基于AP聚类和互信息的弱标记特征选择方法
2022-09-17施恩惠司珊珊徐久成
孙 林,施恩惠,司珊珊,徐久成
(河南师范大学计算机与信息工程学院,河南 新乡 453007)
目前,多标记学习在神经网络、机器学习等领域引起了广泛关注,且被应用于各种现实任务中,作为多标记学习的重要内容,特征选择旨在消除冗余特征、降维获取有用的信息以提升分类性能[1]. 传统的多标记特征选择算法假设多标记数据集的标记空间是完整且不缺失的[2]. 但在实际应用中,标记会因为人为或者设备的原因缺失或者无法获取,由此产生了大量的弱标记数据,即数据存在标记缺失或无标记的情况[3]. 然而,不完整的标记空间将导致特征和标记集相关性度量不准确,并且在特征选择过程中会丢失一些有价值的特征[4-7]. 因此,如何处理带缺失标记的弱标记数据问题显得尤为重要. 目前,缺失标记的处理方法有两种较为普遍,分别是填补法、粗糙集模型扩展法[3,8]. 例如,Zhu等[9]利用线性回归模型来填补缺失标记,并将正则化作用于特征选择矩阵,选择最优特征子集;Jiang等[10]基于标记压缩和局部特征相关性,补全缺失标记. 由于粗糙集模型[11]处理缺失标记的方法不多,而填补法简单方便、直接有效[8],因而本文采用填补法处理缺失标记. 目前,回归填补需要花费大量时间[8];K最近邻填补需要设定K值且处理大规模数据集的效果不佳[12-13];而基于聚类的填补方法不受缺失数据的影响,时间复杂度相对较小,具有普遍的适用性[8,13]. 另外,基于AP聚类的填补方法与其他聚类算法相比,不需要预先设定聚类个数,可以将所有的样本都看作聚类中心,按照样本间的信息传递实现聚类,根据类中相似对象进行填补,且多次运行后的聚类结果比较稳定[8,13]. 因此,本文借鉴AP聚类算法优势来处理缺失标记,结合原有完整标记信息和样本相似性,有效补齐所有的缺失标记.
由于互信息能够检测变量之间的非线性关系,实现有效的特征选择[2],因此很多基于互信息的多标记特征选择算法被提出. 例如,Lee等[14]提出通过最大化特征和标记之间的相关性选择特征子集;Lin等[15]结合互信息,按照特征和标记的最大相关、特征间的最小冗余准则,筛选特征;Sun等[16]将最大相关最小冗余转化为约束凸优化函数,构造应用于多标记学习的特征选择算法. 但是,上述这些算法都假设标记空间中所有标记具有相同的占比,而忽略了标记空间中标记占比可能会对特征和标记集相关性的影响,进而导致相关性计算的不准确. 为了解决这个问题,Shi等[17]提出标记占比并应用于多标记特征选择. 基于此,引入标记占比改进互信息公式,度量特征和标记集之间的相关性,选择最优特征子集.
针对以上问题,本文运用AP聚类算法将样本编号,按照缺失标记数排序,结合样本相似度和概率填补预测缺失标记值,补全缺失标记;将标记先验概率作为标记的占比,结合互信息构建相关性度量评估特征和标记集之间的相关程度,降序排列选择最优特征子集. 实验表明该算法的性能比目前相关算法更好.
1 AP聚类
AP聚类[18]是Frey和Dueck提出的高效聚类算法. 该聚类算法是通过数据点间的消息传递,确定聚类中心,以及给每个聚类中心分配数据点[13]. 相似度矩阵的计算是消息传递的基础,在AP聚类中用欧式距离衡量数据点之间的相似度. 假设X={x1,x2,…,xn}∈Rn×f表示样本空间,对于任意样本xi,xk∈X,相似度公式[8,13]表示为:
s(xi,xk)=-‖xi-xk‖2.
(1)
AP聚类有吸引度和依赖度两类消息传递,用来确定聚类中心,以及给每个聚类中心分配数据点.假设R表示吸引度矩阵,A表示依赖度矩阵.对于任意样本xi,xk∈X,吸引度矩阵更新公式[13]表示为:
r(xi,xk)←s(xi,xk)-max{a(xi,xk′)+s(xi,xk′)},k′≠k.
(2)
对于任意样本xi,xk∈X,依赖度矩阵更新公式[13]表示为:
(3)
2 弱标记特征选择方法
2.1 基于AP聚类的缺失标记填补
定义1假设X={x1,x2,…,xn}∈Rn×f表示样本空间,Y={y1,y2,…,yn}∈Rn×L表示标记空间,数据集X经过聚类划分为k个不相交的簇C={c1,c2,…,ck},根据样本是否含有缺失标记将数据集划分为完备数据集D1和不完备数据集D2.如果样本xi有第j个标记,则xi(lj)=1,否则xi(lj)=-1.如果样本xi的第j个标记值缺失,则设xi(lj)=0.
定义2假设X={x1,x2,…,xn}∈Rn×f表示样本空间,Y={y1,y2,…,yn}∈Rn×L表示标记空间,xi∈D2,xi(lj)=0,xm(lj)=1或-1,且xi,xm∈Cq(q=1,2,…,k).xi与同一簇Cq中所有xm的相似度累加和表示为:
s=∑s(xi,xm).
(4)
定义3假设X={x1,x2,…,xn}∈Rn×f表示样本空间,Y={y1,y2,…,yn}∈Rn×L表示标记空间,xi∈D2,xi(lj)=0,xm(lj)=1或-1,且xi,xm∈Cq(q=1,2,…,k),缺失标记预测值可表示为:
(5)
由于相似样本之间具有相似标记,利用式(4)和式(5)预测缺失标记的值.pre_label即为xi(lj)的预测值,且取值范围为[-1,1].
定义4假设X={x1,x2,…,xn}∈Rn×f表示样本空间,Y={y1,y2,…,yn}∈Rn×L表示标记空间,xi(lj)=0,根据计算得到pre_label值,xi(lj)可表示为:
(6)
2.2 基于互信息的特征选择
定义5假设X={x1,x2,…,xn}∈Rn×f表示样本空间,Y={y1,y2,…,yn}∈Rn×L表示标记空间,F={p1,p2,…,pf}∈Rf表示特征空间.对于任意特征pi∈F和标记lj∈L,pi和lj的互信息公式定义为:
I(pi;lj)=H(pi)-H(lj|pi),
(7)
式中,H(pi)表示特征pi的信息熵,H(lj|pi)表示标记lj的条件熵.式(7)计算特征和标记之间的相关性.
定义6假设X={x1,x2,…,xn}∈Rn×f表示样本空间,Y={y1,y2,…,yn}∈Rn×L表示标记空间,对于任意标记lj∈L,lj的占比公式定义为:
(8)
式中,n表示样本的个数,n(lj)表示包含标记lj的样本个数.如果标记lj的占比很高,则表明很多样本包含标记lj,因此可认为标记lj相对重要.另外,根据式(8)可知,一般情况下每个标记的W(lj)值相差不大.
因为在大多数多标记数据集中,特征值通常是连续或者高度离散的,所以当使用互信息衡量特征之间的冗余度时,结果几乎为0.文献[19]指出,如果使用互信息度量特征和标记之间的相关度,则可以根据相关度值选择特征子集,忽略特征冗余的影响.因此,本文将不考虑特征间的冗余.
定义7假设X={x1,x2,…,xn}∈Rn×f表示样本空间,Y={y1,y2,…,yn}∈Rn×L表示标记空间,F={p1,p2,…,pf}∈Rf表示f维的特征空间.对于任意特征pi∈F和标记lj∈L,pi和L的相关度被定义为:
(9)
2.3 算法描述

假设多标记数据集有N个样本、L个标记和f个特征,聚类产生k个簇,标记随机缺失后,共有p个样本具有缺失标记.WFSAM的时间复杂度计算如下:步骤1聚类的时间复杂度为O(N2logN);步骤2-步骤5补全标记的时间复杂度为O(kpL);步骤6-步骤8特征和标记之间相关度计算的时间复杂度为O(Nf),由此可计算出WFSAM算法总的时间复杂度为O(N2logN+Nf).
3 实验结果与讨论
3.1 实验数据与准备
本文选用6个多标记数据集,数据集来自http://mulan.sourceforge.net,如表1所示. 将基于k最近邻的多标记方法(multi-labelk-nearest neighbors,MLKNN)[20]作为特征选择的分类器(近邻数为10,平滑参数为1). 使用平均精度(average precision,AP)、排序损失(ranking loss,RL)、覆盖率(coverage,CV)和1-错误率(one error,OE)作为评价指标[3,7]. 其中,AP值越大,表示算法性能越好,用“↑”表示,且最优值为1;其他指标值越小,则表示算法性能越好,用“↓”表示,且最优值为0.

表1 多标记数据集信息Table 1 Multi-label datasets information
3.2 不同缺失比率下多标记特征选择算法的分类结果
为了验证算法的有效性,将所提的WFSAM算法与MFML[7]、PMU[14]、MDMR[15]、MDDMspc[21]、MDDMproj[21]、MLNB[22]和MLFRS[23]算法进行比较. 这些算法均使用对应文献中的最佳实验参数. 实验选取特征排序的前30%作为特征子集,对比的实验数据与结果选自文献[7]. 表2-表5展示了8个多标记特征选择算法分别在0%、20%、40%和60%的缺失比率下在6个多标记数据集上的实验结果. 最优结果为粗体表示.

表2 0%缺失标记下4个指标的实验结果对比Table 2 Comparison results of four metrics under 0% missing labels
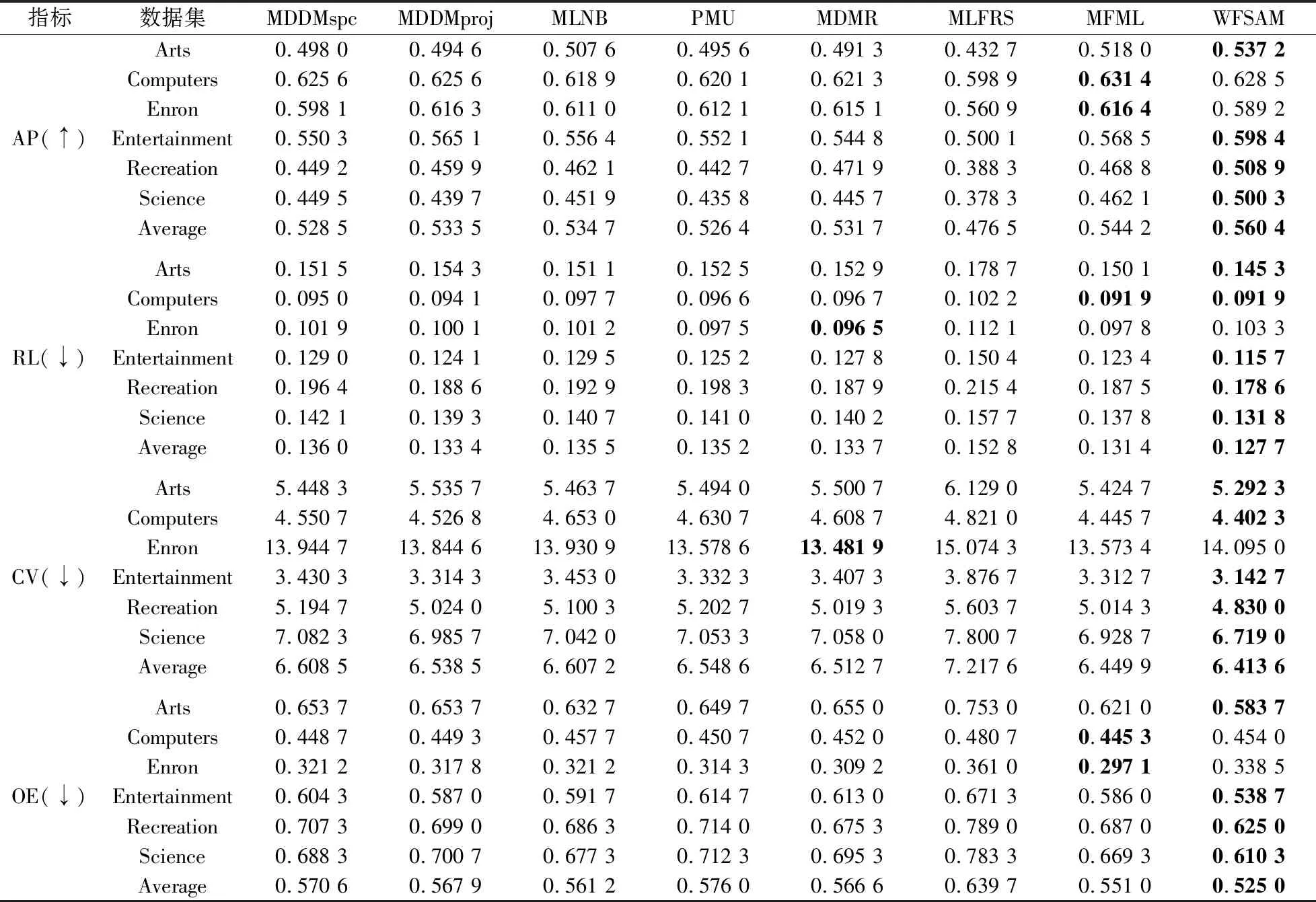
表3 20%缺失标记下4个指标的实验结果对比Table 3 Comparison results of four metrics under 20% missing labels

表4 40%缺失标记下4个指标的实验结果对比Table 4 Comparison results of four metrics under 40% missing labels

表5 60%缺失标记下4个指标的实验结果对比Table 5 Comparison results of four metrics under 60% missing labels
对表2分析可知:(1)在AP指标对比结果中,WFSAM在Enron数据集上仅优于MDDMproj、MLNB和MLFRS,比其余4个算法低0.006 3~0.010 2,但WFSAM的平均值最优. (2)在RL指标对比结果中,WFSAM在Enron数据集上仅优于MLFRS,但与分类最优的MDMR仅差0.006,且WFSAM在其余5个数据集上表现最优. (3)在CV指标对比结果中,WFSAM在Computers、Enron数据集上比MFML分别略相差0.003 3、0.473 2,但是WFSAM在其余4个数据集上表现最优. (4)在OE指标对比结果中,WFSAM在Computers数据集上与MLNB仅差0.002;在Enron数据集上,WFSAM与MDMR、MFML相差0.036 2;在其余4个数据集上,WFSAM表现最优. 总体来说,在标记缺失比率为0%时,WFSAM明显优于其他7种算法.
对表3分析可知:(1)在AP指标对比结果中,WFSAM在Computers数据集上仅次于MFML;在Enron数据集上,WFSAM仅优于MLFRS,略差于其余6种算法. 但是WFSAM的平均值最优. (2)在RL对比结果中,WFSAM在Enron数据集上仅优于MLFRS,但在其余5个数据集上WFSAM表现最优,同时WFSAM的平均值也最优. (3)在CV指标对比结果中,WFSAM在Enron数据集上仅优于MLFRS,与其余6个算法相差0.150 3~0.613 1;在其余5个数据集上WFSAM表现最优. (4)在OE指标对比结果中,WFSAM在 Computers、Enron数据集上与MFML分别仅相差0.008 7、0.041 4;在其余4个数据集上WFSAM表现最优. 同时WFSAM的平均值也最优. 总体来说,在标记缺失比率为20%时,WFSAM分类性能最优.
对表4分析可知:(1)在AP指标对比结果中,WFSAM在Computers数据集上仅优于MDDMproj和MLFRS;在Enron数据集上,WFSAM略差于其他7种算法,与最优算法MDMR仅相差0.052 5;在其余4个数据集上WFSAM性能最优. (2)在RL和CV指标对比结果中,WFSAM在Computers数据集上的RL结果与MDDMspc和MFML仅相差0.000 2,CV结果与MFML仅相差0.021 0;在Enron数据集上,WFSAM的RL和CV结果仅优于MLFRS;在其余4个数据集上WFSAM表现最优. 同时WFSAM的平均值也最优. (3)在OE指标对比结果中,WFSAM在Computers、Enron数据集上与最优算法MLNB、MDDMspc分别仅相差 0.019 0、0.069 1;在其余4个数据集上WFSAM表现最优. 同时WFSAM的平均值也最优. 总体来说,在标记缺失比率为40%时,WFSAM分类效果最佳.
对表5分析可知:(1)WFSAM在Enron数据集上的AP、RL和CV结果略次于MDMR,但在其余5个数据集上均取得最优的分类效果. (2)在OE指标对比结果中,WFSAM在Computers数据集上与MFML仅相差0.007 3;在Enron数据集上,与MDMR仅相差0.164 0;在其余4个数据集上WFSAM分类性能最佳. 同时WFSAM的平均值最优. 总体来说,在标记缺失比率为60%时,WFSAM优于其他对比算法.
综上所述,根据表2-表5的结果,随着标记缺失比率的增加,所有算法分类效果均越来越差,标记缺失时的分类效果明显低于标记完整时的分类效果,这充分说明标记的有效利用有益于弱标记特征选择.
3.3 统计分析
本文使用Friedman和Bonferroni-Dunn测试[24-26]来分析所有实验结果的统计意义,计算公式为:
(10)
(11)
式中,T表示不同评价指标下总的数据集个数,s表示算法的个数,Ri表示某一算法在所有数据集上的平均排序.临界距离[26]可以表示为:
(12)
式中,qα是测试的临界列表值,α是Bonferroni-Dunn测试的重要度.

表6 Friedman测试的FF值(s=8且T=24)Table 6 FF of the Friedman test(s=8 and T=24)
表6展示了在不同的标记缺失比率下统计计算的FF值.由表6分析可知,当α=0.1时,Friedman检验下零假设被拒绝. 因而,可以利用Bonferroni-Dunn测试进一步比较8种算法在统计分析上的不同,进而讨论算法之间的相对性能[7]. 为了直观地显示WFSAM与其他比较算法的相对性能,图1呈现了8种算法在不同标记缺失比率下的CD值,其中每个算法的平均排序沿数轴绘制,轴上的最小值位于左侧,因此,左侧排序的算法更好[2-3,7]. 在图1中,当所有算法两两比较时,将没有显著差异的算法用粗线连接起来,如图1(a)所示,WFSAM与MDDMspc、MLNB与MDDMproj之间有粗线相连,表明每对算法之间无显著差异. 根据图1可得:(1)标记缺失比率为0%和60%时,WFSAM明显优于其他算法;(2)标记缺失比率为20%和40%时,WFSAM略低于MFML,但与其余算法相比,优势仍然明显. 综上所述,在不同标记缺失比率下,WFSAM与MFML效果大致相同,但优于其他6种比较算法. 根据Bonferroni-Dunn测试,当α=0.1,qα=2.45时,CD=1.732,其中s=8,T=24.
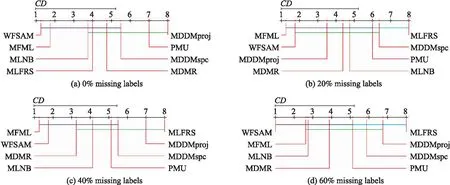
图1 WFSAM与其他比较算法的Bonferroni-Dunn检验Fig.1 The Bonferroni-Dunn test of WFSAM against the other compared algorithms
4 结论
本文提出一种基于AP聚类和互信息的弱标记特征选择方法. 该方法在AP聚类的基础上,结合剩余标记信息和样本相似性,对缺失标记进行填补,使用标记占比改进互信息,度量特征和标记集的相关性,设计弱标记特征选择算法,搜索最优特征子集. 在6个多标记数据集上,与7种算法对比,实验结果显示,缺失标记的填补技术和互信息的改进均是有效的. 但是,本文仅依靠特征和标记集的相关性选择特征子集,忽略了标记间的依赖关系,因此,在未来的研究工作中,针对大规模复杂的弱标记数据集,需要考虑标记相关性,结合线性回归、稀疏正则化等理论,进一步研究多标记分类的弱监督学习问题.
