SMGN:用于对话状态跟踪的状态记忆图网络
2022-09-17张志昌于沛霖庞雅丽曾扬扬
张志昌,于沛霖,庞雅丽,朱 林,曾扬扬
(西北师范大学计算机科学与工程学院,甘肃兰州 730070)
1 引言
随着各种智能设备的快速发展,人机对话近年来引起了学术界和产业界的广泛关注.任务型对话系统相关技术已经在许多产品中得到运用,例如微软公司的“小娜”(Cortana),苹果公司的智能语音助手“Siri”等.在任务型对话系统中,对话状态跟踪(Dialogue State Tracking,DST)是一个重要模块,该模块的主要目标是追踪用户意图并构建对话状态集合,集合由多个结构化的“领域-槽位-值”三元组构成.表1展示了一个对话状态跟踪任务示例,对于用户输入的话语,对话状态跟踪模型需要识别出句子的对话状态(例如“酒店-房间类型-标准间”).正确识别对话状态对任务型对话系统非常重要.

表1 对话状态跟踪任务示例
传统的静态对话状态跟踪模型仅依赖当前轮用户输入的话语[1~4].这类方法忽略了对话历史和当前对话的关系.在多轮对话中,经常需要利用历史对话中的信息来帮助理解用户当前的意图,所以历史敏感的对话状态跟踪模型成了主流研究方向[5~8].其中多数研究都选择通过对历史文本进行编码来引入上文信息,而文献[9~11]等研究表明,对历史时刻生成的对话状态进行编码会更有效.与对话文本不同的是,对话状态本身具有结构性,文献[9]就利用这种结构建立模式图来帮助模型进行特征交互.但是,过去的研究没有显式利用对话状态的结构,只是通过注意力机制中特征的连接来模拟模式图,这种方法忽略了图结构中结点自身包含的信息.
另外,随着对话系统的复杂度逐渐提升,如何生成复杂格式的对话状态也成了一个研究的热点.传统方法是使用序列标注生成对话状态[12],该方法在其他自然语言处理研究中得到了广泛的运用[13,14].但是这种方法无法应对复杂场景下的要求.例如,某些槽位对应的值仅出现在历史对话中,或者槽位并不对应某个具体的值而是对应“是”或“否”(例如在预定酒店场景中,可能会出现“酒店-停车位-否”这类对话状态).已有研究提出多种方法使模型可以生成复杂格式的对话状态.例如文献[7,10]等通过预测4 种离散的运算状态来决定对槽位执行何种操作,文献[15]提出通过编码器-解码器模型(Seq2Seq)将状态预测转化为生成式任务.这些方法会为模型带来额外的计算负担,并且需要针对不同的对话状态调整生成规则,可扩展性差.
针对上述问题,本文提出了一种状态记忆图网络(State Memory Graph Network,SMGN).在对话开始时,模型枚举所有可能出现的“领域-槽位”关系对,通过编码器进行编码生成槽结点,再使用槽结点与对话文本生成的值结点进行特征交互,通过两类结点连接形成状态记忆图.图1展示了表1样例对应的状态记忆图.
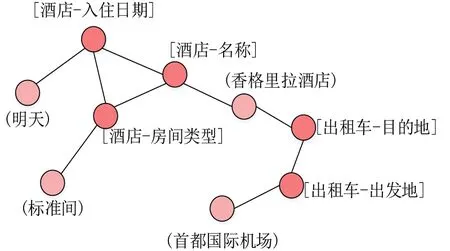
图1 状态记忆图示例
在状态记忆图中,槽结点与值结点相连的边对应一条对话状态,整个状态记忆图对应对话状态集合.模型会使用状态记忆图与当前对话进行特征交互并更新对话状态集合,之后通过图注意力网络(Graph Attention neTwork,GAT)[16]对状态记忆图进行更新.此外,本文通过值结点标记器和图连接层实现了一个新的对话状态生成方法,首先通过值结点标记器为当前对话生成值结点,之后通过判断槽结点与值结点是否连接来生成对话状态.由于状态记忆图会保留历史对话产生的值结点,语义槽可以和历史文本中的值构建对话状态.通过预生成公共值结点,模型也可以生成类似“是”或“否”的特殊类型值,这使得本文的模型可以生成复杂格式的对话状态,并且具有很强的扩展性.
为了验证模型的有效性,本文在3个公开的任务型对话数据集(中文数据集CrossWOZ[17],英文数据集MultiWOZ 2.0[18]及MultiWOZ 2.1[19])上进行了实验.实验结果表明,本文提出的模型在3个数据集上的联合正确率分别为37.47%,53.03%和54.88%.实验分析表明了本文的模型可以有效提升对话状态跟踪任务的性能.相比其他模型,本文模型对历史对话的语义理解能力更强.另外该模型比其他同类模型的运算效率更高.
本文的主要贡献如下:
(1)提出了一种显式利用图结构的状态记忆图网络,通过状态记忆图与当前对话进行特征交互,可以更有效地捕获对话状态的语义信息;
(2)针对复杂结构对话状态生成困难的问题,本文实现了一个基于状态记忆图的复杂对话状态生成方法,通过这种方法模型可以应对各种复杂格式的对话状态生成要求;
(3)在3 个公开的多轮对话数据集上进行了对比实验,实验结果表明本文方法可以有效提高对话状态跟踪任务的联合正确率,与同类模型相比运算效率更高.
2 状态记忆图网络
本文提出的状态记忆图网络模型结构如图2所示.状态记忆图网络由编码层、值结点标记器、图连接层以及图更新层4部分组成.
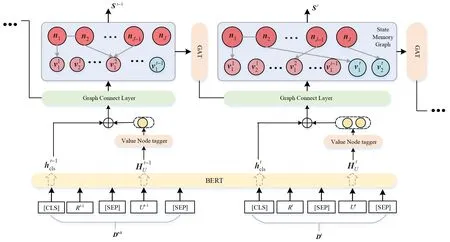
图2 状态记忆图网络模型结构图
2.1 任务定义
针对任意一个多轮对话,t时刻的对话历史文本X可以表示为
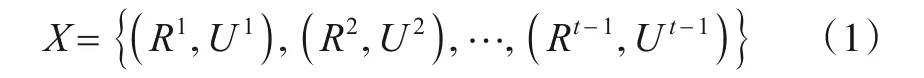
其中,Ri表示系统在第i轮生成的回复,Ui表示用户在第i轮(或者i时刻)输入的话语.t-1 时刻的对话状态集合可以表示为,其中,dj表示领域,sj表示槽位,vj表示槽位对应的值,J表示对话状态总数.
虽然不同对话系统间的对话状态格式有所区别,但都能通过规则转化为“领域-槽位-值”结构的三元组.例如某些对话系统需要预测意图,此时只需要将“意图”槽位对应值设为“空”即可(形如“领域-意图-null”).对话状态跟踪任务的目标是给定对话历史X和历史状态集合St-1,根据用户t时刻的输入Ut预测对话状态集合St.
2.2 编码层
在编码层中,模型分别进行槽结点编码以及输入编码,两部分编码任务共享同一个编码器.
槽结点编码:在对话开始时,模型通过枚举列出所有可能出现的“领域-槽位”关系对,并且为每个关系对编码生成一个槽结点.本文使用BERT(Bidirectional Encoder Representation from Transformers)作为编码器.BERT 是一种大规模预训练语言模型[18],具有强大的通用上下文语意表示能力,已在其他自然语言处理任务中得到充分运用[19].槽结点的具体编码计算方式如下:
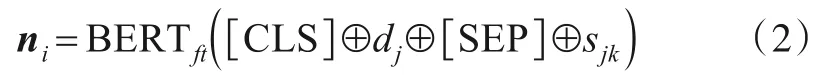
其中,[CLS]和[SEP]为BERT 编码器预先设定的标记符,⊕表示拼接操作,dj表示第j个领域,sjk表示第j个领域下对应的第k个语义槽.BERTft表示在训练期间将对BERT 进行微调(fine-tune).编码后模型截取标识符[CLS]对应的上下文向量作为结点的整体表示ni.
通过槽结点编码,模型获得了一系列槽结点构成的集合N={n1,n2,…,nJ}.需要说明的是,槽结点编码过程并不受对话内容影响,槽结点的个数只与对话系统所支持的领域与槽位有关.
输入编码:在t时刻,模型将系统回复Rt及用户输入Ut进行拼接并通过BERT 进行编码,具体计算方式如下:

2.3 值结点标记器
在获得用户输入Ut对应的上下文向量后,模型通过值结点标记器提取值结点.值结点标记器会进行一个简单的序列标注任务,为每个上下文向量标注一个边界标签来划分出实体边界.本文采用BIO((B-begin,I-inside,O-outside))标注方法,标注方法的具体细节可以参考文献[12].在标注任务中,模型只判断实体的边界而不进行实体分类.在标注结束后,模型对同一实体内的上下文向量进行平均池化,再与当前时刻的句向量拼接获得值结点.具体计算方式为


2.4 图连接层
经过值结点标记器后,模型将当前时刻的值结点添加到状态记忆图中,并对每一对“槽结点-值结点”进行分类,判断两个结点之间是否有边,从而构建连接关系.图连接层的具体计算方式为
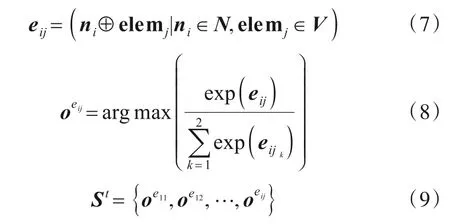
2.5 图更新层
在图更新层中,模型将根据状态记忆图的连接关系对结点进行更新.除了保留图连接层的信息外,模型还为相似的槽结点添加连接.具体方法是,如果两个槽结点具有相同的领域或者槽位,则为这一对结点添加一条边.完成连接后,模型得到了t时刻状态记忆图对应的邻接矩阵At,之后将使用该邻接矩阵对状态记忆图进行更新.

经过图注意力网络后,状态记忆图中的结点信息将被更新,在t+1 时刻被传送至图连接层,为新一轮对话带来历史信息.
2.6 损失计算
整个网络的损失由值结点标记损失和状态分类损失两部分组成.两部分损失都通过交叉熵损失函数(cross entropy loss)[20]计算得到,具体计算方式如下:
其中,Lv是值结点标记损失,LN是状态分类损失,α1和α2是通过开发集结果微调的超参数.
3 实验及分析
3.1 数据集
本文在3 个公开数据集CrossWOZ,MultiWOZ 2.0和MultiWOZ 2.1 上进行实验.CrossWOZ[17]是一个大规模跨领域中文任务导向对话数据集,包含6 000 余轮对话和102 万句话语,涉及5 种领域、72 种槽位、7 000 余种槽位值,每个对话平均涉及3.2 种领域.MultiWOZ 2.0[18]是英文多领域对话数据集,包含7种领域、25种槽位、4 500余种槽位值.为了对比的公平性,本文效仿文献[5]丢弃两个数量过少且仅出现在训练集的领域数据.MultiWOZ 2.1[19]是对2.0 版本数据集的修正版本.表2为3个数据集的具体信息统计.

表2 数据集信息统计
3.2 参数设置
针对CrossWOZ 数据集,本文采用文献[23]发布的BERT-WWM 版本作为预训练模型;针对MultiWOZ 2.0及MultiWOZ 2.1数据集,模型使用Google发布的BERTlarge-uncased[20]版本.模型初始学习率设为5e-5,学习率热身系数设为0.1,即在前10%的训练中,学习率从0递增至预设值,并在之后线性衰减.模型的优化算法使用Adam[24].其他参数通过对比开发集的实验结果来确定.模型批处理大小设置为32,在Tesla P40 GPU 上训练迭代100 个周期,当连续10 个周期损失没有降低时训练过程会提前终止.本文平均了多个随机种子下的实验结果,用以减少统计误差.
3.3 实验结果
表3和表4 分别给出了在中文数据集CrossWOZ和英文数据集MultiWOZ 上的实验结果.针对CrossWOZ数据集,本文与文献[15]提供的TRADE 模型进行性能比较.CrossWOZ 数据集的特点是大量对话发生在跨领域场景中,而跨领域或多领域场景会为模型带来更大的噪音,影响模型预测.表中S 表示单一领域;M表示多领域但是领域内信息并不发生交叉;M+T 表示多领域并且与交通领域相关;CM 表示跨领域,即领域内信息会发生交叉,多个槽位可能指向同一实体;CM+T 表示跨领域并且与交通领域相关.本文的模型与TRADE 模型相比在S 场景下联合正确率提升了0.97%,在M 场景下提升了1.47%,在M+T 场景下提升了1.27%,在CM 场景下提升了2.15%,在CM+T 场景下提升了2.09%,总体提升了1.39%.可以看出SMGN 模型在多领域和跨领域等复杂场景下性能提升更加明显.

表3 CrossWOZ数据集实验结果
表4 是在MultiWOZ 数据集上的实验结果.为了公平进行对比,本文将各个模型实验时使用模型的具体情况列在表4 中.其中“Ontology”列表示模型在实验中是否使用预定义本体方法.预定义本体是指在对话开始之前提前告知模型哪些槽位类型会出现在该对话中,使用预定义本体会大幅降低对话状态种类数目,从而降低任务难度.“BERT”列表示该模型在实验中是否使用例如BERT 等预训练语言模型.使用BERT 的模型相比其他模型在词向量编码过程中更有优势,模型可以捕获到更丰富的语义信息.

表4 MultiWOZ数据集实验结果
本文主要与以下对话状态跟踪方法进行对比.
DST-Reader[7]:将对话状态跟踪任务建模为阅读理解任务,通过预测字段跨度来提取槽位值.
HyST[23]:使用分层循环神经网络(Recurrent Neural Network,RNN)编码器,通过混合模型结合预定义本体与开放词表.
TRADE[5]:对整个对话历史文本进行编码,使用复制增强解码器对每个槽位进行解码.
DSTQA[6]:将对话状态跟踪任务建模为问答任务,并使用动态演变的知识图来学习槽值对的连接关系.
SOM-DST[24]:将对话状态视为一个固定大小的临时记忆,并提出了选择覆盖机制.
SUMBT[11]:使用BERT 作为话语,槽位和值的编码器,通过计算距离来对每个候选值进行评分.
SST[9]:利用注意力机制模拟对话状态模式图,通过循环网络控制状态更新.
从表4 可以看出,SMGN 在2 个数据集上的联合正确率分别为53.03%和54.88%.在MultiWOZ 2.0 数据集中本文模型超越其他模型;在MultiWOZ 2.1 数据集中,本文模型性能略弱于SST 模型,这是因为SST 模型是使用预定义本体方法方法设计的模型.相比起其他同种类模型,本文模型的性能有明显提升.
3.4 消融实验
在本节中,本文将进行消融实验,通过对模型中各个模块进行替换或删除后比较性能,从而验证SMGN模型中各部分改进的有效性.表5 是在MultiWOZ 2.0 数据集上进行消融实验的结果.
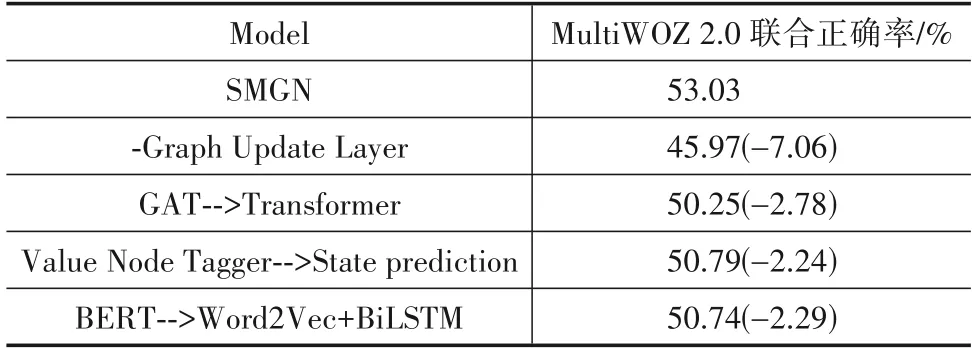
表5 消融实验结果
首先尝试从SMGN模型中删除图更新层,这将使模型变为静态模型,仅能保留上一轮对话的历史信息,更早的信息将被覆盖.这种方法会大幅降低模型的正确率.
其次尝试将模型图更新层中的图注意力GAT 网络替换为Transformer 结构,并使用结构图的连接关系作为注意力权重矩阵.这使得状态记忆图退化为仅利用边结构的模拟图方法.可以看出,替换后性能与隐式利用图网络的SST模型性能相近,这表明显式构建图网络可以有效提升模型对上文信息的利用能力.
为了与其他不使用BERT预训练语言模型的对话状态跟踪方法进行对比,本文将BERT 替换为Word2Vec+双向长短时记忆网络(Bidirectional Long Short-Term Memory,BiLSTM)方法并将其作为模型的编码层进行对比实验.从结果可以看出,使用预训练语言模型可以提升对话状态跟踪任务性能,但即使不使用BERT,状态记忆图网络仍然比其他同类模型性能更好.
最后本文尝试使用状态预测方法代替模型的值结点标记器,实验结果表明在使用状态记忆图的模型中,“标记值结点+结点分类”的方法会比直接进行状态预测的方法效果更好.
3.5 效率对比
SMGN 模型的另一优点是可以提高计算效率.由于使用了状态记忆图,模型无需在每一轮都对历史文本或对话状态进行重新编码,仅需要保存并传递状态记忆图中的结点信息和连接关系.为了证明以上观点,本文在相同的计算环境下,使用不同模型在MultiWOZ 2.0 数据集上进行实验,并对比一轮对话状态跟踪任务所需的平均时间,实验结果如表6 所示.其中SOMDST,SUMBT和本文提出的SMGN 模型使用BERT 作为编码器.

表6 模型计算效率对比
可以看出,相比TRADE 等对话文本编码模型,虽然BERT 编码器编码所需时间比RNN 要高出数倍,但是本文模型整体运算时间远低于此类模型.与其他状态信息编码模型相比,本文的模型计算效率仅略低于SST 模型,这主要是由于使用BERT 编码会比其他静态语言模型花费更多计算时间.但横向对比使用BERT作为编码器的SOM-DST和SUMBT 模型,本文模型可以提升48%~138%的计算效率.如果对运算效率有严格要求或没有GPU 运算资源,SST 模型是最佳选择;如果可以使用预训练语言模型,综合考量性能和效率,本文模型优势更明显.
3.6 样例分析
为了进一步验证SMGN 模型的有效性,本文在CrossWOZ 数据集中选取了一个跨领域场景的对话作为样例进行分析,结果如表7所示.

表7 CrossWOZ数据集示例结果对比
为了便于对比,在表格中省去了两种模型均预测正确的对话状态.在样例中,用户于第二轮对话时使用“那附近”一词代替了景点名称“寿延寺”,而“寿延寺”一词仅出现在上一轮对话历史中.TRADE 模型在这个样例中无法正确预测出用户希望寻找“寿延寺”景点附近的酒店,只能判断出酒店类型为高档型.另外,TRADE模型无法有效区分“延寿寺”和“延寿寺附近”这种语义非常相近的槽值,这导致餐馆领域的地点槽位没有找到完全正确的答案.本文的模型在状态记忆图中保留了第一轮对话形成的值结点“寿延寺附近”,在结合当前时刻用户的描述后模型可以正确判断出(酒店-位置-寿延寺附近)对话状态,并且“延寿寺”和“延寿寺附近”会作为两个向量相似但不同的值结点存储在状态记忆图中,使模型可以正确区分相似的槽值.这表明了SMGN 模型可以更加有效地处理复杂格式的对话状态生成要求,并且对历史对话的语义理解能力更强.
4 总结
针对对话状态跟踪任务,本文提出了一种状态记忆图网络模型,旨在显式利用对话状态自身结构来增加历史信息的语义理解能力.此外,针对复杂格式对话状态生成困难的问题,本文实现了一个基于状态记忆图的对话状态生成方法,通过判断结点连接情况来生成对话状态.因为结点定义自由且易于扩展,该方法可以应对不同格式的生成要求.本文在3 个公开的多轮对话数据集上进行了实验.实验结果表明,本文的方法可以有效提高对话状态跟踪任务的性能,同时可以提高运算效率.在今后的研究中会考虑如何将模型修改为并行的多任务学习模型,以解决现有模型会受到错误传播影响的问题.
