Beacon+:面向E级超级计算机的轻量级端到端I/O性能监控与分析诊断系统*
2022-09-21王敬宇刘世超邵明山何晓斌刘卫国
杨 斌,王敬宇,刘世超,邵明山,肖 伟,陈 起,4,何晓斌,刘卫国,薛 巍
(1.山东大学软件学院,山东 济南 250101;2.国家超级计算无锡中心,江苏 无锡 214072;3.国家并行计算机工程技术研究中心,北京 100080;4.清华大学计算机科学与技术系,北京 100084)
1 引言
随着世界各国在超级计算领域的投入不断加大,超级计算机技术迎来了飞速的发展,计算速度快速增长。一方面,计算能力的飞速提升,为人工智能、脑模拟等新兴应用,以及地球模拟、计算流体力学等传统应用的发展带来了巨大帮助;另一方面,众多特征各异的HPC(High Performance Computing)应用也对超级计算机的设计和部署提出了新的挑战。
超级计算机的核心存储系统往往是一个大规模并行文件系统,主要用来提供计算结点方面统一和共享的文件视图,并提供高吞吐的带宽。例如,神威·太湖之光[1]的Lustre[2]文件系统,底层共有144个盘阵,能提供10 PB的存储容量,最大吞吐率达到200 GB/s以上。近年来,为了匹配越来越快的计算速度,支撑不同HPC应用的需求,以大规模共享并行文件系统为主的超级计算机存储系统需要进一步升级,为此,新一代超级计算机的存储系统往往都会引入新型的存储设备、新的存储架构和新的软件栈,这也导致超级计算机的存储系统变得越来越复杂,例如,以神威·太湖之光[1]为代表的中间转发架构,以Summit[3]为代表的结点内Burst Buffer系统[4]等。多层级的存储架构、冗长的I/O路径和复杂的软件栈一定程度上提高了系统的性能上限,使其可以满足更多类型的I/O需求,但是也加剧了优化使用和管理等方面的问题。
众所周知,共享是超级计算机存储系统的一个重要特点,其为不同计算结点间的及时数据传递提供了便捷,但也带来了潜在的冲突和干扰。有许多研究工作[5 - 8]表明,在深共享环境下,应用的性能常常会出现明显的抖动。首先,应用间的冲突干扰是造成性能抖动的一个重要原因。架构日趋复杂使得有效地发现和定位冲突干扰更加困难,而系统的动态变化也加大了有效地还原性能问题现场的难度。其次,系统由于某种部件故障导致的性能降级[9]也会明显影响应用的性能。不同于宕机等严重故障,部件性能降级后该部件仍然可以提供服务,所以常规的心跳监控很难识别这类问题。系统规模越大,出现性能降级和故障的概率也大幅增加。第三,系统参数的错误配置、资源的不合理分配也会对应用的性能造成明显影响[10]。这是因为不同的存储系统对应用的最优访问配置可能不同,且最优配置可能随负载水平变化而动态变化。综上所述,存储系统规模的增加和结构的日趋复杂不仅导致了发现性能问题和诊断其原因更加困难,同时也让资源的管理变得更加复杂。这无疑对应用开发者优化应用 I/O 性能,以及系统管理员合理配置资源,提高系统利用率带来了巨大的挑战。
为了解决上述问题,近年来出现了一系列I/O性能采集和问题诊断的相关研究,其主要思想是通过持续抓取应用或者系统的I/O行为,来帮助还原问题现场,从而进行性能诊断分析。例如,针对应用的Darshan[11]和ScalableIOTrace[12];针对文件系统的FSMonitor[13]和LustrePerfMon[14];跨层级的Modular Darshan[15]和Reflector[16]等。但是,这些已有的工具都存在一定局限性:针对应用的工具可以很好地描述应用在用户层的表现,但是缺少全局视图,无法解释系统层对应用的影响,不适用于复杂的超级计算机存储架构上的I/O性能诊断;针对文件系统的工具可以较好地抓取文件系统的行为,但是往往难以与用户层的应用特征结合起来,很难对应用的优化提供足够的帮助。多层级监控是一个发展趋势,但是目前大都由于开销问题而处于实验阶段,正式部署还极少。Titan[17]上正式部署的多层级监控工具GUIDE[18]采集的内容涵盖了多个方面,存储方面主要是Lustre文件系统和硬盘信息的采集,这也导致其无法提供细致的应用I/O分析。神威·太湖之光[1]上部署的Beacon[10]进行了太湖之光I/O全路径的采集,并且已经在太湖之光上长期稳定运行。神威新一代超级计算机在计算性能上较太湖之光提升了一个数量级,I/O信息采集总量大幅增加,Beacon已有的压缩方法、存储和处理方案需要持续改进,以最小化开销与资源需求,同时,在不同平台和更多存储组件上的部署,使得Beacon需要在易用性和可移植性上进一步完善。
本文针对神威新一代超级计算机更加庞大的规模和新的架构,设计并实现了面向E级超级计算机的轻量级端到端I/O性能监控与分析诊断系统——Beacon+。对比神威·太湖之光上的Beacon系统,Beacon+在以下几个方面具有明显的优势:
(1)针对I/O性能数据的采集,Beacon+增加了多个维度的数据采集,以适应E级超级计算机更加复杂的架构。与此同时,还重新设计了采集程序的压缩算法,并且增加了随机缓冲功能,对数据的传输进行了错峰处理,大大降低了多维度获取数据带来的开销,极大地减少了网络OPS(Operations Per Second),释放了更多网络监控资源。
(2)针对数据存储,Beacon+采用了内存数据库来缓存实时源数据,并通过流处理的方法及时消费。这样不仅显著提高了数据处理的速度,也减少了存储E级超级计算机产生的海量数据的开销。
(3)针对数据分析,Beacon+增加了预处理机制,将不同平台不同层级采集的数据进行了统一的格式化处理,并且抽象出通用的数据接口供后续数据分析程序调用,大大增加了整个系统的可移植性。同时,Beacon+改进了异常检测算法,较Beacon[10]提高了15%的精度。此外,Beacon+还增加了RPC(Remote Procedure Call)层来提供统一的分析结果输出接口。
基于上述优化改进,Beacon+系统已经开发完成并实现了在新一代神威异构众核超级计算机上的部署,虽然其规模数倍于神威·太湖之光,但是Beacon+存储模块占用的系统结点规模仅比太湖之光增加了不到30%,同时系统结点上的内存占用对比Beacon的降低到了50%以下。采集程序的CPU和内存占用对比Beacon的分别降低了70%和90%以下。整体上的开销不到1%。
2 背景
首先介绍本文平台神威新一代超级计算机。虽然Beacon+主要是在神威新一代超级计算机上进行的部署测试,但是它所采用的一些方法都可以被运用到其他超级计算机平台上。
神威新一代超级计算机系统继承和发展了太湖之光的体系架构,基于申威新一代高性能异构众核处理器和互连网络芯片构建。系统由运算系统、互连网络系统、软件系统、外围服务系统、维护诊断系统、电源系统和冷却系统组成,其整体架构如图1所示。
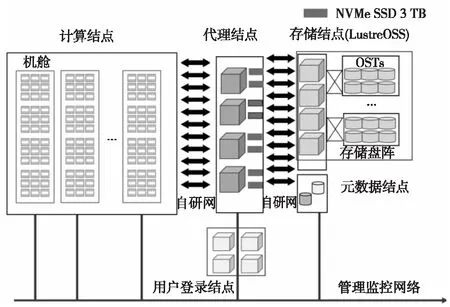
Figure 1 Architecture of the Sunway next-generation supercomputer图1 神威新一代超级计算机的架构图
每个计算结点包含1个申威新一代众核处理器,该处理器采用类似SW26010的异构主核+众核的架构,这些部件通过环形网络进行互连。每256个计算结点组成一个超结点,超结点内的计算结点通过自研网络SWnet全连接。每4个超结点组成1个机舱,整体规模超过了100个机舱。计算结点通过互连网络与代理结点进行连接,代理结点提供I/O请求转发或存储。提供I/O请求转发时,代理结点通过存储网络与存储结点连接,由存储结点提供最终的数据持久化。
神威新一代超级计算机的计算结点提供了2种文件访问方式:与太湖之光超级计算机类似的LWFS(Light Weight File System)与Lustre[2,10]组成的全局文件系统和独有的Burst Buffer[19]文件系统HadaFS。计算结点同时作为LWFS的客户端和HadaFS的客户端,并且通过自研网络SWnet与代理结点相连,每1 024个计算结点对应6个代理结点。代理结点作为全局文件系统中LWFS的服务端和Lustre的客户端,同时也作为HadaFS的服务端。每个代理结点上有2块3 TB的NVMe SSD,整个HadaFS提供约4 PB的存储。代理结点同样通过SWnet与存储结点相连,存储结点作为Lustre的服务端链接了若干存储盘阵,其存储容量达15 PB。此外,还有由多个元数据结点组成的元数据集群,用来提高全局文件系统的元数据服务能力。
3 Beacon+的设计与实现
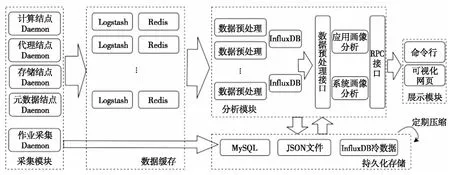
Figure 2 Architecture of Beacon+图2 Beacon+架构图
Beacon+对超级计算机进行I/O全路径的性能数据采集和实时分析。给应用开发者提供了应用画像,便于定位应用的I/O性能问题;给系统管理员提供了系统画像,便于定位系统热点,识别性能干扰与部件性能降级。图2展示了Beacon+的4个主要模块:
(1)采集模块。通过轻量级后台程序采集I/O行为信息,进行数据清洗和压缩后,以自主push方式向存储模块推送数据。为了避免对应用造成影响,数据通过管理网络传输(应用通信主要通过高速互连网络)。采集模块运行在应用I/O路径的各层结点上,其设计目标是尽可能降低对应用程序的性能影响(<1%),并最小化性能数据传输开销,尤其是降低网络OPS压力,以达到不干扰原有管理网络应用的目的。
(2)存储模块。通过Logstash[20]、Redis[21]、MySQL[22]和InflulxDB[23]提供高性能数据读写,通过JSON(Java Script Object Notation)文件和InfluxDB导出文件提供持久化存储。同时,为了降低存储压力,对这些文件定期进行压缩。存储模块主要部署在代理结点上,其设计目标是支持高扇入比的海量流式数据存储(计算结点规模超过10万)和在线的分析任务数据查询(秒级响应)。
(3)分析模块。通过流式预处理实时消费源数据,提供格式化数据的接口供后续分析程序调用,并通过RPC服务提供分析结果的输出接口。分析模块主要部署在专用的Beacon+服务器上,其设计目标是提供低延迟的分析结果。
(4)展示模块。通过命令行和可视化网页客户端展示最终的分析结果。展示模块的设计目标是易用性,方便用户和管理员以熟悉的方式快速定位应用和系统问题。
3.1 采集模块
与太湖之光的Beacon相比,Beacon+增加了多个维度的数据采集,以覆盖E级超级计算机更加复杂的架构,对应用实现了I/O全路径采集。与此同时,Beacon+还重新设计了采集程序的压缩算法,尽可能地合并了短消息,并且增加了随机缓冲功能,将数据的传输进行了错峰处理,大大降低了多维度获取数据带来的开销,极大地减少了网络OPS,释放了更多网络监控资源。
(1)计算结点:传统采集工具为了获取应用特征,往往通过插桩一些高层I/O库来获取数据,如MPI-IO(Message Passing Interface Input/Ouput)[24]和HDF5(Hierarchical Data Format)[25]等。但是,这种方法需要用户参与,且需要重新编译应用源代码或者重新链接外部库,无法做到对用户透明,使用十分不方便,也无法保证采集覆盖率。而Beacon+采取的方法与这些传统采集工具有很大的不同,它通过插桩计算结点上的轻量级文件系统LWFS,打印出应用各进程的I/O操作,从而提取出应用的I/O行为。这样既可以获取应用的I/O特征,也不需要用户参与,实现了与用户的松耦合。且由于神威新一代超级计算机的计算结点提供了LWFS和HadaFS 2条I/O路径,所以Beacon+分别对其进行了插桩,将文件系统中的I/O操作记录在内存日志(log)中,再通过后台的轻量采集程序将数据传输出去。同时,考虑到E级超级计算机的规模庞大,每天的数据可达数十TB,本文对log文件做了定期回滚。采集程序通过记录已读取文件的偏移和当前文件的大小来判断log文件是否发生了回滚。当log文件大小小于记录的已读取文件偏移时,则认为文件发生了回滚,需要重新读取。
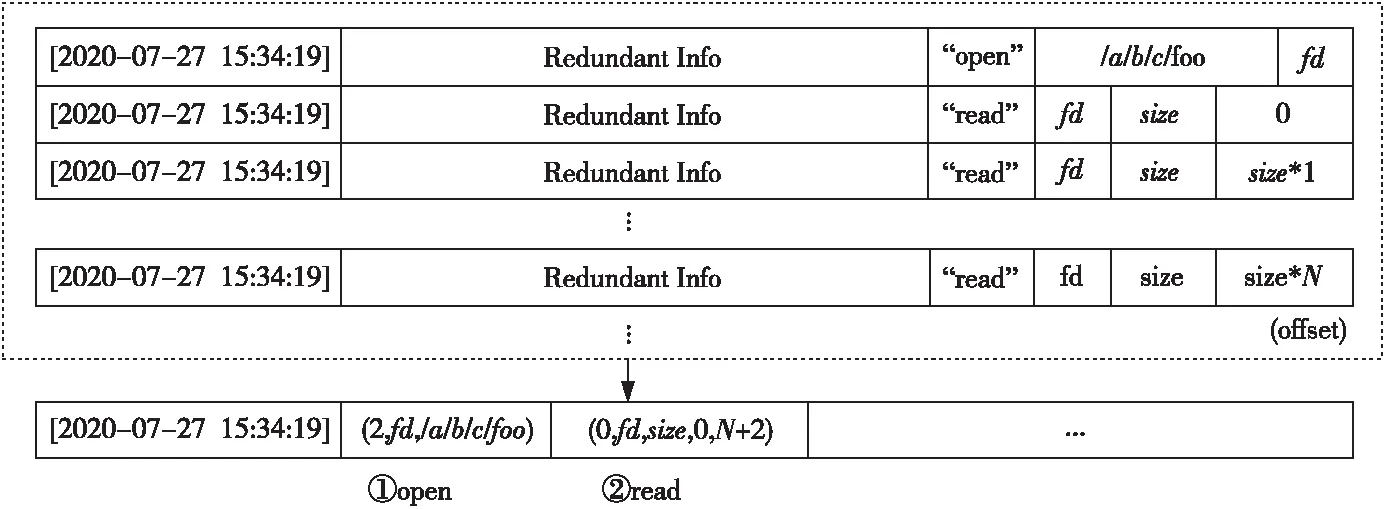
Figure 3 Diagram of data compression algorithm图3 数据压缩算法示意图
与此同时,为了减少发送的数据量,降低发送数据的频次,减少管理网络中的OPS,最大化降低采集程序的开销,本文设计了高效的压缩算法,并且在不同层级采用了不同的压缩策略来应对不同的数据需求。计算结点是整个系统中采集规模最大的层级,同时也是最贴近应用的层级。为了最大化地保留计算结点的信息,还原用户的I/O行为,本文采用了细粒度Trace配合无损压缩算法的采集方法。图3是压缩算法示意图,具体的步骤见算法1。
算法1计算结点数据压缩算法
输入:LWFS和HadaFS客户端的原始log。
输出:压缩后的数据。
步骤1提取并重组 log的格式。log文件中每个条目都代表一个文件操作记录,具有固定的格式,其中除了关键信息外,还有很大一部分冗余信息,比如open操作的条目除了包含时间戳、目标文件路径和返回的文件描述符(fd)等信息外,还包含应用名、文件名和本地进程号等痕迹信息。采集程序通过识别操作关键词,根据既定格式,对采集所涉及的open、release、read、write、create、rename和unlink等文件操作的记录进行关键信息提取,滤去一些没有价值的信息后再重新组合。经测试,将每一条记录重组后,能减少70%以上的空间占用。
步骤2合并同一时间内的连续读写I/O请求。log文件中涉及最多的是读写操作,应用对于大块数据的读写会在系统中被拆分成若干小数据块读写操作,即应用发起的一个大块读/写请求,会在log文件中产生大量的读/写记录,它们往往针对同一个文件,具有相同的数据块大小,以及连贯的文件偏移。基于此特点,压缩程序对这些条目进行统计,通过标记起始偏移位置、数据块大小和操作数量,把这些同时间的I/O 操作合并成一条记录,如此能减少一个log文件中 90% 以上的条目。
步骤3建立缓冲区,合并一段时间内的缓冲区数据。数据压缩完毕后,不立即发送,而是将压缩后的数据先放入缓冲区中。同时设定随机的缓冲时间,随机时间的取值为(0,30] s。当缓冲区缓冲时间达到随机设定的时间后,将缓冲区内的数据合并成一条记录发送出去。这种方法将原来的若干条记录合并成了一条记录发送,可以有效减少网络中由于频繁的短消息所导致的OPS过高的情况。本文通过此方法,减少了96%以上的网络OPS。
(2)代理结点:代理结点包含了I/O路径中的多个部分。
首先是LWFS的服务端,1个服务端需要服务上百个LWFS客户端,数据量十分庞大。由于计算结点已经采集了详细的信息,所以在服务端可以去除冗余信息,进一步减小系统开销。同时,根据已有的性能分析经验,服务端对应用I/O性能的影响与服务端的负载情况有较强的正相关性。因此,本文在LWFS服务端通过对代码插桩的方式进行了统计分析。设定每隔1 000(默认1 000,可配置)条I/O请求,就对这些I/O请求的执行时间进行统计分析,并输出这些I/O请求的执行时间分布情况。除了I/O请求的执行时间,本文对I/O请求的等待时间也做了相应的处理,并且将I/O请求分为元数据操作、读操作和写操作3类操作分别输出。例如,LWFS的服务端收到了1 000条I/O请求,通过上述统计分析方法,压缩后仅输出6条记录(所有读请求等待的时间分布、写请求等待的时间分布、元数据请求等待的时间分布、读请求执行的时间分布、写请求执行的时间分布和元数据请求执行的时间分布),压缩比超过了160倍,极大地降低了开销。本文对于HadaFS的服务端,也采取了类似的统计分析的方法。
其次是HadaFS的后端存储NVMe SSD的采集。Beacon+通过nvme-cli[26]命令采样采集了设备的smart-log信息,主要包含NVMe温度、使用率、寿命、读写数据量和读写操作数等内容,可以帮助系统管理员分析NVMe SSD的使用情况。
接着是作为全局文件系统的Lustre的客户端,Beacon+采样采集了/proc/fs/lustre下Lustre OSC(Object Storage Client)到服务端OST(Object Storage Target)的RPC信息,每个OSC-OST对的数据可以表示为(timestamp,OSC,OST,RPC size,RPC count)。此外,为了提高传输效率,Beacon+将同一时间内的所有数据合并为一条记录进行发送。
(3)存储结点:存储结点上主要是Lustre的服务端OSS(Object Storage Server)和存储对象OST。Beacon+采样采集了/proc/fs/lustre下的OST的状态表信息,例如,OST ID、Size和Count等信息。每个OST采集的数据可以表示为(timestamp,OST,RPC size,RPC count)。同样,为了提高传输效率,将同一时间内的所有数据合并为一条记录进行发送。
(4)元数据结点:元数据结点上采样采集了Lustre MDT的元数据操作信息,按操作类型和操作数进行统计后由采集程序传出。
上述采样方法的采集频次可以根据实际需要进行调节。目前Beacon+在神威新一代超级计算中设置为每秒1次采样,用来应对超级计算机多变的负载。
(5)作业信息采集:Beacon+通过作业调度器来获取运行的作业信息,例如,作业ID、作业提交时间、作业结束时间和作业使用的计算结点列表等信息,并且将作业信息按照(年-月)分表,存储在MySQL数据库中。作业信息可以帮助针对某一具体应用的用户应用画像描述。
3.2 存储模块
存储模块主要负责数据的中间缓存和持久化存储。Beacon+重新设计了存储架构,精简了软件栈,同时采用了内存数据库来缓存实时源数据,并通过流处理的方法及时消费数据。后台采集程序对采集的数据进行数据清洗和压缩处理后,通过管理网络将数据发送到Logstash和Redis中,其中Logstash 负责接收数据,Redis负责暂存数据。为了提高性能和服务的稳定性,Redis采用了单点模式,这样不仅可以显著提高数据处理的速度,也可以减少E级超级计算机产生的海量数据的存储开销。Logstash和Redis的数量根据不同层级的采集数据量来确定:(1)计算结点上每4个超结点数据对应1个Logstash+Redis中间数据缓冲。(2)代理结点上根据3种采集点类型:LWFS及HadaFS的服务端、Lustre的客户端和NVMe SSD划分了3个Logstash+Redis中间数据缓冲。(3)存储结点和元数据结点各配置了1个Logstash+Redis中间数据缓冲。
持久化存储主要包括:MySQL数据库存储的作业运行信息、预处理导出的原始数据文件和存储预处理结果的InfluxDB数据库导出的冷数据。Beacon+通过定期对这些文件进行压缩,来减少数据存储开销。根据本文的实验评估,100 TB的总容量可以存储5年以上的数据。
3.3 分析模块
分析模块负责将Beacon+采集到的多层数据进行组合分析。为了提高效率和增加可移植性,Beacon+增加了预处理机制,将不同平台不同层级的采集数据进行了统一格式化处理,并且抽象出通用的数据接口供后续数据分析程序调用,大大增加了整个系统的可移植性。同时,Beacon+还改进了异常检测算法,较Beacon[10]提高了15%的精度。此外,Beacon+还增加了RPC层来提供统一的分析结果输出接口。
(1)数据预处理:图2的架构图中展示了预处理处理流程。首先,预处理程序每隔一段时间将暂存在Redis中的原始数据批量取出,进行反序列化。接着,将数据按结点划分,对每个结点按秒级粒度进行处理。经过预处理后,数据被统一表示为以下结构:(结点ID,timestamp,读写带宽,读写数据量,IOPS,MDOPS(每秒元数据操作数),读写大小的分布,文件读写情况)。预处理后的数据会被存储在InfluxDB中,以供后续分析使用。InfluxDB中的数据会被保留1周。与此同时,预处理程序还会将原始数据导出为JSON格式的文件进行持久化存储。
通过预处理可以将不同平台不同层级的数据进行统一格式化处理,得到格式化的数据。然后通过接口向后续的应用画像分析或者系统画像分析程序提供数据支持。这样可以避免后续分析程序针对不同采集方案的修改,提高了Beacon+的可移植性,降低了跨平台移植成本。
(2)数据分析:数据分析主要通过接口获取各层级预处理后的格式化数据,结合作业信息,为普通用户和管理员用户提供不同的视图。
针对普通用户想要获取自身应用性能详细分析的需求,Beacon+提供了应用画像。应用画像通过对作业的I/O行为进行详细分析,为用户提供:①应用的整体I/O表现,例如,应用的I/O带宽、IOPS、MDOPS和请求大小分析等;②I/O模式,例如,1-1读写,N-1读写,N-N读写和N-M读写等;③资源使用情况,例如,代理结点使用情况和存储结点使用情况;④可能存在的性能瓶颈,例如,低效的I/O模式(1-1读写,N-1读写),大量小文件读写,冲突干扰等。其中,冲突干扰是超级计算系统中常见的现象[27]。因为超级计算系统是一个资源深度共享的运行环境,同一时刻可能会运行各种类型的应用,数量可能十分庞大,所以冲突干扰现象屡见不鲜。但是,由于超级计算系统的环境复杂,及时发现冲突干扰并定位其原因一直是一个巨大的挑战。Beacon+为了解决该问题,采用了基于应用历史数据的聚类算法[10]来诊断应用的性能异常。
针对系统管理员,Beacon+提供了系统画像,用来对超级计算机的各层结点进行实时可视化展示。一方面,通过对各结点进行实时监控和记录,计算并实时展示结点的聚合带宽和负载均衡情况,既可以纵向对比从计算到存储各类结点的I/O流量,也可横向观察某类结点内部的具体I/O分布。另一方面,实时地对异常结点进行告警,例如,系统故障的结点、性能降级的结点等。系统故障指结点由于宕机等原因停止了服务,可以通过心跳监控的方法较为方便地捕获。性能降级指结点仍然可以提供服务,但是服务能力达不到正常水平。一般情况下,性能降级的结点在轻负载时同正常结点的表现几乎相同,所以很难被捕获。
为了解决上述问题,本文根据统筹应用和系统侧采集到的2方面数据,设计了基于应用的异常诊断方法,帮助诊断应用的性能异常和定位性能异常的系统结点。
(3)异常诊断分析:通过Beacon+提供的多层数据,本文结合作业信息,设计了如图4所示的从应用出发的异常诊断分析方法。
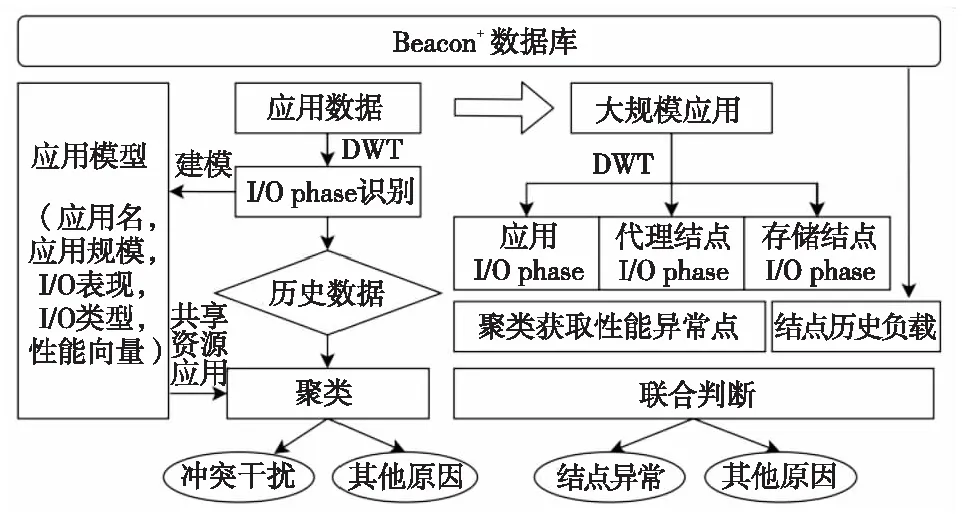
Figure 4 Anomaly detection based on applications图4 基于应用的异常诊断方法
首先通过作业信息获取作业运行时间和使用的结点,然后调用预处理接口查询获取相关结点对应时间的数据进行整合,得到应用的详细I/O行为。通过离散小波变换DWT(Discret Wavelet Transform)将作业的I/O行为转化为若干I/O phase[10],然后对I/O phase进行建模。模型中最重要的一步是求解出性能向量PV(Performance Vertor)。性能向量用来描述I/O phase的带宽表现。然后利用DBSCAN(Density-based Spatial Clustering of Applications with Noise)对具有相同应用名、相同并行规模、相同I/O表现和相同I/O类型的I/O phase的性能向量进行聚类,识别出异常的I/O phase。算法2描述了基于I/O phase的建模算法。
算法2I/O phase建模算法
输入:应用的I/O phase的带宽序列。
输出:D维性能向量PV。
步骤1统计应用的所有相似I/O phase的最大带宽THmax和最小带宽THmin。选择PV的维度D。
步骤2计算划分区间大小I=(THmax-THmin)/D。按照间隔I划分[THmin,THmax],即[THmin,THmin+I),[THmin+I,THmin+2I),…,[THmin+(D-1)*i,THmax]。
步骤3对I/O phase中的带宽序列,按照区间进行统计,得到一个N维向量Vec=[X1,X2,X3,…,XD]。表示序列中有X1个数位于[THmin,THmin+I),有X2个数位于[THmin+I,THmin+2I),以此类推,有XN个数位于[THmin+(D-1)*i,THmax]。Vec即为所求的性能向量PV。
根据此建模算法的结果来进行聚类,相较文献[10,27,28]的算法,精度提高了15%以上。当前应用出现异常后,本文进一步判断当前应用的相邻应用(相邻应用指共享资源的应用)的I/O类型,是否属于几个典型的容易引起冲突干扰的I/O类型,如:N-1读写模式、高I/O带宽和高MDOPS等。如果存在有上述典型I/O类型的相邻应用,那么当前应用就被判断为可能受到了典型应用的冲突干扰而导致了性能异常。如果没有这些典型类型的应用,那么判断同一时刻是否有许多作业都进行了资源共享,如果有许多作业同时共享资源,那么也可能会产生冲突干扰。除了冲突干扰外,还会有一些其他可能的原因导致应用性能异常,例如,系统结点参数设置不正确,系统结点降级等。
对于系统结点的异常诊断则是从大规模高负载的应用出发来判断。大规模应用往往可以独占若干存储资源,这样便于寻找出性能异常的I/O结点。如图4的右侧所示,同样先采用DWT的方法进行计算结点的应用I/O phase提取。同时,对大应用占用的代理结点以及存储结点也做相应的I/O phase提取。然后进行建模,接着通过聚类找出性能异常的结点,结合结点的历史记录,判断结点是否出现了性能降级。
(4)RPC对外接口:为了便于展示端在多平台使用,本文通过Thrift[29]RPC框架对外提供数据分析结果。
3.4 展示模块
展示模块通过RPC接口获取结果。主要提供2种方式:(1)命令行;(2)可视化网页。命令行通过RPC调用获取分析结果,结合Matplotlib[30]进行图像展示。可视化网页采用Vue[31]+Django[32]的前后端框架,后端数据获取同样通过RPC调用。

Figure 6 Overhead tests on two file systems图6 2种文件系统上的开销测试
4 实验与结果分析
4.1 准确性评估
保证采集的数据真实反映应用的I/O行为是衡量性能分析工具的一个重要指标。本文通过将I/O benchmark自身打印的日志的I/O带宽与Beacon+的分析结果获取的I/O带宽相比较,来验证Beacon+的准确性。实验采用IOR(Interleaved Or Random)[33]为测试用例,I/O模式为N-N读写,每个进程读写200 MB的文件,并行规模从4进程到4 096进程,每个规模各进行20次实验,其中10次运行在全局文件系统上,10次运行在Burst Buffer文件系统上。
图5展示了IOR运行在全局文件系统上和Burst Buffer文件系统上时应用日志和Beacon+输出的I/O带宽对比,其中横轴为并行规模,每个规模左侧的盒须图代表日志输出的带宽,右侧代表Beacon+输出的带宽。可以看到,对比应用原始日志输出的真实I/O行为,Beacon+输出的结果误差不到4%,可以说Beacon+真实地反映了应用的I/O行为。对比Beacon[10]的准确性,两者基本相同。
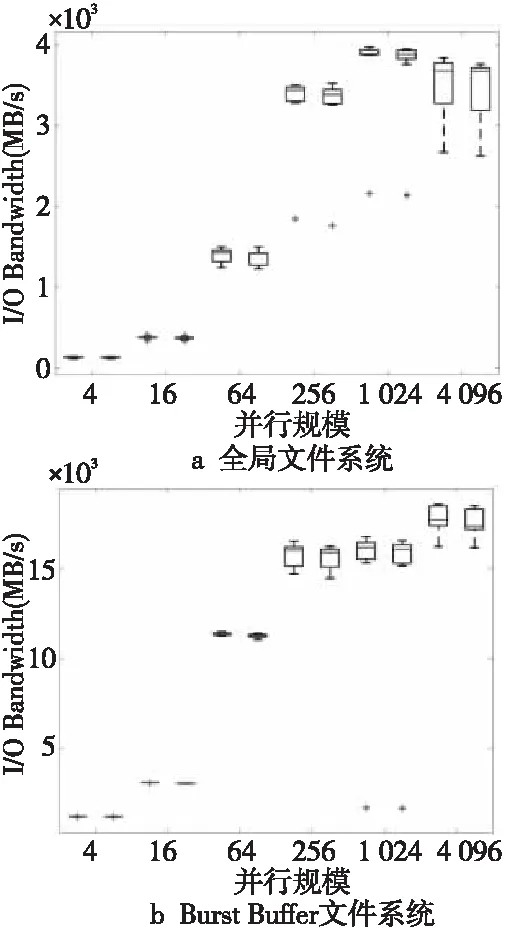
Figure 5 Performance reported by applications’ log and Beacon+ on two file systems图5 2种文件系统上应用日志和Beacon+输出的性能
4.2 开销评估
作为对用户透明、与用户松耦合的系统,Beacon+需要尽可能地降低生产环境对应用的影响。本文通过高负载的IOR[33]来探究极限情况下Beacon+对应用造成的性能影响。实验分别测试了Beacon+在全局文件系统和Burst Buffer文件系统上的开销。
(1)全局文件系统:测试了IOR在未部署监控系统、部署Beacon+和部署Beacon 系统情况下的性能对比。测试程序为1 024个进程(每个进程占据1个计算结点),每个进程读写200 MB文件,进行10次实验。图6上侧的盒须图是实验结果,可以看到,对比Beacon,Beacon+对应用的性能影响更小,平均不到1%。
(2)Burst Buffer文件系统:测试了IOR在未部署监控系统、部署Beacon+和部署Beacon的系统情况下的性能对比。测试程序为6 144个进程,每个进程读写200 MB文件,进行10次实验。图6下侧的盒须图是实验结果,相比于Beacon,Beacon+下的应用性能更加接近原生未部署监控系统时的性能,对应用带宽的影响平均不到1%。
综上所述,可以看到,相较于Beacon,Beacon+对应用的I/O带宽影响更低,多次测试带宽的变化也更小。此外,在真实环境下,真实应用I/O的占比较I/O测试程序会小很多,且I/O的负载也较轻,所以对应用程序的整体运行时间的影响会进一步降低。
4.3 资源占用评估
由于Beacon+的某些模块与生产系统部署在一起,所以资源占用一定要小,否则可能会影响生产系统的其他服务。表1展示了Beacon+和Beacon的资源开销对比。
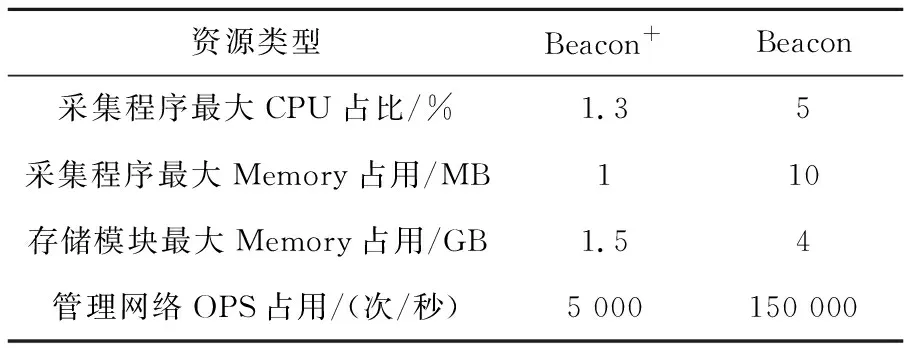
Table 1 Comparison of system overhead
从表1可以看到,Beacon+通过优化采集算法,减少内存拷贝,减少I/O栈深度和增加随机缓冲发送等手段大大减少了CPU、Memory和网络OPS资源的占用,使得其更加适用于E级超大规模的计算系统。
4.4 性能评估
Beacon+的目标是为用户提供实时的诊断结果,所以需要保证数据处理的实效性。本节对比了Beacon+和Beacon的数据处理能力,图7展示了实验结果。
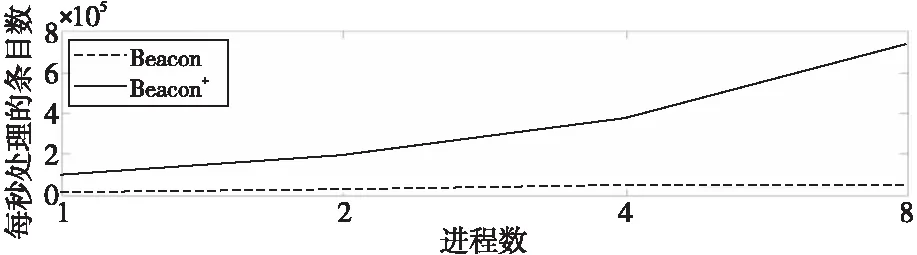
Figure 7 Data processing rate of Beacon+ and Beacon图7 Beacon+和 Beacon数据处理速率对比
从图7可以看到,Beacon+相比于Beacon有明显的可扩展优势,其数据处理性能基本可以随着数据处理进程数的增加而获得线性提升。这是因为Beacon+精简了I/O栈,将数据放在内存数据库Redis中,且采用了单点Redis模式,所以较Beacon[10]采用的Elasticsearch集群存储方案有明显的可扩展优势。虽然Beacon+的存储方案较Beacon会增加些许管理难度,但是该方案的性能提升明显,更适用于E级超级计算机存储海量数据需要实时处理的场景。
4.5 真实案例评估
本节展示了Beacon+在真实场景下的应用。
全局文件系统:全局文件系统由于无需修改应用代码,且支持标准I/O接口,所以往往是许多用户的第一选择。
图8a展示了某分子对接应用[34]在神威下一代超级计算机上的历史多次运行情况,纵轴显示了应用的I/O带宽,多次运行的结果采用不同的线条表示。可以看到,应用的性能抖动十分明显,最大可达2倍以上。借助Beacon+提供的可视化网页,用户可以方便地在应用画像界面获取应用的性能异常原因。对于本应用来说,Beacon+发现同一时刻存在多道作业共享资源,且当中存在极高I/O带宽的应用,从而产生了所谓的性能干扰。
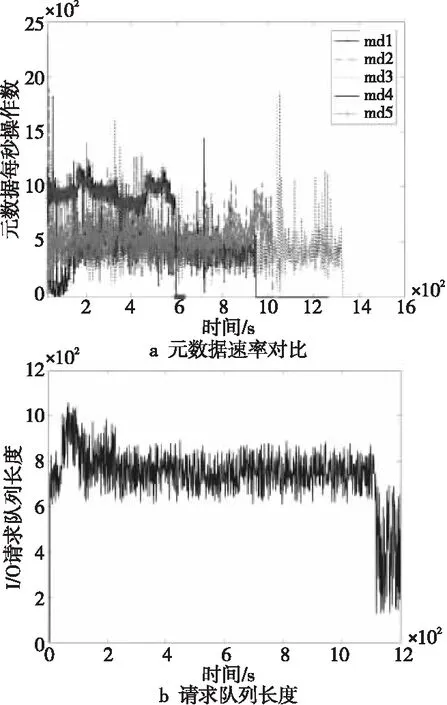
Figure 8 Running history of the applications图8 应用的历史运行信息
与此同时,共享的I/O代理结点上存在大量I/O请求等待的现象,如图8b所示,请求队列的最大等待长度达到了1 000以上。结合多层数据分析,Beacon+给出了本应用性能异常的主要原因是应用的冲突干扰。实际上对于许多的超级计算机应用来说,应用间冲突干扰是造成性能抖动的一个重要因素[10]。解决应用冲突干扰的最好办法是进行资源隔离,将有不同资源需求的应用按照一定的调度策略进行调度,尽量避免有同种资源需求的应用分配到相同的结点上,学术界已有不少相关工作[35,36]。
Burst Buffer文件系统:Burst Buffer文件系统HadaFS的后端存储是高性能的NVMe SSD,所以在某些场景下会有更好的表现。
图9展示了某粒子模拟应用在全局文件系统上的运行情况。由图9a可以看到,该应用的I/O带宽非常低,平均为50 MB/s。图9b展示了该应用的I/O请求大小的分布,可以看到大部分请求小于4 KB,且Beacon+根据I/O请求的偏移进一步分析了其连续性,发现其I/O请求属于不规则随机读,故Beacon+给出的性能瓶颈在于频繁的随机小块读。因为全局文件系统的I/O路径较长,加上后端采用了硬盘作为最终存储,所以I/O请求的延迟相对较长,对小块I/O请求非常不友好。全局文件系统的设计适于对延迟不敏感的高并发的大块读写应用。
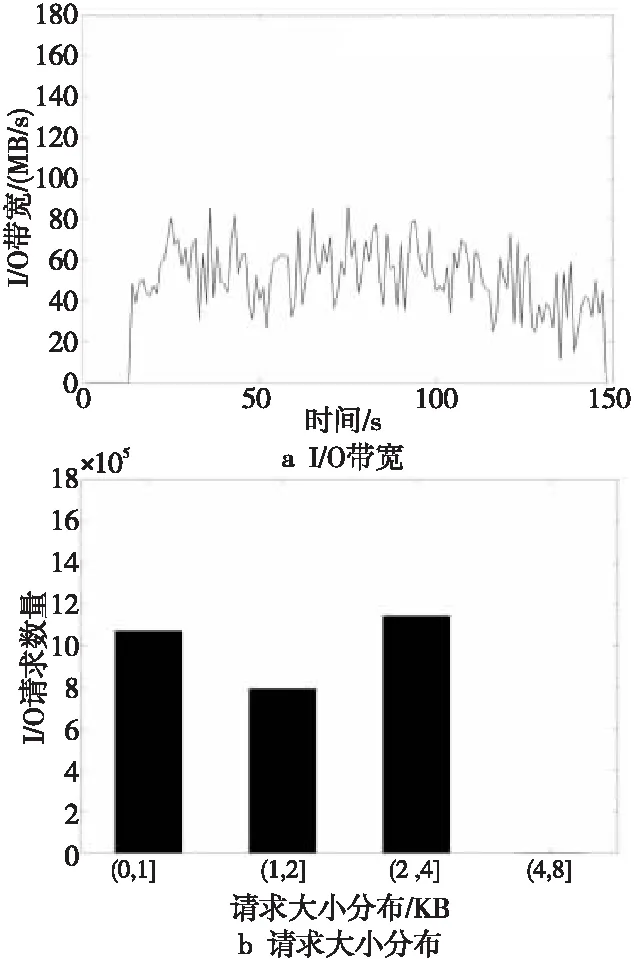
Figure 9 A particle simulation application running on GFS图9 全局文件系统上运行的粒子模拟应用
基于以上考虑,本文使用HadsFS接口替换了应用的I/O模块,并对应用的I/O行为重新进行了评估。图10展示了该应用在相同规模配置下,分别运行在Burst Buffer文件系统和全局文件系统上的性能对比,可以看到应用的I/O行为虽然没有改变,但是由于HadaFS的特性,获得了大约1倍的性能提升。HadaFS的接口可以方便地替换标准的POSIX(Portable Operating System Interface)接口,所以可以大大减少应用开发者重新设计实现I/O策略和重构数据文件的开销。
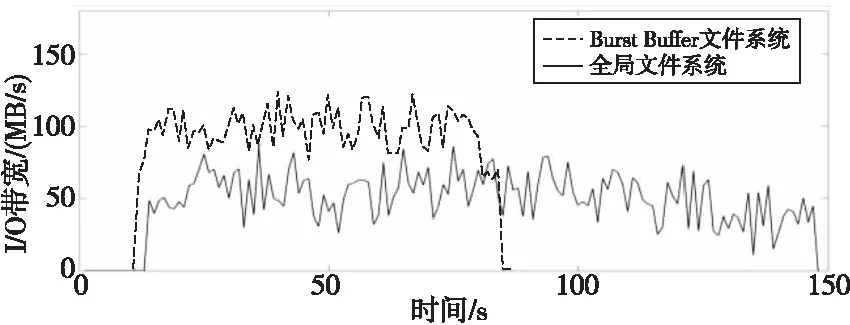
Figure 10 Performance comparison on two file systems图10 2种文件系统上的性能对比
5 结束语
本文面向E级超级计算机的庞大且复杂的架构,设计并实现了高可扩展的轻量级端到端I/O采集与分析诊断系统——Beacon+。该系统具备以下特性:(1)Beacon+支持全机全路径采集,针对不同的层级采用了多种压缩算法,大大降低了系统开销。(2)Beacon+通过流式预处理结合数据流缓冲存储的方法,显著提高了处理效率,面对E级超级计算机的海量数据也可以保证对应用和系统I/O行为的实时分析。(3)Beacon+提供了基于应用的异常诊断系统,可以主动对应用以及系统结点的性能异常进行实时反馈,为最终的问题定位提供关键的基础信息。(4)Beacon+具有很好的可移植性,通过预处理可以将不同平台不同层级的数据统一为格式化后的数据,移植到其他平台时,可以最大程度地减少对应用画像和系统画像分析的修改。(5)Beacon+为了解决E级超级计算机的海量数据而采用的一些方法和采集存储框架,也适用于其他平台。
