基于主题提示的电力命名实体识别①
2022-09-20康雨萌翟千惠程雅梦
康雨萌, 何 玮, 翟千惠, 程雅梦, 俞 阳
(国网江苏营销服务中心, 南京 210019)
随着人工智能技术的迅速发展, 国网集团启动了“互联网+电力营销”的工作模式, 将传统的线下营业厅与人工客服热线升级为自动化的电力客服机器人. 为了支撑智能化的客服问答, 构建知识图谱成为了一个主要途径. 而在整个构建流程中, 如何从电力领域文本中进行命名实体识别(named entity recognition, NER)[1]是一个重要环节, 它旨在将输入文本中的单词或短语识别为不同类型的实体标签[2], 为后续关系抽取等步骤提供基础.
传统的NER方法主要是基于BiLSTM-CRF框架.鉴于预训练语言模型(pre-trained language model, PLM)[3]在多项自然语言处理任务上带来的显著提升, 微调PLM的参数以编码输入文本, 并利用Softmax或条件随机场(conditional random field, CRF)[4]分配实体标签, 成为了NER领域的普遍做法. 尽管这类方法在一般任务上表现不俗, 但是由于预训练和下游NER任务之间存在差距, 且对于新的目标领域, 模型需要足够的训练实例进行微调, 因此在电力场景下, NER[5]任务仍然面临着以下挑战:
首先, 现有方法大多假定具有充足的标注训练数据, 然而, 提供电力领域的标注往往需要具备领域知识的专业人员. 这使得在实际应用中训练数据不足, 即存在少样本(few-shot)问题. 其次, 在传统开放领域NER数据集中, 实体类型一般较少且更含义宽泛, 如在广泛使用的英文数据集CoNLL03[2]中, 只有4种实体类型.而在中文电力场景中, 由于其行业特殊性, 实体类型高达14种, 而且训练数据更少, 这无疑加大了预测实体类型的难度.
为了克服上述挑战, 本文提出了一种基于主题提示的NER模型(topic prompt NER model, TP-NER). 该模型打破了BERT-LSTM-CRF范式, 使用自然语言提示模板挖掘PLM的潜在知识, 以提升少样本NER的效果. 同时, 该模型利用了电力语料中的主题信息,使得实体类型预测更加准确.
1 相关工作
近年来, 基于神经网络的方法在 NER 任务中提供了有竞争力的表现. Lewis等人[5]和Chiu等人[6]将NER视为对输入文本的每个单词的分类问题. Ma等人[4]利用CRF和“序列-到-序列”框架[7], 从而得到实体跨度与对应类型标签. Zhang等人[8], Cui等人[9]和Gui等人[10]分别使用标签注意网络和贝叶斯神经网络. 随着预训练模型的兴起, Yamada等人[11]提出了基于实体感知的预训练, 从而NER 上获得不错的效果. 这些方法与本文方法的区别是它们是为指定的命名实体类型[12-14]设计的, 采用了序列标注的框架, 这令它们在少样本场景难以适应新的类型.
目前已经有一些关于少样本场景下NER的研究.Wiseman等人[15]提出了不同的预训练方法和微调策略. Yang等人[16]利用常见的少样本分类方法, 如原型网络和匹配网络, 其中还学习了提高性能的转换分数.这些方法依赖复杂的训练过程, 但结果并不显著. Chen等人[17]的方法不需要元训练, 通过最近邻分类器和结构化解码器, 取得了更好效果.
利用外部知识来提高 PLM 的性能近年来得到了广泛的研究, 通常应用于预训练和微调阶段. 具体来说,在文本分类任务中, Li等人[18]探索了利用知识图谱来增强输入文本. 与这些方法不同, 本文的方法在提示调优结合了主题知识, 因此在少样本NER任务中产生了显著的改进.
自从 GPT-3出现以来, 提示调优受到了相当大的关注. GPT-3表明, 通过即时调整和上下文学习, 大规模语言模型可以在低资源情况下表现良好. Schick等人[19]认为小规模语言模型也可以使用提示调整获得不错的性能. 虽然大多数研究都是针对文本分类任务进行的, 但一些工作将提示调整的影响扩展到其他任务,例如关系抽取. 除了对各种下游任务使用提示调优, 提示模板还用于从PLM中探查知识. 因此, 这为NER任务提供了一种前景, 即通过运用提示模板, 模型可能有效利用预训练带来的知识.
2 基于主题提示的电力NER模型
2.1 任务定义
给定一条输入电力文本 X={x1,x2,···,xn}, 其中xi表 示文本中的第i 个字, T+为文本总字数. 命名实体识别任务的目标是输出三元组Y =(us,ue,l), 其中us∈[1,n]和ue∈[us,n]分 别表示识别出的实体在 X中的起始索引与结束索引, l∈L 表示实体的类型标签, L为数据集中所有类型的集合. 如果输入文本 X 中不包含实体, 则输出(-1, -1, -1). 如下展示了两个电力场景中关于NER任务的例子, 其中例1中的输入文本包含“业务需求”类型实体“复电”, 例2中的输入文本没有包含任何实体.
例1. 输入文本: 复电手续如何申请?
输出:(us=1,ue=2,l=business)
解释: ( 1,2)表示实体跨度“复电”, business表示标签“业务需求”.
例2. 输入文本: 这是怎么回事?
输出:(us=-1,ue=-1,l=-1)
解释: 该输入文本中无实体.
2.2 基于提示调优的NER框架
PLM模型蕴含了从海量语料中学习到的丰富知识. 利用这些涵盖各个领域的知识即可在仅有少量训练样本的情况下对电力领域完成快速适配. 在传统NER常用的BERT+LSTM+CRF模型[20]中, 尽管预训练的BERT被用于编码输入文本, 但最终还是需要通过微调(fine-tuning)其参数以适应NER任务. 由于预训练的目标(掩码预测)与NER微调的目标(序列标注)不一致, 因此知识无法被有效利用, 使得基于微调的模型在电力NER上通常无法取得较好的结果.
区别于这些微调模型, 本文提出的TP-NER构建了一种基于提示调优(prompt-tuning)的框架, 以解决的电力场景的少样本问题. 简单来说, TP-NER将NER的输出包装成自然语言提示模板. 相比于原有的三元组形式, PLM更适合对自然语言进行语义表示和打分, 这是因为它原本就在自然语言语料上进行预训练. 这种提示模板统一了预训练任务与下游NER任务的形式, 使得PLM中的知识可以被直接利用. 这样, 仅使用少量的训练样本即可完成对电力领域的适配.
整个方法流程概览如图1所示. 在离线阶段, 预先构建NER自然语言模板; 在推理阶段, 首先通过枚举候选跨度填充模板, 生成候选提示句, 再利用PLM对候选提示句直接打分排序. 得分最高的提示句所对应的实体与类型作为输出被返回.
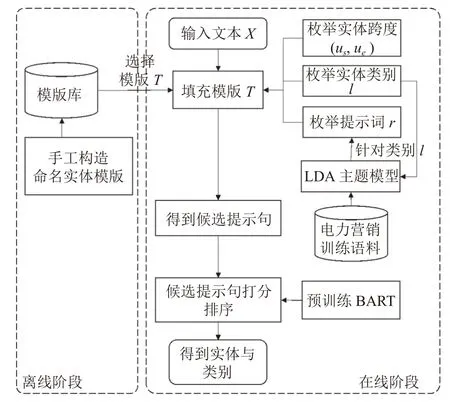
图1 基于主题提示的NER方法流程图
2.2.1 NER提示模板构建
在本文的定义中, NER提示模板是一个包含空槽位的自然语言句子. 例如, “[MASK-e]是一个[MASK-t]类型的实体”是一个模板. 其中, [MASK-e]表示识别出的实体跨度, 如“电能表”; [MASK-t]表示实体[MASK-e]的类型, 如“机器设备”. 这种模板以自然语言的形式对候选的实体与类型进行了重新包装, 以便PLM模型可以利用在自然语言语料上学习到的先验知识克服少样本问题.
如引言所提到的, 电力领域中实体类型较多, 包含14种, 如“业务需求”“机器设备”. 在少样本场景下,PLM模型缺少足够的训练数据去理解这些细粒度实体类型的差别. 因此, 对上述NER提示模板进行实体类型方面的增强. 具体地, 模板被扩充为“[MASK-e]是一个[MASK-t]类型的实体, 与[MASK-r]相关”. 其中,[MASK-r]表示与实体类型[MASK-t]语义关联的提示词. 这些词与实体类型密切相关, 在预训练的语料中往往与对应的类型共同出现, 因此对PLM可以起到有效的提示作用, 从而进一步帮助它理解实体类型的语义.
在离线阶段, 为了涵盖不同的自然语言表达方式,设计了3种正样本模板T+与 1个负样本模板T-, 如表1所示. T+表 示句子中存在实体, 而T-表示句子中无实体. 这样, 模板既能利用[MASK-t]带有的全局类型信息, 也能利用与[MASK-r]获得局部信息.

表1 命名实体模板
2.2.2 模板填充与候选提示句生成
在推理阶段, 首先从正样本模板中随机选择一个模板T+, 如“[MASK-e]是一个[MASK-t]类型的实体, 与[MASK-r]相关”, 作为待填充的模板. 接着, 枚举命名实体跨度( us,ue). 具体做法是, 对于任意一个索引u ∈[1,n],枚举长度从1到 m 之间的所有跨度, 即(u,u),(u,u+1),···,(u,u+k) . 对跨度( us,ue) , 将Xus:ue填入T+. 如跨度( 1,3),即文本“复电手”, 填入模板后得到提示句“复电手是一个[MASK-t]类型的实体, 与[MASK-r]相关”. 随后, 枚举一个实体类型标签l ∈L, 如“business”, 将其对应的标签词“业务需求”填入到T+的[MASK-t]中, 模板更新为“复电手是一个业务需求类型的实体, 与[MASK-r]相关”. 最后, 利用LDA模型从电力训练语料中获取b 个提示词, 记为R ={r1,r2,···,rm}. 这些提示词与实体类型在语义上密切相关, 其获取过程将在第2.3节中详细阐述. 枚举每个提示词ri∈R, 如“申请”, 填入到[MASK-r]中, 最终得到完整的提示句“复电手是一个业务需求类型的实体, 与申请相关”, 记为Tus,ue,l. 对输入文本 X 完成所有枚举后, 一共得到 n×m×b×|L|个提示句. 这里,n 为 X 的长度, | L|表示类型标签集合大小. 此外, 考虑文本X 中无实体的情况, 此时仅枚举实体跨度填充负样本模板T-, 而不需要枚举实体类型, 得到n ×m个负样本提示句. 综上, 一共得到n ×m×(b×|L|+1)个候选提示句.
2.2.3 候选提示句打分排序
此阶段的目标是计算每个候选提示句的分数. 为了克服电力领域的少样本问题, 使用生成式PLM模型BART[5], 以其蕴含的丰富知识弥补训练样本的缺失.BART是一种基于编码器-解码器框架的PLM模型, 集成了BERT双向编码和GPT自左向右解码的特点, 这使得它比BERT更适合文本生成的场景. 在本文中, 将文本 X输入到BART编码器中, 通过自注意力得到的上下文表示. 接着使用BART解码器进行自回归解码,在每个解码时刻得到单词的输出概率.
具体来说, 对输入文本 X={x1,x2,···,xn}, 设候选提示句 Tus,ue,l={t1,t2,···,tn′} , 其中ti表示该句的第i 个字, n′表 示文本X 总 字数. 则Tus,ue,l的 语义分数score(Tus,ue,l)由每个解码时间步生成字ti的概率乘积计算得到, 如式(1)所示.
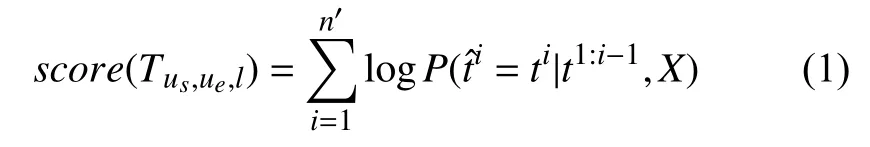
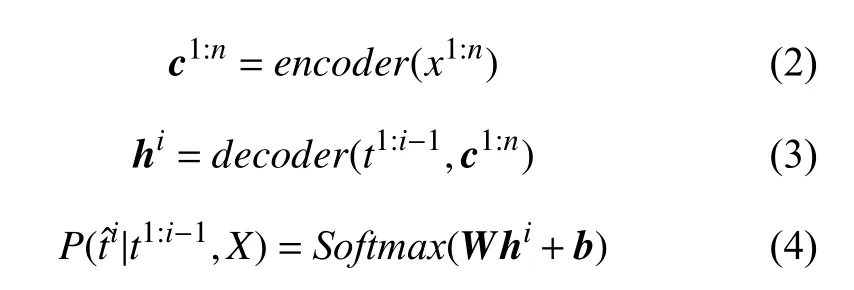
其中, encoder和decoder分别表示BART的编码器与解码器, c1:n∈Rd×n表示对X 进行自注意力机制编码后得到的上下文语义向量, hi∈Rd表示在解码时间步i时,结合 c1:n与之前i -1步 结果t1:i-1, 得到的隐藏向量. d表示向量维数, W ∈R|V|×d, b ∈R|V|为可训练的参数矩阵与向量, 用于将 hi投 影到BART词表V 上, | V|表示字典大小.表示在解码时间步i 时, 模型生成字的概率.
最终, TP-NER选择 score(Tus,ue,l) 最高的( us,ue,l)作为输出返回, 如图2所示, 返回(1, 2, business), 识别出实体“复电”与实体类型“业务需求”.
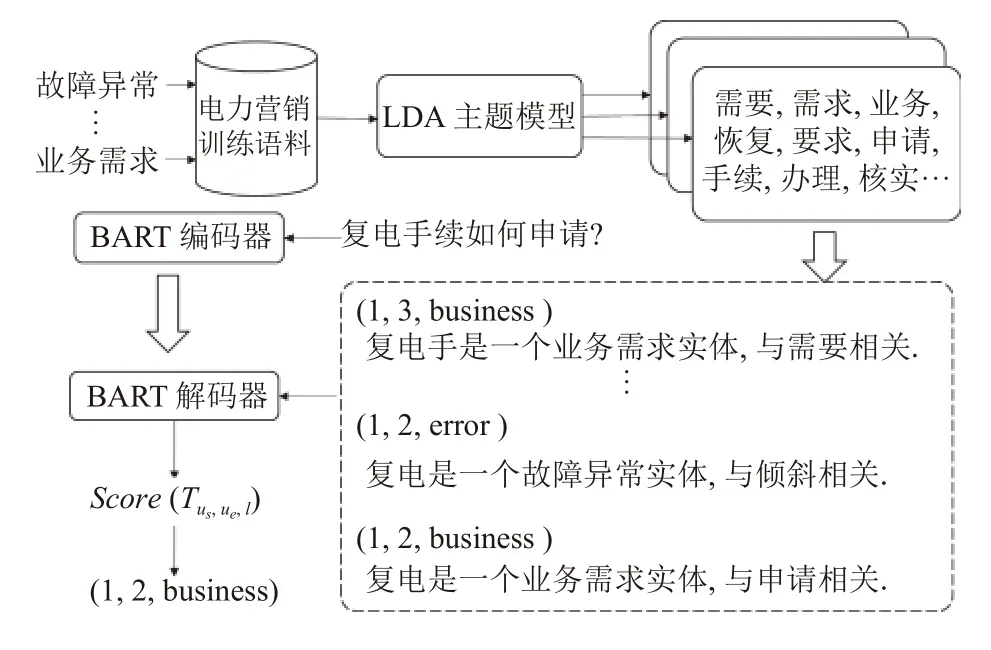
图2 TP-NER框架
2.3 主题模型生成提示词
上文已提到, NER提示模板中的槽位[MASK-r]用于补充与类型[MASK-t]相关的语义信息, 以帮助PLM在少样本电力场景下区分实体类型. 由于行业文本的特殊性, 电力领域中的一种实体类型标签(如“机器设备”“财务票据”“业务需求”)往往可以看作一个主题, 而相关主题词可以视为对主题的进一步描述, 用于提示PLM. 例如, 对于“故障异常”类型, 常见主题词有“掉落、停电、故障、破坏、波动、倾斜、失败、没电、欠费”等; 对于“业务需求”类型, 常见主题词有“需要、需求、业务、恢复、要求、申请、手续、办理、核实”等. 这些主题词在预训练的语料中就常常伴随着类型(主题)共同出现, 有利于为预训练语言模型提供语义提示, 从而帮助确定实体类型. 基于此动机, 本文使用经典的主题模型LDA[20]从训练语料中抽取主题词加入到提示模板中, 以增强PLM处理电力领域数量较多实体类型的能力.
2.3.1 文档构成
对于电力训练集中每个实体类型标签 l ∈L, 将其视为一个主题, 并收集包含l类型实体的所有训练文本,例如, 当l 为“业务需求”时, “复电手续如何办理”即为一个被收集的文本. 将所有收集到的文本拼接成一整篇电力文档, 记为D , 以便后续抽取与l相关的提示词.
2.3.2 文档建模过程
参考LDA模型[20], 对电力文档 D 进行基于实体类型(即主题)的建模. 整个过程包含单词、实体类型和文档3层结构, 如图3所示. 在此设定中, D 被视为一个词袋(bag-of-words)模型, 忽略其中单词的先后顺序.
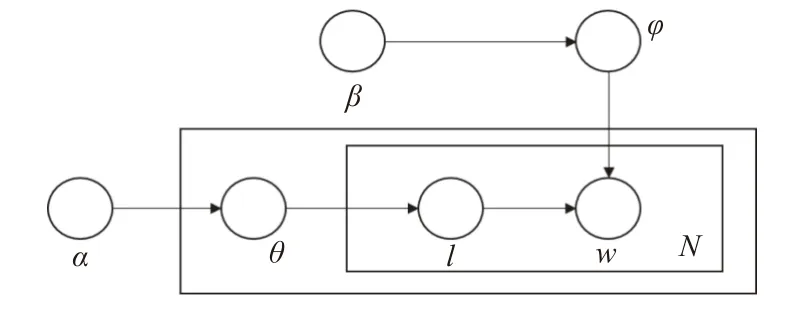
图3 LDA模型示意图
具体来说, 设θ 表示实体类型在电力文档D 上的概率分布, φ表示特定类型l 上的单词概率分布, 则生成D 的过程由参数α 和β 控制, 步骤如下:
(1)根据泊松分布, 得到电力文档的词数N .
(2)根据狄利克雷分布 D ir(α), 得到电力文档的实体类型概率分布θ.
(3)对于隐含实体类型l, 根据狄利克雷分布D ir(β),得到实体类型l下的单词概率分布φ.
(4)对于 D 中的N 个单词中的每个单词wi, 首先根据 θ的多项式分布 M(θ), 随机选择一个实体类型l; 再根据l的多项式分布M (φ) , 随机选择一个单词作为wi.
基于此过程, 在参数 α ,β条件下, 当所有单词都确定后, 得到电力文档D , 而生成D 的条件概率P (D|α,β)通过式(5)计算:
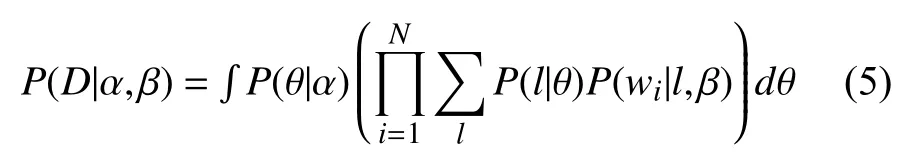
其 中, P(θ|α) 表示在参数α条件下实体类型θ的概率,P(l|θ)表 示选择类型l 的概率, P (wi|l,β) 表示在已选择l的条件下选择单词wi的概率.
2.3.3 生成提示词
为了对θ 和φ 进行估计, TP-NER采用LDA中常用的Gibbs采样算法. 其过程可以看成上述文档生成过程的逆向过程, 即对于第2.3.1节中得到的电力文档 D ,通过以下步骤进行参数估计:
(1)为每个单词wi随 机分配一个实体类型li.
(2)对于任意wi, 设l-i表示除wi以外的其他单词的实体类型分布. 在已经得到l-i的情况下, 计算wi与实体类型为 j的后验概率P (li=j|l-i,wi), 并将最可能的实体类型分配给wi.
(3)重复迭代步骤(2), 直到每个单词wi相关的实体类型分布收敛到稳定状态.
其中, P (li=j|l-i,wi)通过式(6)计算得到:
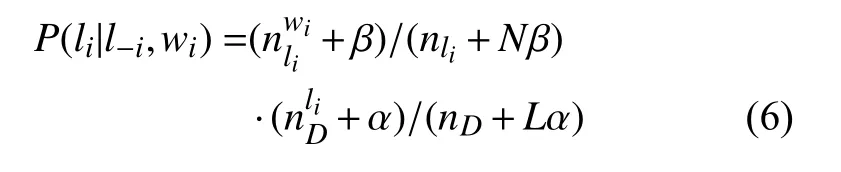
其中, N 和L 分别表示电力文档中的单词总数和实体类型总数.表示单词wi与实体类型li相 关的频数, nli为所有单词都与li相 关的总频数;表示文档D 中与类型li相关的单词频数, nD表示D 中的总单词数. 根据每个单词分配的相关实体类型时, 通过如式(7)和式(8)计算参数:
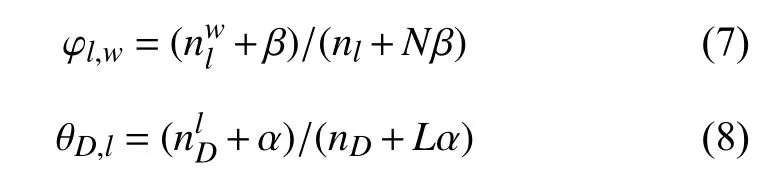
其中, φl,w表示单词w 与实体类型l 相关的概率, θD,l表示电力文档 D出现实体类型l的概率. 结合φl,w与θD,l, 则单词w 在文档D 中出现的概率PD,w=φl,w×θD,l. 此概率反映了单词与文档主题的相关性, 是判断主题词的依据.
最后, 将电力文档 D 中所有的词按PD,w排序, 选取前 b个词作为与实体类型l 的提示词, 填入模板T+的[MASK-r]槽位, 完成最终提示句, 用于BART打分排序(第2.2.2节). 这些提示句引导BART利用其蕴含的知识, 在少样本场景下, 完成对电力领域实体与细粒度类型的识别.
2.4 模型训练
为了训练TP-NER中的打分排序模型, 需要使用训练数据中提供的正确实体构建提示句. 假设实体跨度( us,ue) 的类型是l , 则将( us,ue) 与l 填入正样本模板T+,得到目标提示句 Tus,ue,l. 若( us,ue)不是一个实体跨度,则将( us,ue) 填入负样本模板T-, 作为目标提示句Tus,ue.根据训练集中所有正确实体, 可以构造出正样本对集合 { (X,T+)} ; 通过随机枚举非实体的跨度( us,ue), 可以构造负样本对集合{ (X,T-)}. 在实验中, 负样本对集合的大小为正样本集合大小的1.5倍. 对于每个样本对( X,T), 计算模型解码器输出的交叉熵损失, 以反向更新模型参数.
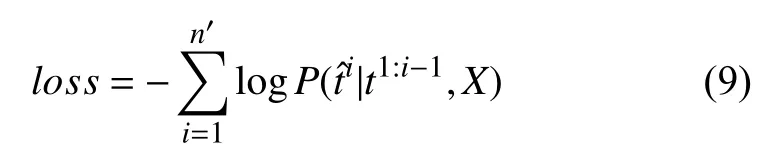
3 实验与分析
3.1 实验环境
实验的硬件环境: Intel® Core 7700, 内存8 GB. 软件环境: Ubuntu 16.04, Python 3.6.8, GPU采用Nvidia RTX-2080ti 11 GB, 深度学习框架采用PyTorch 1.4.0.代码开发环境选择PyCharm 2019.3.4.
3.2 数据集
本文重点关注中文电力领域, 采用国家电网真实工单数据与用户互动数据, 构建了电力领域命名实体识别数据集. 该数据集定义包括以下14种类型的实体:“机器设备、电价电费、业务需求、故障异常、财务票据、电子渠道、用户信息、文件法规、营销活动、身份、公司、违法行为、专业词汇”. 训练集, 验证集,测试集, 分别包含10 244、1 059、2 032条电力文本与对应的实体、类型标注.
3.3 评价指标
本文采用准确率(P)、召回率(R)以及F1 值(F1)作为模型性能的评价指标, 对测试集上的实体识别结果进行评估, 计算方式如下:
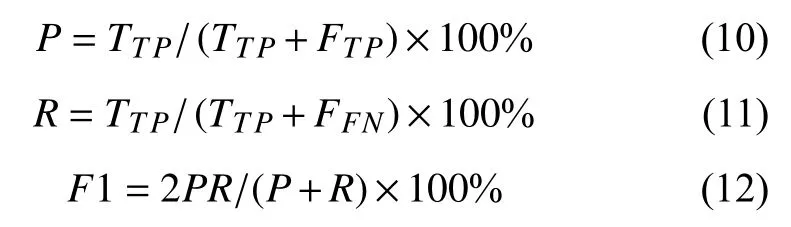
其中, TTP表示模型正确识别出的实体个数; FTP表示模型识别出的不相关实体个数; FFN表示实际为相关实体但模型识别错误的实体个数.
3.4 总体实验结果
本文对比的方法包括几种常用的NER模型: BiGRU、BiLSTM-CNN、BiLSTM-CRF、BiLSTM-CNN. 同时,本文也与开放领域上表现优异的预训练模型进行对比:BERT和BERT-BiLSTM-CRF.
实验结果如表2所示. 从中可以看出, 本文提出TP-NER模型在中文电力NER数据集上击败了所有的对比模型, 取得了最好的结果. 对比开放领域中表现优异的BERT-BiLSTM-CRF模型, TP-NER在F1指标上提升了2.17%, 这证明了本文提出的主题提示调优方法相比于传统序列标注方式, 在处理多实体类型的NER任务时更加有效.
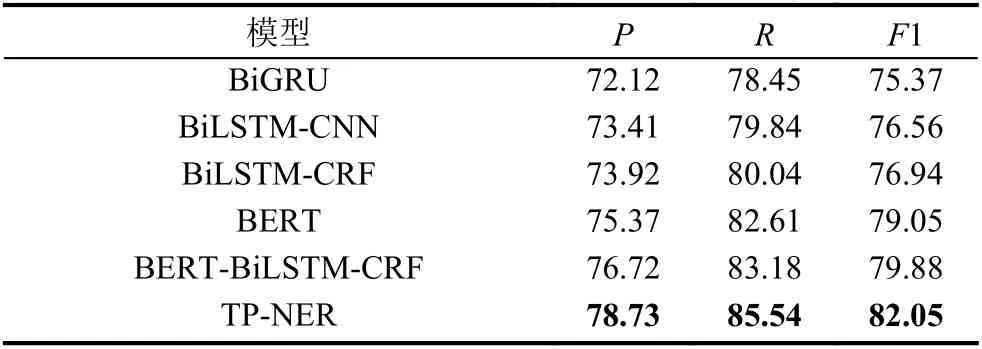
表2 电力命名实体识别总体结果(%)
3.5 消融实验
为了检验TP-NER 模型中的两个主要改进: 提示模板与LDA主题提示词各自的贡献, 我们针对如下两种模型设置进行了消融实验:
1)移除提示模板: 将提示模板移除, 仅使用BART对输入文本执行一般的序列标注以识别实体.
2)移除LDA提示词: 不使用LDA模型对提示模板进行扩充, 仅依赖实体跨度与实体类型构建候选提示句并进行排序.
消融实验结果如表3所示, 移除提示模板后, 模型F1下降了约3.5%, 而移除LDA提示词后, F1下降约1%, 这证明了这两个组件对模型均有贡献. 相比之下,提示模板带来的提升比LDA带来的提升更大, 因为它从根本上改变了NER的任务形式.
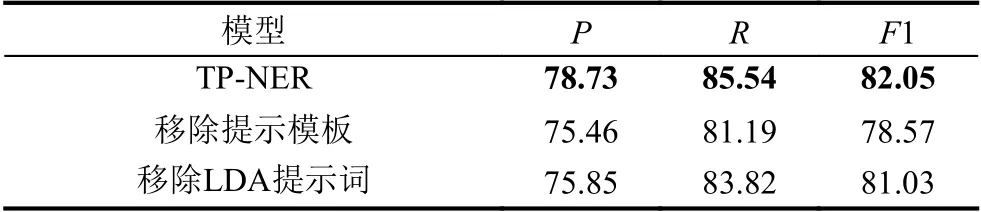
表3 消融实验结果(%)
3.6 少样本场景实验结果
为了探究TP-NER在少样本场景下的表现, 本文设计如下少样本场景, 对于每个实体类型, 分别从训练集中随机抽取{10, 20, 50, 100}个样本组成小样本训练集训练模型, 再统计模型在测试集上的F1分数.
实验结果如表4所示. 从中可以看出, 与使用全部训练集时相比, TP-NER在少样本场景下相对对比模型的优势更大. 并且, 训练样本越少, TP-NER的优势越明显. 同时可以发现, 在不同数量的训练样本, TP-NER整体模型始终比移除提示模板后效果更好. 这充分说明了提示模板对于整个模型的贡献. 值得注意的是, LDA提示词在样本数较少时提升更大.
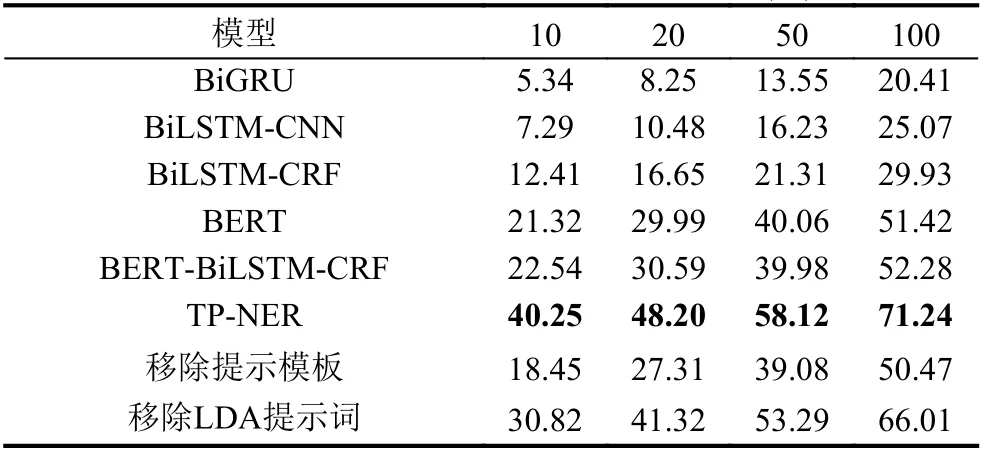
表4 少样本命名实体识别F1分数(%)
3.7 不同类型实验结果
为了探究TP-NER在不同实体类型下的表现, 本文对测试集上每个类型都统计了模型的F1分数.
实验结果如表5所示. 从中可以看出, TP-NER模型在大部分任务上都能取得比BERT-LSTM-CRF模型更好的效果, 尤其是在“文件法规”“公司”“营销活动”和“违法行为”这4种类型上提升最大. 造成这种显著提升的原因主要是, 在数据集中这些类型的标注样本较少, 平均不足100条, BERT-LSTM-CRF模型没有足够的训练数据对其参数进行微调, 以至于利用BERT的先验知识完成识别. 相反地, TP-NER将三元组输出的形式包装成自然语言形式, 使得PLM可以快速适配到电力NER任务上, 从而有效利用其知识. 在如“财务票据”“电子渠道”等类型上, TP-NER稍稍落后于BERT-LSTM-CRF, 这是因为这些类型的训练样本较多, 在这种训练资源丰富的场景中预训练模型微调与提示调优的差距不足以体现. 此外, 与“电价电费”“专业词汇”相比, “文件法规”“公司”“违法行为”这些类型的粒度更细, LDA收集到的主题词与类型有着紧密的语义联系. 例如“违法行为”包含“民事责任”“举报”等密切相关的主题词, 因此可以精准地提示PLM, 从而取得显著的提升.
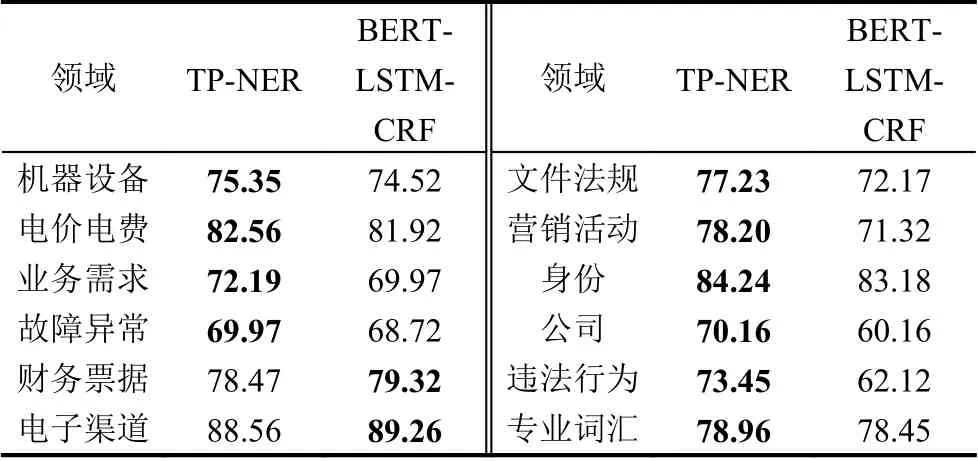
表5 各领域命名实体识别F1分数(%)
4 结束语
本文针对中文电力领域场景的少样本问题和多类型问题, 提出一种基于主题提示的中文电力领域命名实体识别方法. 与传统的BERT-LSTM-CRF框架不同,该方法提出了一种新的NER方式: 通过枚举实体跨度,实体类型, 主题词从而构造候选提示句. 这种方式可以有效利用预训练模型中潜在的知识, 从而克服少样本NER的挑战.
此外, 该模型还提出使用LDA模型从语料中抽取主题词, 作为提示以增强模型对于实体类型的感知, 从而缓解实体类型较多带来的挑战.
实验结果表明, 本文的方法在电力场景中取得了比传统方法更好的结果. 尤其在“营销活动”“公司”“业务需求”等类型的实体识别上, 本文方法的优势更为显著.
在未来工作中, 尝试使用基于神经网络的方法替代主题模型, 引入外部知识以尝试解决更加困难的零样本NER任务.
