工智能课程中培养计算思维的关键。
● 监督学习实现预测中的“抽象”与“建模”
1.在问题分析中开展“抽象”
以《监督学习中的线性回归预测》一课为例,可用精确的数学表达式来表示的关系称为函数关系,即当变量x的取值确定后,有唯一确定的y值与之相对应,如正方形的面积和边长的关系;而如果两个变量之间存在着非常密切的关系但又达不到函数关系,如通过散点图可以发现,页数多的图书往往价格高,页数少的图书往往价格低,但页数又不是决定价格的唯一因素,因为图书是否彩色印刷以及畅销程度等因素都会影响到价格,这种关系则称为相关关系。
学生结合数学知识与生活经验,探讨如何根据图书页数预测价格,包括可以将点连成线进而去模拟它们之间的关系。当然,在这个过程中学生也会发现,如果刻意去逼近,虽然数据都出现在线上,一定程度上也体现出了关系,但需要去求解一个分段函数,过于复杂也因此很难具有实际预测功能;大部分学生也会通过观察发现点大致都落在一条从左下角到右上角的直线附近,随着书页数的增加,相应的价格也呈现出增加的趋势,因此这两个量之间是存在一种线性相关关系的,所以问题便抽象为了找到一条能够很好地解释数据的线,使得这条直线与样本数据距离都能够尽量接近。
2.在“抽象”基础上实现“建模”
在抽象的基础上,引导学生分析总结出如果能够求出这条直线的方程,就可以比较清楚地了解图书价格与页数之间的关系,也因而可以根据页数进行价格预测,但这种相关关系不能简单地通过解方程组得出,学生结合经验意识到可以用一个线性函数f(x)=a*x+b[x称为自变量,f(x)称为因变量,a称为斜率参数,b称为截距参数]去模拟这种线性关系并借助一定的算法计算参数a和b,当然参数取值的不同也决定了预测的效果好坏,如果每个图书价格的预测值f(x)和图书价格y的真实值越接近,预测效果则越好。所以,学生会结合数学基础提出用n个数据的偏差之和来刻画模型预测效果的好坏,总的偏差越小,模型的预测效果越好,由于每一条数据的偏差可正可负,为避免相互抵消,可以取每一条数据偏差的平方并求和来表示总的偏差Q(如下图),其中x表示图书的页数,y表示真实价格。
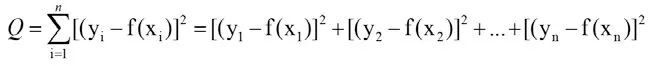
回归分析方法常用来研究相关变量之间的关系,如何选择a和b的取值使得总的偏差越小,即函数Q的值最小,其中Q被称为损失函数或者误差函数,这种将样本数据真实值到预测值偏差的平方和作为损失函数的方法叫最小二乘法。进而采用研究学习时间与考试成绩之间的关系是否存在相关性,并通过学习时间预测考试成绩的例子帮助学生了解机器是如何借助最小二乘法,通过对相关数据的计算得到斜率以及截距从而完成建模,最终得到学习时间与考试成绩的回归模型,在得到机器模型后,再输入学习时间,就可以预测出相应的考试成绩。
● 监督学习实现分类中的“抽象”与“建模”
1.在问题分析中开展“抽象”
以《监督学习中的感知器分类》一课为例,学生通过前面的学习也已经知道机器要完成分类任务也需要先基于已有的带标签数据进行学习,而这些数据本身是具有自己的特征和属性的,机器会使用相应的算法提取相应的特征并总结规律进行分类。可借助英荔AI训练平台以及“Machine Learning for Kids”等平台,帮助学生通过体验,进一步总结梳理出监督学习中分类的过程,并发现有效的特征设计很大程度上决定了机器分类结果的好坏。
关于提取特征要素,学生通过观察发现所有的训练数据中猫基本上都是小鼻子和尖耳朵,而所有的狗几乎都是大鼻子和圆耳朵的,因此训练集的图片中可以提取以下两个特征——鼻子的大小和耳朵的形状,引导学生思考如果每一幅图片都用两个数字来表示当前选择的特征——一个数字表示相对的鼻子大小,另外一个数字表示耳朵圆尖的程度,这样一张图片也就是一组数据便抽象成了一个特征向量,把特征向量表示为直角坐标系中的一个点,称为特征点,所有这些特征点则构成了一个特征空间,训练集中的图片也就都可以在这一个二维的特征空间中表示出来了,其中“鼻子大小”特征和“耳朵形状”特征分别由水平坐标和垂直坐标表示。这时,学生发现所有的表示猫的特征点和所有表示狗的特征点都聚集成一堆并且区分开来了,如果用直线作为分界线,那么这个问题就抽象为一个简单的几何问题:坐标平面中有两类点,画一条直线将这两类点分开,即让计算机在精心设计的特征空间中找到能够区分猫和狗的一个线性模型。
2.在“抽象”基础上实现“建模”
线性模型包含斜率和截距两个参数,这意味着与之前学习线性回归一样需要根据训练数据的特征为这些参数找到合适的值。而完成分类任务的模型可以称为分类器,即当机器看到猫或者狗的照片时,首先会提取图片指定的特征并将这些特征输入到已经训练好的分类器中,分类器能够根据这些特征做出预测并最终输出是猫还是狗,所以分类器也可以理解为由特征向量到预测类别的一个函数。这里需要寻找一个线性分类器对猫狗进行分类,线性分类器f(x)可以由学生概括表示出来:f(x,x)=ax+ax+b,其中x、x分别表示鼻子的相对大小数据和耳朵的圆尖程度数据,f(x,x)称为因变量,a、a为斜率参数,b为截距参数。建模的目的就是找到合适的参数a、a、b,使得对应的分类器能够区分猫和狗。后续提到的感知器是一种训练线性分类器的算法,它是利用被误分类的训练数据调整现有的分类器的参数,使得调整后的分类器判断得更加准确。
● 结语
聚焦“抽象”和“建模”的高中人工智能教育实践有助于在问题解决中渗透计算思维等核心素养,在简单的预测和分类的基础上,还可以设计后续的教学内容进一步引导学生针对问题开展抽象和建模。例如,在利用非监督学习的K均值聚类算法将景点划分到景区的教学中,引导学生尝试选取一些代表性的特征将景点抽象为平面坐标体系中的特征点从而形成特征空间,并将特征点之间的相似程度抽象为曼哈顿距离的大小,进而采用K均值聚类算法建立聚类模型解决问题;在深度学习教学中引导学生观察和分析计算机是如何将大脑的神经元的集合体抽象为数学模型并具体解析隐含层是如何采用卷积运算一步步抽象图片的特征,进而理解卷积神经网络的工作原理等。
当然,思维能力的培养并不是一蹴而就的,它需要一个循序渐进的过程,特别是人工智能前沿方向核心原理的分析与探究对于学生来说是较难的环节,需要大量的数学知识作为基础,包括微积分、线性代数、概率统计等,这对一些数学基础较弱的学生来说更是难上加难。因此,需要细化探究任务,将探究活动拆分为不同层次的小问题,帮助学生深入了解机器学习的过程,最终掌握算法和原理,并尝试引导其思考哪些因素会对结果的准确率造成影响,激发进一步探究学习的欲望并尝试提出优化模型的策略,即培养学生的创新能力。例如,在《监督学习中的感知器分类》一课中,虽然刚开始鼻子大小和耳朵形状的组合确实能区分出猫和狗,但是由于训练集太小且不够多样化,我们发现基于训练集选择出来的特征并不能完全有效,因此学生会通过讨论总结出:
①可以收集更多的数据组成一个庞大且多样的训练集,但是不要去刻意迎合数据、记忆数据从而导致模型无法概括趋势;
②设计更具有辨识性的特征(如脸型的凹凸、尾巴的形状等)来进一步帮助区分猫和狗,但是不要过度将模型复杂化,在一定程度上要简化参数;
③用设计的特征训练新的模型并用同样的方式来测试,看它与原来的模型相比是否有所改进。
值得一提的是,聚焦“抽象”和“建模”的高中人工智能教育实践在一定程度上还能够反作用于数学关键能力的培养,因此也让信息技术与数学进行了更为紧密的融合,让学生对知识也能够有更多角度的理解,在一定程度上贯通大学与中学人工智能教育,推进拔尖创新人才培养的持续、健康发展。
