一种轻量化中文指路标志的文本识别算法*
2022-09-21宜超杰包宇翔
宜超杰,陈 莉,包宇翔
(西北大学信息科学与技术学院,陕西 西安 710100)
1 引言
指路标志牌是交通标志中最为复杂的一种,能够灵活地传达距离信息、路线信息等。因此,指路标志牌中的文字提取和识别对交通大数据、自动驾驶等具有重要的意义。
如今,使用机器视觉方法对指路标志进行提取和识别十分容易[1 - 4],但从指路标志中提取和识别文字仍然存在较大的困难。典型的指路标志牌如图1所示。

Figure 1 Typical guide signs图1 典型指路标志牌
传统的文本识别方法主要通过对图像色彩、形状等维度的解析和变换来提取图像特征。Wu等[3]使用特征点聚类的方法提取标志牌的水平文字区域;Liu等[5]使用图像的二阶导数来确定图像中的字体边缘信息,并进行区域融合以定位出图像中的文字区域;Neumann等[6]通过边缘和色彩等信息提取最大稳定极值区域MSER(Maximally Stable Extremal Regions)来确定字符位置,并训练分类器实现文本识别。

Figure 2 Flowchart of the proposed algorithm图2 本文算法流程图
但是,传统的检测方法鲁棒性较差,无法适应多变的拍摄环境和角度。近年来,深度学习技术凭借其强大的特征提取能力在机器视觉领域大放异彩,光学字符识别OCR(Optical Character Recognition)技术也随之取得了较大进步。当前深度OCR框架主要由文本区域提取和文本识别2个子模块构成。文本区域提取是指从自然场景中检测和提取出文字区域。如Tian等[7]提出的CTPN(Connectionist Text Proposal Network)使用了锚框的思想来检测水平排布的文本区域;Zhou等[8]提出的EAST(Efficient and Accuracy Scene Text)框架采用多方向的矩形区域来标识检测出的文本区域;Long等[9]提出的TextSnake算法则使用了更为灵活的多圆形组件来定位出任意方向和角度的文本区域。文本识别的任务是从文本区域中识别出文本信息。Shi等[10]提出的CRNN(Convolutional Recurrent Neural Network)网络结构融合了CNN(Convolutional Neural Network)与RNN(Recurrent Neural Network)的特性,可以在文本区域中定位和识别出文本内容;Graves等[11]提出的CTC(Connectionist Temporal Classification)算法能够解决复杂的文本字符对齐问题;还有一些OCR框架将文本进行字符对齐后使用图像分类网络如VGG(Visual Geometry Group)[12]、ResNet(deep Residual Network)[13]等来完成文字识别。Tian等[14]提出的基于弱监督学习的文本检测训练方法WeText,使得在拥有少数已标注的图像数据的情况下仍可以完成文本检测框架的训练。
本文针对中文指路标志的结构和特点,使用轻量化的思想,设计了一种指路标志多方向中文文本提取和识别算法。
2 算法设计
本文提出的算法将中文指路标志的文本识别分为3大步骤,分别为:(1)YOLOv5t(You Only Look Once)文本区域识别和提取;(2)M-split字符分割;(3)文本识别与整合。算法流程如图2所示。
2.1 YOLOv5t文本区域提取
当前OCR技术中较为常用的文本区域提取算法有CTPN[7]、EAST[8]等。CTPN算法借鉴了经典目标检测网络Faster R-CNN[15]中使用的锚框来预锚定文本行对象;EAST算法使用多方向的矩形来标记文本区域。这些常用的深度OCR框架对于文字的方向和排布有一定的要求。尽管近年提出的TextSnake等框架可以灵活地定位多方向、多角度的文本内容,但训练这些框架的数据集标注起来非常困难和耗时。另一种常用的方法是使用通用的目标检测框架来提取文本区域,如SSD(Single Shot multibox Detector)网络[16]、R-CNN(Regions with CNN features)系列和YOLO[17]系列网络等。本文对YOLOv5l目标检测框架进行轻量化改进以实现文本区域的检测。YOLOv5l框架的开源代码地址为https:∥github.com/ultralytics/yolov5.
为了与原网络加以区分以及后期评估的方便,本文将所提算法中经过轻量化改进的YOLOv5l目标检测网络命名为YOLOv5t(YOLOv5 for Traffic)。
YOLOv5l的主要创新点有:
(1)在网络浅层引入Focus切片操作,即对特征图进行等间隔的切片,再对切片进行通道拼接和卷积。
(2)使用CSPNet[18]中的BottleneckCSP瓶颈层堆叠作为基本结构,以加深网络的特征提取能力。
(3)将激活函数换为H-Swish(Hard-Swish),以激励网络学到更为稀疏的特征。设x为神经元的输出值,则H-Swish的表达如式(1)所示:
(1)
YOLOv5l的网络结构如表1所示。
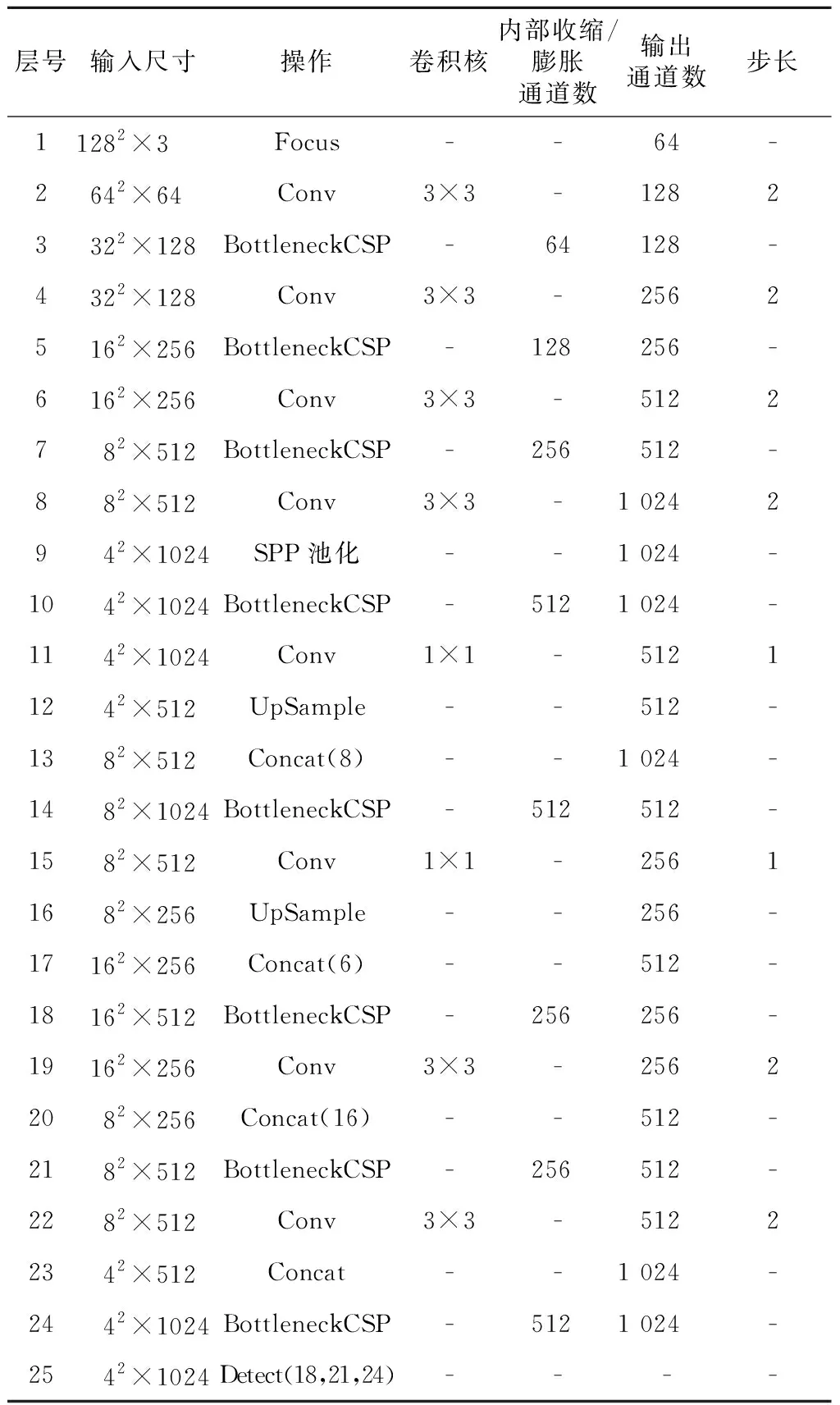
Table 1 Structure of YOLOv5l
表1中,第1~10层为网络的backbone部分,用来提取图像的特征信息;第11~25层为网络的head部分,用来进行特征融合和目标检测。表中1次Conv操作代表1次卷积、批量归一化BN(Batch Normalization)和H-Swish激活函数的组合,Concat表示通道拼接操作。在自动驾驶汽车等设备中,用于进行实时智能计算加速的资源通常十分有限,直接将完整的神经网络部署在这些设备上难度较大,因此对网络进行轻量化改进对于算法的移动布署具有重要意义。
Han等[19]提出的GhostModule通过对特征图进行线性变换,可以得到足够多的特征图,足以代替标准卷积操作,其结构如图3所示。该结构与残差结构融合后,根据不同步长,得到了如图4a和图4b所示的2种GhostBottleneck结构。Howard等[20]在其提出的轻量化网络MobileNetV1中给出了“深度可分离卷积”的概念,将卷积神经网络中的卷积分解为1次“深度卷积”和1次“点卷积”,减少了卷积操作中的参数量。普通卷积和深度可分离卷积分别如图5a和5b所示。

Figure 3 Structure of GhostModule图3 GhostModule结构

Figure 4 Structure of GhostBottleneck图4 GhostBottleneck结构
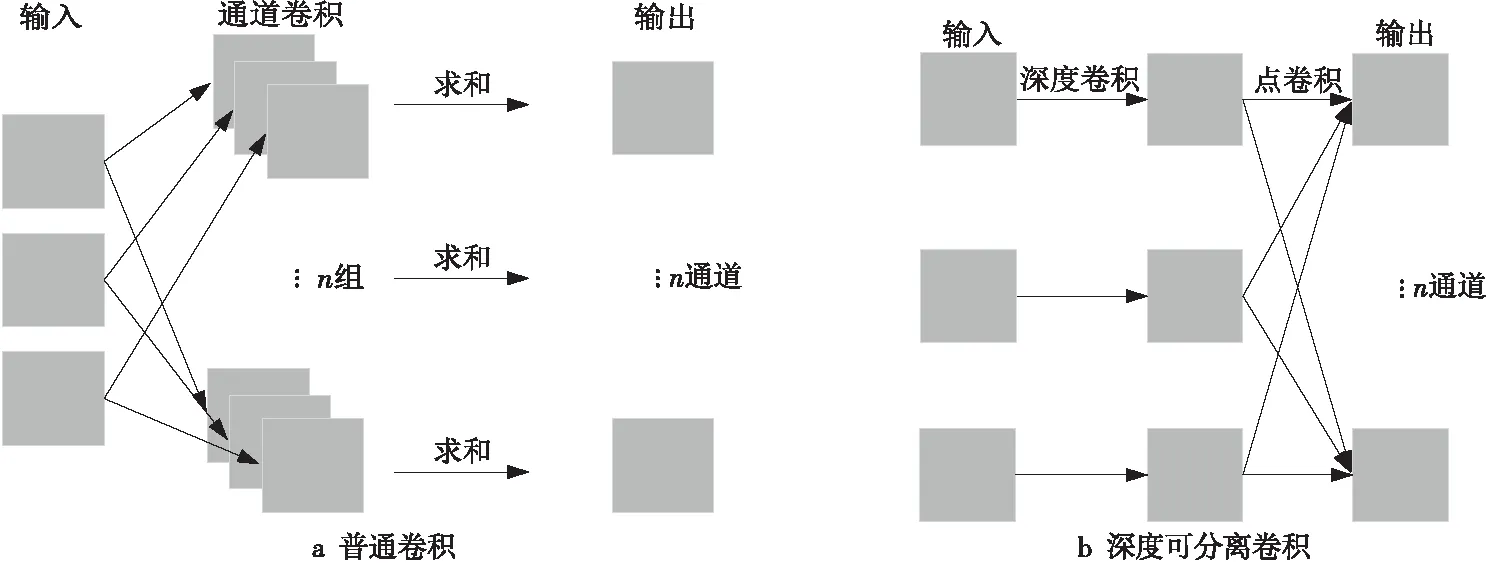
Figure 5 Normal convolution and depthwise separable convolution图5 普通卷积与深度可分离卷积
本文基于上述技术,对YOLOv5l网络进行了如下改进,以优化网络性能:
(1)将YOLOv5l网络的backbone部分改为类GhostNet结构,但将第1层的卷积操作替换为原Focus操作,同时去掉了GhostNet尾部的部分卷积与池化层。
(2)将head部分中BottleneckCSP模块内部的卷积操作替换为深度可分离卷积,并在替换后的网络中的每个BottleneckCSP后添加SE(Squeeze-and-Excitation)层[21]注意力模块,使用全局最大池化的注意力机制来保持网络精度。
(3)对模块间的输入与输出通道进行统一调整,确保不同尺寸的特征能够正常融合。
改进后的网络结构如表2所示。
2.2 M-split字符分割算法
文本区域被提取出来后,需要再分割为单字符,才能输入到神经网络中进行识别。字符分割的方法有基于边缘轮廓的字符分割[22]、基于投影阈值的字符分割等。汉字中,一个汉字可能包含多个独立子结构,如“北”“昌”等字符就由多个“组件”组合而成。此外,某些图像的检测结果中还可能混入了一些噪声(如图6所示),因此上述2种方法都无法完整而准确地划分中文字符。本文提出了一种改进的字符分割算法M-split,主要包括旋转与二值化、投影直方图生成、多项式拟合和极小值点分割等步骤。
2.2.1 旋转与二值化
2.1节中提取出的文字区域中的文字存在横排或者竖排2种排布方向。神经网络可以通过训练识别出多角度的文字,对于竖排的文字,算法直接将其逆时针旋转90°并按照水平文本统一处理。
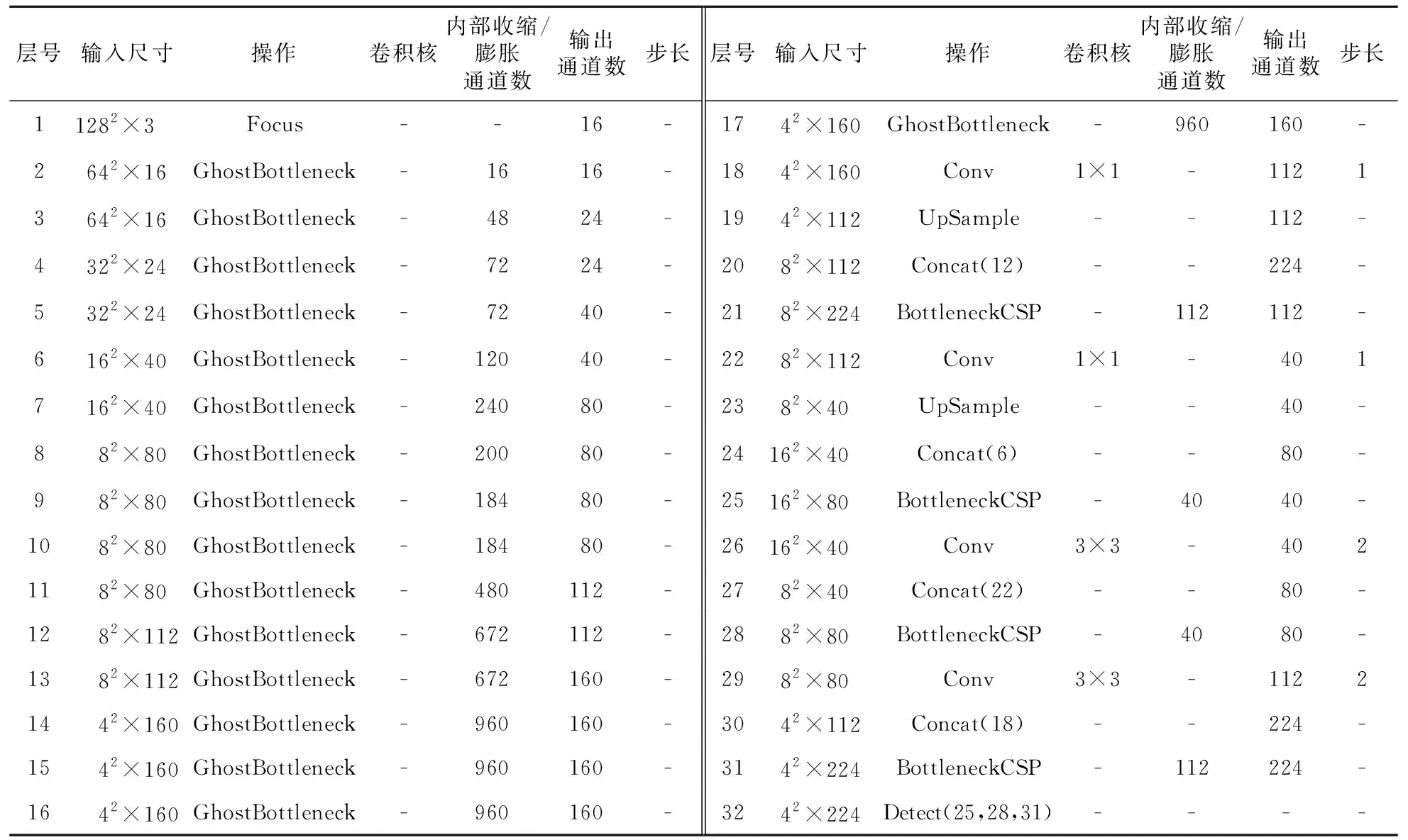
Table 2 Structure of YOLOv5t
当文本区域的宽高比大于或等于1.2时,算法判定文本是水平排布的,否则判定为垂直排布。
在文本区域角度调节完毕后,使用Otsu方法[23]对文本区域进行二值化处理,以去除部分显著噪声点,突出前景文字。文本区域的旋转、二值化处理及其结果如图6所示。
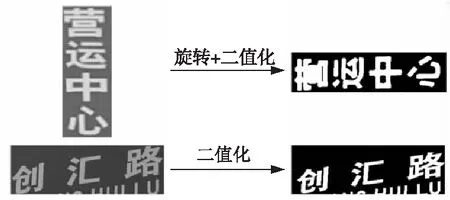
Figure 6 Rotation and binarization operations图6 旋转与二值化操作
2.2.2 投影直方图生成
在图6中,由于YOLOv5t框架只能使用矩形框标识目标,导致部分倾斜或质量较差的区域在进行旋转和二值化处理后仍带有文本以外的噪声。对文本区域进行旋转和二值化处理后,区域中只剩下前景和背景区域,接下来统计二值化后的图像每一像素列中前景部分的像素点个数,得到图像每一列中的白色像素点个数数组P,再对P绘制直方图,以图6中的“创汇路”图像为例,绘制出的对应的水平投影直方图如图7所示。
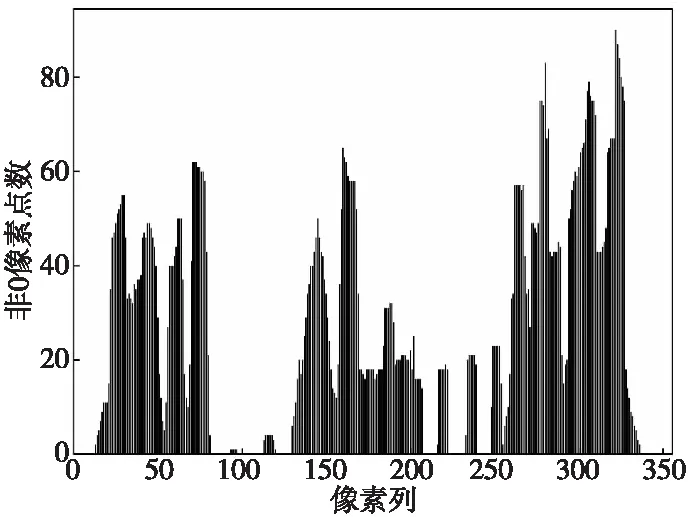
Figure 7 Histogram of text projection图7 文本投影直方图
2.2.3 多项式拟合
由图7可知,虽然字符之间存在明显的、非零像素点数为0的界限,但由于噪声的存在以及汉字结构本身的特性,无法直接通过固定阈值划分出单个字符。因此,本文算法使用多项式来近似拟合直方图,以精确得到分割点。首先将图7所示的直方图看作非0像素点个数y关于像素列p的k(k>0)次多项式函数,即使用如式(2)所示的函数f(p)对直方图进行拟合:
f(p)=a0pk+a1pk-1+…+
(2)
其中,ai为系数,取值范围为全体实数。由直方图可以得到每一像素列pi对应的非0像素点个数yi,于是使用均方误差构建如式(3)所示的损失函数:
(3)
其中w表示像素列总数。
在得到了损失函数后,只需要通过梯度下降法最小化损失函数,即可近似拟合2.2.2节中生成的直方图分布。至此,算法将离散的像素点数值连续化为了多项式函数。
在拟合过程中,可以通过改变k值对直方图进行不同精度的拟合,图8展示了k=5,k=10和k=15时对图6中“创汇路”文字区域的拟合结果。
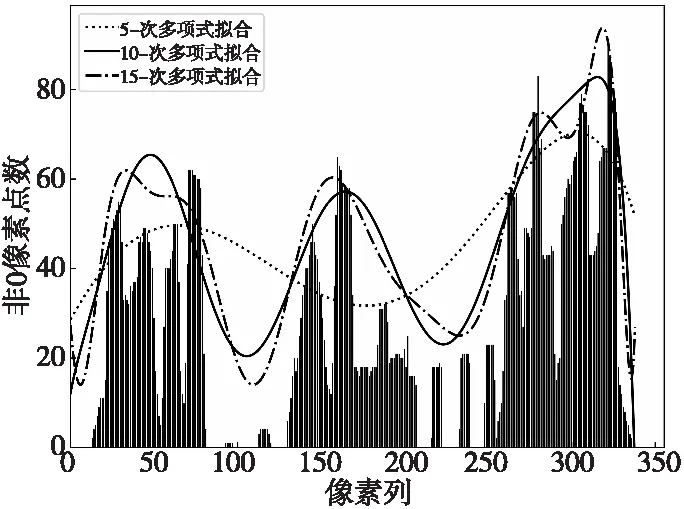
Figure 8 Results of polynomial fitting图8 多项式拟合结果
2.2.4 极小值点分割
由图8知,当k值过小时,曲线并不能很好地拟合直方图的变化,而当k过大时,曲线又会对噪声和汉字内部结构变得过分敏感,因此,k的取值直接关系到M-split算法的分割性能。
在得到多项式f(p)以后,另一项工作是获取f(p)在[0,w]内的极小值。最直接的方法是求解式(4)所示的方程:
f′(p)=0,p∈[0,w]
(4)
并根据解的性质找到f(p)的所有极值点。然而,由于f(p)是高次多项式,求解方程的时间复杂度极大。因此,本文算法以0.5为步长在[0,w]内遍历f(p),以求得方程近似解。判定点M:(p,f(p))为可分割极小值的规则如下所示:
(1)round(f′(p),1)=0;
(2)f′(p-1)≤0且f′(p+1)≥0;
(3)f(p)值小于或等于数组P的下40%分位点。
其中,round(f′(p),1)表示f′(p)四舍五入保留小数点后1位的结果。在执行遍历的过程中,当找到一个新的分割点时,应该与已找到的最近分割点进行比较,若两点之间的距离与w之比小于或等于0.05,则算法认为该新的分割点是重复的,丢弃该分割点。
横排文字和竖排文字的完整分割流程分别如图9a和图9b所示。
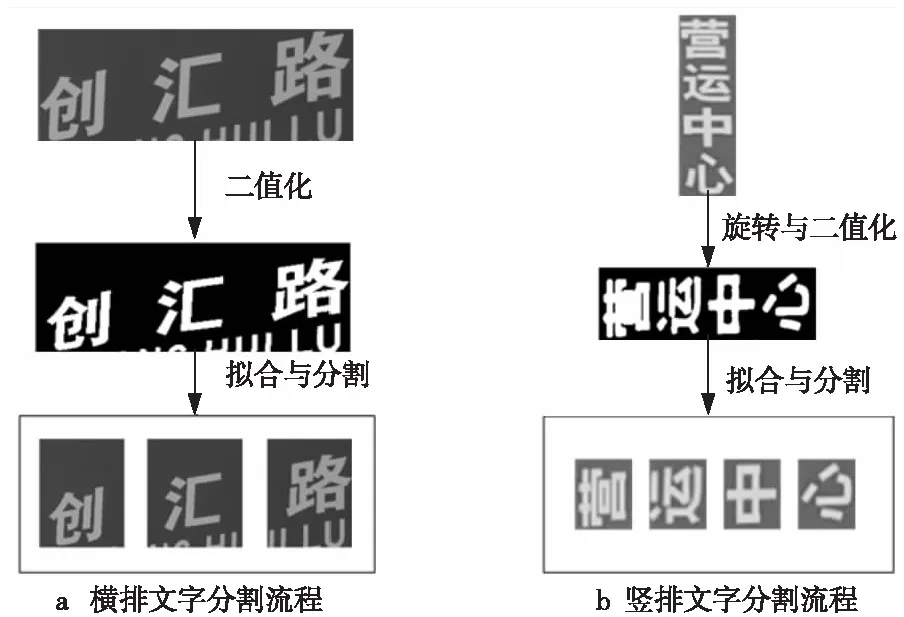
Figure 9 Flow chart of the character division图9 字符分割流程
2.3 文本识别
由于拍摄条件的多样性,最终分割出来的字符区域中可能会存在部分英文、色块等“噪声”,因此在文本识别时,算法需要具有强大的特征提取能力。本文算法使用学习能力较强的神经网络来训练和识别字符,以提高识别精度,出于对时间性能的考虑,算法选择轻量化网络MobileNetV3[24]来实现字符的识别训练。MobileNetV3为MobileNets系列网络的最新版本,其主要创新是引入了通道先扩张再收缩的“反转残差”结构,并使用了SE层[21]来增强网络的学习能力。本文将文本识别任务作为多分类任务实现。训练完成后的MobileNetV3网络权重文件大小仅有18.4 MB,完全可以在边缘计算设备中部署。

Figure 10 Text detect part of TS-Detect dataset图10 TS-Detect文本检测部分
3 仿真实验
3.1 数据集
由于中文指路标志方面尚没有公开数据集,因此本文使用自制的TS-Detect数据集进行网络训练和算法调试。数据集共包含3个部分:文本检测部分、字符分割部分和文本识别部分。其中,文本检测部分包含1 210幅中文指路标志图像,均是从腾讯街景和百度街景中采集获得的。文本检测部分中含有近景(分辨率较高)和远景(分辨率较低)2种尺度的指路标志图像。文本检测部分的数据如图10所示。字符分割部分包含从文本检测部分截取的多角度文本区域图像,由于M-Split字符分割算法不需要进行训练,因此字符分割部分全部用于测试和评估。文本识别部分的训练集包含1 000幅常用汉字字符图像,均进行了旋转、二值化、仿射、添加随机噪声等随机数据增强;测试集包含127幅不同的汉字图像。文本识别部分的数据如图11所示,TS-Detect数据集的划分情况如表3所示。

Figure 11 Text recognition part of TS-Detect dataset图11 TS-Detect文本识别部分
3.2 实验环境及参数设置
本文算法使用Intel Core i9-10900K 3.8 GHz处理器进行数据处理,并使用NVIDIA RTX2080Ti GPU进行神经网络训练加速。算法在Ubuntu 18.04.5 LTS系统环境下进行开发和测试。YOLOv5t网络与MobileNetV3网络均使用PyTorch框架搭建。YOLOv5t网络训练的初始学习率为0.001,使用余弦退火方式调整学习率,batch-size为15;MobileNetV3文本识别网络使用交叉熵作为损失函数,初始学习率固定为0.000 1,batch-size设置为100。
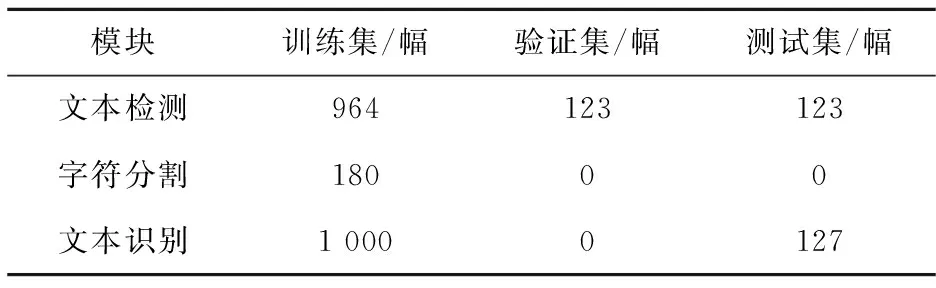
Table 3 Division details of TS-Detect表3 TS-Detect 数据集划分情况
3.3 结果分析与评估
3.3.1 文本区域提取评估
本节中使用mAP@.5指标与mAP@.5:.95指标分别评估YOLOv5t网络的文本区域检测性能。mAP(mean Average Precision)为准确率-召回率(Precision-Recall)曲线使用峰值近似算法得到的与坐标轴围成的近似面积。其中mAP@.5为将IOU(Intersection over Union)阈值设置为0.5时的mAP值;mAP@.5:.95为IOU阈值从0.5以步长0.05增长到0.95时计算得到的mAP平均值。前者评估算法对目标的检出能力,后者反映算法对目标的定位精度。在训练阶段,mAP@.5和mAP@.5:.95的变化曲线分别如图12a和图12b所示。

Figure 12 Train curves of YOLOv5t图12 YOLOv5t训练曲线
本节使用TS-Detect的测试部分评估YOLOv5t网络对中文文本区域的检测效果,并与1.1节中的相关算法进行对比。此外,为了进一步验证YOLOv5t网络结构的轻量化性能,还将YOLOv5l中的卷积操作替换为深度可分离卷积,并将该结构加入对比实验,为了方便评估,本文将该替换后的网络命名为YOLOv5d。对比结果如表4所示。
由表4可知,YOLOv5t网络的权重相较于原版YOLOv5l网络的下降了93.3%,mAP@.5:.95仅下降了3%,mAP@.5甚至高于原版YOLOv5l网络的,并优于YOLOv5d等其他对比网络,在TS-Detect文本检测部分的测试集上达到了最佳精度。可见,本文提出的YOLOv5t网络能够高效地检测出指路标志中的中文文本区域,并过滤了英文、指示图形等干扰元素。
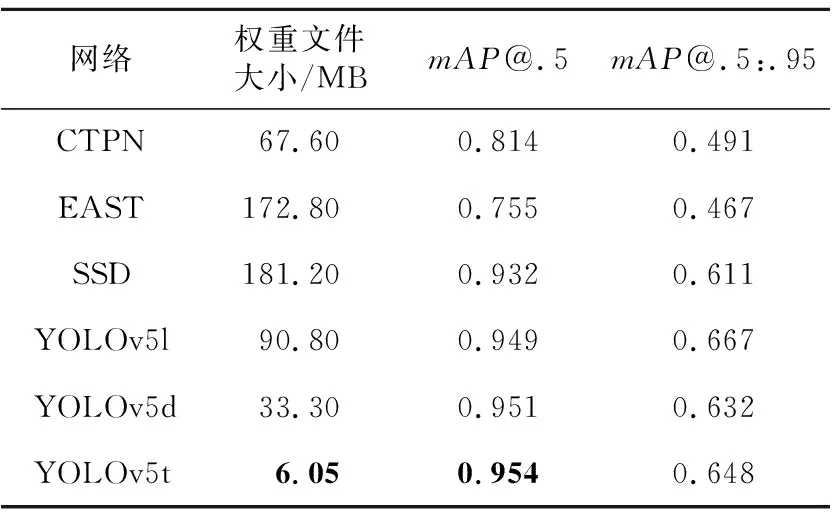
Table 4 Comparison of text detection algorithms
3.3.2 字符分割评估
本节使用TS-Detect数据集中的字符分割部分对M-split字符分割算法进行评估,并与主流的字符分割算法进行对比。
当拟合多项式的指数参数k分别取5,10,11,12,13,14,15时,使用准确率(Precision)、召回率(Recall)及F1指数(F1-Score)3种指标评价M-split字符分割算法在 TS-Detect字符分割数据集上的文本分割性能。3种指标的相关定义如式(5)~式(7)所示:
(5)
(6)
(7)
其中,TP为真正例(True Positive),即被正确分割的字符数量;FP为假正例(False Positive),即结果中分割错误的字符数量;FN为假反例(False Negative),即测试集中未被分割出的字符个数。
M-split算法的测试结果如表5所示。
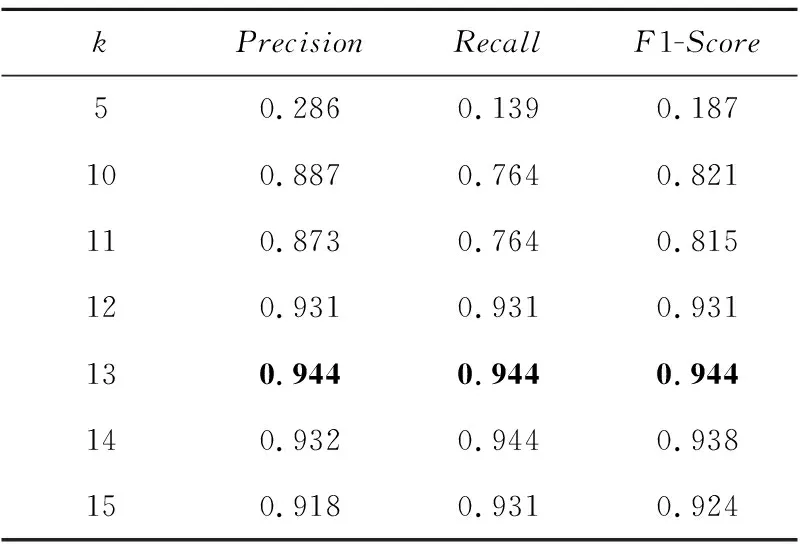
Table 5 Experimental results of character split algorthm
由表5可知,当k=13时,M-split算法的F1-Score值最高,效果最优。在得到字符分割参数后,使用2.2节中所述的投影阈值法和边缘轮廓法(使用Sobel算子强化边缘信息)在TS-Detect字符分割数据集上与M-split算法进行对比实验,结果如图13所示。
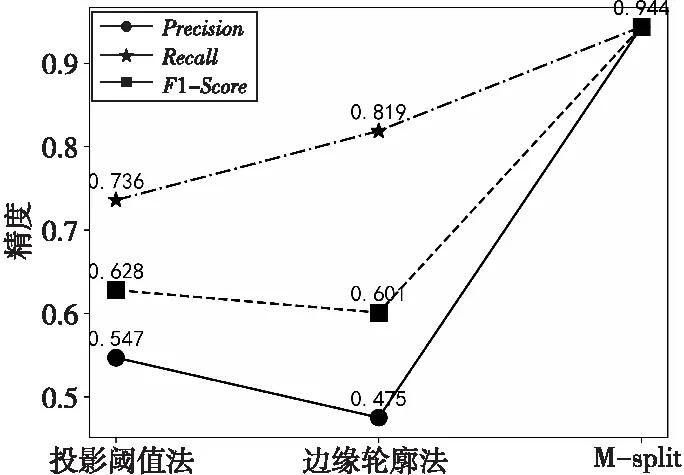
Figure 13 Comparison of different character split algorithms图13 字符分割算法对比
由图13可知,本文提出的M-split算法的F1-Score值达到了0.944,比投影阈值算法的高出50.3%,比边缘轮廓分割法的高出57.1%,相较于其他字符分割算法,M-split算法具有更优异的性能,能够胜任多角度、含有英文等噪声图像的字符分割任务。
3.3.3 文本识别评估
本文将文本识别作为图像分类任务进行处理。文本识别训练集包括了1 000幅常用汉字样本图像来检验算法的有效性。损失函数的下降曲线如图14所示。本文采取分类任务的常用指标——正确率(Accuracy)来衡量分类结果,其计算公式如式(8)所示:
(8)
其中,P为所有正例(Positive),N为所有反例(Negative),P+N代表测试集中的所有文字个数,TP+TN代表被正确识别的文字个数。本文分别训练了VGG16、ResNet50和AlexNet 3种图像分类网络作为对比分类器,还使用未经分割的水平文本数据训练了主流的CRNN+CTC端到端文本识别网络,测试结果如表6所示。
Figure 14 Loss curve of MobileNetV3图14 MobileNetV3训练损失下降曲线
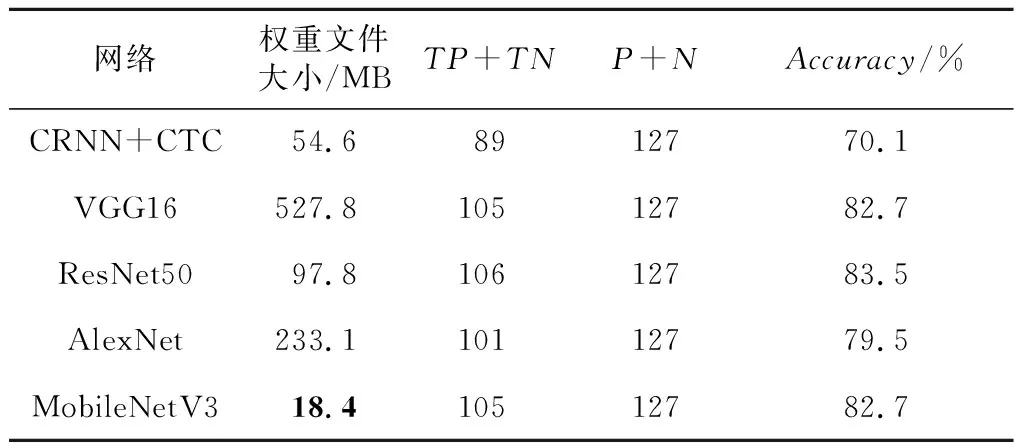
Table 6 Experimental results of text recognition表6 文本识别结果
由表6可知,MobileNetV3文本识别网络的识别精度达到了82.7%,能够准确识别汉字,过滤噪声。其余几种文本识别网络中,ResNet50网络的识别精度最高,达到了83.5%。相比之下,本文算法所采用的MobileNetV3轻量化网络与最佳结果仅相差0.8%,但权重文件大小只有后者的18.8%,十分轻量化,更加易于部署和实时计算。
3.3.4 算法整合
在各模块分别开发完成后,对图像的尺寸进行适应性调整和连接,最后融合为完整算法。本文使用TS-Detect文本检测部分数据集中的验证集+测试集共246幅测试图像对完整算法进行性能综合评估,并与当前主流的自然场景OCR算法进行正确率对比,还使用帧率(每秒可检测的图像数量)来衡量算法的实时性能,在帧率评估时不区分远景与近景图像。综合评估结果如表7所示。
由表7可知,本文算法在TS-Detect文本检测数据集上的近景检测正确率达到了90.1%,远景检测正确率达到了70.2%,在近景和远景图像的文本检测精度在所有参评算法中都是最佳。且本文算法的推断速度达到了40 fps,相较于其他算法也具有明显的优势。在实际的部署场景中,还可以利用连续拍摄得到的冗余信息进一步提高检测精度。部分检测结果样例如图15所示。
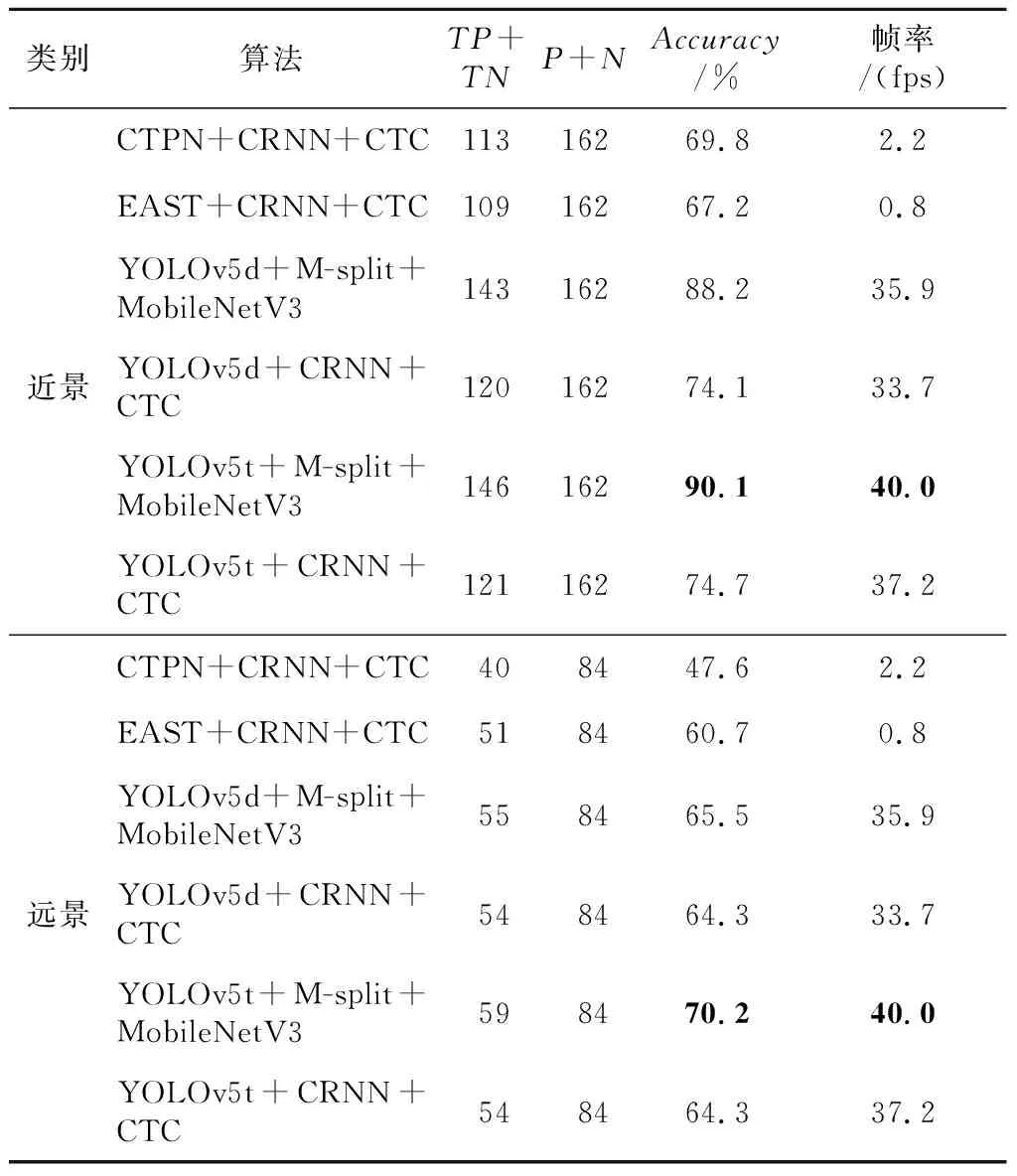
Table 7 Experimental results of algorithms

Figure 15 Results of the proposed algorithm图15 结果展示
4 结束语
本文设计了一种结合了CNN与传统机器学习方法的轻量化中文指路标志文本提取与识别算法。算法分为文本提取、字符分割和文本识别3大模块。在文本提取时对YOLOv5l网络进行了轻量化改进,提出了YOLOv5t文本区域检测网络;在字符分割时,提出了一种基于投影直方图和多项式拟合的M-split分割算法,充分利用汉字结构和汉字间距来达到快速、精准的分割效果;使用MobileNetV3轻量化网络完成文本识别任务。最后通过实验对整体算法和各个模块分别进行了评估,验证了本文算法的有效性和高效性。
