基于聚类和新覆盖信息的模糊测试改进①
2022-09-20王化磊孙晓山
程 亮, 王化磊, 张 阳, 孙晓山
1(中国科学院大学, 北京 100049)
2(中国科学院 软件研究所 可信计算与信息保障实验室, 北京 100190)
1 引言
随着计算机和网络技术的发展, 软件与我们的生活和工作的关系越来越密切. 然而软件复杂的功能使得软件中不可避免地存在漏洞. 在模糊测试首次被提出的论文[1]中提到“常用系统中可能会潜伏着严重的漏洞”. 比如: 2010年披露的震网蠕虫漏洞[2]是第一种攻击工业控制系统的病毒; 2015年6月, 三星被爆出了高危的输入法漏洞. 该漏洞影响全球超过6亿的三星手机用户[3]. 2015年7月Android被爆出存在Stagefright高危漏洞, 约95%的安卓设备受到该漏洞影响[3].2020年8月, 研究人员发现CSP绕过漏洞(CVE-2020-6519[4]), 该漏洞使攻击者可以完全绕过Chrome 73版至83版的CSP规则, 数十亿的用户可能会受到影响.
软件安全一直是安全人员研究的重点, 当前主流的程序安全分析方法有: 污点分析、符号执行、代码审计和模糊测试等. 如何高效地发掘软件可能存在的漏洞一直是这些主流安全分析方法研究的重点.
污点分析技术[5]可以分为动态污点分析和静态污点分析, 静态污点在无法获取源代码时, 静态污点分析的精确性将会大大降低. 动态污点分析在运行时具有很大的开销, 难以实际分析规模较大的软件. 符号执行系统地探索许多可能的执行路径, 而不需要具体的输入, 通过抽象地将输入表示为符号, 利用约束求解器来构造可能满足条件的输入. 符号执行的缺点是处理像循环这样的语言结构时可能会成倍地增加执行状态的数量, 从而出现路径爆炸的问题[6-8]. 代码审计是一种对源代码的全面分析技术, 但是代码审计非常依赖安全人员自身的经验. 综上分析, 符号执行等方法虽然通过提取丰富的代码细节达到程序分析的功能, 但是由于其效率等方面的原因, 在程序安全性分析方面存在较多的局限. 模糊测试[9]通过随机变异种子或者基于规则生成种子对程序进行测试. 模糊测试通常分为白盒模糊测试、灰盒模糊测试和黑盒模糊测试[10-13]. 白盒模糊测试提取程序详细的运行时信息, 但是开销很大,总体效率很低. 黑盒模糊测试完全忽略了程序的内在信息, 虽然具有较快的运行速度, 但是准确性很低, 总体漏洞发现能力较弱. 而灰盒模糊测试兼顾了两者的优势, 通过静态代码插桩的方式获取程序运行时覆盖情况, 并用获得的信息指导种子变异方式, 以尽快扩大测试的覆盖率, 相较于其他方法能够更快地发现程序潜在的漏洞. 因此, 灰盒模糊测试已成为目前主流的模糊测试方法, 其中典型工具—AFL (American fuzzy loop)[14]已成为学术界和工业界进行模糊测试的事实标准工具, 我们的工作也基于AFL实现.
虽然灰盒模糊测试在发现漏洞方面具有一定的优势. 但是其采用的随机性算法具有极大的盲目性, 所以仍然存在进一步改进的空间.
现有的针对基于AFL灰盒模糊测试的改进工具将全部或过多的能量集中非确定性变异阶段, 加大了变异的盲目性, 使其难以求解复杂的条件约束;并且在种子能量分配阶段忽视了种子探索新分支的能力, 使得过多的能量消耗在没有价值的种子.
针对上述问题, 我们在模糊测试工具AFL 2.52b进行了改进, 通过对关键变异位置持续性变异和能量分配策略的优化, 提高模糊测试发现程序覆盖和程序潜在漏洞的能力, 我们的设计有以下几个特点:
1)提取有效变异位置. 在种子变异阶段, 首先对种子执行非确定性变异. 对于产生新覆盖的非确定性变异种子, 我们提取变异的组合位置并认为该组合位置中存在有效变异位置(我们定义变异后能够产生有效新覆盖的单一位置是有效变异位置), 再利用聚类算法确定组合变异中有效变异位置, 最后针对有效变异位置以及其后续位置进行持续的细粒度变异.
2)利用新覆盖信息评估种子. 对于每个发现新覆盖的种子, 保留新发现覆盖的信息. 在种子评分阶段,根据种子的新覆盖信息对种子进行评分.
3)提取程序静态信息. 模糊测试改进往往是在缺少程序信息的前提下进行的策略上的优化, 这种优化存在局限性; 而使用污点分析或者符号执行等方式提取程序信息的方法[15-18], 往往因为分析效率较低而影响模糊测试工具总体的效率. 因此我们提取了轻量级的程序静态信息, 在模糊测试阶段结合静态信息对种子的能量分配策略进行更加准确的计算.
我们在主流的模糊测试工具AFL的设计思路上完成了改进, 并实现了改进后的模糊测试工具AgileFuzz经过实验验证, AgileFuzz能够在相同的时间内发现更多的程序分支覆盖, 并且能够挖掘到新的程序漏洞.
2 背景
本节主要以AFL为例介绍典型灰盒模糊测试的工作流程以及路径统计方式.
2.1 AFL工作流程
AFL主函数是一个条件为true的while循环, 只有用户主动停止模糊测试工作, 测试才会结束. AFL的工作流程如图1所示, 核心步骤如下: 1)待测目标程序和程序的输入文件作为AFL启动时的原始输入, 初始输入经过运行后会加入种子库中参与后续的模糊测试. 2) AFL每次执行测试, 都会从种子队列中选择1个种子, 根据该种子的执行时间、种子大小、路径覆盖数量、执行次数等进行种子评分, 评分越高的种子在非确定性变异阶段会进行更多次的变异. 并且, AFL根据路径不同保存了很多种子, 但是AFL会将单一分支执行最快的种子标记为favored, 在种子被选择后, 不是favored标记的种子会以较大的概率跳过执行. 3)种子经过变异后, 得到的新种子作为待测程序的输入,AFL监视每个种子执行过程中程序是否发生崩溃, 如果待测程序发生崩溃, 则种子被保存在crash种子队列. 4) AFL还记录每个种子在程序执行过程中的路径覆盖情况, 如果产生新的覆盖则将种子加入正常样本队列, 然后参与后续的模糊测试工作.
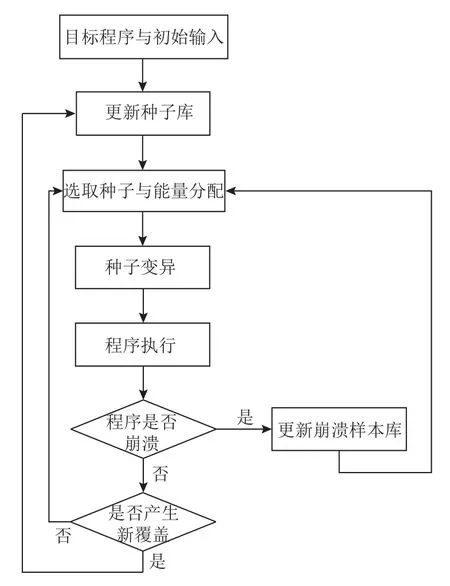
图1 AFL工作流程图
2.2 AFL路径统计方式
AFL通过插桩方式获取程序运行时的执行路径信息. 对于有源码的程序, AFL在编译程序时将插桩代码插入程序的每个基本块中, 具体流程如下: AFL在每个基本块入口处插入0-65535范围的随机数以及特定功能的函数afl_maybe_log;如果程序执行了该基本块,afl_maybe_log函数会将插入基本块的随机数与前一个执行的基本块的随机数进行异或操作, 运算的结果作为覆盖信息写入共享内存. 共享内存是一块64 KB的内存空间, 可以统计65 536条分支转移信息, AFL不仅记录分支转移是否发生, 还会记录分支转移执行的次数, 因为同一个分支转移, 可能因为不同的执行次数出现不用的程序状态. 对于没有源码的程序, AFL使用运行时插桩技术统计程序执行路径, 插桩的逻辑与静态插桩方式相同.
3 方案设计
如图2所示, 其中实线方框为AFL的标准功能模块, 使用虚线方框的部分是我们增加或改进的模块, 主要包括3个部分: 第1部分是对模糊测试变异策略的改进, 第2部分是利用聚类算法确定关键变异位置, 第3部分是结合静态分析和新覆盖信息的种子评分策略调整.
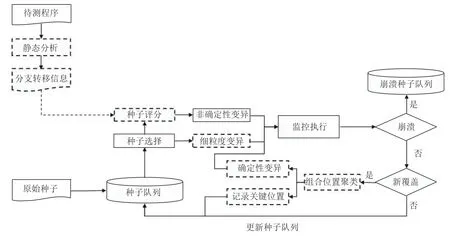
图2 改进后的模糊测试工作流程
3.1 变异策略改进
AFL在种子变异阶段分为确定性变异和非确定性变异. 每个被选中的种子都会执行一次确定性变异, 在确定性变异阶段会对种子进行比特位粒度的变异, 所以在确定性变异阶段十分耗时. 事实上, 种子的很多位置都是无效的变异位置, 即无论进行何种变异都无法产生新的覆盖. MOPT和EcoFuzz考虑到确定性变异耗时, 所以选择直接跳过了确定性变异, 但是只通过非确定性变异, 将会使得模糊测试变异更加盲目和随机.
(1) 确定种子关键变异位置. 在调整后的变异策略中, 种子变异阶段只对种子的部分关键位置进行确定性变异. 核心步骤是确定种子的关键位置. 具体来说,当选中一个种子后, 首先进行非确定性变异, 如果非确定性变异生成的种子访问了新的分支覆盖, 并不会在保存种子后直接进行下一次变异操作, 而是分析产生该种子的变异过程. 通过分析, 可以确定组合变异位置中有效的变异位置, 而有效的变异位置将会记作新种子的关键位置.
(2) 选择性确定性变异. 在确定关键位置w后, 变异前的种子和变异后的种子会针对关键位置进行不同的变异操作. 对变异前的种子的w位置进行与AFL相同的确定性变异, 对于记录关键位置的新种子, 如果关键位置的字段长度小于m个字节, 那么当该种子被选中进行变异时, 首先对该关键位置的后续n个位置进行更加细粒度的确定性变异, 与AFL原有的确定性变异不同, 细粒度的确定性变异会将选中的位置(字节)变异成所有可能的结果. 经过多次实验测试, m和n的值取2时, 总体效果较好.
3.2 聚类确定关键变异位置
关键位置的长度直接影响变异的效率. 如果将产生新覆盖的种子变异过程中的所有组合变异位置都看作关键位置, 然后对这些进行确定性变异, 仍然存在较多的无效变异.
为了缩小关键位置的长度, 使用聚类算法对离散的组合变异位置进行聚类. 在文件结构中, 字段是连续的一段内容, 所以在一个文件中, 距离越近的位置越可能属于同一字段. 如图3所示, 文件A的组合变异M个位置(其中包括蓝色标记和红色位置标记的位置,而且红色位置为关键变异位置)得到的种子B访问了新的覆盖, 对种子B变异的位置进行聚类操作-将离散的变异位置聚类为N个字段, 根据N个字段生成N个新的种子, 每个新种子只有对应字段的内容与原文件不同. 如果种子Ni访问了新的覆盖, 那么Ni种子对应的变异字段就是关键的变异字段.
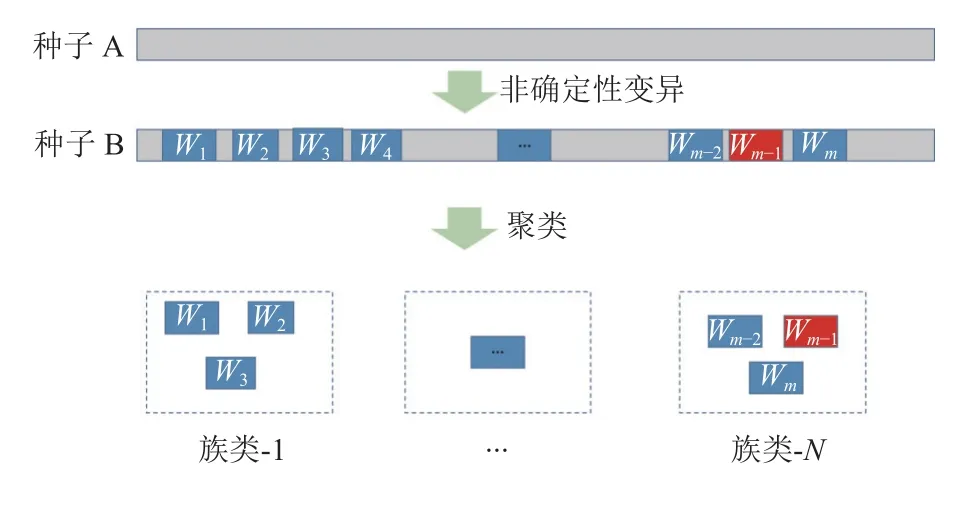
图3 对组合变异位置进行聚类
为了完成变异位置聚类, 我们使用Meanshift算法.使用该算法的原因有两点: 1)该算法是基于密度的聚类算法, 2)聚类之前不需要指定类的数量. Meanshift算法的核心思想是通过不断移动样本点, 使其向密度更大的区域移动, 直到满足某一条件, 此时该点就是样本点的收敛点, 收敛到同一点则被认为属于同一族类.对于变异位置p, 其偏移向量计算方式如式(1)所示,其中, pi表示所有变异位置点集中到p点距离小于l的所有点.
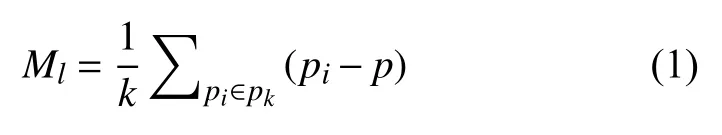
聚类算法具体步骤如下:
1)随机选择未被分类的变异位置, 作为中心点P.
2)找出离中心点P距离L范围的所有变异点, 这些点记作集合M.
3)计算中心点P与集合M中所有点的向量, 将这些向量相加得到偏移向量M.
4)将中心点P加上向量M得到新的中心点.
5)重复步骤2)-4), 直到偏移向量满足设定的阈值,保存此时的中心点.
6)重复步骤1)-5)直到所有点都完成分类.
7)根据每个类, 对每个点的访问频率, 取访问频率最大的那个类, 作为当前点集的所属类.

算法1. 基于聚类的确定性变异优化方法输入: 非确定性变异后产生新覆盖的种子seed_son和变异前的种子seed输出: 确定性变异产生的新覆盖的种子1 diff_points=get_diff_point(seed, seed_son)2 cluster_points=cluster(diff_ponts)3 for cluster in cluster_points:4 seed_single_cluster=generate_seed_by_cluster(cluster):5 if(is_new_path(seed_single)):6 seeds_deter=deter_variate(cluster, seed):7 while seed_deter in seeds_deter:8 fuzzy_run(seed_deter)9 end while 10 end if 11 end for
3.3 新覆盖与静态分析进行种子评分
在AFL的种子评分中, 会根据种子的总分支覆盖数量进行能量分配, 这种方式导致能量分配不合理. 我们调整种子评分策略, 将种子新发现的分支数量作为评分依据. 并且我们对待测二进制程序进行静态分析,提取基本块转移信息. 这样做的目的是因为并不是每个分支转移都存在潜在未发现的分支转移.
如图4所示, 对于每个基本块转移, 如: branch 1,我们记录通过该分支转移到达基本块后, 可能存在的后续基本块转移, 即对于branch 1, 我们记录branch 1-1和branch 1-2的信息, 我们把branch 1-1和branch 1-2记作分支branch 1的子分支转移. 注意的是, 虽然基本块是连续指令的集合, 但是branch 1-1或branch 1-2可能并不同时存在或都不存在. 这种情况发生在某基本块子节点的父节点超过一个时, 其子节点即使只有一个, 但是仍然是一个独立的基本块. 通过静态分析, 我们可以得到每个基本块转移的子分支转移, 如果某个分支的子分支转移数量为2, 我们认为该分支转移对发现新覆盖是有价值的, 将会对种子评分产生增益效果.
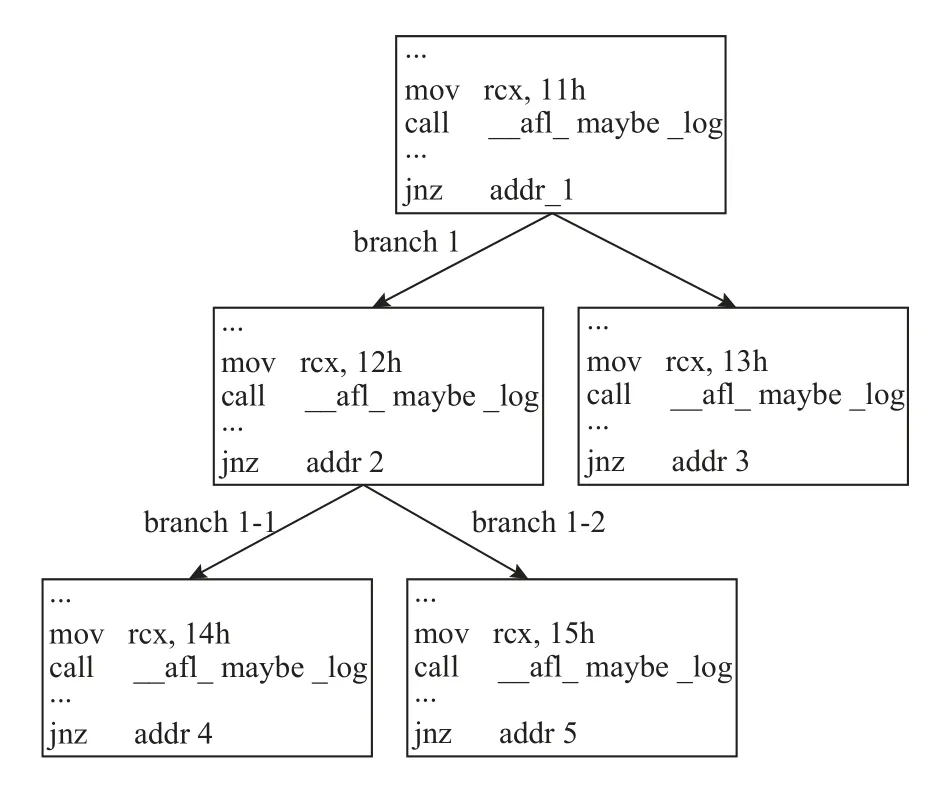
图4 基本块转移示意图
所以在种子评分阶段, 具体步骤如下:
1) 对于待测程序, 通过静态分析获取每个基本块转移的子分支转移信息, 保存在文件中, 在启动模糊测试测试时, 该文件作为分支附加信息提供.
2) 对于每个新加入队列的种子, 比较其分支覆盖与总分支覆盖的差异, 得到新发现的分支覆盖数量和具体分支编号.
3) 在种子评分阶段, 计算种子分支覆盖中是新覆盖且对应分支有两个子分支的数量, 记作value_branch_num.
4) 种子A的评分使用式(2)进行计算, 使用log函数是为了避免分支覆盖数量对种子能量进行成倍的增益, 并且经过多次实验验证, ln函数作为计算种子能量总体实验效果较好. 根据公式可知, 当种子的新覆盖数量为0时, 最低能量值为1.
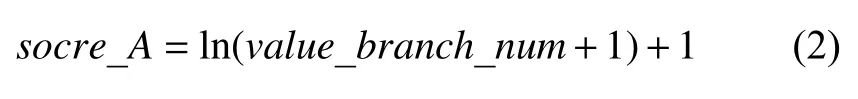
4 实验评估
我们在AFL 2.52b的基础上实现了改进策略, 得到了改进后的模糊测试工具AgileFuzz. 我们的评估主要回答下面4个问题:
1) 产生新覆盖的非确定性变异的组合位置中是否存在关键位置? 如果存在, 存在的比例是多少? 对关键位置进行确定性变异, 是否能够发现新的覆盖?
2) 与非确定性变异相比, 对聚类得到关键位置进行细粒度持续变异如何能够更快地发现新覆盖?
3) AgileFuzz在实际程序中发现程序覆盖的能力与现有的模糊测试改进工具对比如何?
4) AgileFuzz是否能够发现真实程序程序中的漏洞?
4.1 “关键位置”分析与统计
非确定性变异阶段对种子的随机组合位置进行变异, 变异后的种子产生新覆盖可能有两个原因: 1)组合变异产生新覆盖, 单一位置变异并不能产生; 2)组合变异中, 变异了“关键位置”, 而且即使只变异该位置, 也可以产生新覆盖. 其中, 我们称这种“关键位置”为单一有效变异位置. 我们统计在模糊测试过程中, 产生新覆盖的非确定性变异包括多少“关键位置”以及针对“关键位置”变异仍然能够产生新覆盖的数量. 实验测试选择libxml2 (xmllint)、binutils (readelf)和harfbuzz(test)这3组程序, 这3组程序常用作模糊测试工具的测评, 比较具有代表性. 在相同的实验环境下, 对3个程序进行3组重复性实验, 每组实验进行72 h, 最终取平均结果. 统计结果如表1所示, 从结果中可以看出, 产生新覆盖的非确定性变异次数中, 具有“关键位置”的非确定性变异比例较高(分别为59%、45%和36%), 并且90%以上的“关键位置”经过确定性变异后仍然能够产生新覆盖.
4.2 新覆盖发现效率的分析
在本小节, 我们解释为什么针对“关键位置”进行细粒度变异相比非确定性变异能够更快地发现新覆盖.我们以libxml2的xmllint程序为例, 将我们的模糊测试工具AgileFuzz与AFL 2.52b、关闭确定性变异的AFL 2.52b -d以及关闭确定性变异的模糊测试改进工具EcoFuzz进行24 h实验比较, 覆盖率对比结果如图5所示, 图中可以看出AgileFuzz在相同的时间内发现了更多的路径. 我们将对这一实验结果进行详细的分析,并展示我们的模糊测试工具的优势.
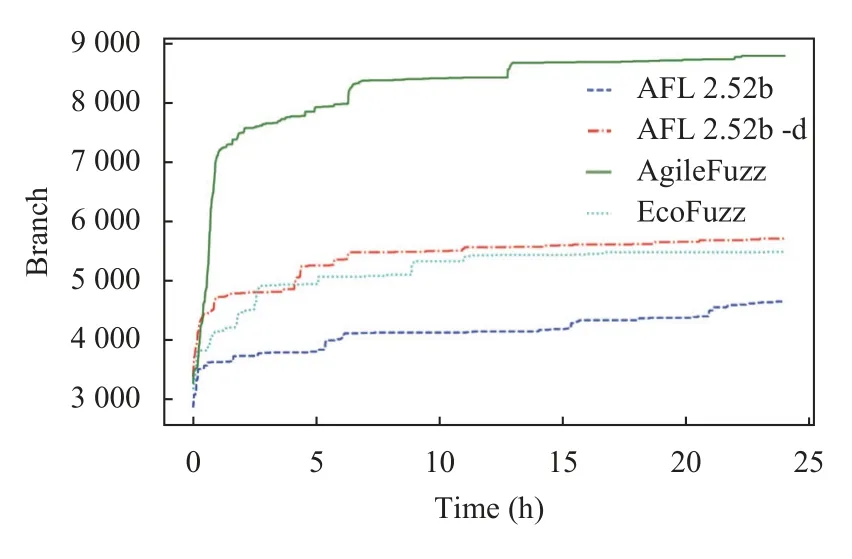
图5 xmllint程序覆盖率对比
为了分析覆盖率差异, 我们使用afl-cov[19]分析4个模糊测试工具所发现的程序覆盖的差异. 分析结果显示, AgileFuzz不仅发现了EcoFuzz等工具所发现的全部程序代码, 还发现了更多的难以发现的程序代码.其中hash.c文件的代码, AgileFuzz覆盖率为56.3%,而EcoFuzz等工具为0%, 这是导致程序覆盖率出现较大差异的主要原因. 我们进一步分析产生现象的原因,通过程序分析发现如图6所示的调用序列以及条件判断. 这里简单介绍一下CMP9函数, 这是xmllint实现的定长字符串匹配宏定义, 与C语言自带的strcmp函数不同的是, “<”和“
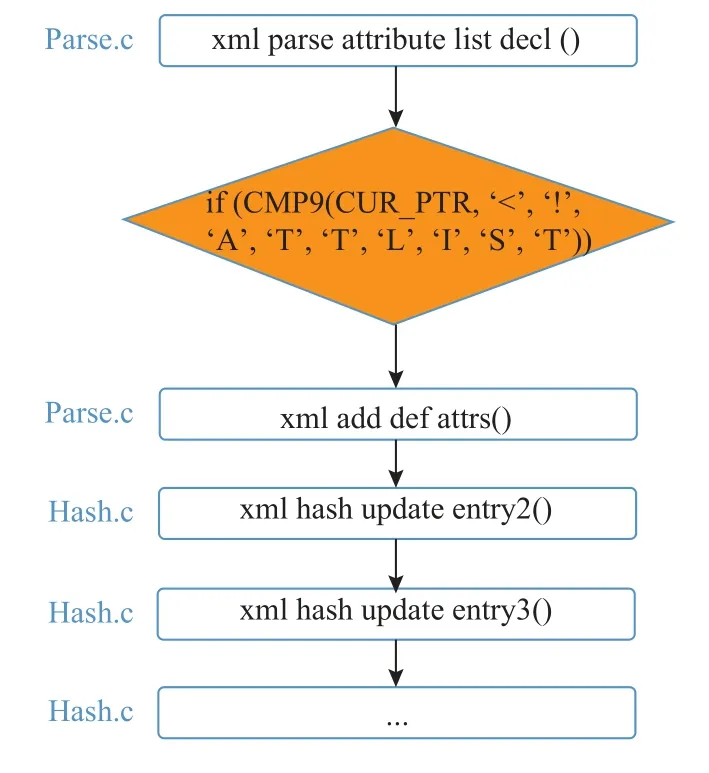
图6 xmllint程序hash.c调用依赖
EcoFuzz通过24 h的变异无法产生满足条件约束的字符串-“
AgileFuzz在通过非确定性变异产生了包含字符串“<**”种子时, 触发了cmp9函数新的覆盖, 此时AgileFuzz利用聚类算法确定单一有效变异位置, 确定新覆盖是由于变异了“<”字符所在的位置. 保存的新种子记录了关键位置, 能够对关键位置的后继位置进行持续性的细粒度变异, 从而保证了产生“
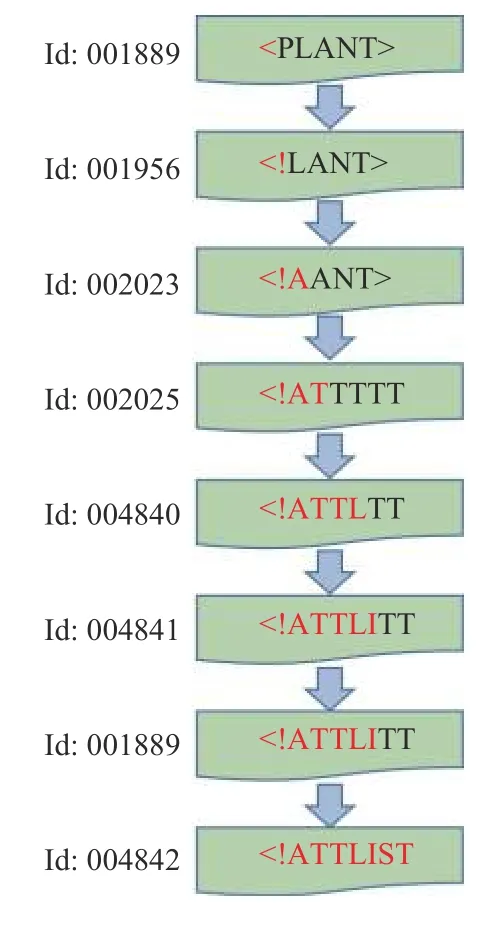
图7 种子变异过程
4.3 程序覆盖率对比
为了验证我们改进的模糊测试工具AgileFuzz在通用程序上的测试效果, 我们与近年来效果比较好的Eco-Fuzz、AFLFast以及原始的AFL 2.52b进行了实验, 实验以覆盖率作为对比指标, 选择了libxml2、binutils等常用的程序作为测试对象. 在相同的硬件和软件环境中进行了3次实验, 每次实验的时间为72 h, 3次实验的覆盖率的平均值作为实验结果, 然后计算覆盖率对比图, 如图8所示. 通过实验对比可以看出, AgileFuzz能够更快地发现程序的覆盖, 并且在不同的程序中效果较为稳定.
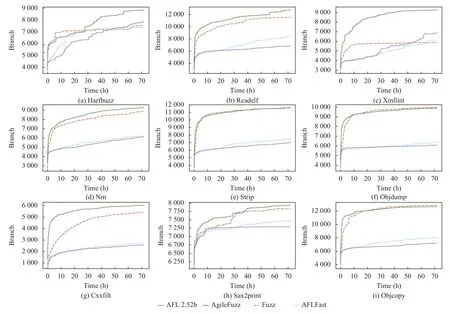
图8 多个程序72 h的覆盖率比较
4.4 漏洞挖掘能力
如表2所示, 为体现工具的普适性, 我们使用Agile-Fuzz对字体解析、html解析等多种类型的程序进行漏洞挖掘工作, 如: fontforge、harfbuzz、htmlcss、ffjpeg等软件, 在挖掘工作中发现了大量的未知漏洞, 经过分析确定了漏洞类型, 并将漏洞崩溃样本以及漏洞分析结果反馈给作者. 通过在实际程序中发现的未知漏洞,证明了AgileFuzz具有发现实际程序漏洞的能力.

表2 程序漏洞挖掘结果统计
5 相关工作
国际很多研究工作都针对AFL进行了改进. 这些针对AFL的改进主要在种子变异、能量分配方面进行了改进[20-23], 在确定性变异改进方面, FairFuzz[21]根据是否包括稀有分支跳过部分确定性变异, MOPT[22]详细分析了确定性变异效率低对变异的影响, 并只保留了极少数的确定性变异, EcoFuzz[19]直接跳过了所有的确定性变异. 在种子评分改进方面, AFLFast[20]使用马尔科夫链对种子能量分配进行建模, 被选次数更多的和被执行次数较少的种子分配的能量较高. EcoFuzz[19]使用多臂老虎机对模糊测试进行更准确的建模以完成能量分配. 但是这些模糊测试改进存在以下两个问题:
1)变异更加盲目和随机. 这些模糊测试工具认为确定性变异效率较低, 采取的策略是直接跳过全部或大部分确定性变异, 但是只保留非确定性变异的模糊测试在对种子进行变异时更加盲目和随机, 无法对产生新覆盖的变异位置进行持续的变异.
2)忽视了种子产生的新分支覆盖数量对模糊测试的影响. 种子评分阶段根据种子大小、种子运行速度和种子总分支覆盖数量对种子进行评分, 但是总分支覆盖数量越多的种子新发现的分支覆盖数量并不一定越多, 所以新分支数量多的种子评分可能很低, 这导致模糊测试将大量的能量消耗在已经经过多次变异的分支覆盖, 发现新覆盖的能力受到限制, 并且作为影响种子评分的分支信息缺少程序的静态分析.
6 结束语
模糊测试是一种高效的漏洞挖掘工具, 能够发现程序真实的漏洞. 本文设计了一种基于聚类算法和新覆盖的模糊测试改进工具, 能够针对单一有效位置进行持续性细粒度变异, 并且利用待测程序的静态分析结果与新覆盖信息结合对种子评分进行调整, 使得更多的能量分配给新分支, 降低了变异的盲目性. 总体来看, 我们的改进取得了较好的效果.模糊测试仍然存在很多的工作需要进一步研究, 在将来的工作中, 我们将研究如何针对程序的长字符串和整数匹配进行拆分,提高针对关键位置进行细粒度变异的适用性和效率.
