柴油机故障的堆栈自编码特征提取与随机森林识别
2022-09-22郭兆松吴士力
郭兆松,吴士力,2,邓 侃
(1.南京交通职业技术学院,江苏 南京 211188;2.南京理工大学,江苏 南京 210094;3.长沙湾流智能科技有限公司,湖南 长沙 410100)
1 引言
柴油机广泛应用于舰艇、汽车、核电等领域,由于柴油机工作环境恶劣,当某一部件发生故障时容易引发整机故障,轻则造成系统瘫痪,影响生产或工作效率,重则引发大型机毁人亡事故[1]。传统依赖专家个人经验的故障诊断方法已经无法满足当前故障多样性和诊断实时性要求,因此研究柴油机故障的智能诊断技术极为必要,亦具有重要的经济意义和安全意义。
可以表征柴油机运行状态的参数较多,包括转速、油液、振动、压力等。依据不同的参数,出现了热工参数法、瞬时转速分析法、油液分析法和振动信号分析法等。热工参数法[2]依据转速、压力、温度等参数判断柴油机运行状态,此方法可以对柴油机状态进行实时监测,但是存在传感器安装困难、难以确定故障位置等缺陷。文献[3]使用空间几何法和距离法对不同负载下柴油机的热工参数进行故障分析,两种方法的检测结果相近,实现了两者的交叉验证。瞬时转速分析法可以根据发动机的瞬时转速确定异常气缸位置、失火故障程度等,此方法优点是转速获取方便,缺点是无法分析出故障的诱因。文献[4]通过对比正常状态和失火状态下的瞬时转速特征,提出了改进段角加速度和神经网络的失火故障诊断方法,实现了失火故障的在线诊断。油液分析法通过对机油进行铁谱和光谱分析,判断零部件的磨损情况,此方法的突出缺陷是无法进行在线检测。文献[5]通过激光粒度分析法对油液中的磨粒数量和尺寸进行检测,通过研究磨粒的变化规律及时对设备进行保养,从而防止设备故障的发生。振动信号分析法是指根据机身振动、缸盖振动或者侧面振动信号中的特征信号进行故障诊断的技术,此方法是当前的研究热点,优点是可在线检测、准确率高、振动信号获取容易等。文献[6]使用小波分解获取了缸盖振动信号的各频带能量特征,基于随机森林实现了故障模式诊断,此方法能够准确识别柴油机的运行状态。
针对柴油机运行故障的在线诊断问题,从信号去噪、特征提取、故障模式识别等3 个角度进行研究。改进小波阈值去噪方法,提高信号的信噪比。使用堆栈自动编码网络提取信号中的故障特征,提出话语权随机森林算法进行故障模式识别。经过研究,提高了柴油机故障识别准确度。
2 数据获取与改进小波阈值降噪
2.1 数据获取
由文献[7]可知,排在前3位的柴油机故障分别为燃油系统故障、漏水故障、进排气阀故障。由于漏水故障诊断简单,且燃油系统故障和进排气阀故障直接影响燃烧过程,因此对燃油系统故障和进排气阀故障进行研究。研究对象为R6105AZLD柴油机,此柴油机为四冲程,具有6个气缸,发火顺序依次为153624。根据传感器安装方便、获取数据具有故障特征等原则,将加速度传感器安装在柴油机缸盖罩上,从而获得缸盖罩的振动信号,振动信号采样频率为40kHz。实验用柴油机,如图1(a)所示。数据采集系统,如图1(b)所示。


图1 实验设备Fig.1 Experiment Equipment
柴油机设置7种识别工况,分别为正常工况、单缸断油、双缸断油、喷油泵渗漏、供油提前角增大、供油提前角减小、空气滤清器堵塞等。每种工况下截取120组样本数据,共840组样本数据。
2.2 改进小波阈值降噪
使用柴油机缸盖罩的振动信号进行运行模式识别,由于缸盖罩的振动信号存在大量噪声,因此首先要进行信号降噪。常见的小波阈值降噪方法包括硬阈值函数和软阈值函数两类,但是硬阈值去噪存在“阈值点处不连续、存在附加震荡点”等问题,软阈值去噪存在“定值缩减、信号失真”等问题[8]。因此提出了样本熵自适应阈值函数的小波降噪。针对软阈值函数和硬阈值函数降噪存在的缺陷,制定几点改进原则:(1)改进函数连续,防止出现振荡点;(2)大于阈值的小波系数尽量接近真实值,小于阈值的小波系数尽量收缩;(3)系数调整应随信号含噪情况自适应调整。根据以上3点原则,制定小波系数自适应变化方法为:
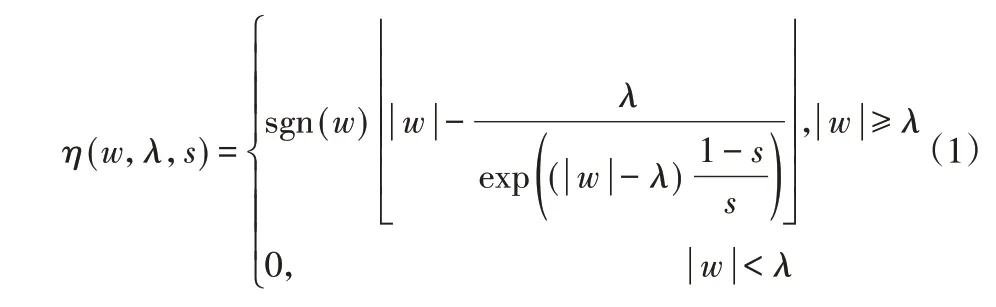
式中:w—原始小波系数;η—自适应小波系数;λ—阈值,s∈(0,1]为自适应调整系数。分析式(1)可知,此式满足3点改进原则。且传统软、硬阈值均为式(1)的特例,当s→0时上式为硬阈值函数,当s=1时上式为软阈值函数。自适应阈值降噪函数,如图2所示。
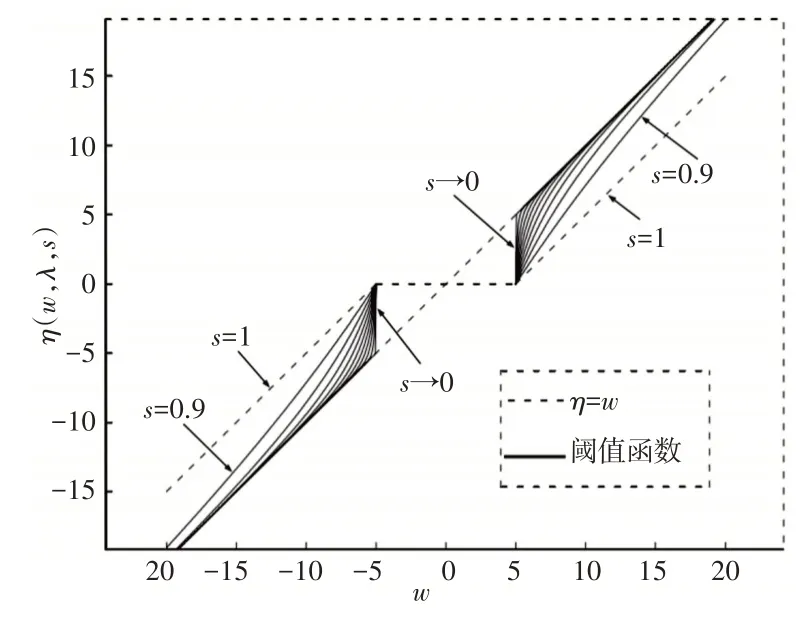
图2 自适应阈值降噪函数Fig.2 Denoising Function of Adaptive Threshold
样本熵可以说明信号中的噪声含量,因此使用样本熵构造自适应参数s。当信号中噪声较大时,样本熵也较大,此时设置较大的s值,即倾向于使用软阈值;当信号中噪声较小时,样本熵也较小,此时设置较小的s值,即倾向于使用硬阈值。根据以上分析,得到s值计算方法为:
(1)对于长度为N的数据序列,按照单点后移的方法将其分解为N-l个长度为l的子序列;(2)计算每个子序列的样本熵作为此序列中间点样本熵,而后进行归一化,得到归一化样本熵为:

2.3 降噪效果验证
为了验证样本熵自适应阈值的小波降噪方法,使用MAT⁃LAB仿真出有用信号为:

式中:t—时间;E—有用信号功率。
截取6个周期共1536ns的数据,在有用信号中加入10dB的高斯白噪声,有用信号及含噪信号,如图3所示。
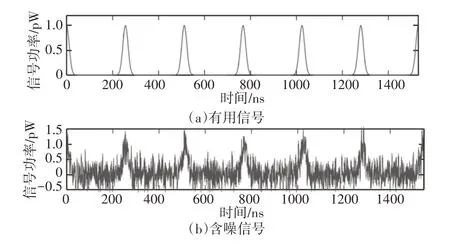
图3 有用信号与含噪信号Fig.3 Useful Signal and Containing Denoise Signal
分别使用硬阈值小波函数、软阈值小波函数、自适应阈值小波函数对含噪信号进行降噪,基小波使用sym5小波,分解层数为4层,阈值使用Stein无偏风险阈值。三种阈值函数的降噪效果,如图4所示。
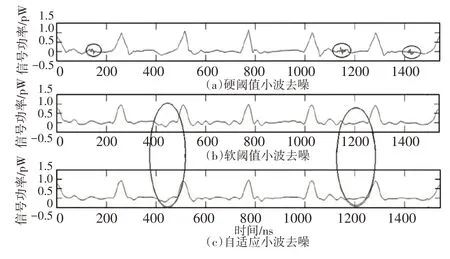
图4 降噪效果对比Fig.4 Comparison of De-Noising Effect
由图4可知,硬阈值小波去噪后信号存在明显的振荡点,软阈值去噪和自适应阈值小波去噪信号较为光滑。对比软阈值函数和自适应阈值函数的去噪信号,自适应阈值函数去噪信号比软阈值函数去噪信号更加光滑。计算3种方法去噪信号与有用信号的均方根误差、去噪信号的信噪比结果,如表1所示。
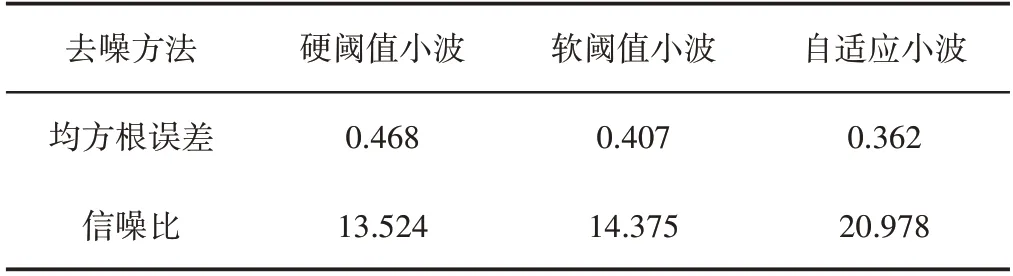
表1 去噪效果验证Tab.1 Comparison of De-Noising Effect
由表1可知,自适应阈值小波去噪信号与有用信号的均方根误差最小,去噪信号的信噪比最大,说明自适应阈值小波去噪能够有效去除信号中的噪声,保留信号中的有用成分。综合图3和表1可知,自适应阈值小波的去噪效果明显优于传统的硬阈值小波和软阈值小波。
3 故障特征的堆栈自编码网络提取
3.1 堆栈自动编码器原理
理解堆栈自编码器网络原理,首先需要介绍自动编码器。自动编码器包括输入层、隐含层、输出层共3层网络[9],如图5所示。图中:x={x1,x2,…,xn}—输入向量和输出向量;h={h1,h2,…,hm}—隐含层提取的特征向量;wij—输入层节点i向隐含层节点j的传递权值;vji—隐含层节点j向输出层节点i的传递权值。
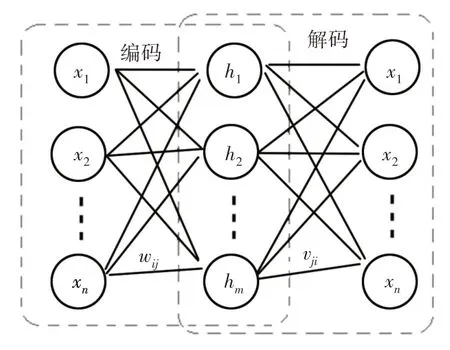
图5 自动编码器Fig.5 Auto Encoder
从输入层到隐含层是编码的过程,也即提取特征的过程;从隐含层到输出层是解码的过程,也即故障模式识别的过程。
特征提取过程即为输入层向隐含层映射的过程,即

式中:hj—第j个特征值;f1()—输入层与隐含层间的激活函数,使用Sigmoid函数;bj—隐含层第j个神经元的偏置。
解码过程为由特征向量h={h1,h2,…,hm} 还原为输入向量的过程,即:


式中:L—一次解码和编码的重构误差。
堆栈自动编码器是由多个自动编码器串联叠加的网络结构,第一个编码器进行特征提取后传递给第二个编码器,依次向后传递直至最后一个编码器,得到最终获得的特征向量。以上过程为信号正向传递过程,也即特征提取不断深化的过程。堆栈自动编码网络参数的训练是重构误差的反向传递过程,使网络参数朝着重构误差梯度减小最快的方向调整,即:
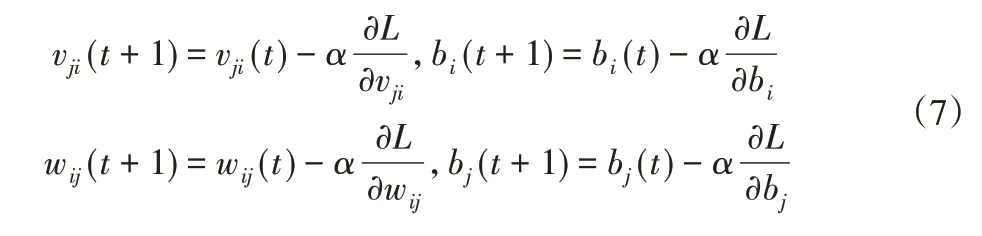
式中:α—学习效率;t—迭代次数。
3.2 堆栈自动编码网络参数确定
堆栈自动编码网络结构的深度和节点数量对特征提取影响较大,所谓“深度”是指隐含层的数量,网络结构越深则越能够挖掘出数据中的深层次特征,但是网络结构也会越复杂,甚至出现过拟合现象,因此网络深度应进行合理设置。使用实验的方法,将隐含层数量分别设置为1、2、3、4等四种情况,每个隐含层节点数量为15。训练样本为柴油机7种工况下的840组样本数据,每种情况下进行10次训练,则四种情况下的平均训练误差,如图6所示。
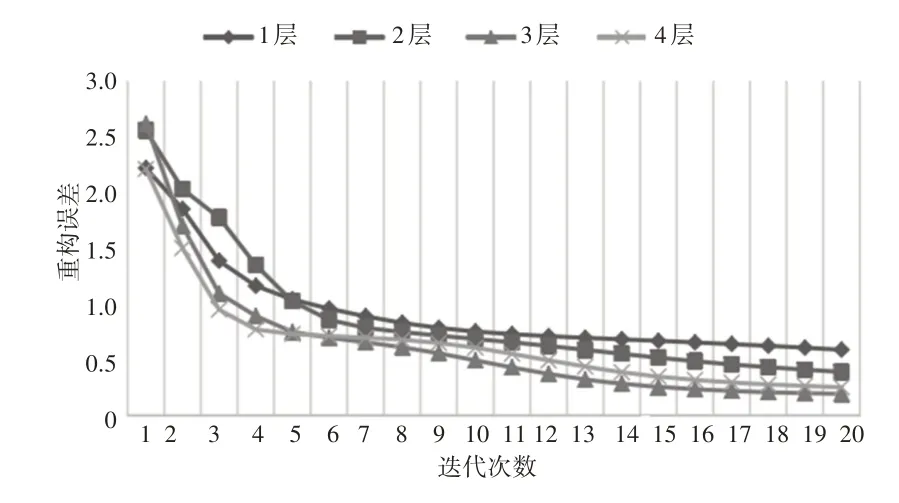
图6 参数训练过程Fig.6 Process of Parameters Training
分析图6可知,隐含层数由1层增加到3层的过程中,重构误差依次下降。但是当隐含层增加到4层时,重构误差反而增大,说明此时出现了过拟合现象。综合以上分析,将隐含层数量确定为3。同样的,使用实验的方法,隐含层节点数量依次设置为50、30、10,即最后一层隐含层共提取10个特征参数作为特征向量。
3.3 特征提取效果验证
根据前文的优化结果,对840组样本数据提取特征向量。为了形成对比效果,同时使用1层隐含层的自动编码网络进行特征向量提取,隐含层神经元数量设置为10,即也提取10个特征参数。将提取的特征向量在3个特征参数方向上进行投影结果,如图7所示。
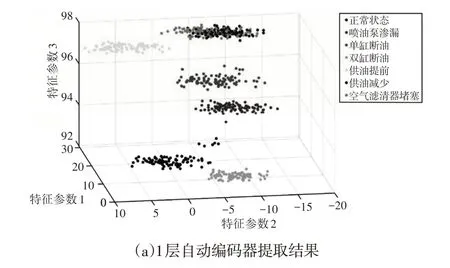
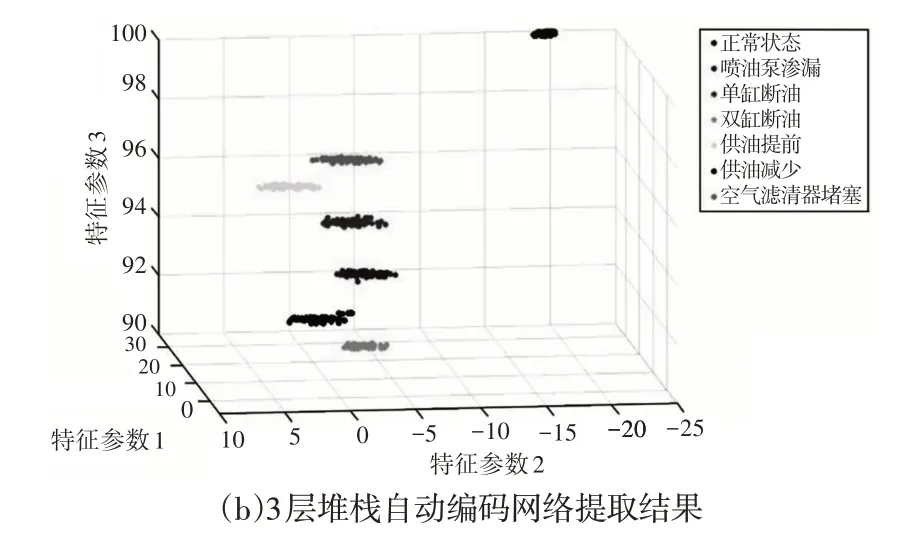
图7 特征提取对比Fig.7 Comparison of Feature Extraction
分析图7可知,1层自动编码器提取的特征存在严重的重叠问题,且同一运行状况的特征聚合度较差,特征参数的分布过于分散。而3层堆栈自动编码网络提取的特征聚合度较好,且柴油机不同运行状态下特征不存在任何重叠问题。综合以上分析可知,3层堆栈自动编码网络可以有效提取柴油机状态特征向量。
4 话语权随机森林算法
随机森林是由多决策树组成的分类器,类似于民主投票,得票数最多的类即为识别结果。根据不同决策树的分类准确率为其赋予不同的话语权,投票后话语权之和最大的类为最终识别结果。
4.1 传统随机森林算法
随机森林算法的实现分为3 个关键步骤,分别为构建决策树、集成学习、投票与决策。决策树是森林中的基础个体,是民主投票的一份子。集成学习是各决策树的训练过程,提高决策树的投票准确度。
投票与决策是指决策树根据自身经验进行民主投票,随机森林根据投票结果,得票数最多的即为最终分类结果。随机森林具体原理可参考文献[10],这里不再详细介绍,仅对重要内容进行说明。
根据特征评估标准使用递归的方法构造决策树,从根节点开始依次生成子节点,直至分裂出所有叶节点,决策树构造完毕。特征评估标准较多,由于CART算法对空缺点和孤立点不敏感,因此选择CART算法作为特征评估标准。
集成学习的抽样方法包括有放回随机抽样法(即Bagging抽样法)和有权重抽样法(即Boosting抽样法),其中Bagging抽样法是一种安全独立随机抽样,可以减少训练完毕决策树的相关性和泛化误差,因此使用Bagging抽样法。
Bagging抽样方法为:决策树数量记为L,从总训练样本集中抽取n个样本组成一个训练集,而后将此n个样本放回到总训练样本集中,进行下次抽样。以上过程进行L次得到L个训练集,此L个训练集随机分配给L个决策树进行训练。
投票与决策。对于样本x,决策树c的投票结果记为fc(x)=m,m=1,2,…,M,式中:c=1,2,…,C—决策树编号;M—类数。随机森林的决策结果以决策树的投票结果为依据,取投票结果的众数作为随机森林的决策结果,即:
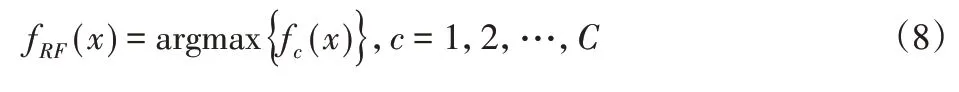
式中:fRF(x)—随机森林的决策结果;argmax()—取众数。
4.2 话语权随机森林算法
话语权随机森林算法的核心思想是根据决策树训练过程中的投票准确度为不同决策树赋予不同的话语权,使投票准确的决策树具有更高的话语权。随机森林根据话语权之和最大的原则做出最终决策。
首先将训练样本分组,随机选择训练样本的80%作为训练组,另外20%作为预测试组。首先使用训练组对决策树进行训练,而后使用预测试组计算决策树的投票准确度,为:

式中:Rc—决策树c的预投票准确率;Xc—决策树c的预投票正确数量;Xc—决策树c的预投票总数量。
将决策树的预投票准确率作为其投票话语权,即wc=Rc,而后将所有决策树的话语权进行归一化,为:

使用话语权随机森林法进行分类时,所有决策树投票结果的话语权之和最大值即为最终决策结果。
5 实验验证
5.1 数据获取与去噪
按照前文的数据获取方案,每种运行工况下采集120组样本数据,共采集840组样本数据。每个样本时长为0.08s,共3200个数据。由于篇幅有限,在此只展示正常工况、单缸断油、喷油泵渗漏、空气滤清器堵塞等4种工况下的原始振动数据,如图8所示。
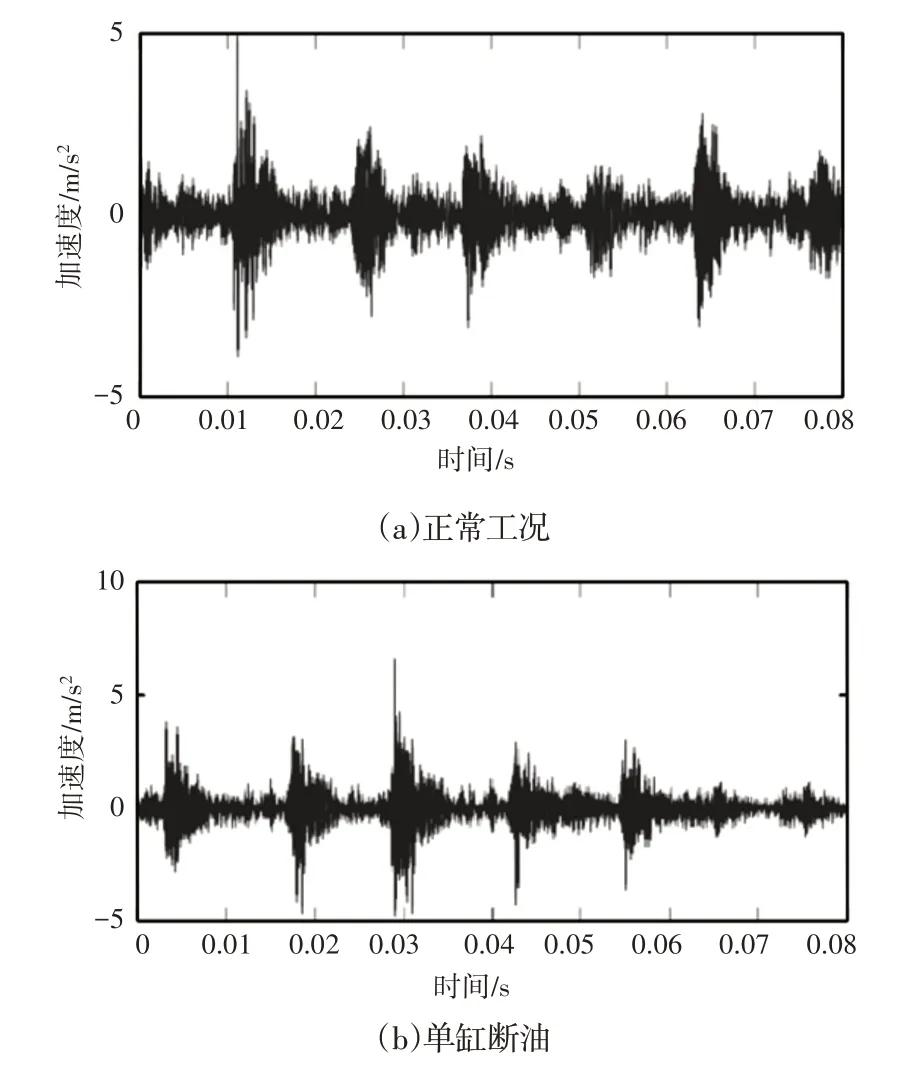
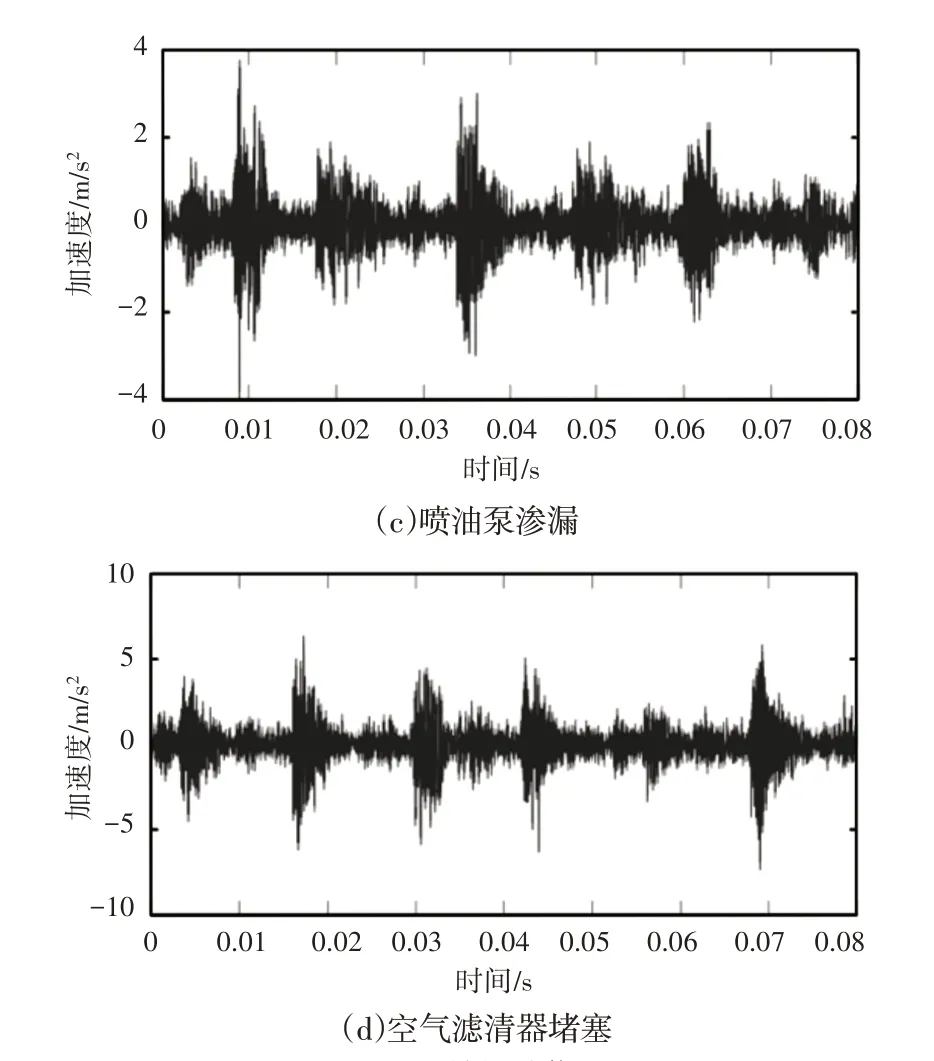
图8 原始振动信号Fig.8 Original Vibration Signal
7种工况下原始振动信号的滤波过程完全一致,在此仅给出正常工况下自适应阈值小波去噪后的信号,如图9所示。
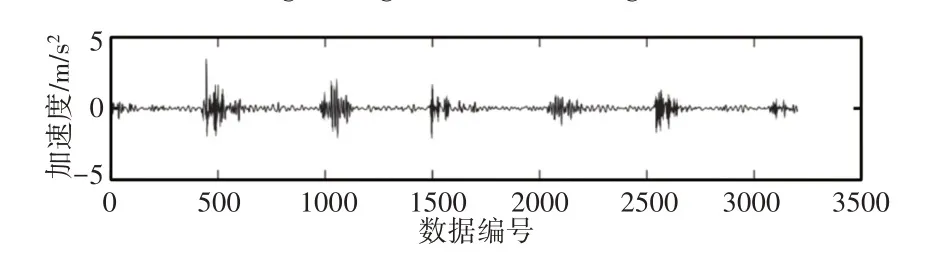
图9 正常工况下振动信号的去噪结果Fig.9 De-Nosing Result of Vibration Signal Under Normal Condition
对比图9和图8(a)可以直观看出,柴油机的噪声信号被有效滤除,而有用的信号特征得以保留,为了更加有效地对原始信号和去噪信号进行比较,对原始振动信号和去噪信号进行频谱分析,如图10所示。分析图10中去噪前后信号的频谱图可知,低频的有用信号频谱特征极为相似,表示去噪前后对低频有用信号的保留较好。比较去噪前后的高频频谱,去噪信号的高频噪声部分幅值得到有效抑制。综合以上分析,自适应小波去噪方法可以使低频的有用信号特征得到保留,高频的噪声信号得到抑制。
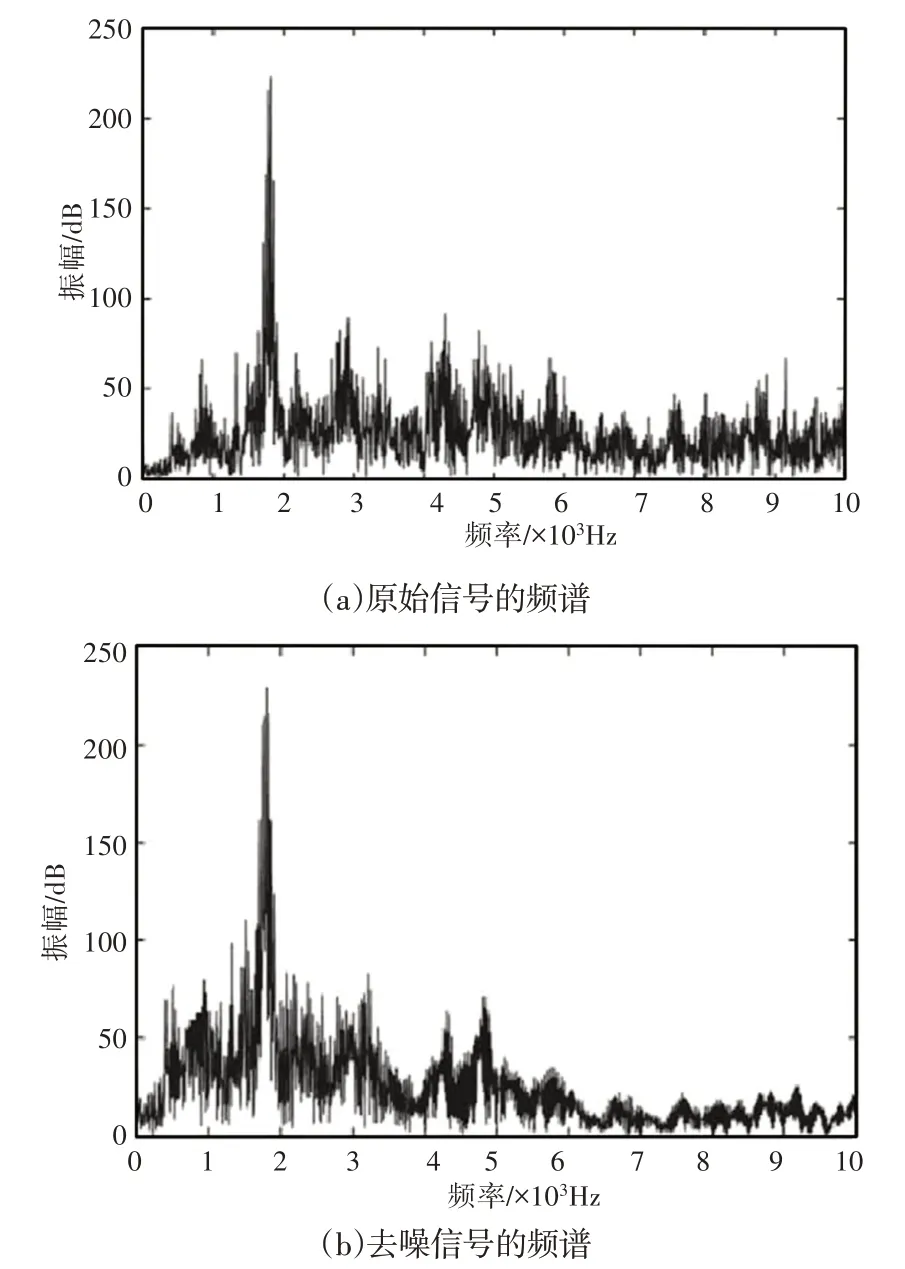
图10 去噪前后的频谱图Fig.10 Spectrogram Before and After De-Noising
5.2 诊断结果对比与分析
使用堆栈自编码网络提取7种运行状态下去噪信号的10维特征向量,而后分别使用传统随机森林算法和话语权随机森林算法进行柴油机运行模式识别。前文中提到,每种模式下采集120组样本,每种模式下随机选择100组样本作为训练集,剩余的20组样本作为测试集,100 组训练集中随机选择80 组分配到训练组,剩余20组作为预测试组,用于为决策树赋予不同的话语权。
为了减小随机因素对识别效果的影响,传统随机森林算法和话语权随机森林算法分别进行10次实验,其中一次的实验结果,如图11所示。图11中前20组样本为柴油机正常状态下振动样本,而后依次为喷油泵渗漏、单缸断油、双缸断油、供油提前、供油减少、空气滤清器堵塞。直观的看,话语权随机森林算法的识别准确率明显高于传统随机森林算法。为了更加准确的比较两种算法的识别性能,统计10次识别准确率的平均值和标准差结果,如表1所示。
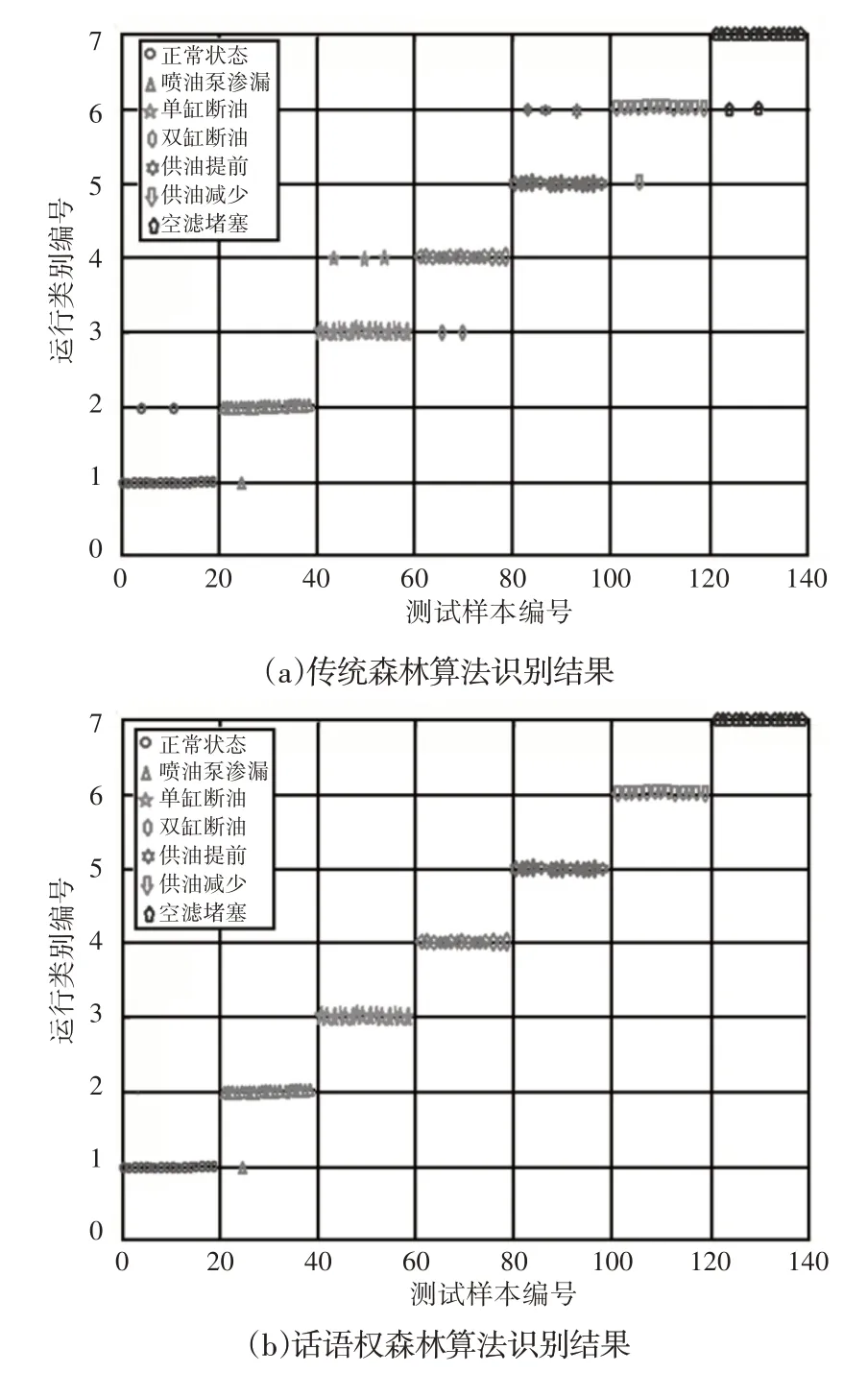
图11 识别结果对比Fig.11 Comparison of Recognition Result
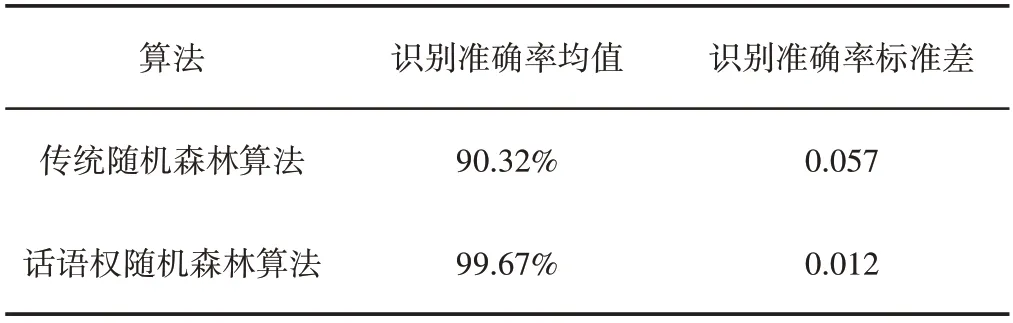
表1 传统森林算法与话语权森林算法的识别结果对比Tab.1 Recognition Result Comparison of Traditional For⁃est Algorithm and Speaking-Weight Forest Algorithm
由表1中数据可知,传统随机森林算法在10次的识别准确率均值为90.32%,话语权森林算法的10 次识别准确率均值为99.67%,比传统算法提高了10.35%,说明话语权森林算法的识别水平得到了明显提高。另外,传统随机森林算法的识别准确率标准差为0.057,话语权随机森林算法的准确率标准差为0.012,远小于传统随机森林算法,说明话语权森林算法的识别稳定性远好于传统森林算法。综合以上分析,根据预测试样本的识别准确率为不同决策树赋予不同的话语权,使预判准确率高的决策树具有更高的发言权,这种改进方法不仅可以提高柴油机运行模式识别准确率,而且算法的识别性能更加稳定。
6 结论
研究了柴油机运行故障的特征提取与故障类型识别问题,使用堆栈自动编码网络提取了振动信号的10维特征,对随机森林算法进行决策树的话语权改进,并将其应用于故障类型识别,经验证得出以下结论:(1)堆栈自动编码网络提取的特征向量类内聚合度高、类间分辨率高,说明特征向量能够极好地代表故障特征;(2)话语权森林算法的模式识别精度和识别稳定性远高于传统随机森林算法。
