基于链接器的RISC-V字加载指令优化①
2022-09-20乌鑫龙廖春玉
乌鑫龙, 廖春玉
1(中国科学院 软件研究所, 北京 100190)
2(北京师范大学珠海分校 计算机学院, 珠海 519087)
1 引言
由于RISC-V指令集架构具有开源、芯片设计友好、开发成本低等特点[1,2], 近年来被越来越多地运用于嵌入式设备中. 同时RISC-V指令集作为RISC的一员, 也会不可避免的存在一些精简指令集的弊端,RISC二进制程序体积偏大的问题就是其中之一. 因为RISC指令集只要求实现计算机硬件中最常用且数量有限的基础指令, 所以其中较复杂的操作只能通过基础指令的组合来实现. 因此在完成相同操作的情况下,相较于直接包含复杂操作指令的CISC来说, RISC程序往往需要执行更多条指令. 尤其是在内存大小受限的嵌入式设备中[3], 二进制程序体积偏大的问题更加突出[1].
本文第2节简要介绍了相关减小程序体积的部分方法以及研究, 并且简要介绍Zce子扩展对于指令优化的效果. 第3节介绍RISC-V架构以Zce子扩展的优化思路. 第4节详细解释了LSGP指令优化程序体积的方法. 最后基于LLD链接器实现了LSGP指令的优化并对优化效率进行分析.
2 相关研究
针对RISC程序体积偏大的问题, 目前主流方法之一就是在基础指令集以外额外支持一个“短指令集”.该指令集用更短的指令宽度编码基础指令集中最常用的指令从而二进制程序体积. 在ARM架构中就使用Thumb指令集缩减程序体积, MIPS架构则有MISP16指令集承担缩小程序体积的任务[3]. 得益于RISC-V指令集可扩展性高的特点, RISC-V当前也有C指令集子扩展被用于同样的目的.
除此之外, Halambi等人[3]还通过对MIPS指令建模, 使用启发式的方法来估算因为寄存器数量有限导致被分配的堆栈, 计算分析从而更细粒度地选择压缩指令. 在MISP 16压缩指令集的基础上更进一步的压缩了MIPS二进制程序的体积.
在嵌入式领域的基准测试中, RISC-V架构的二进制体积相较ARM架构增大了约11%, 即使在使用了C子扩展的情况下仍有较大差距[4]. 本文研究的RISC-V的Zce子扩展[4]与C子扩展同样被用来解决二进制程序体积偏大的问题. 但与C子扩展不相同的是, 该扩展除了通过缩减常用指令的长度以外, 还尝试替换频繁使用的固定指令组合从而缩减程序体积, 进一步增加了代码密度. 具体而言, 在C子扩展的基础上, Zce子扩展使得二进制体积比ARM架构小约1.75%. 本文对于Zce扩展中以LWGP为代表的指令进行研究, 基于LLD链接器实现该优化并且评估其优化效率.
3 RISC-V指令集扩展
RISC-V指令集由基础指令集和众多扩展指令集组成. 其中基础指令集包含了如整数加减和位运算以及分支跳转指令等, 如表1所示. 这些指令足以支撑一个简单的裸机程序或者操作系统的运行.

表1 基础指令集中常用的主要指令
除此之外, 基础指令集还为RISC-V指令集定义了x0-x31共32个通用寄存器. 每个寄存器都有其对应的用途. 如表2所示.
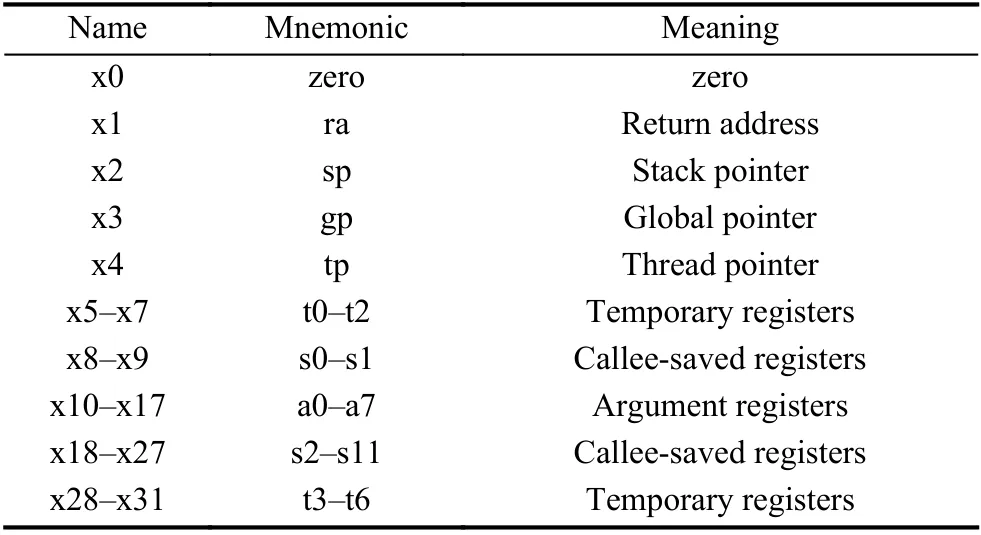
表2 通用寄存器使用规范
表2中, gp和tp寄存器则较为特殊, 它在程序执行的过程中被当作常量值使用.
3.1 Zce指令集扩展
与基础指令集不同, Zce扩展更多的是针对当前已有指令的压缩和优化问题. 它通过减少指令中某些情况下冗余操作数或者替换常用的固定指令组合来缩减单个指令的长度和指令条数.
以基础指令集中逻辑运算指令为例, 逻辑运算中只有与, 或和异或, 非运算则通过将源寄存器异或-1实现. 图1是XORI的指令格式

图1 XORI 指令格式
XORI指令将rs1寄存器中的数和立即数imm按位异或运算, 结果写入rd寄存器. 在非运算过程中较频繁的会出现rs1和rd使用同一个寄存器的情况, 因此Zce扩展尝试将这种情况下rs1和rd寄存器合并以节约编码点. Zce中将非运算(c.not)定义为如图2格式.

图2 c.not指令格式
c.not 指令合并rs1和rd寄存器为rsd, 同时因为约定立即数为-1所以删除了立即数. 将基础指令集实现的32位非运算指令XORI rd, rs1, -1缩减为16位的c.not指令.
Zce扩展中还有一部分指令用于压缩固定的指令组合. 例如push/pop指令. 在RISC-V汇编中, 函数的开始和末尾都需要保存和恢复堆栈指针和参数或返回值. Zce以使用push/pop指令一次性代替多条SW/LW指令的方式缩减指令条数.
LSGP指令缩减程序体积的方式也与之类似,LSGP指令仍为32 bit指令, 它通过提高硬件的复杂度,将两条指令合并为一条指令从而减小程序二进制体积.Zce中使用GP寄存器进行优化的指令共4条, 分别是LWGP、SWGP、LDGP、SDGP (下用LSGP指代全部4条指令). 其与基础指令集的Load/Store指令对应.其中, LDGP和SDGP仅被用于RISC-V 64位机器中加载双字长的数据.
4 LWGP指令优化原理
4.1 LW指令介绍
前面提到的RISC-V基础指令中还定义了字加载/存储指令, 分别是LW、SW、LD、SD (下多以LW指令为例), 它们被用来从给定地址加载字节数据. 其指令格式如图3所示. LW指令使用rs1的值为基地址,将rs1+offset处4个字节的数据加载到rd寄存器中.这就意味着在程序执行LW指令之前仍需使用额外指令将基地址加载到rs1寄存器中. 适用于这种情况的有两条指令, 分别是ADDI和LUI. 本文主要研究使用LUI指令加载基地址的情况.

图3 Load/Store指令格式
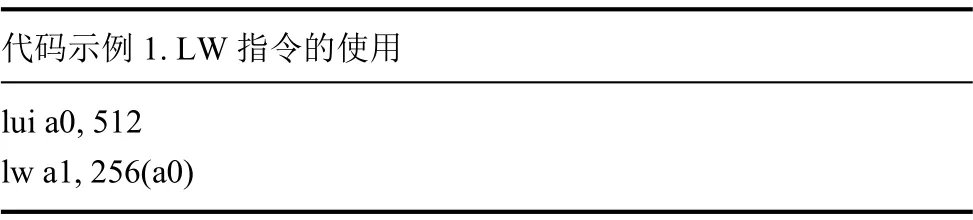
代码示例 1. LW指令的使用lui a0, 512 lw a1, 256(a0)
在代码示例1中, 两条指令一起被用来加载位于0x200100的数据. 由LUI现将该数据的高二十位地址加载进a0寄存器, 再由LW指令将位于此处的数据加载到a1中.
为了对这种情况进行优化, RISC-V引入了一个全局指针寄存器GP. 这个寄存器的值在链接过程中被确定并且在程序执行过程中保持不变. GP寄存器主要被用来优化程序中全局变量的访问, 所以在一般情况下,链接器会将GP指针指向ELF文件中.sdata小数据段+0X800的位置. 当某一个全局变量可以被以GP为基地址访问时. 链接器就会删除LW指令之前的LUI指令以缩减代码体积. 示意如图4.

图4 GP指针位置示意
但是由于LW指令中的偏移量的长度仅有12 bit,因此仅能访问到GP±2 KB范围内的全局变量. 对于超出该范围的全局变量, 就仍需要LUI指令通过其他寄存器传递基地址.
4.2 通过LWGP提高LW指令的访存能力
LW指令的主要问题是偏移量位宽不足以当前情况. 它只能访问基地址±2 KB范围内的变量. 所以需要较为频繁的使用LUI指令以重新加载新的基地址. 而LWGP正是通过增加长偏移量的位宽提高了其访存能力. LWGP指令格式如图5.

图5 LWGP指令格式
LWGP指令事先约定了使用GP寄存器作为基址寄存器, 如此可以将LW中基地址寄存器rs1对应的编码点分享给偏移量offset使用. 这样就可以使得偏移量的宽度从LW的12 bit扩展到了LWGP的16 bit, 从而使LWGP指令可以访问GP±32 KB范围内的全局变量. 基于同样的原理, LDGP和SDGP的访存能力更是扩大到了GP±64 KB的范围.
5 基于LLD的LSGP指令优化
正如上文所提到的, GP指针被用来优化全局变量的访问. 然而在程序链接之前, 全局变量的地址还尚未被确定. 因此当前生成的一些汇编指令需要使用标志符预先占位, 如 %hi (symbol) 代表符号symbol的高20位地址, 这些标志并不能被直接编码到二进制指令中, 所以编译器会使用重定位类型(如R_RISCV_LO12_I)标记这条指令, 表示这条指令还需要链接器做后续处理. 而具体的相应数据会在链接过程中被写入.
5.1 链接器松弛
在链接器松弛过程中, 链接器会从整个可执行程序的视角对于代码进行优化. 链接器会读取并解析文件中所有的重定位信息, 针对每一条重定位信息进行相应的优化处理, 链接器松弛的简要流程如图6所示.每条重定位信息的优化方式取决于该条信息的重定位类型, 不同的重定位类型对应着不同的函数方法. 本文的优化主要设涉及3种重定位类型, 分别是R_RISCV_HI20、R_RISCV_LO12_I和R_RISCV_LO12_S.

图6 链接器松弛简要流程
当LUI指令被用来加载一个全局变量的高20位地址时, 编译器会将该指令用R_RISCV_HI20标记. 同时, 该指令通常会和使用全局变量低12位的LW指令一起使用. 以本文研究涉及到的LW和LUI的指令为例, 编译器会给LW指令标记重定位类型R_RISCV_LO12_I.
在链接器的松弛阶段中, 链接器会不断重复扫描并尝试优化程序中每一条重定位信息, 直到全部的重定位信息都不能够再次被优化. 其中被用来加载全局变量的LUI和LW两条指令会被尝试优化成以GP寄存器为基地址寄存器的LW指令. 基于同样的逻辑, 本文主要讨论的LSGP也需要做相似的处理.

代码示例 2. LW指令使用的重定位类型lui a0, %hi (symbol) # R_RISCV_HI20 (symbol)lw a0, %lo (symbol) (a0) # R_RISCV_LO12_I (symbol)
由于LSGP指令格式与其他指令都不相同, 因此并不能被目前已经存在的重定位标记正确处理. 于是在这一阶段我们定义了新的重定位类型来指定LSGP指令的优化操作. 同时, 链接器中所有被用到的重定位类型都需要由psABI来定义. 但是由于Zce扩展仍处在实验阶段, psABI中没有定义相关的重定位类型, 因此出于实验测试目的, 作者针对LSGP临时定义了重定位标记用于指令的优化.
链接器松弛结束后, 每一条被重定位类型标记的指令会被按照这个重定位类型的要求计算地址, 并且填充到对应占位标志的地方.
5.2 链接器上LSGP优化的实现
本节中使用LLD链接器为例子进行讨论. 由于LLD主线针对于RISC-V链接器松弛的实现尚不完善,因此我们使用了一个上游正在review的补丁来完善相关功能. 在此基础上进行LSGP等指令的生成、优化以及评估工作. 同时, 为了能够单独评估LSGP的优化效率, 我们定义了一个-mzce-lsgp开关, 用来更直观地评估LSGP四条指令的优化效率.
编译器会为LUI和LW指令分别标记重定位类型R_RISCV_HI20和R_RISCV_LO12_I. 在初始阶段,链接器就会统一提取所有的重定位信息. 因此我们通过遍历重定位标记就可以找到需要被优化的指令. 但值得注意的是, LUI指令并不仅会和LW被一起使用.也会和例如ADDI等其他指令一同被用来加载绝对地址. 因此我们在判断LUI指令是否可以被优化的时候还需要提前读取并判断下一条指令是否属于字加载指令.
在此之后还需针对R_RISCV_LO12_*进行优化.为了避免造成额外的影响, 首先需要判断当前指令是否为LW/SW/LD/SD的其中之一, 之后计算当前指令使用的全局变量是否位于LSGP指令要求的地址范围内. 过程中要注意保存rd寄存器的值来确保优化前后的功能不会改变. 整体实现逻辑伪代码如示例代码3所示. 链接器在将LW修改成LWGP的过程中并不会对偏移量offset参数进行赋值, 它的值将会在链接器优化阶段结束后被统一调整.

代码示例 3. 优化LUI和LSGP指令1. for each rel in relocations 2. if rel.type is R_RISCV_HI20 and rel.inst is LUI 3. if rel.nextInst is one of (LW ro LD or SW or SD)4. if rel.inst.offset is in range of Uint16 and aligned by 4 b 5. Call removeInst(rel)6. else if rel.type is R_RISCV_LO12_I or R_RISCV_LO12_S 7. if rel.inst is LW 8. if rel.inst.offset is in range of Uint16 and aligned by 4 b 9. Call repleaseInstByLWGP(rel)10. rel.type = R_RISCV_LWGP 11. else if rel.inst is SW 12. if rel.inst.offset is in range of Uint16 and aligned by 4 b 13. Call repleaseInstBySWGP(rel)14. rel.type = R_RISCV_SWGP 15. else if rel.inst is LD 16. if rel.inst.offset is in range of Uint17 and aligned by 8 b 17. Call repleaseInstByLDGP(rel)18. rel.type = R_RISCV_LDGP 19. else if rel.inst is SD 20. if rel.inst.offset is in range of Uint17 and aligned by 8 b 21. Call repleaseInstBySDGP(rel)22. rel.type = R_RISCV_SDGP 23. end
链接器优化结束后, 意味着各个段的地址已经被最终确定. 编译器会分别为不同的重定位标记计算地址, 并按照相应的指令格式将偏移量写入指令. 同样因为LSGP四条指令的格式各不相同, 所以需要分别处理.
6 LSGP优化效率分析
为了分析LSGP指令对于程序的优化效果, 我们尝试使用上文中修改的LLD和Clang对RISC-V测试(riscv-test)代码的部分程序进行编译链接. 并对比分析使用LSGP指令前后反汇编代码数目.
6.1 LSGP缩减代码体积的比例
由于LSGP指令针对于全局变量进行访问, 我们从RISC-V test测试集合中选取了两个使用全局变量较为频繁的测试程序, 分别是用来测试整数加法的Dhrystone测试以及测试递归调用的towers测试, 此外还编译了Linux常用软件bash和vim进行测试. 测试过程中均以riscv32imac作为基准, 结果如图7所示.

图7 LSGP 缩减程序体积与数据段大小的关系
在Dhrystone测试程序中, 使用LSGP指令前后反汇编得出的指令条数分别为18 447和18 413条. .data和.sdata共计4 384字节. 有22个全局变量被访问, 共计184字节的全局数据通过LDGP/SDGP被访问. 优化前二进制大小286 216字节, 优化后二进制大小286 080字节. 二进制体积减少约0.047%. 对于towers测试程序, 由于相对使用全局变量较少且程序整体代码量较少. .data与.sdata总计1 880字节, 共计36字节全局数据通过LSGP被访问, 优化前二进制大小为10 152字节, 优化后为10 144字节. 二进制程序体积减少了0.07%.我们还尝试编译了目前常用的GNU软件vim和bash作为日常软件的代表. 与测试集合中刻意的测试代码不同, bash和vim程序体积减小的幅度小于Dhrystone和towers. Bash中.data与.sdata总计35 548字节中的148字节数据被通过LSGP指令访问. Vim中则共有782字节的数据被LSGP访问. 相较于使用LSGP加载数据之前, bash和vim二进制程序体积的缩减效率分别是0.007 6%和0.009 8%. 总体而言, 程序体积的缩减效率与程序数据段占比呈正相关.
表3中展示的优化效率看似较为低下, 其主要由于Zce扩展的优化空间所导致. Zce指令集的目的是在C压缩指令扩展的基础上进一步缩减程序体积.C扩展指令已经将RISC-V程序体积大幅度缩小. 尽管如此, 相较于ARM Cortex M4架构下的二进制程序,仍然有不到10%的体积差距[5]. 于是Zce子扩展则致力于进一步缩小这不到10%的差距. 这也就导致了Zce扩展的优化空间普遍较小, 从而优化效率相较于C指令集较低. 同时考虑到Zce扩展中其他单条指令的优化效率也都在0.02%-0.24%之间, 所以从这个角度来分析LSGP作为单条指令的优化效率也算合格.
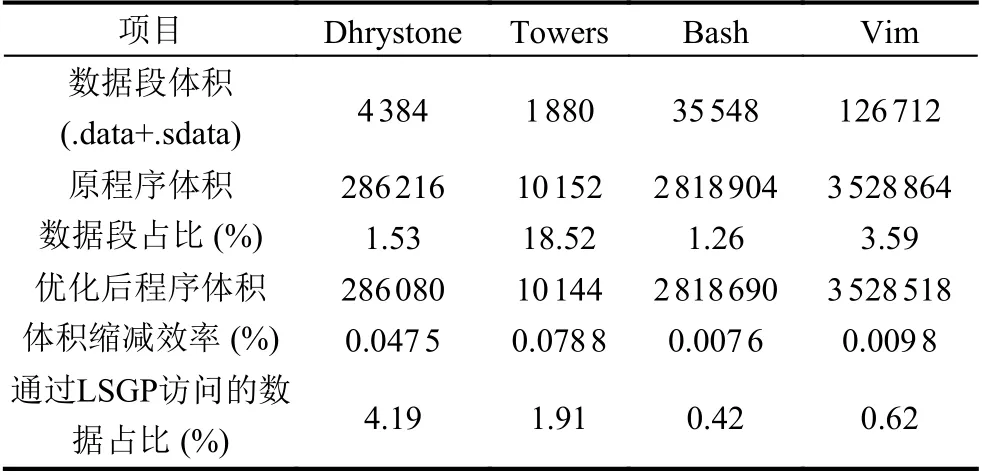
表3 LSGP缩减程序体积的效率
对于代码体积的优化问题, 本研究中主要针对于对全局变量的优化, 因此正如表3和图7所体现的, 一个程序中全局变量的数量或占比决定了LSGP优化的效率. 而程序中全局变量使用的数量一定程度上取决于程序的规模[6]和功能. 因此, 对于底层软件, 例如操作系统, 单片机程序等也会使用到较多全局变量的程序来说, LSGP缩减代码体积的效果同样是乐观的.
7 结论和展望
综上所述, 与LW等常规字加载指令相比, LSGP指令能够针对LW指令的部分使用场景进行优化, 通过约定基址寄存器的方式将寄存器的位宽分配给偏移量使用, 从而扩大指令的寻址范围. 本文在LLD链接器上实现这部分的优化并进行了评估. 对于RISC-V的部分标准测试程序来说, LSGP达到了较高的优化效率. 同时在日常通用软件中, LSGP对于程序体积的缩减也起到了一定的作用.
虽然前文描述了LWGP确实在一定程度上优化了代码体积. 但是优化效率相较于标准测试程序中的理想条件仍有一定差距. 可以通过改进以下问题进一步减小这个差距.
(1) LSGP指针的编码不合理.
(2) 部分LSGP的寻址能力被浪费.
(3) 局限于优化.sdata段而忽略了其他可以被优化的数据段.
psABI只考虑到LW指令的4K寻址能力. 因此将GP指针的值设置为.sdata+2K (0X800)的位置来确保尽可能大覆盖到.sdata节的数据. 但是对于LSGP指令达到64 KB的寻址能力来说, GP指令仍位于.sdata+2K (0X800)位置的话就意味着LSGP指令的寻址范围并不是从.sdata段开始. 所以最简单的办法本应是改变GP指针的位置, 但由于LSGP指令无法完全代替LW指令, 无法改变GP指针的位置. 基于此, 当前最好的解决办法就是尝试更改LSGP指令的格式, offset偏移量从带符号数改为无符号数, 从GP±32 KB变成GP±64 KB, 这样LW和LWGP搭配使用, 可以通过GP指针访问更大范围的全局变量.
又因为LSGP大部分的寻址范围覆盖到了除.sdata段以外的地址. 因此每个数据段之间的相对位置就变得相对重要. 如果相关的数据段排列在一起, 可以更大程度上避免LSGP寻址能力被浪费. 同时, .sdata段是小数据段, 其存储了数据长度小于某一阈值(通常小于8字节)的变量, 其余的全局变量会被存储到.data段. 这就导致程序中的.sdata段普遍较小, 甚至一部分程序根本不存在.sdata段. 目前链接器的实现(以LLD为例)仅基于.sdata段设置GP指针. 如果.sdata段不存在, 则GP指针就会被LLD忽略, 不只LSGP, 甚至对于LW的优化也会被无效化. 如果链接器在.sdata段不存在的情况下将GP指向.data段, 程序体积可以被进一步缩减.
8 结束语
本文通过介绍和分析LW指令的作用以及存在的问题, 阐述了LSGP指令的优势和特点. 将之实现到LLD链接器上并粗略评估了LSGP指令优化效率. 相较于现有的字加载指令, LSGP通过扩大偏移量立即数的位宽增大寻址范围的方式避免使用LUI指令加载高位地址, 从而缩减代码条数和程序体积的方式, 针对于使用GP寄存器作为基址的情况进行优化. 证明了LSGP指令存在一定的优化价值. 同时在整个过程中作者也发现了目前LSGP作为实验性指令存在的一些问题. 针对于这些问题提出了相应的解决方案. 我们已经将这些问题和建议反馈到RISC-V社区.
