语义增强的多策略政策术语抽取系统①
2022-09-20曹秀娟马志柔张庆文
曹秀娟, 马志柔, 朱 涛, 张庆文, 杨 燕, 叶 丹
1(广西大学 计算机与电子信息学院, 南宁 530004)
2(中国科学院 软件研究所 软件工程技术研究开发中心, 北京 100190)
3(政和科技股份有限公司, 济南 250000)
政策文本是用来记录政策活动而产生的过程性文件, 是政策服务研究的重要载体和依据, 包括通知、公告、意见、批复等公文类别. 目前, 政府与企业之间在政策服务上存在着一定的壁垒, 一方面企业无法及时解读相关政策, 不能及时享受政府补贴; 另一方面, 政府无法及时了解政策发布的受益面及其所发挥的作用,而政策文本分析在政策解读、政企协同、企业决策和成果转化等政策服务方面具有非常重要的现实意义.由于政策术语新词的大量出现, 使得政策领域的分词不准确, 严重影响了对政策文本的解读[1], 政策术语抽取成为了解决这一难题的当务之急. 政策术语具有时效性、低频度、稀疏性和复合短语的特点, 难以用频繁模式和序列标注的方法直接抽取, 多由领域专家手工抽取.
为了实现半自动化的政策术语抽取, 本文设计了语义增强的多策略政策术语抽取系统, 该系统融合频数、自由度、凝固度等多种策略, 获得包含政策结构信息的术语新词; 并利用预训练语言模型增强语义相似度匹配来召回包含政策语义信息的术语新词, 结合两者信息来生成政策术语词库并可对其迭代更新, 切实解决了人工抽取政策术语的困难.
1 相关工作
随着大数据和人工智能时代的到来, 自动术语抽取技术作为实现领域术语抽取系统的关键技术, 受到了广泛的关注和研究. 解决自动术语抽取的主流方法主要有3大类: 基于语言学方法、基于统计学方法、基于深度学习方法.
1.1 基于语言学方法的术语抽取
基于语言学方法的术语抽取根据领域术语的语言特征规则, 或与词典中的术语相匹配. 首先将文本进行分词和词性标注, 然后对比分词结果和词法规则, 匹配一致的内容为候选术语. 研究者主要通过对行业领域术语的构词模式进行分析, 实现不同领域的术语抽取.曾浩等人[2]制定了4条扩展规则并结合统计特征进行术语抽取. 赵志滨等人[3]运用句法分析和词向量技术对新词发现进行研究, 在护肤品论坛的真实文本数据集上取得了较好的效果. Kafando等人[4]结合统计特征和语言学定性定量规则分析, 利用BioTex工具抽取生物医学领域组合术语. 基于语言学方法的术语抽取需要领域专家的知识背景进行支撑及维护, 无法完成领域迁移.
1.2 基于统计学方法的术语抽取
基于统计学方法的术语抽取主要采用N-Gram统计语言模型建模, 结合扩展统计特征对术语进行抽取.常见的统计特征主要有词频数(TF)、凝固度(PMI)、自由度(DF)和C-value等. 目前应用统计学方法进行术语抽取具有较多工作. Chen等人[5]为有效地确定专利领域新词的边界, 引入二元词的双向条件概率信息,提取专利领域长词. 王煜等人[6]利用改进的频繁模式树算法, 结合DF、PMI和时间特征, 对网络新闻热点新词进行了有效识别. Li等人[7]改进PMI并结合DF特征自动抽取未登录词. 陈先来等人[8]采用融入逻辑回归的凝固度模型提取新词, 有效地提高了电子病历文本数据分词准确率. 基于统计学方法的术语抽取能抽取到高频且高质量的术语, 无法抽取低频且稀疏的术语.
1.3 基于深度学习方法的术语抽取
随着机器学习尤其是深度学习的发展, 推动术语抽取研究产生了各类模型和方法的领域应用. Chen等人[9]采用统计特征提取候选术语, 利用CNN模型生成消费品缺陷领域词典. 基于术语语义相关性的思想, 张一帆等人[10]使用TextRank抽取领域种子词典, 而后计算候选术语与种子集的余弦相似度进行术语抽取.Qian等人[11]使用包含词语信息的Word2Vec词向量对N-Gram频繁字符串候选词组进行剪枝, 无监督地进行术语抽取, 但其并未考虑中文词语的一词多义问题. 张乐等人[12]提出将汉字笔画知识和知网中的义原知识引入Word2Vec词向量训练, 从而获得多语义词向量, 但其针对社交媒体领域. 近年来, 预训练语言模型BERT提出后, 在术语抽取上得到了广泛应用, Choi等人[13]将统计特征TF-IDF与FastText和BERT模型结合, 实现了韩文语料的自动术语抽取.
上述研究表明, 单一的方法均无法达到最佳的术语抽取效果, 基于统计学方法抽取的候选术语仍需进行停用词过滤和对应领域的语言规则过滤, 基于深度学习的方法需要海量的标注数据来训练模型, 对分布稀疏的政策术语来说, 难以达到抽取效果. 因此, 本文考虑引入预训练语言模型来增强语义, 并融合多策略频繁模式来提高政策术语抽取效果, 实现政策术语的半自动化抽取.
2 关键技术研究
政策术语抽取系统的半自动化实现, 其关键技术是如何利用人工智能和自然语言处理技术, 尝试将自动术语抽取与语义知识相结合, 高效地构建政策领域术语词典, 有效提升政策术语抽取的效果.
通常政策文本术语抽取示例如表1所示.
由表1可知, 政策术语有如下的特点: 1) 复合短语: 由多个词语嵌套、复合、派生组成的固定短语;2) 词性分布: 多为名词性短语或动名词性短语; 3) 长度分布: 长度分布于4至15字词之间; 4) 低频度: 出现的频次普遍不高; 5) 时效性: 政策术语随着时间的推移会不断更新.

表1 政策文本术语抽取示例
针对低频且稀疏的政策术语抽取难的问题, 本文提出了一种零样本语义增强的多策略政策术语抽取方法来实现系统, 包括多策略频繁模式抽取算法和语义增强抽取算法.
2.1 多策略频繁模式抽取算法
肖仰华等人[14]指出衡量一个术语的质量, 主要考虑4个方面: 高频率、一致性、信息量和完整性. 高频率主要指术语应该在给定文档中出现足够频繁; 一致性是指术语和不同词之间的搭配是否合理或是否常见;信息量主要考虑术语传达的信息, 其应当表达一定的主题或者概念; 完整性主要指术语在特定上下文中是一个完整的语义单元. 凝固度衡量文本片段中字与字之间的紧密程度, 即术语的一致性; 自由度衡量一个文本片段左右两侧字符组合的丰富度, 即术语的完整性;C-value衡量候选短语质量即术语的信息量, 通过有效校正父子嵌套短语重复统计带来的频次估计的偏差,提取多词嵌套的长政策术语.
为了抽取政策文本中内部凝结紧且外部组合自由度高的政策术语, 设计了一种多策略频繁模式抽取算法. 该算法以N-Gram统计语言模型为基础, 采用综合词频、自由度、凝固度和C-value特征各自优势的指标FPDC来衡量术语, 结合停用词和常用词前后缀搭配规则过滤术语. 算法步骤如下:
Step 1. 文本预处理. 对文本进行预处理, 删除政策文本中的邮箱、电话号码、手机号码、日期、网址等,置换标点符号为空格.
Step 2. 候选短语生成. 基于N-Gram统计语言模型对文本语料进行统计, 过滤词长阈值以下的文本片段, 得到候选文本片段.
Step 3. 术语质量评分. 首先对各候选文本片段计算词频tf、凝固度pmi、自由度df和C-value值cval,然后对各特征进行Sigmoid函数归一化, 最后融合各特征值计算指标FPDC, 初始化为每个特征平均分配权重, 考虑到政策领域多词嵌套的中心词, 对词频进行了0.15的惩罚, 对C-value进行了0.15的奖励, 如式(1)所示. 根据阈值筛选, 得到候选政策术语.
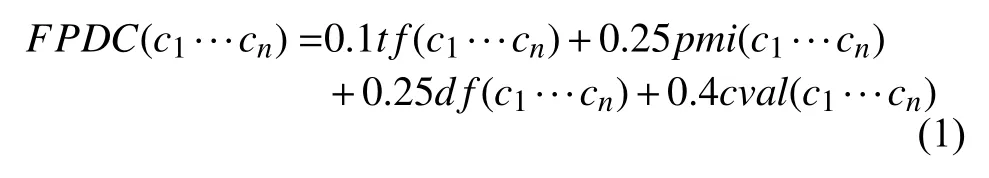
其中, c1···cn表示多个字构成的候选文本片段.
Step 4. 语言规则过滤. 对候选政策术语进行停用词过滤和常用词作为前后缀的语言学规则过滤.
Step 5. 结果排序输出. 按照FPDC指标由高到低排序, 输出政策术语抽取结果.
2.2 语义增强抽取算法
在零样本无监督挖掘情况下, 多策略算法可以抽取到大量频繁、高质量的政策术语, 但针对低频、稀疏的政策术语抽取效果仍不够好. 引入预训练语言模型来增强政策领域术语语义特征匹配, 在多策略算法的基础上, 设计了语义增强抽取算法来召回低频术语新词. 语义增强抽取算法流程如下所示:
Step 1. 候选术语生成. 将现有词库中的政策术语ngrams_dict和文本语料特征词集合ngrams_fw特征词计算归一化的C-value指标, 更新父子嵌套类型术语的FPDC值, 将其作为Jieba分词的自定义词典, 对原始语料重新分词, 过滤不符合词长和词语频数要求的文本片段作为候选术语.
Step 2. 语义向量生成. 从ngrams_fw特征词中选取FPDC排序前20%的特征词作为种子词, 采用RoBERTa预训练语言模型[15]对候选术语和种子词语义特征向量化, 得出每个候选术语和种子词的语义特征向量表示.
Step 3. 语义相似度计算. 从每个种子词出发, 计算每个种子词和所有候选术语的语义向量的归一化欧式距离相似度. 欧氏距离计算结果受到向量长度以及向量维度的影响, 取值范围不固定, 采用L2-norm对候选术语和种子词的语义特征向量标准化. 假设X是n维的语义特征向量 X=(x1,x2,x3,···,xn), 则向量X的L2标准化公式如下:
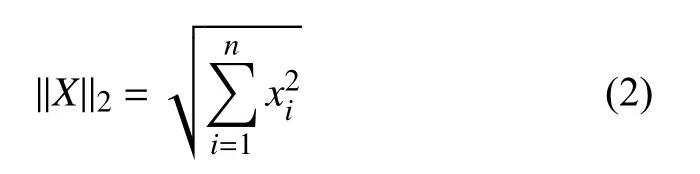
向量X和向量Y的归一化欧式距离计算公式如下:
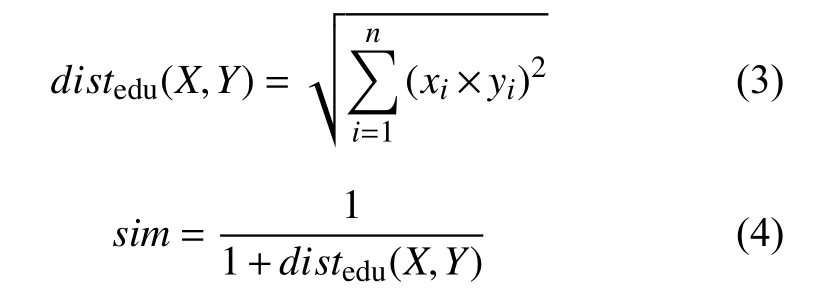
Step 4. 语义特征相似度匹配. 遍历每个特征种子词, 找到与每个特征词相似度最大的候选术语, 当相似度大于设定阈值时认为该候选术语与种子词相似, 将候选术语加入结果术语集合; 考虑到候选术语之间的连通性, 对相似度阈值进行指数衰减法来将词与词分开. 设定最小相似度阈值为MinSim, 阈值将随着词连通个数增大, 指数衰减法公式如下:
其中, α为衰减因子, i dx 表示种子词的序号.
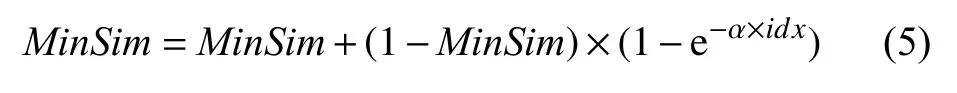
Step 5. 结果排序输出. 通过每个特征种子词与候选术语的语义特征相似度匹配, 得到相似度匹配结果,根据相似度由高到低排序, 输出最终的政策术语抽取结果, 并对词库进行了更新.
3 系统设计与实现
3.1 系统架构设计
为了解决人工抽取政策术语的问题, 本文设计了一套语义增强的多策略政策术语抽取系统. 系统的组织架构如图1所示, 分为数据层、模型层、服务层和应用层.
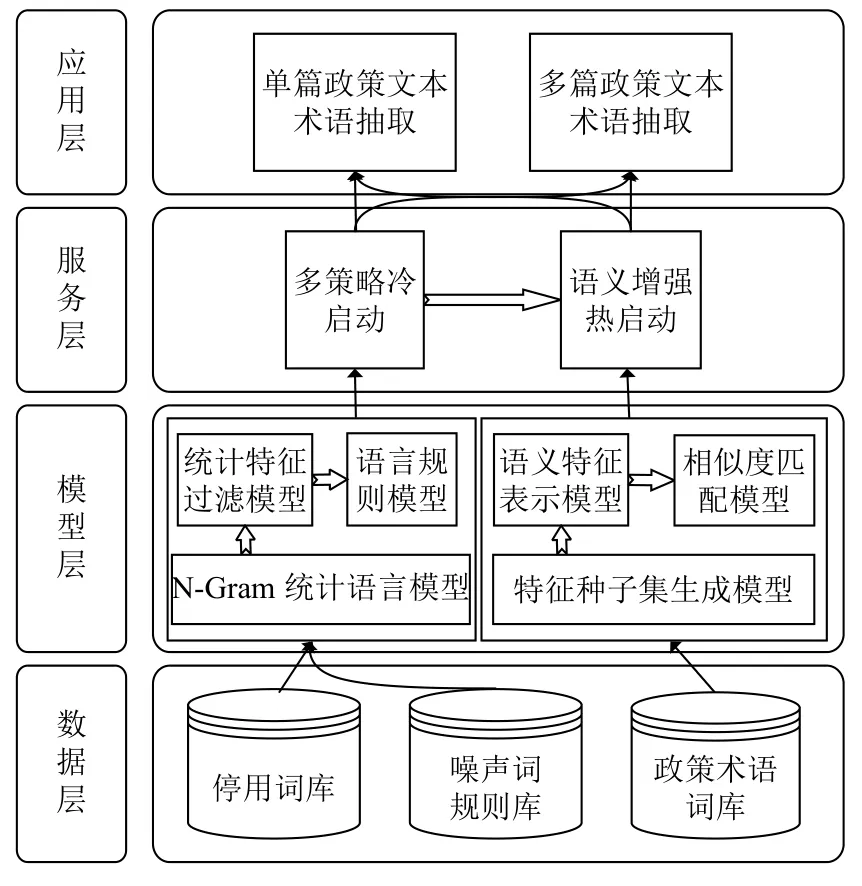
图1 系统架构图
(1) 数据层
数据层包括系统中模型使用的停用词库、噪声词规则库和政策术语词库.
停用词库用于过滤术语抽取结果中的垃圾串, 即如果候选术语中的任意一个子串包含在停用词库中,则丢弃该候选术语. 该词库初始化为通用的停用词库.
噪声词规则库用于过滤前后缀为常用词的候选术语. 该规则库中初始化为常与政策术语作为前后缀进行搭配的模式, 如“采用#”“提供#”“#与”和“#如下”等,“#”与常用词结合的位置代表该常用词作为候选政策术语的前缀或者后缀.
政策术语词库用于保存政策术语抽取结果. 词库中包含政策术语、术语频次、术语词性、术语类别等信息. 系统提供了对于词库的增、删、改、查和词库统计信息可视化. 词库初始化为空, 通过设定或调整特征指标FPDC阈值, 由系统从候选术语列表中批量增加或更新术语词库.
(2) 模型层
模型层是术语抽取系统所使用的核心模型, 为多策略冷启动服务和语义增强热启动服务提供模型支持, 包括N-Gram统计语言模型、统计特征过滤模型、语言规则模型、特征种子集生成模型、语义特征表示模型和相似度匹配模型. 以下对各个模型的作用进行简要介绍.
N-Gram统计语言模型为初始文本片段生成模型.模型对文本语料进行长度为1到n的滑动窗口操作,形成长度为1到n的字符片段序列, 按给定的词长阈值过滤字符片段序列, 得到候选文本片段集合.
统计特征过滤模型接收N-Gram模型的输出, 对候选文本片段进行TF、PMI、DF、C-value特征的统计, 计算术语特征融合指标FPDC, 按设定阈值过滤,输出高于阈值的候选政策术语.
语言规则模型对候选政策术语进行噪声过滤, 分为停用词库过滤和噪声词规则库过滤, 输出去噪后的候选政策术语.
特征种子集生成模型主要生成语料的政策术语特征种子集. 模型根据候选术语和已有政策术语词库的FPDC值计算C-value进行更新, 选取FPDC值排序前20%的候选术语, 输出为语料特征种子集.
语义特征表示模型主要生成候选术语和特征种子词的语义特征表示. 模型对所有候选术语和特征种子词利用中文预训练语言模型生成相应的语义特征向量,并对语义特征向量进行L2标准化.
相似度匹配模型主要利用候选术语和特征种子词的相似度挖掘低频且稀疏的政策术语. 模型遍历语料特征种子集中的每个特征种子词, 计算所有候选术语与该词的语义向量的归一化欧式距离相似度, 根据指数衰减的相似度阈值进行连通性匹配, 输出最终抽取的政策术语结果.
(3) 服务层
针对零样本的术语抽取需求, 提供了多策略冷启动服务和语义增强热启动服务, 即分别集成了多策略频繁模式算法和语义增强的多策略术语抽取算法, 为两种算法提供RESTful API访问接口.
多策略冷启动服务提供无词库支持的多策略政策术语抽取服务, 模型使用第2.1节介绍的算法. 通过设定术语TF阈值、术语长度阈值、术语PMI阈值、术语DF阈值、C-value阈值以及是否进行语言规则过滤, 先利用N-Gram统计语言模型从政策文本中抽取候选文本片段, 接着基于统计特征过滤模型和语言规则模型进行候选文本片段分析与过滤, 最后排序输出冷启动抽取结果.
语义增强热启动服务提供有词库支持的语义增强政策术语抽取服务, 模型使用第2.2节介绍的算法. 冷启动服务得到的抽取结果存在一定的不足, 一方面抽取术语中带有噪声词汇, 一方面遗漏了低频数据. 在冷启动术语抽取结果的基础上, 先利用特征种子集生成模型得到语料特征种子集, 接着依次使用语义特征表示模型和相似度匹配模型去除已抽取噪声词和召回未登录低频词, 最后排序输出热启动抽取结果.
(4) 应用层
应用层提供零样本条件下的交互式政策术语抽取构建词库的功能, 按照术语抽取的使用场景不同, 分为单篇政策文本术语抽取和多篇政策文本术语抽取两个场景, 提供政策术语词库的维护管理, 包括增加、删除、修改、查询等交互功能, 以及统计可视化功能.
在单篇政策文本术语抽取场景下, 用户可设定和调整政策术语抽取参数(术语TF阈值、术语长度阈值、术语PMI阈值、术语DF阈值、C-value阈值以及是否进行语言规则过滤、是否加入当前词库和相似度阈值)实现从无词库冷启动到有词库热启动半自动化的政策术语抽取.
在多篇政策文本术语抽取场景下, 与单篇政策文本术语抽取不同之处在于, 抽取时不仅要考虑候选政策术语在单篇语料中的局部特征, 而且还需考虑其在多篇语料中的全局统计特征, 实现对某类政策文本的全局政策术语抽取.
系统整体流程如图2所示.
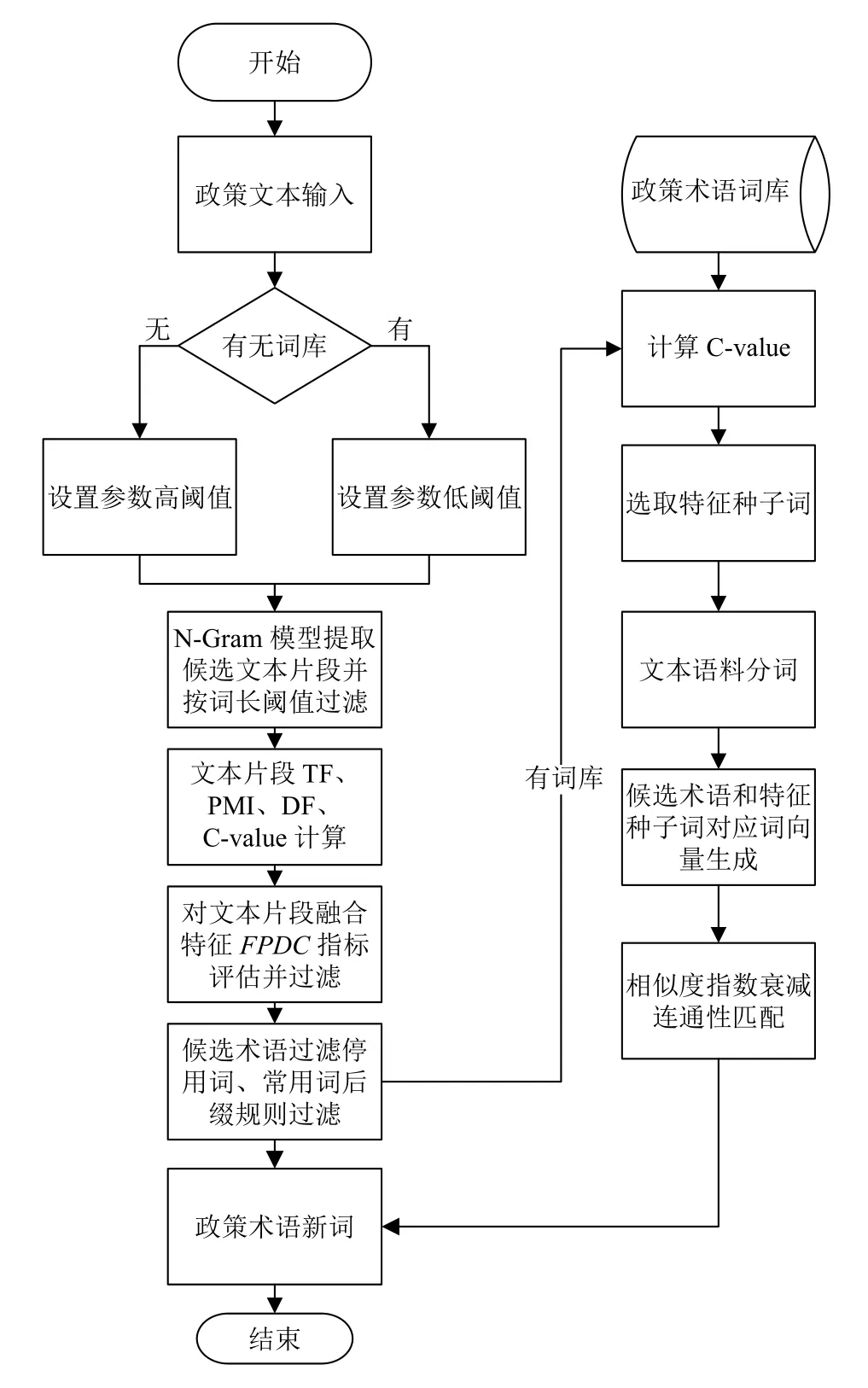
图2 语义增强的多策略政策术语抽取流程图
3.2 系统实现与展示
系统实现采用Python语言作为程序开发语言, 选用具有强扩展性和兼容性的Flask框架作为Web服务框架, 以Keras框架作为快速加载预训练语言模型的深度学习框架. 系统展示如图3所示.
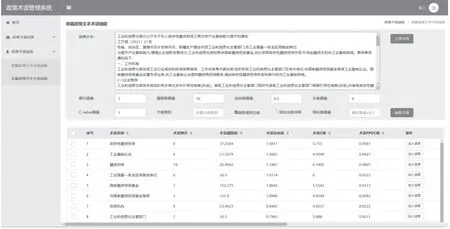
图3 系统界面效果图
系统包括政策术语词库统计、政策术语词库管理和政策术语抽取3大功能模块. 系统首页为政策术语词库统计模块, 包括政策术语词库中政策术语总数、政策术语长度分布、政策术语类型分布、政策术语词性分布、政策术语频数分布. 政策术语词库管理模块提供了对政策术语词库的增、删、改、查. 政策术语抽取模块, 分为单篇政策文本术语抽取和多篇政策文本术语抽取两部分.
4 应用与结果分析
本系统在某公司政务通平台进行术语抽取应用验证, 选取数据集为1 942篇来自各省、直辖市或以上行政级别政府单位所公布的政策文本, 由业务人员判断抽取的术语是否有用. 抽取效果评价指标如下:
(1) 术语抽取准确率

(2) 术语抽取召回率

(3) F1值
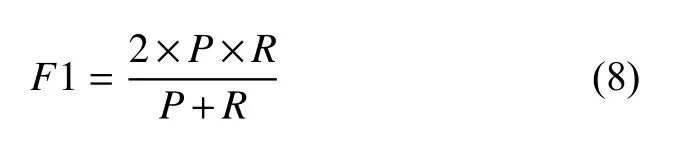
4.1 系统方法可行性分析
为了说明系统抽取方法的必要性和可行性, 设计了消融实验探究各个特定模块对抽取结果的影响, 得出了如表2所示的实验结果.
由表2可知语义增强的多策略算法取得了最好的政策术语抽取效果, 移除了语义增强、凝固度、自由度、规则过滤和C-value特征中的任一策略都使得政策术语抽取效果变差.

表2 1 940篇政策文本术语抽取效果(%)
4.2 系统结果有效性分析
为了说明系统抽取结果的可用性和有效性, 对验证数据集抽取的3 436条术语进行统计分析, 词库中的低频长词占比为55%, 通过普通的术语抽取方法难以抽取得到. 系统抽取的政策术语示例如表3所示.

表3 政策术语抽取结果示例
5 结束语
本文介绍了语义增强的多策略政策术语抽取系统的设计与实现. 该系统针对政策术语的时效性、低频度和复合短语等特点, 设计了一种基于统计学方法和语言学方法的多策略冷启动算法, 并在冷启动得到政策术语词库后, 利用预训练语言模型语义增强方式召回低频且稀疏的政策术语, 提供交互式页面对词库进行了循环更新, 实现了半自动化的政策术语抽取, 有助于政务企业对政策内容的智能解读, 提升企业政策精准推送服务效果.
