基于深度学习的DGA域名检测方法研究
2022-09-22韩雨男周博超
韩雨男,周博超,张 权
(中北大学 信息与通信工程学院,山西 太原 030051)
0 引 言
域名生成算法(DGA)最大的特点是字符产生的随机性,这也使得DGA域名的生成在不断地更新,这些域名会在短时间内使用,然后逐步淘汰生成新的域名. 恶意软件感染了主机后,通常和命令与控制(C&C)服务器连接,攻击者与恶意软件使用同一套DGA算法,生成相同的备选域名列表,发动攻击时选用少量进行注册,便可以建立通信. 单个活动的DGA可以在短时间内生成成千上万的域,人工筛选标注域名将是个巨大的工程,传统的域名黑名单[1]的检测方式将无法可靠地检测DGA变体和阻断这些域的连接. 域名生成算法被越来越多的恶意软件所使用,恶意攻击会对个人、 企业、 国家的信息安全造成巨大的威胁,为了解决这个问题,相应的检测方法也需要与时俱进[2].
近年来,伴随着深度学习的再一次崛起,卷积神经网络(Convolutional Neural Network, CNN)[3],循环神经网络(Recurrent Neural Network, RNN),以及长短期记忆神经网络(LSTM)相继被提出[4-5],DGA域名检测方法也有了新的突破. 受文献[6]分布式拒绝服务攻击检测方法的启发,本文使用长短期记忆神经网络,分两步对DGA域名进行检测,第一步是基于信息熵的初步检测,第二步是基于改进和优化的3层LSTM网络模型的深度检测. 实验结果显示,该方法具有更高的准确率和更低的误报率,同时检测耗时更少.
1 相关工作
2016年,Woodbridge等[7]首次将深度学习应用到DGA域名检测中,利用深度学习可以自动提取特征的优势[8],解决了传统机器学习所面临的困难. Saxe J等[9]使用卷积神经网络(CNN)对DGA域名进行检测,将原始短字符串作为输入,学习同时使用字符嵌入和CNN来提取特征. 文献[10]利用门控循环单元(Gated Recurrent Unit,GRU)检测恶意域名,相较于LSTM网络节省了训练时间,但在遇到随机性偏低的恶意域名时误报率会上升. Curtin等[11]提出了将循环神经网络架构和域注册辅助信息相结合的模型,该模型能够有效地识别由困难的 DGA 家族生成的域名,但该模型专门针对基于英文单词的DGA家族,对于看起来不像自然域名的DGA家族检测效果较差. 王堃宇[12]提出一种利用LSTM和CNN的恶意域名检测方法,提取域名作为特征标签,通过多种神经网络的混合使用,显著提高了识别恶意域名的准确率和AUC值,但是没有考虑误报率的问题.
上述方法都是基于深度学习网络来构建DGA域名检测模型,深度学习的优点在于无需特征工程[13],但是对于网络安全的应用,提取恶意域名特征的方法更具有说服力,综合不同的检测方法可以从不同的角度提取特征,从而提升DGA域名检测的性能. 另外,基于深度学习模型的训练需要消耗较多的时间,而通过基于信息熵的初步检测方法可以快速筛选出大部分正常域名,从而提升整体检测效率. 因此,深度学习模型和信息熵相组合的新方法,既发挥了LSTM的自身学习特性,也吸收了信息熵的客观拟合特征信息的特点.
2 检测模型的设计
2.1 基于信息熵与LSTM网络的检测方法
总体检测算法流程如图 1 所示,本文所用方法主要包括两个部分,基于信息熵的初步检测和基于LSTM模型的深度检测. 首先,对域名中的字符串进行特征提取,并进行熵值计算,将计算结果与预设的阈值进行对比来实现初步检测; 然后,把不在阈值范围内的域名设为疑似DGA域名,将其作为输入导入基于LSTM的模型进行深度检测,通过模型来判断可疑域名是否为DGA域名.

图 1 检测算法流程图Fig.1 Flow chart of detection algorithm
2.2 基于信息熵的初步检测
熵的定义为随机变量中的不确定度度量[14],信息熵的计算采用香农公式[15]
H(d)=-∑lg(P(Xi))×P(Xi),
(1)
式中:d为域名字符串;Xi为该域名中的某个字符;P(Xi)为该字符出现的概率.
DGA域名生成算法生成的恶意域名是随机的,域名字符串的混乱程度越高,熵值就越大,而正常域名的熵值比较小,所以信息熵可以作为初步判断标准.
对域名进行特征分析,识别到域名中的点号,通过点号对域名进行分割,选取二级域名部分字符串进行检测. 选取字符频率作为域名特征,通过对其计算得到熵值,与预先设定的阈值进行比较,当计算的信息熵高于设置的阈值时,则认为域名是疑似DGA域名,并传递给基于LSTM的深度检测. 基于信息熵的检测方法有较大的局限性,不能将其结果作为判断域名是DGA的最终标准,只是利用其对疑似DGA域名进行排查,所以,为了尽可能将DGA域名排查出来,需要将阈值设定得小一些,使初步检测有较高的识别率,同时允许有较高的误报率.
2.3 基于LSTM的深度检测
长短期记忆网络(LSTM)对循环神经网络(RNN)的隐藏层进行了改进,原始RNN的隐藏层只有一个状态h, 它对短距离的输入很敏感,而LSTM网络增加了单元状态c, 用来保存长期的状态,在长期训练中解决了梯度消失和爆炸的问题. 本文使用的LSTM网络单元结构[16-17]如图 2 所示.

图 2 LSTM网络单元结构Fig.2 Unit structure of LSTM network

ft=σ(Wf×[ht-1,xt]+bf),
(2)
it=σ(Wi×[ht-1,xt]+bi),
(3)

(5)
Ot=σ(Wo×[ht-1,xt]+bo),
(6)
ht=Ot⊙tanhCt,
(7)
式中:xt是t时刻的输入值;W是权重矩阵;b是偏置项;σ是激活函数.
本文搭建3层LSTM网络层,3层LSTM层后设置1层全连接层,选择初步检测的疑似DGA域名作为有效信息流入,可以提取时间序列在时间步长上的时间依赖特征,epoch设置为100,embedding size设置为128, internal size设置128,batch size设置为64,时间步长timestep设置为100,选用的优化算法为AdaBound,初始学习率设置为0.001,后端通过激活函数采用sigmoid函数和tanh函数,然后加入全连接层,在全连接层后加入dropout层以防止模型过拟合,提高泛化性能,丢失率设置为 0.2,最后加入Softmax 函数对输出进行分类.
3 梯度下降优化函数
SGD算法利用梯度下降与固定的学习率,在更新参数时对各个维度上梯度的放缩是一致的,但向模型的最小值方向更新的速度比较慢,并且在训练数据分布极不均衡时训练效果很差,模型可能停留在局部最优解附近来回震荡,前期收敛慢是算法最大的缺陷.
SGDM算法在SGD算法的基础上加入了动量机制,为了抑制SGD的震荡,SGDM在梯度下降过程中加入惯性,即在陡峭的地方下降速度快,在平缓的地方下降速度慢. 引入的一阶动量是各个时刻梯度方向的指数移动平均值.
v1=λv0-η∇L(θ0),
(8)
v2=λv1-η∇L(θ1),
(9)
式中:v0=0;λ为衰减权重;θ0和θ1为优化参数的对象,θ1=θ0+v1,θ2=θ1+v2.
Adam算法[19]设定一个初始的学习率,神经网络会根据梯度值自适应地选择需要训练的参数的学习步长,相比SGD算法,Adam算法省去了手动调节学习率的麻烦,在学习初期会让结果收敛得更快. 但是,Adam算法也有泛化性较差的缺点,在训练末期会出现极大或极小的学习率,导致结果不收敛,而SGD算法可以执行严格收敛,当知道最优学习率的值的时候,SGD算法表现得会比Adam算法好.
AdaBound算法可以对自适应学习率进行动态裁剪[20],随着训练步数的变大,优化函数会从Adam动态转换为SGD,该算法既结合了快速的初始过程,也具有了SGD算法的良好泛化属性. 具体计算过程如下:

(16)
式中:mi和vi表示更新的速度,训练样本总数为k,i=0,…,k;θ表示优化的参数对象;η表示学习率,学习率在区间(ηl,ηu)范围内;J(θi)表示损失函数; ∇J(θi)表示损失函数计算θ的梯度.
通过对比多组超参数的实验结果,可以发现学习率为0.001,β1=0.9,β2=0.999时,实验效果最好.
4 实验与分析
本实验用到的恶意域名数据来自360netlab的公开数据集[21],正常域名数据来自Alexa[22]统计排名靠前的域名. 数据集包含多类DGA家族恶意域名,例如chinad,corebot,dircrypt,dnschanger等,数据集按照4∶1的比例分成训练集和测试集两部分,训练集总共有2 433 189个样本,其中合法的有800 097个,非法的有1 633 092个,测试集总共有608 297个样本,其中合法的有199 903个,非法的有408 394个.
为了方便统计,本实验把多分类问题简化成了二分类问题,对域名的标签做了二值化处理,所有正常域名的标签改成0,所有子类家族恶意域名的标签改成1.
本实验的程序开发环境是Anaconda3,python版本是3.6,框架使用的是pytorch1.7.0版本,操作系统使用的是Windows10(64位),处理器使用的是Intel(R) Core(TM) i7-9700K@ 3.60 GHz,显卡使用的是NVIDIA GeForce RTX 2070 SUPER.
4.1 检测评估指标
二分类模型在预测中有4种预测结果: 第一种,真正例(TP),预测是非法的,实际是非法的; 第二种,真负例(TN),预测是合法的,实际是合法的; 第三种,假正例(FP),预测是非法的,实际是合法的; 第四种,假负例(FN),预测是合法的,实际是非法的.
本文使用误报率和准确率作为对模型性能评判的指标. 误报率是指把合法域名预测为非法域名的样本占所有合法域名样本的比例,准确率是指预测对的样本占总样本的比例. 计算公式为
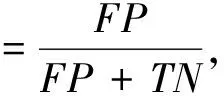
(17)

(18)
4.2 基于信息熵的实验结果分析
正常域名和DGA域名的熵值分布如图 3 所示. 正常域名的熵值集中分布在2.8左右,DGA域名的熵值则集中分布在4.3左右,两者之间存在交集,因为基于信息熵的初步检测不是为了准确预测出DGA域名,所以实验中把阈值设置得低一些,允许对正常域名有误判,但是不能丢失过多的DGA域名.

图 3 正常域名和DGA域名的熵值分布Fig.3 Entropy distribution of normal domain name and DGA domain name
为了选取合适的阈值,得到较高的识别率,本文通过测试集进行测试,主要阈值的数据指标如表 1 所示.

表 1 主要阈值的识别率和误报率Tab.1 Recognition rate and false positive rate of main thresholds
由实验结果得,基于信息熵初步检测时,信息熵的阈值设置为3.2,可以得到较高的识别率,可以有效地检测出疑似DGA域名,并为基于LSTM神经网络的深度检测压缩了25%的数据样本,减少了耗时.
4.3 基于LSTM模型的实验结果分析
为了验证LSTM网络层数对检测效果的影响,分别构建了2层LSTM,3层LSTM,4层 LSTM模型进行对比实验,优化函数选择了SGDM,训练周期设置为100. 图 4 和图 5 显示了不同层数的LSTM网络在测试集上的检测结果.

图 5 不同层数LSTM模型检测的误报率Fig.5 False positive rate of LSTM model detection with different layers
由图 4 和图 5 可以看出,不同层的LSTM模型经过100次训练后,3层LSTM模型在检测的准确率和误报率上表现得更好,并且当网络层数过多时会造成训练时间的增长.
为了进一步提高检测的速度和效果,本文将 3层 LSTM模型和不同优化函数结合,进行对比实验. 优化函数分别使用了SGDM,Adam,AdaBound. Adam的参数设置为η=0.001,图 6 和图 7 显示了3种优化函数模型在测试集上的检测结果.

图 6 3种优化模型检测的准确率Fig.6 Detection accuracy of three optimization models

图 7 3种优化模型检测的误报率Fig.7 False positive rate detected by three optimization models
由图 6 和图 7 可以看出,在使用Adam优化函数的时候,虽然指标优化得快,但是最后的泛化性属性表现不好,而Adabound结合了其他两种优化函数的优势,提高了优化速度,节约了训练时间,在最后指标趋于稳定时,泛化性属性还优于SGDM.
加入学习率衰减因子(Learning Rate Decay),可以让学习率随着迭代周期的增加而变小,通过减小梯度下降时的搜索步长来减缓震荡,损失值设置0.05,0.035,0.020,0.010等4个阈值,衰减倍数设置为2,5,10,20.

表 2 加入衰减因子与不加入衰减因子的对比Tab.2 Comparison between adding attenuation factor and not adding attenuation factor
由表 2 可以看出,在加入衰减因子后,模型的准确率提高了 0.06%,误报率下降了 0.22%,训练轮数和训练时间也减少了一半以上.
为了验证本文所提方法的有效性,引入支持向量机(Support Vector Machines,SVM)[13]、 FANCI域名检测模型[23]、 卷积神经网络(CNN)[9]、 门控循环单元(GRU)[10]、 split-glrt-lstm-aug模型[11]、 LSTM-CNN模型[12]算法与本文提出的基于信息熵和LSTM3网络模型的组合模型(IE+LSTM3)进行对比实验,在相同的数据集的基础上,选取准确率和误报率作为评价指标,结果如表 3 所示.

表 3 不同算法模型的对比实验结果Tab.3 Compare experimental results with different algorithm models
从表 3 中可知,5个深度学习模型在DGA域名检测中的性能表现要优于2个机器学习模型. SVM算法对于大规模训练样本难以实施,准确率和误报率的表现都较差. FANCI算法[23]通过监视DNS流量中的NXD响应来检测DGA域名,特征仅从包含在NXD响应中的域名中提取,不需要从任何其他来源中提取,实验结果显示,该模型的误报率接近深度学习模型,准确率超过了98%. 基于CNN和GRU的检测方法是通过提取域名字符和序列时序特征,对于字符随机性大的DGA域名数据有较好的检测效果,而对多类DGA家族的检测性能一般. split-glrt-lstm-aug模型专门针对基于英文单词的DGA家族,对看起来不像自然域名的DGA家族检测效果较差,检测的准确率没有超过99%. 本文提出的基于信息熵和LSTM3网络模型的组合模型相较LSTM-CNN组合模型,在准确率和误报率性能上均有提升,误报率降低到2%以下.
从结果可以看出,基于信息熵和LSTM3模型的检测方法在各项性能指标上皆优于具有代表性的传统机器学习算法以及深度学习算法.
采用相同的数据集对基于LSTM-CNN的网络模型、 单一LSTM3网络模型和基于信息熵和LSTM3网络模型的组合模型进行对比实验,结果如表 4 所示.

表 4 单一模型和组合模型的对比实验结果Tab.4 Single model and combined model compare experimental results
由表 4 可以看出,基于信息熵和LSTM3网络模型相组合的双重检测方法,在保证较高准确率的前提下,检测耗时减少了25%左右,提高了检测效率.
5 结 论
本文在对现有的DGA域名检测方法研究的基础上,提出了基于信息熵和LSTM模型相结合的双重检测方法. 本文的初步检测利用DGA域名熵值较大的特征排查出疑似DGA域名,再通过LSTM网络对初步检测结果进行最终确定. 实验结果表明,与其他模型相比,本文提出的方法可以有效提高检测的准确率和降低检测的误报率,并且能够减少检测耗时,提高检测效率. 下一步将研究更优的基于深度LSTM网络的检测方法,以进一步提升算法性能.
