一种基于IBDP-GRU模型的热带果树寒冻害预警技术
2022-09-19张晓鹏秦亮曦秦川苏永秀
张晓鹏, 秦亮曦*, 秦川, 苏永秀
(1.广西大学 计算机与电子信息学院,广西 南宁 530004;2.广西多媒体通信与网络技术重点实验室,广西 南宁 530004;3.广西壮族自治区气候中心, 广西 南宁 530022;4.广西壮族自治区气象科学研究所, 广西 南宁 530022)
0 引言
近年来,随着人们生活水平的提高,对水果的需求量不断增长。热带水果因具有独特的味道和营养价值而深受人们的喜爱。国家对热带水果产业的扶持政策使得我国热带水果产业快速发展,然而,热带水果产量往往会受到各种气候要素的影响,特别是低温寒冻害对水果生产具有重大的负面影响。寒害主要指热带、亚热带作物在冬季气温不低于0 ℃时,因气温降低引起作物生理机能障碍,导致减产甚至死亡的一种农业气象灾害[1]。冻害主要是指气温在0 ℃以下时,一些作物或多年生经济林木受冻甚至冻死的气象灾害,常发生的有越冬农作物冻害、果树冻害和经济林木冻害等[1]。对于热带果树,极端低温不仅可能影响水果品质和产量,甚至能使果树大面积冻死,造成巨大的经济损失。广西作为全国水果主要产地之一,亚热带特色水果品种丰富,香蕉、菠萝、芒果、火龙果等水果产量位居全国前列[2],因此,开展热带果树寒冻害预警技术研究,对于促进广西热带水果产业的稳步发展,提高果农的收入和广西经济发展水平,满足人民对于热带水果的需求具有重要意义。
在果树寒冻害预警方面,早期主要由果农根据经验对未来天气作出判断,并确定是否需要对果树采取保护措施,然而,这需要有丰富的经验,而且这种判断的准确率可能不高,或者未能及时判断,从而错过了保护果树的最好时机。在现有果树寒冻害预警研究中,还鲜有通过利用深度学习进行热带果树寒冻害预警的方法。现有的这方面的研究主要聚焦在研究某区域相关热带果树的种植适宜度,从而提前规划热带果树种植区域。如通过某区域往年气象数据建立相关热带果树寒冻害发生频率的空间分布图,分析该区域内各局部区域的寒冻害发生频率,筛选出寒冻害发生频率低的局部区域种植热带果树。又如,收集多个气象站点的气象数据,通过机器学习方法训练模型,最后通过训练出的模型判断某地区是否适合种植相应的热带果树。这些方法的目的在于为某地区热带果树种植提供规划,避免在一些不适合种植热带果树的区域盲目种植,因此,建立寒冻害预警模型,预测未来一段时间内果树是否会发生寒冻害,以在寒冻害天气来临前保护已经种植在寒冻害频发地区的热带果树,就显得尤为重要。
基于上述考虑,本文中提出了一个基于不平衡数据处理和门控循环单元的预警模型,用于预测果树未来一段时间是否会发生寒冻害。该模型首先对未来的日最低气温进行预测,然后结合相关果树的寒冻害指标,对相关热带果树是否会发生寒冻害作出预警。
1 相关研究工作
1.1 果树寒冻害分析和风险区划等相关研究
近年来,许多研究者陆续对果树寒冻害进行了研究。谢晓燕等[3]利用广西桂林市14个国家站1981—2017年逐日气象数据,采用Morlet小波分析砂糖橘寒冻害周期变化,采用重标极差分析法(R/S分析)对寒冻日数未来趋势进行分析,并结合数字高程模型(DEM)数据分析寒冻日数空间变化。汪仁军等[4]利用广西气象资料和桑树寒冻害指标,获得广西桑树的低温冻害等级的空间分布图。吴炫柯等[5]利用广西91个国家级气象观测站1961—2016年的气象资料,计算出广西木薯低温寒冻害轻、中、重、严重发生频率,并基于SURFER技术获得广西木薯低温寒冻害轻、中、重、严重发生频率的空间分布特征图。苏晓玲等[6]根据福建省67个气象站的观测资料和相应的地理信息,应用逐步回归分析方法和GIS技术构建福建省越冬期极端最低气温和4个等级冻害指标发生频次空间分析模型,然后根据荔枝冻害的指标,为福建省各地区合理种植荔枝提供参考。彭继达等[7]将福建省低温类型划分为辐射型、平流型、混合型,分别探讨3种低温类型下台湾青枣的寒冻害特征,并建立寒冻害指标,为台湾青枣寒冻害评估及防御提供了参考。庞奇华等[8]提出一种基于深度置信网络的分类模型,判断广西某些区域是否适合种植热带果树。徐路等[9]提出一种改进的遗传算法来优化误差反向传播神经网络模型用于热带果树种植适宜度分析,取得了较高的分类准确率。
1.2 不平衡数据处理的相关研究工作
在传统的机器学习算法中,常以提高整体分类的准确率为目标,因而往往会忽略不平衡数据集中少数类样本的正确分类[10]。现有研究处理不平衡数据分类问题主要从数据抽样、特征选择和代价敏感[11]3个方面着手。
不平衡数据的抽样主要通过增加少数类样本(过抽样)或者减少多数类样本(欠抽样),从而使数据集相对平衡。如经典的过抽样算法[12](synthetic minority oversampling technique, SMOTE)的主要思想是在少数类样本之间进行插值来生成新的少数类样本。Wang等[13]为预测中风患者是否会心脏病发作,结合随机欠采样、聚类和过采样技术平衡训练数据样本。Xie等[14]提出了基于高斯分布的过采样算法(Gaussian distribution based oversampling,GDO),以处理不平衡数据进行分类。在GDO算法中,通过考虑少数类样本携带的密度和距离信息,以概率的方式从少数类样本中选择锚样本,然后按照高斯分布模型生成新的少数类样本。
特征选择层面,主要通过选择有利于提高少数类样本分类准确率的特征来分类不平衡数据[15]。Huang等[16]提出了基于关联规则的特征选择算法和基于随机均衡采样的综合分类算法,以解决计算机医疗辅助诊断中医学样本不平衡的问题。Lv等[17]针对高光谱图像(HSI)分类面临的多类不平衡的问题,基于随机特征子空间对训练样本进行随机过抽样和多次数据增强,然后以卷积神经网络为子分类器构建组合学习模型进行分类。
代价敏感层面,主要思想在于通过为少数类样本赋予比多数类样本更大的权重,增加模型在训练时对少数类样本被误分的惩罚来提高少数类样本的分类准确率。面对极限学习机在分类不平衡数据时表现欠佳的问题,Zong等[18]提出了加权极限学习机算法(weighted extreme learning machine,WELM),通过为少数类样本赋予比多数类样本大的权重让算法更加注重少数类的分类。面对糖尿病检测问题,Bal等[19]提出一种加权正则化的极限学习机以解决软件故障预测中数据不平衡的问题。
2 基于不平衡数据处理和门控循环单元的预警模型
鉴于一年中果树受寒冻害影响的天数比较少,模型在预测时可能倾向于减少对寒冻害天气的正报,故本文中提出一种基于不平衡数据处理和门控循环单元(GRU)的预警模型(称为IBDP-GRU)对未来一天的日最低气温进行预测,再将预测结果与相关热带果树的寒冻害指标中的极端最低气温进行比较,从而判断果树在未来一天是否会受害。
2.1 “三合一”欠抽样算法
预测下一日的最低气温是一个回归问题。为了结合不平衡数据的处理技术,设置一个低温阈值,将日最低气温值低于或等于该阈值的归类为少数类样本,高于该阈值的归为多数类样本。然后对多数类样本使用提出的“三合一”欠抽样方法进行欠抽样。
现今的欠抽样技术中,仅仅考虑减少多数类样本,容易造成多数类样本信息的丢失。为了弥补欠抽样算法中多数类样本信息的大量丢失,提出了一种新的欠抽样方法,即“三合一”欠抽样算法。在每3个样本中,计算三者的质心(即该3个样本各个属性上的平均值),并保留该质心而丢弃原来的3个样本。重复此过程直至满足多数类样本的数量要求。“三合一”欠抽样算法因在每减少3个样本的同时用这3个样本的质心去替代减去的这3个样本,能较好地弥补多数类样本信息的丢失。为了选择合理的多数类样本进行“三合一”欠抽样,分2个阶段进行:第1阶段将多数类样本按照日最低气温的范围将多数类训练样本分为多个簇,然后选取簇中样本数量多于欠抽样后平均每个簇的样本数量Navg[如式(1)]的簇,并对这些多余数量的样本用于“三合一”欠抽样。由于第1阶段完成后多数类样本数量可能未满足要求,因此在第2阶段欠抽样中,每次随机选取3个多数类样本进行欠抽样,直至欠抽样后的多数类样本数量满足数量的要求。第2阶段欠抽样将选取的用于合并的样本数量N[如式(2)]。第1阶段主要是对样本数量较多的簇进行欠抽样,这样不仅可以保留样本数量较少的簇的信息,还能在整体上保留多数类样本的信息。而第2阶段主要在于微调多数类样本数量以满足多数类样本的数量要求。“三合一”欠抽样算法的步骤如算法1所示。
(1)
(2)
式中Nmaj、Rmaj、Kmaj、Ntmp分别为训练集中多数类样本的数量、设定的欠抽样比例、多数类簇的数量和第1阶段欠抽样结束后多数类样本的数量。
算法1“三合一”欠抽样算法
输入:多数类训练样本集Dmaj、Rmaj、Kmaj;
Step1:将多数类样本按照等长的气温范围分为多个簇,记为Cmaj;
Step2:获取训练集中多数类样本的数量Nmaj;
Step3:根据式(1)计算Navg;
Step4:对Cmaj中样本数量大于Navg的多数类簇分别进行欠抽样;
Step5:根据式(2)计算N;
Step6:若N≥3,进行第2阶段欠抽样。
输出:Dmaj欠抽样后的多数类训练样本Dmaj_sampled。
2.2 IBDP-GRU模型总体设计
IBDP-GRU模型总体流程如图1所示。

图1 IBDP-GRU模型总体流程
对多数类样本进行欠抽样的目的在于降低数据的不平衡率,提高模型对少数类样本的预测能力,从而提高模型对热带果树寒冻害预警的正报率。同时,因为少数类样本数量减少,模型的训练时间将缩短。结合代价敏感思想,为少数类样本赋予比多数类样本大的权重,能进一步提高模型对少数类样本的关注度,有助于提高模型对热带果树寒冻害预警的正报率。在神经网络模型选取方面,因门控循环单元[20](gated recurrent unit, GRU)是一种非常适合时间序列预测的循环神经网络,且相比长短期记忆网络[21](long-short term memory,LSTM),GRU的参数更少,更易于计算和训练,而且其预测效果依然与LSTM相当,故选取GRU作为建模的神经网络模型。
3 实验与分析
实验的硬件环境:CPU为Intel Xeon E5-1620 v3、4核心、主频为3.50 GHz,内存为8 GB。操作系统为Windows 10,运行环境为Python 3.7。
3.1 实验用到的神经网络模型
在实验中,将提出的IBDP-GRU模型与GRU、LSTM、CNN-GRU组合模型和BP神经网络进行对比。其中实验搭建的各类神经网络模型如图2所示。
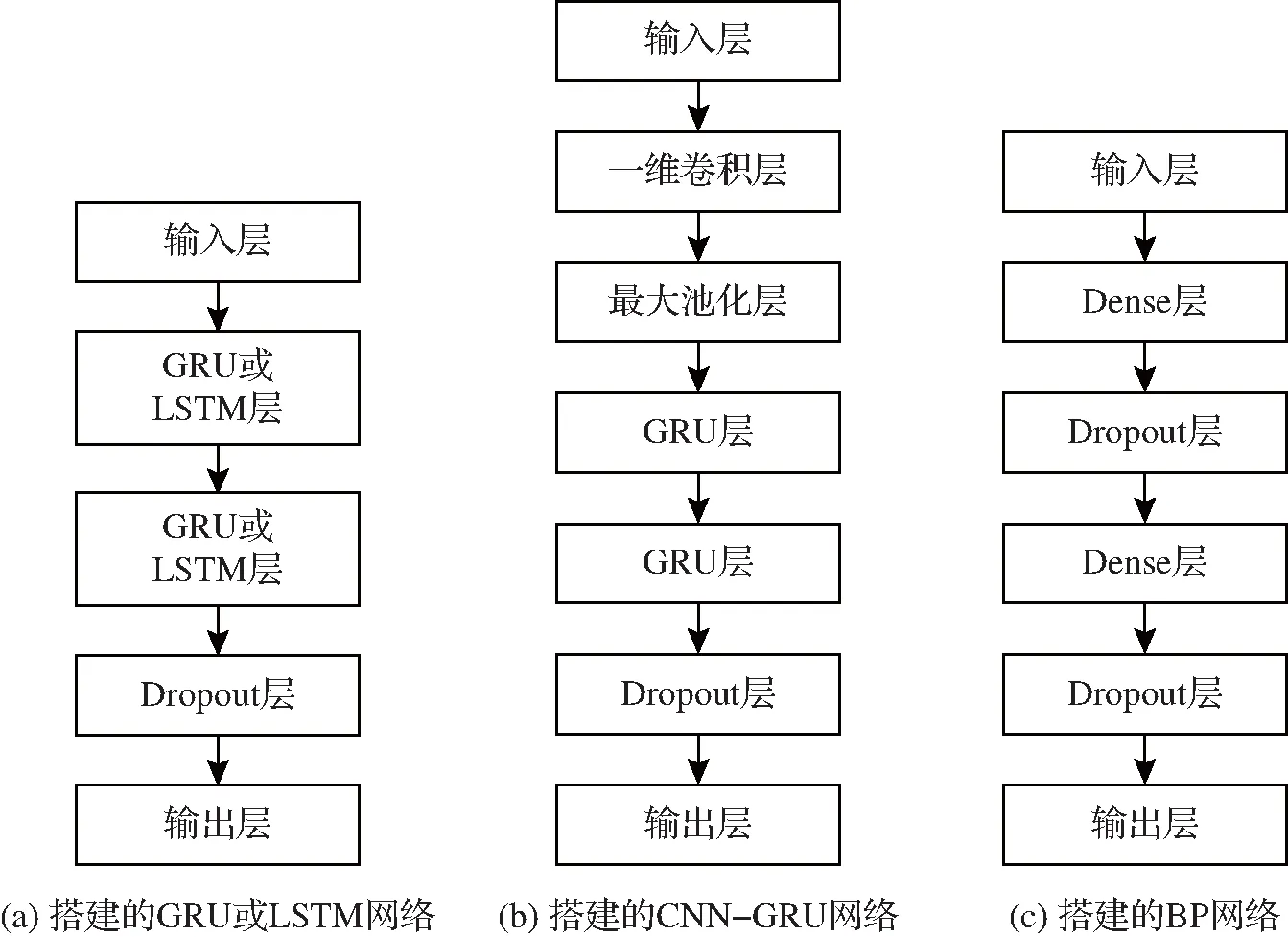
图2 实验中搭建的各类神经网络模型
为了保证实验结果的可比性,IBDP-GRU模型中搭建的GRU神经网络与对比模型中的GRU模型的相同,而实验中对比的LSTM模型结构也与此相似,只是仅仅将GRU层换位LSTM层。CNN-GRU组合模型也是在GRU模型的基础上,增加了一层卷积层和一层池化层。BP神经网络模型的隐藏层也为2层。
3.2 实验参数设置
在对比实验中,采用控制变量法。IBDP-GRU、GRU、LSTM、CNN-GRU和BP模型中,步长均设置为5;输出神经元个数为1;批处理大小为100,迭代次数为150,Adam学习率为1×10-3。IBDP-GRU、GRU、LSTM和CNN-GRU中,GRU(或LSTM)为2层,每层神经元个数均为50,recurrent_dropout为0.7;CNN-GRU组合模型中,CNN卷积核个数为10,池化层的大小为1,步长为1。BP模型中,全连接层为2层,每层神经元个数也为50。另外,对于IBDP-GRU,温度阈值设置为5.5,设置欠抽样率为0.7,多数类样本权重为1.0,少数类样本权重为2.0。
3.3 数据集
为验证IBDP-GRU模型在日最低气温预测阶段的性能,采用了湖南郴州2014—2019年逐日气象数据集。为验证IBDP-GRU模型在热带果树寒冻害预警方面的性能,采取了地处亚热带的广西南宁在1961—2020年冬季的逐日气象数据集。2份数据集的详细信息见表1。其中,湖南郴州2014—1019年逐日气象数据集中的16个特征分别为平均气温、最高气温、最低气温、平均相对湿度、最小相对湿度、最小风速、最大风速、日照时数、日降雨量、日蒸发量、平均气压、最大气压、最小气压、平均地表温度、最大地表温度和最小地表温度。广西南宁1961—2020年冬季逐日气象数据集中的5个特征分别为日平均气温、日最高气温、日最低气温、降雨量和日照时数。

表1 数据集详细信息
另外,因每一年里的日最低气温是有周期性趋势的,为了在组合样本后不丢失样本的周期趋势信息,利用周期均设置为365的sin和cos 2个函数,将样本时间特征的月和日映射到sin()和cos()函数值中,并将这2组值分别作为新特征引入到数据集中。在此,称这2个新的特征分别为sin和cos特征。IBDP-GRU、GRU、LSTM、CNN-LSTM和BP模型在训练和预测时,均在数据集加入了sin和cos特征。
实验中,将数据集按照7∶3的比例划分为训练集和测试集,即前70%的样本用于训练,后30%的样本用于测试。
3.4 评价方法
在日最低气温预测阶段,本研究结合不平衡数据处理技术和神经网络模型对次日最低气温进行预测,属于回归问题。使用均方误差(mean square error, MSE)、均方根误差(root mean square error, RMSE)、平均绝对误差(mean absolute error, MAE)和决定系数R2作为评价指标。MSE、RMSE、MAE值越小,表明模型的预测效果越好。R2值越接近1,模型预测效果越好;R2值越接近0,模型预测效果越差。在热带果树寒冻害预警效果评价方面,使用正报率(TPR)、漏报率(FNR)和误报率(FPR)评价模型对果树的寒冻害预警效果。
3.5 热带果树寒冻害指标
因为香蕉是我国的第一大热带水果,而莲雾是南宁近年引进的新兴物种,故选取了香蕉和莲雾作为寒冻害预警的研究目标。二者的寒冻害指标见表2。

表2 香蕉和莲雾寒冻害指标
3.6 实验结果
为了消除偶然因素对实验结果的影响,各模型均进行了30次随机重复实验,最后各模型的各个评价指标均取该指标30次的平均值和标准差。
3.6.1 郴州数据集的实验结果
各模型在湖南郴州2014—2019年逐日气象数据集上的少数类样本、多数类样本及总体样本的评价指标比较情况见表3—5。
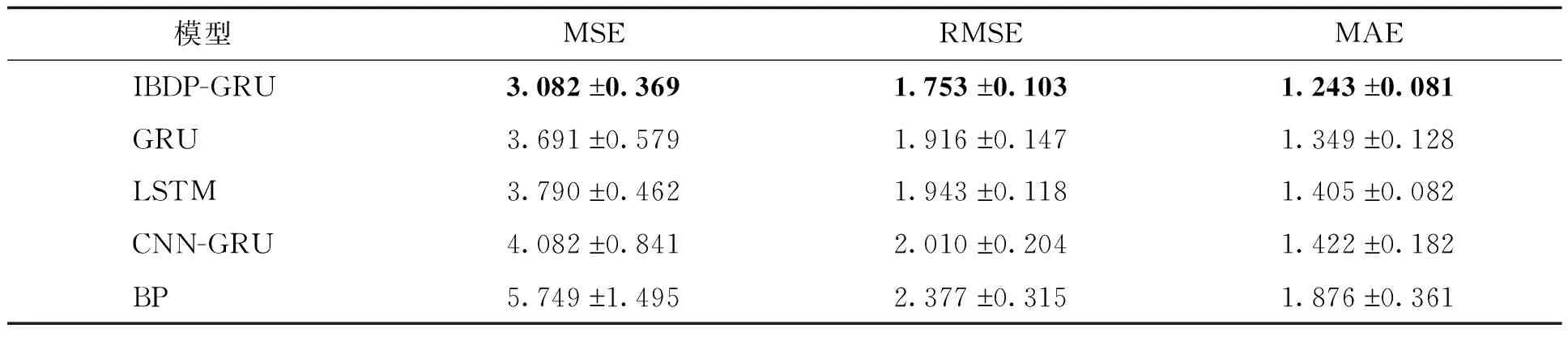
表3 湖南郴州数据集上各模型少数类样本MSE、RMSE和MAE评价指标对比
从表3可知,IBDP-GRU在少数类样本的预测方面表现最好,3个误差均取得最小值。如MSE值为3.082,误差比最好的GRU小0.609,比最差的BP模型小2.667,分别减少了16.50%和46.39%。从表4可知,在多数类样本的预测方面,IBDP-GRU只比表现最好的GRU略差一些,和LSTM基本相当,优于CNN-GRU和BP。从表5可知,在总体样本的预测方面,IBDP-GRU的各个指标基本排在第2位,且与最好的GRU相差较小,优于LSTM、CNN-GRU和BP。之所以得到上述结果,主要是因为IBDP-GRU对多数类样本做了“三合一”欠抽样,从而降低了2类数据的不平衡率,使模型增加了对少数类的关注,降低了对多数类的关注;其次,为少数类样本赋予合理的更大的权重,也减小了模型对少数类样本预测的误差,因此,IBDP-GRU能在少数类样本的预测上取得更好的结果,且对多数类样本的预测结果不会产生显著影响。由于在冬季人们对气温的降低更为关注,因此IBDP-GRU在低温(少数类)预测的准确度提高,更能满足这方面的需求。

表4 湖南郴州数据集上各模型多数类样本MSE、RMSE和MAE评价指标对比

表5 湖南郴州数据集上各模型总体MSE、RMSE、MAE和R2评价指标对比
3.6.2 南宁热带果树寒冻害预警结果
利用南宁1961—2020年冬季逐日气象数据集,对次日最低气温预测的结果见表6—8。由表6可知,IBDP-GRU对少数类(低温)样本的预测误差在所有模型中是最小的。如MSE指标,IBDP-GRU比GRU的误差小2.523,比BP小4.693,分别降低了26.90%和40.63%。从表7、8 可知,IBDP-GRU模型对总体测试样本和对多数类测试样本的预测误差没有受到显著影响。

表6 广西南宁数据集上各模型少数类样本MSE、RMSE和MAE评价指标对比
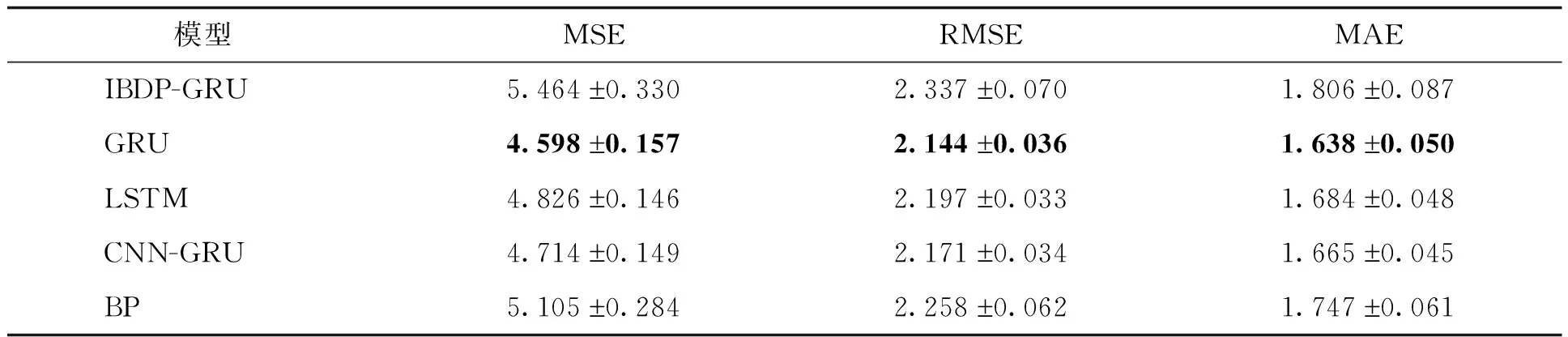
表7 广西南宁数据集上各模型多数类样本MSE、RMSE和MAE评价指标对比
对比湖南郴州2014—2019年逐日气象数据集,各模型在南宁1961—2020年冬季逐日气象数据集的MSE、RMSE和MAE指标值较大,R2值较小。这可能是因为,一方面,南宁的气候变化要比郴州的大,即南宁的气象数据集的数据波动比郴州的大。在时间序列预测中,各类算法对周期性明显,数据局部波动较小的数据集的预测效果往往较好。而如果数据极值点多,且极值点出现的规律不明显时,对时间序列模型来说都是不容易预测的。另一方面,实验使用的郴州的气象数据的特征比南宁气象数据的特征多,也是导致模型在南宁气象数据集预测的MSE、RMSE和MAE指标值比在郴州气象数据集的大、R2值较小的原因。
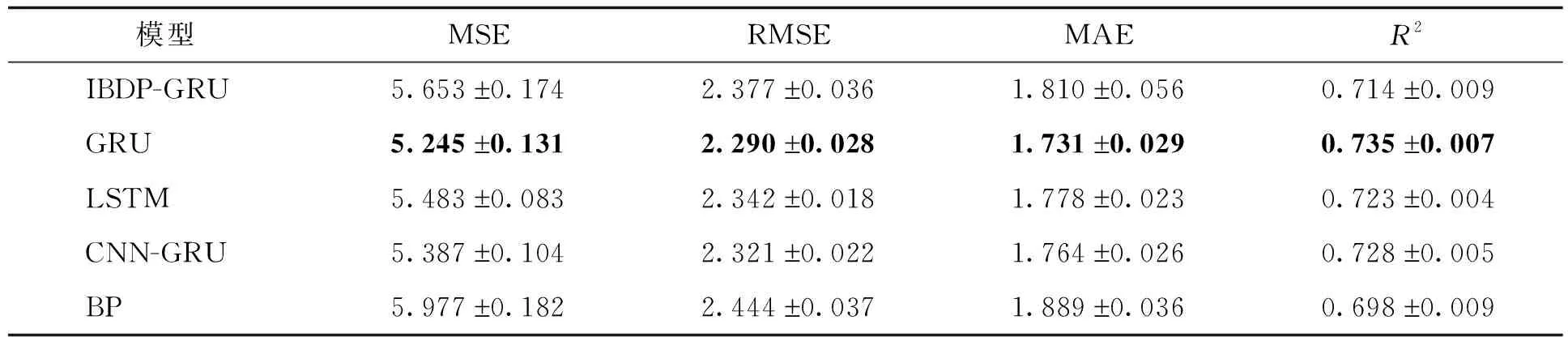
表8 广西南宁数据集上各模型总体MSE、RMSE、MAE和R2评价指标对比
另外,还利用南宁数据集,采用各模型对香蕉和莲雾次日是否受害进行预警。预警效果的比较见表9。从表中可以看出,IBDP-GRU对2种热带水果寒冻害预警的正报率是最高的,漏报率是最低的,只是误报率比其他模型略高。其中,IBDP-GRU对香蕉寒冻害预警的正报率分别比GRU、LSTM、CNN-GRU和BP模型的高16.4%、19.3%、20.3%、31.3%,对莲雾寒冻害预警的正报率分别比上述模型高18.7%、18.6%、20.5%、32.2%。IBDP-GRU误报率略高的原因主要是因为对多数类采用了欠抽样,且赋予多数类样本的权重比少数类样本的小,使得多数类的预测准确性略有降低。而误报率最低的BP模型,其对香蕉和莲雾的正报率低至28.7%和32.8%,漏报率高达71.3%和67.2%,表明BP对少数类样本的预测效果不理想,并不能为热带果树寒冻害预测提供可靠的参考。IBDP-GRU模型相比其他模型正报率最高,漏报率最低,表明它能够为热带果树次日是否会发生寒冻害提供可信度更高的预报。
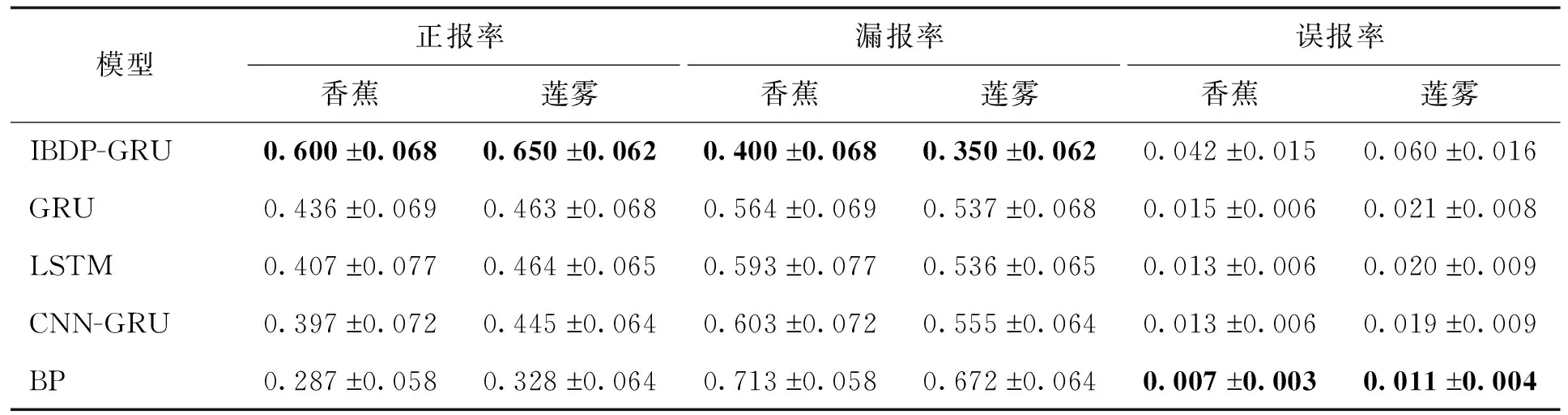
表9 各模型对寒冻害的预警效果
3.7 时间性能比较
在时间性能对比方面,统计了各模型分别在湖南郴州2014—2019年逐日气象数据集和南宁1961—2020年冬季逐日气象数据集上30次重复实验的平均训练时间,结果见表10。BP模型在这2个数据集上需要的训练时间都为最短。这是因为相比循环神经网络模型,BP模型更加简单,需要的参数更加少,故训练时间更少。在循环神经网络中,IBDP-GRU模型比GRU、LSTM和CNN-GRU模型需要的训练时间最少。在湖南郴州2014—2019年逐日气象数据集上,GRU、LSTM和CNN-GRU模型所需的训练时间分别为19.890、21.100、18.517 s,而IBDP-GRU模型所需的训练时间为15.573 s,相比上述模型分别减少了21.70%、26.19%、15.90%;在南宁1961—2020年冬季逐日气象数据集上,GRU、LSTM和CNN-GRU模型所需的训练时间分别为35.442、39.403、36.620 s,而IBDP-GRU模型所需的训练时间为27.532 s,相比上述模型分别下降了22.33%、30.13%和24.82%。相比GRU、LSTM和CNN-GRU模型,IBDP-GRU模型能显著降低训练时间,主要原因在于,通过“三合一”欠抽样算法对多数类样本的欠抽样,减少了多数类训练样本,故总的训练样本减少,模型训练的计算量减少,训练时间大大缩短。

表10 各模型训练时间对比
4 结论
针对热带果树寒冻害预警和气象数据集不平衡问题,本文中提出了一种结合不平衡数据处理和GRU的预警模型(IBDP-GRU)。首先将气象样本按照日最低气温阈值划分为多数类和少数类两类样本,随后对多数类样本采用提出的“三合一”欠抽样算法进行欠抽样,接着为少数类样本赋予比多数类样本大的权重,之后将训练样本和对应的权重输入到GRU中训练,最后结合日最低气温预测结果和相关热带果树寒冻害指标,预测果树在未来一天是否会发生寒冻害。结果表明:在日最低气温阶段,IBDP-GRU能在不显著影响多数类样本预测的情况下,提高模型对少数类样本预测的性能;在判断果树下一天是否会受害时,IBDP-GRU对香蕉寒冻害预警的正报率分别比GRU、LSTM、CNN-GRU和BP模型的高16.4%、19.3%、20.3%、31.3%,对莲雾寒冻害预警的正报率分别比上述模型高18.7%、18.6%、20.5%、32.2%;IBDP-GRU模型相比GRU、LSTM和CNN-GRU模型能显著降低训练时间。
随着热带水果产业的大力发展,对热带果树和水果的寒冻害防护越发重要。下一步,将考虑更多的气象要素,以进一步提高模型的正报率,降低误报率。
